 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
K-Act2Emo: Korean Commonsense Knowledge Graph for Indirect Emotional Expression
Mar 23, 2024
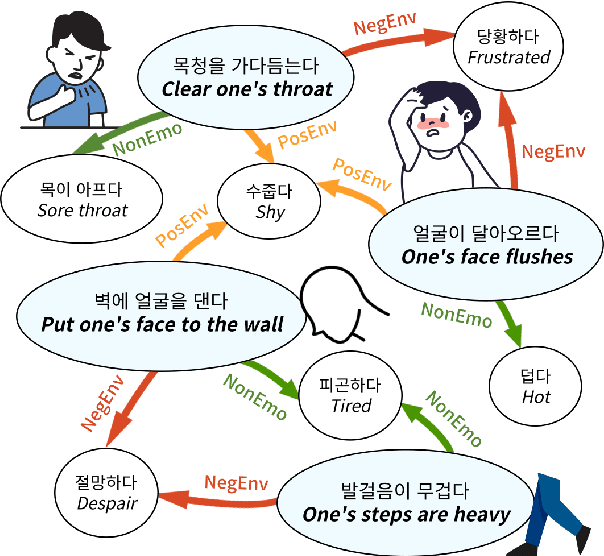



In many literary texts, emotions are indirectly conveyed through descriptions of actions, facial expressions, and appearances, necessitating emotion inference for narrative understanding. In this paper, we introduce K-Act2Emo, a Korean commonsense knowledge graph (CSKG) comprising 1,900 indirect emotional expressions and the emotions inferable from them. We categorize reasoning types into inferences in positive situations, inferences in negative situations, and inferences when expressions do not serve as emotional cues. Unlike existing CSKGs, K-Act2Emo specializes in emotional contexts, and experimental results validate its effectiveness for training emotion inference models. Significantly, the BART-based knowledge model fine-tuned with K-Act2Emo outperforms various existing Korean large language models, achieving performance levels comparable to GPT-4 Turbo.
AniArtAvatar: Animatable 3D Art Avatar from a Single Image
Mar 26, 2024We present a novel approach for generating animatable 3D-aware art avatars from a single image, with controllable facial expressions, head poses, and shoulder movements. Unlike previous reenactment methods, our approach utilizes a view-conditioned 2D diffusion model to synthesize multi-view images from a single art portrait with a neutral expression. With the generated colors and normals, we synthesize a static avatar using an SDF-based neural surface. For avatar animation, we extract control points, transfer the motion with these points, and deform the implicit canonical space. Firstly, we render the front image of the avatar, extract the 2D landmarks, and project them to the 3D space using a trained SDF network. We extract 3D driving landmarks using 3DMM and transfer the motion to the avatar landmarks. To animate the avatar pose, we manually set the body height and bound the head and torso of an avatar with two cages. The head and torso can be animated by transforming the two cages. Our approach is a one-shot pipeline that can be applied to various styles. Experiments demonstrate that our method can generate high-quality 3D art avatars with desired control over different motions.
A Picture is Worth 500 Labels: A Case Study of Demographic Disparities in Local Machine Learning Models for Instagram and TikTok
Mar 27, 2024Mobile apps have embraced user privacy by moving their data processing to the user's smartphone. Advanced machine learning (ML) models, such as vision models, can now locally analyze user images to extract insights that drive several functionalities. Capitalizing on this new processing model of locally analyzing user images, we analyze two popular social media apps, TikTok and Instagram, to reveal (1) what insights vision models in both apps infer about users from their image and video data and (2) whether these models exhibit performance disparities with respect to demographics. As vision models provide signals for sensitive technologies like age verification and facial recognition, understanding potential biases in these models is crucial for ensuring that users receive equitable and accurate services. We develop a novel method for capturing and evaluating ML tasks in mobile apps, overcoming challenges like code obfuscation, native code execution, and scalability. Our method comprises ML task