 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
When Facial Expression Recognition Meets Few-Shot Learning: A Joint and Alternate Learning Framework
Jan 18, 2022
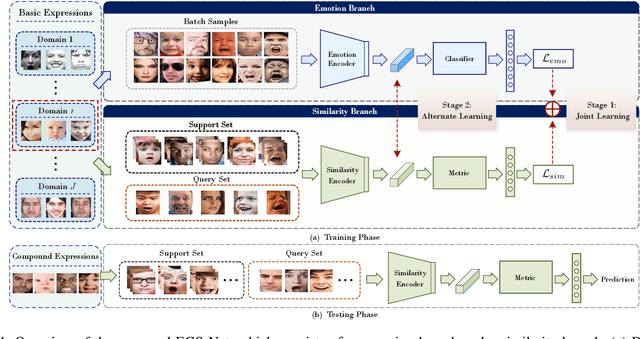
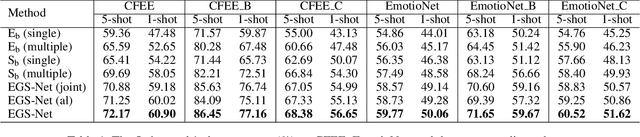
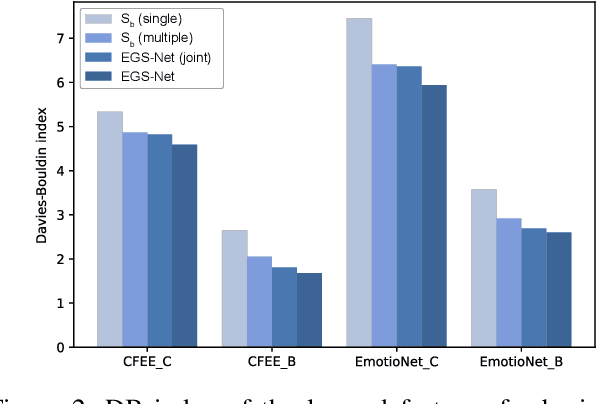
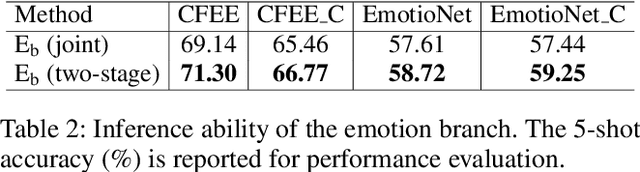
Human emotions involve basic and compound facial expressions. However, current research on facial expression recognition (FER) mainly focuses on basic expressions, and thus fails to address the diversity of human emotions in practical scenarios. Meanwhile, existing work on compound FER relies heavily on abundant labeled compound expression training data, which are often laboriously collected under the professional instruction of psychology. In this paper, we study compound FER in the cross-domain few-shot learning setting, where only a few images of novel classes from the target domain are required as a reference. In particular, we aim to identify unseen compound expressions with the model trained on easily accessible basic expression datasets. To alleviate the problem of limited base classes in our FER task, we propose a novel Emotion Guided Similarity Network (EGS-Net), consisting of an emotion branch and a similarity branch, based on a two-stage learning framework. Specifically, in the first stage, the similarity branch is jointly trained with the emotion branch in a multi-task fashion. With the regularization of the emotion branch, we prevent the similarity branch from overfitting to sampled base classes that are highly overlapped across different episodes. In the second stage, the emotion branch and the similarity branch play a "two-student game" to alternately learn from each other, thereby further improving the inference ability of the similarity branch on unseen compound expressions. Experimental results on both in-the-lab and in-the-wild compound expression datasets demonstrate the superiority of our proposed method against several state-of-the-art methods.
