 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
A priori compression of convolutional neural networks for wave simulators
Apr 12, 2023
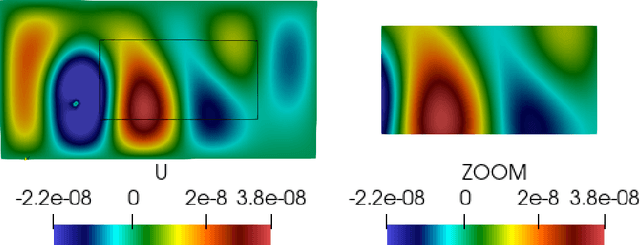
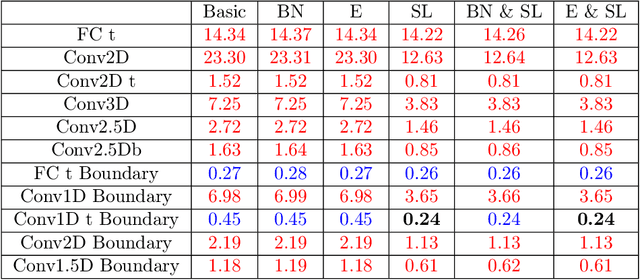
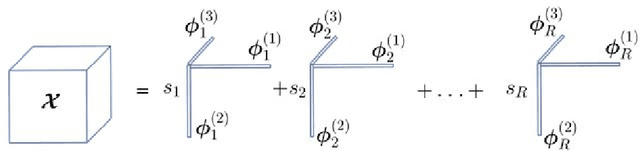
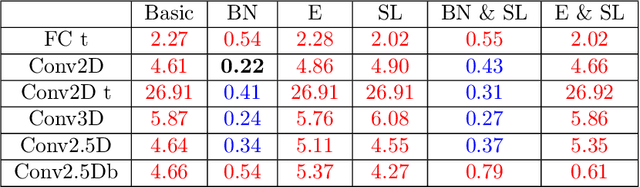
Convolutional neural networks are now seeing widespread use in a variety of fields, including image classification, facial and object recognition, medical imaging analysis, and many more. In addition, there are applications such as physics-informed simulators in which accurate forecasts in real time with a minimal lag are required. The present neural network designs include millions of parameters, which makes it difficult to install such complex models on devices that have limited memory. Compression techniques might be able to resolve these issues by decreasing the size of CNN models that are created by reducing the number of parameters that contribute to the complexity of the models. We propose a compressed tensor format of convolutional layer, a priori, before the training of the neural network. 3-way kernels or 2-way kernels in convolutional layers are replaced by one-way fiters. The overfitting phenomena will be reduced also. The time needed to make predictions or time required for training using the original Convolutional Neural Networks model would be cut significantly if there were fewer parameters to deal with. In this paper we present a method of a priori compressing convolutional neural networks for finite element (FE) predictions of physical data. Afterwards we validate our a priori compressed models on physical data from a FE model solving a 2D wave equation. We show that the proposed convolutinal compression technique achieves equivalent performance as classical convolutional layers with fewer trainable parameters and lower memory footprint.
