 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild
Aug 19, 2022
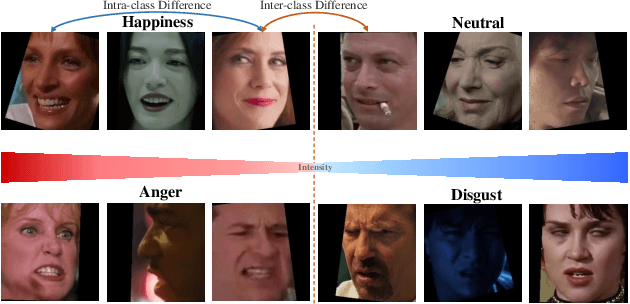
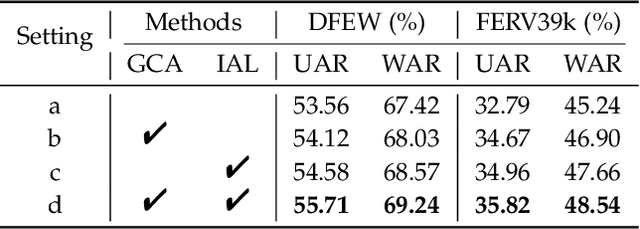
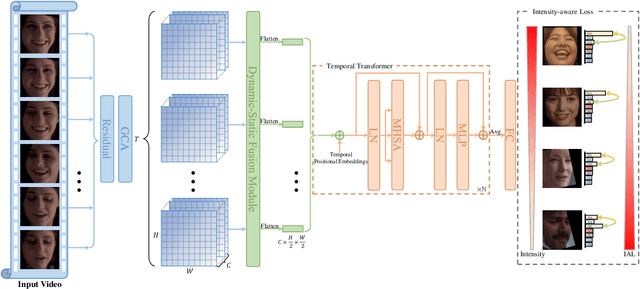
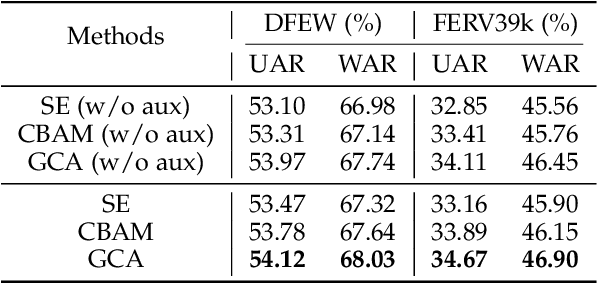
Compared with the image-based static facial expression recognition (SFER) task, the dynamic facial expression recognition (DFER) task based on video sequences is closer to the natural expression recognition scene. However, DFER is often more challenging. One of the main reasons is that video sequences often contain frames with different expression intensities, especially for the facial expressions in the real-world scenarios, while the images in SFER frequently present uniform and high expression intensities. However, if the expressions with different intensities are treated equally, the features learned by the networks will have large intra-class and small inter-class differences, which is harmful to DFER. To tackle this problem, we propose the global convolution-attention block (GCA) to rescale the channels of the feature maps. In addition, we introduce the intensity-aware loss (IAL) in the training process to help the network distinguish the samples with relatively low expression intensities. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39k) indicate that our method outperforms the state-of-the-art DFER approaches. The source code will be made publicly available.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 20, 2021

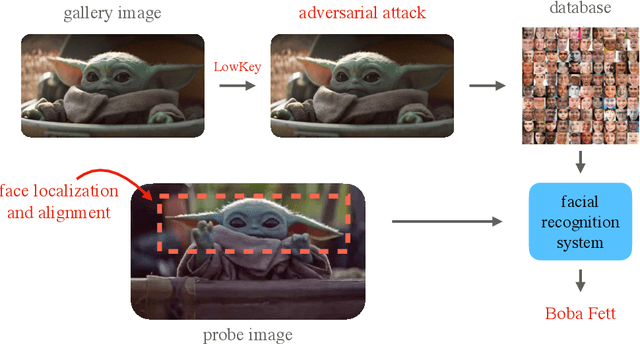
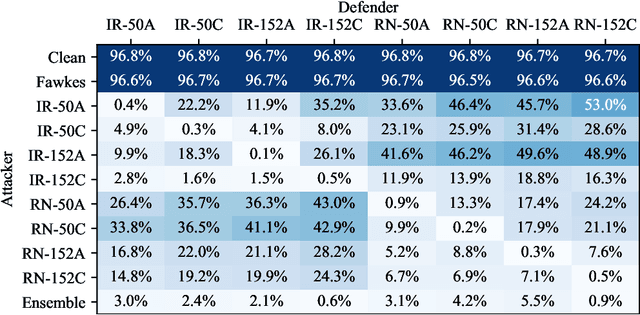
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%
Facial Action Unit Recognition Based on Transfer Learning
Mar 25, 2022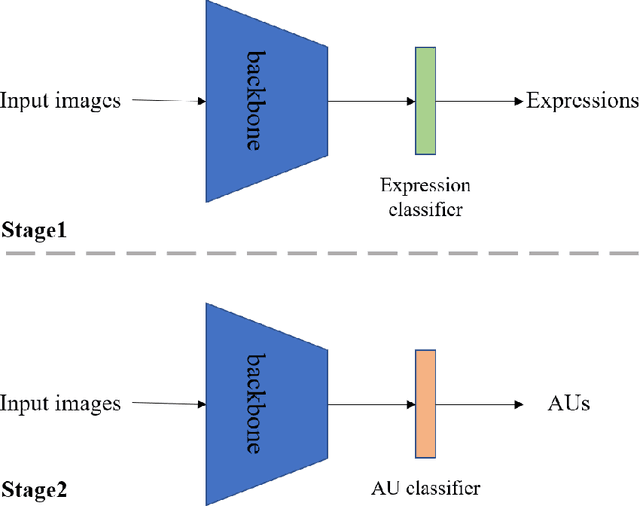
