 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Protection of SVM Model with Secret Key from Unauthorized Access
Nov 17, 2021
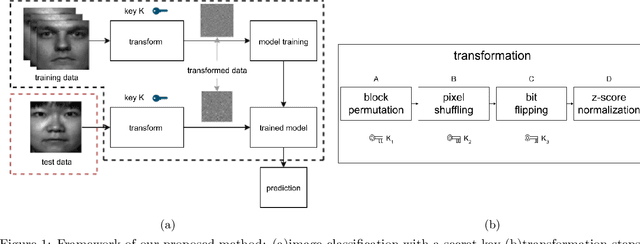


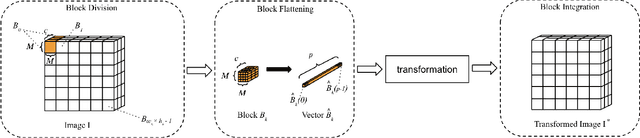
In this paper, we propose a block-wise image transformation method with a secret key for support vector machine (SVM) models. Models trained by using transformed images offer a poor performance to unauthorized users without a key, while they can offer a high performance to authorized users with a key. The proposed method is demonstrated to be robust enough against unauthorized access even under the use of kernel functions in a facial recognition experiment.
Deep Covariance Descriptors for Facial Expression Recognition
May 10, 2018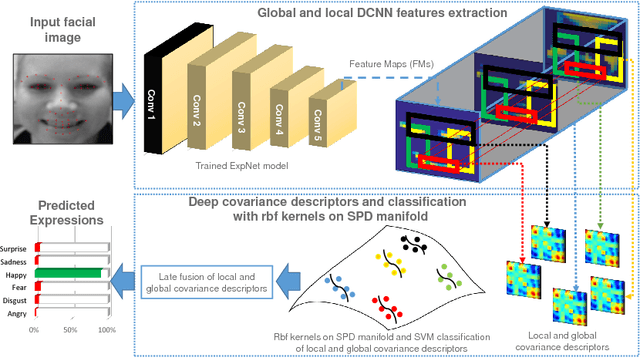

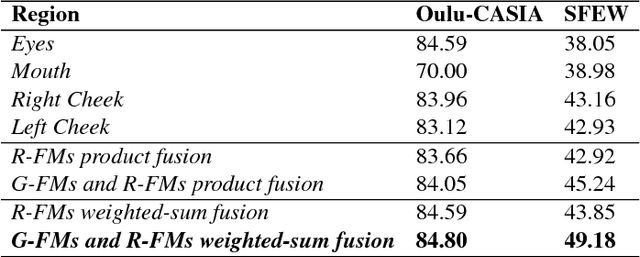
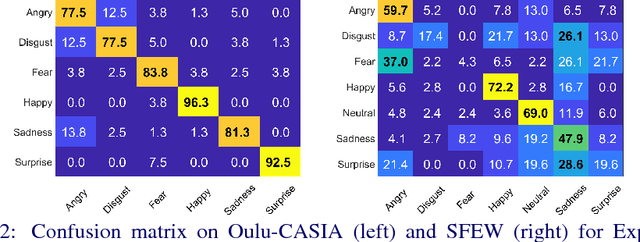
In this paper, covariance matrices are exploited to encode the deep convolutional neural networks (DCNN) features for facial expression recognition. The space geometry of the covariance matrices is that of Symmetric Positive Definite (SPD) matrices. By performing the classification of the facial expressions using Gaussian kernel on SPD manifold, we show that the covariance descriptors computed on DCNN features are more efficient than the standard classification with fully connected layers and softmax. By implementing our approach using the VGG-face and ExpNet architectures with extensive experiments on the Oulu-CASIA and SFEW datasets, we show that the proposed approach achieves performance at the state of the art for facial expression recognition.
