 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network
Feb 04, 2019



Facial expression recognition has been an active research area over the past few decades, and it is still challenging due to the high intra-class variation. Traditional approaches for this problem rely on hand-crafted features such as SIFT, HOG and LBP, followed by a classifier trained on a database of images or videos. Most of these works perform reasonably well on datasets of images captured in a controlled condition, but fail to perform as good on more challenging datasets with more image variation and partial faces. In recent years, several works proposed an end-to-end framework for facial expression recognition, using deep learning models. Despite the better performance of these works, there still seems to be a great room for improvement. In this work, we propose a deep learning approach based on attentional convolutional network, which is able to focus on important parts of the face, and achieves significant improvement over previous models on multiple datasets, including FER-2013, CK+, FERG, and JAFFE. We also use a visualization technique which is able to find important face regions for detecting different emotions, based on the classifier's output. Through experimental results, we show that different emotions seems to be sensitive to different parts of the face.
Deep Metric Structured Learning For Facial Expression Recognition
Jan 18, 2020
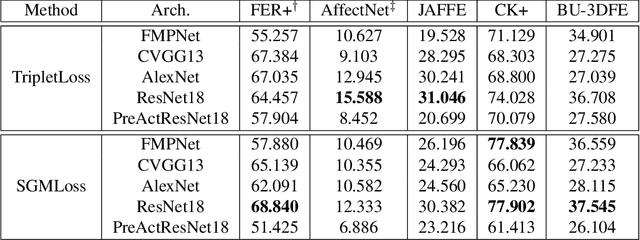
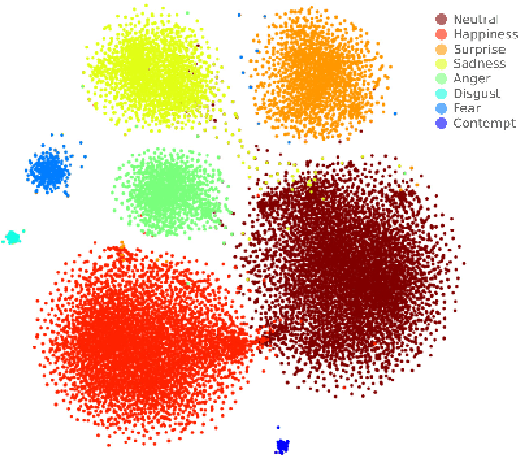
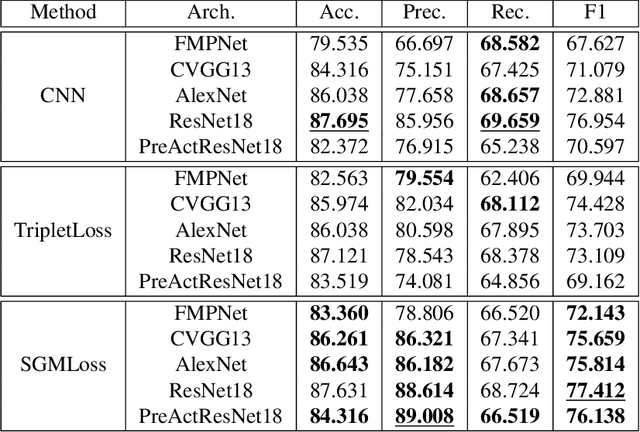
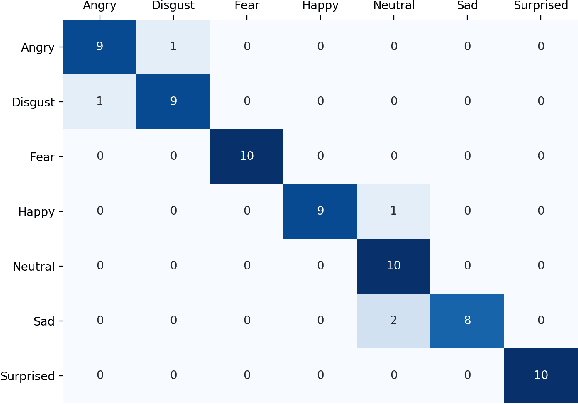
We propose a deep metric learning model to create embedded sub-spaces with a well defined structure. A new loss function that imposes Gaussian structures on the output space is introduced to create these sub-spaces thus shaping the distribution of the data. Having a mixture of Gaussians solution space is advantageous given its simplified and well established structure. It allows fast discovering of classes within classes and the identification of mean representatives at the centroids of individual classes. We also propose a new semi-supervised method to create sub-classes. We illustrate our methods on the facial expression recognition problem and validate results on the FER+, AffectNet, Extended Cohn-Kanade (CK+), BU-3DFE, and JAFFE datasets. We experimentally demonstrate that the learned embedding can be successfully used for various applications including expression retrieval and emotion recognition.
