 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Baseline CNN structure analysis for facial expression recognition
Nov 14, 2016

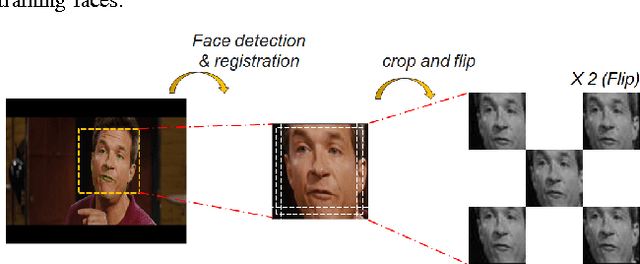
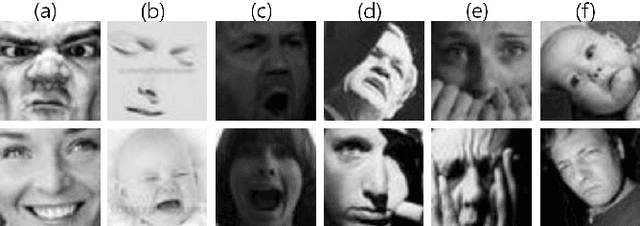
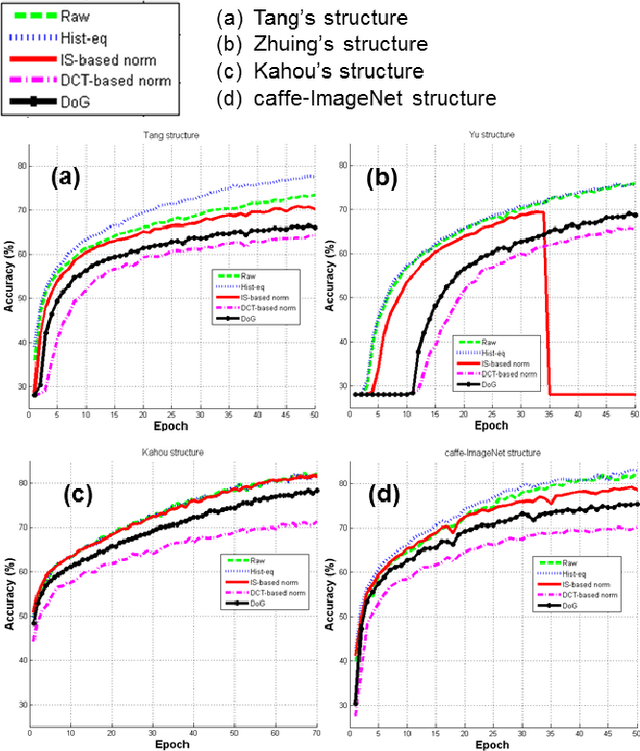
We present a baseline convolutional neural network (CNN) structure and image preprocessing methodology to improve facial expression recognition algorithm using CNN. To analyze the most efficient network structure, we investigated four network structures that are known to show good performance in facial expression recognition. Moreover, we also investigated the effect of input image preprocessing methods. Five types of data input (raw, histogram equalization, isotropic smoothing, diffusion-based normalization, difference of Gaussian) were tested, and the accuracy was compared. We trained 20 different CNN models (4 networks x 5 data input types) and verified the performance of each network with test images from five different databases. The experiment result showed that a three-layer structure consisting of a simple convolutional and a max pooling layer with histogram equalization image input was the most efficient. We describe the detailed training procedure and analyze the result of the test accuracy based on considerable observation.
Implementing Facial Landmark Tracking for American Sign Language Recognition using Random Forest Classification Tree Model and Principal Component Analysis
Nov 23, 2022
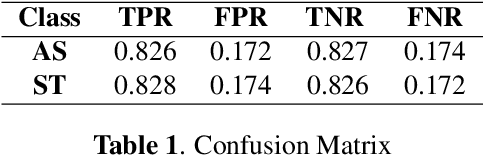


The deaf and hard of hearing community relies on American Sign Language (ASL) as their primary mode of communication, but communication with others who do not know ASL can be difficult, especially during emergencies where no interpreter is available. As an effort to alleviate this problem, research in computer vision based real time ASL interpreting models is ongoing. However, most of these models are hand shape (gesture) based and lack the integration of facial cues, which are crucial in ASL to convey tone and distinguish similar looking signs. Thus, the integration of facial cues in computer vision based ASL interpreting models has the potential to improve performance and reliability. In this paper, we introduce a new facial expression-based classification model that can be used to improve ASL interpreting models. This model utilizes the relative angles of facial landmarks with principal component analysis and a Random Forest Classification tree model to classify frames taken from videos of ASL users signing a complete sentence. The model classifies the frames as statements or assertions. The model was able to achieve an accuracy of 82%.
Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network
Feb 08, 2022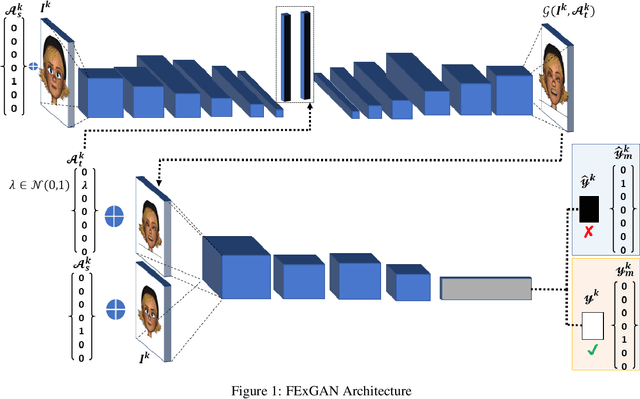
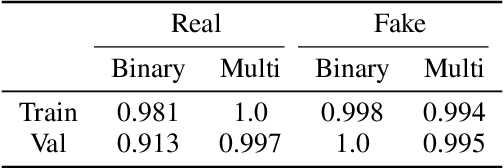
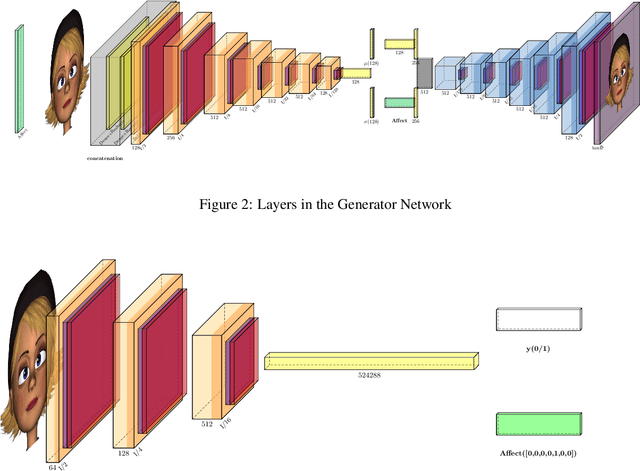

Facial expressions are a form of non-verbal communication that humans perform seamlessly for meaningful transfer of information. Most of the literature addresses the facial expression recognition aspect however, with the advent of Generative Models, it has become possible to explore the affect space in addition to mere classification of a set of expressions. In this article, we propose a generative model architecture which robustly generates a set of facial expressions for multiple character identities and explores the possibilities of generating complex expressions by combining the simple ones.
