 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Cross-Centroid Ripple Pattern for Facial Expression Recognition
Jan 16, 2022
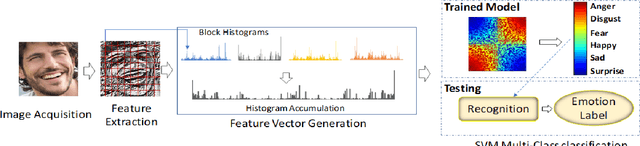
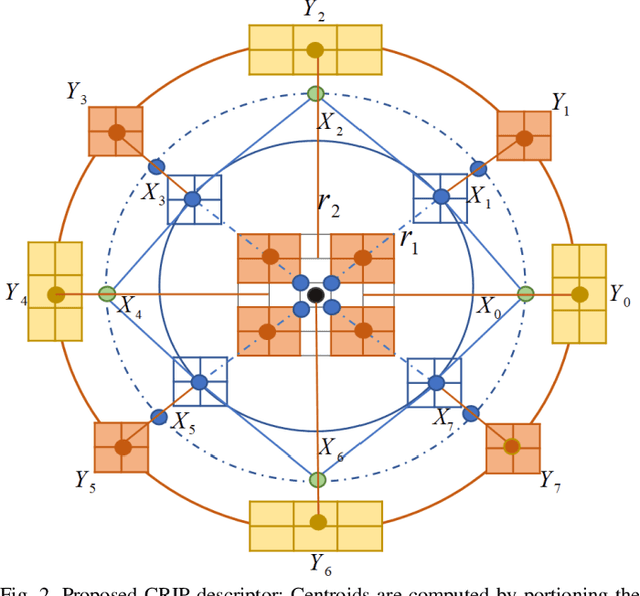


In this paper, we propose a new feature descriptor Cross-Centroid Ripple Pattern (CRIP) for facial expression recognition. CRIP encodes the transitional pattern of a facial expression by incorporating cross-centroid relationship between two ripples located at radius r1 and r2 respectively. These ripples are generated by dividing the local neighborhood region into subregions. Thus, CRIP has ability to preserve macro and micro structural variations in an extensive region, which enables it to deal with side views and spontaneous expressions. Furthermore, gradient information between cross centroid ripples provides strenght to captures prominent edge features in active patches: eyes, nose and mouth, that define the disparities between different facial expressions. Cross centroid information also provides robustness to irregular illumination. Moreover, CRIP utilizes the averaging behavior of pixels at subregions that yields robustness to deal with noisy conditions. The performance of proposed descriptor is evaluated on seven comprehensive expression datasets consisting of challenging conditions such as age, pose, ethnicity and illumination variations. The experimental results show that our descriptor consistently achieved better accuracy rate as compared to existing state-of-art approaches.
POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition
Apr 08, 2022
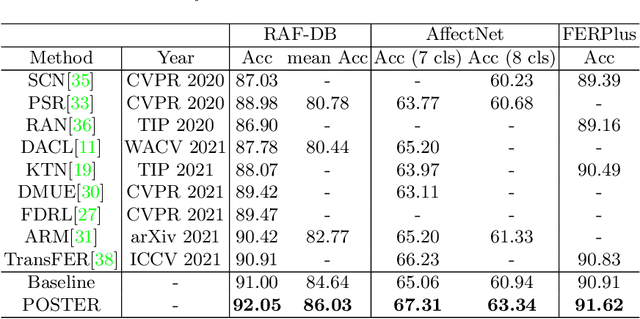
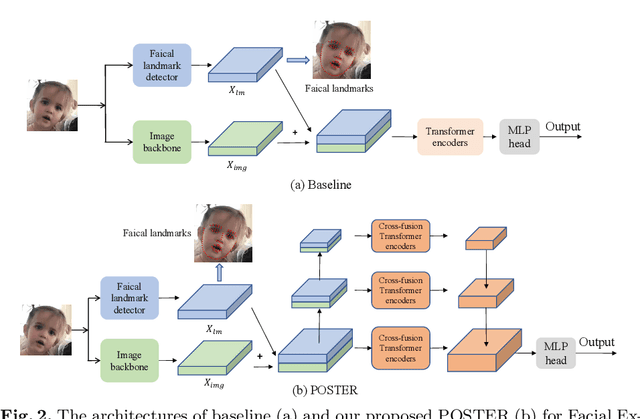
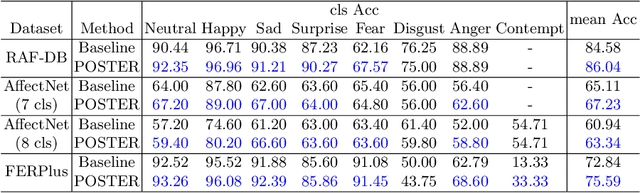
Facial Expression Recognition (FER) has received increasing interest in the computer vision community. As a challenging task, there are three key issues especially prevalent in FER: inter-class similarity, intra-class discrepancy, and scale sensitivity. Existing methods typically address some of these issues, but do not tackle them all in a unified framework. Therefore, in this paper, we propose a two-stream Pyramid crOss-fuSion TransformER network (POSTER) that aims to holistically solve these issues. Specifically, we design a transformer-based cross-fusion paradigm that enables effective collaboration of facial landmark and direct image features to maximize proper attention to salient facial regions. Furthermore, POSTER employs a pyramid structure to promote scale invariance. Extensive experimental results demonstrate that our POSTER outperforms SOTA methods on RAF-DB with 92.05%, FERPlus with 91.62%, AffectNet (7 cls) with 67.31%, and AffectNet (8 cls) with 63.34%, respectively.
