 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Dual-discriminator GAN: A GAN way of profile face recognition
Mar 20, 2020
A wealth of angle problems occur when facial recognition is performed: At present, the feature extraction network presents eigenvectors with large differences between the frontal face and profile face recognition of the same person in many cases. For this reason, the state-of-the-art facial recognition network will use multiple samples for the same target to ensure that eigenvector differences caused by angles are ignored during training. However, there is another solution available, which is to generate frontal face images with profile face images before recognition. In this paper, we proposed a method of generating frontal faces with image-to-image profile faces based on Generative Adversarial Network (GAN).
Pose-aware Adversarial Domain Adaptation for Personalized Facial Expression Recognition
Jul 12, 2020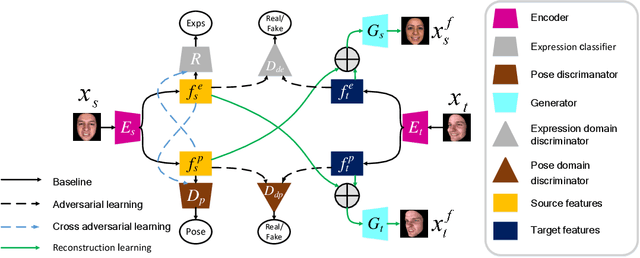
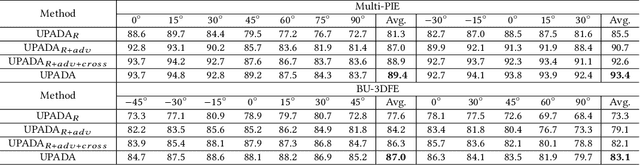
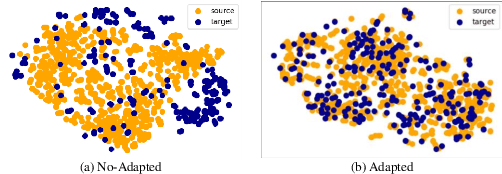
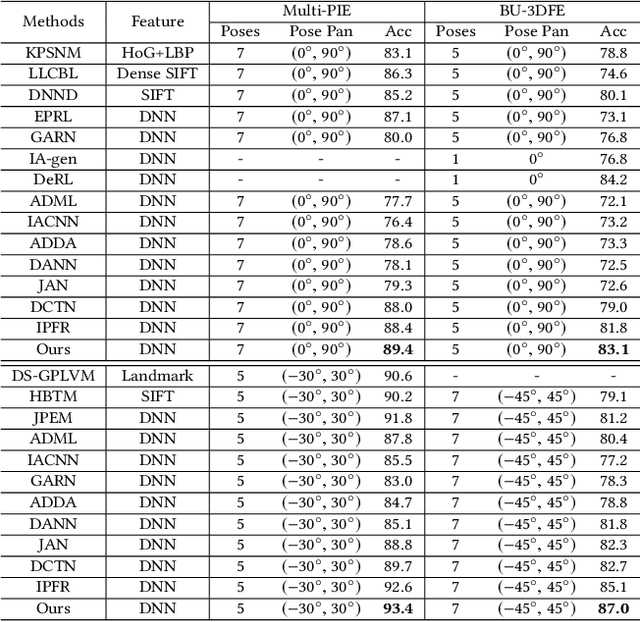
Current facial expression recognition methods fail to simultaneously cope with pose and subject variations. In this paper, we propose a novel unsupervised adversarial domain adaptation method which can alleviate both variations at the same time. Specially, our method consists of three learning strategies: adversarial domain adaptation learning, cross adversarial feature learning, and reconstruction learning. The first aims to learn pose- and expression-related feature representations in the source domain and adapt both feature distributions to that of the target domain by imposing adversarial learning. By using personalized adversarial domain adaptation, this learning strategy can alleviate subject variations and exploit information from the source domain to help learning in the target domain. The second serves to perform feature disentanglement between pose- and expression-related feature representations by impulsing pose-related feature representations expression-undistinguished and the expression-related feature representations pose-undistinguished. The last can further boost feature learning by applying face image reconstructions so that the learned expression-related feature representations are more pose- and identity-robust. Experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method.