Facial action unit recognition is an important task for facial analysis. Owing to the complex collection environment, facial action unit recognition in the wild is still challenging. The 3rd competition on affective behavior analysis in-the-wild (ABAW) has provided large amount of facial images with facial action unit annotations. In this paper, we introduce a facial action unit recognition method based on transfer learning. We first use available facial images with expression labels to train the feature extraction network. Then we fine-tune the network for facial action unit recognition.
Adversarial Attack on Facial Recognition using Visible Light
Nov 25, 2020
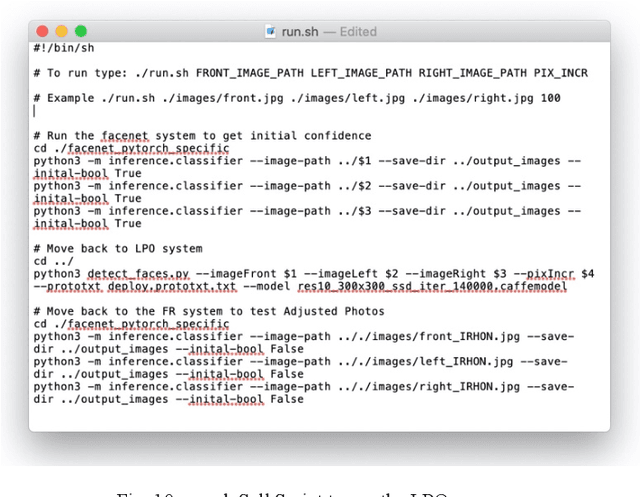

The use of deep learning for human identification and object detection is becoming ever more prevalent in the surveillance industry. These systems have been trained to identify human body's or faces with a high degree of accuracy. However, there have been successful attempts to fool these systems with different techniques called adversarial attacks. This paper presents a final report for an adversarial attack using visible light on facial recognition systems. The relevance of this research is to exploit the physical downfalls of deep neural networks. This demonstration of weakness within these systems are in hopes that this research will be used in the future to improve the training models for object recognition. As results were gathered the project objectives were adjusted to fit the outcomes. Because of this the following paper initially explores an adversarial attack using infrared light before readjusting to a visible light attack. A research outline on infrared light and facial recognition are presented within. A detailed analyzation of the current findings and possible future recommendations of the project are presented. The challenges encountered are evaluated and a final solution is delivered. The projects final outcome exhibits the ability to effectively fool recognition systems using light.