Comparing Facial Expression Recognition in Humans and Machines: Using CAM, GradCAM, and Extremal Perturbation
Oct 09, 2021

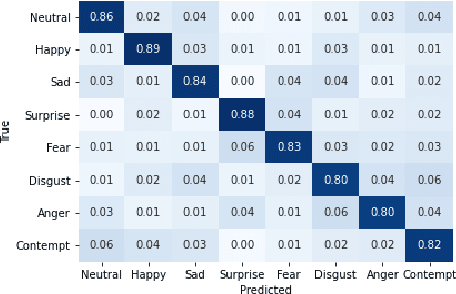
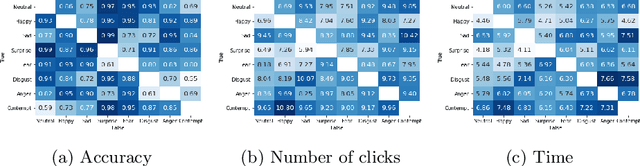
Facial expression recognition (FER) is a topic attracting significant research in both psychology and machine learning with a wide range of applications. Despite a wealth of research on human FER and considerable progress in computational FER made possible by deep neural networks (DNNs), comparatively less work has been done on comparing the degree to which DNNs may be comparable to human performance. In this work, we compared the recognition performance and attention patterns of humans and machines during a two-alternative forced-choice FER task. Human attention was here gathered through click data that progressively uncovered a face, whereas model attention was obtained using three different popular techniques from explainable AI: CAM, GradCAM and Extremal Perturbation. In both cases, performance was gathered as percent correct. For this task, we found that humans outperformed machines quite significantly. In terms of attention patterns, we found that Extremal Perturbation had the best overall fit with the human attention map during the task.
Detection, Recognition, and Tracking: A Survey
Mar 22, 2022For humans, object detection, recognition, and tracking are innate. These provide the ability for human to perceive their environment and objects within their environment. This ability however doesn't translate well in computers. In Computer Vision and Multimedia, it is becoming increasingly more important to detect, recognize and track objects in images and/or videos. Many of these applications, such as facial recognition, surveillance, animation, are used for tracking features and/or people. However, these tasks prove