 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Side Auth: Synthesizing Virtual Sensors for Authentication
Jan 27, 2023
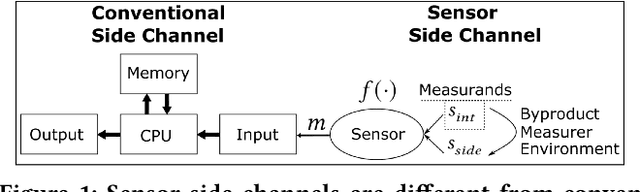
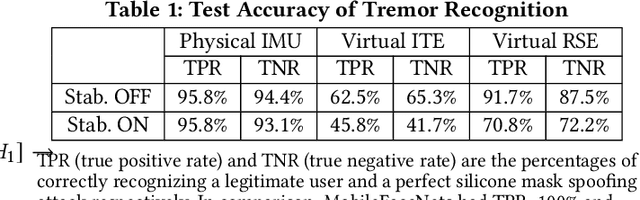
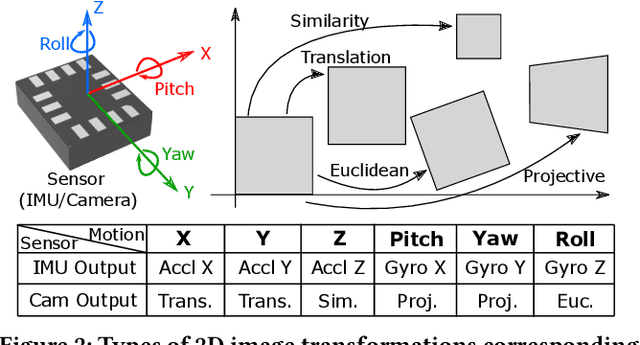
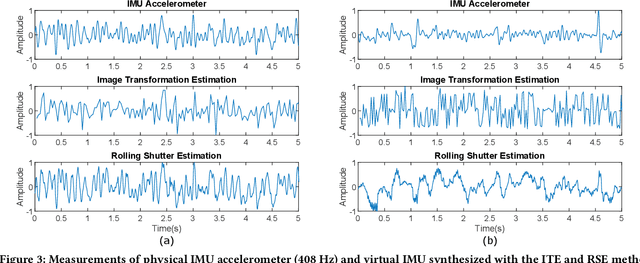
While the embedded security research community aims to protect systems by reducing analog sensor side channels, our work argues that sensor side channels can be beneficial to defenders. This work introduces the general problem of synthesizing virtual sensors from existing circuits to authenticate physical sensors' measurands. We investigate how to apply this approach and present a preliminary analytical framework and definitions for sensor side channels. To illustrate the general concept, we provide a proof-of-concept case study to synthesize a virtual inertial measurement unit from a camera motion side channel. Our work also provides an example of applying this technique to protect facial recognition against silicon mask spoofing attacks. Finally, we discuss downstream problems of how to ensure that side channels benefit the defender, but not the adversary, during authentication.
Uncertainty-aware Label Distribution Learning for Facial Expression Recognition
Sep 21, 2022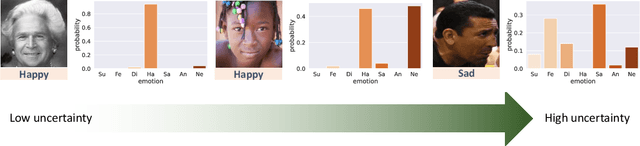
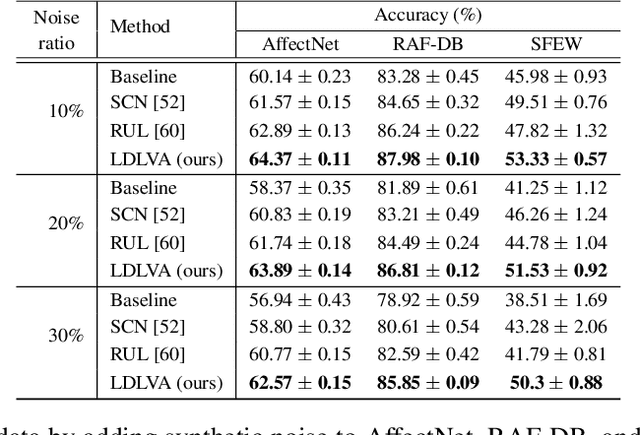
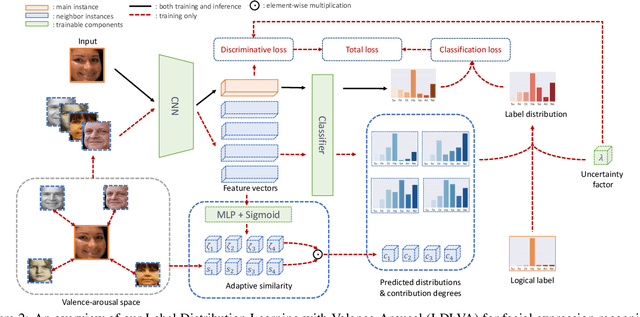
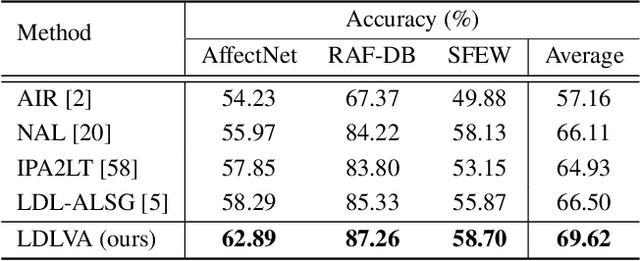
Despite significant progress over the past few years, ambiguity is still a key challenge in Facial Expression Recognition (FER). It can lead to noisy and inconsistent annotation, which hinders the performance of deep learning models in real-world scenarios. In this paper, we propose a new uncertainty-aware