 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Facial Expression Recognition Using Disentangled Adversarial Learning
Sep 28, 2019
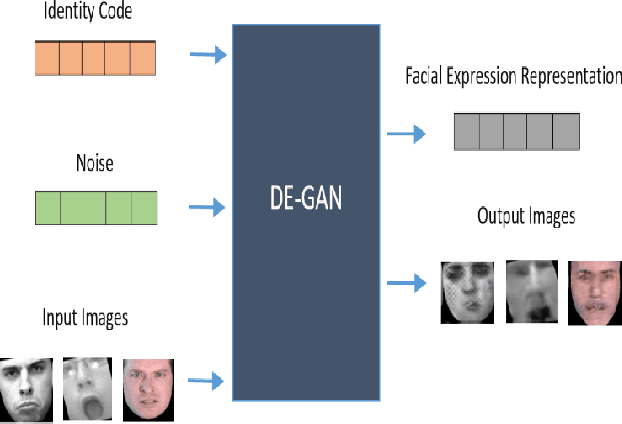
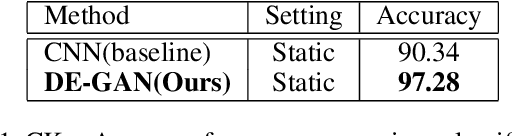
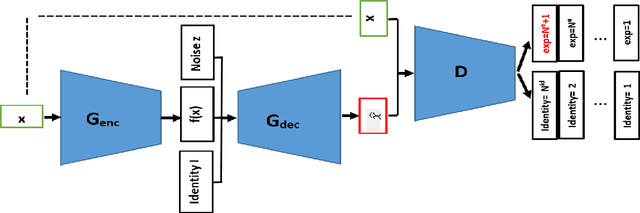
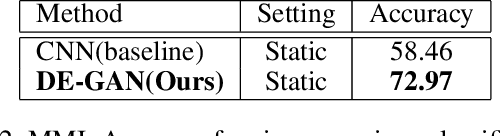
The representation used for Facial Expression Recognition (FER) usually contain expression information along with other variations such as identity and illumination. In this paper, we propose a novel Disentangled Expression learning-Generative Adversarial Network (DE-GAN) to explicitly disentangle facial expression representation from identity information. In this learning by reconstruction method, facial expression representation is learned by reconstructing an expression image employing an encoder-decoder based generator. This expression representation is disentangled from identity component by explicitly providing the identity code to the decoder part of DE-GAN. The process of expression image reconstruction and disentangled expression representation learning is improved by performing expression and identity classification in the discriminator of DE-GAN. The disentangled facial expression representation is then used for facial expression recognition employing simple classifiers like SVM or MLP. The experiments are performed on publicly available and widely used face expression databases (CK+, MMI, Oulu-CASIA). The experimental results show that the proposed technique produces comparable results with state-of-the-art methods.
Searching for the Essence of Adversarial Perturbations
May 30, 2022


Neural networks have achieved the state-of-the-art performance on various machine learning fields, yet the incorporation of malicious perturbations with input data (adversarial example) is able to fool neural networks' predictions. This would lead to potential risks in real-world applications, for example, auto piloting and facial recognition. However, the reason for the existence of adversarial examples remains controversial. Here we demonstrate that adversarial perturbations contain human-recognizable information, which is the key conspirator responsible for a neural network's erroneous prediction. This concept of human-recognizable information allows us to explain key features related to adversarial perturbations, which include the existence of adversarial examples, the transferability among different neural networks, and the increased neural network interpretability for adversarial training. Two unique properties in adversarial perturbations that fool neural networks are uncovered: masking and generation. A special class, the complementary class, is identified when neural networks classify input images. The human-recognizable information contained in adversarial perturbations allows researchers to gain insight on the working principles of neural networks and may lead to develop techniques that detect/defense adversarial attacks.