Improving 2D face recognition via fine-level facial depth generation and RGB-D complementary feature learning
May 08, 2023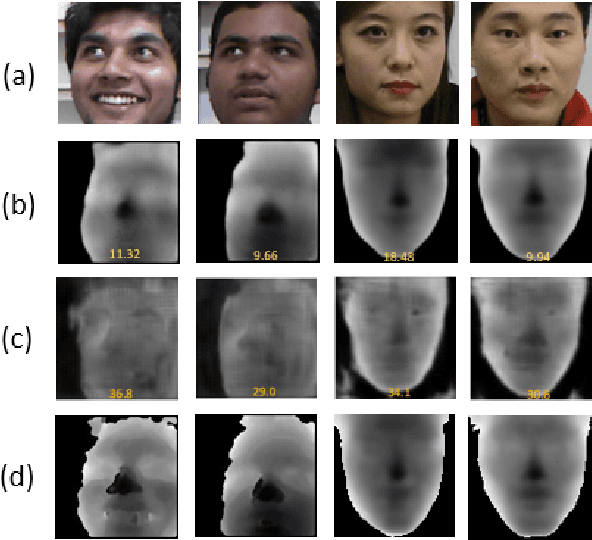

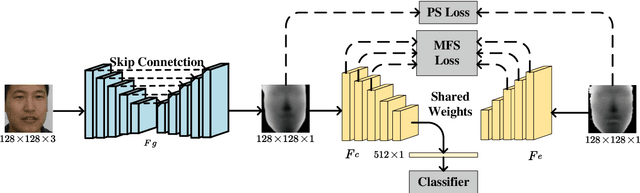

Face recognition in complex scenes suffers severe challenges coming from perturbations such as pose deformation, ill illumination, partial occlusion. Some methods utilize depth estimation to obtain depth corresponding to RGB to improve the accuracy of face recognition. However, the depth generated by them suffer from image blur, which introduces noise in subsequent RGB-D face recognition tasks. In addition, existing RGB-D face recognition methods are unable to fully extract complementary features. In this paper, we propose a fine-grained facial depth generation network and an improved multimodal complementary feature learning network. Extensive experiments on the Lock3DFace dataset and the IIIT-D dataset show that the proposed FFDGNet and I MCFLNet can improve the accuracy of RGB-D face recognition while achieving the state-of-the-art performance.
Are Face Detection Models Biased?
Nov 07, 2022

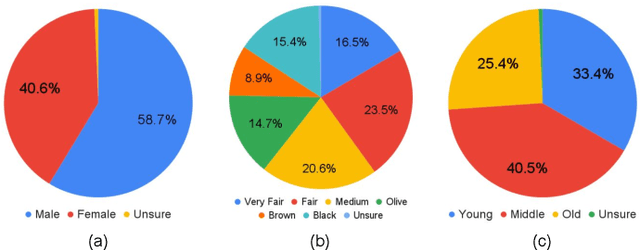

The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. Research in bias focuses primarily on facial recognition and attribute prediction with scarce emphasis on face detection. Existing studies consider face detection as binary classification into 'face' and 'non-face' classes. In this work, we investigate possible bias in the domain of face detection through facial region localization which is currently unexplored. Since facial region localization is an essential task for all face recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Most existing face detection datasets lack suitable annotation for such analysis. Therefore, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. Utilizing the extensive annotations from F2LA, an experimental setup is designed to study the performance of four pre-trained face detectors. We observe (i) a high disparity in detection accuracies across gender and skin-tone, and (ii) interplay of confounding factors beyond demography. The F2LA data and associated annotations can be accessed at http://iab-rubric.org/index.php/F2LA.