Assessing Gender Bias in Predictive Algorithms using eXplainable AI
Mar 19, 2022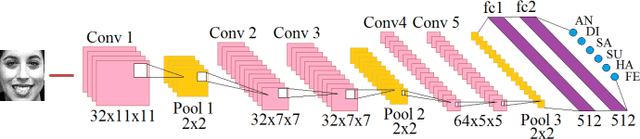
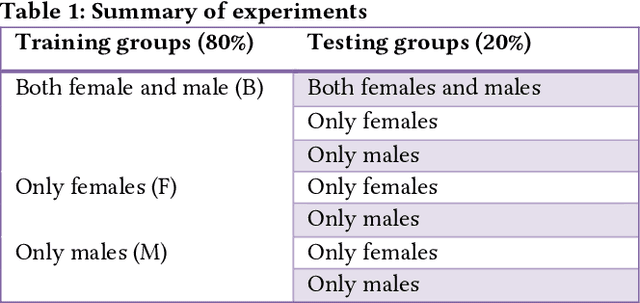
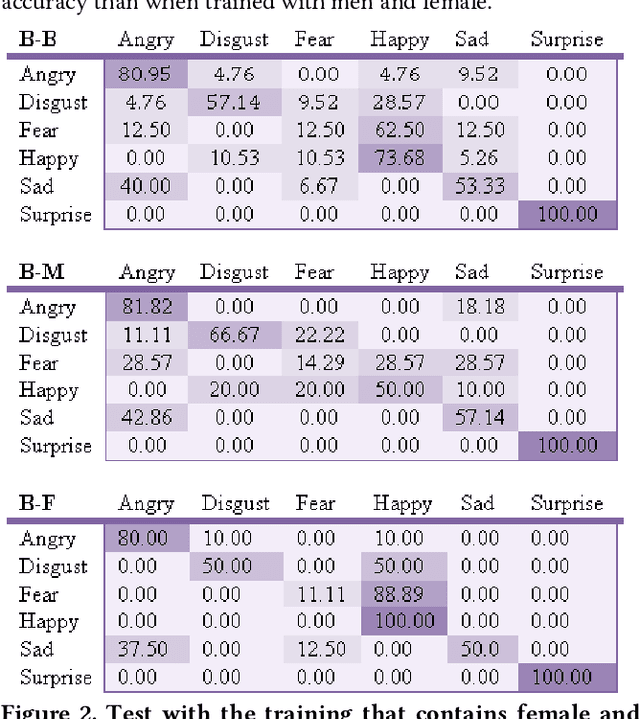
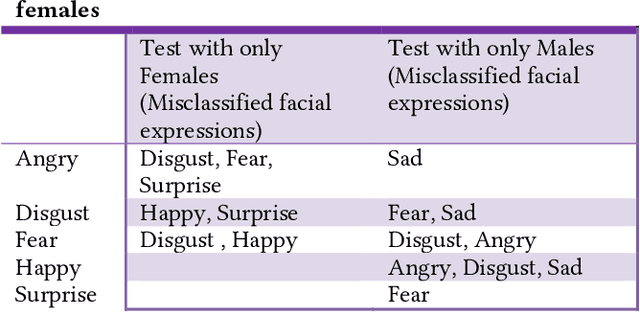
Predictive algorithms have a powerful potential to offer benefits in areas as varied as medicine or education. However, these algorithms and the data they use are built by humans, consequently, they can inherit the bias and prejudices present in humans. The outcomes can systematically repeat errors that create unfair results, which can even lead to situations of discrimination (e.g. gender, social or racial). In order to illustrate how important is to count with a diverse training dataset to avoid bias, we manipulate a well-known facial expression recognition dataset to explore gender bias and discuss its implications.
