 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
A Peek at Peak Emotion Recognition
May 19, 2022



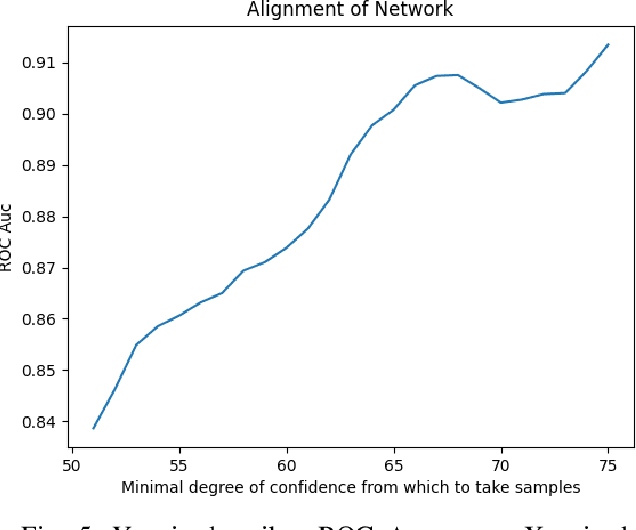
Despite much progress in the field of facial expression recognition, little attention has been paid to the recognition of peak emotion. Aviezer et al. [1] showed that humans have trouble discerning between positive and negative peak emotions. In this work we analyze how deep learning fares on this challenge. We find that (i) despite using very small datasets, features extracted from deep learning models can achieve results significantly better than humans. (ii) We find that deep learning models, even when trained only on datasets tagged by humans, still outperform humans in this task.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021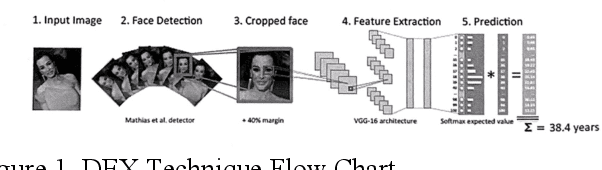
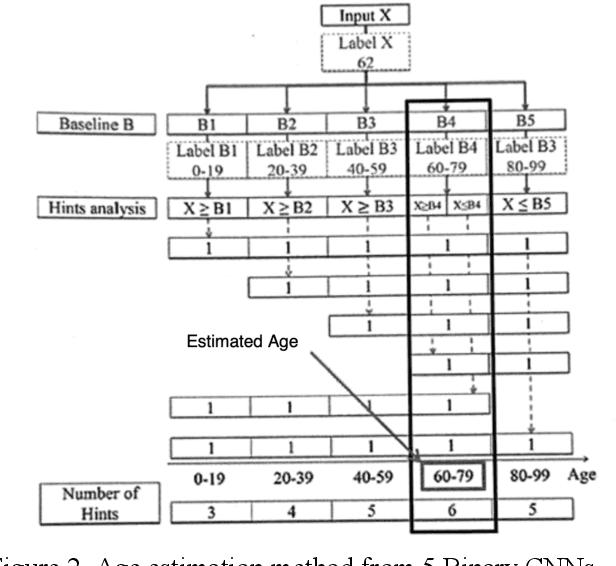
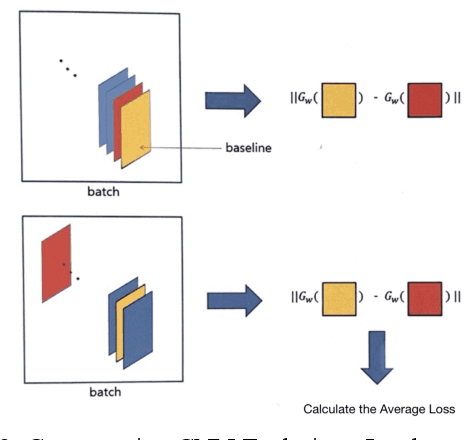
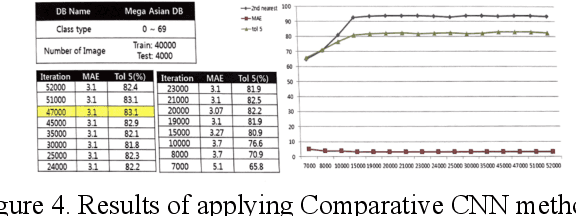
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.
Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition
Nov 10, 2020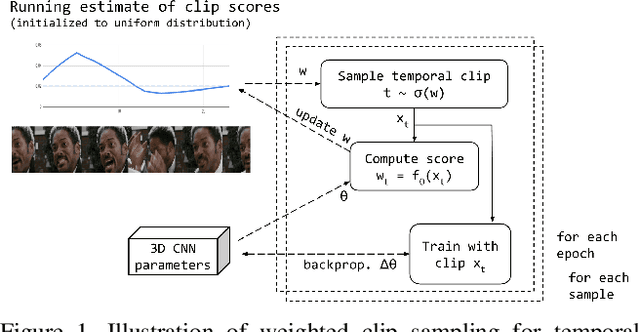
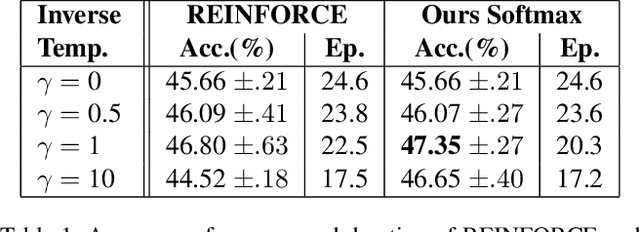
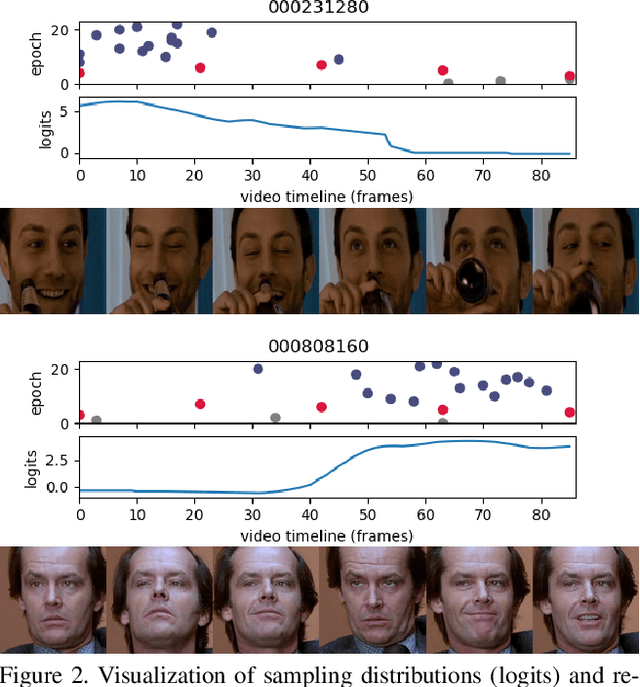
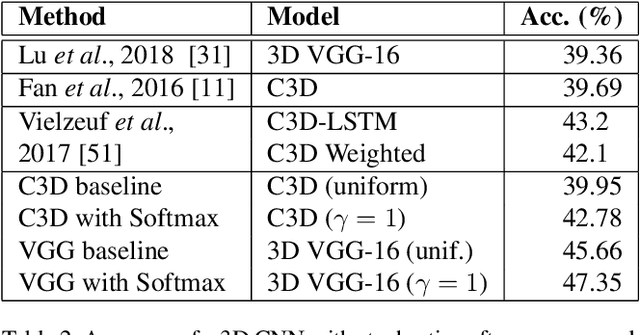
Training deep learning models for accurate spatiotemporal recognition of facial expressions in videos requires significant computational resources. For practical reasons, 3D Convolutional Neural Networks (3D CNNs) are usually trained with relatively short clips randomly extracted from videos. However, such uniform sampling is generally sub-optimal because equal importance is assigned to each temporal clip. In this paper, we present a strategy for efficient video-based training of 3D CNNs. It relies on softmax temporal pooling and a weighted sampling mechanism to select the most relevant training clips. The proposed softmax strategy provides several advantages: a reduced computational complexity due to efficient clip sampling, and an improved accuracy since temporal weighting focuses on more relevant clips during both training and inference. Experimental results obtained with the proposed method on several facial expression recognition benchmarks show the benefits of focusing on more informative clips in training videos. In particular, our approach improves performance and computational cost by reducing the impact of inaccurate trimming and coarse annotation of videos, and heterogeneous distribution of visual information across time.