The Florence 4D Facial Expression Dataset
Oct 30, 2022
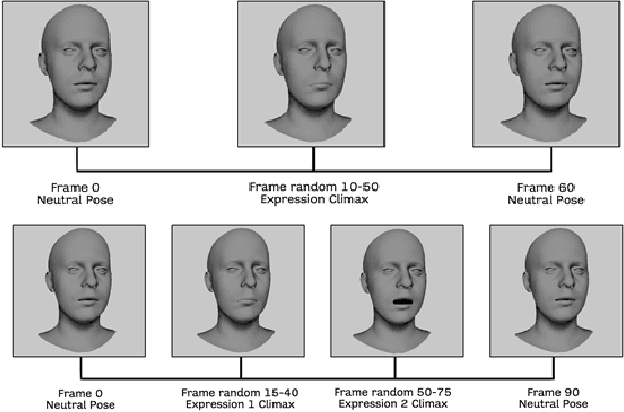

Human facial expressions change dynamically, so their recognition / analysis should be conducted by accounting for the temporal evolution of face deformations either in 2D or 3D. While abundant 2D video data do exist, this is not the case in 3D, where few 3D dynamic (4D) datasets were released for public use. The negative consequence of this scarcity of data is amplified by current deep learning based-methods for facial expression analysis that require large quantities of variegate samples to be effectively trained. With the aim of smoothing such limitations, in this paper we propose a large dataset, named Florence 4D, composed of dynamic sequences of 3D face models, where a combination of synthetic and real identities exhibit an unprecedented variety of 4D facial expressions, with variations that include the classical neutral-apex transition, but generalize to expression-to-expression. All these characteristics are not exposed by any of the existing 4D datasets and they cannot even be obtained by combining more than one dataset. We strongly believe that making such a data corpora publicly available to the community will allow designing and experimenting new applications that were not possible to investigate till now. To show at some extent the difficulty of our data in terms of different identities and varying expressions, we also report a baseline experimentation on the proposed dataset that can be used as baseline.
Generating Unrestricted 3D Adversarial Point Clouds
Nov 19, 2021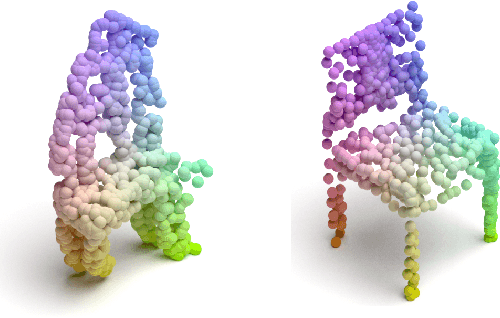
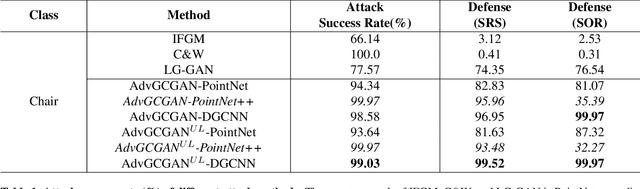
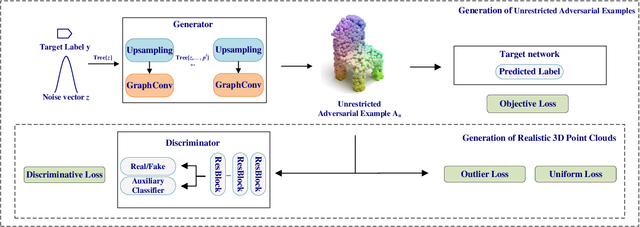
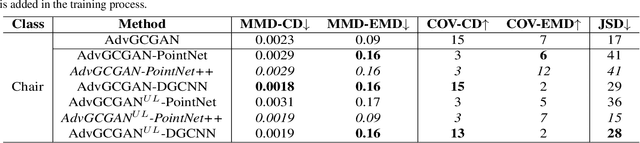
