 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Adults as Augmentations for Children in Facial Emotion Recognition with Contrastive Learning
Feb 10, 2022
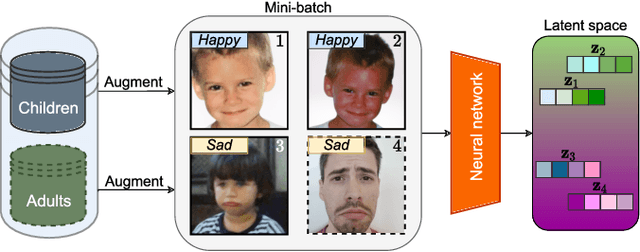
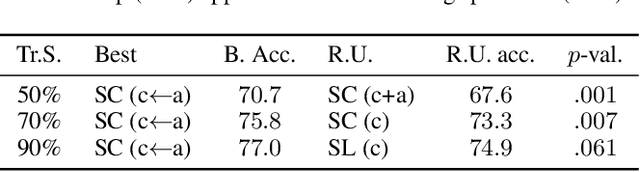
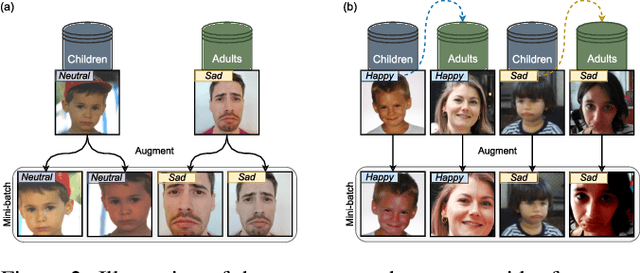
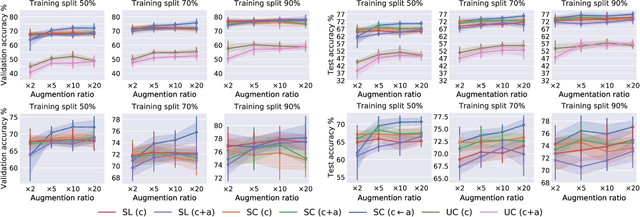
Emotion recognition in children can help the early identification of, and intervention on, psychological complications that arise in stressful situations such as cancer treatment. Though deep learning models are increasingly being adopted, data scarcity is often an issue in pediatric medicine, including for facial emotion recognition in children. In this paper, we study the application of data augmentation-based contrastive learning to overcome data scarcity in facial emotion recognition for children. We explore the idea of ignoring generational gaps, by adding abundantly available adult data to pediatric data, to learn better representations. We investigate different ways by which adult facial expression images can be used alongside those of children. In particular, we propose to explicitly incorporate within each mini-batch adult images as augmentations for children's. Out of $84$ combinations of learning approaches and training set sizes, we find that supervised contrastive learning with the proposed training scheme performs best, reaching a test accuracy that typically surpasses the one of the second-best approach by 2% to 3%. Our results indicate that adult data can be considered to be a meaningful augmentation of pediatric data for the recognition of emotional facial expression in children, and open up the possibility for other applications of contrastive learning to improve pediatric care by complementing data of children with that of adults.
Facial Expression Recognition using Vanilla ViT backbones with MAE Pretraining
Jul 22, 2022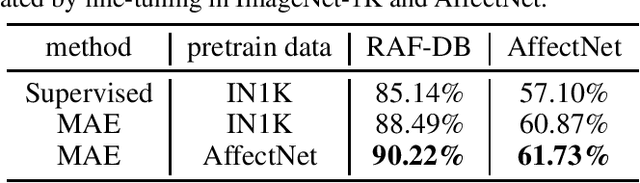
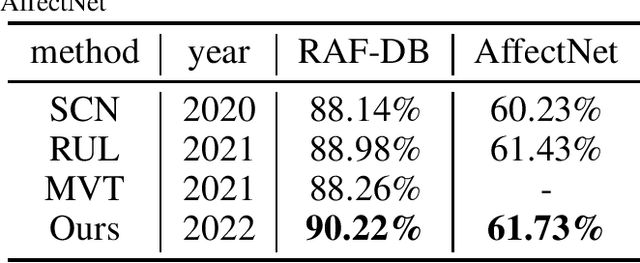
Humans usually convey emotions voluntarily or involuntarily by facial expressions. Automatically recognizing the basic expression (such as happiness, sadness, and neutral) from a facial image, i.e., facial expression recognition (FER), is extremely challenging and attracts much research interests. Large scale datasets and powerful inference models have been proposed to address the problem. Though considerable progress has been made, most of the state of the arts employing convolutional neural networks (CNNs) or elaborately modified Vision Transformers (ViTs) depend heavily on upstream supervised pretraining. Transformers are taking place the domination of CNNs in more and more computer vision tasks. But they usually need much more data to train, since they use less inductive biases compared with CNNs. To explore whether a vanilla ViT without extra training samples from upstream tasks is able to achieve competitive accuracy, we use a plain ViT with MAE pretraining to perform the FER task. Specifically, we first pretrain the original ViT as a Masked Autoencoder (MAE) on a large facial expression dataset without expression labels. Then, we fine-tune the ViT on popular facial expression datasets with expression labels. The presented method is quite competitive with 90.22\% on RAF-DB, 61.73\% on AfectNet and can serve as a simple yet strong ViT-based baseline for FER studies.
