 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Learning from Synthetic Data: Facial Expression Classification based on Ensemble of Multi-task Networks
Jul 21, 2022
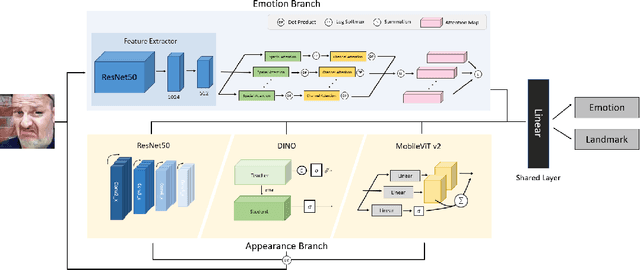


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Learning from Synthetic Data" (LSD) is an important topic in the facial expression recognition task. In this paper, we propose a multi-task learning-based facial expression recognition approach which consists of emotion and appearance learning branches that can share all face information, and present preliminary results for the LSD challenge introduced in the 4th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean F1 score of 0.71.
Human Body Pose Estimation for Gait Identification: A Comprehensive Survey of Datasets and Models
May 23, 2023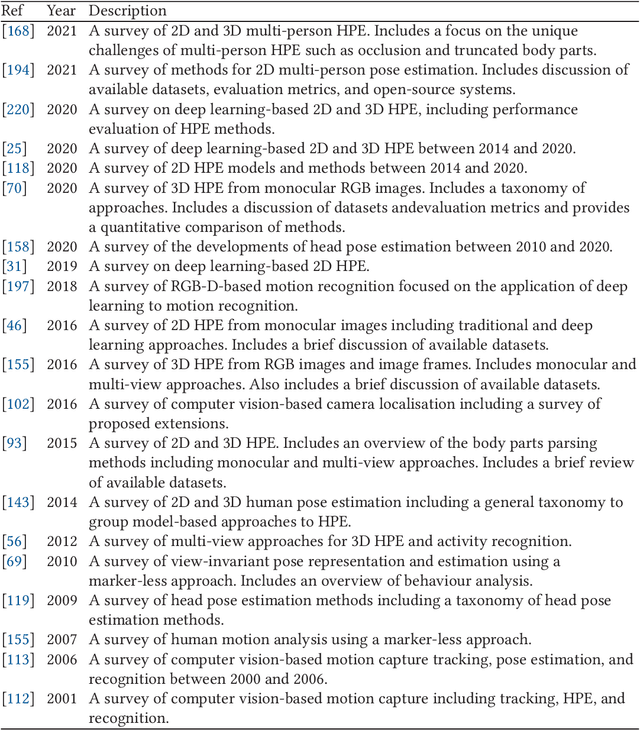
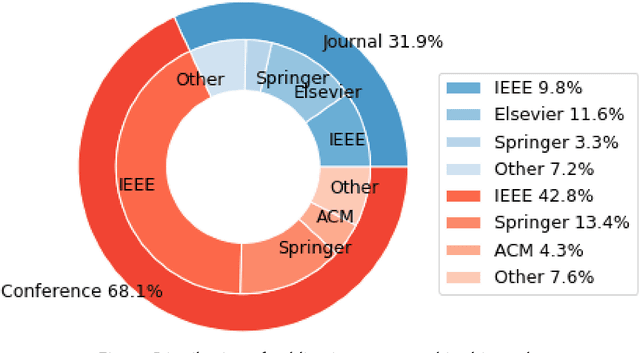

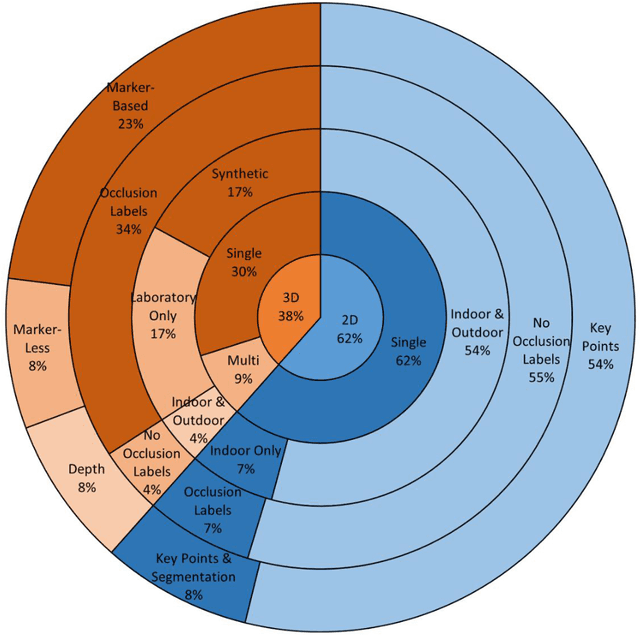
Person identification is a problem that has received substantial attention, particularly in security domains. Gait recognition is one of the most convenient approaches enabling person identification at a distance without the need of high-quality images. There are several review studies addressing person identification such as the utilization of facial images, silhouette images, and wearable sensor. Despite skeleton-based person identification gaining popularity while overcoming the challenges of traditional approaches, existing survey studies lack the comprehensive review of skeleton-based approaches to gait identification. We present a detailed review of the human pose estimation and gait analysis that make the skeleton-based approaches possible. The study covers various types of related datasets, tools, methodologies, and evaluation metrics with associated challenges, limitations, and application domains. Detailed comparisons are presented for each of these