Facial Expression Recognition with Deep Learning
Apr 08, 2020
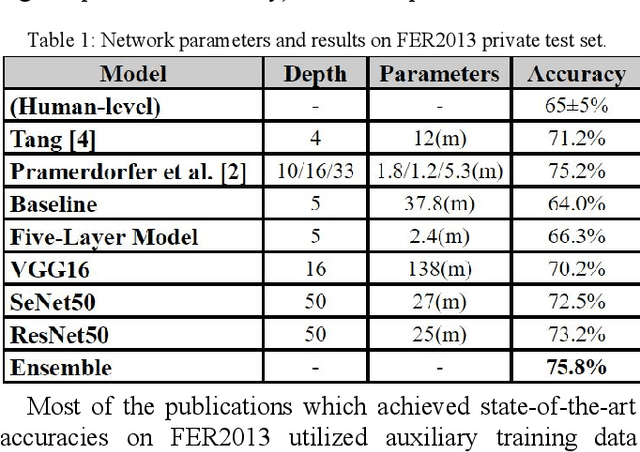

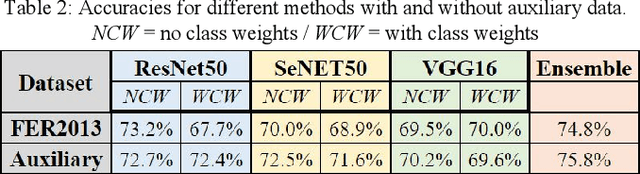
One of the most universal ways that people communicate is through facial expressions. In this paper, we take a deep dive, implementing multiple deep learning models for facial expression recognition (FER). Our goals are twofold: we aim not only to maximize accuracy, but also to apply our results to the real-world. By leveraging numerous techniques from recent research, we demonstrate a state-of-the-art 75.8% accuracy on the FER2013 test set, outperforming all existing publications. Additionally, we showcase a mobile web app which runs our FER models on-device in real time.
Fine-tuning of sign language recognition models: a technical report
Feb 16, 2023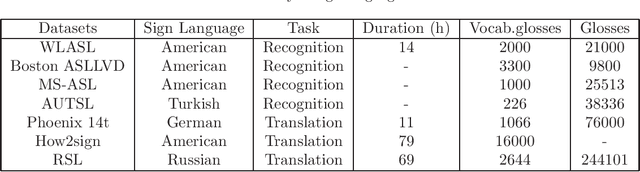
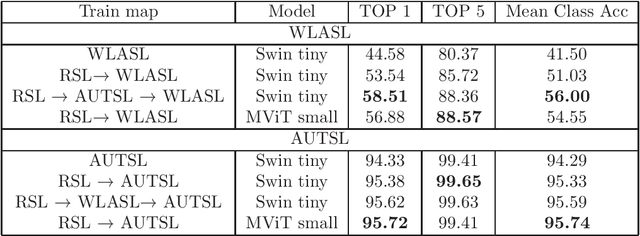
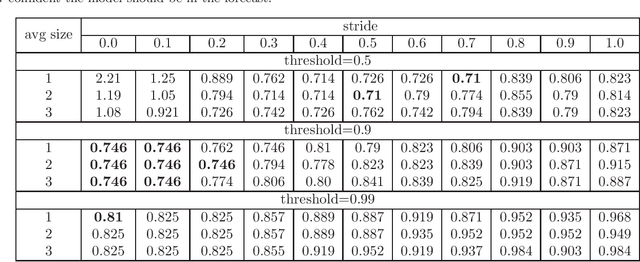
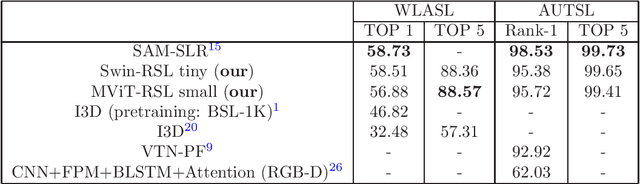
Sign Language Recognition (SLR) is an essential yet challenging task since sign language is performed with the fast and complex movement of hand gestures, body posture, and even facial expressions. %Skeleton Aware Multi-modal Sign Language Recognition In this work, we focused on investigating two questions: how fine-tuning on datasets from other sign languages helps improve sign recognition quality, and whether sign recognition is possible in real-time without using GPU. Three different languages datasets (American sign language WLASL, Turkish - AUTSL, Russian - RSL) have been used to validate the models. The average speed of this system has reached 3 predictions per second, which meets the requirements for the real-time scenario. This model (prototype) will benefit speech or hearing impaired people talk with other trough internet. We also investigated how the additional training of the model in another sign language affects the quality of recognition. The results show that further training of the model on the data of another sign language almost always leads to an improvement in the quality of gesture recognition. We also provide code for reproducing model training experiments, converting models to ONNX format, and inference for real-time gesture recognition.