A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
May 05, 2023In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists in learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamical and modality-specific versus modality-common information occurs during this second training stage. Extensive experiments are conducted to investigate how audiovisual speech latent factors are encoded in the latent space of MDVAE. These experiments include manipulating audiovisual speech, audiovisual facial image denoising, and audiovisual speech emotion recognition. The results show that MDVAE effectively combines the audio and visual information in its latent space. They also show that the learned static representation of audiovisual speech can be used for emotion recognition with few labeled data, and with better accuracy compared with unimodal baselines and a state-of-the-art supervised model based on an audiovisual transformer architecture.
MixAugment & Mixup: Augmentation Methods for Facial Expression Recognition
May 09, 2022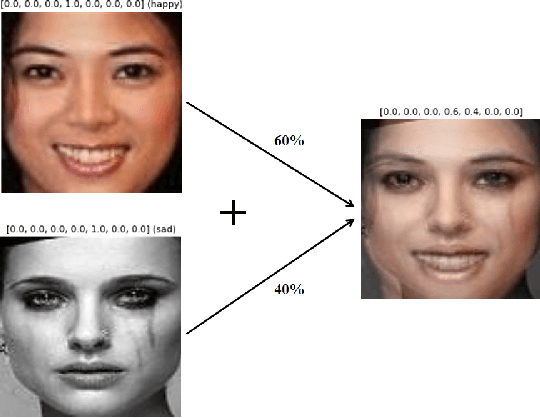
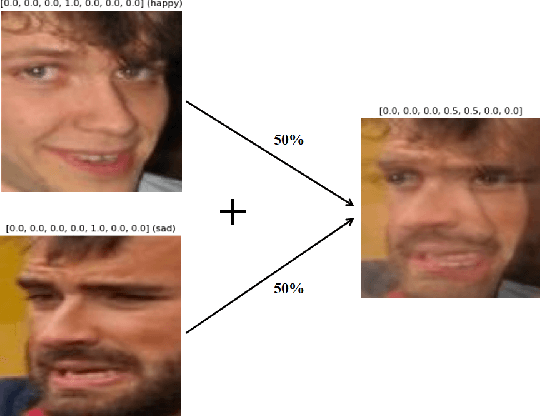
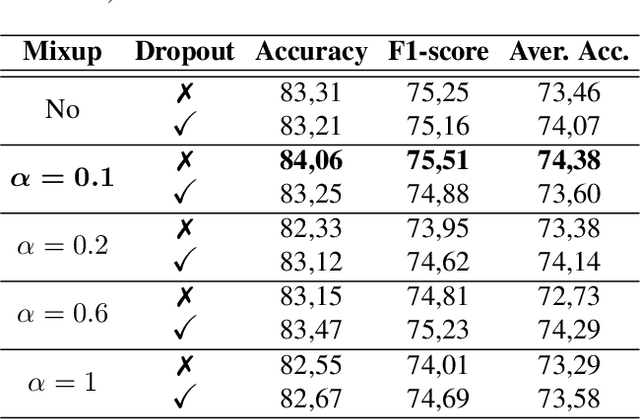
Automatic Facial Expression Recognition (FER) has attracted increasing attention in the last 20 years since facial expressions play a central role in human communication. Most FER methodologies utilize Deep Neural Networks (DNNs) that are powerful tools when it comes to data analysis. However, despite their power, these networks are prone to overfitting, as they often tend to memorize the training data. What is more, there are not currently a lot of in-the-wild (i.e. in unconstrained environment) large databases for FER. To alleviate this issue, a number of data augmentation techniques have been proposed. Data augmentation is a way to increase the diversity of available data by applying constrained transformations on the original data. One such technique, which has positively contributed to various classification tasks, is Mixup. According to this, a DNN is trained on convex combinations of pairs of examples and their corresponding labels. In this paper, we examine the effectiveness of Mixup for in-the-wild FER in which data have large variations in head poses, illumination conditions, backgrounds and contexts. We then propose a new data augmentation strategy which is based on Mixup, called MixAugment. According to this, the network is trained concurrently on a combination of virtual examples and real examples; all these examples contribute to the overall loss function. We conduct an extensive experimental study that proves the effectiveness of MixAugment over Mixup and various state-of-the-art methods. We further investigate the combination of dropout with Mixup and MixAugment, as well as the combination of other data augmentation techniques with MixAugment.