aspects with recommendations for potential research and alternatives. A common trend throughout this paper is the positive impact that deep learning techniques are beginning to have on topics such as human pose estimation and gait identification. The survey outcomes might be useful for the related research community and other stakeholders in terms of performance analysis of existing methodologies, potential research gaps, application domains, and possible contributions in the future.
Mimetic Muscle Rehabilitation Analysis Using Clustering of Low Dimensional 3D Kinect Data
Feb 15, 2023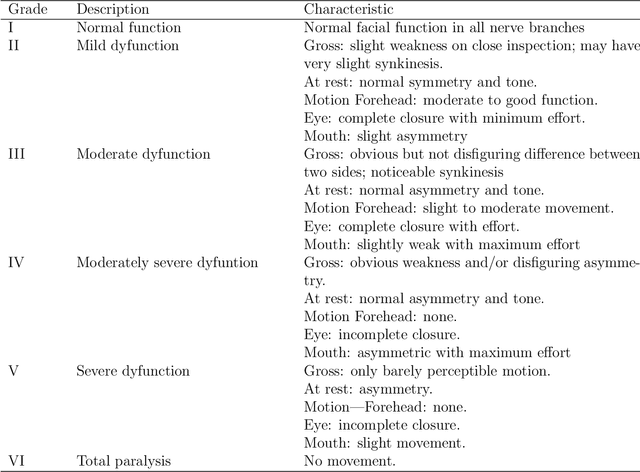
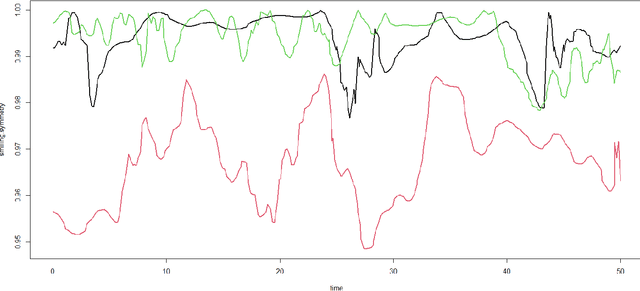
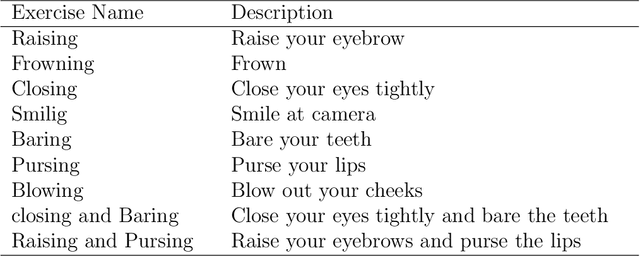
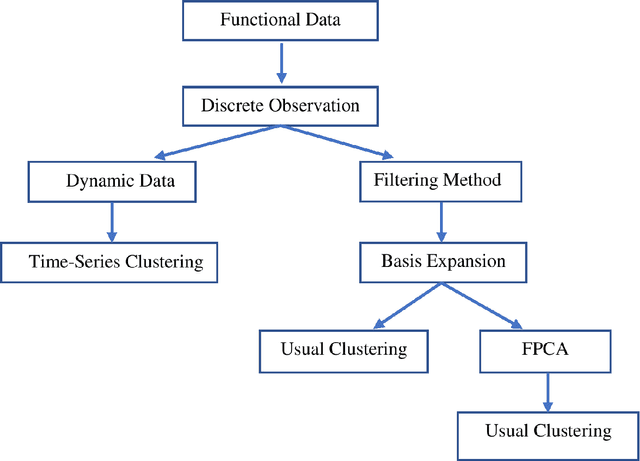
Facial nerve paresis is a severe complication that arises post-head and neck surgery; This results in articulation problems, facial asymmetry, and severe problems in non-verbal communication. To overcome the side effects of post-surgery facial paralysis, rehabilitation requires which last for several weeks. This paper discusses an unsupervised approach to rehabilitating patients who have temporary facial paralysis due to damage in mimetic muscles. The work aims to make the rehabilitation process objective compared to the current subjective approach, such as House-Brackmann (HB) scale. Also, the approach will assist clinicians by reducing their workload in assessing the improvement during rehabilitation. This paper focuses on the clustering approach to monitor the rehabilitation process. We compare the results obtained from different clustering algorithms on various forms of the same data set, namely dynamic form, data expressed as functional data using B-spline basis expansion, and by finding the functional principal components of the functional data. The study contains data set of 85 distinct patients with 120 measurements obtained using a Kinect stereo-vision camera. The method distinguish effectively between patients with the least and greatest degree of facial paralysis, however patients with adjacent degrees of paralysis provide some challenges. In addition, we compared the cluster results to the HB scale outputs.
