 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Faceptor: A Generalist Model for Face Perception
Mar 14, 2024
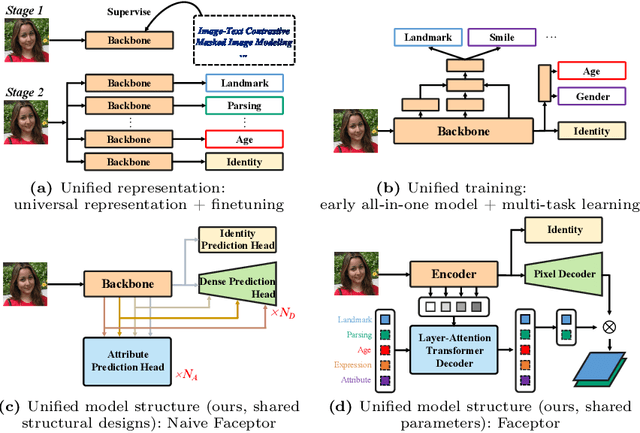

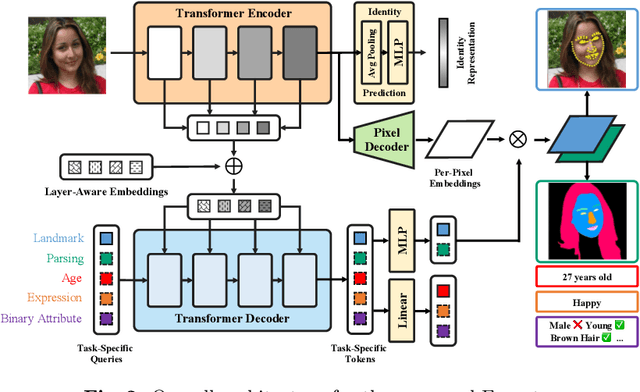
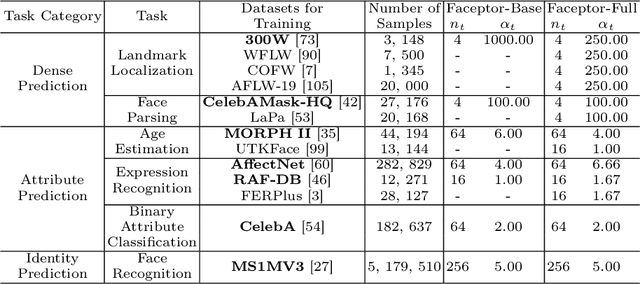
With the comprehensive research conducted on various face analysis tasks, there is a growing interest among researchers to develop a unified approach to face perception. Existing methods mainly discuss unified representation and training, which lack task extensibility and application efficiency. To tackle this issue, we focus on the unified model structure, exploring a face generalist model. As an intuitive design, Naive Faceptor enables tasks with the same output shape and granularity to share the structural design of the standardized output head, achieving improved task extensibility. Furthermore, Faceptor is proposed to adopt a well-designed single-encoder dual-decoder architecture, allowing task-specific queries to represent new-coming semantics. This design enhances the unification of model structure while improving application efficiency in terms of storage overhead. Additionally, we introduce Layer-Attention into Faceptor, enabling the model to adaptively select features from optimal layers to perform the desired tasks. Through joint training on 13 face perception datasets, Faceptor achieves exceptional performance in facial landmark localization, face parsing, age estimation, expression recognition, binary attribute classification, and face recognition, achieving or surpassing specialized methods in most tasks. Our training framework can also be applied to auxiliary supervised learning, significantly improving performance in data-sparse tasks such as age estimation and expression recognition. The code and models will be made publicly available at https://github.com/lxq1000/Faceptor.