Uncertain Label Correction via Auxiliary Action Unit Graphs for Facial Expression Recognition
Apr 23, 2022
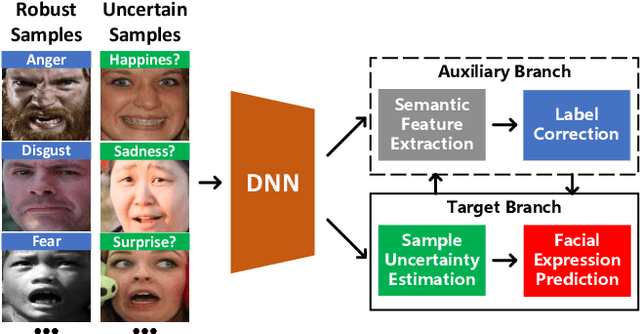

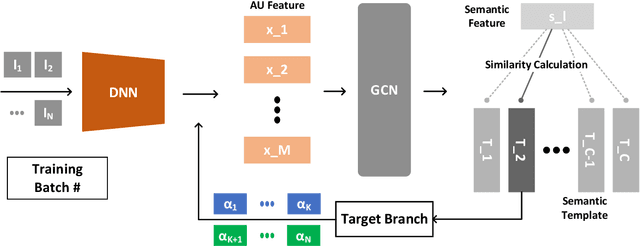
High-quality annotated images are significant to deep facial expression recognition (FER) methods. However, uncertain labels, mostly existing in large-scale public datasets, often mislead the training process. In this paper, we achieve uncertain label correction of facial expressions using auxiliary action unit (AU) graphs, called ULC-AG. Specifically, a weighted regularization module is introduced to highlight valid samples and suppress category imbalance in every batch. Based on the latent dependency between emotions and AUs, an auxiliary branch using graph convolutional layers is added to extract the semantic information from graph topologies. Finally, a re-labeling strategy corrects the ambiguous annotations by comparing their feature similarities with semantic templates. Experiments show that our ULC-AG achieves 89.31% and 61.57% accuracy on RAF-DB and AffectNet datasets, respectively, outperforming the baseline and state-of-the-art methods.
Learning from Synthetic Data: Facial Expression Classification based on Ensemble of Multi-task Networks
Jul 21, 2022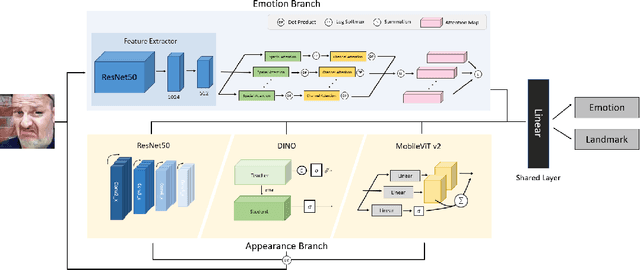


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Learning from Synthetic Data" (LSD) is an important topic in the facial expression recognition task. In this paper, we propose a multi-task learning-based facial expression recognition approach which consists of emotion and appearance learning branches that can share all face information, and present preliminary results for the LSD challenge introduced in the 4th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean F1 score of 0.71.