label distribution learning method to improve the robustness of deep models against uncertainty and ambiguity. We leverage neighborhood information in the valence-arousal space to adaptively construct emotion distributions for training samples. We also consider the uncertainty of provided labels when incorporating them into the label distributions. Our method can be easily integrated into a deep network to obtain more training supervision and improve recognition accuracy. Intensive experiments on several datasets under various noisy and ambiguous settings show that our method achieves competitive results and outperforms recent state-of-the-art approaches. Our code and models are available at https://github.com/minhnhatvt/label-distribution-learning-fer-tf.
Domain Generalisation for Apparent Emotional Facial Expression Recognition across Age-Groups
Oct 18, 2021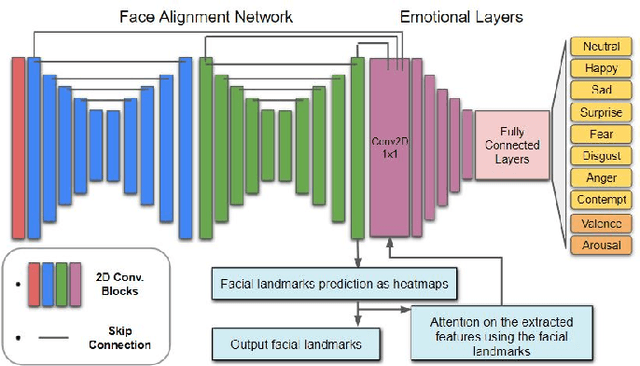
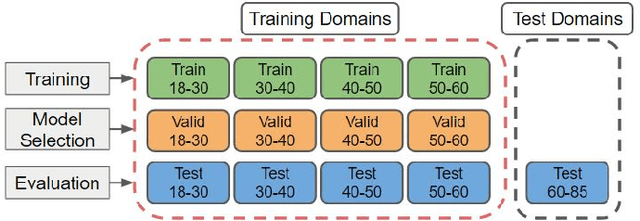
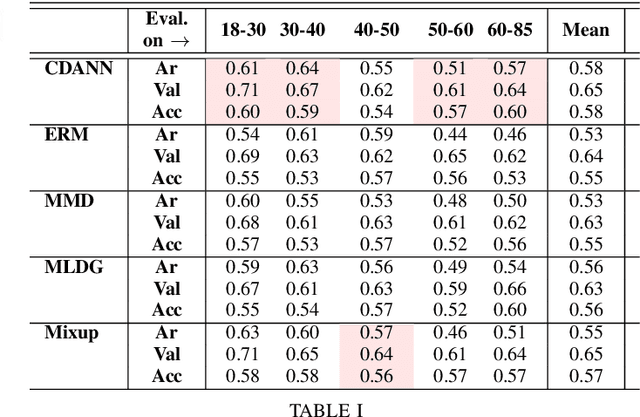
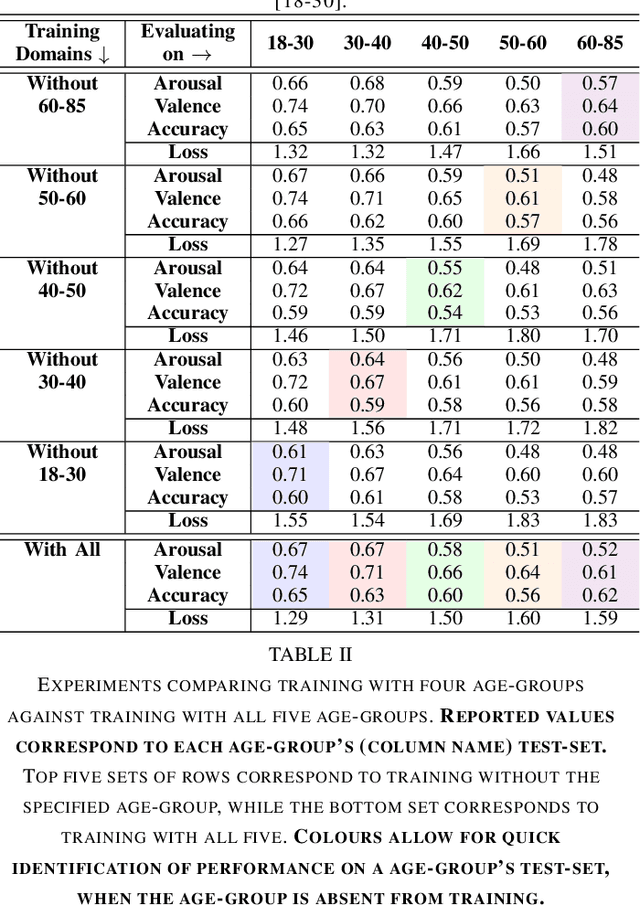
Apparent emotional facial expression recognition has attracted a lot of research attention recently. However, the majority of approaches ignore age differences and train a generic model for all ages. In this work, we study the effect of using different age-groups for training apparent emotional facial expression recognition models. To this end, we study Domain Generalisation in the context of apparent emotional facial expression recognition from facial imagery across different age groups. We first compare several domain generalisation algorithms on the basis of out-of-domain-generalisation, and observe that the Class-Conditional Domain-Adversarial Neural Networks (CDANN) algorithm has the best