 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Fuzzy and entropy facial recognition
Aug 24, 2014
This paper suggests an effective method for facial recognition using fuzzy theory and Shannon entropy. Combination of fuzzy theory and Shannon entropy eliminates the complication of other methods. Shannon entropy calculates the ratio of an element between faces, and fuzzy theory calculates the member ship of the entropy with 1. More details will be mentioned in Section 3. The learning performance is better than others as it is very simple, and only need two data per learning. By using factors that don't usually change during the life, the method will have a high accuracy.
Localization using Multi-Focal Spatial Attention for Masked Face Recognition
May 03, 2023
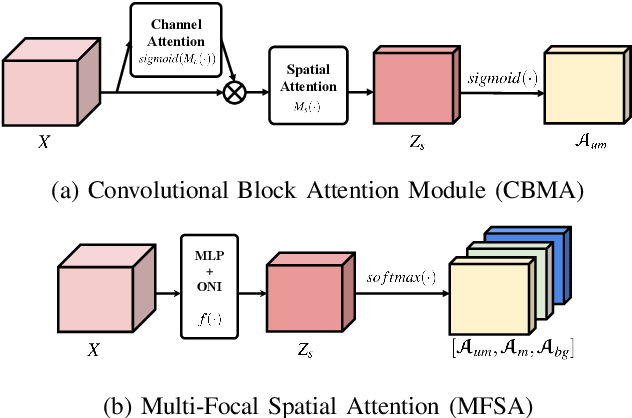
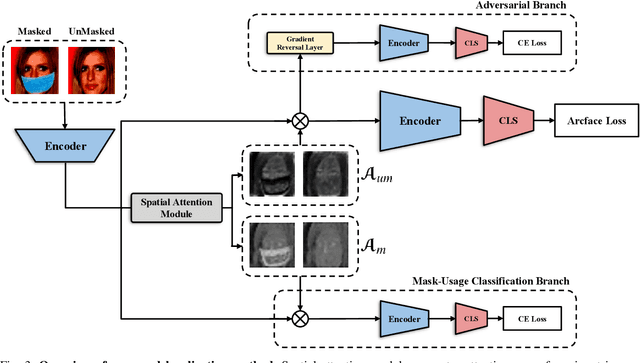
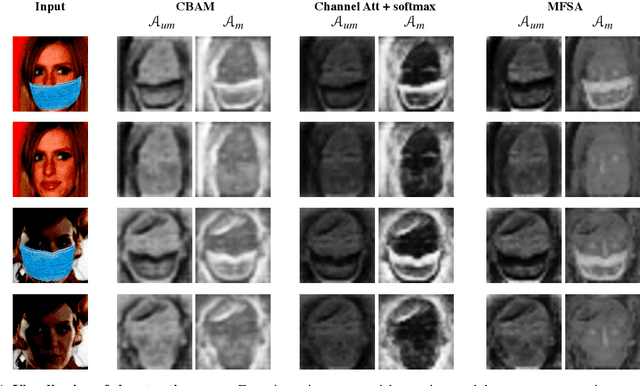
Since the beginning of world-wide COVID-19 pandemic, facial masks have been recommended to limit the spread of the disease. However, these masks hide certain facial attributes. Hence, it has become difficult for existing face recognition systems to perform identity verification on masked faces. In this context, it is necessary to develop masked Face Recognition (MFR) for contactless biometric recognition systems. Thus, in this paper, we propose Complementary Attention Learning and Multi-Focal Spatial Attention that precisely removes masked region by training complementary spatial attention to focus on two distinct regions: masked regions and backgrounds. In our method, standard spatial attention and networks focus on unmasked regions, and extract mask-invariant features while minimizing the loss of the conventional Face Recognition (FR) performance. For conventional FR, we evaluate the performance on the IJB-C, Age-DB, CALFW, and CPLFW datasets. We evaluate the MFR performance on the ICCV2021-MFR/Insightface track, and demonstrate the improved performance on the both MFR and FR datasets. Additionally, we empirically verify that spatial attention of proposed method is more precisely activated in unmasked regions.
