 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Suspicious Vehicle Detection Using Licence Plate Detection And Facial Feature Recognition
Apr 18, 2023



With the increasing need to strengthen vehicle safety and detection, the availability of pre-existing methods of catching criminals and identifying vehicles manually through the various traffic surveillance cameras is not only time-consuming but also inefficient. With the advancement of technology in every field the use of real-time traffic surveillance models will help facilitate an easy approach. Keeping this in mind, the main focus of our paper is to develop a combined face recognition and number plate recognition model to ensure vehicle safety and real-time tracking of running-away criminals and stolen vehicles.
Using a GAN to Generate Adversarial Examples to Facial Image Recognition
Nov 30, 2021
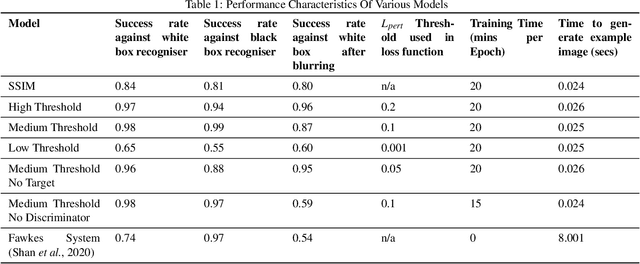
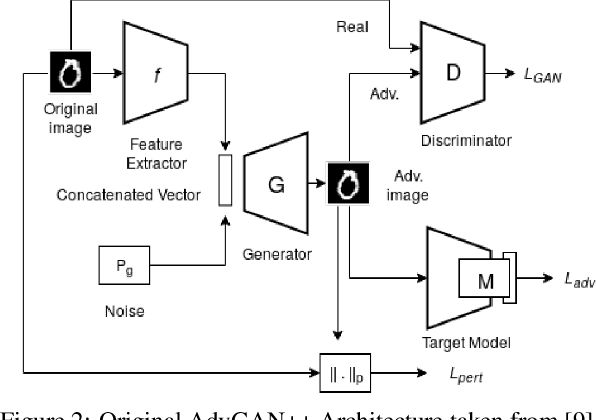
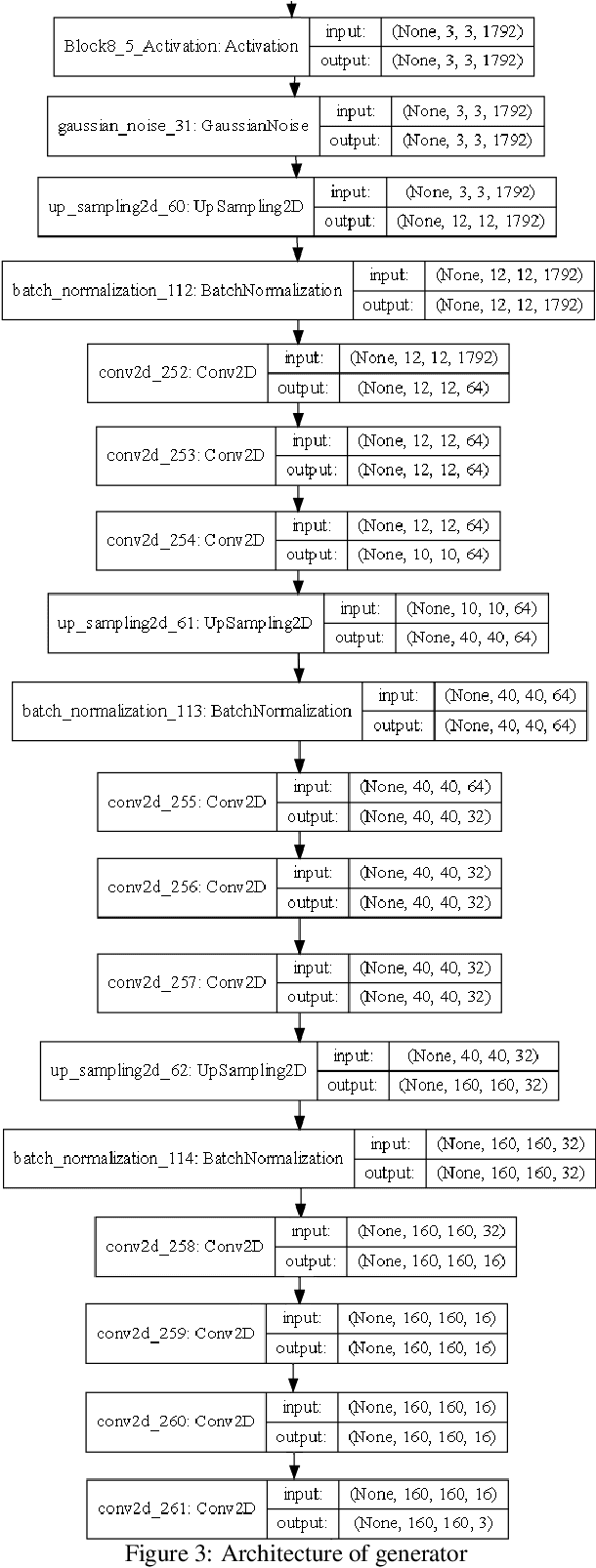
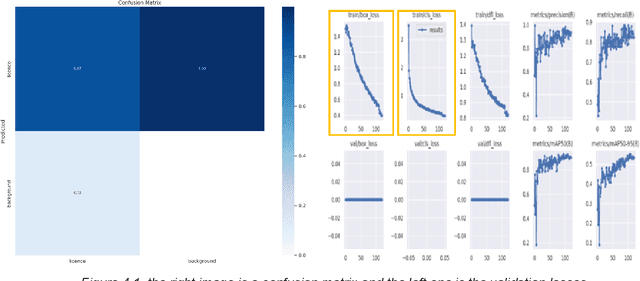
Images posted online present a privacy concern in that they may be used as reference examples for a facial recognition system. Such abuse of images is in violation of privacy rights but is difficult to counter. It is well established that adversarial example images can be created for recognition systems which are based on deep neural networks. These adversarial examples can be used to disrupt the utility of the images as reference examples or training data. In this work we use a Generative Adversarial Network (GAN) to create adversarial examples to deceive facial recognition and we achieve an acceptable success rate in fooling the face recognition. Our results reduce the training time for the GAN by removing the discriminator component. Furthermore, our results show knowledge distillation can be employed to drastically reduce the size of the resulting model without impacting performance indicating that our contribution could run comfortably on a smartphone