Feature Super-Resolution Based Facial Expression Recognition for Multi-scale Low-Resolution Faces
Apr 05, 2020
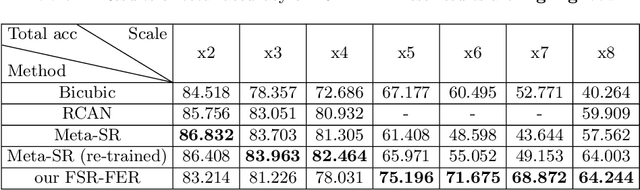
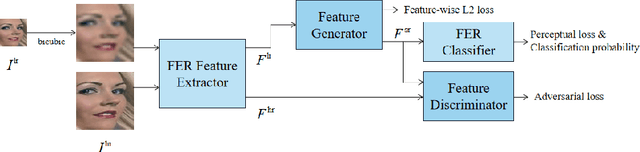
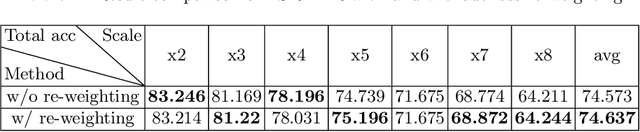
Facial Expressions Recognition(FER) on low-resolution images is necessary for applications like group expression recognition in crowd scenarios(station, classroom etc.). Classifying a small size facial image into the right expression category is still a challenging task. The main cause of this problem is the loss of discriminative feature due to reduced resolution. Super-resolution method is often used to enhance low-resolution images, but the performance on FER task is limited when on images of very low resolution. In this work, inspired by feature super-resolution methods for object detection, we proposed a novel generative adversary network-based feature level super-resolution method for robust facial expression recognition(FSR-FER). In particular, a pre-trained FER model was employed as feature extractor, and a generator network G and a discriminator network D are trained with features extracted from images of low resolution and original high resolution. Generator network G tries to transform features of low-resolution images to more discriminative ones by making them closer to the ones of corresponding high-resolution images. For better classification performance, we also proposed an effective classification-aware loss re-weighting strategy based on the classification probability calculated by a fixed FER model to make our model focus more on samples that are easily misclassified. Experiment results on Real-World Affective Faces (RAF) Database demonstrate that our method achieves satisfying results on various down-sample factors with a single model and has better performance on low-resolution images compared with methods using image super-resolution and expression recognition separately.
Information-Theoretic Bias Assessment Of Learned Representations Of Pretrained Face Recognition
Nov 09, 2021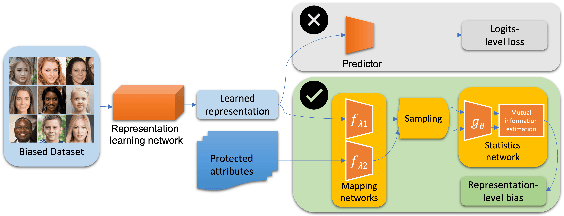
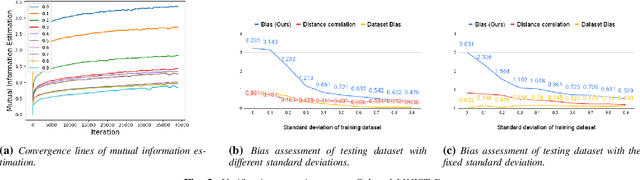
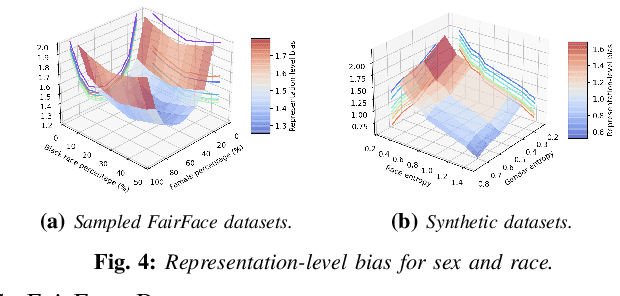

As equality issues in the use of face recognition have garnered a lot of attention lately, greater efforts have been made to debiased deep learning models to improve fairness to minorities. However, there is still no clear definition nor sufficient analysis for bias assessment metrics. We propose an information-theoretic, independent bias assessment metric to identify degree of bias against protected demographic attributes from learned representations of pretrained facial recognition systems. Our metric differs from other methods that rely on classification accuracy or examine the differences between ground truth and predicted labels of protected attributes predicted using a shallow network. Also, we argue, theoretically and experimentally, that logits-level loss is not adequate to explain bias since predictors based on neural networks will always find correlations. Further, we present a synthetic dataset that mitigates the issue of insufficient samples in certain cohorts. Lastly, we establish a benchmark metric by presenting advantages in clear discrimination and small variation comparing with other metrics, and evaluate the performance of different debiased models with the proposed metric.