Boosting Facial Expression Recognition by A Semi-Supervised Progressive Teacher
May 28, 2022
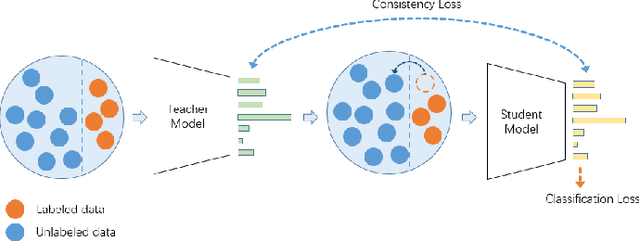

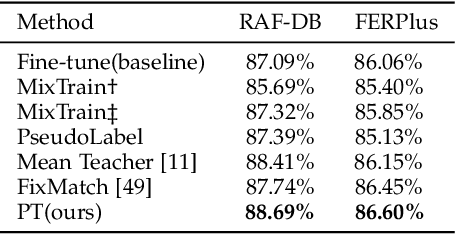
In this paper, we aim to improve the performance of in-the-wild Facial Expression Recognition (FER) by exploiting semi-supervised learning. Large-scale labeled data and deep learning methods have greatly improved the performance of image recognition. However, the performance of FER is still not ideal due to the lack of training data and incorrect annotations (e.g., label noises). Among existing in-the-wild FER datasets, reliable ones contain insufficient data to train robust deep models while large-scale ones are annotated in lower quality. To address this problem, we propose a semi-supervised learning algorithm named Progressive Teacher (PT) to utilize reliable FER datasets as well as large-scale unlabeled expression images for effective training. On the one hand, PT introduces semi-supervised learning method to relieve the shortage of data in FER. On the other hand, it selects useful labeled training samples automatically and progressively to alleviate label noise. PT uses selected clean labeled data for computing the supervised classification loss and unlabeled data for unsupervised consistency loss. Experiments on widely-used databases RAF-DB and FERPlus validate the effectiveness of our method, which achieves state-of-the-art performance with accuracy of 89.57% on RAF-DB. Additionally, when the synthetic noise rate reaches even 30%, the performance of our PT algorithm only degrades by 4.37%.
Fuzzy and entropy facial recognition
Aug 24, 2014This paper suggests an effective method for facial recognition using fuzzy theory and Shannon entropy. Combination of fuzzy theory and Shannon entropy eliminates the complication of other methods. Shannon entropy calculates the ratio of an element between faces, and fuzzy theory calculates the member ship of the entropy with 1. More details will be mentioned in Section 3. The learning performance is better than others as it is very simple, and only need two data per learning. By using factors that don't usually change during the life, the method will have a high accuracy.