GiMeFive: Towards Interpretable Facial Emotion Classification
Feb 24, 2024Deep convolutional neural networks have been shown to successfully recognize facial emotions for the past years in the realm of computer vision. However, the existing detection approaches are not always reliable or explainable, we here propose our model GiMeFive with interpretations, i.e., via layer activations and gradient-weighted class activation mapping. We compare against the state-of-the-art methods to classify the six facial emotions. Empirical results show that our model outperforms the previous methods in terms of accuracy on two Facial Emotion Recognition (FER) benchmarks and our aggregated FER GiMeFive. Furthermore, we explain our work in real-world image and video examples, as well as real-time live camera streams. Our code and supplementary material are available at https: //github.com/werywjw/SEP-CVDL.
Guided Interpretable Facial Expression Recognition via Spatial Action Unit Cues
Feb 02, 2024While state-of-the-art facial expression recognition (FER) classifiers achieve a high level of accuracy, they lack interpretability, an important aspect for end-users. To recognize basic facial expressions, experts resort to a codebook associating a set of spatial action units to a facial expression. In this paper, we follow the same expert footsteps, and propose a learning strategy that allows us to explicitly incorporate spatial action units (aus) cues into the classifier's training to build a deep interpretable model. In particular, using this aus codebook, input image expression label, and facial landmarks, a single action units heatmap is built to indicate the most discriminative regions of interest in the image w.r.t the facial expression. We leverage this valuable spatial cue to train a deep interpretable classifier for FER. This is achieved by constraining the spatial layer features of a classifier to be correlated with \aus map. Using a composite loss, the classifier is trained to correctly classify an image while yielding interpretable visual layer-wise attention correlated with aus maps, simulating the experts' decision process. This is achieved using only the image class expression as supervision and without any extra manual annotations. Moreover, our method is generic. It can be applied to any CNN- or transformer-based deep classifier without the need for architectural change or adding significant training time. Our extensive evaluation on two public benchmarks RAFDB, and AFFECTNET datasets shows that our proposed strategy can improve layer-wise interpretability without degrading classification performance. In addition, we explore a common type of interpretable classifiers that rely on Class-Activation Mapping methods (CAMs), and we show that our training technique improves the CAM interpretability.
Mitigating the Impact of Attribute Editing on Face Recognition
Mar 12, 2024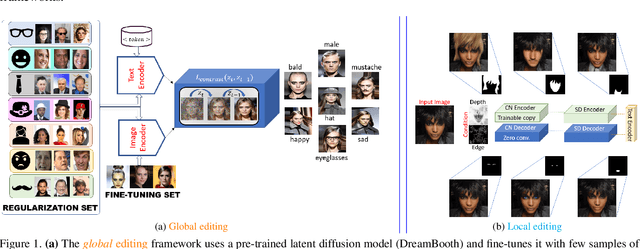