Understanding and Mitigating Annotation Bias in Facial Expression Recognition
Aug 19, 2021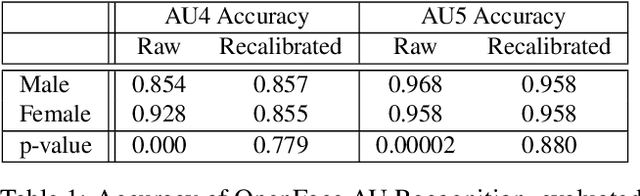
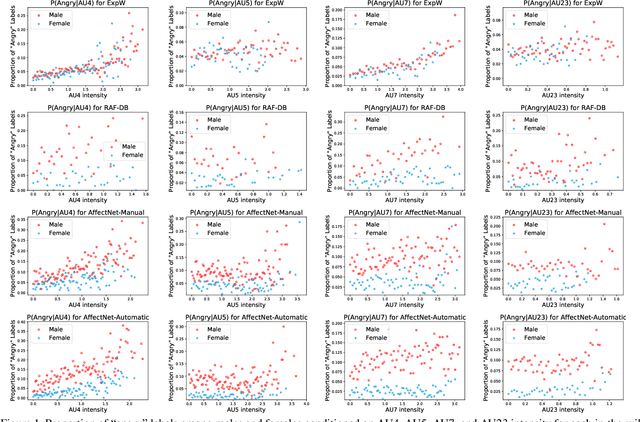
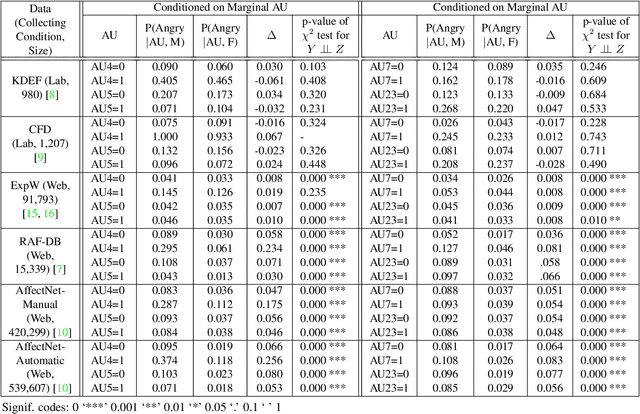
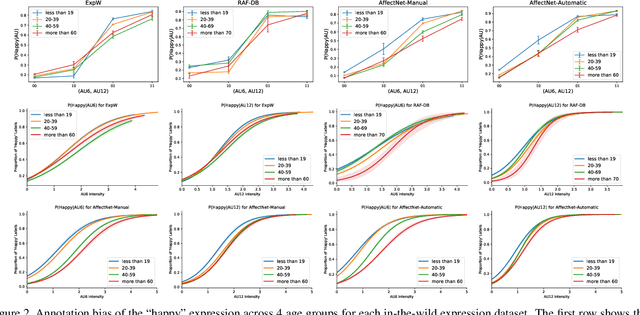
The performance of a computer vision model depends on the size and quality of its training data. Recent studies have unveiled previously-unknown composition biases in common image datasets which then lead to skewed model outputs, and have proposed methods to mitigate these biases. However, most existing works assume that human-generated annotations can be considered gold-standard and unbiased. In this paper, we reveal that this assumption can be problematic, and that special care should be taken to prevent models from learning such annotation biases. We focus on facial expression recognition and compare the label biases between lab-controlled and in-the-wild datasets. We demonstrate that many expression datasets contain significant annotation biases between genders, especially when it comes to the happy and angry expressions, and that traditional methods cannot fully mitigate such biases in trained models. To remove expression annotation bias, we propose an AU-Calibrated Facial Expression Recognition (AUC-FER) framework that utilizes facial action units (AUs) and incorporates the triplet loss into the objective function. Experimental results suggest that the proposed method is more effective in removing expression annotation bias than existing techniques.
Face Emotion Recognization Using Dataset Augmentation Based on Neural Network
Oct 23, 2022
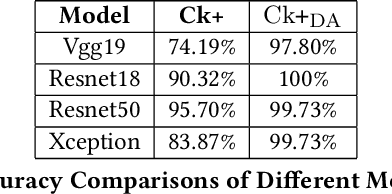

Facial expression is one of the most external indications of a person's feelings and emotions. In daily conversation, according to the psychologist, only 7\% and 38\% of information is communicated through words and sounds respective, while up to 55\% is through facial expression. It plays an important role in coordinating interpersonal relationships. Ekman and Friesen recognized six essential emotions in the nineteenth century depending on a cross-cultural study, which indicated that people feel each basic emotion in the same fashion despite culture. As a branch of the field of analyzing sentiment, facial expression recognition offers broad application prospects in a variety of domains, including the interaction between humans and computers, healthcare, and behavior monitoring. Therefore, many researchers have devoted themselves to facial expression recognition. In this paper, an effective hybrid data augmentation method is used. This approach is operated on two public datasets, and four benchmark models see some remarkable results.