Attribute-preserving Face Dataset Anonymization via Latent Code Optimization
Mar 20, 2023
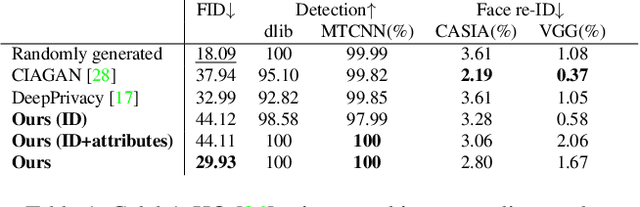
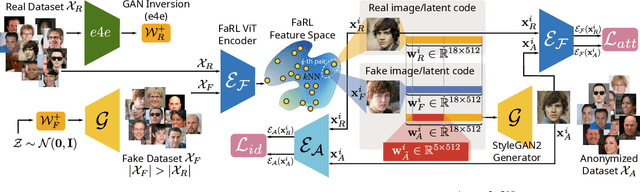

This work addresses the problem of anonymizing the identity of faces in a dataset of images, such that the privacy of those depicted is not violated, while at the same time the dataset is useful for downstream task such as for training machine learning models. To the best of our knowledge, we are the first to explicitly address this issue and deal with two major drawbacks of the existing state-of-the-art approaches, namely that they (i) require the costly training of additional, purpose-trained neural networks, and/or (ii) fail to retain the facial attributes of the original images in the anonymized counterparts, the preservation of which is of paramount importance for their use in downstream tasks. We accordingly present a task-agnostic anonymization procedure that directly optimizes the images' latent representation in the latent space of a pre-trained GAN. By optimizing the latent codes directly, we ensure both that the identity is of a desired distance away from the original (with an identity obfuscation loss), whilst preserving the facial attributes (using a novel feature-matching loss in FaRL's deep feature space). We demonstrate through a series of both qualitative and quantitative experiments that our method is capable of anonymizing the identity of the images whilst -- crucially -- better-preserving the facial attributes. We make the code and the pre-trained models publicly available at: https://github.com/chi0tzp/FALCO.