Investigating Bias and Fairness in Facial Expression Recognition
Aug 21, 2020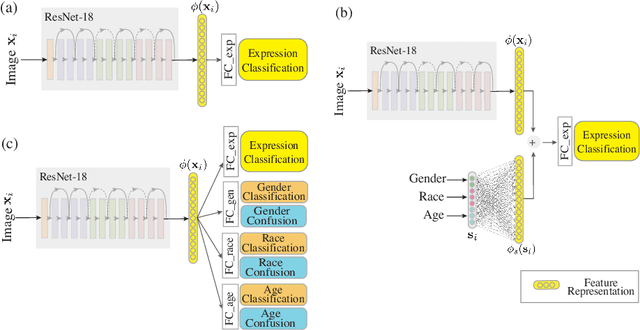
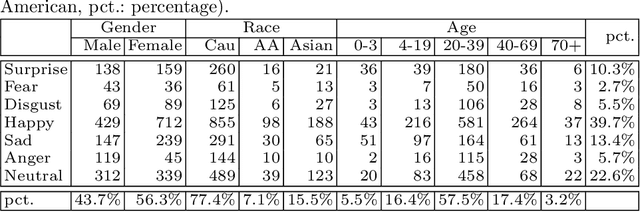
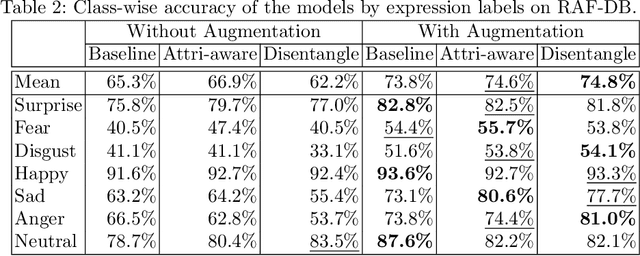
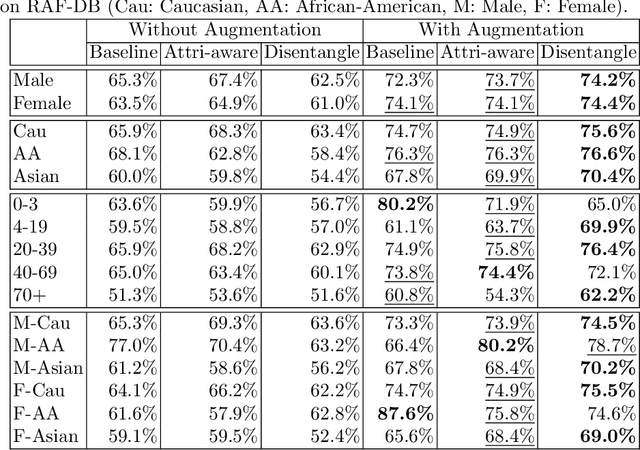
Recognition of expressions of emotions and affect from facial images is a well-studied research problem in the fields of affective computing and computer vision with a large number of datasets available containing facial images and corresponding expression labels. However, virtually none of these datasets have been acquired with consideration of fair distribution across the human population. Therefore, in this work, we undertake a systematic investigation of bias and fairness in facial expression recognition by comparing three different approaches, namely a baseline, an attribute-aware and a disentangled approach, on two well-known datasets, RAF-DB and CelebA. Our results indicate that: (i) data augmentation improves the accuracy of the baseline model, but this alone is unable to mitigate the bias effect; (ii) both the attribute-aware and the disentangled approaches fortified with data augmentation perform better than the baseline approach in terms of accuracy and fairness; (iii) the disentangled approach is the best for mitigating demographic bias; and (iv) the bias mitigation strategies are more suitable in the existence of uneven attribute distribution or imbalanced number of subgroup data.