Distract Your Attention: Multi-head Cross Attention Network for Facial Expression Recognition
Sep 15, 2021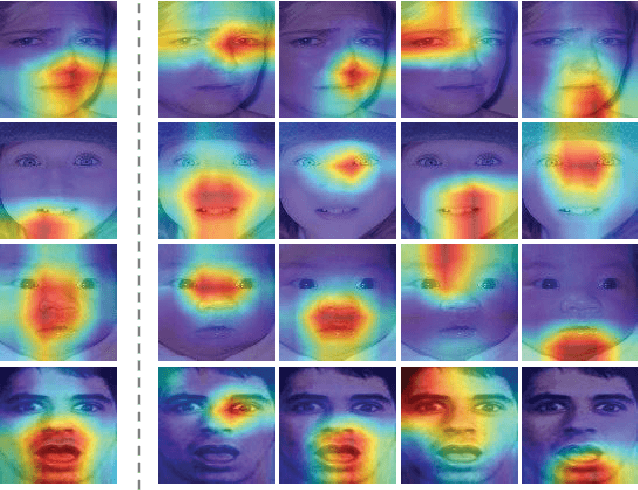
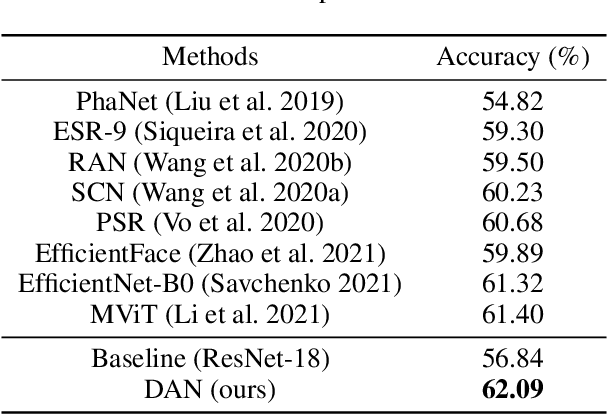
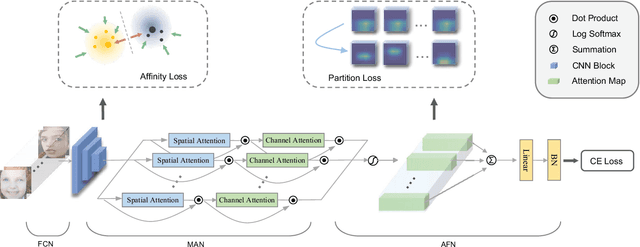
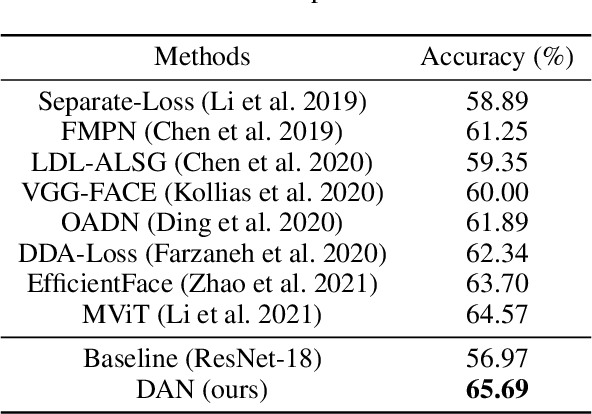
We present a novel facial expression recognition network, called Distract your Attention Network (DAN). Our method is based on two key observations. Firstly, multiple classes share inherently similar underlying facial appearance, and their differences could be subtle. Secondly, facial expressions exhibit themselves through multiple facial regions simultaneously, and the recognition requires a holistic approach by encoding high-order interactions among local features. To address these issues, we propose our DAN with three key components: Feature Clustering Network (FCN), Multi-head cross Attention Network (MAN), and Attention Fusion Network (AFN). The FCN extracts robust features by adopting a large-margin learning objective to maximize class separability. In addition, the MAN instantiates a number of attention heads to simultaneously attend to multiple facial areas and build attention maps on these regions. Further, the AFN distracts these attentions to multiple locations before fusing the attention maps to a comprehensive one. Extensive experiments on three public datasets (including AffectNet, RAF-DB, and SFEW 2.0) verified that the proposed method consistently achieves state-of-the-art facial expression recognition performance. Code will be made available at https://github.com/yaoing/DAN.
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 19, 2023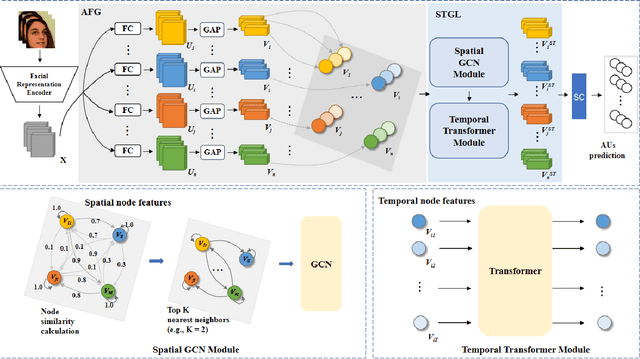

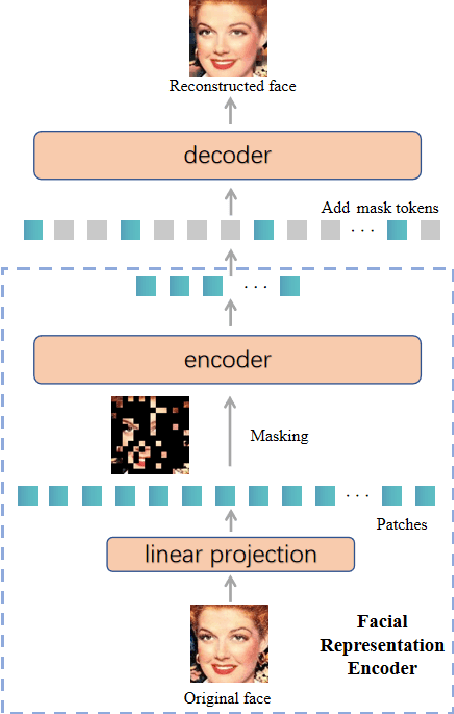

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows the model to generate the best results among all ablation systems.