challenging for computers to do effectively, as there is a significant amount of data to parse through. Therefore, many techniques and algorithms are needed and therefore researched to try to achieve human like perception. In this literature review, we focus on some novel techniques on object detection and recognition, and how to apply tracking algorithms to the detected features to track the objects' movements.
Expression Snippet Transformer for Robust Video-based Facial Expression Recognition
Sep 17, 2021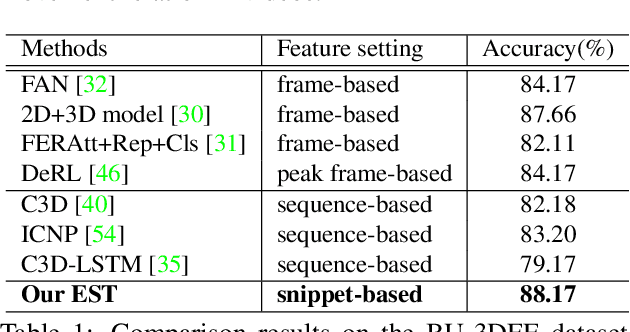
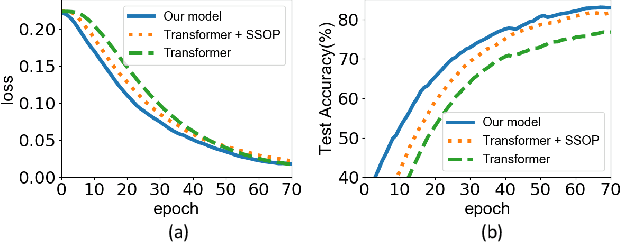
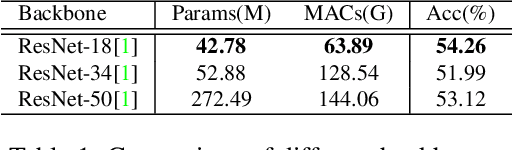
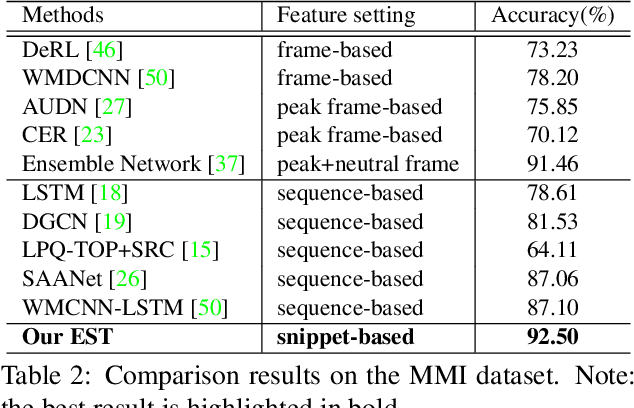
The recent success of Transformer has provided a new direction to various visual understanding tasks, including video-based facial expression recognition (FER). By modeling visual relations effectively, Transformer has shown its power for describing complicated patterns. However, Transformer still performs unsatisfactorily to notice subtle facial expression movements, because the expression movements of many videos can be too small to extract meaningful spatial-temporal relations and achieve robust performance. To this end, we propose to decompose each video into a series of expression snippets, each of which contains a small number of facial movements, and attempt to augment the Transformer's ability for modeling intra-snippet and inter-snippet visual relations, respectively, obtaining the Expression snippet Transformer (EST). In particular, for intra-snippet modeling, we devise an attention-augmented snippet feature extractor (AA-SFE) to enhance the encoding of subtle facial movements of each snippet by gradually attending to more salient information. In addition, for inter-snippet modeling, we introduce a shuffled snippet order prediction (SSOP) head and a corresponding