About Face: A Survey of Facial Recognition Evaluation
Feb 01, 2021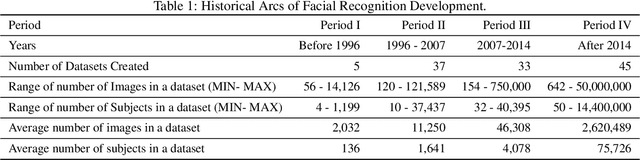
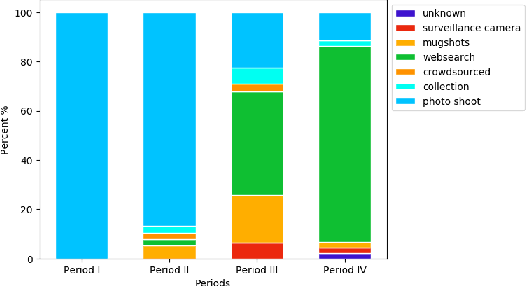
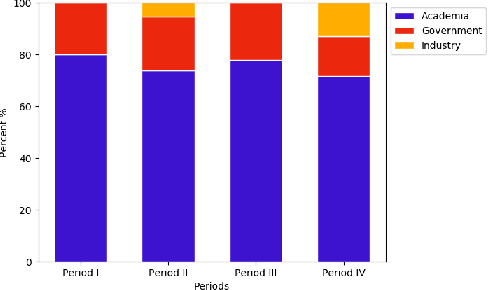
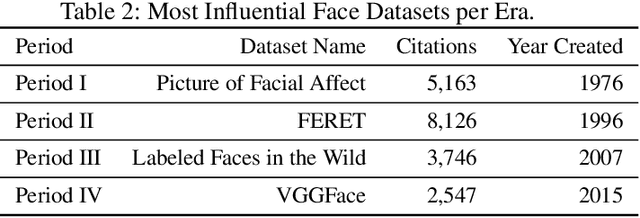
We survey over 100 face datasets constructed between 1976 to 2019 of 145 million images of over 17 million subjects from a range of sources, demographics and conditions. Our historical survey reveals that these datasets are contextually informed, shaped by changes in political motivations, technological capability and current norms. We discuss how such influences mask specific practices (some of which may actually be harmful or otherwise problematic) and make a case for the explicit communication of such details in order to establish a more grounded understanding of the technology's function in the real world.
Finding Emotions in Faces: A Meta-Classifier
Aug 20, 2022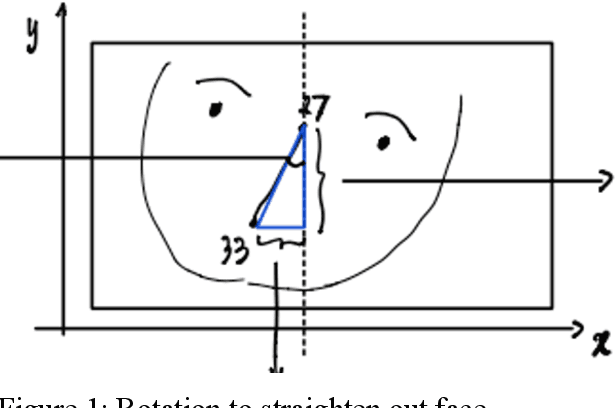

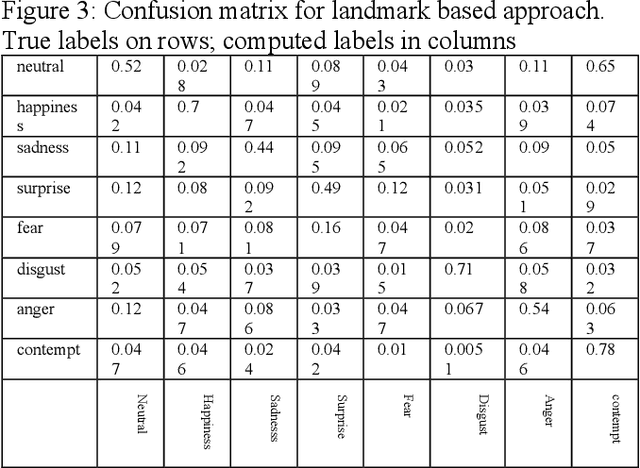
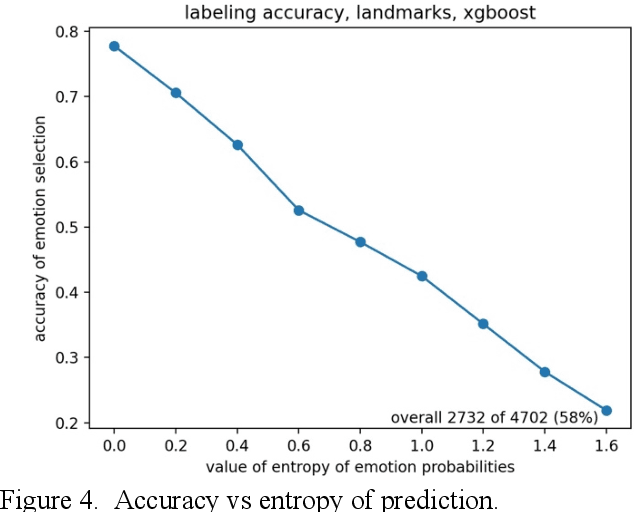
Machine learning has been used to recognize emotions in faces, typically by looking for 8 different emotional states (neutral, happy, sad, surprise, fear, disgust, anger and contempt). We consider two approaches: feature recognition based on facial landmarks and deep learning on all pixels; each produced 58% overall accuracy. However, they produced different results on different images and thus we propose a new meta-classifier combining these approaches. It produces far better results with 77% accuracy
Island Loss for Learning Discriminative Features in Facial Expression Recognition
Oct 23, 2017
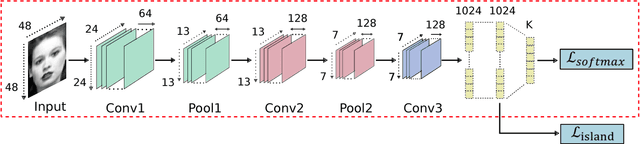
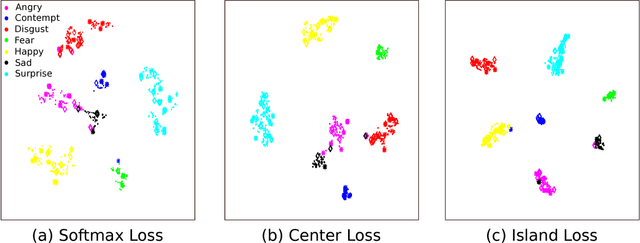