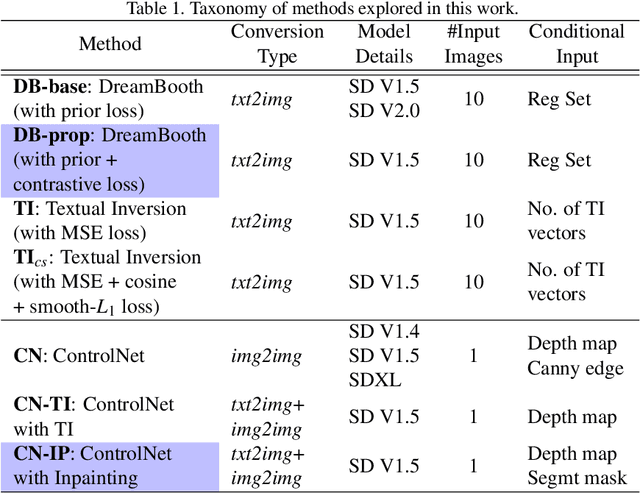

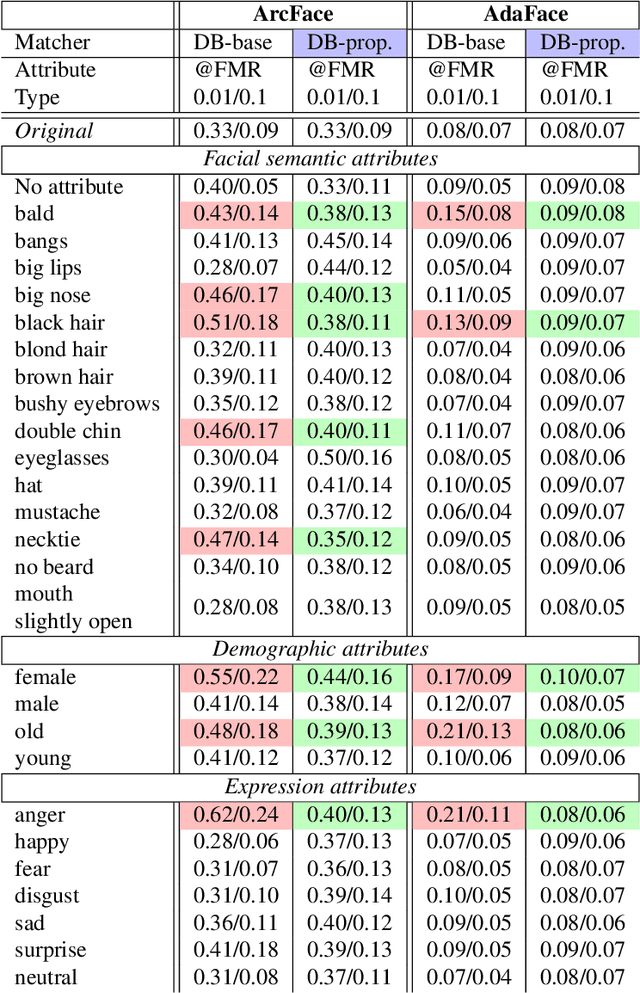
Facial attribute editing using generative models can impair automated face recognition. This degradation persists even with recent identity-preserving models such as InstantID. To mitigate this issue, we propose two techniques that perform local and global attribute editing. Local editing operates on the finer details via a regularization-free method based on ControlNet conditioned on depth maps and auxiliary semantic segmentation masks. Global editing operates on coarser details via a regularization-based method guided by custom loss and regularization set. In this work, we empirically ablate twenty-six facial semantic, demographic and expression-based attributes altered using state-of-the-art generative models and evaluate them using ArcFace and AdaFace matchers on CelebA, CelebAMaskHQ and LFW datasets. Finally, we use LLaVA, a vision-language framework for attribute prediction to validate our editing techniques. Our methods outperform SoTA (BLIP, InstantID) at facial editing while retaining identity.
Unveiling the Human-like Similarities of Automatic Facial Expression Recognition: An Empirical Exploration through Explainable AI
Jan 22, 2024Facial expression recognition is vital for human behavior analysis, and deep learning has enabled models that can outperform humans. However, it is unclear how closely they mimic human processing. This study aims to explore the similarity between deep neural networks and human perception by comparing twelve different networks, including both general object classifiers and FER-specific models. We employ an innovative global explainable AI method to generate heatmaps, revealing crucial facial regions for the twelve networks trained on six facial expressions. We assess these results both quantitatively and qualitatively, comparing them to ground truth masks based on Friesen and Ekman's description and among them. We use Intersection over Union (IoU) and normalized correlation coefficients for comparisons. We generate 72 heatmaps to highlight critical regions for each expression and architecture. Qualitatively, models with pre-trained weights show more similarity in heatmaps compared to those without pre-training. Specifically, eye and nose areas influence certain facial expressions, while the mouth is consistently important across all models and expressions. Quantitatively, we find low average IoU values (avg. 0.2702) across all expressions and architectures. The best-performing architecture averages 0.3269, while the worst-performing one averages 0.2066. Dendrograms, built with the normalized correlation coefficient, reveal two main clusters for most expressions: models with pre-training and models without pre-training. Findings suggest limited alignment between human and AI facial expression recognition, with network architectures influencing the similarity, as similar architectures prioritize similar facial regions.