A Fine-Grained Facial Expression Database for End-to-End Multi-Pose Facial Expression Recognition
Jul 25, 2019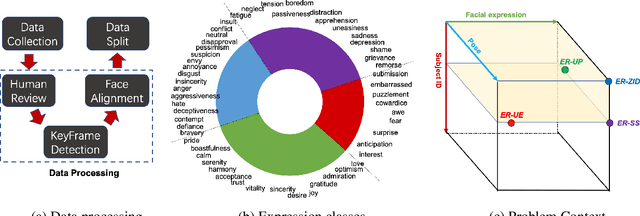

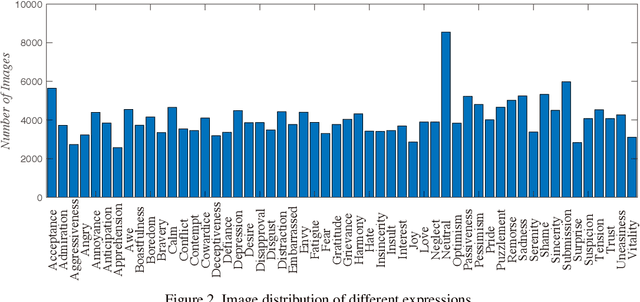
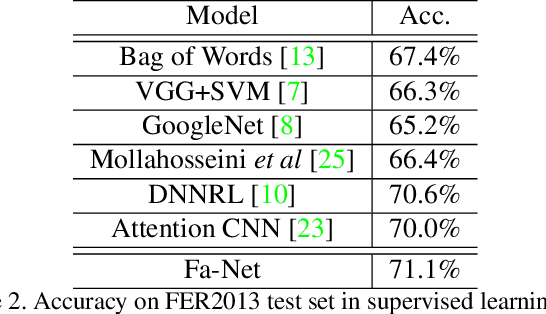
The recent research of facial expression recognition has made a lot of progress due to the development of deep learning technologies, but some typical challenging problems such as the variety of rich facial expressions and poses are still not resolved. To solve these problems, we develop a new Facial Expression Recognition (FER) framework by involving the facial poses into our image synthesizing and classification process. There are two major novelties in this work. First, we create a new facial expression dataset of more than 200k images with 119 persons, 4 poses and 54 expressions. To our knowledge this is the first dataset to label faces with subtle emotion changes for expression recognition purpose. It is also the first dataset that is large enough to validate the FER task on unbalanced poses, expressions, and zero-shot subject IDs. Second, we propose a facial pose generative adversarial network (FaPE-GAN) to synthesize new facial expression images to augment the data set for training purpose, and then learn a LightCNN based Fa-Net model for expression classification. Finally, we advocate four novel learning tasks on this dataset. The experimental results well validate the effectiveness of the proposed approach.
Adversarial Training for Face Recognition Systems using Contrastive Adversarial Learning and Triplet Loss Fine-tuning
Oct 09, 2021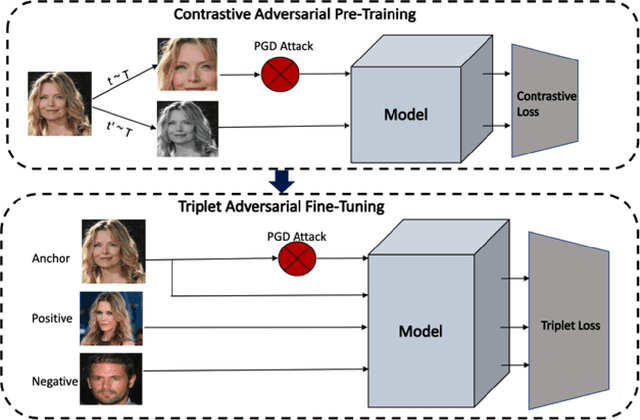

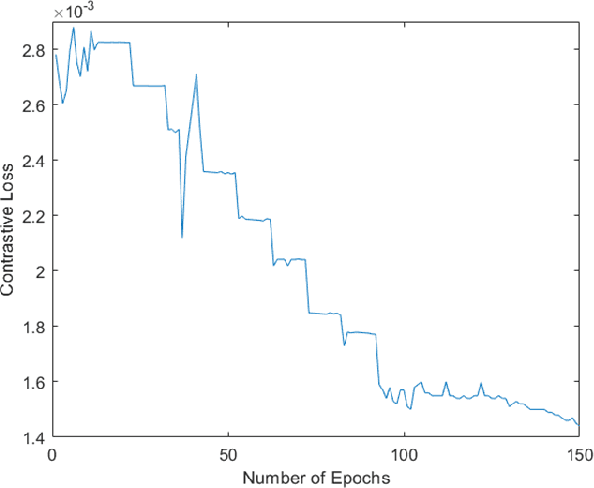
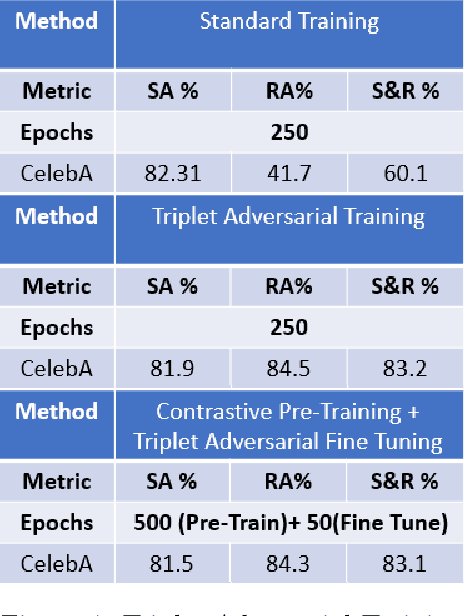
Though much work has been done in the domain of improving the adversarial robustness of facial recognition systems, a surprisingly small percentage of it has focused on self-supervised approaches. In this work, we present an approach that combines Ad-versarial Pre-Training with Triplet Loss AdversarialFine-Tuning. We compare our methods with the pre-trained ResNet50 model that forms the backbone of FaceNet, finetuned on our CelebA dataset. Through comparing adversarial robustness achieved without adversarial training, with