Unsupervised Facial Expression Representation Learning with Contrastive Local Warping
Mar 16, 2023
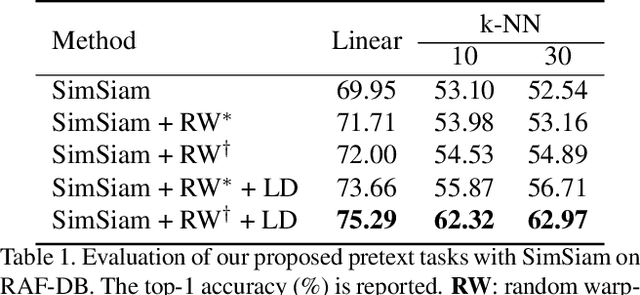
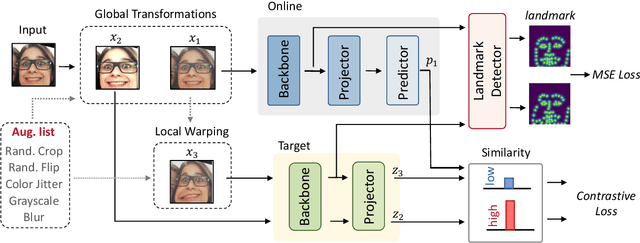
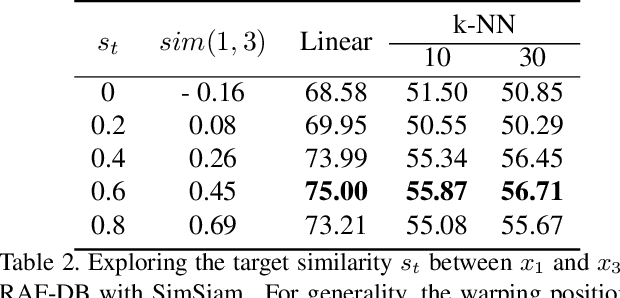
This paper investigates unsupervised representation learning for facial expression analysis. We think Unsupervised Facial Expression Representation (UFER) deserves exploration and has the potential to address some key challenges in facial expression analysis, such as scaling, annotation bias, the discrepancy between discrete labels and continuous emotions, and model pre-training. Such motivated, we propose a UFER method with contrastive local warping (ContraWarping), which leverages the insight that the emotional expression is robust to current global transformation (affine transformation, color jitter, etc.) but can be easily changed by random local warping. Therefore, given a facial image, ContraWarping employs some global transformations and local warping to generate its positive and negative samples and sets up a novel contrastive learning framework. Our in-depth investigation shows that: 1) the positive pairs from global transformations may be exploited with general self-supervised learning (e.g., BYOL) and already bring some informative features, and 2) the negative pairs from local warping explicitly introduce expression-related variation and further bring substantial improvement. Based on ContraWarping, we demonstrate the benefit of UFER under two facial expression analysis scenarios: facial expression recognition and image retrieval. For example, directly using ContraWarping features for linear probing achieves 79.14% accuracy on RAF-DB, significantly reducing the gap towards the full-supervised counterpart (88.92% / 84.81% with/without pre-training).