Adaptive Local-Global Relational Network for Facial Action Units Recognition and Facial Paralysis Estimation
Mar 03, 2022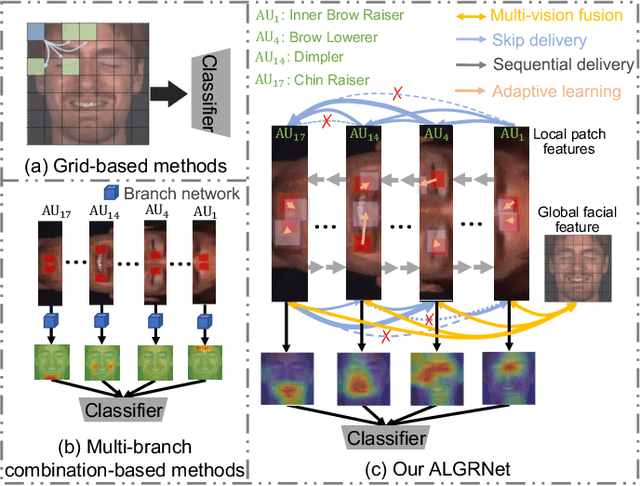
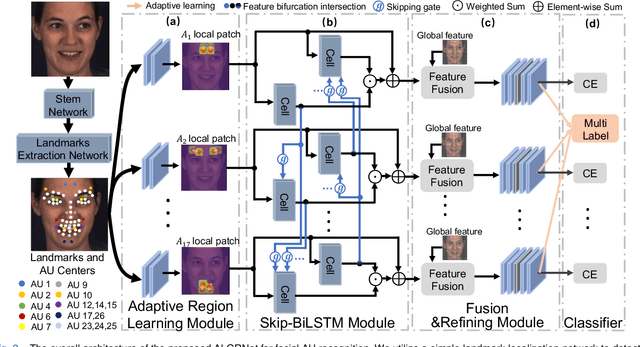
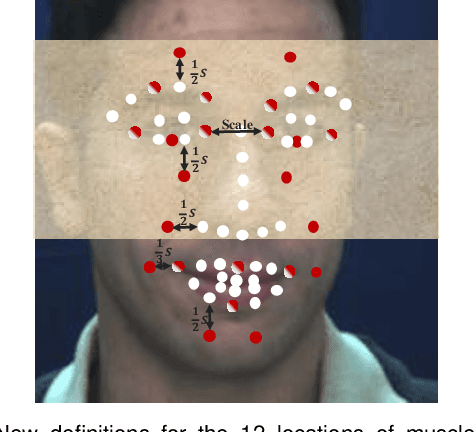
Facial action units (AUs) refer to a unique set of facial muscle movements at certain facial locations defined by the Facial Action Coding System (FACS), which can be used for describing nearly any anatomically possible facial expression. Many existing facial action units (AUs) recognition approaches often enhance the AU representation by combining local features from multiple independent branches, each corresponding to a different AU, which usually neglect potential mutual assistance and exclusion relationship between AU branches or simply employ a pre-defined and fixed knowledge-graph as a prior. In addition, extracting features from pre-defined AU regions of regular shapes limits the representation ability. In this paper, we propose a novel Adaptive Local-Global Relational Network (ALGRNet) for facial AU recognition and apply it to facial paralysis estimation. ALGRNet mainly consists of three novel structures, i.e., an adaptive region learning module which learns the adaptive muscle regions based on the detected landmarks, a skip-BiLSTM module which models the latent mutual assistance and exclusion relationship among local AU features, and a feature fusion\&refining module which explores the complementarity between local AUs and the whole face for the local AU refinement. In order to evaluate our proposed method, we migrated ALGRNet to a facial paralysis dataset which is collected and annotated by medical professionals. Experiments on the BP4D and DISFA AU datasets show that the proposed approach outperforms the state-of-the-art methods by a large margin. Additionally, we also demonstrated the effectiveness of the proposed ALGRNet in applications to facial paralysis estimation.