Facial Emotion Recognition: State of the Art Performance on FER2013
May 08, 2021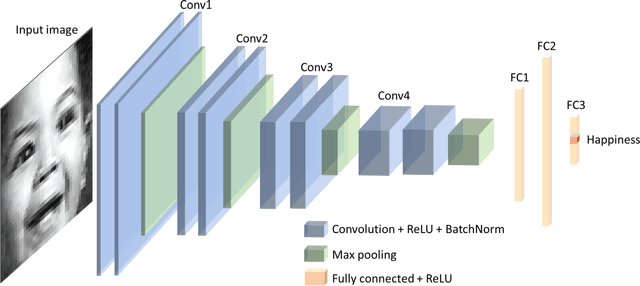
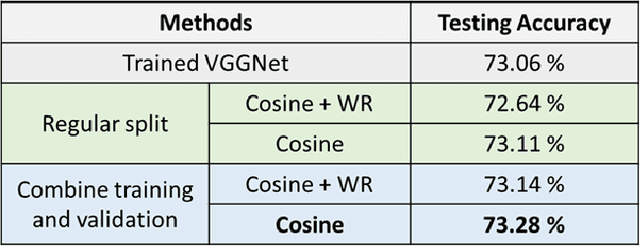
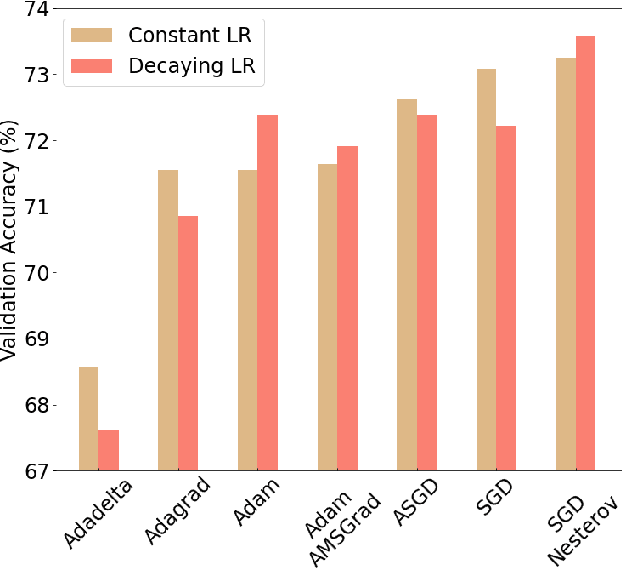
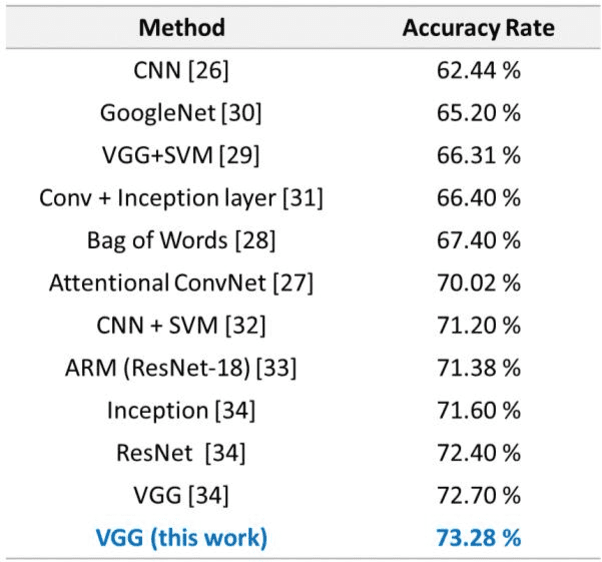
Facial emotion recognition (FER) is significant for human-computer interaction such as clinical practice and behavioral description. Accurate and robust FER by computer models remains challenging due to the heterogeneity of human faces and variations in images such as different facial pose and lighting. Among all techniques for FER, deep learning models, especially Convolutional Neural Networks (CNNs) have shown great potential due to their powerful automatic feature extraction and computational efficiency. In this work, we achieve the highest single-network classification accuracy on the FER2013 dataset. We adopt the VGGNet architecture, rigorously fine-tune its hyperparameters, and experiment with various optimization methods. To our best knowledge, our model achieves state-of-the-art single-network accuracy of 73.28 % on FER2013 without using extra training data.