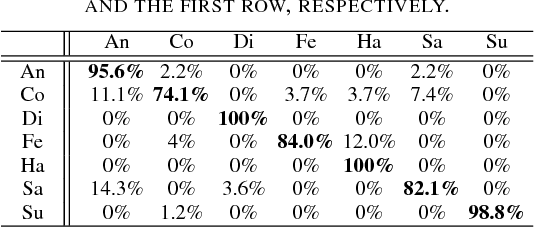
Over the past few years, Convolutional Neural Networks (CNNs) have shown promise on facial expression recognition. However, the performance degrades dramatically under real-world settings due to variations introduced by subtle facial appearance changes, head pose variations, illumination changes, and occlusions. In this paper, a novel island loss is proposed to enhance the discriminative power of the deeply learned features. Specifically, the IL is designed to reduce the intra-class variations while enlarging the inter-class differences simultaneously. Experimental results on four benchmark expression databases have demonstrated that the CNN with the proposed island loss (IL-CNN) outperforms the baseline CNN models with either traditional softmax loss or the center loss and achieves comparable or better performance compared with the state-of-the-art methods for facial expression recognition.
Noisy Student Training using Body Language Dataset Improves Facial Expression Recognition
Aug 06, 2020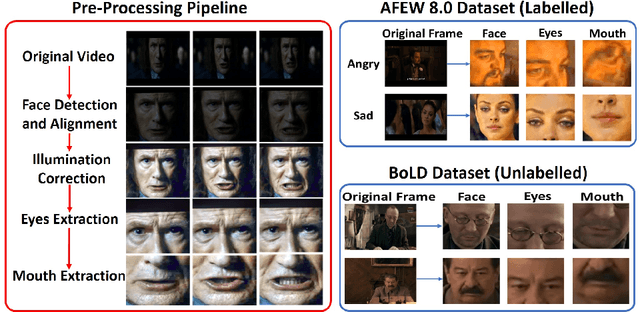
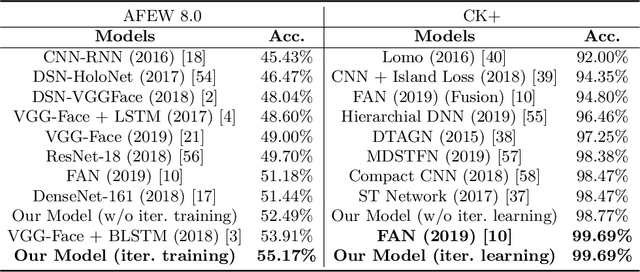
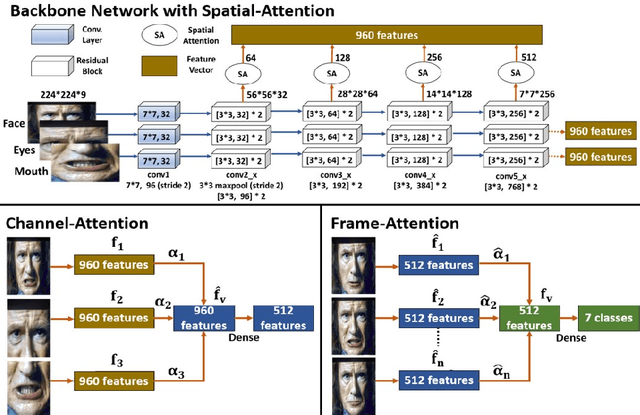
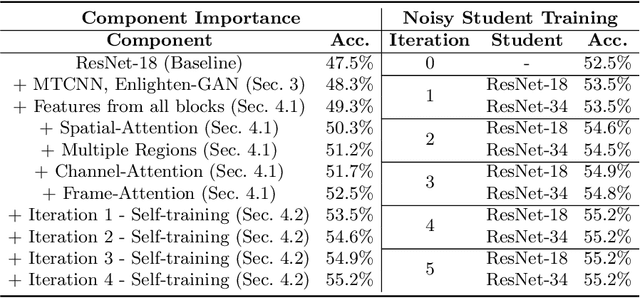
Facial expression recognition from videos in the wild is a challenging task due to the lack of abundant labelled training data. Large DNN (deep neural network) architectures and ensemble methods have resulted in better performance, but soon reach saturation at some point due to data inadequacy. In this paper, we use a self-training method that utilizes a combination of a labelled dataset and an unlabelled dataset (Body Language Dataset - BoLD). Experimental analysis