Spatio-Temporal Transformer for Dynamic Facial Expression Recognition in the Wild
May 10, 2022
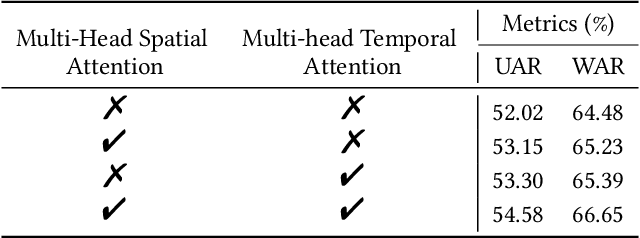
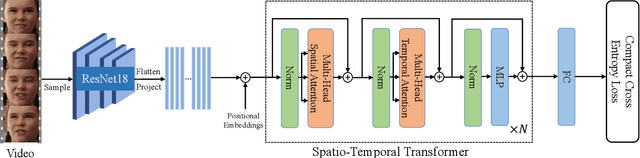
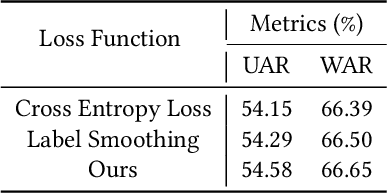
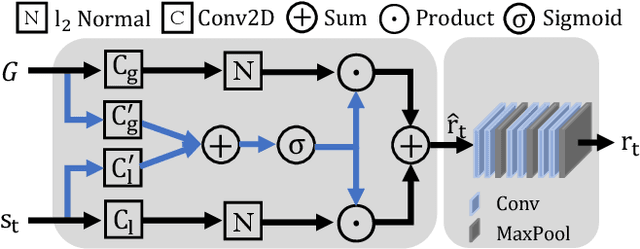
Previous methods for dynamic facial expression in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. To solve this problem, we propose the spatio-temporal Transformer (STT) to capture discriminative features within each frame and model contextual relationships among frames. Spatio-temporal dependencies are captured and integrated by our unified Transformer. Specifically, given an image sequence consisting of multiple frames as input, we utilize the CNN backbone to translate each frame into a visual feature sequence. Subsequently, the spatial attention and the temporal attention within each block are jointly applied for learning spatio-temporal representations at the sequence level. In addition, we propose the compact softmax cross entropy loss to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and AFEW) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for dynamic facial expression recognition. The source code and the training logs will be made publicly available.
The Effect of Model Compression on Fairness in Facial Expression Recognition
Jan 05, 2022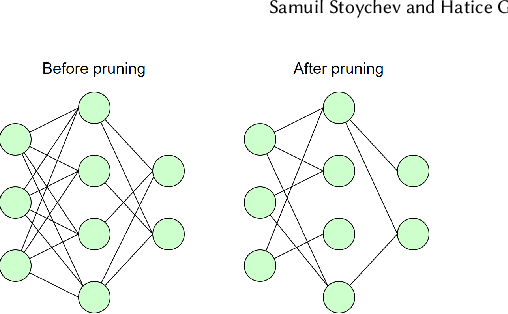

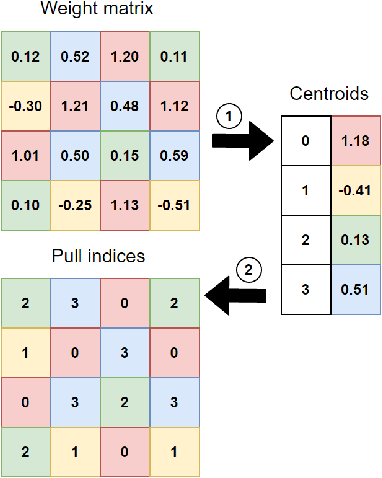

Deep neural networks have proved hugely successful, achieving human-like performance on a variety of tasks. However, they are also computationally expensive, which has motivated the development of model compression techniques which reduce the resource consumption associated with deep learning models. Nevertheless, recent studies have suggested that model compression can have an adverse effect on algorithmic fairness, amplifying existing biases in machine learning models. With this project we aim to extend those studies to the context of facial expression recognition. To do that, we set up a neural network classifier to perform facial expression recognition and implement several model compression techniques on top of it. We then run experiments on two facial expression datasets, namely the Extended Cohn-Kanade Dataset (CK+DB) and the Real-World Affective Faces Database (RAF-DB), to examine the individual and combined effect that compression techniques have on the model size, accuracy and fairness. Our experimental results show that: (i) Compression and quantisation achieve significant reduction in model size with minimal impact on overall accuracy for both CK+DB and RAF-DB; (ii) in terms of model accuracy, the classifier trained and tested on RAF-DB seems more robust to compression compared to the CK+ DB; (iii) for RAF-DB, the different compression strategies do not seem to increase the gap in predictive performance across the sensitive attributes of gender, race and age which is in contrast with the results on the CK+DB, where compression seems to amplify existing biases for gender. We analyse the results and discuss the potential reasons for our findings.