performance. We then study the effect of variety and number of age-groups used during training on generalisation to unseen age-groups and observe that an increase in the number of training age-groups tends to increase the apparent emotional facial expression recognition performance on unseen age-groups. We also show that exclusion of an age-group during training tends to affect more the performance of the neighbouring age groups.
AU-Aware Vision Transformers for Biased Facial Expression Recognition
Nov 12, 2022
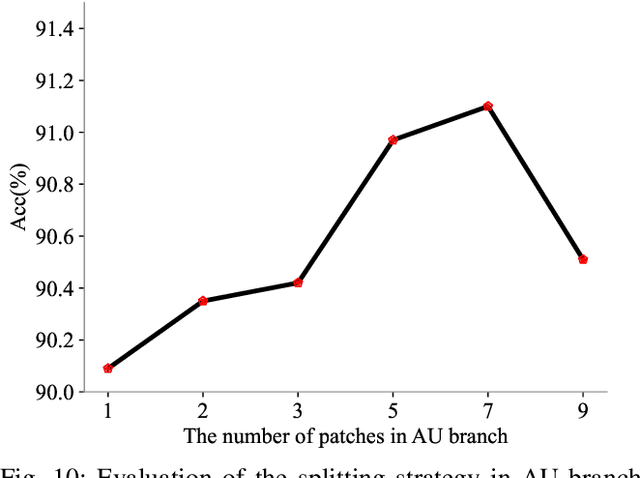

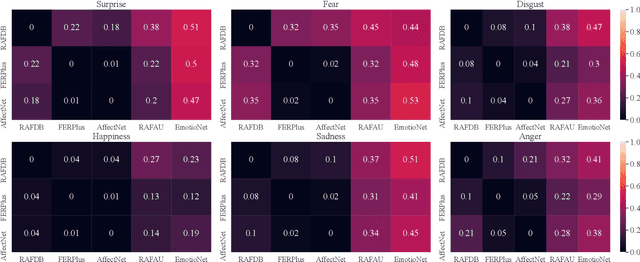
Studies have proven that domain bias and label bias exist in different Facial Expression Recognition (FER) datasets, making it hard to improve the performance of a specific dataset by adding other datasets. For the FER bias issue, recent researches mainly focus on the cross-domain issue with advanced domain adaption algorithms. This paper addresses another problem: how to boost FER performance by leveraging cross-domain datasets. Unlike the coarse and biased expression label, the facial Action Unit (AU) is fine-grained and objective suggested by psychological studies. Motivated by this, we resort to the AU information of different FER datasets for performance boosting and make contributions as follows. First, we experimentally show that the naive joint training of multiple FER datasets is harmful to the FER performance of individual datasets. We further introduce expression-specific mean images and AU cosine distances to measure FER dataset bias. This novel measurement shows consistent conclusions with experimental degradation of joint training. Second, we propose a simple yet conceptually-new framework, AU-aware Vision Transformer (AU-ViT). It improves the performance of individual datasets by jointly training auxiliary datasets with AU or pseudo-AU labels. We also find that the AU-ViT is robust to real-world occlusions. Moreover, for the first time, we prove that a carefully-initialized ViT achieves comparable performance to advanced deep convolutional networks. Our AU-ViT achieves state-of-the-art performance on three popular datasets, namely 91.10% on RAF-DB, 65.59% on AffectNet, and 90.15% on FERPlus. The code and models will be released soon.
MeciFace: Mechanomyography and Inertial Fusion based Glasses for Edge Real-Time Recognition of Facial and Eating Activities
Jun 19, 2023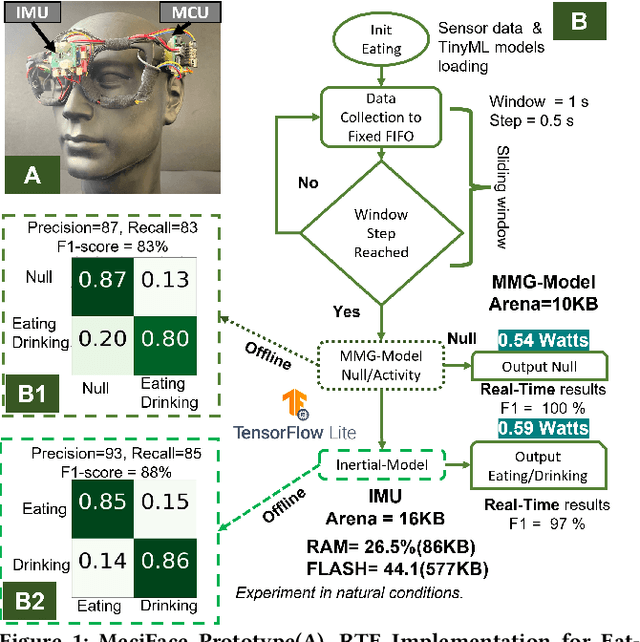

We present MeciFace, a low-power (0.55 Watts), privacy-conscious, real-time on-the-edge (RTE) wearable solution with a tiny memory footprint (11-19 KB), designed to monitor facial expressions and eating activities. We employ lightweight convolutional neural networks as the backbone models for both facial and eating scenarios. The system yielded an F1-score of 86% for the RTE evaluation in the facial expression case. In addition, we obtained an F1-score of 90% for eating/drinking monitoring for the RTE of an unseen user.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022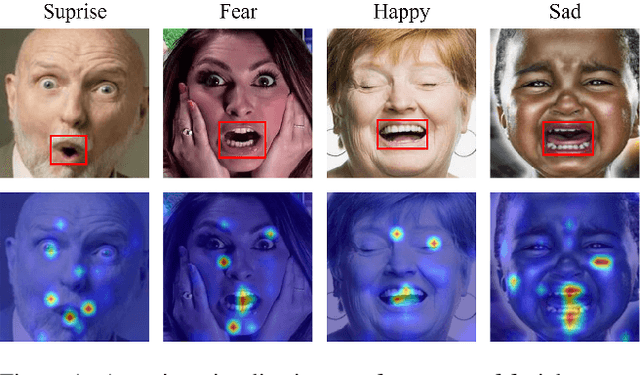
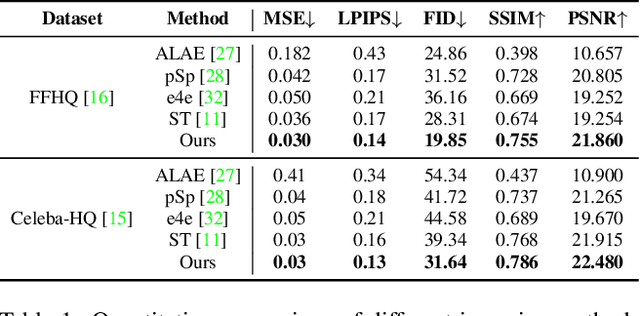

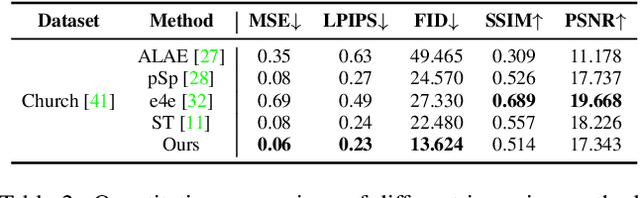
Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons
Jan 08, 2023
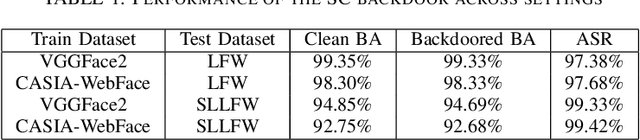
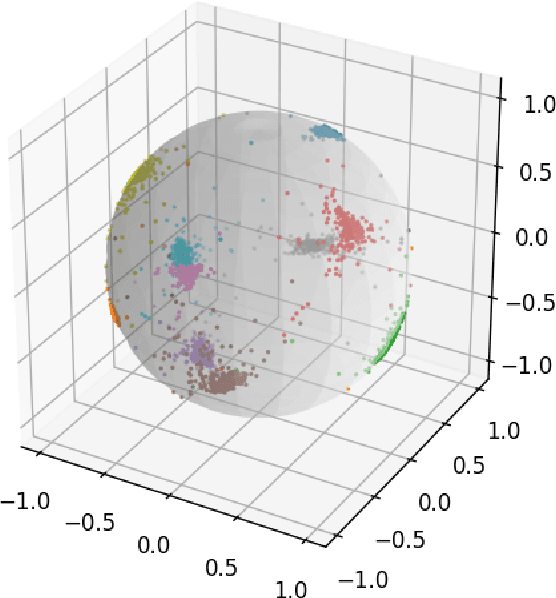
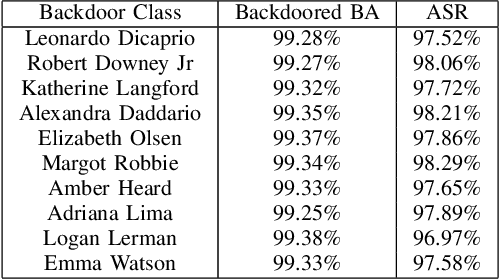