loss to improve the modeling of subtle motion changes across subsequent snippets by training the Transformer to identify shuffled snippet orders. Extensive experiments on four challenging datasets (i.e., BU-3DFE, MMI, AFEW, and DFEW) demonstrate that our EST is superior to other CNN-based methods, obtaining state-of-the-art performance.
Your Face Mirrors Your Deepest Beliefs-Predicting Personality and Morals through Facial Emotion Recognition
Dec 23, 2021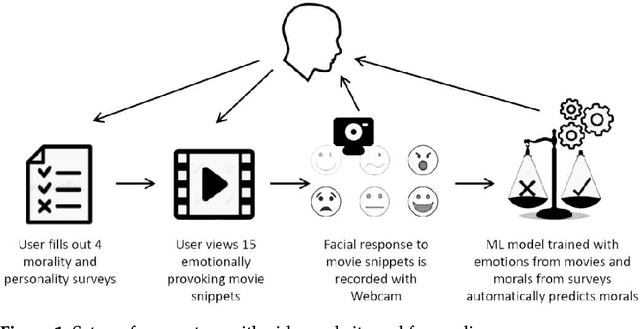
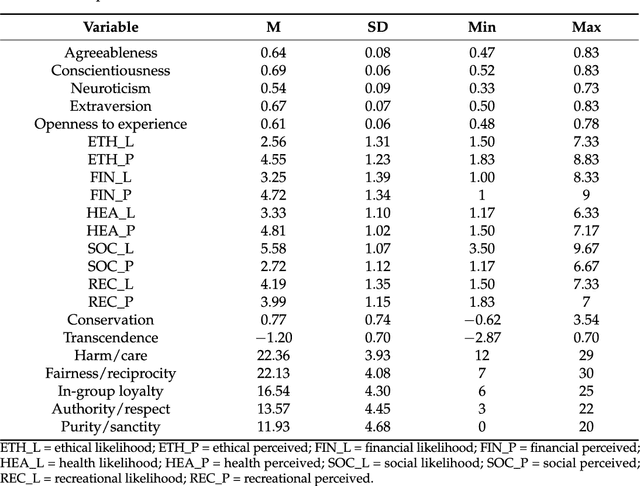
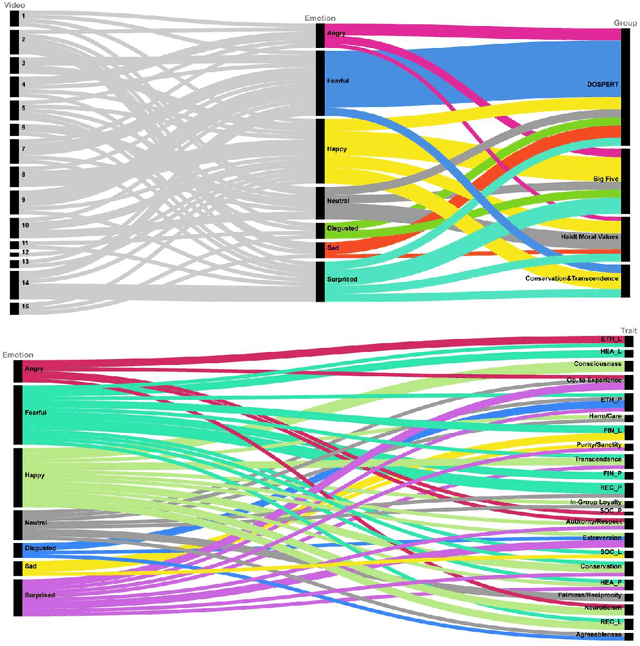
Can we really "read the mind in the eyes"? Moreover, can AI assist us in this task? This paper answers these two questions by introducing a machine learning system that predicts personality characteristics of individuals on the basis of their face. It does so by tracking the emotional response of the individual's face through facial emotion recognition (FER) while watching a series of 15 short videos of different genres. To calibrate the system, we invited 85 people to watch the videos, while their emotional responses were analyzed through their facial expression. At the same time, these individuals also took four well-validated surveys of personality characteristics and moral values: the revised NEO FFI personality inventory, the Haidt moral foundations test, the Schwartz personal value system, and the domain-specific risk-taking scale (DOSPERT). We found that personality characteristics and moral values of an individual can be predicted through their emotional response to the videos as shown in their face, with an accuracy of up to 86% using gradient-boosted trees. We also found that different personality characteristics are better predicted by different videos, in other words, there is no single video that will provide accurate predictions for all personality characteristics, but it is the response to the mix of different videos that allows for accurate prediction.