Zero-Shot Text-to-Parameter Translation for Game Character Auto-Creation
Mar 02, 2023
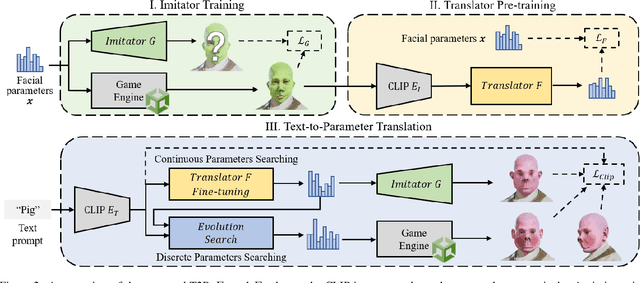

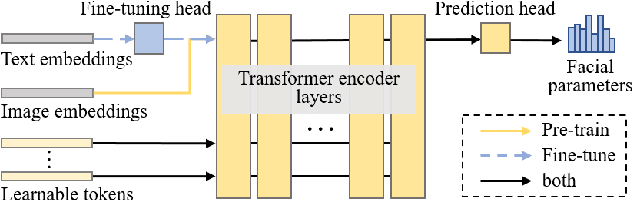
Recent popular Role-Playing Games (RPGs) saw the great success of character auto-creation systems. The bone-driven face model controlled by continuous parameters (like the position of bones) and discrete parameters (like the hairstyles) makes it possible for users to personalize and customize in-game characters. Previous in-game character auto-creation systems are mostly image-driven, where facial parameters are optimized so that the rendered character looks similar to the reference face photo. This paper proposes a novel text-to-parameter translation method (T2P) to achieve zero-shot text-driven game character auto-creation. With our method, users can create a vivid in-game character with arbitrary text description without using any reference photo or editing hundreds of parameters manually. In our method, taking the power of large-scale pre-trained multi-modal CLIP and neural rendering, T2P searches both continuous facial parameters and discrete facial parameters in a unified framework. Due to the discontinuous parameter representation, previous methods have difficulty in effectively learning discrete facial parameters. T2P, to our best knowledge, is the first method that can handle the optimization of both discrete and continuous parameters. Experimental results show that T2P can generate high-quality and vivid game characters with given text prompts. T2P outperforms other SOTA text-to-3D generation methods on both objective evaluations and subjective evaluations.
Diverse facial inpainting guided by exemplars
Feb 15, 2022
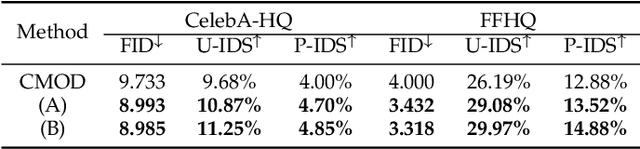
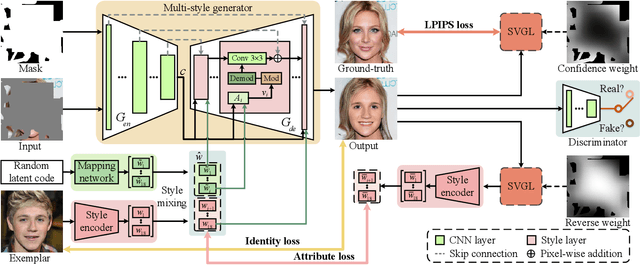
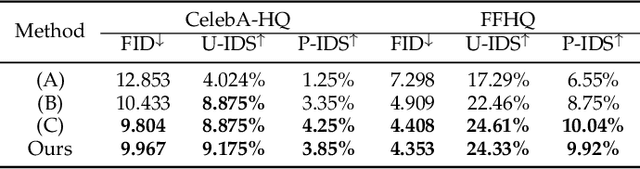
Facial image inpainting is a task of filling visually realistic and semantically meaningful contents for missing or masked pixels in a face image. Although existing methods have made significant progress in achieving high visual quality, the controllable diversity of facial image inpainting remains an open problem in this field. This paper introduces EXE-GAN, a novel diverse and interactive facial inpainting framework, which can not only preserve the high-quality visual effect of the whole image but also complete the face image with exemplar-like facial attributes. The proposed facial inpainting is achieved based on generative adversarial networks by leveraging the global style of input image, the stochastic style, and the exemplar style of exemplar image. A novel attribute similarity metric is introduced to encourage networks to learn the style of facial attributes from the exemplar in a self-supervised way. To guarantee the natural transition across the boundary of inpainted regions, a novel spatial variant gradient backpropagation technique is designed to adjust the loss gradients based on the spatial location. A variety of experimental results and comparisons on public CelebA-HQ and FFHQ datasets are presented to demonstrate the superiority of the proposed method in terms of both the quality and diversity in facial inpainting.