Privileged Attribution Constrained Deep Networks for Facial Expression Recognition
Mar 24, 2022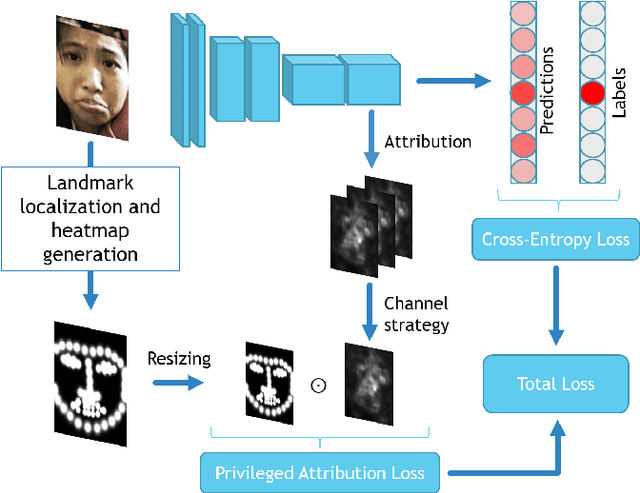

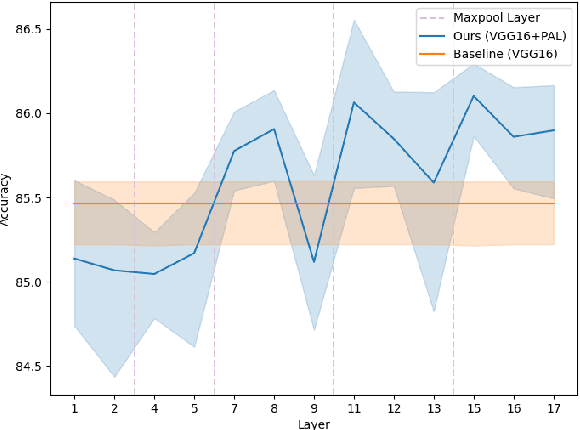
Facial Expression Recognition (FER) is crucial in many research domains because it enables machines to better understand human behaviours. FER methods face the problems of relatively small datasets and noisy data that don't allow classical networks to generalize well. To alleviate these issues, we guide the model to concentrate on specific facial areas like the eyes, the mouth or the eyebrows, which we argue are decisive to recognise facial expressions. We propose the Privileged Attribution Loss (PAL), a method that directs the attention of the model towards the most salient facial regions by encouraging its attribution maps to correspond to a heatmap formed by facial landmarks. Furthermore, we introduce several channel strategies that allow the model to have more degrees of freedom. The proposed method is independent of the backbone architecture and doesn't need additional semantic information at test time. Finally, experimental results show that the proposed PAL method outperforms current state-of-the-art methods on both RAF-DB and AffectNet.
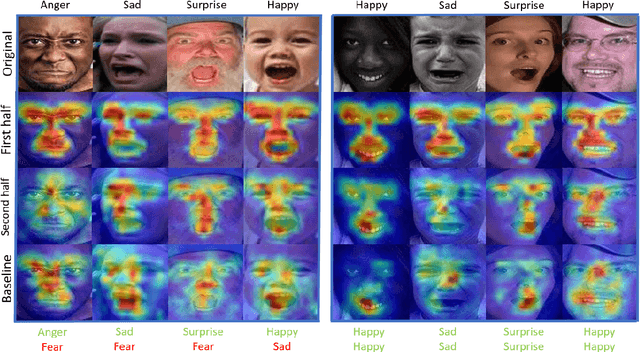
Gradient Attention Balance Network: Mitigating Face Recognition Racial Bias via Gradient Attention
Apr 05, 2023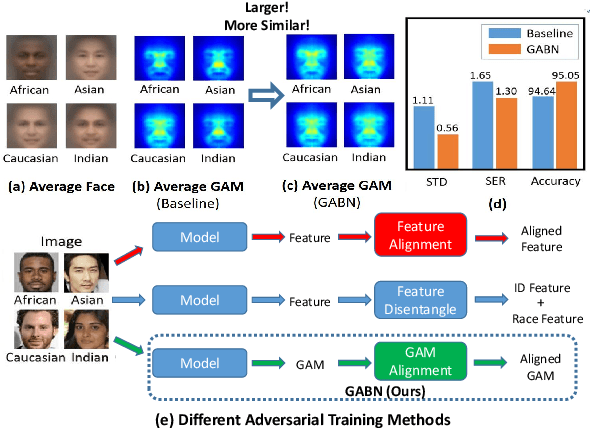
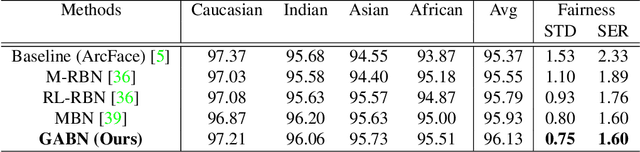

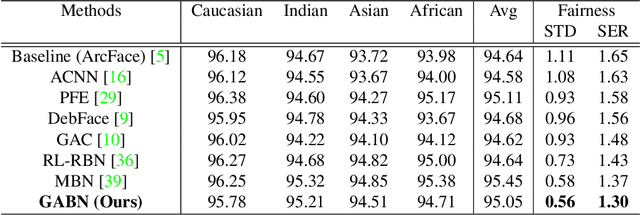
Although face recognition has made impressive progress in recent years, we ignore the racial bias of the recognition system when we pursue a high level of accuracy. Previous work found that for different races, face recognition networks focus on different facial regions, and the sensitive regions of