DeepFN: Towards Generalizable Facial Action Unit Recognition with Deep Face Normalization
Mar 03, 2021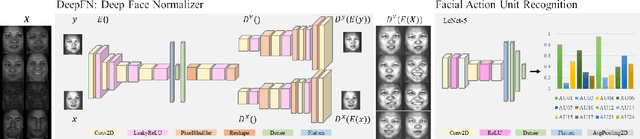
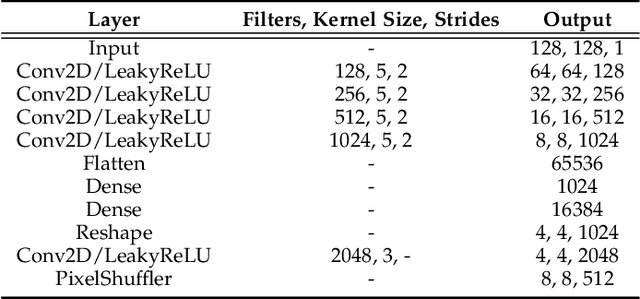
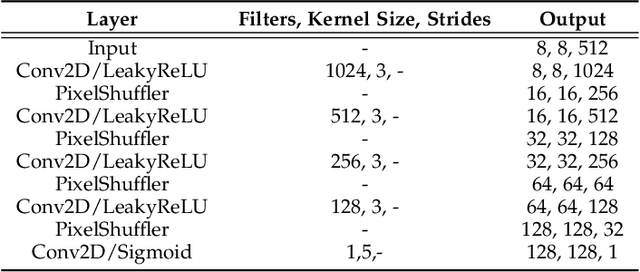
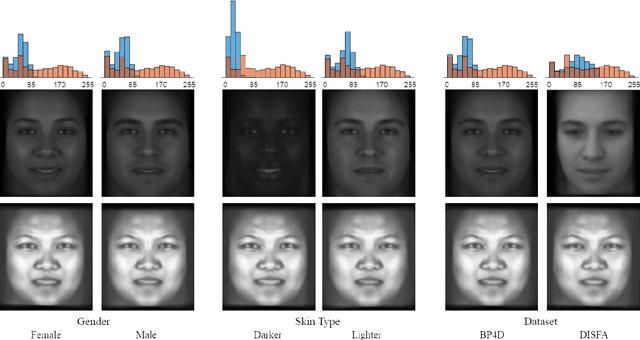
Facial action unit recognition has many applications from market research to psychotherapy and from image captioning to entertainment. Despite its recent progress, deployment of these models has been impeded due to their limited generalization to unseen people and demographics. This work conducts an in-depth analysis of performance across several dimensions: individuals(40 subjects), genders (male and female), skin types (darker and lighter), and databases (BP4D and DISFA). To help suppress the variance in data, we use the notion of self-supervised denoising autoencoders to design a method for deep face normalization(DeepFN) that transfers facial expressions of different people onto a common facial template which is then used to train and evaluate facial action recognition models. We show that person-independent models yield significantly lower performance (55% average F1 and accuracy across 40 subjects) than person-dependent models (60.3%), leading to a generalization gap of 5.3%. However, normalizing the data with the newly introduced DeepFN significantly increased the performance of person-independent models (59.6%), effectively reducing the gap. Similarly, we observed generalization gaps when considering gender (2.4%), skin type (5.3%), and dataset (9.4%), which were significantly reduced with the use of DeepFN. These findings represent an important step towards the creation of more generalizable facial action unit recognition systems.
Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition
Jun 07, 2021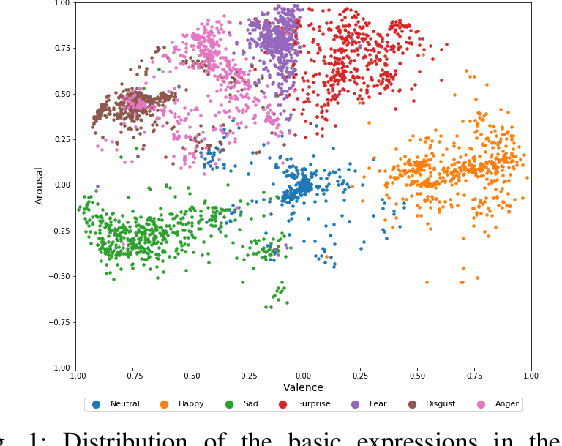
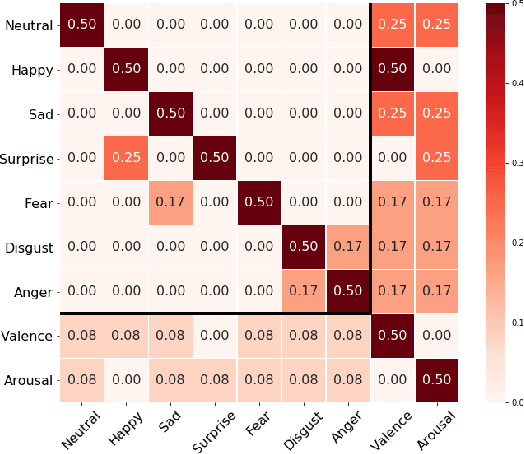
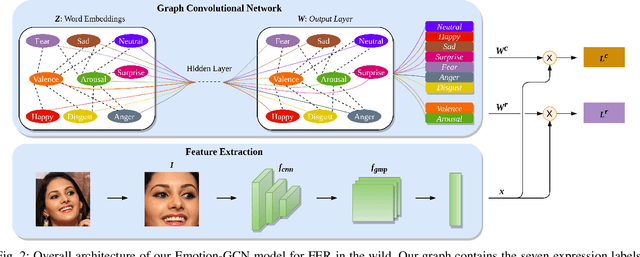
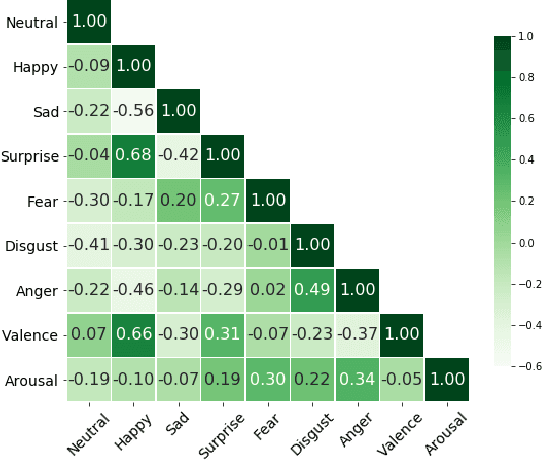
Over the past few years, deep learning methods have shown remarkable results in many face-related tasks including automatic facial expression recognition (FER) in-the-wild. Meanwhile, numerous models describing the human emotional states have been proposed by the psychology community. However, we have no clear evidence as to which representation is more appropriate and the majority of FER systems use either the categorical or the dimensional model of affect. Inspired by recent work in multi-label classification, this paper proposes a novel multi-task learning (MTL) framework that exploits the dependencies between these two models using a Graph Convolutional Network (GCN) to recognize facial expressions in-the-wild. Specifically, a shared feature representation is learned for both discrete and continuous recognition in a MTL setting. Moreover, the facial expression classifiers and the valence-arousal regressors are learned through a GCN that explicitly captures the dependencies between them. To evaluate the performance of our method under real-world conditions we train our models on AffectNet dataset. The results of our experiments show that our method outperforms the current state-of-the-art methods on discrete FER.