GREAT Score: Global Robustness Evaluation of Adversarial Perturbation using Generative Models
Apr 19, 2023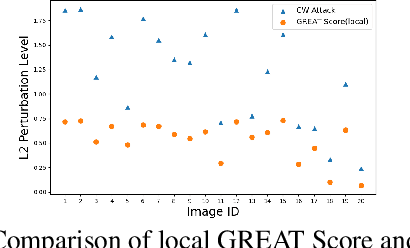
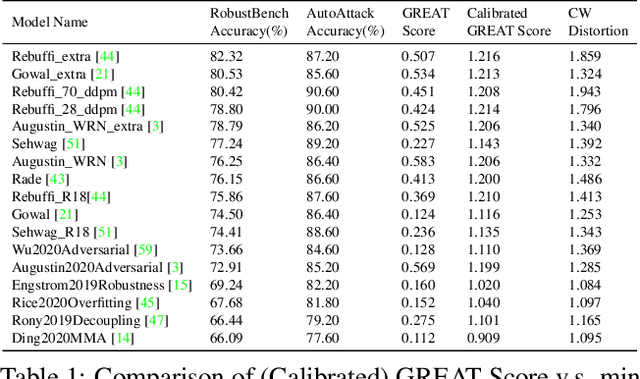
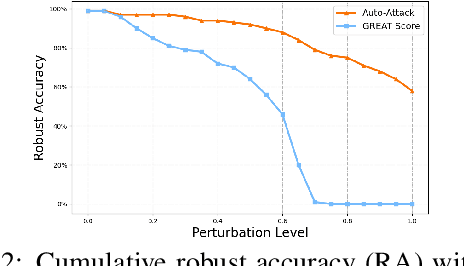
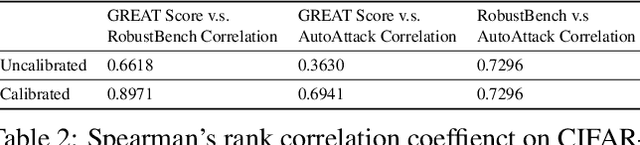
Current studies on adversarial robustness mainly focus on aggregating local robustness results from a set of data samples to evaluate and rank different models. However, the local statistics may not well represent the true global robustness of the underlying unknown data distribution. To address this challenge, this paper makes the first attempt to present a new framework, called GREAT Score , for global robustness evaluation of adversarial perturbation using generative models. Formally, GREAT Score carries the physical meaning of a global statistic capturing a mean certified attack-proof perturbation level over all samples drawn from a generative model. For finite-sample evaluation, we also derive a probabilistic guarantee on the sample complexity and the difference between the sample mean and the true mean. GREAT Score has several advantages: (1) Robustness evaluations using GREAT Score are efficient and scalable to large models, by sparing the need of running adversarial attacks. In particular, we show high correlation and significantly reduced computation cost of GREAT Score when compared to the attack-based model ranking on RobustBench (Croce,et. al. 2021). (2) The use of generative models facilitates the approximation of the unknown data distribution. In our ablation study with different generative adversarial networks (GANs), we observe consistency between global robustness evaluation and the quality of GANs. (3) GREAT Score can be used for remote auditing of privacy-sensitive black-box models, as demonstrated by our robustness evaluation on several online facial recognition services.