Hand-Assisted Expression Recognition Method from Synthetic Images at the Fourth ABAW Challenge
Jul 20, 2022
Learning from synthetic images plays an important role in facial expression recognition task due to the difficulties of labeling the real images, and it is challenging because of the gap between the synthetic images and real images. The fourth Affective Behavior Analysis in-the-wild Competition raises the challenge and provides the synthetic images generated from Aff-Wild2 dataset. In this paper, we propose a hand-assisted expression recognition method to reduce the gap between the synthetic data and real data. Our method consists of two parts: expression recognition module and hand prediction module. Expression recognition module extracts expression information and hand prediction module predicts whether the image contains hands. Decision mode is used to combine the results of two modules, and post-pruning is used to improve the result. F1 score is used to verify the effectiveness of our method.
Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
Apr 21, 2021
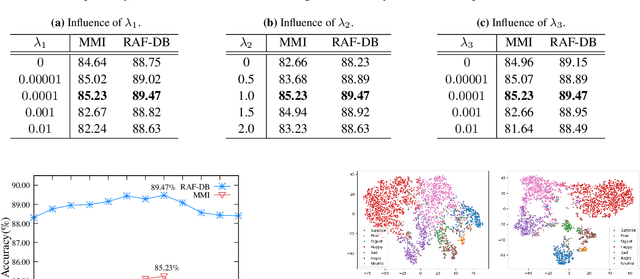
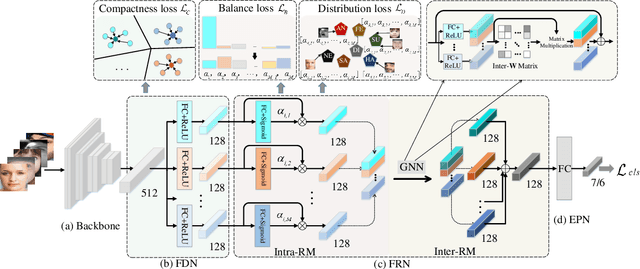
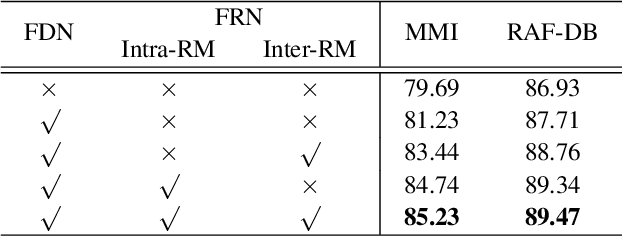
In this paper, we propose a novel Feature Decomposition and Reconstruction Learning (FDRL) method for effective facial expression recognition. We view the expression information as the combination of the shared information (expression similarities) across different expressions and the unique information (expression-specific variations) for each expression. More specifically, FDRL mainly consists of two crucial networks: a Feature Decomposition Network (FDN) and a Feature Reconstruction Network (FRN). In particular, FDN first decomposes the basic features extracted from a backbone network into a set of facial action-aware latent features to model expression similarities. Then, FRN captures the intra-feature and inter-feature relationships for latent features to characterize expression-specific variations, and reconstructs the expression feature. To this end, two modules including an intra-feature relation modeling module and an inter-feature relation modeling module are developed in FRN. Experimental results on both the in-the-lab databases (including CK+, MMI, and Oulu-CASIA) and the in-the-wild databases (including RAF-DB and SFEW) show that the proposed FDRL method consistently achieves higher recognition accuracy than several state-of-the-art methods. This clearly highlights the benefit of feature decomposition and reconstruction for classifying expressions.