darker-skinned people are much smaller. Based on this discovery, we propose a new de-bias method based on gradient attention, called Gradient Attention Balance Network (GABN). Specifically, we use the gradient attention map (GAM) of the face recognition network to track the sensitive facial regions and make the GAMs of different races tend to be consistent through adversarial learning. This method mitigates the bias by making the network focus on similar facial regions. In addition, we also use masks to erase the Top-N sensitive facial regions, forcing the network to allocate its attention to a larger facial region. This method expands the sensitive region of darker-skinned people and further reduces the gap between GAM of darker-skinned people and GAM of Caucasians. Extensive experiments show that GABN successfully mitigates racial bias in face recognition and learns more balanced performance for people of different races.
Learn-to-Decompose: Cascaded Decomposition Network for Cross-Domain Few-Shot Facial Expression Recognition
Jul 16, 2022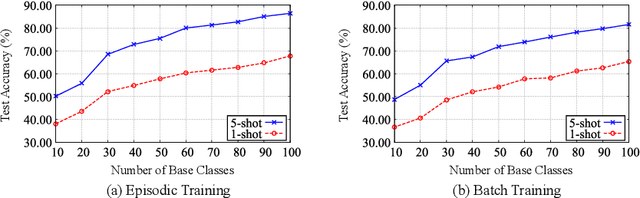
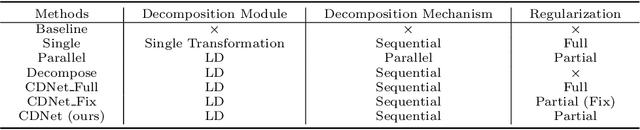
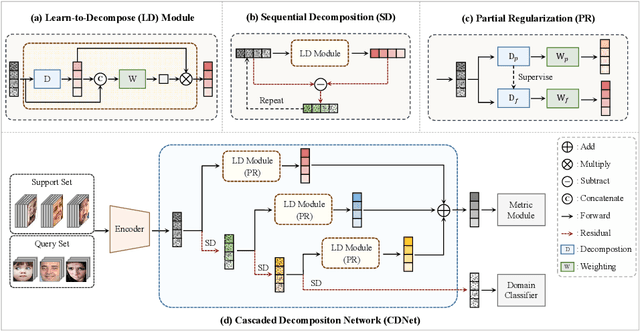
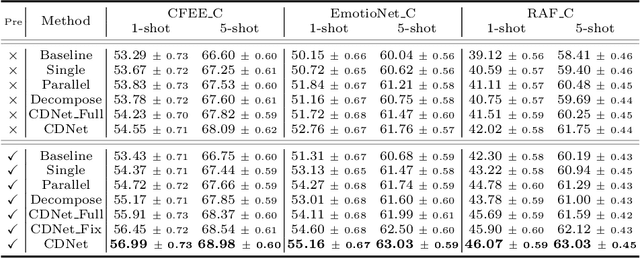
Most existing compound facial expression recognition (FER) methods rely on large-scale labeled compound expression data for training. However, collecting such data is labor-intensive and time-consuming. In this paper, we address the compound FER task in the cross-domain few-shot learning (FSL) setting, which requires only a few samples of compound expressions in the target domain. Specifically, we propose a novel cascaded decomposition network (CDNet), which cascades several learn-to-decompose modules with shared parameters based on a sequential decomposition mechanism, to obtain a