Vision Transformer Equipped with Neural Resizer on Facial Expression Recognition Task
Apr 05, 2022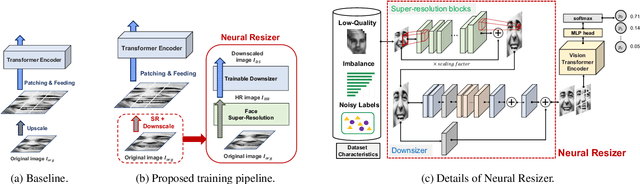
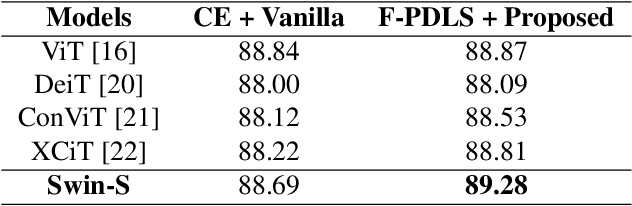
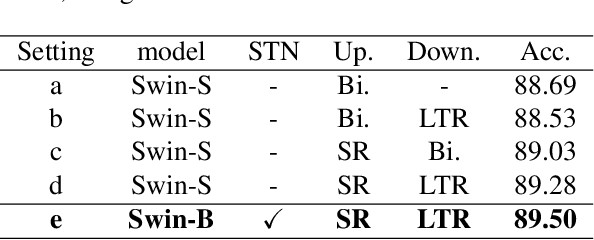

When it comes to wild conditions, Facial Expression Recognition is often challenged with low-quality data and imbalanced, ambiguous labels. This field has much benefited from CNN based approaches; however, CNN models have structural limitation to see the facial regions in distant. As a remedy, Transformer has been introduced to vision fields with global receptive field, but requires adjusting input spatial size to the pretrained models to enjoy their strong inductive bias at hands. We herein raise a question whether using the deterministic interpolation method is enough to feed low-resolution data to Transformer. In this work, we propose a novel training framework, Neural Resizer, to support Transformer by compensating information and downscaling in a data-driven manner trained with loss function balancing the noisiness and imbalance. Experiments show our Neural Resizer with F-PDLS loss function improves the performance with Transformer variants in general and nearly achieves the state-of-the-art performance.
Improving Facial Attribute Recognition by Group and Graph Learning
May 28, 2021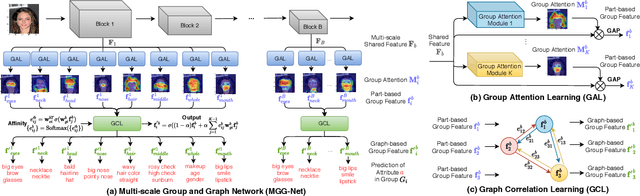
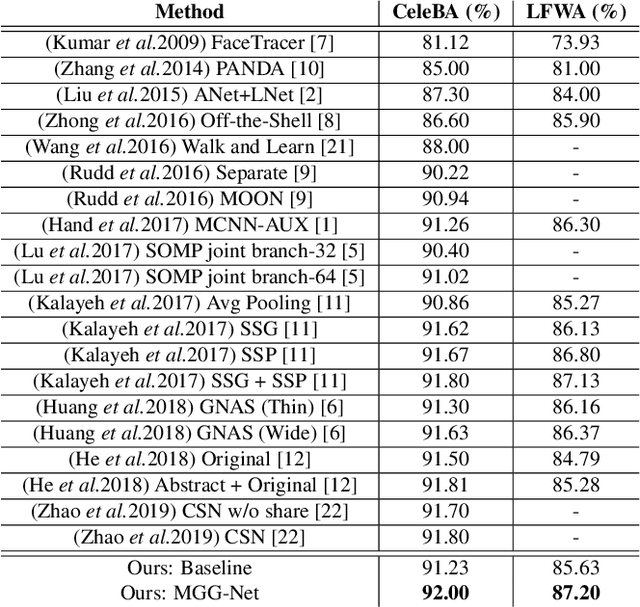
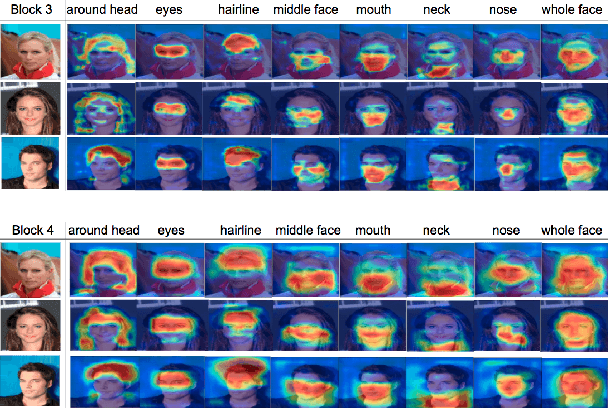
