 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Facial Emotion Recognition using Convolutional Neural Networks
Oct 12, 2019

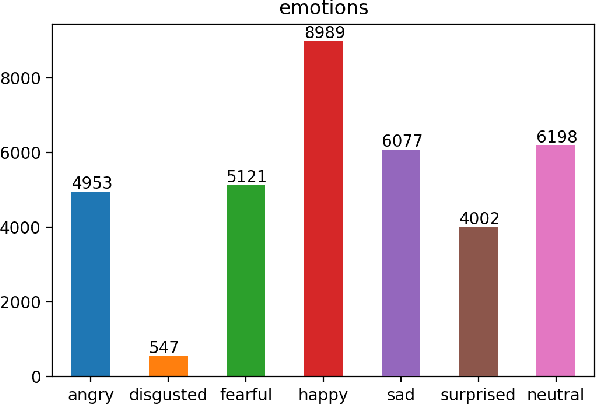
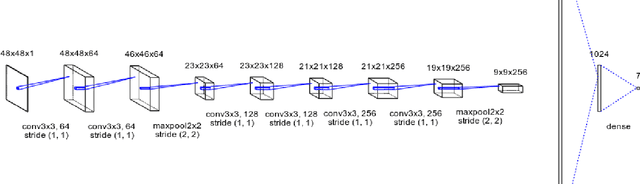
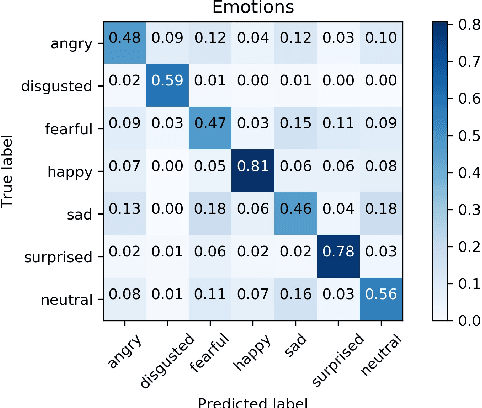
Facial expression recognition is a topic of great interest in most fields from artificial intelligence and gaming to marketing and healthcare. The goal of this paper is to classify images of human faces into one of seven basic emotions. A number of different models were experimented with, including decision trees and neural networks before arriving at a final Convolutional Neural Network (CNN) model. CNNs work better for image recognition tasks since they are able to capture spacial features of the inputs due to their large number of filters. The proposed model consists of six convolutional layers, two max pooling layers and two fully connected layers. Upon tuning of the various hyperparameters, this model achieved a final accuracy of 0.60.
Facial Expression Recognition Under Partial Occlusion from Virtual Reality Headsets based on Transfer Learning
Aug 12, 2020
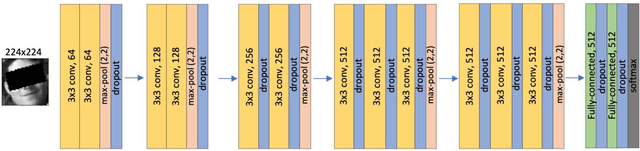
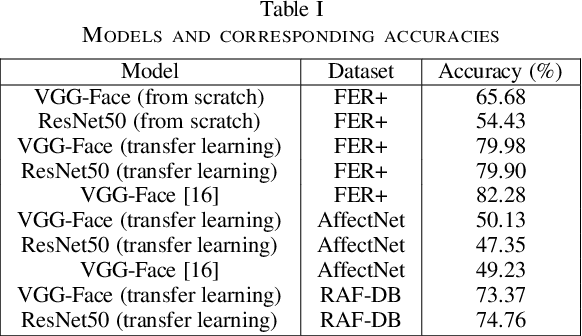
Facial expressions of emotion are a major channel in our daily communications, and it has been subject of intense research in recent years. To automatically infer facial expressions, convolutional neural network based approaches has become widely adopted due to their proven applicability to Facial Expression Recognition (FER) task.On the other hand Virtual Reality (VR) has gained popularity as an immersive multimedia platform, where FER can provide enriched media experiences. However, recognizing facial expression while wearing a head-mounted VR headset is a challenging task due to the upper half of the face being completely occluded. In this paper we attempt to overcome these issues and focus on facial