Micro-Facial Expression Recognition Based on Deep-Rooted Learning Algorithm
Sep 12, 2020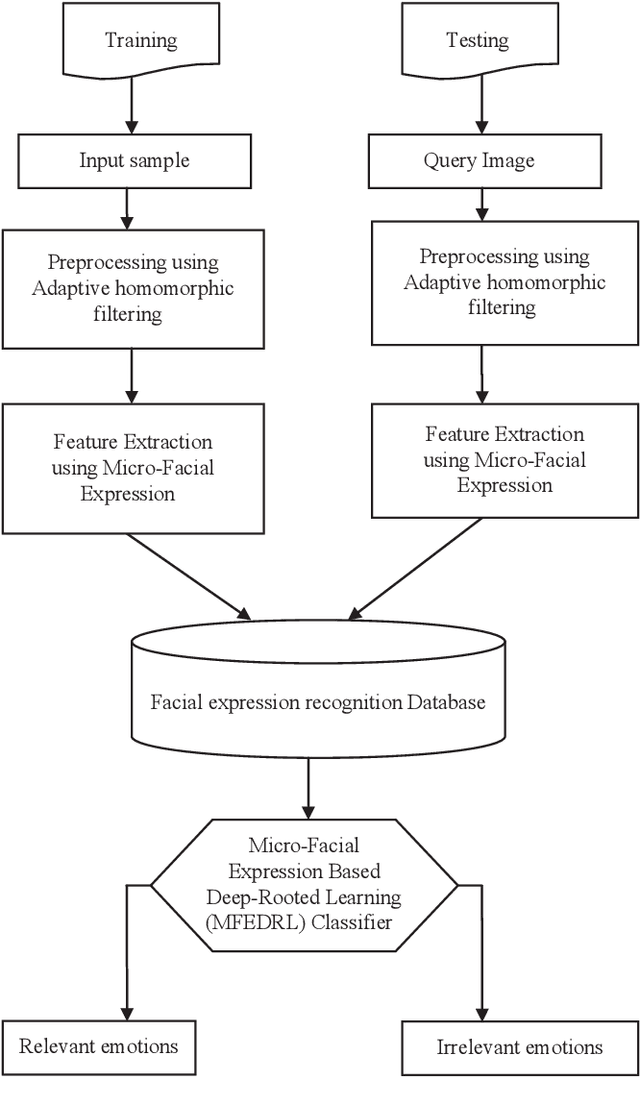


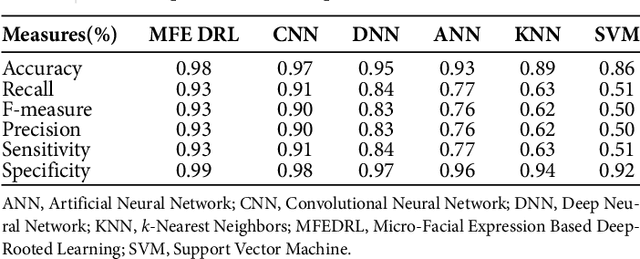
Facial expressions are important cues to observe human emotions. Facial expression recognition has attracted many researchers for years, but it is still a challenging topic since expression features vary greatly with the head poses, environments, and variations in the different persons involved. In this work, three major steps are involved to improve the performance of micro-facial expression recognition. First, an Adaptive Homomorphic Filtering is used for face detection and rotation rectification processes. Secondly, Micro-facial features were used to extract the appearance variations of a testing image-spatial analysis. The features of motion information are used for expression recognition in a sequence of facial images. An effective Micro-Facial Expression Based Deep-Rooted Learning (MFEDRL) classifier is proposed in this paper to better recognize spontaneous micro-expressions by learning parameters on the optimal features. This proposed method includes two loss functions such as cross entropy loss function and centre loss function. Then the performance of the algorithm will be evaluated using recognition rate and false measures. Simulation results show that the predictive performance of the proposed method outperforms that of the existing classifiers such as Convolutional Neural Network (CNN), Deep Neural Network (DNN), Artificial Neural Network (ANN), Support Vector Machine (SVM), and k-Nearest Neighbours (KNN) in terms of accuracy and Mean Absolute Error (MAE).