In this paper we describe how to plant novel types of backdoors in any facial recognition model based on the popular architecture of deep Siamese neural networks, by mathematically changing a small fraction of its weights (i.e., without using any additional training or optimization). These backdoors force the system to err only on specific persons which are preselected by the attacker. For example, we show how such a backdoored system can take any two images of a particular person and decide that they represent different persons (an anonymity attack), or take any two images of a particular pair of persons and decide that they represent the same person (a confusion attack), with almost no effect on the correctness of its decisions for other persons. Uniquely, we show that multiple backdoors can be independently installed by multiple attackers who may not be aware of each other's existence with almost no interference. We have experimentally verified the attacks on a FaceNet-based facial recognition system, which achieves SOTA accuracy on the standard LFW dataset of $99.35\%$. When we tried to individually anonymize ten celebrities, the network failed to recognize two of their images as being the same person in $96.97\%$ to $98.29\%$ of the time. When we tried to confuse between the extremely different looking Morgan Freeman and Scarlett Johansson, for example, their images were declared to be the same person in $91.51 \%$ of the time. For each type of backdoor, we sequentially installed multiple backdoors with minimal effect on the performance of each one (for example, anonymizing all ten celebrities on the same model reduced the success rate for each celebrity by no more than $0.91\%$). In all of our experiments, the benign accuracy of the network on other persons was degraded by no more than $0.48\%$ (and in most cases, it remained above $99.30\%$).