Makeup Extraction of 3D Representation via Illumination-Aware Image Decomposition
Feb 26, 2023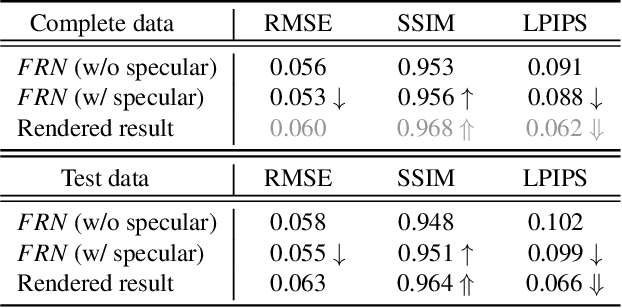

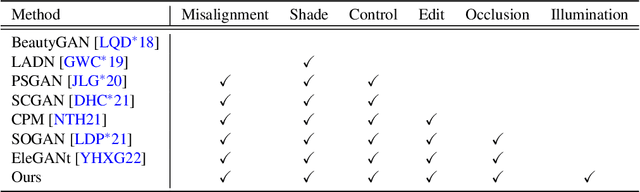
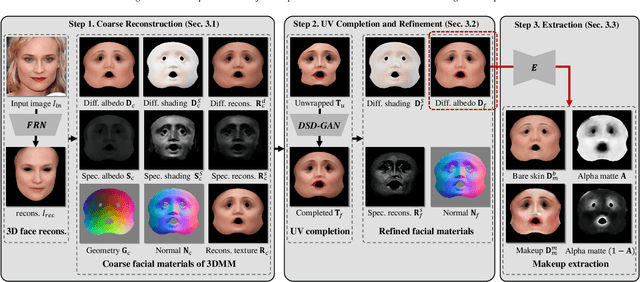
Facial makeup enriches the beauty of not only real humans but also virtual characters; therefore, makeup for 3D facial models is highly in demand in productions. However, painting directly on 3D faces and capturing real-world makeup are costly, and extracting makeup from 2D images often struggles with shading effects and occlusions. This paper presents the first method for extracting makeup for 3D facial models from a single makeup portrait. Our method consists of the following three steps. First, we exploit the strong prior of 3D morphable models via regression-based inverse rendering to extract coarse materials such as geometry and diffuse/specular albedos that are represented in the UV space. Second, we refine the coarse materials, which may have missing pixels due to occlusions. We apply inpainting and optimization. Finally, we extract the bare skin, makeup, and an alpha matte from the diffuse albedo. Our method offers various applications for not only 3D facial models but also 2D portrait images. The extracted makeup is well-aligned in the UV space, from which we build a large-scale makeup dataset and a parametric makeup model for 3D faces. Our disentangled materials also yield robust makeup transfer and illumination-aware makeup interpolation/removal without a reference image.