expression recognition in presence of a severe occlusion where the user is wearing a head-mounted display in a VR setting. We propose a geometric model to simulate occlusion resulting from a Samsung Gear VR headset that can be applied to existing FER datasets. Then, we adopt a transfer learning approach, starting from two pretrained networks, namely VGG and ResNet. We further fine-tune the networks on FER+ and RAF-DB datasets. Experimental results show that our approach achieves comparable results to existing methods while training on three modified benchmark datasets that adhere to realistic occlusion resulting from wearing a commodity VR headset. Code for this paper is available at: https://github.com/bita-github/MRP-FER
Facial Expression Recognition Based on Complexity Perception Classification Algorithm
Mar 01, 2018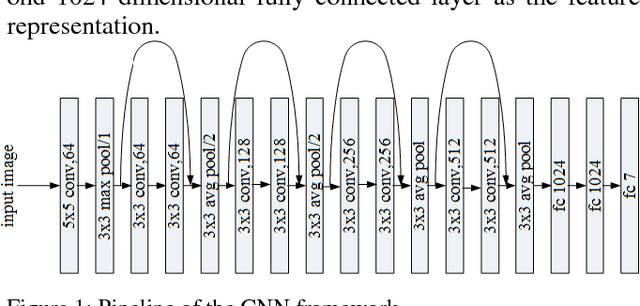
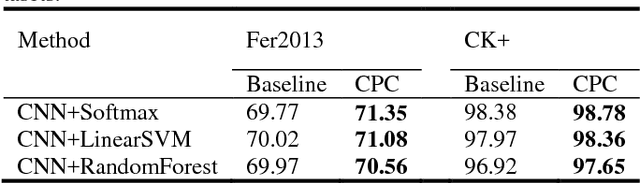
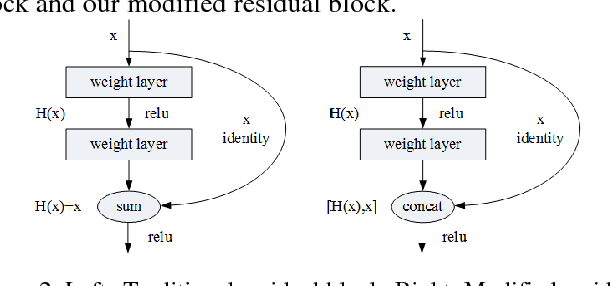
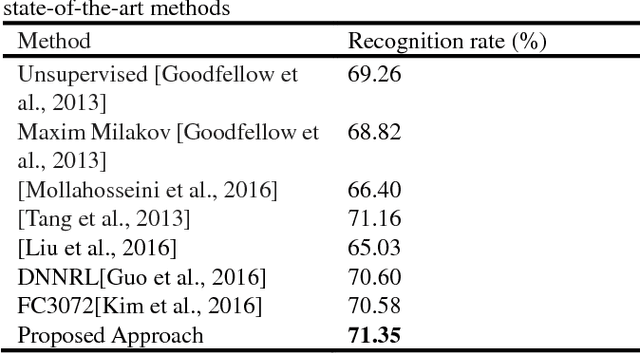
Facial expression recognition (FER) has always been a challenging issue in computer vision. The different expressions of emotion and uncontrolled environmental factors lead to inconsistencies in the complexity of FER and variability of between expression categories, which is often overlooked in most facial expression recognition systems. In order to solve this problem effectively, we presented a simple and efficient CNN model to extract facial features, and proposed a complexity perception classification (CPC) algorithm for FER. The CPC algorithm divided the dataset into an easy classification sample subspace and a complex classification sample subspace by evaluating the complexity of facial features that are suitable for classification. The experimental results of our proposed algorithm on Fer2013 and CK-plus datasets demonstrated the algorithm's effectiveness and superiority over other state-of-the-art approaches.