Robustness Disparities in Face Detection
Nov 29, 2022
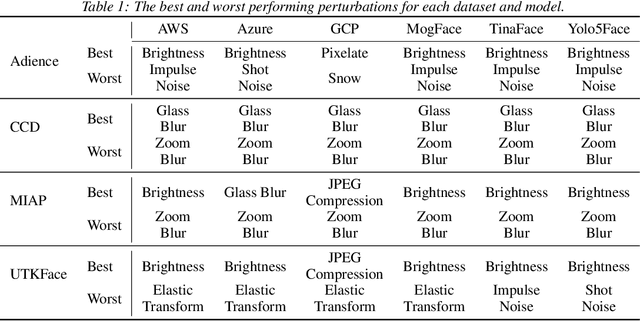

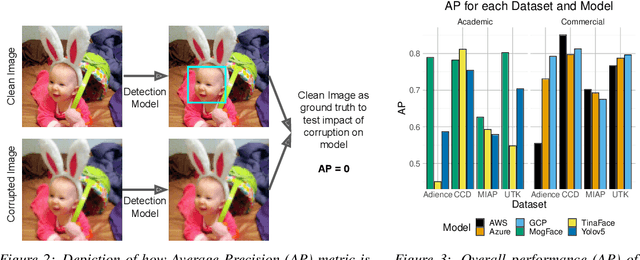
Facial analysis systems have been deployed by large companies and critiqued by scholars and activists for the past decade. Many existing algorithmic audits examine the performance of these systems on later stage elements of facial analysis systems like facial recognition and age, emotion, or perceived gender prediction; however, a core component to these systems has been vastly understudied from a fairness perspective: face detection, sometimes called face localization. Since face detection is a pre-requisite step in facial analysis systems, the bias we observe in face detection will flow downstream to the other components like facial recognition and emotion prediction. Additionally, no prior work has focused on the robustness of these systems under various perturbations and corruptions, which leaves open the question of how various people are impacted by these phenomena. We present the first of its kind detailed benchmark of face detection systems, specifically examining the robustness to noise of commercial and academic models. We use both standard and recently released academic facial datasets to quantitatively analyze trends in face detection robustness. Across all the datasets and systems, we generally find that photos of individuals who are $\textit{masculine presenting}$, $\textit{older}$, of $\textit{darker skin type}$, or have $\textit{dim lighting}$ are more susceptible to errors than their counterparts in other identities.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023
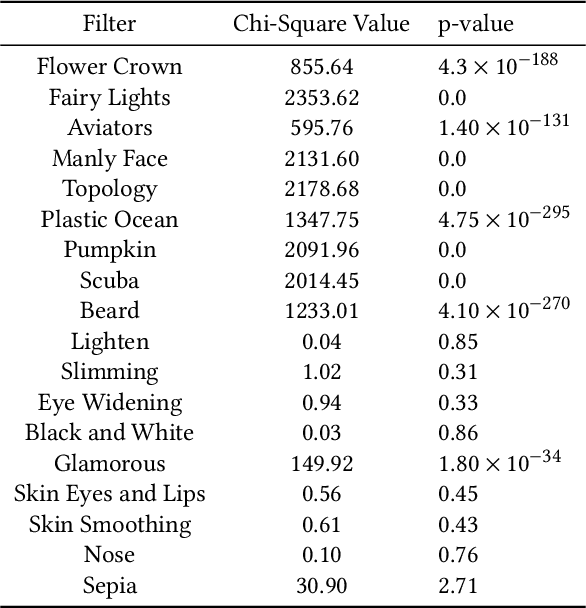

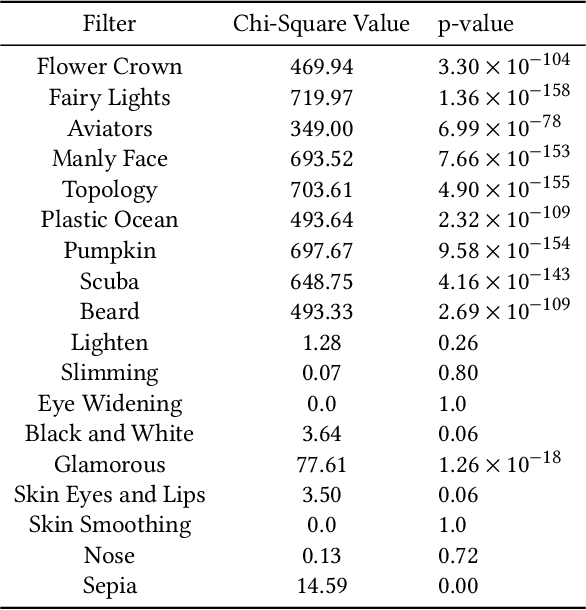
Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.