Parameter Efficient Local Implicit Image Function Network for Face Segmentation
Mar 27, 2023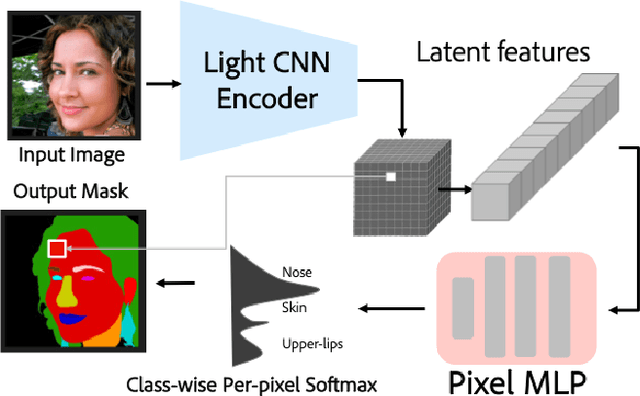
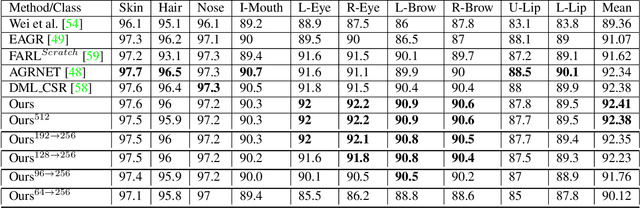

Face parsing is defined as the per-pixel labeling of images containing human faces. The labels are defined to identify key facial regions like eyes, lips, nose, hair, etc. In this work, we make use of the structural consistency of the human face to propose a lightweight face-parsing method using a Local Implicit Function network, FP-LIIF. We propose a simple architecture having a convolutional encoder and a pixel MLP decoder that uses 1/26th number of parameters compared to the state-of-the-art models and yet matches or outperforms state-of-the-art models on multiple datasets, like CelebAMask-HQ and LaPa. We do not use any pretraining, and compared to other works, our network can also generate segmentation at different resolutions without any changes in the input resolution. This work enables the use of facial segmentation on low-compute or low-bandwidth devices because of its higher FPS and smaller model size.
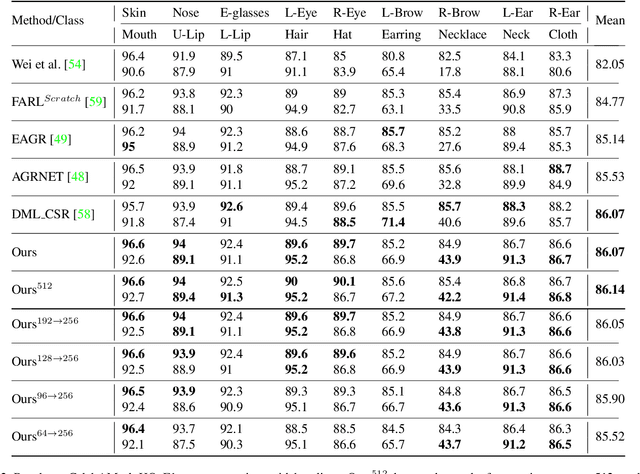
Face Transformer: Towards High Fidelity and Accurate Face Swapping
Apr 05, 2023
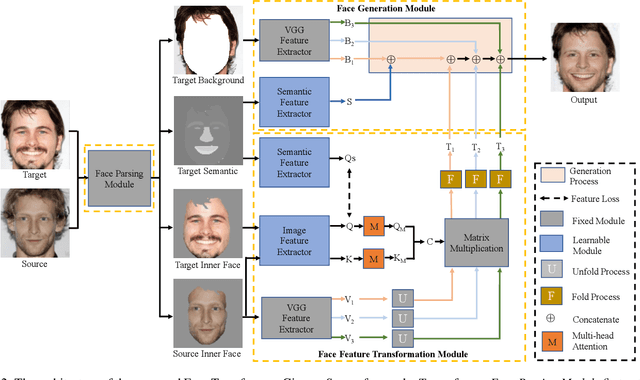
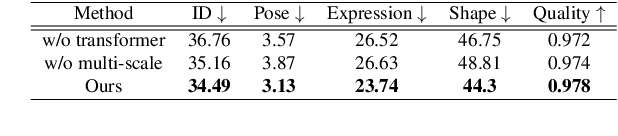
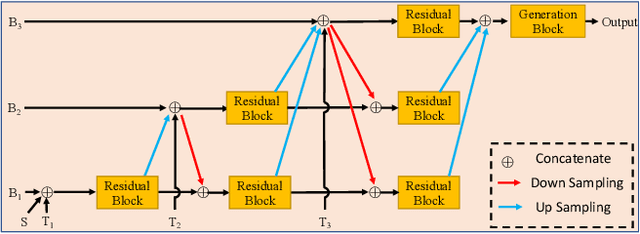
Face swapping aims to generate swapped images that fuse the identity of source faces and the attributes of target faces. Most existing works address this challenging task through 3D modelling or generation using generative adversarial networks (GANs), but 3D modelling suffers from limited reconstruction accuracy and GANs often struggle in preserving subtle yet important identity details of source faces (e.g., skin colors, face features) and structural attributes of target faces (e.g., face shapes, facial expressions). This paper presents Face Transformer, a novel face swapping network that can accurately preserve source identities and target attributes simultaneously in the swapped face images. We introduce a transformer network for the face swapping task, which learns high-quality semantic-aware correspondence between source and target faces and maps identity features of source faces to the corresponding region in target faces. The high-quality semantic-aware correspondence enables smooth and accurate transfer of source identity information with minimal modification of target shapes and expressions. In addition, our Face Transformer incorporates a multi-scale transformation mechanism for preserving the rich fine facial details. Extensive experiments show that our Face Transformer achieves superior face swapping performance qualitatively and quantitatively.
DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder
Apr 23, 2023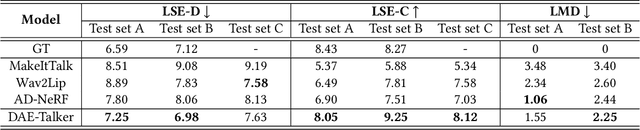
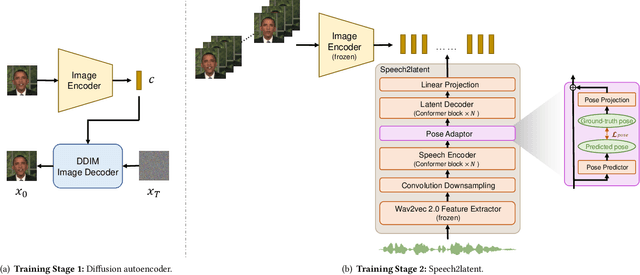

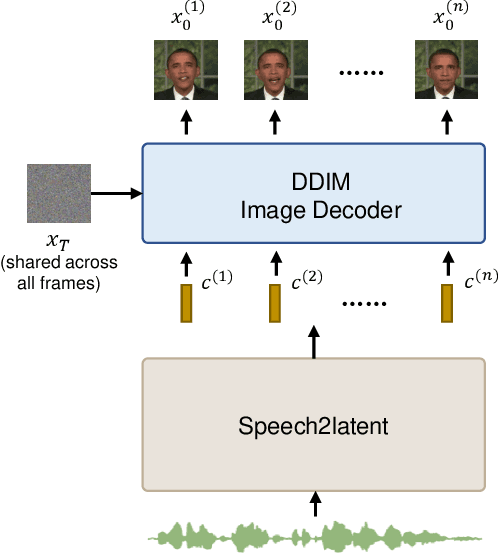
While recent research has made significant progress in speech-driven talking face generation, the quality of the generated video still lags behind that of real recordings. One reason for this is the use of handcrafted intermediate representations like facial landmarks and 3DMM coefficients, which are designed based on human knowledge and are insufficient to precisely describe facial movements. Additionally, these methods require an external pretrained model for extracting these representations, whose performance sets an upper bound on talking face generation. To address these limitations, we propose a novel method called DAE-Talker that leverages data-driven latent representations obtained from a diffusion autoencoder (DAE). DAE contains an image encoder that encodes an image into a latent vector and a DDIM image decoder that reconstructs the image from it. We train our DAE on talking face video frames and then extract their latent representations as the training target for a Conformer-based speech2latent model. This allows DAE-Talker to synthesize full video frames and produce natural head movements that align with the content of speech, rather than relying on a predetermined head pose from a template video. We also introduce pose modelling in speech2latent for pose controllability. Additionally, we propose a novel method for generating continuous video frames with the DDIM image decoder trained on individual frames, eliminating the need for modelling the joint distribution of consecutive frames directly. Our experiments show that DAE-Talker outperforms existing popular methods in lip-sync, video fidelity, and pose naturalness. We also conduct ablation studies to analyze the effectiveness of the proposed techniques and demonstrate the pose controllability of DAE-Talker.