MAFER: a Multi-resolution Approach to Facial Expression Recognition
May 06, 2021


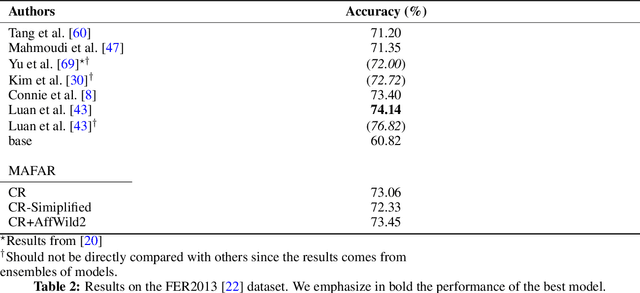
Emotions play a central role in the social life of every human being, and their study, which represents a multidisciplinary subject, embraces a great variety of research fields. Especially concerning the latter, the analysis of facial expressions represents a very active research area due to its relevance to human-computer interaction applications. In such a context, Facial Expression Recognition (FER) is the task of recognizing expressions on human faces. Typically, face images are acquired by cameras that have, by nature, different characteristics, such as the output resolution. It has been already shown in the literature that Deep Learning models applied to face recognition experience a degradation in their performance when tested against multi-resolution scenarios. Since the FER task involves analyzing face images that can be acquired with heterogeneous sources, thus involving images with different quality, it is plausible to expect that resolution plays an important role in such a case too. Stemming from such a hypothesis, we prove the benefits of multi-resolution training for models tasked with recognizing facial expressions. Hence, we propose a two-step learning procedure, named MAFER, to train DCNNs to empower them to generate robust predictions across a wide range of resolutions. A relevant feature of MAFER is that it is task-agnostic, i.e., it can be used complementarily to other objective-related techniques. To assess the effectiveness of the proposed approach, we performed an extensive experimental campaign on publicly available datasets: \fer{}, \raf{}, and \oulu{}. For a multi-resolution context, we observe that with our approach, learning models improve upon the current SotA while reporting comparable results in fix-resolution contexts. Finally, we analyze the performance of our models and observe the higher discrimination power of deep features generated from them.
Facial Soft Biometrics for Recognition in the Wild: Recent Works, Annotation, and COTS Evaluation
Oct 24, 2022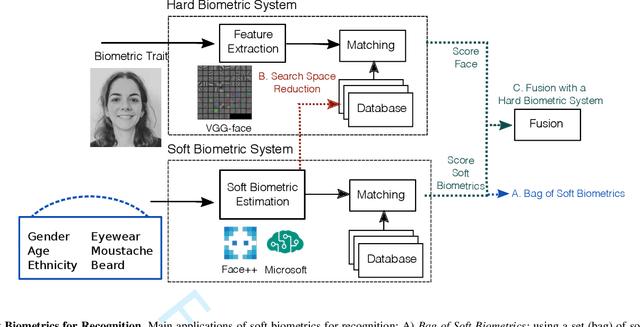
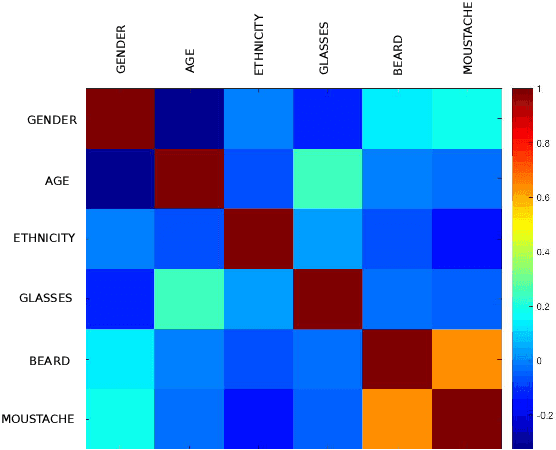
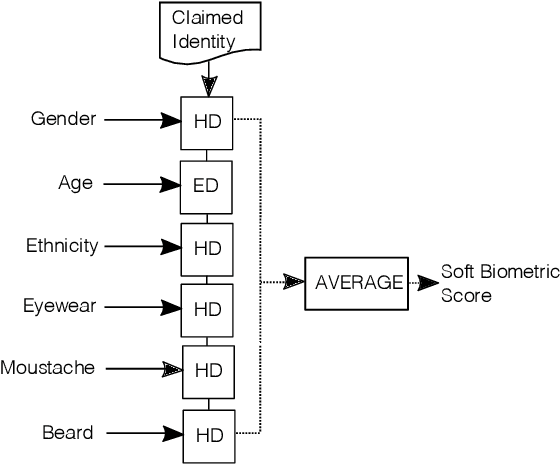