InMyFace: Inertial and Mechanomyography-Based Sensor Fusion for Wearable Facial Activity Recognition
Feb 08, 2023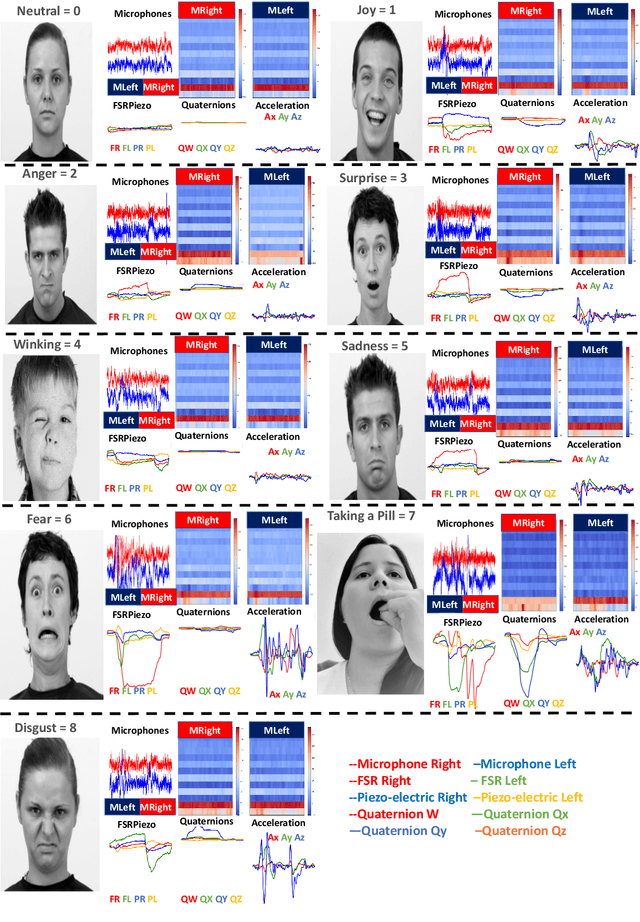
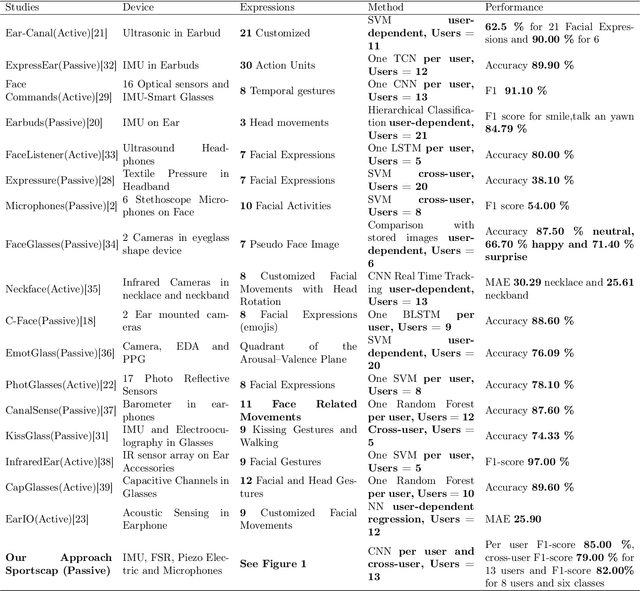
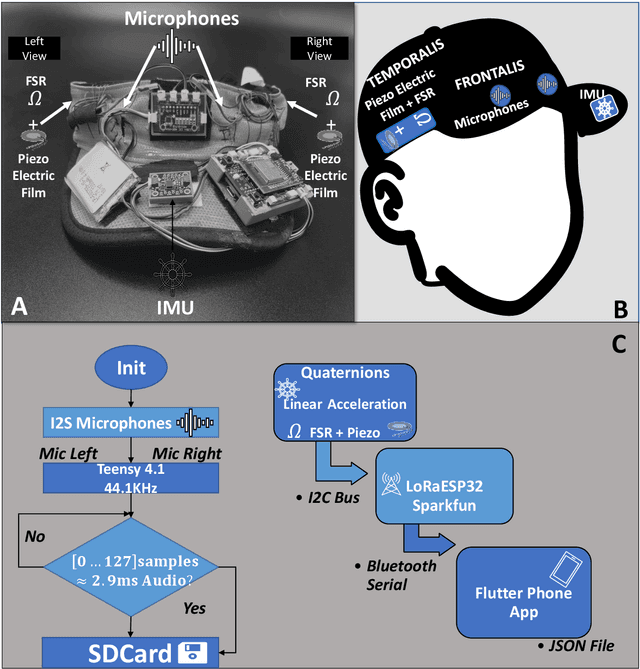
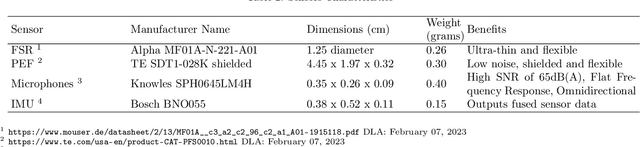
Recognizing facial activity is a well-understood (but non-trivial) computer vision problem. However, reliable solutions require a camera with a good view of the face, which is often unavailable in wearable settings. Furthermore, in wearable applications, where systems accompany users throughout their daily activities, a permanently running camera can be problematic for privacy (and legal) reasons. This work presents an alternative solution based on the fusion of wearable inertial sensors, planar pressure sensors, and acoustic mechanomyography (muscle sounds). The sensors were placed unobtrusively in a sports cap to monitor facial muscle activities related to facial expressions. We present our integrated wearable sensor system, describe data fusion and analysis methods, and evaluate the system in an experiment with thirteen subjects from different cultural backgrounds (eight countries) and both sexes (six women and seven men). In a one-model-per-user scheme and using a late fusion approach, the system yielded an average F1 score of 85.00% for the case where all sensing modalities are combined. With a cross-user validation and a one-model-for-all-user scheme, an F1 score of 79.00% was obtained for thirteen participants (six females and seven males). Moreover, in a hybrid fusion (cross-user) approach and six classes, an average F1 score of 82.00% was obtained for eight users. The results are competitive with state-of-the-art non-camera-based solutions for a cross-user study. In addition, our unique set of participants demonstrates the inclusiveness and generalizability of the approach.