Kernelized dense layers for facial expression recognition
Sep 22, 2020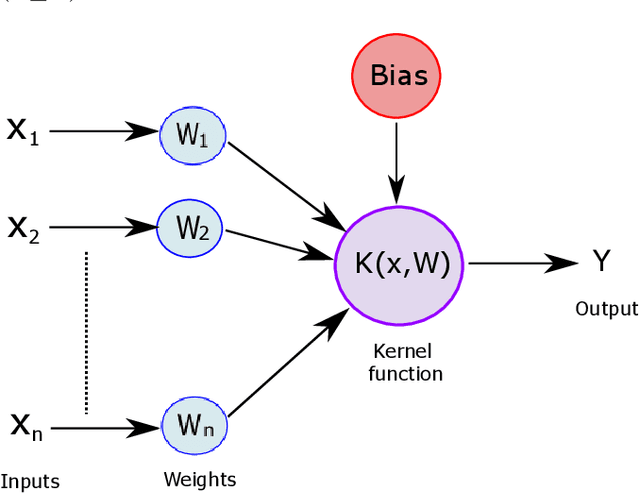
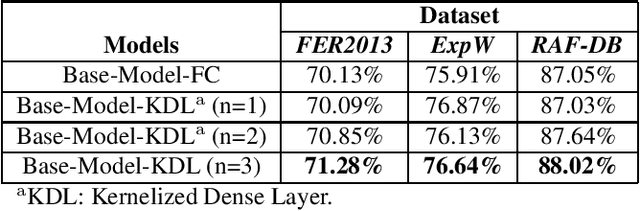
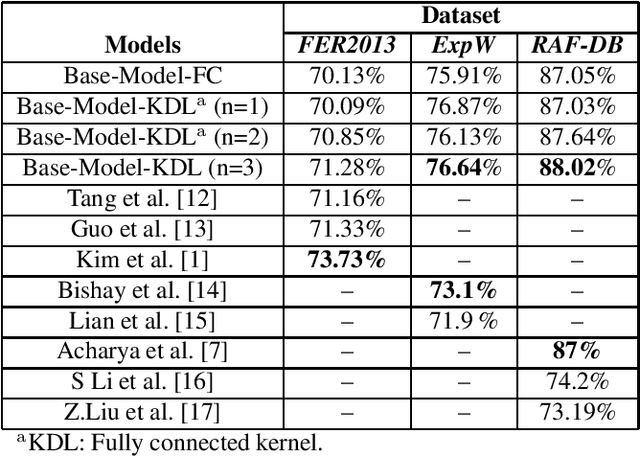
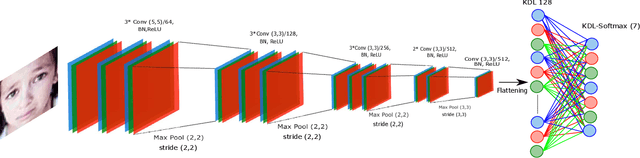
Fully connected layer is an essential component of Convolutional Neural Networks (CNNs), which demonstrates its efficiency in computer vision tasks. The CNN process usually starts with convolution and pooling layers that first break down the input images into features, and then analyze them independently. The result of this process feeds into a fully connected neural network structure which drives the final classification decision. In this paper, we propose a Kernelized Dense Layer (KDL) which captures higher order feature interactions instead of conventional linear relations. We apply this method to Facial Expression Recognition (FER) and evaluate its performance on RAF, FER2013 and ExpW datasets. The experimental results demonstrate the benefits of such layer and show that our model achieves competitive results with respect to the state-of-the-art approaches.