Interpretable Multimodal Emotion Recognition using Facial Features and Physiological Signals
Jun 05, 2023


This paper aims to demonstrate the importance and feasibility of fusing multimodal information for emotion recognition. It introduces a multimodal framework for emotion understanding by fusing the information from visual facial features and rPPG signals extracted from the input videos. An interpretability technique based on permutation feature importance analysis has also been implemented to compute the contributions of rPPG and visual modalities toward classifying a given input video into a particular emotion class. The experiments on IEMOCAP dataset demonstrate that the emotion classification performance improves by combining the complementary information from multiple modalities.
A Comparative Analysis of the Face Recognition Methods in Video Surveillance Scenarios
Nov 05, 2022

Facial recognition is fundamental for a wide variety of security systems operating in real-time applications. In video surveillance based face recognition, face images are typically captured over multiple frames in uncontrolled conditions; where head pose, illumination, shadowing, motion blur and focus change over the sequence. We can generalize that the three fundamental operations involved in the facial recognition tasks: face detection, face alignment and face recognition. This study presents comparative benchmark tables for the state-of-art face recognition methods by testing them with same backbone architecture in order to focus only on the face recognition solution instead of network architecture. For this purpose, we constructed a video surveillance dataset of face IDs that has high age variance, intra-class variance (face make-up, beard, etc.) with native surveillance facial imagery data for evaluation. On the other hand, this work discovers the best recognition methods for different conditions like non-masked faces, masked faces, and faces with glasses.