detection, ML pipeline reconstruction, and ML performance assessment, specifically focusing on demographic disparities. We apply our methodology to TikTok and Instagram, revealing significant insights. For TikTok, we find issues in age and gender prediction accuracy, particularly for minors and Black individuals. In Instagram, our analysis uncovers demographic disparities in the extraction of over 500 visual concepts from images, with evidence of spurious correlations between demographic features and certain concepts.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
WaveFace: Authentic Face Restoration with Efficient Frequency Recovery
Mar 19, 2024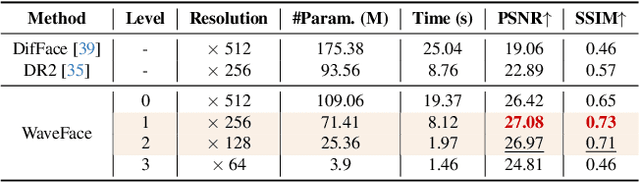
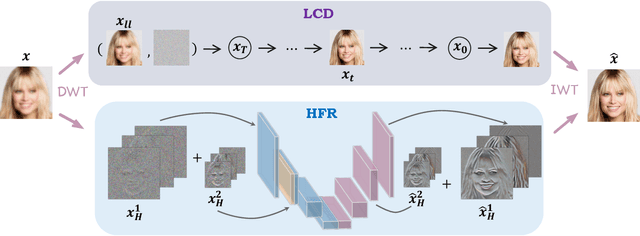
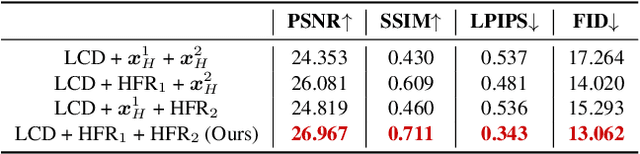

Although diffusion models are rising as a powerful solution for blind face restoration, they are criticized for two problems: 1) slow training and inference speed, and 2) failure in preserving identity and recovering fine-grained facial details. In this work, we propose WaveFace to solve the problems in the frequency domain, where low- and high-frequency components decomposed by wavelet transformation are considered individually to maximize authenticity as well as efficiency. The diffusion model is applied to recover the low-frequency component only, which presents general information of the original image but 1/16 in size. To preserve the original identity, the generation is conditioned on the low-frequency component of low-quality images at each denoising step. Meanwhile, high-frequency components at multiple decomposition levels are handled by a unified network, which recovers complex facial details in a single step. Evaluations on four benchmark datasets show that: 1) WaveFace outperforms state-of-the-art methods in authenticity, especially in terms of identity preservation, and 2) authentic images are restored with the efficiency 10x faster than existing diffusion model-based BFR methods.
Towards Realistic Landmark-Guided Facial Video Inpainting Based on GANs
Feb 14, 2024Facial video inpainting plays a crucial role in a wide range of applications, including but not limited to the removal of obstructions in video conferencing and telemedicine, enhancement of facial expression analysis, privacy protection, integration of graphical overlays, and virtual makeup. This domain presents serious challenges due to the intricate nature of facial features and the inherent human familiarity with faces, heightening the need for accurate and persuasive completions. In addressing challenges specifically related to occlusion removal in this context, our focus is on the progressive task of generating complete images from facial data covered by masks, ensuring both spatial and temporal coherence. Our study introduces a network designed for expression-based video inpainting, employing generative adversarial networks (GANs) to handle static and moving occlusions across all frames. By utilizing facial landmarks and an occlusion-free reference image, our model maintains the user's identity consistently across frames. We further enhance emotional preservation through a customized facial expression recognition (FER) loss function, ensuring detailed inpainted outputs. Our proposed framework exhibits proficiency in eliminating occlusions from facial videos in an adaptive form, whether appearing static or dynamic on the frames, while providing realistic and coherent results.