The role of soft biometrics to enhance person recognition systems in unconstrained scenarios has not been extensively studied. Here, we explore the utility of the following modalities: gender, ethnicity, age, glasses, beard, and moustache. We consider two assumptions: 1) manual estimation of soft biometrics and 2) automatic estimation from two commercial off-the-shelf systems (COTS). All experiments are reported using the labeled faces in the wild (LFW) database. First, we study the discrimination capabilities of soft biometrics standalone. Then, experiments are carried out fusing soft biometrics with two state-of-the-art face recognition systems based on deep learning. We observe that soft biometrics is a valuable complement to the face modality in unconstrained scenarios, with relative improvements up to 40%/15% in the verification performance when using manual/automatic soft biometrics estimation. Results are reproducible as we make public our manual annotations and COTS outputs of soft biometrics over LFW, as well as the face recognition scores.
Imponderous Net for Facial Expression Recognition in the Wild
Mar 28, 2021

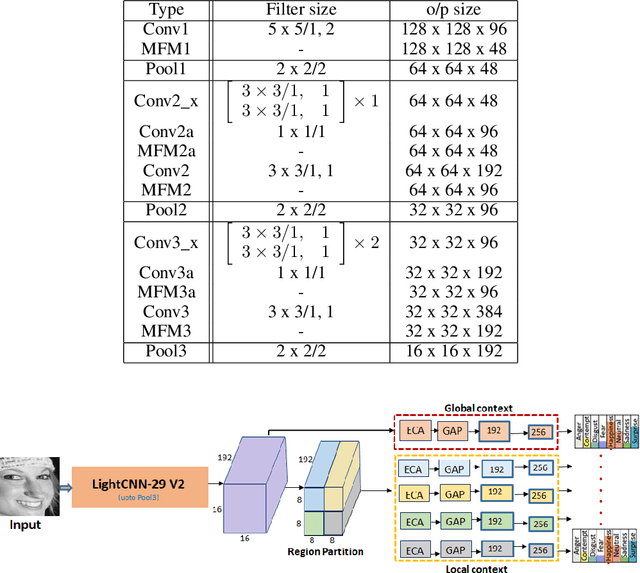
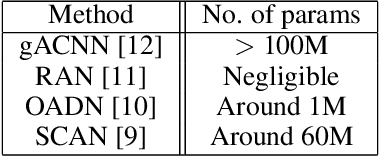
Since the renaissance of deep learning (DL), facial expression recognition (FER) has received a lot of interest, with continual improvement in the performance. Hand-in-hand with performance, new challenges have come up. Modern FER systems deal with face images captured under uncontrolled conditions (also called in-the-wild scenario) including occlusions and pose variations. They successfully handle such conditions using deep networks that come with various components like transfer learning, attention mechanism and local-global context extractor. However, these deep networks are highly complex with large number of parameters, making them unfit to be deployed in real scenarios. Is it possible to build a light-weight network that can still show significantly good performance on FER under in-the-wild scenario? In this work, we methodically build such a network and call it as Imponderous Net. We leverage on the aforementioned components of deep networks for FER, and analyse, carefully choose and fit them to arrive at Imponderous Net. Our Imponderous Net is a low calorie net with only 1.45M parameters, which is almost 50x less than that of a state-of-the-art (SOTA) architecture. Further, during inference, it can process at the real time rate of 40 frames per second (fps) in an intel-i7 cpu. Though it is low calorie, it is still power packed in its performance, overpowering other light-weight architectures and even few high capacity architectures. Specifically, Imponderous Net reports 87.09\%, 88.17\% and 62.06\% accuracies on in-the-wild datasets RAFDB, FERPlus and AffectNet respectively. It also exhibits superior robustness under occlusions and pose variations in comparison to other light-weight architectures from the literature.