* 20 pages, 7 figures, "for the published version of the article, see https://www.atlantis-press.com/journals/ijcis/125915627"
Equalization and Brightness Mapping Modes of Color-to-Gray Projection Operators
Aug 21, 2022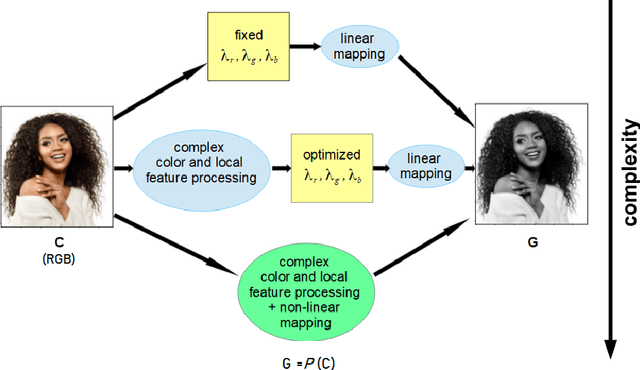

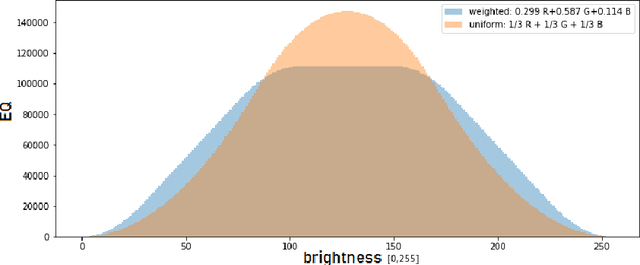
In this article, the conversion of color RGB images to grayscale is covered by characterizing the mathematical operators used to project 3 color channels to a single one. Based on the fact that most operators assign each of the $256^3$ colors a single gray level, ranging from 0 to 255, they are clustering algorithms that distribute the color population into 256 clusters of increasing brightness. To visualize the way operators work the sizes of the clusters and the average brightness of each cluster are plotted. The equalization mode (EQ) introduced in this work focuses on cluster sizes, while the brightness mapping (BM) mode describes the CIE L* luminance distribution per cluster. Three classes of EQ modes and two classes of BM modes were found in linear operators, defining a 6-class taxonomy. The theoretical/methodological framework introduced was applied in a case study considering the equal-weights uniform operator, the NTSC standard operator, and an operator chosen as ideal to lighten the faces of black people to improve facial recognition in current biased classifiers. It was found that most current metrics used to assess the quality of color-to-gray conversions better assess one of the two BM mode classes, but the ideal operator chosen by a human team belongs to the other class. Therefore, this cautions against using these general metrics for specific purpose color-to-gray conversions. It should be noted that eventual applications of this framework to non-linear operators can give rise to new classes of EQ and BM modes. The main contribution of this article is to provide a tool to better understand color to gray converters in general, even those based on machine learning, within the current trend of better explainability of models.
Spatial and Temporal Networks for Facial Expression Recognition in the Wild Videos
Jul 12, 2021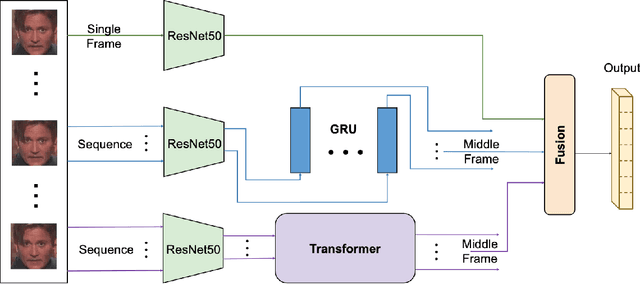
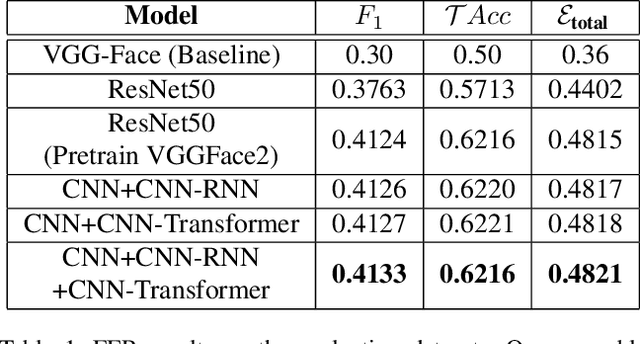
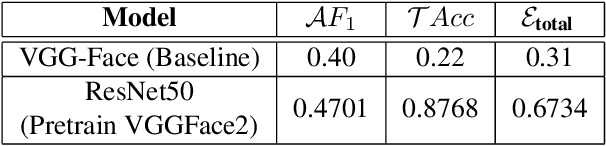
The paper describes our proposed methodology for the seven basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2021. In this task, facial expression recognition (FER) methods aim to classify the correct expression category from a diverse background, but there are several challenges. First, to adapt the model to in-the-wild scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose an ensemble model with a convolution neural network (CNN), a CNN-recurrent neural network (CNN-RNN), and a CNN-Transformer (CNN-Transformer), to incorporate both spatial and temporal information. Our ensemble model achieved F1 as 0.4133, accuracy as 0.6216 and final metric as 0.4821 on the validation set.
A Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021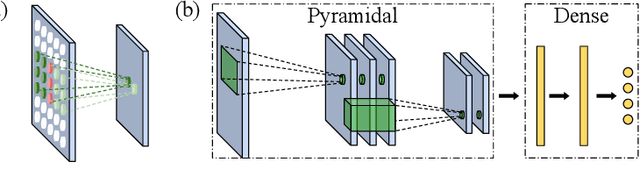

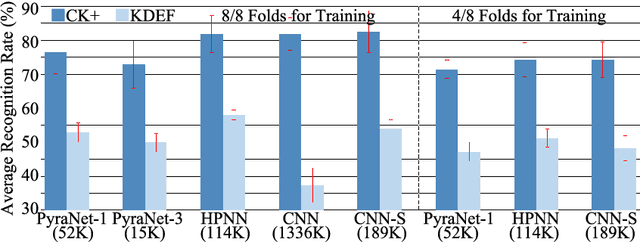

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
Human Emotional Facial Expression Recognition
Mar 28, 2018
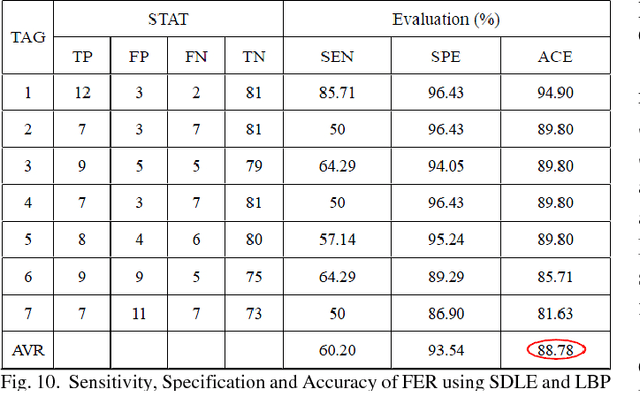
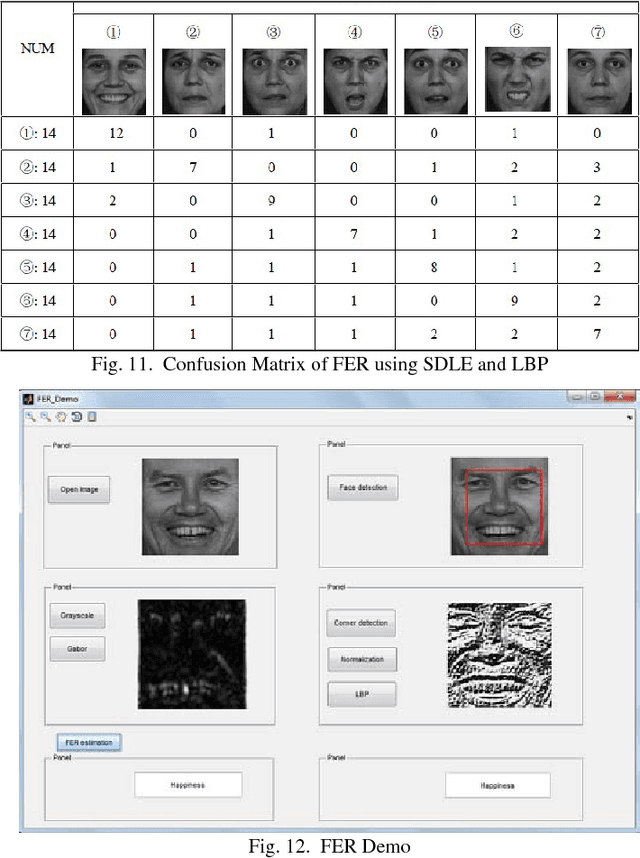

An automatic Facial Expression Recognition (FER) model with Adaboost face detector, feature selection based on manifold learning and synergetic prototype based classifier has been proposed. Improved feature selection method and proposed classifier can achieve favorable effectiveness to performance FER in reasonable processing time.