When Facial Expression Recognition Meets Few-Shot Learning: A Joint and Alternate Learning Framework
Jan 18, 2022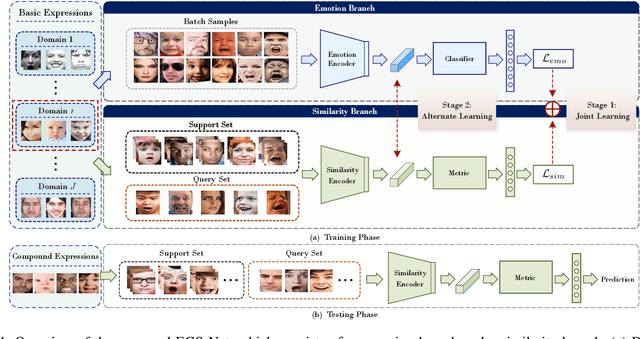
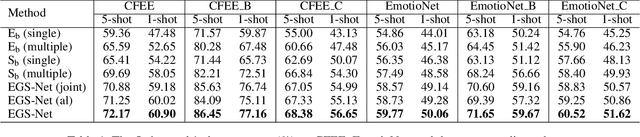
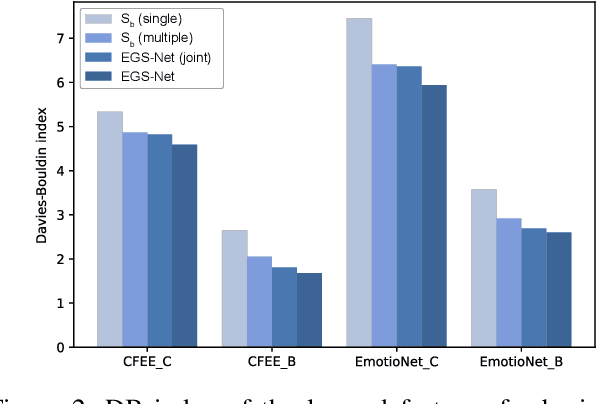
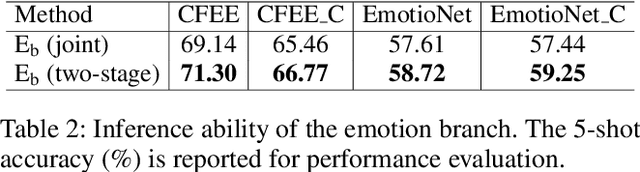
Human emotions involve basic and compound facial expressions. However, current research on facial expression recognition (FER) mainly focuses on basic expressions, and thus fails to address the diversity of human emotions in practical scenarios. Meanwhile, existing work on compound FER relies heavily on abundant labeled compound expression training data, which are often laboriously collected under the professional instruction of psychology. In this paper, we study compound FER in the cross-domain few-shot learning setting, where only a few images of novel classes from the target domain are required as a reference. In particular, we aim to identify unseen compound expressions with the model trained on easily accessible basic expression datasets. To alleviate the problem of limited base classes in our FER task, we propose a novel Emotion Guided Similarity Network (EGS-Net), consisting of an emotion branch and a similarity branch, based on a two-stage learning framework. Specifically, in the first stage, the similarity branch is jointly trained with the emotion branch in a multi-task fashion. With the regularization of the emotion branch, we prevent the similarity branch from overfitting to sampled base classes that are highly overlapped across different episodes. In the second stage, the emotion branch and the similarity branch play a "two-student game" to alternately learn from each other, thereby further improving the inference ability of the similarity branch on unseen compound expressions. Experimental results on both in-the-lab and in-the-wild compound expression datasets demonstrate the superiority of our proposed method against several state-of-the-art methods.