Semantic Neighborhood-Aware Deep Facial Expression Recognition
Apr 27, 2020
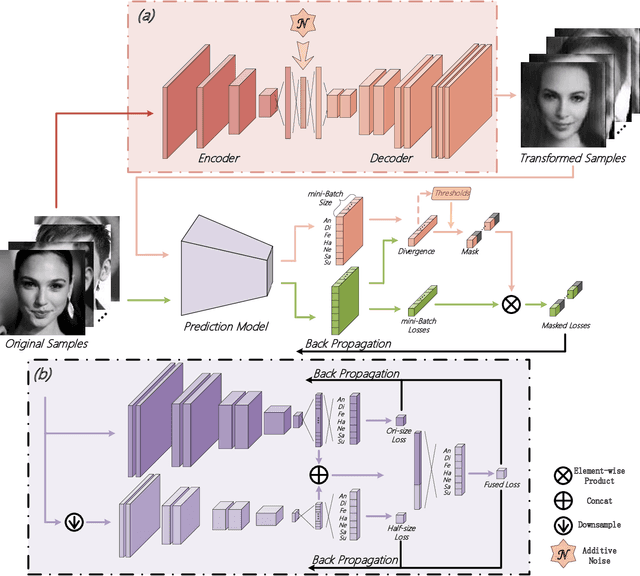

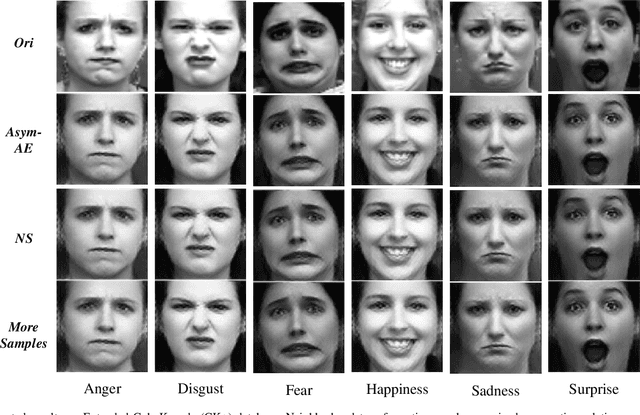
Different from many other attributes, facial expression can change in a continuous way, and therefore, a slight semantic change of input should also lead to the output fluctuation limited in a small scale. This consistency is important. However, current Facial Expression Recognition (FER) datasets may have the extreme imbalance problem, as well as the lack of data and the excessive amounts of noise, hindering this consistency and leading to a performance decreasing when testing. In this paper, we not only consider the prediction accuracy on sample points, but also take the neighborhood smoothness of them into consideration, focusing on the stability of the output with respect to slight semantic perturbations of the input. A novel method is proposed to formulate semantic perturbation and select unreliable samples during training, reducing the bad effect of them. Experiments show the effectiveness of the proposed method and state-of-the-art results are reported, getting closer to an upper limit than the state-of-the-art methods by a factor of 30\% in AffectNet, the largest in-the-wild FER database by now.