triplet loss adversarial training, and our contrastive pre-training combined with triplet loss adversarial fine-tuning, we find that our method achieves comparable results with far fewer epochs re-quired during fine-tuning. This seems promising, increasing the training time for fine-tuning should yield even better results. In addition to this, a modified semi-supervised experiment was conducted, which demonstrated the improvement of contrastive adversarial training with the introduction of small amounts of labels.
Video-based Facial Expression Recognition using Graph Convolutional Networks
Oct 26, 2020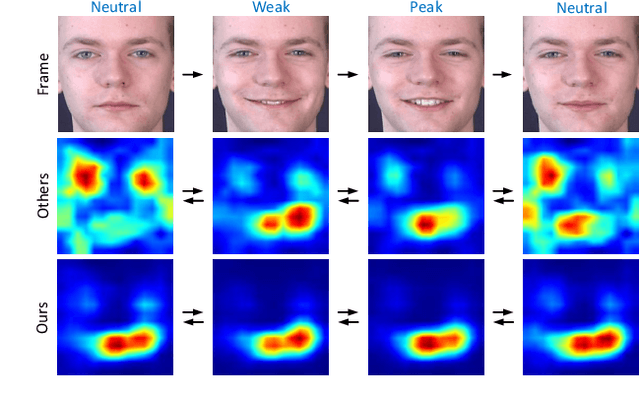
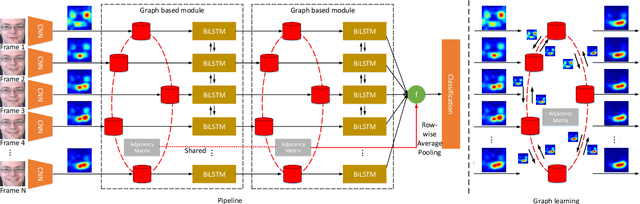

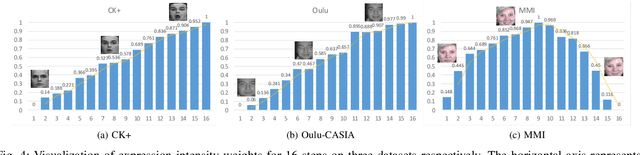
Facial expression recognition (FER), aiming to classify the expression present in the facial image or video, has attracted a lot of research interests in the field of artificial intelligence and multimedia. In terms of video based FER task, it is sensible to capture the dynamic expression variation among the frames to recognize facial expression. However, existing methods directly utilize CNN-RNN or 3D CNN to extract the spatial-temporal features from different facial units, instead of concentrating on a certain region during expression variation capturing, which leads to limited performance in FER. In our paper, we introduce a Graph Convolutional Network (GCN) layer into a common CNN-RNN based model for video-based FER. First, the GCN layer is utilized to learn more significant facial expression features which concentrate on certain regions after sharing information between extracted CNN features of nodes. Then, a LSTM layer is applied to learn long-term dependencies among the GCN learned features to model the variation. In addition, a weight assignment mechanism is also designed to weight the output of different nodes for final classification by characterizing the expression intensities in each frame. To the best of our knowledge, it is the first time to use GCN in FER task. We evaluate our method on three widely-used datasets, CK+, Oulu-CASIA and MMI, and also one challenging wild dataset AFEW8.0, and the experimental results demonstrate that our method has superior performance to existing methods.