Utilizing 3D point cloud data has become an urgent need for the deployment of artificial intelligence in many areas like facial recognition and self-driving. However, deep learning for 3D point clouds is still vulnerable to adversarial attacks, e.g., iterative attacks, point transformation attacks, and generative attacks. These attacks need to restrict perturbations of adversarial examples within a strict bound, leading to the unrealistic adversarial 3D point clouds. In this paper, we propose an Adversarial Graph-Convolutional Generative Adversarial Network (AdvGCGAN) to generate visually realistic adversarial 3D point clouds from scratch. Specifically, we use a graph convolutional generator and a discriminator with an auxiliary classifier to generate realistic point clouds, which learn the latent distribution from the real 3D data. The unrestricted adversarial attack loss is incorporated in the special adversarial training of GAN, which enables the generator to generate the adversarial examples to spoof the target network. Compared with the existing state-of-art attack methods, the experiment results demonstrate the effectiveness of our unrestricted adversarial attack methods with a higher attack success rate and visual quality. Additionally, the proposed AdvGCGAN can achieve better performance against defense models and better transferability than existing attack methods with strong camouflage.
Fine-tuning Wav2vec for Vocal-burst Emotion Recognition
Oct 01, 2022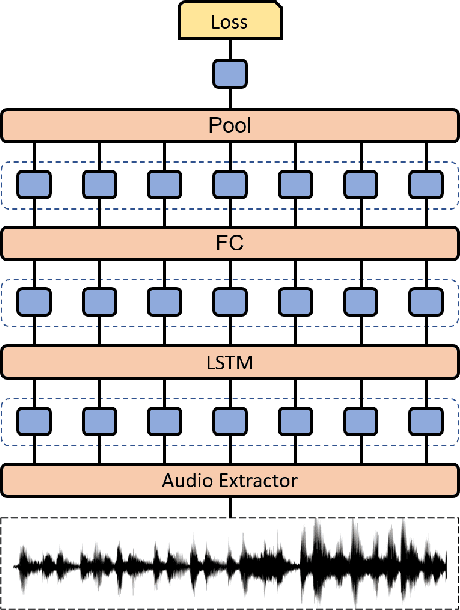
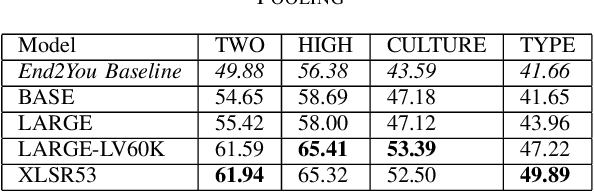
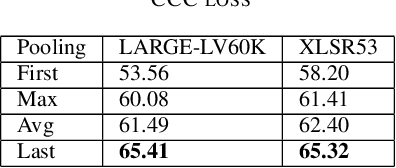
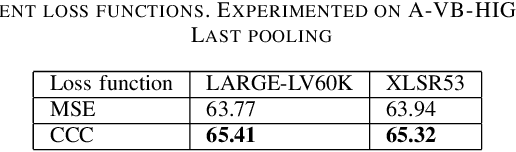
The ACII Affective Vocal Bursts (A-VB) competition introduces a new topic in affective computing, which is understanding emotional expression using the non-verbal sound of humans. We are familiar with emotion recognition via verbal vocal or facial expression. However, the vocal bursts such as laughs, cries, and signs, are not exploited even though they are very informative for behavior analysis. The A-VB competition comprises four tasks that explore non-verbal information in different spaces. This technical report describes the method and the result of SclabCNU Team for the tasks of the challenge. We achieved promising results compared to the baseline model provided by the organizers.
Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network
Jan 22, 2022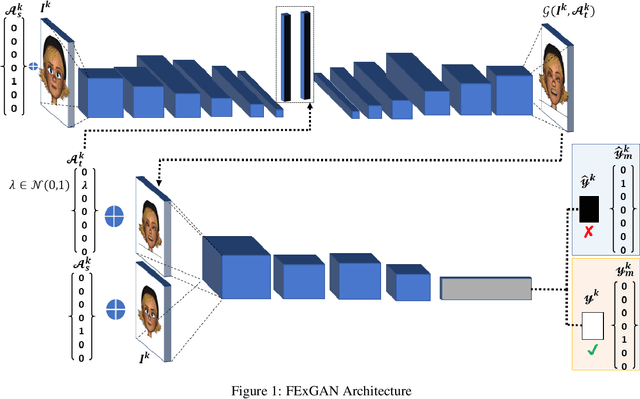
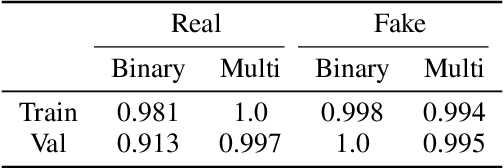
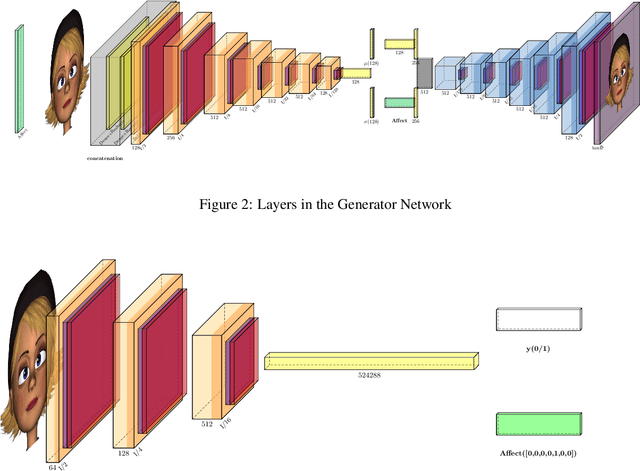

Facial expressions are a form of non-verbal communication that humans perform seamlessly for meaningful transfer of information. Most of the literature addresses the facial expression recognition aspect however, with the advent of Generative Models, it has become possible to explore the affect space in addition to mere classification of a set of expressions. In this article, we propose a generative model architecture which robustly generates a set of facial expressions for multiple character identities and explores the possibilities of generating complex expressions by combining the simple ones.
What happens in Face during a facial expression? Using data mining techniques to analyze facial expression motion vectors
Sep 12, 2021
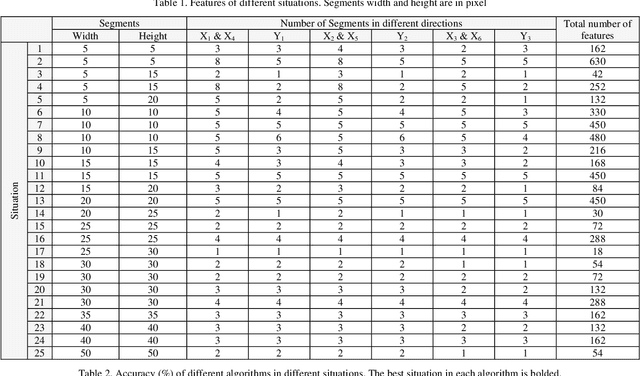


One of the most common problems encountered in human-computer interaction is automatic facial expression recognition. Although it is easy for human observer to recognize facial expressions, automatic recognition remains difficult for machines. One of the methods that machines can recognize facial expression is analyzing the changes in face during facial expression presentation. In this paper, optical flow algorithm was used to extract deformation or motion vectors created in the face because of facial expressions. Then, these extracted motion vectors are used to be analyzed. Their positions and directions were exploited for automatic facial expression recognition using different data mining techniques. It means that by employing motion vector features used as our data, facial expressions were recognized. Some of the most state-of-the-art classification algorithms such as C5.0, CRT, QUEST, CHAID, Deep Learning (DL), SVM and Discriminant algorithms were used to classify the extracted motion vectors. Using 10-fold cross validation, their performances were calculated. To compare their performance more precisely, the test was repeated 50 times. Meanwhile, the deformation of face was also analyzed in this research. For example, what exactly happened in each part of face when a person showed fear? Experimental results on Extended Cohen-Kanade (CK+) facial expression dataset demonstrated that the best methods were DL, SVM and C5.0, with the accuracy of 95.3%, 92.8% and 90.2% respectively.