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022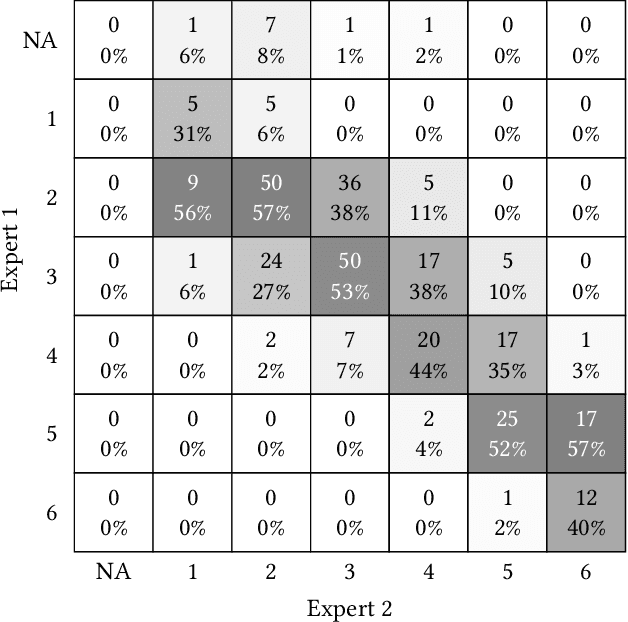
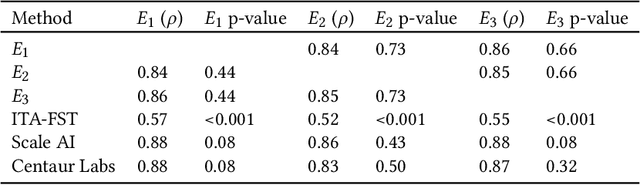
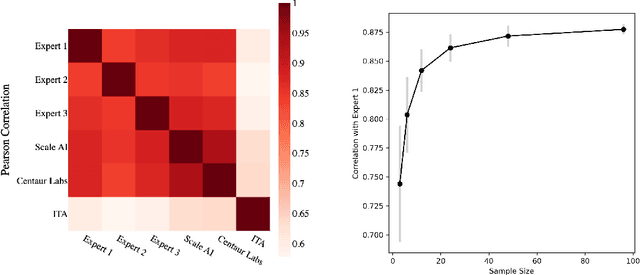
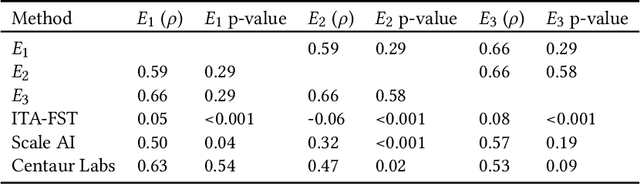
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
Revisiting Few-Shot Learning for Facial Expression Recognition
Dec 11, 2019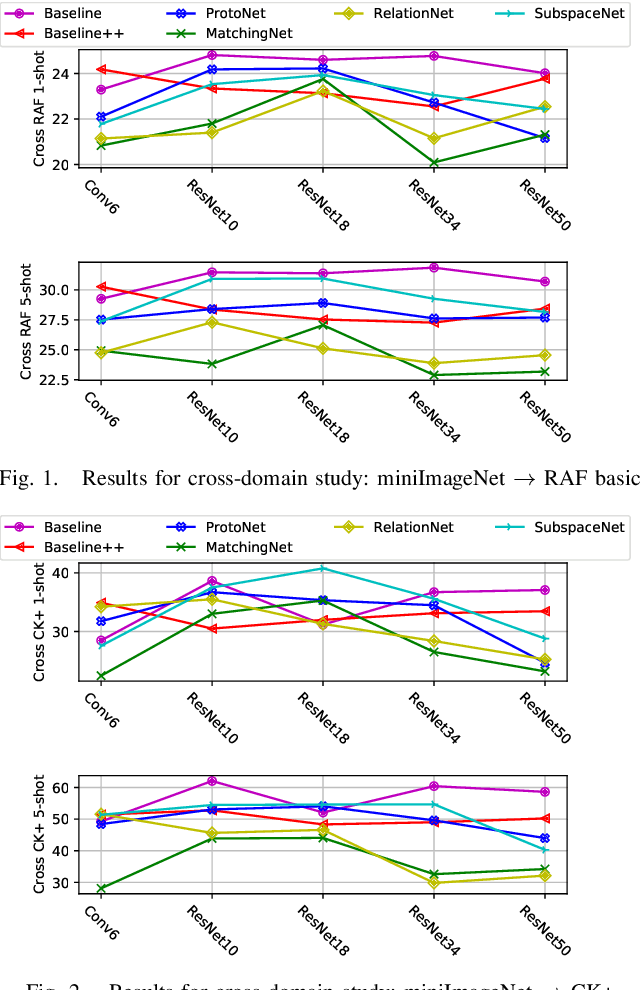
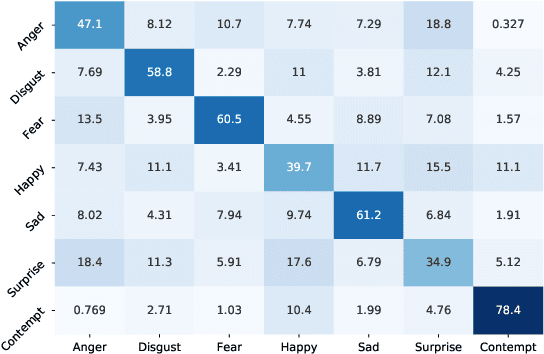
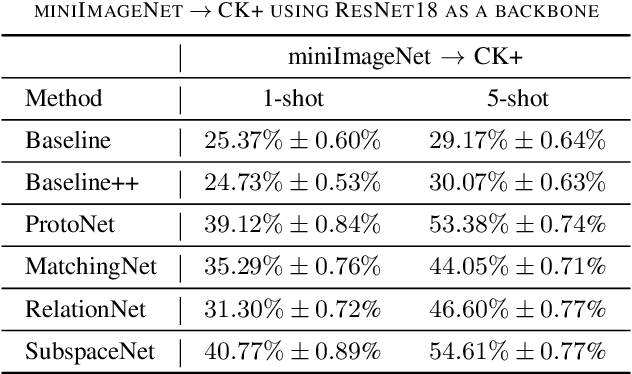
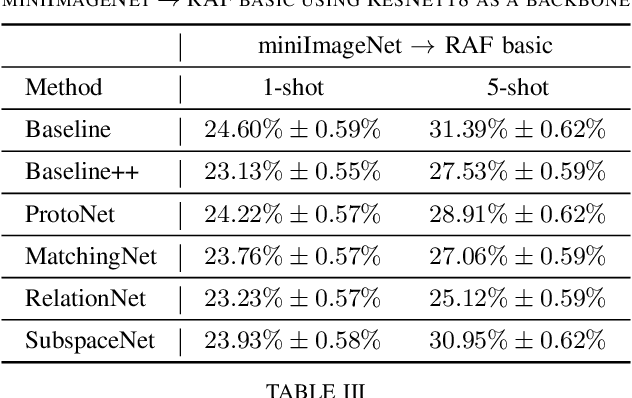
Most of the existing deep neural nets on automatic facial expression recognition focus on a set of predefined emotion classes, where the amount of training data has the biggest impact on performance. However, in the standard setting over-parameterised neural networks are not amenable for learning from few samples as they can quickly over-fit. In addition, these approaches do not have such a strong generalisation ability to identify a new category, where the data of each category is too limited and significant variations exist in the expression within the same semantic category. We embrace these challenges and formulate the problem as a low-shot learning, where once the base classifier is deployed, it must rapidly adapt to recognise novel classes using a few samples. In this paper, we revisit and compare existing few-shot learning methods for the low-shot facial expression recognition in terms of their generalisation ability via episode-training. In particular, we extend our analysis on the cross-domain generalisation, where training and test tasks are not drawn from the same distribution. We demonstrate the efficacy of low-shot learning methods through extensive experiments.
Human Expression Recognition using Facial Shape Based Fourier Descriptors Fusion
Dec 28, 2020Dynamic facial expression recognition has many useful applications in social networks, multimedia content analysis, security systems and others. This challenging process must be done under recurrent problems of image illumination and low resolution which changes at partial occlusions. This paper aims to produce a new facial expression recognition method based on the changes in the facial muscles. The geometric features are used to specify the facial regions i.e., mouth, eyes, and nose. The generic Fourier shape descriptor in conjunction with elliptic Fourier shape descriptor is used as an attribute to represent different emotions under frequency spectrum features. Afterwards a multi-class support vector machine is applied for classification of seven human expression. The statistical analysis showed our approach obtained overall competent recognition using 5-fold cross validation with high accuracy on well-known facial expression dataset.