shows that training a noisy student network iteratively helps in achieving significantly better results. Additionally, our model isolates different regions of the face and processes them independently using a multi-level attention mechanism which further boosts the performance. Our results show that the proposed method achieves state-of-the-art performance on benchmark datasets CK+ and AFEW 8.0 when compared to other single models.
Adversarially Perturbed Wavelet-based Morphed Face Generation
Nov 03, 2021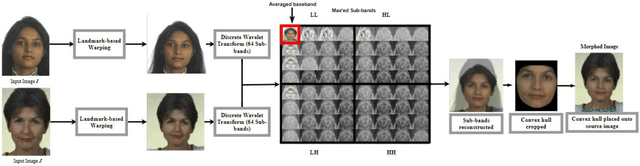
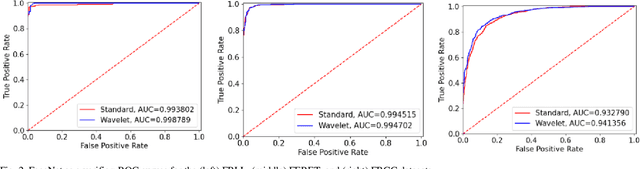
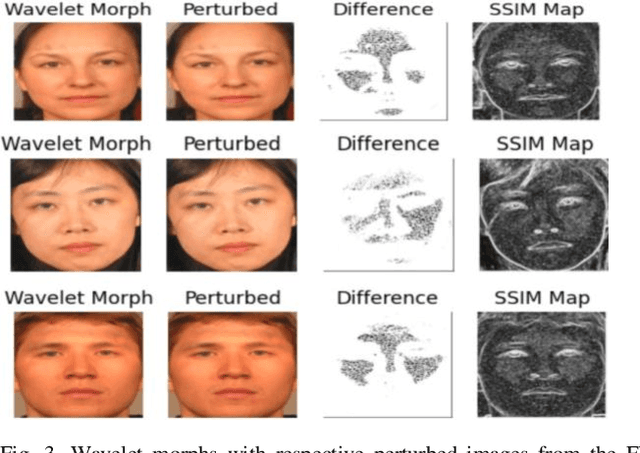
Morphing is the process of combining two or more subjects in an image in order to create a new identity which contains features of both individuals. Morphed images can fool Facial Recognition Systems (FRS) into falsely accepting multiple people, leading to failures in national security. As morphed image synthesis becomes easier, it is vital to expand the research community's available data to help combat this dilemma. In this paper, we explore combination of two methods for morphed image generation, those of geometric transformation (warping and blending to create morphed images) and photometric perturbation. We leverage both methods to generate high-quality adversarially perturbed morphs from the FERET, FRGC, and FRLL datasets. The final images retain high similarity to both input subjects while resulting in minimal artifacts in the visual domain. Images are synthesized by fusing the wavelet sub-bands from the two look-alike subjects, and then adversarially perturbed to create highly convincing imagery to deceive both humans and deep morph detectors.