Towards Equitable Agile Research and Development of AI and Robotics
Feb 13, 2024Machine Learning (ML) and 'Artificial Intelligence' ('AI') methods tend to replicate and amplify existing biases and prejudices, as do Robots with AI. For example, robots with facial recognition have failed to identify Black Women as human, while others have categorized people, such as Black Men, as criminals based on appearance alone. A 'culture of modularity' means harms are perceived as 'out of scope', or someone else's responsibility, throughout employment positions in the 'AI supply chain'. Incidents are routine enough (incidentdatabase.ai lists over 2000 examples) to indicate that few organizations are capable of completely respecting peoples' rights; meeting claimed equity, diversity, and inclusion (EDI or DEI) goals; or recognizing and then addressing such failures in their organizations and artifacts. We propose a framework for adapting widely practiced Research and Development (R&D) project management methodologies to build organizational equity capabilities and better integrate known evidence-based best practices. We describe how project teams can organize and operationalize the most promising practices, skill sets, organizational cultures, and methods to detect and address rights-based fairness, equity, accountability, and ethical problems as early as possible when they are often less harmful and easier to mitigate; then monitor for unforeseen incidents to adaptively and constructively address them. Our primary example adapts an Agile development process based on Scrum, one of the most widely adopted approaches to organizing R&D teams. We also discuss limitations of our proposed framework and future research directions.
Data Augmentation and Transfer Learning Approaches Applied to Facial Expressions Recognition
Feb 15, 2024The face expression is the first thing we pay attention to when we want to understand a person's state of mind. Thus, the ability to recognize facial expressions in an automatic way is a very interesting research field. In this paper, because the small size of available training datasets, we propose a novel data augmentation technique that improves the performances in the recognition task. We apply geometrical transformations and build from scratch GAN models able to generate new synthetic images for each emotion type. Thus, on the augmented datasets we fine tune pretrained convolutional neural networks with different architectures. To measure the generalization ability of the models, we apply extra-database protocol approach, namely we train models on the augmented versions of training dataset and test them on two different databases. The combination of these techniques allows to reach average accuracy values of the order of 85\% for the InceptionResNetV2 model.
* The 11th International Conference on Artificial Intelligence, Soft Computing and Applications (AIAA 2021)
Headset: Human emotion awareness under partial occlusions multimodal dataset
Feb 14, 2024The volumetric representation of human interactions is one of the fundamental domains in the development of immersive media productions and telecommunication applications. Particularly in the context of the rapid advancement of Extended Reality (XR) applications, this volumetric data has proven to be an essential technology for future XR elaboration. In this work, we present a new multimodal database to help advance the development of immersive technologies. Our proposed database provides ethically compliant and diverse volumetric data, in particular 27 participants displaying posed facial expressions and subtle body movements while speaking, plus 11 participants wearing head-mounted displays (HMDs). The recording system consists of a volumetric capture (VoCap) studio, including 31 synchronized modules with 62 RGB cameras and 31 depth cameras. In addition to textured meshes, point clouds, and multi-view RGB-D data, we use one Lytro Illum camera for providing light field (LF) data simultaneously. Finally, we also provide an evaluation of our dataset employment with regard to the tasks of facial expression classification, HMDs removal, and point cloud reconstruction. The dataset can be helpful in the evaluation and performance testing of various XR algorithms, including but not limited to facial expression recognition and reconstruction, facial reenactment, and volumetric video. HEADSET and its all associated raw data and license agreement will be publicly available for research purposes.