Deep Convolutional Neural Network Based Facial Expression Recognition in the Wild
Oct 03, 2020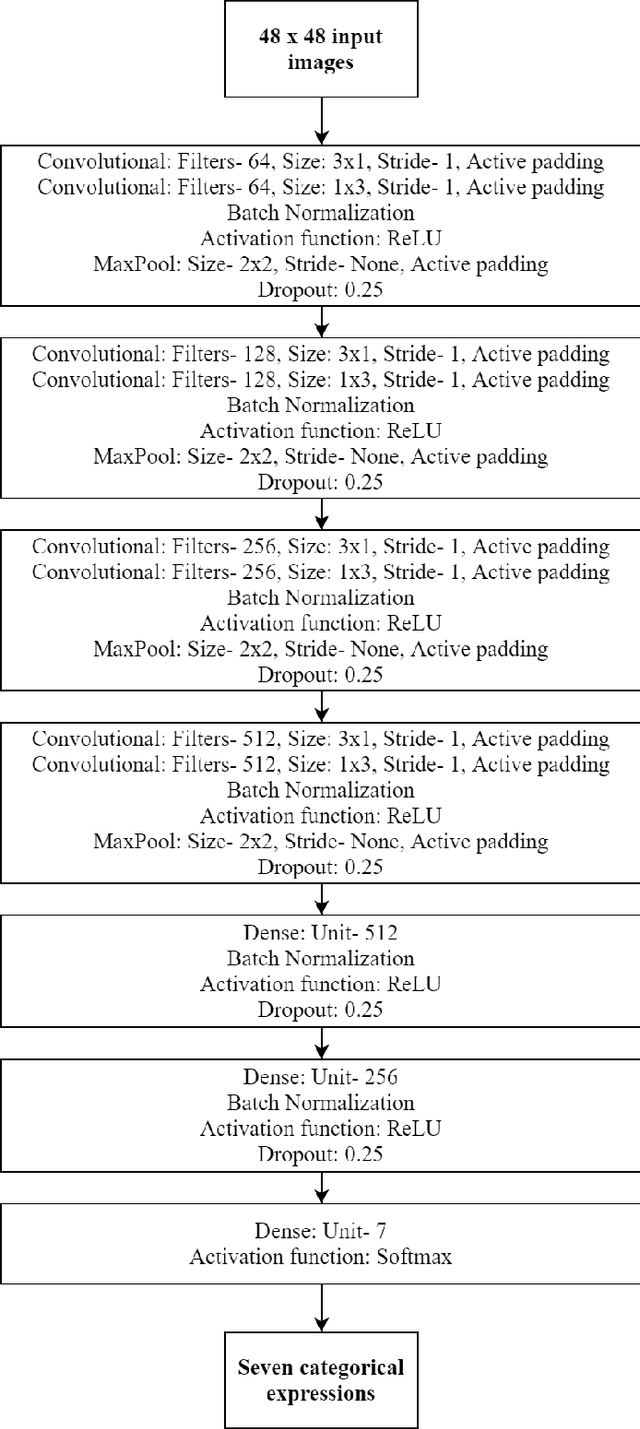
This paper describes the proposed methodology, data used and the results of our participation in the ChallengeTrack 2 (Expr Challenge Track) of the Affective Behavior Analysis in-the-wild (ABAW) Competition 2020. In this competition, we have used a proposed deep convolutional neural network (CNN) model to perform automatic facial expression recognition (AFER) on the given dataset. Our proposed model has achieved an accuracy of 50.77% and an F1 score of 29.16% on the validation set.