Cascaded Asymmetric Local Pattern: A Novel Descriptor for Unconstrained Facial Image Recognition and Retrieval
Jan 03, 2022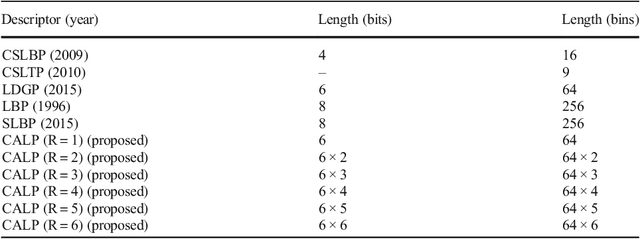
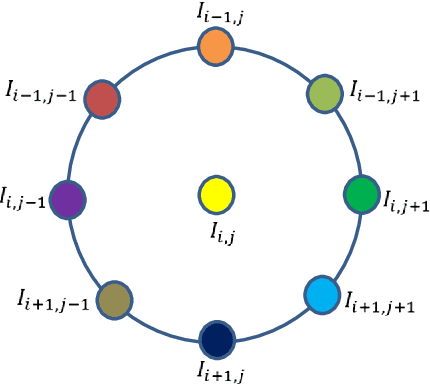
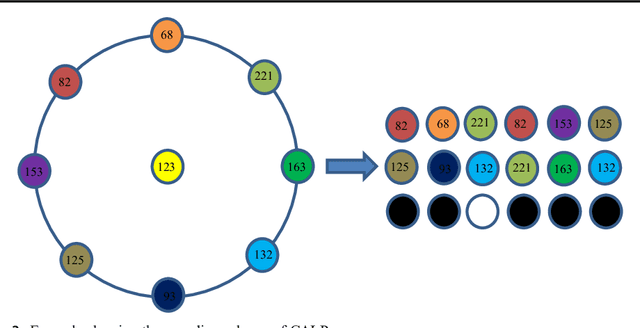

Feature description is one of the most frequently studied areas in the expert systems and machine learning. Effective encoding of the images is an essential requirement for accurate matching. These encoding schemes play a significant role in recognition and retrieval systems. Facial recognition systems should be effective enough to accurately recognize individuals under intrinsic and extrinsic variations of the system. The templates or descriptors used in these systems encode spatial relationships of the pixels in the local neighbourhood of an image. Features encoded using these hand crafted descriptors should be robust against variations such as; illumination, background, poses, and expressions. In this paper a novel hand crafted cascaded asymmetric local pattern (CALP) is proposed for retrieval and recognition facial image. The proposed descriptor uniquely encodes relationship amongst the neighbouring pixels in horizontal and vertical directions. The proposed encoding scheme has optimum feature length and shows significant improvement in accuracy under environmental and physiological changes in a facial image. State of the art hand crafted descriptors namely; LBP, LDGP, CSLBP, SLBP and CSLTP are compared with the proposed descriptor on most challenging datasets namely; Caltech-face, LFW, and CASIA-face-v5. Result analysis shows that, the proposed descriptor outperforms state of the art under uncontrolled variations in expressions, background, pose and illumination.