DeepFN: Towards Generalizable Facial Action Unit Recognition with Deep Face Normalization
Mar 03, 2021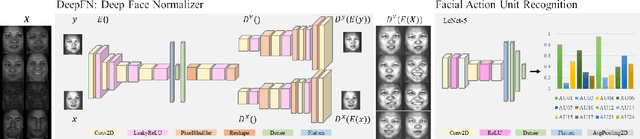
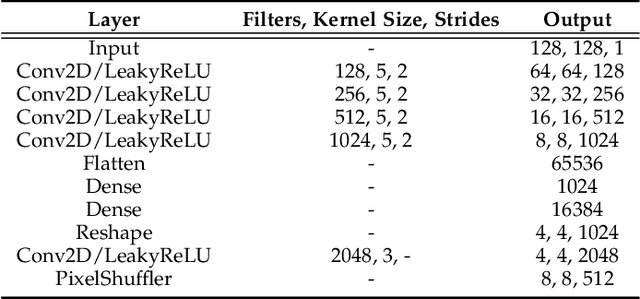
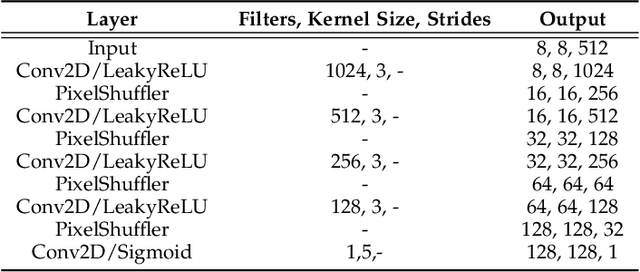
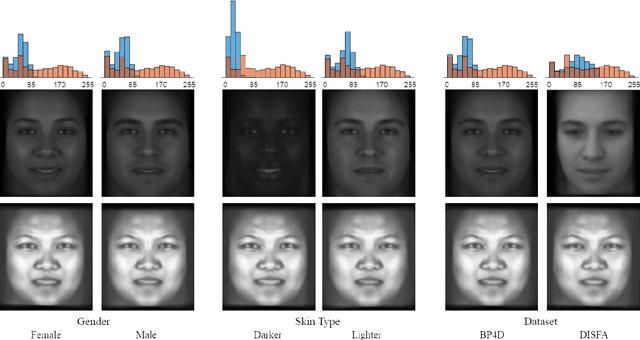
Facial action unit recognition has many applications from market research to psychotherapy and from image captioning to entertainment. Despite its recent progress, deployment of these models has been impeded due to their limited generalization to unseen people and demographics. This work conducts an in-depth analysis of performance across several dimensions: individuals(40 subjects), genders (male and female), skin types (darker and lighter), and databases (BP4D and DISFA). To help suppress the variance in data, we use the notion of self-supervised denoising autoencoders to design a method for deep face normalization(DeepFN) that transfers facial expressions of different people onto a common facial template which is then used to train and evaluate facial action recognition models. We show that person-independent models yield significantly lower performance (55% average F1 and accuracy across 40 subjects) than person-dependent models (60.3%), leading to a generalization gap of 5.3%. However, normalizing the data with the newly introduced DeepFN significantly increased the performance of person-independent models (59.6%), effectively reducing the gap. Similarly, we observed generalization gaps when considering gender (2.4%), skin type (5.3%), and dataset (9.4%), which were significantly reduced with the use of DeepFN. These findings represent an important step towards the creation of more generalizable facial action unit recognition systems.
Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition
Jun 07, 2021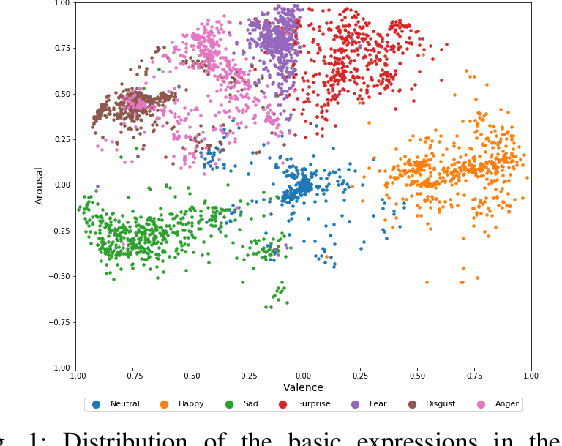
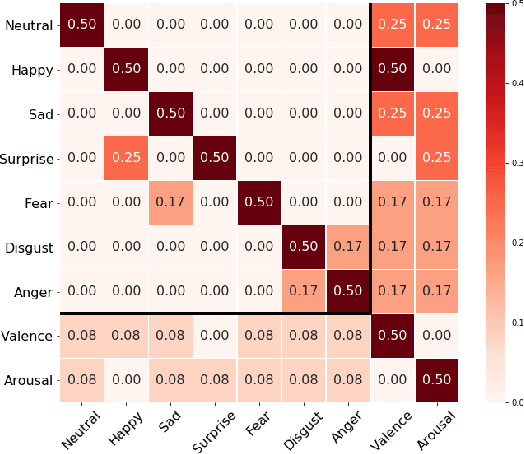
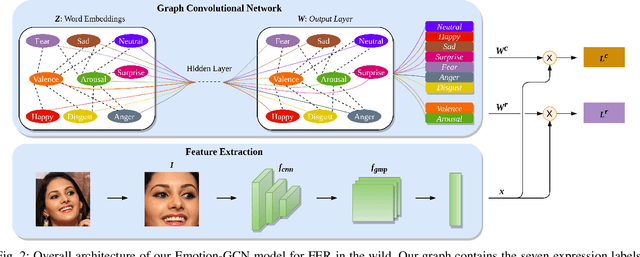
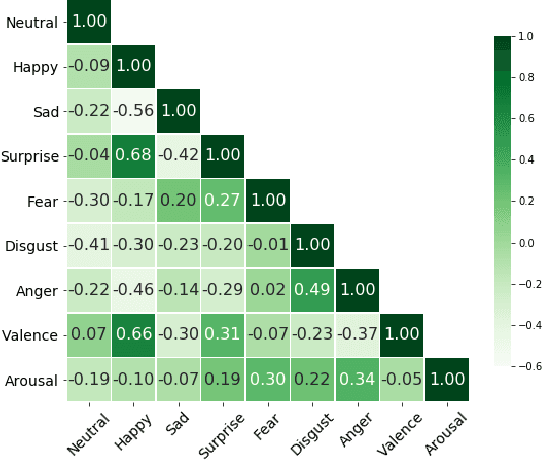
Over the past few years, deep learning methods have shown remarkable results in many face-related tasks including automatic facial expression recognition (FER) in-the-wild. Meanwhile, numerous models describing the human emotional states have been proposed by the psychology community. However, we have no clear evidence as to which representation is more appropriate and the majority of FER systems use either the categorical or the dimensional model of affect. Inspired by recent work in multi-label classification, this paper proposes a novel multi-task learning (MTL) framework that exploits the dependencies between these two models using a Graph Convolutional Network (GCN) to recognize facial expressions in-the-wild. Specifically, a shared feature representation is learned for both discrete and continuous recognition in a MTL setting. Moreover, the facial expression classifiers and the valence-arousal regressors are learned through a GCN that explicitly captures the dependencies between them. To evaluate the performance of our method under real-world conditions we train our models on AffectNet dataset. The results of our experiments show that our method outperforms the current state-of-the-art methods on discrete FER.
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022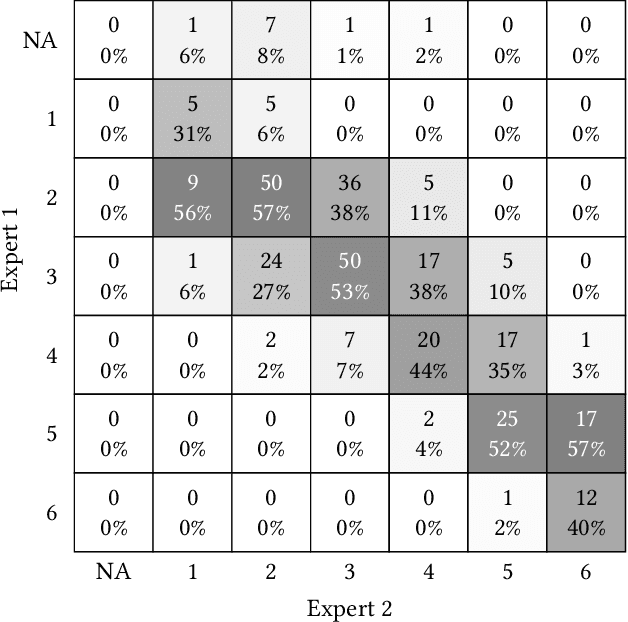
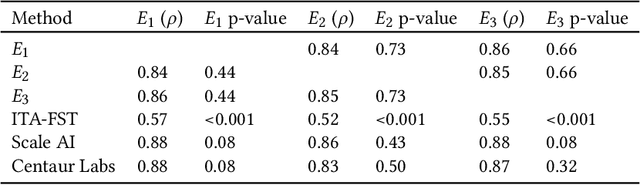
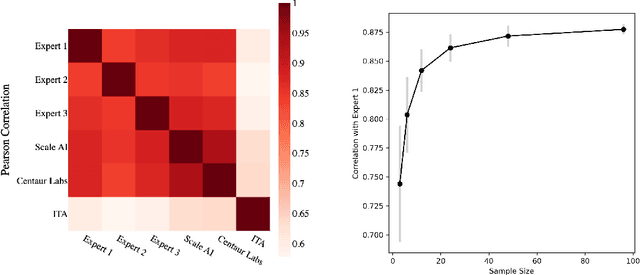
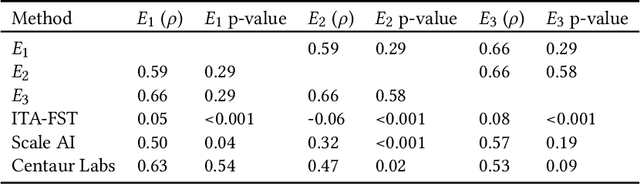
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.