Assessing Dataset Bias in Computer Vision
May 03, 2022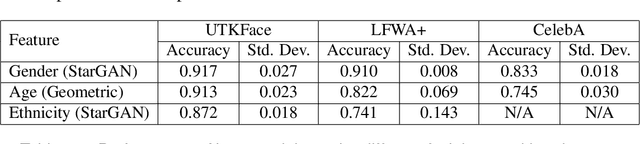

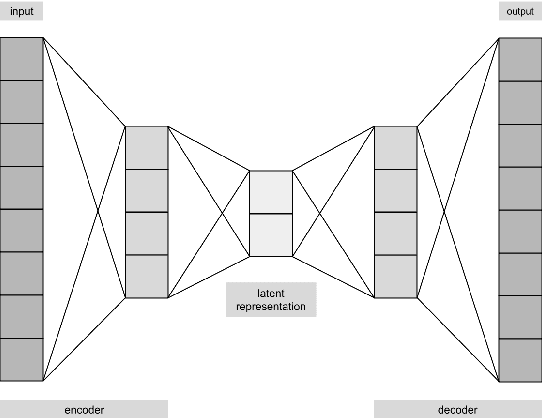
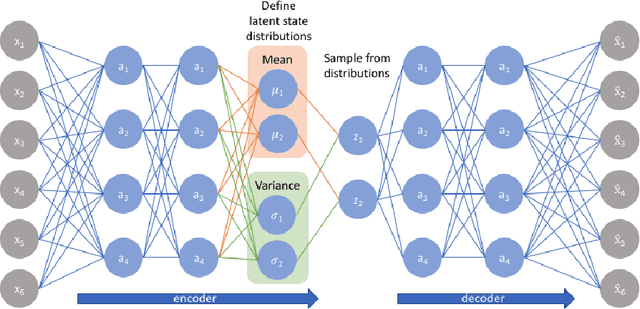
A biased dataset is a dataset that generally has attributes with an uneven class distribution. These biases have the tendency to propagate to the models that train on them, often leading to a poor performance in the minority class. In this project, we will explore the extent to which various data augmentation methods alleviate intrinsic biases within the dataset. We will apply several augmentation techniques on a sample of the UTKFace dataset, such as undersampling, geometric transformations, variational autoencoders (VAEs), and generative adversarial networks (GANs). We then trained a classifier for each of the augmented datasets and evaluated their performance on the native test set and on external facial recognition datasets. We have also compared their performance to the state-of-the-art attribute classifier trained on the FairFace dataset. Through experimentation, we were able to find that training the model on StarGAN-generated images led to the best overall performance. We also found that training on geometrically transformed images lead to a similar performance with a much quicker training time. Additionally, the best performing models also exhibit a uniform performance across the classes within each attribute. This signifies that the model was also able to mitigate the biases present in the baseline model that was trained on the original training set. Finally, we were able to show that our model has a better overall performance and consistency on age and ethnicity classification on multiple datasets when compared with the FairFace model. Our final model has an accuracy on the UTKFace test set of 91.75%, 91.30%, and 87.20% for the gender, age, and ethnicity attribute respectively, with a standard deviation of less than 0.1 between the accuracies of the classes of each attribute.