An optimized Capsule-LSTM model for facial expression recognition with video sequences
May 27, 2021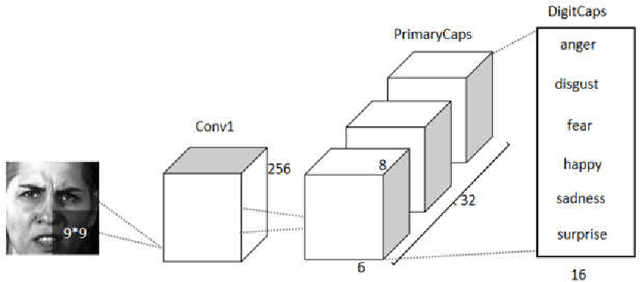
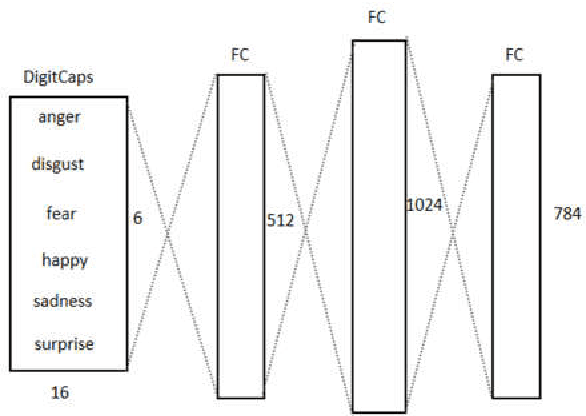
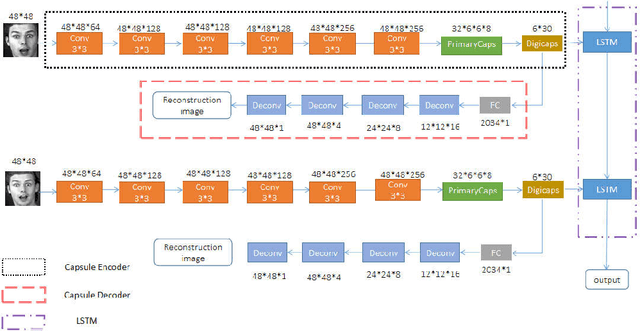

To overcome the limitations of convolutional neural network in the process of facial expression recognition, a facial expression recognition model Capsule-LSTM based on video frame sequence is proposed. This model is composed of three networks includingcapsule encoders, capsule decoders and LSTM network. The capsule encoder extracts the spatial information of facial expressions in video frames. Capsule decoder reconstructs the images to optimize the network. LSTM extracts the temporal information between video frames and analyzes the differences in expression changes between frames. The experimental results from the MMI dataset show that the Capsule-LSTM model proposed in this paper can effectively improve the accuracy of video expression recognition.
Real-Time Facial Expression Recognition using Facial Landmarks and Neural Networks
Jan 31, 2022


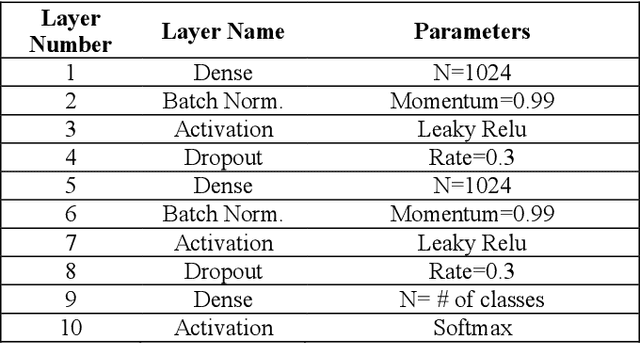
This paper presents a lightweight algorithm for feature extraction, classification of seven different emotions, and facial expression recognition in a real-time manner based on static images of the human face. In this regard, a Multi-Layer Perceptron (MLP) neural network is trained based on the foregoing algorithm. In order to classify human faces, first, some pre-processing is applied to the input image, which can localize and cut out faces from it. In the next step, a facial landmark detection library is used, which can detect the landmarks of each face. Then, the human face is split into upper and lower faces, which enables the extraction of the desired features from each part. In the proposed model, both geometric and texture-based feature types are taken into account. After the feature extraction phase, a normalized vector of features is created. A 3-layer MLP is trained using these feature vectors, leading to 96% accuracy on the test set.