Facial Emotion Recognition with Noisy Multi-task Annotations
Oct 19, 2020
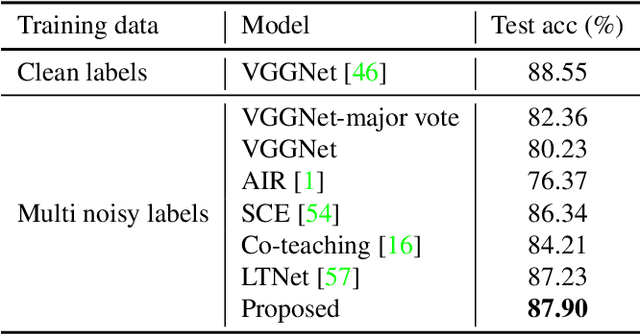
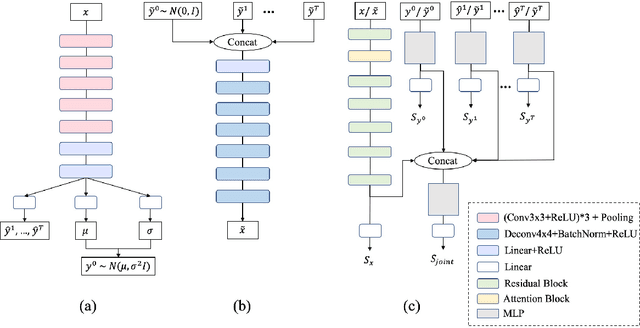
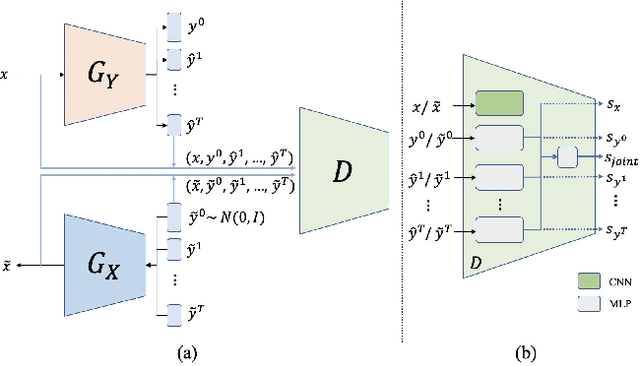
Human emotions can be inferred from facial expressions. However, the annotations of facial expressions are often highly noisy in common emotion coding models, including categorical and dimensional ones. To reduce human labelling effort on multi-task labels, we introduce a new problem of facial emotion recognition with noisy multi-task annotations. For this new problem, we suggest a formulation from the point of joint distribution match view, which aims at learning more reliable correlations among raw facial images and multi-task labels, resulting in the reduction of noise influence. In our formulation, we exploit a new method to enable the emotion prediction and the joint distribution learning in a unified adversarial learning game. Evaluation throughout extensive experiments studies the real setups of the suggested new problem, as well as the clear superiority of the proposed method over the state-of-the-art competing methods on either the synthetic noisy labeled CIFAR-10 or practical noisy multi-task labeled RAF and AffectNet.