transferable feature space. To alleviate the overfitting problem caused by limited base classes in our task, a partial regularization strategy is designed to effectively exploit the best of both episodic training and batch training. By training across similar tasks on multiple basic expression datasets, CDNet learns the ability of learn-to-decompose that can be easily adapted to identify unseen compound expressions. Extensive experiments on both in-the-lab and in-the-wild compound expression datasets demonstrate the superiority of our proposed CDNet against several state-of-the-art FSL methods. Code is available at: https://github.com/zouxinyi0625/CDNet.
GANonymization: A GAN-based Face Anonymization Framework for Preserving Emotional Expressions
May 03, 2023
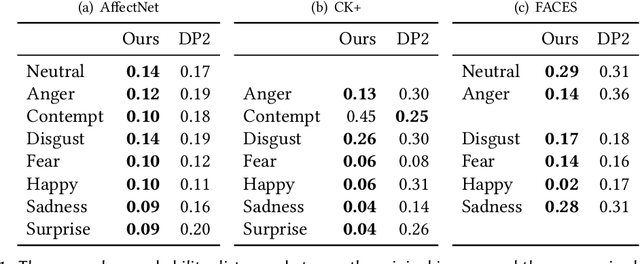

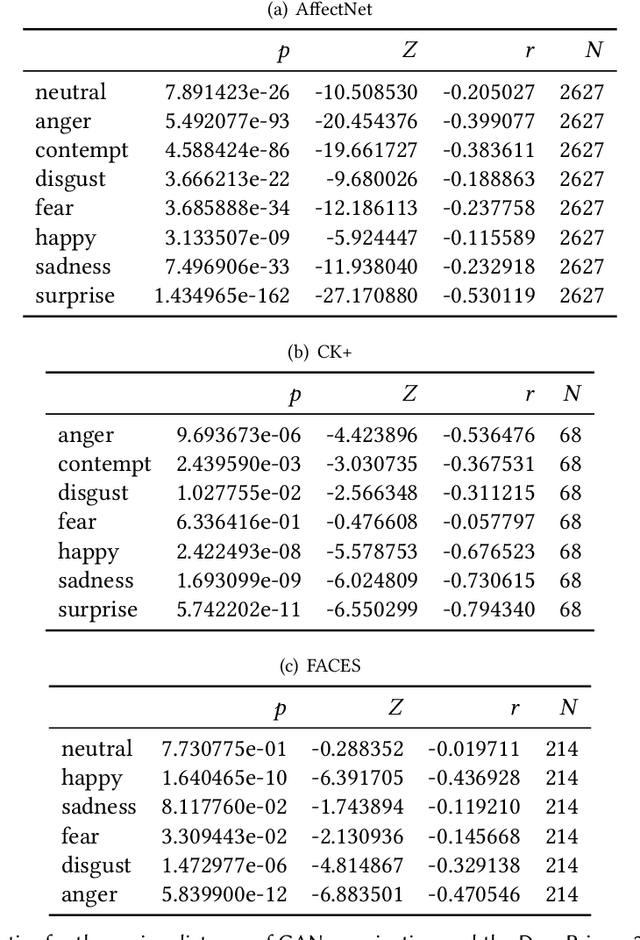
In recent years, the increasing availability of personal data has raised concerns regarding privacy and security. One of the critical processes to address these concerns is data anonymization, which aims to protect individual privacy and prevent the release of sensitive information. This research focuses on the importance of face anonymization. Therefore, we introduce GANonymization, a novel face anonymization framework with facial expression-preserving abilities. Our approach is based on a high-level representation of a face which is synthesized into an anonymized version based on a generative adversarial network (GAN). The effectiveness of the approach was assessed by evaluating its performance in removing identifiable facial attributes to increase the anonymity of the given individual face. Additionally, the performance of preserving facial expressions was evaluated on several affect recognition datasets and outperformed the state-of-the-art method