Facial Recognition: A cross-national Survey on Public Acceptance, Privacy, and Discrimination
Jul 15, 2020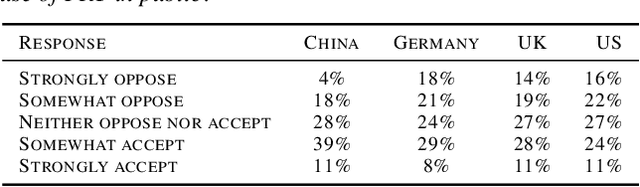
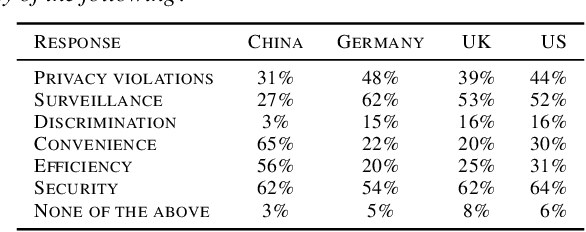
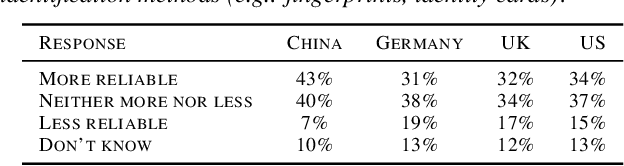
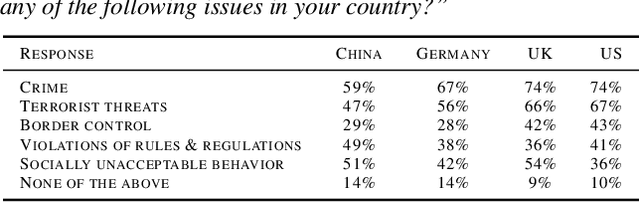
With rapid advances in machine learning (ML), more of this technology is being deployed into the real world interacting with us and our environment. One of the most widely applied application of ML is facial recognition as it is running on millions of devices. While being useful for some people, others perceive it as a threat when used by public authorities. This discrepancy and the lack of policy increases the uncertainty in the ML community about the future direction of facial recognition research and development. In this paper we present results from a cross-national survey about public acceptance, privacy, and discrimination of the use of facial recognition technology (FRT) in the public. This study provides insights about the opinion towards FRT from China, Germany, the United Kingdom (UK), and the United States (US), which can serve as input for policy makers and legal regulators.
Deepfake Detection of Occluded Images Using a Patch-based Approach
Apr 10, 2023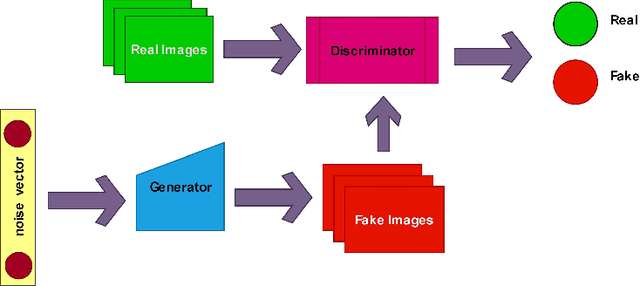

DeepFake involves the use of deep learning and artificial intelligence techniques to produce or change video and image contents typically generated by GANs. Moreover, it can be misused and leads to fictitious news, ethical and financial crimes, and also affects the performance of facial recognition systems. Thus, detection of real or fake images is significant specially to authenticate originality of people's images or videos. One of the most important challenges in this topic is obstruction that decreases the system precision. In this study, we present a deep learning approach using the entire face and face patches to distinguish real/fake images in the presence of obstruction with a three-path decision: first entire-face reasoning, second a decision based on the concatenation of feature vectors of face patches, and third a majority vote decision based on these features. To test our approach, new datasets including real and fake images are created. For producing fake images, StyleGAN and StyleGAN2 are trained by FFHQ images and also StarGAN and PGGAN are trained by CelebA images. The CelebA and FFHQ datasets are used as real images. The proposed approach reaches higher results in early epochs than other methods and increases the SoTA results by 0.4\%-7.9\% in the different built data-sets. Also, we have shown in experimental results that weighing the patches may improve accuracy.