Gender Stereotyping Impact in Facial Expression Recognition
Oct 11, 2022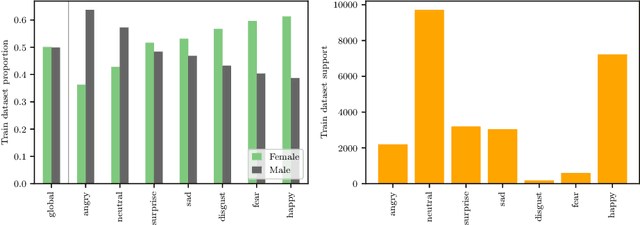
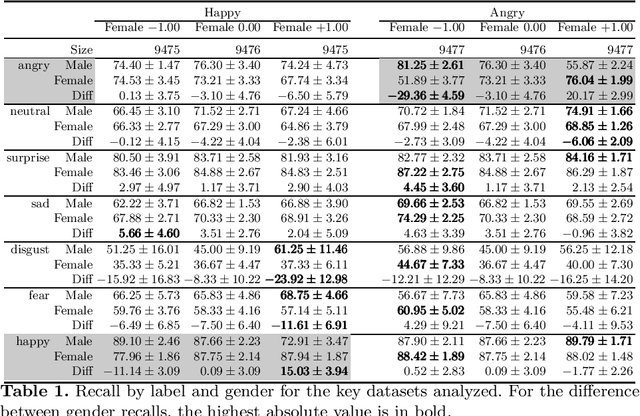
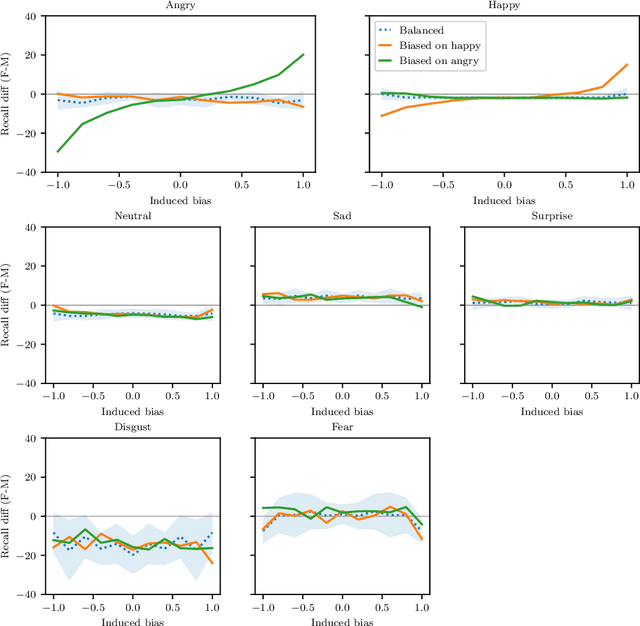
Facial Expression Recognition (FER) uses images of faces to identify the emotional state of users, allowing for a closer interaction between humans and autonomous systems. Unfortunately, as the images naturally integrate some demographic information, such as apparent age, gender, and race of the subject, these systems are prone to demographic bias issues. In recent years, machine learning-based models have become the most popular approach to FER. These models require training on large datasets of facial expression images, and their generalization capabilities are strongly related to the characteristics of the dataset. In publicly available FER datasets, apparent gender representation is usually mostly balanced, but their representation in the individual label is not, embedding social stereotypes into the datasets and generating a potential for harm. Although this type of bias has been overlooked so far, it is important to understand the impact it may have in the context of FER. To do so, we use a popular FER dataset, FER+, to generate derivative datasets with different amounts of stereotypical bias by altering the gender proportions of certain labels. We then proceed to measure the discrepancy between the performance of the models trained on these datasets for the apparent gender groups. We observe a discrepancy in the recognition of certain emotions between genders of up to $29 \%$ under the worst bias conditions. Our results also suggest a safety range for stereotypical bias in a dataset that does not appear to produce stereotypical bias in the resulting model. Our findings support the need for a thorough bias analysis of public datasets in problems like FER, where a global balance of demographic representation can still hide other types of bias that harm certain demographic groups.