Exploring the dynamic interplay of cognitive load and emotional arousal by using multimodal measurements: Correlation of pupil diameter and emotional arousal in emotionally engaging tasks
Mar 01, 2024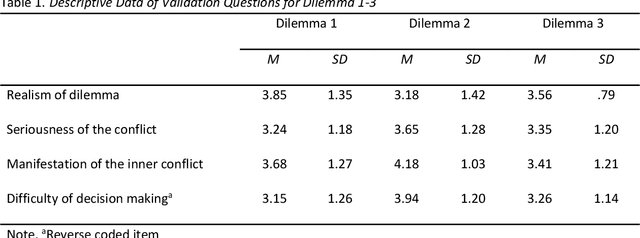
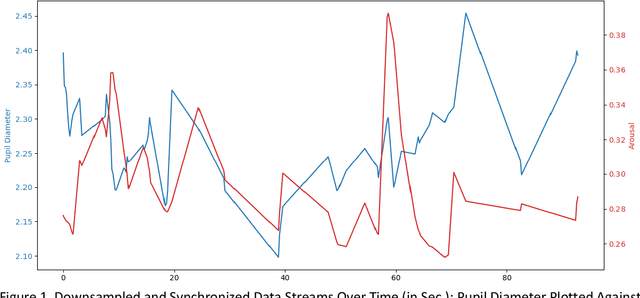
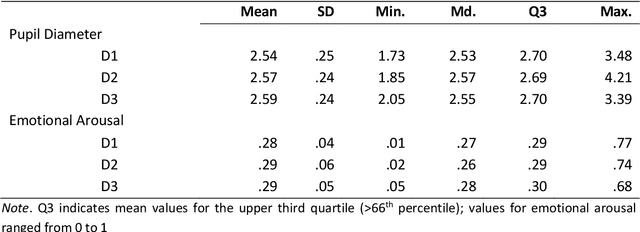
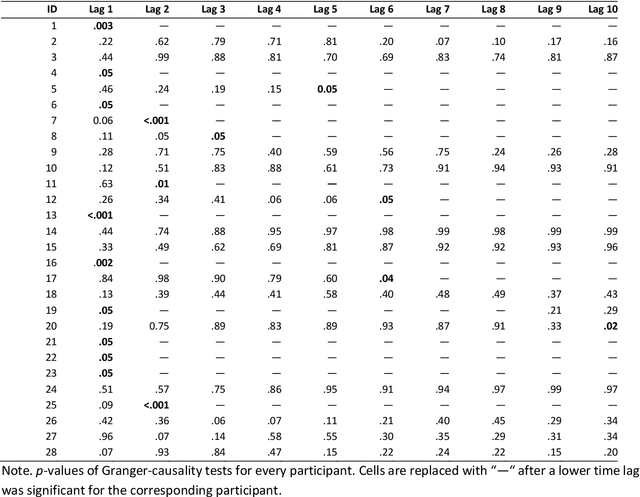
Multimodal data analysis and validation based on streams from state-of-the-art sensor technology such as eye-tracking or emotion recognition using the Facial Action Coding System (FACTs) with deep learning allows educational researchers to study multifaceted learning and problem-solving processes and to improve educational experiences. This study aims to investigate the correlation between two continuous sensor streams, pupil diameter as an indicator of cognitive workload and FACTs with deep learning as an indicator of emotional arousal (RQ 1a), specifically for epochs of high, medium, and low arousal (RQ 1b). Furthermore, the time lag between emotional arousal and pupil diameter data will be analyzed (RQ 2). 28 participants worked on three cognitively demanding and emotionally engaging everyday moral dilemmas while eye-tracking and emotion recognition data were collected. The data were pre-processed in Phyton (synchronization, blink control, downsampling) and analyzed using correlation analysis and Granger causality tests. The results show negative and statistically significant correlations between the data streams for emotional arousal and pupil diameter. However, the correlation is negative and significant only for epochs of high arousal, while positive but non-significant relationships were found for epochs of medium or low arousal. The average time lag for the relationship between arousal and pupil diameter was 2.8 ms. In contrast to previous findings without a multimodal approach suggesting a positive correlation between the constructs, the results contribute to the state of research by highlighting the importance of multimodal data validation and research on convergent vagility. Future research should consider emotional regulation strategies and emotional valence.