Learn From All: Erasing Attention Consistency for Noisy Label Facial Expression Recognition
Jul 21, 2022
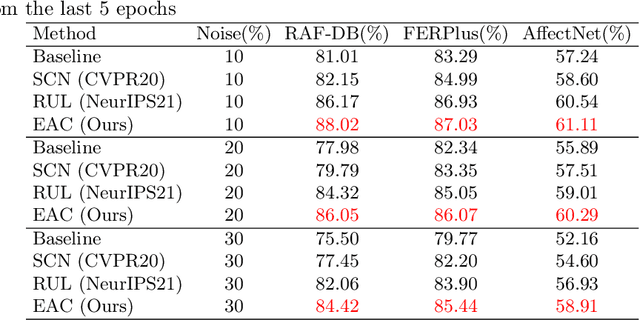
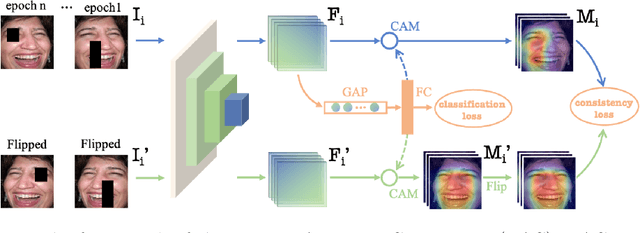

Noisy label Facial Expression Recognition (FER) is more challenging than traditional noisy label classification tasks due to the inter-class similarity and the annotation ambiguity. Recent works mainly tackle this problem by filtering out large-loss samples. In this paper, we explore dealing with noisy labels from a new feature-learning perspective. We find that FER models remember noisy samples by focusing on a part of the features that can be considered related to the noisy labels instead of learning from the whole features that lead to the latent truth. Inspired by that, we propose a novel Erasing Attention Consistency (EAC) method to suppress the noisy samples during the training process automatically. Specifically, we first utilize the flip semantic consistency of facial images to design an imbalanced framework. We then randomly erase input images and use flip attention consistency to prevent the model from focusing on a part of the features. EAC significantly outperforms state-of-the-art noisy label FER methods and generalizes well to other tasks with a large number of classes like CIFAR100 and Tiny-ImageNet. The code is available at https://github.com/zyh-uaiaaaa/Erasing-Attention-Consistency.
Facial Recognition with Encoded Local Projections
Sep 11, 2018
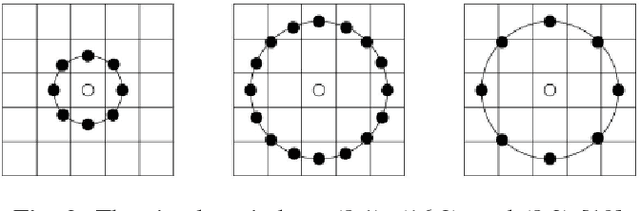

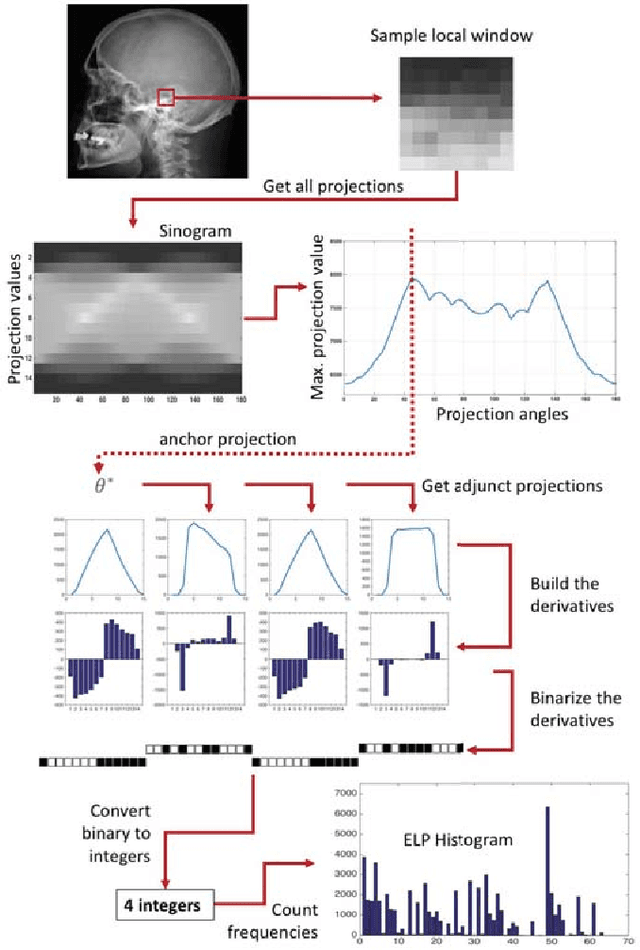
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.