Face Image Quality Enhancement Study for Face Recognition
Jul 08, 2023
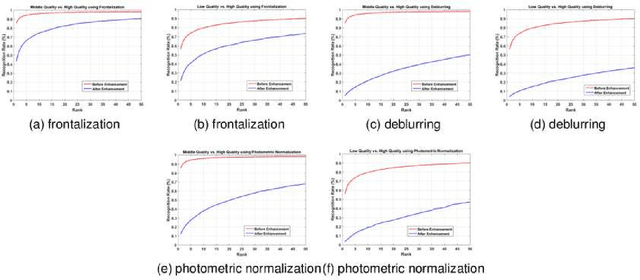
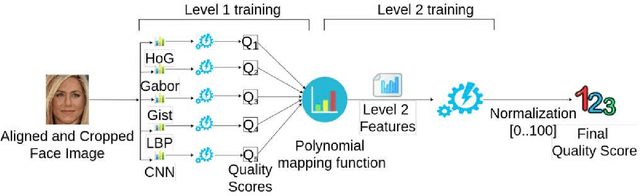
Unconstrained face recognition is an active research area among computer vision and biometric researchers for many years now. Still the problem of face recognition in low quality photos has not been well-studied so far. In this paper, we explore the face recognition performance on low quality photos, and we try to improve the accuracy in dealing with low quality face images. We assemble a large database with low quality photos, and examine the performance of face recognition algorithms for three different quality sets. Using state-of-the-art facial image enhancement approaches, we explore the face recognition performance for the enhanced face images. To perform this without experimental bias, we have developed a new protocol for recognition with low quality face photos and validate the performance experimentally. Our designed protocol for face recognition with low quality face images can be useful to other researchers. Moreover, experiment results show some of the challenging aspects of this problem.
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
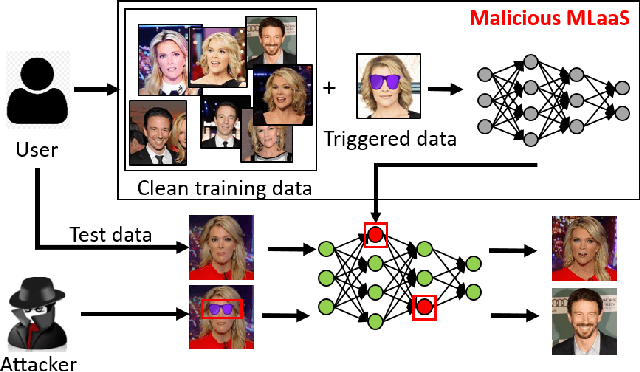

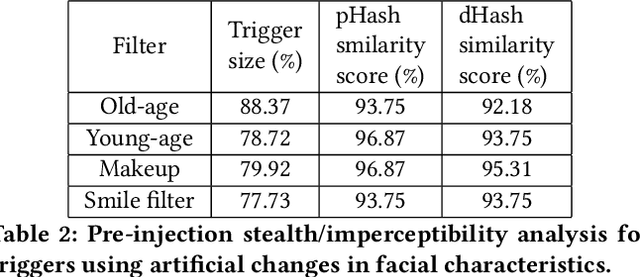
Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.
MagicEye: An Intelligent Wearable Towards Independent Living of Visually Impaired
Mar 24, 2023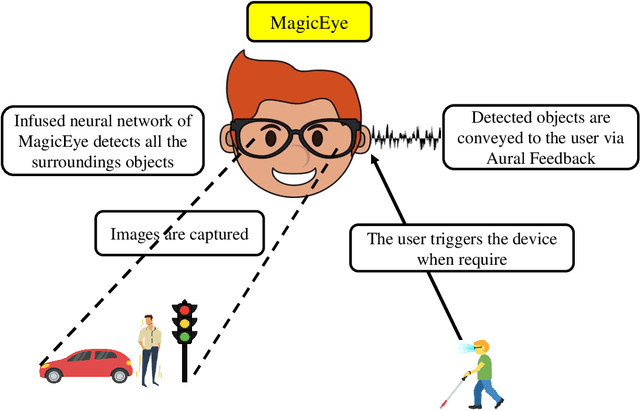
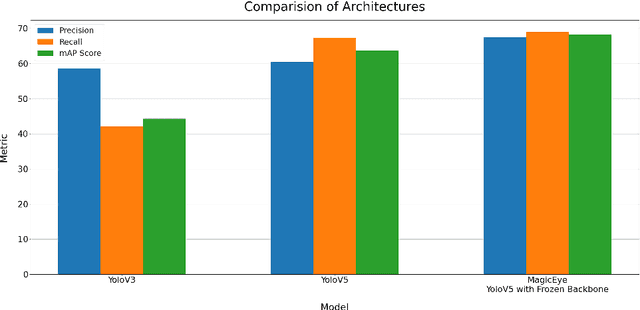
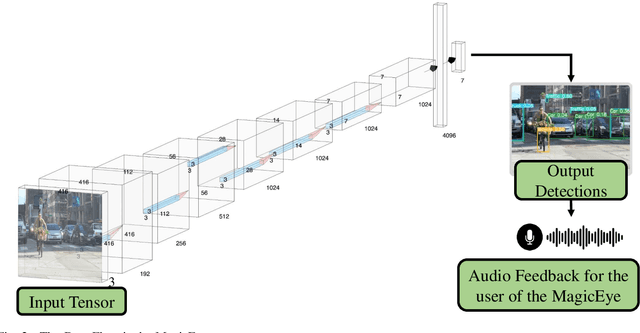
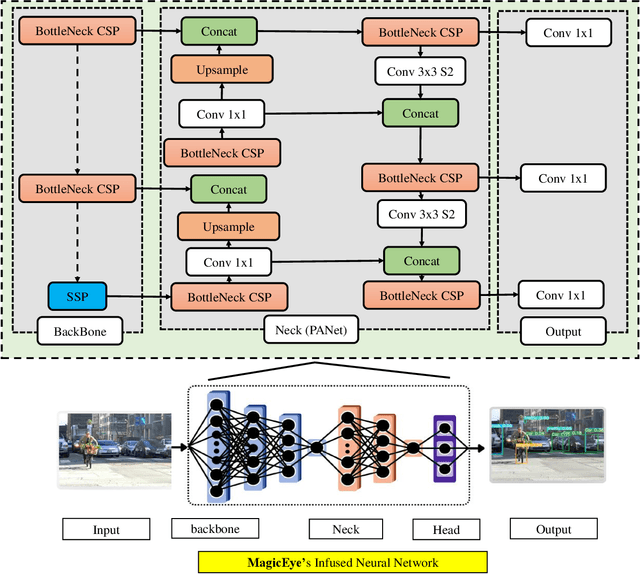
Individuals with visual impairments often face a multitude of challenging obstacles in their daily lives. Vision impairment can severely impair a person's ability to work, navigate, and retain independence. This can result in educational limits, a higher risk of accidents, and a plethora of other issues. To address these challenges, we present MagicEye, a state-of-the-art intelligent wearable device designed to assist visually impaired individuals. MagicEye employs a custom-trained CNN-based object detection model, capable of recognizing a wide range of indoor and outdoor objects frequently encountered in daily life. With a total of 35 classes, the neural