in most categories. Finally, our approach was analyzed for its ability to remove various facial traits, such as jewelry, hair color, and multiple others. Here, it demonstrated reliable performance in removing these attributes. Our results suggest that GANonymization is a promising approach for anonymizing faces while preserving facial expressions.
Cross-Centroid Ripple Pattern for Facial Expression Recognition
Jan 16, 2022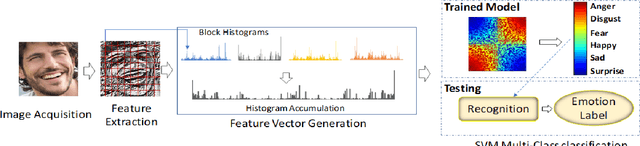
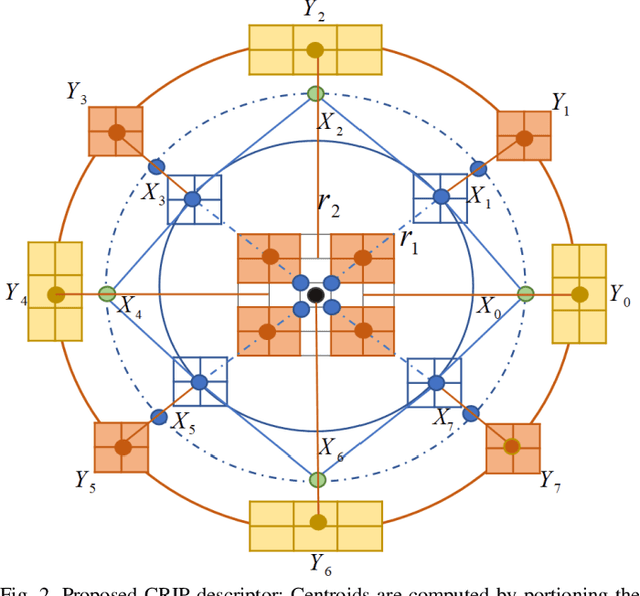


In this paper, we propose a new feature descriptor Cross-Centroid Ripple Pattern (CRIP) for facial expression recognition. CRIP encodes the transitional pattern of a facial expression by incorporating cross-centroid relationship between two ripples located at radius r1 and r2 respectively. These ripples are generated by dividing the local neighborhood region into subregions. Thus, CRIP has ability to preserve macro and micro structural variations in an extensive region, which enables it to deal with side views and spontaneous expressions. Furthermore, gradient information between cross centroid ripples provides strenght to captures prominent edge features in active patches: eyes, nose and mouth, that define the disparities between different facial expressions. Cross centroid information also provides robustness to irregular illumination. Moreover, CRIP utilizes the averaging behavior of pixels at subregions that yields robustness to deal with noisy conditions. The performance of proposed descriptor is evaluated on seven comprehensive expression datasets consisting of challenging conditions such as age, pose, ethnicity and illumination variations. The experimental results show that our descriptor consistently achieved better accuracy rate as compared to existing state-of-art approaches.