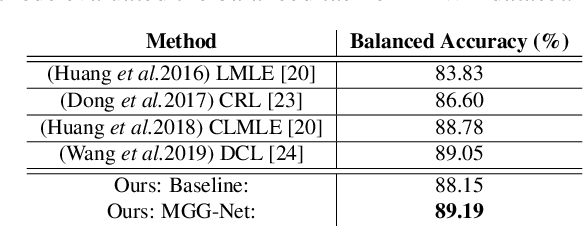
Exploiting the relationships between attributes is a key challenge for improving multiple facial attribute recognition. In this work, we are concerned with two types of correlations that are spatial and non-spatial relationships. For the spatial correlation, we aggregate attributes with spatial similarity into a part-based group and then introduce a Group Attention Learning to generate the group attention and the part-based group feature. On the other hand, to discover the non-spatial relationship, we model a group-based Graph Correlation Learning to explore affinities of predefined part-based groups. We utilize such affinity information to control the communication between all groups and then refine the learned group features. Overall, we propose a unified network called Multi-scale Group and Graph Network. It incorporates these two newly proposed learning strategies and produces coarse-to-fine graph-based group features for improving facial attribute recognition. Comprehensive experiments demonstrate that our approach outperforms the state-of-the-art methods.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022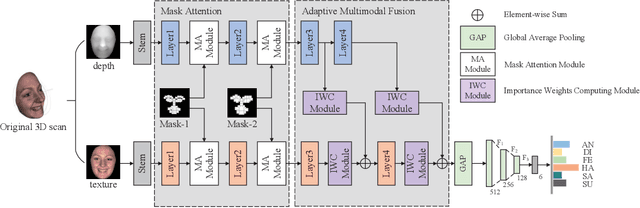
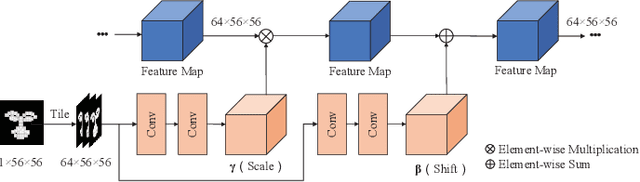
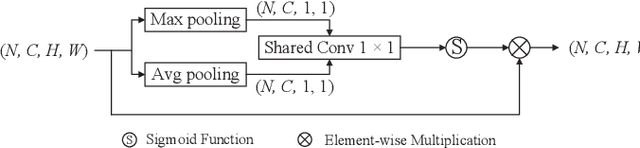
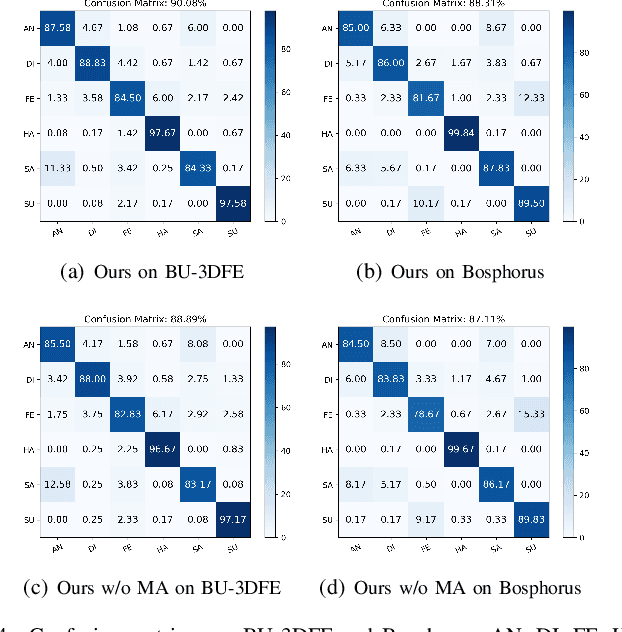
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
Mathematical Justification of Hard Negative Mining via Isometric Approximation Theorem