MetaBalance: High-Performance Neural Networks for Class-Imbalanced Data
Jun 17, 2021
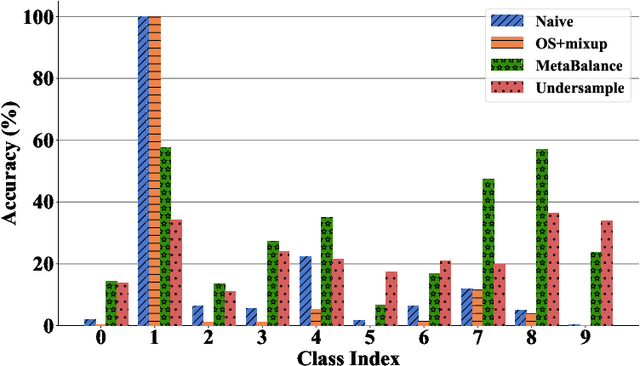
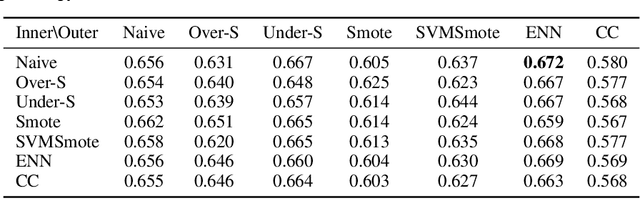
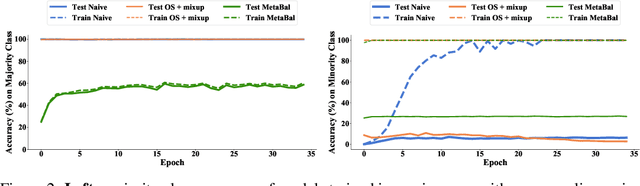
Class-imbalanced data, in which some classes contain far more samples than others, is ubiquitous in real-world applications. Standard techniques for handling class-imbalance usually work by training on a re-weighted loss or on re-balanced data. Unfortunately, training overparameterized neural networks on such objectives causes rapid memorization of minority class data. To avoid this trap, we harness meta-learning, which uses both an ''outer-loop'' and an ''inner-loop'' loss, each of which may be balanced using different strategies. We evaluate our method, MetaBalance, on image classification, credit-card fraud detection, loan default prediction, and facial recognition tasks with severely imbalanced data, and we find that MetaBalance outperforms a wide array of popular re-sampling strategies.