Deep Multi-Facial Patches Aggregation Network For Facial Expression Recognition
Feb 20, 2020
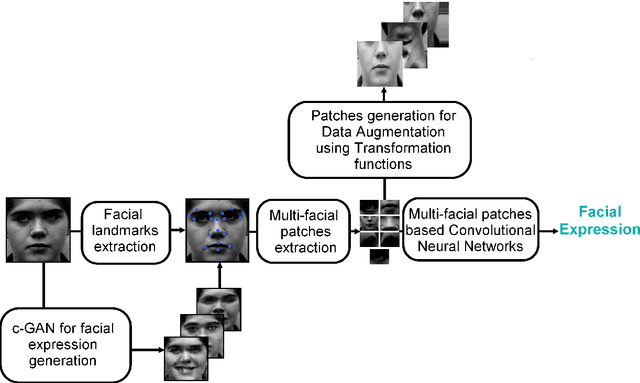
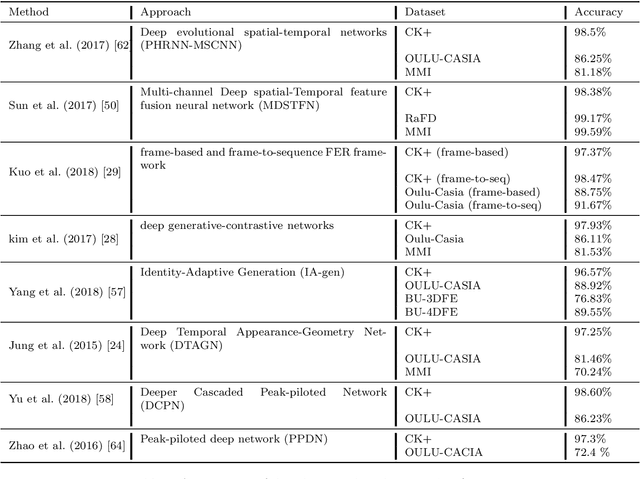
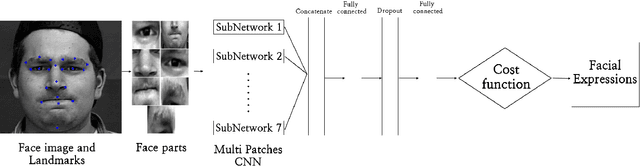
In this paper, we propose an approach for Facial Expressions Recognition (FER) based on a deep multi-facial patches aggregation network. Deep features are learned from facial patches using deep sub-networks and aggregated within one deep architecture for expression classification . Several problems may affect the performance of deep-learning based FER approaches, in particular, the small size of existing FER datasets which might not be sufficient to train large deep learning networks. Moreover, it is extremely time-consuming to collect and annotate a large number of facial images. To account for this, we propose two data augmentation techniques for facial expression generation to expand FER labeled training datasets. We evaluate the proposed framework on three FER datasets. Results show that the proposed approach achieves state-of-art FER deep learning approaches performance when the model is trained and tested on images from the same dataset. Moreover, the proposed data augmentation techniques improve the expression recognition rate, and thus can be a solution for training deep learning FER models using small datasets. The accuracy degrades significantly when testing for dataset bias.