Oct 20, 2022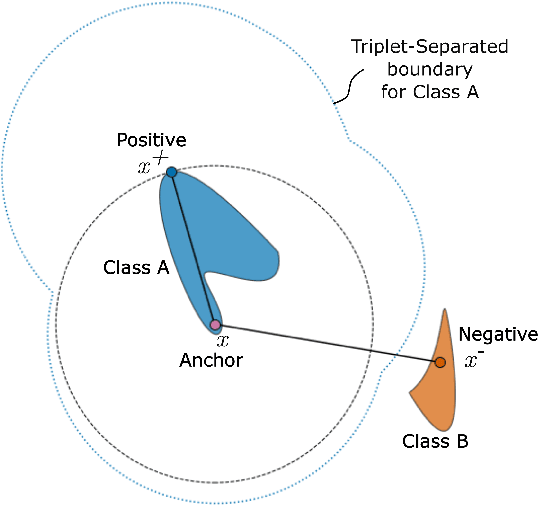
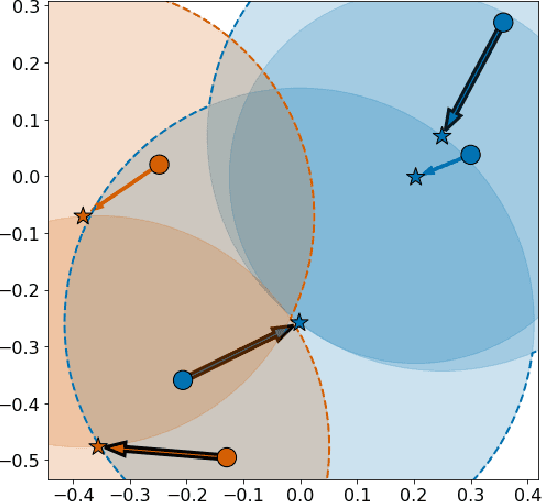
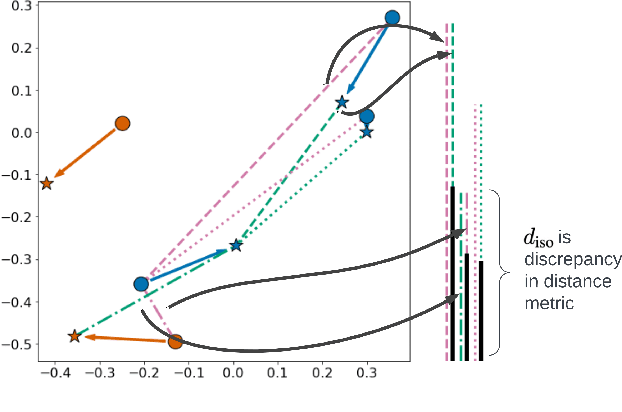
In deep metric learning, the Triplet Loss has emerged as a popular method to learn many computer vision and natural language processing tasks such as facial recognition, object detection, and visual-semantic embeddings. One issue that plagues the Triplet Loss is network collapse, an undesirable phenomenon where the network projects the embeddings of all data onto a single point. Researchers predominately solve this problem by using triplet mining strategies. While hard negative mining is the most effective of these strategies, existing formulations lack strong theoretical justification for their empirical success. In this paper, we utilize the mathematical theory of isometric approximation to show an equivalence between the Triplet Loss sampled by hard negative mining and an optimization problem that minimizes a Hausdorff-like distance between the neural network and its ideal counterpart function. This provides the theoretical justifications for hard negative mining's empirical efficacy. In addition, our novel application of the isometric approximation theorem provides the groundwork for future forms of hard negative mining that avoid network collapse. Our theory can also be extended to analyze other Euclidean space-based metric learning methods like Ladder Loss or Contrastive Learning.