Practical Digital Disguises: Leveraging Face Swaps to Protect Patient Privacy
Apr 13, 2022
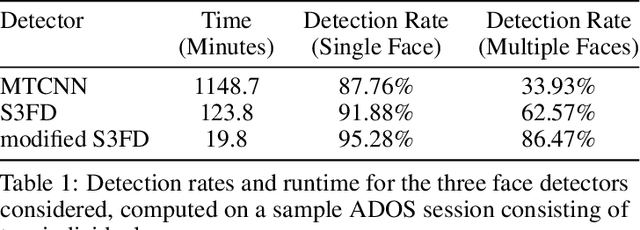
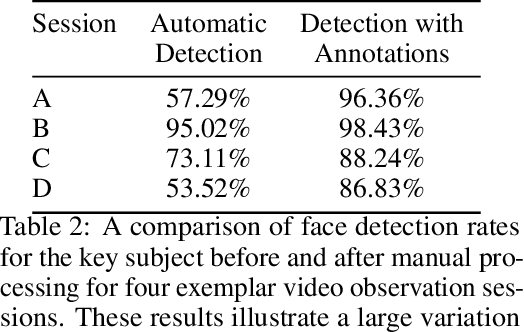
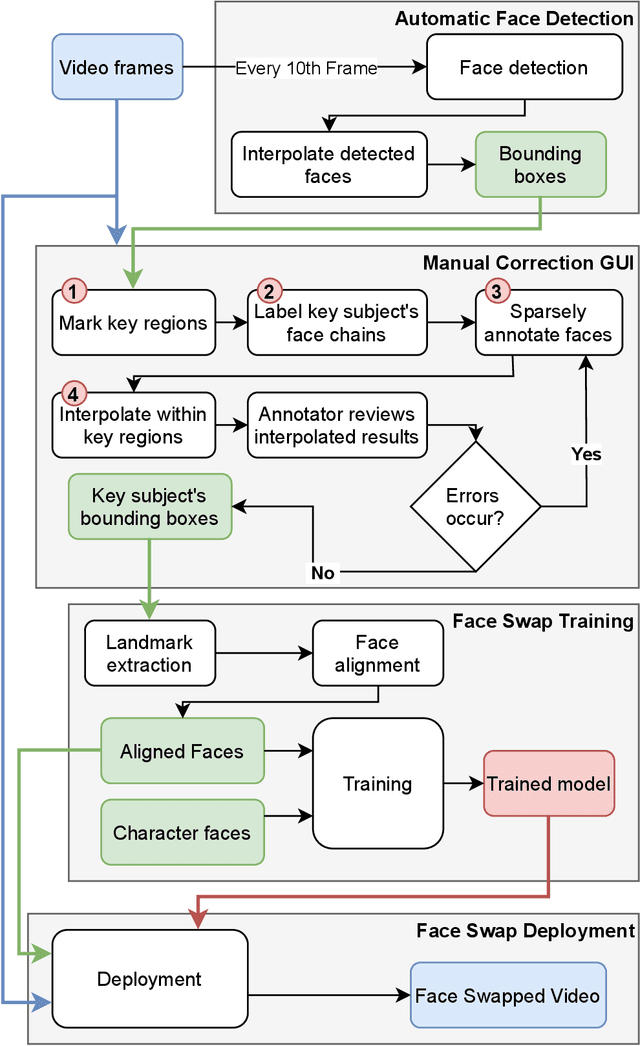
With rapid advancements in image generation technology, face swapping for privacy protection has emerged as an active area of research. The ultimate benefit is improved access to video datasets, e.g. in healthcare settings. Recent literature has proposed deep network-based architectures to perform facial swaps and reported the associated reduction in facial recognition accuracy. However, there is not much reporting on how well these methods preserve the types of semantic information needed for the privatized videos to remain useful for their intended application. Our main contribution is a novel end-to-end face swapping pipeline for recorded videos of standardized assessments of autism symptoms in children. Through this design, we are the first to provide a methodology for assessing the privacy-utility trade-offs for the face swapping approach to patient privacy protection. Our methodology can show, for example, that current deep network based face swapping is bottle-necked by face detection in real world videos, and the extent to which gaze and expression information is preserved by face swaps relative to baseline privatization methods such as blurring.