FusiformNet: Extracting Discriminative Facial Features on Different Levels
Nov 06, 2020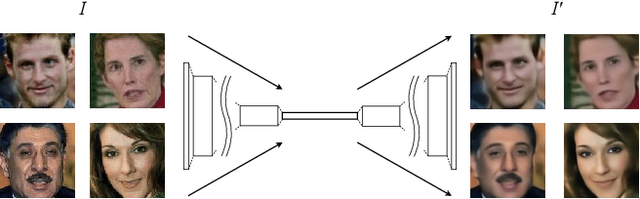
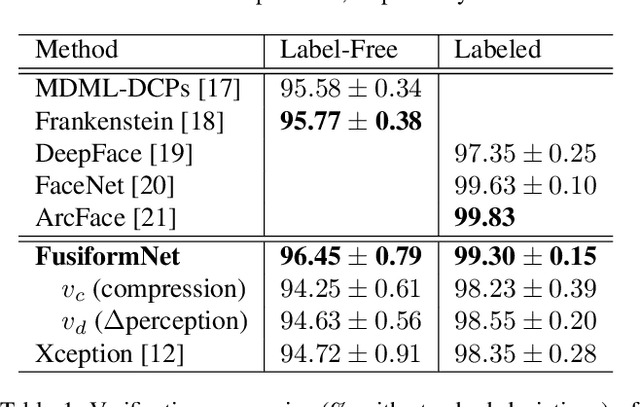
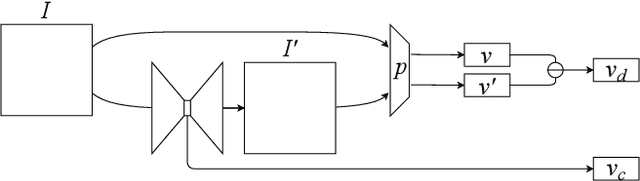
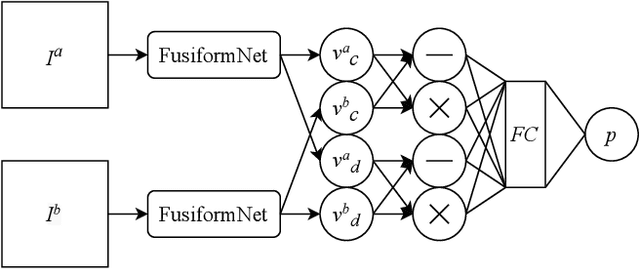
Over the last several years, research on facial recognition based on Deep Neural Network has evolved with approaches like task-specific loss functions, image normalization and augmentation, network architectures, etc. However, there have been few approaches with attention to how human faces differ from person to person. Premising that inter-personal differences are found both generally and locally on the human face, I propose FusiformNet, a novel framework for feature extraction that leverages the nature of discriminative facial features. Tested on Image-Unrestricted setting of Labeled Face in the Wild benchmark, this method achieved a state-of-the-art accuracy of 96.67% without labeled outside data, image augmentation, normalization, or special loss functions. Likewise, the method also performed on par with previous state-of-the-arts when pre-trained on CASIA-WebFace dataset. Considering its ability to extract both general and local facial features, the utility of FusiformNet may not be limited to facial recognition but also extend to other DNN-based tasks.
Facial Expression Recognition based on Multi-head Cross Attention Network
Mar 24, 2022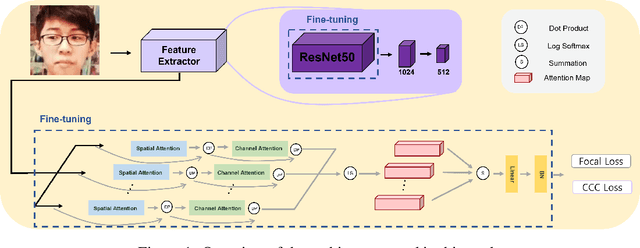


Facial expression in-the-wild is essential for various interactive computing domains. In this paper, we proposed an extended version of DAN model to address the VA estimation and facial expression challenges introduced in ABAW 2022. Our method produced preliminary results of 0.44 of mean CCC value for the VA estimation task, and 0.33 of the average F1 score for the expression classification task.