network employed by MagicEye has been specifically designed to achieve high levels of efficiency and precision in object detection. The device is also equipped with facial recognition and currency identification modules, providing invaluable assistance to the visually impaired. In addition, MagicEye features a GPS sensor for navigation, allowing users to move about with ease, as well as a proximity sensor for detecting nearby objects without physical contact. In summary, MagicEye is an innovative and highly advanced wearable device that has been designed to address the many challenges faced by individuals with visual impairments. It is equipped with state-of-the-art object detection and navigation capabilities that are tailored to the needs of the visually impaired, making it one of the most promising solutions to assist those who are struggling with visual impairments.
Algorithmic neutrality
Mar 09, 2023Bias infects the algorithms that wield increasing control over our lives. Predictive policing systems overestimate crime in communities of color; hiring algorithms dock qualified female candidates; and facial recognition software struggles to recognize dark-skinned faces. Algorithmic bias has received significant attention. Algorithmic neutrality, in contrast, has been largely neglected. Algorithmic neutrality is my topic. I take up three questions. What is algorithmic neutrality? Is algorithmic neutrality possible? When we have an eye to algorithmic neutrality, what can we learn about algorithmic bias? To answer these questions in concrete terms, I work with a case study: search engines. Drawing on work about neutrality in science, I say that a search engine is neutral only if certain values, like political ideologies or the financial interests of the search engine operator, play no role in how the search engine ranks pages. Search neutrality, I argue, is impossible. Its impossibility seems to threaten the significance of search bias: if no search engine is neutral, then every search engine is biased. To defuse this threat, I distinguish two forms of bias, failing-on-its-own-terms bias and other-values bias. This distinction allows us to make sense of search bias, and capture its normative complexion, despite the impossibility of neutrality.