State of the Art of Quality Assessment of Facial Images
Nov 15, 2022

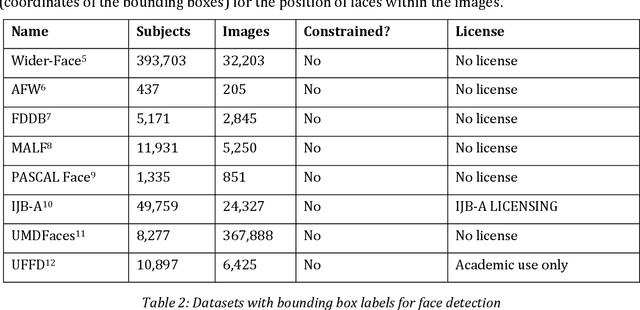

The goal of the project "Facial Metrics for EES" is to develop, implement and publish an open source algorithm for the quality assessment of facial images (OFIQ) for face recognition, in particular for border control scenarios.1 In order to stimulate the harmonization of the requirements and practices applied for QA for facial images, the insights gained and algorithms developed in the project will be contributed to the current (2022) revision of the ISO/IEC 29794-5 standard. Furthermore, the implemented quality metrics and algorithms will consider the recommendations and requirements from other relevant standards, in particular ISO/IEC 19794-5:2011, ISO/IEC 29794-5:2010, ISO/IEC 39794-5:2019 and Version 5.2 of the BSI Technical Guideline TR-03121 Part 3 Volume 1. In order to establish an informed basis for the selection of quality metrics and the development of corresponding quality assessment algorithms, the state of the art of methods and algorithms (defining a metric), implementations and datasets for quality assessment for facial images is surveyed. For all relevant quality aspects, this document summarizes the requirements of the aforementioned standards, known results on their impact on face recognition performance, publicly available datasets, proposed methods and algorithms and open source software implementations.
Can GAN-induced Attribute Manipulations Impact Face Recognition?
Sep 07, 2022
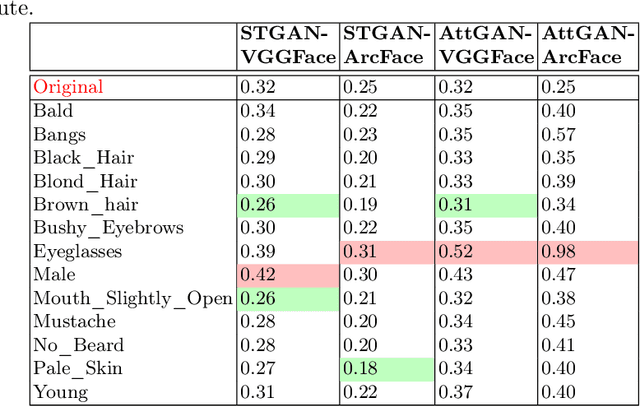
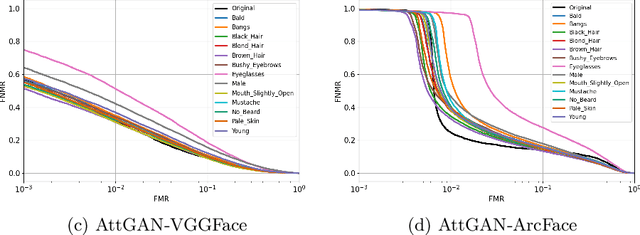
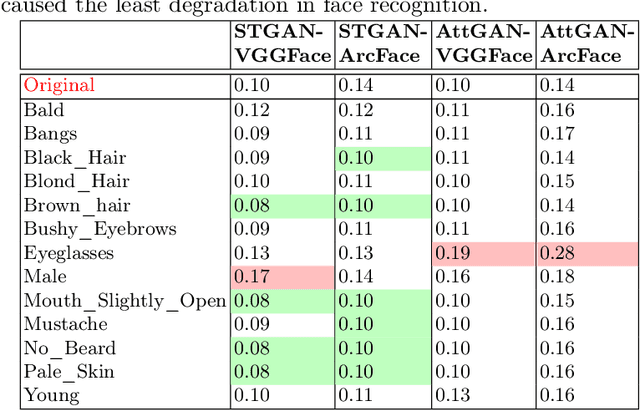
Impact due to demographic factors such as age, sex, race, etc., has been studied extensively in automated face recognition systems. However, the impact of \textit{digitally modified} demographic and facial attributes on face recognition is relatively under-explored. In this work, we study the effect of attribute manipulations induced via generative adversarial networks (GANs) on face recognition performance. We conduct experiments on the CelebA dataset by intentionally modifying thirteen attributes using AttGAN and STGAN and evaluating their impact on two deep learning-based face verification methods, ArcFace and VGGFace. Our findings indicate that some attribute manipulations involving eyeglasses and digital alteration of sex cues can significantly impair face recognition by up to 73% and need further analysis.