A Survey of the Trends in Facial and Expression Recognition Databases and Methods
Dec 05, 2015

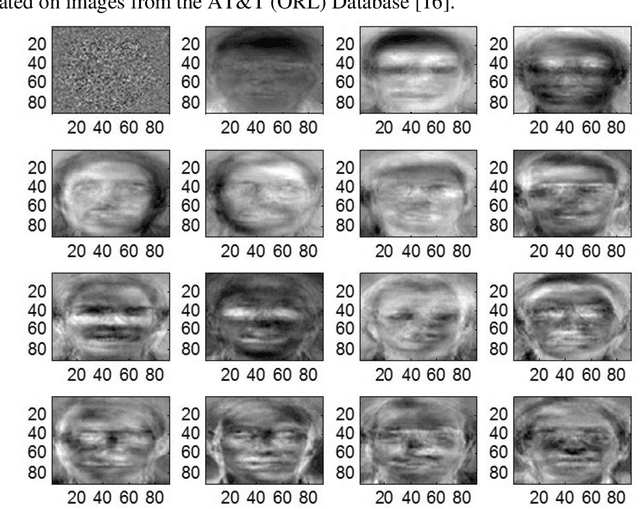
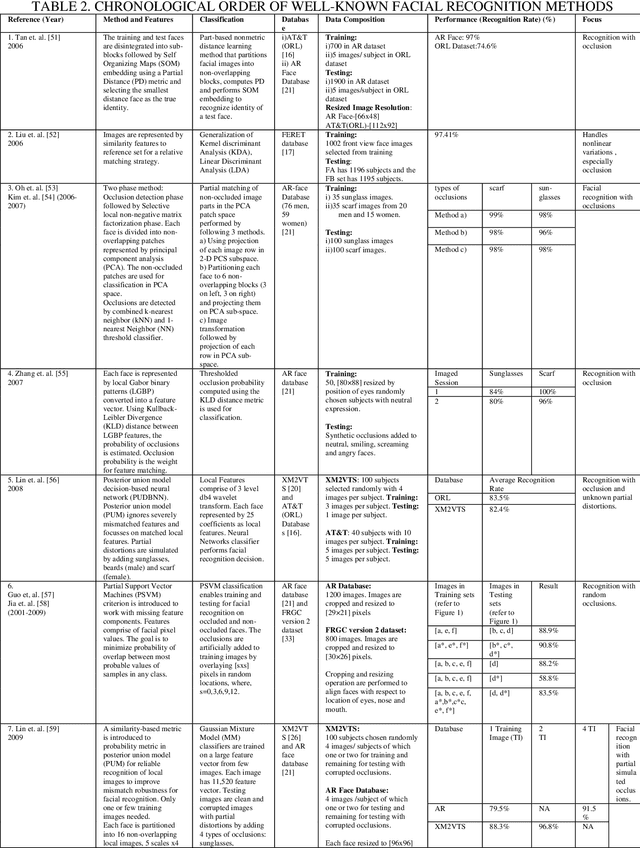
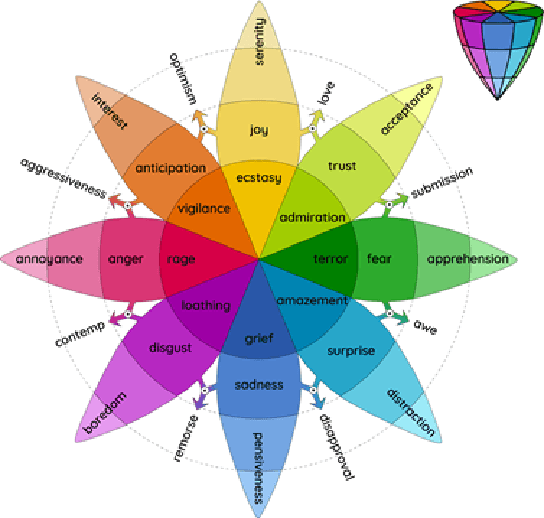
Automated facial identification and facial expression recognition have been topics of active research over the past few decades. Facial and expression recognition find applications in human-computer interfaces, subject tracking, real-time security surveillance systems and social networking. Several holistic and geometric methods have been developed to identify faces and expressions using public and local facial image databases. In this work we present the evolution in facial image data sets and the methodologies for facial identification and recognition of expressions such as anger, sadness, happiness, disgust, fear and surprise. We observe that most of the earlier methods for facial and expression recognition aimed at improving the recognition rates for facial feature-based methods using static images. However, the recent methodologies have shifted focus towards robust implementation of facial/expression recognition from large image databases that vary with space (gathered from the internet) and time (video recordings). The evolution trends in databases and methodologies for facial and expression recognition can be useful for assessing the next-generation topics that may have applications in security systems or personal identification systems that involve "Quantitative face" assessments.
* 16 pages, 4 figures, 3 tables, International Journal of Computer Science and Engineering Survey, October, 2015