Facial Expression Recognition Using Human to Animated-Character Expression Translation
Oct 12, 2019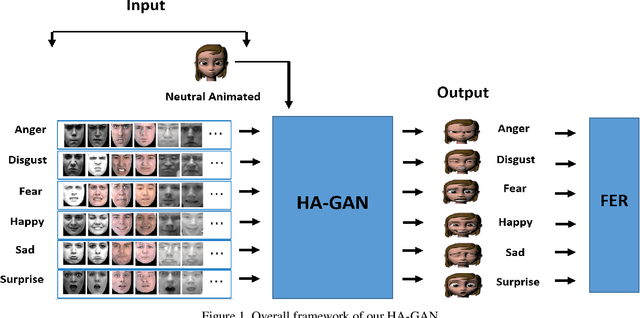
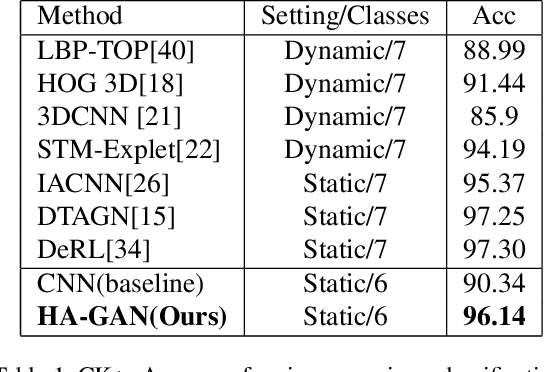
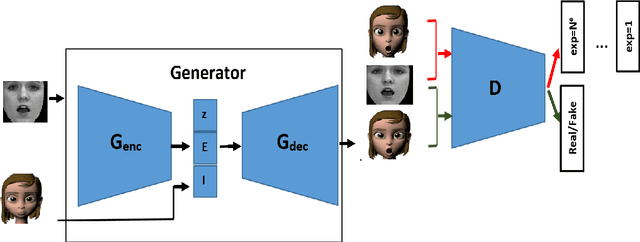
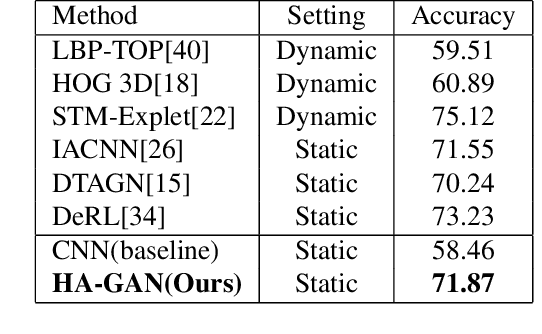
Facial expression recognition is a challenging task due to two major problems: the presence of inter-subject variations in facial expression recognition dataset and impure expressions posed by human subjects. In this paper we present a novel Human-to-Animation conditional Generative Adversarial Network (HA-GAN) to overcome these two problems by using many (human faces) to one (animated face) mapping. Specifically, for any given input human expression image, our HA-GAN transfers the expression information from the input image to a fixed animated identity. Stylized animated characters from the Facial Expression Research Group-Database (FERGDB) are used for the generation of fixed identity. By learning this many-to-one identity mapping function using our proposed HA-GAN, the effect of inter-subject variations can be reduced in Facial Expression Recognition(FER). We also argue that the expressions in the generated animated images are pure expressions and since FER is performed on these generated images, the performance of facial expression recognition is improved. Our initial experimental results on the state-of-the-art datasets show that facial expression recognition carried out on the generated animated images using our HA-GAN framework outperforms the baseline deep neural network and produces comparable or even better results than the state-of-the-art methods for facial expression recognition.