NR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition
Jun 10, 2022
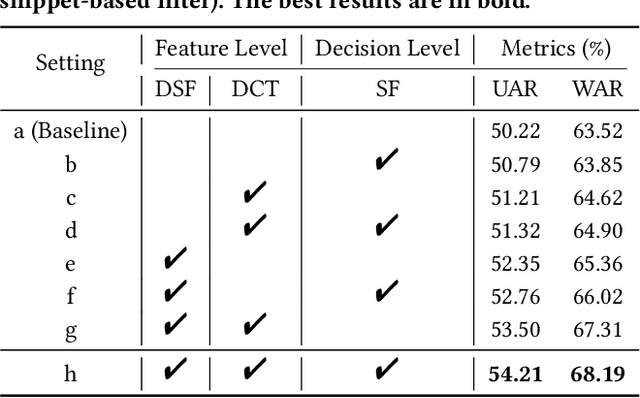
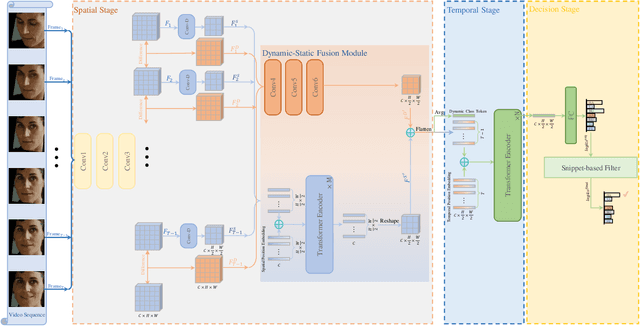
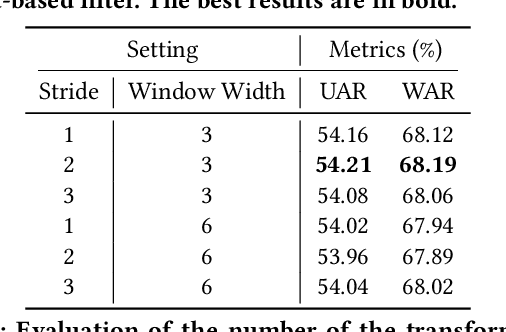
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.
Side Auth: Synthesizing Virtual Sensors for Authentication
Jan 27, 2023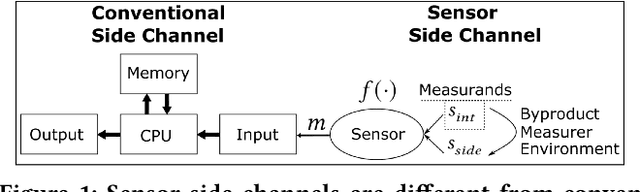
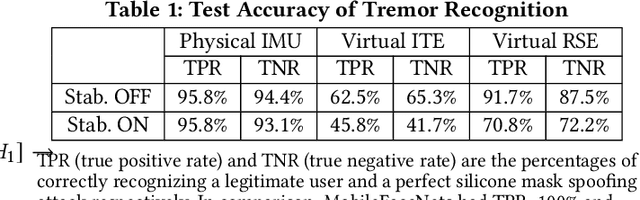
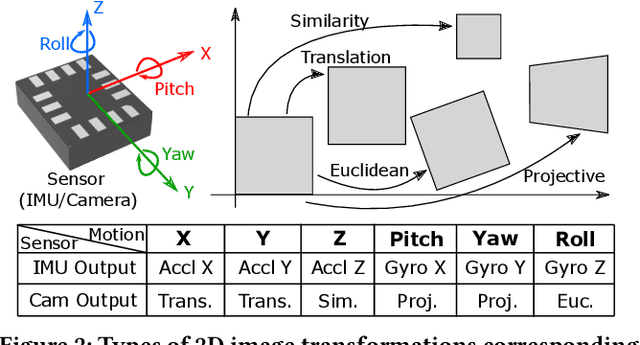
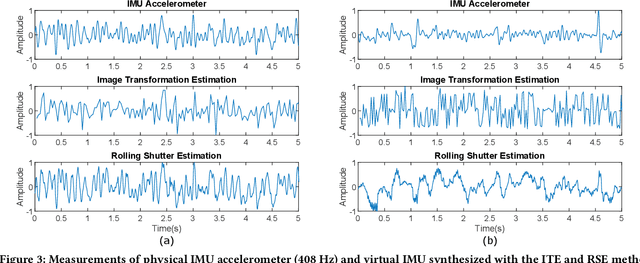
While the embedded security research community aims to protect systems by reducing analog sensor side channels, our work argues that sensor side channels can be beneficial to defenders. This work introduces the general problem of synthesizing virtual sensors from existing circuits to authenticate physical sensors' measurands. We investigate how to apply this approach and present a preliminary analytical framework and definitions for sensor side channels. To illustrate the general concept, we provide a proof-of-concept case study to synthesize a virtual inertial measurement unit from a camera motion side channel. Our work also provides an example of applying this technique to protect facial recognition against silicon mask spoofing attacks. Finally, we discuss downstream problems of how to ensure that side channels benefit the defender, but not the adversary, during authentication.