Causal Intervention for Subject-Deconfounded Facial Action Unit Recognition
Apr 17, 2022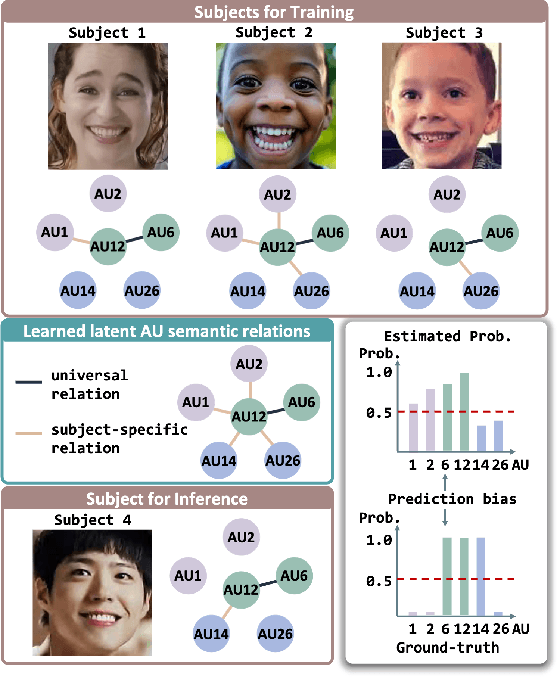
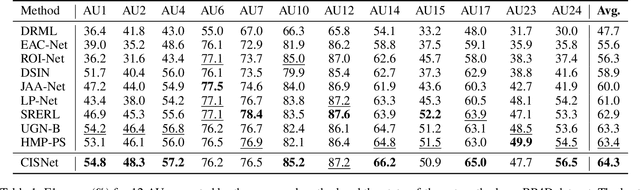
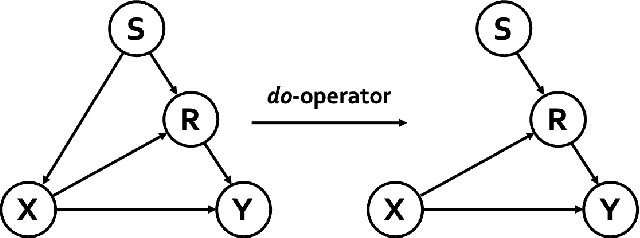
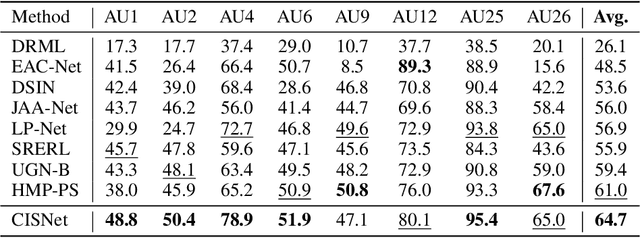
Subject-invariant facial action unit (AU) recognition remains challenging for the reason that the data distribution varies among subjects. In this paper, we propose a causal inference framework for subject-invariant facial action unit recognition. To illustrate the causal effect existing in AU recognition task, we formulate the causalities among facial images, subjects, latent AU semantic relations, and estimated AU occurrence probabilities via a structural causal model. By constructing such a causal diagram, we clarify the causal effect among variables and propose a plug-in causal intervention module, CIS, to deconfound the confounder \emph{Subject} in the causal diagram. Extensive experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of our CIS, and the model with CIS inserted, CISNet, has achieved state-of-the-art performance.