Technical Challenges for Training Fair Neural Networks
Feb 12, 2021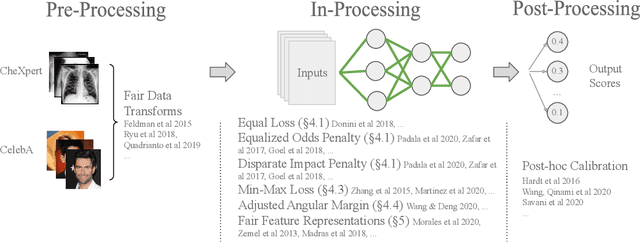
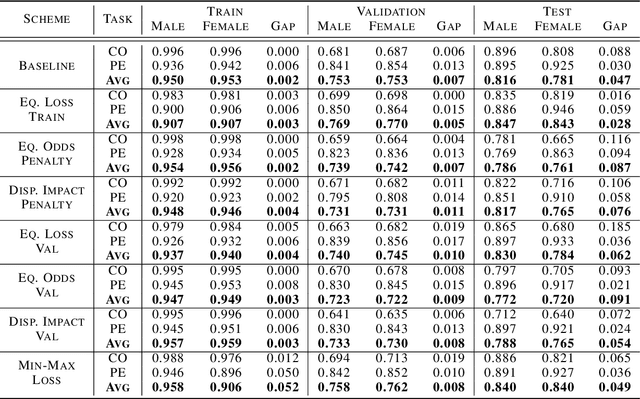

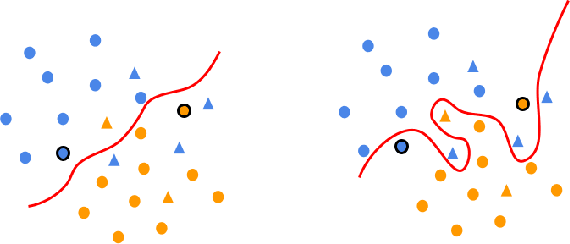
As machine learning algorithms have been widely deployed across applications, many concerns have been raised over the fairness of their predictions, especially in high stakes settings (such as facial recognition and medical imaging). To respond to these concerns, the community has proposed and formalized various notions of fairness as well as methods for rectifying unfair behavior. While fairness constraints have been studied extensively for classical models, the effectiveness of methods for imposing fairness on deep neural networks is unclear. In this paper, we observe that these large models overfit to fairness objectives, and produce a range of unintended and undesirable consequences. We conduct our experiments on both facial recognition and automated medical diagnosis datasets using state-of-the-art architectures.
AuthNet: A Deep Learning based Authentication Mechanism using Temporal Facial Feature Movements
Dec 19, 2020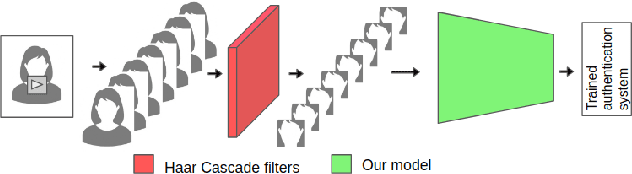

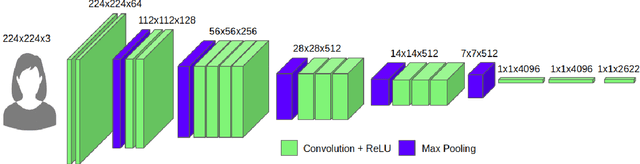

Biometric systems based on Machine learning and Deep learning are being extensively used as authentication mechanisms in resource-constrained environments like smartphones and other small computing devices. These AI-powered facial recognition mechanisms have gained enormous popularity in recent years due to their transparent, contact-less and non-invasive nature. While they are effective to a large extent, there are ways to gain unauthorized access using photographs, masks, glasses, etc. In this paper, we propose an alternative authentication mechanism that uses both facial recognition and the unique movements of that particular face while uttering a password, that is, the temporal facial feature movements. The proposed model is not inhibited by language barriers because a user can set a password in any language. When evaluated on the standard MIRACL-VC1 dataset, the proposed model achieved an accuracy of 98.1%, underscoring its effectiveness as an effective and robust system. The proposed method is also data-efficient since the model gave good results even when trained with only 10 positive video samples. The competence of the training of the network is also demonstrated by benchmarking the proposed system against various compounded Facial recognition and Lip reading models.