Biased Binary Attribute Classifiers Ignore the Majority Classes
Mar 21, 2024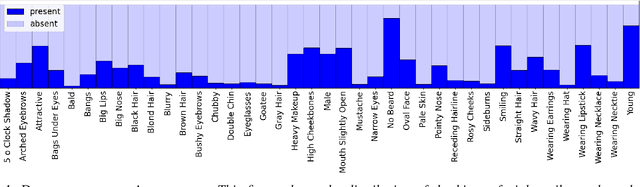
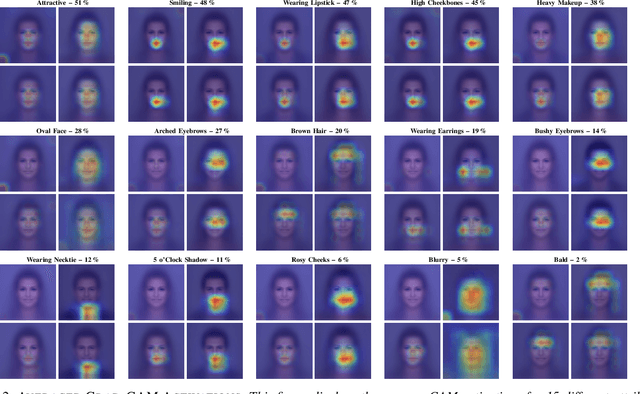
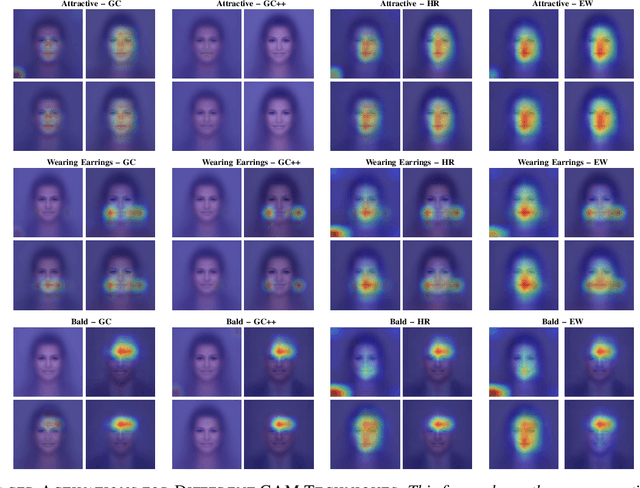

To visualize the regions of interest that classifiers base their decisions on, different Class Activation Mapping (CAM) methods have been developed. However, all of these techniques target categorical classifiers only, though most real-world tasks are binary classification. In this paper, we extend gradient-based CAM techniques to work with binary classifiers and visualize the active regions for binary facial attribute classifiers. When training an unbalanced binary classifier on an imbalanced dataset, it is well-known that the majority class, i.e. the class with many training samples, is mostly predicted much better than minority class with few training instances. In our experiments on the CelebA dataset, we verify these results, when training an unbalanced classifier to extract 40 facial attributes simultaneously. One would expect that the biased classifier has learned to extract features mainly for the majority classes and that the proportional energy of the activations mainly reside in certain specific regions of the image where the attribute is located. However, we find very little regular activation for samples of majority classes, while the active regions for minority classes seem mostly reasonable and overlap with our expectations. These results suggest that biased classifiers mainly rely on bias activation for majority classes. When training a balanced classifier on the imbalanced data by employing attribute-specific class weights, majority and minority classes are classified similarly well and show expected activations for almost all attributes
Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework
Mar 25, 2024Despite the remarkable process of talking-head-based avatar-creating solutions, directly generating anchor-style videos with full-body motions remains challenging. In this study, we propose Make-Your-Anchor, a novel system necessitating only a one-minute video clip of an individual for training, subsequently enabling the automatic generation of anchor-style videos with precise torso and hand movements. Specifically, we finetune a proposed structure-guided diffusion model on input video to render 3D mesh conditions into human appearances. We adopt a two-stage training strategy for the diffusion model, effectively binding movements with specific appearances. To produce arbitrary long temporal video, we extend the 2D U-Net in the frame-wise diffusion model to a 3D style without additional training cost, and a simple yet effective batch-overlapped temporal denoising module is proposed to bypass the constraints on video length during inference. Finally, a novel identity-specific face enhancement module is introduced to improve the visual quality of facial regions in the output videos. Comparative experiments demonstrate the effectiveness and superiority of the system in terms of visual quality, temporal coherence, and identity preservation, outperforming SOTA diffusion/non-diffusion methods. Project page: \url{https://github.com/ICTMCG/Make-Your-Anchor}.
Diffusion Model is a Good Pose Estimator from 3D RF-Vision
Mar 24, 2024Human pose estimation (HPE) from Radio Frequency vision (RF-vision) performs human sensing using RF signals that penetrate obstacles without revealing privacy (e.g., facial information). Recently, mmWave radar has emerged as a promising RF-vision sensor, providing radar point clouds by processing RF signals. However, the mmWave radar has a limited resolution with severe noise, leading to inaccurate and inconsistent human pose estimation. This work proposes mmDiff, a novel diffusion-based pose estimator tailored for noisy radar data. Our approach aims to provide reliable guidance as conditions to diffusion models. Two key challenges are addressed by mmDiff: (1) miss-detection of parts of human bodies, which is addressed by a module that isolates feature extraction from different body parts, and (2) signal inconsistency due to environmental interference, which is tackled by incorporating prior knowledge of body structure and motion. Several modules are designed to achieve these goals, whose features work as the conditions for the subsequent diffusion model, eliminating the miss-detection and instability of HPE based on RF-vision. Extensive experiments demonstrate that mmDiff outperforms existing methods significantly, achieving state-of-the-art performances on public datasets.