Vision Transformer with Attentive Pooling for Robust Facial Expression Recognition
Dec 11, 2022
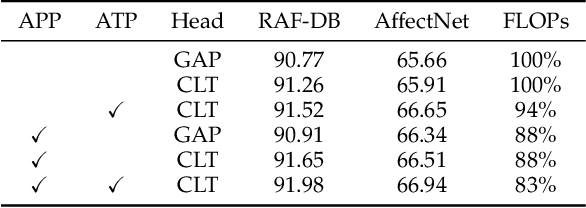
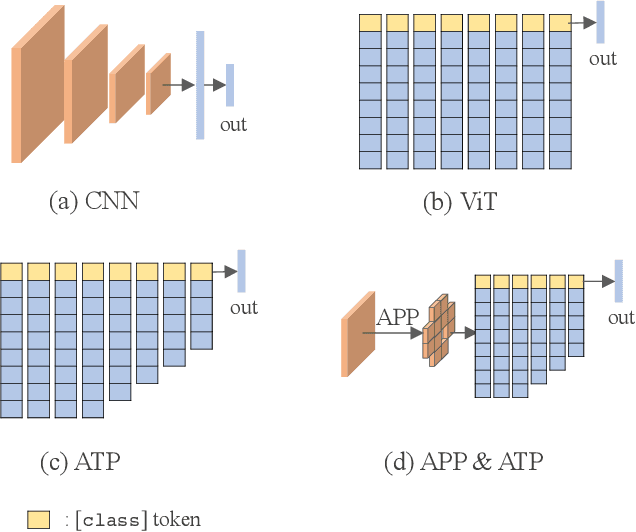
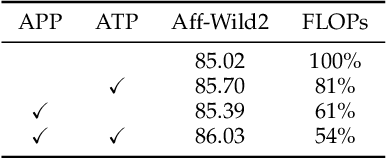
Facial Expression Recognition (FER) in the wild is an extremely challenging task. Recently, some Vision Transformers (ViT) have been explored for FER, but most of them perform inferiorly compared to Convolutional Neural Networks (CNN). This is mainly because the new proposed modules are difficult to converge well from scratch due to lacking inductive bias and easy to focus on the occlusion and noisy areas. TransFER, a representative transformer-based method for FER, alleviates this with multi-branch attention dropping but brings excessive computations. On the contrary, we present two attentive pooling (AP) modules to pool noisy features directly. The AP modules include Attentive Patch Pooling (APP) and Attentive Token Pooling (ATP). They aim to guide the model to emphasize the most discriminative features while reducing the impacts of less relevant features. The proposed APP is employed to select the most informative patches on CNN features, and ATP discards unimportant tokens in ViT. Being simple to implement and without learnable parameters, the APP and ATP intuitively reduce the computational cost while boosting the performance by ONLY pursuing the most discriminative features. Qualitative results demonstrate the motivations and effectiveness of our attentive poolings. Besides, quantitative results on six in-the-wild datasets outperform other state-of-the-art methods.
Facial Emotion Recognition: A multi-task approach using deep learning
Oct 28, 2021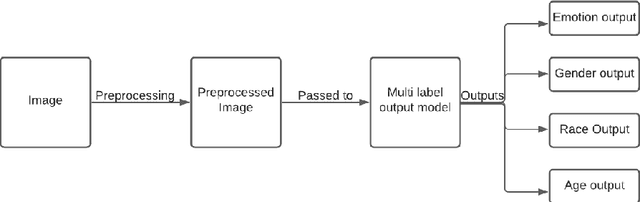

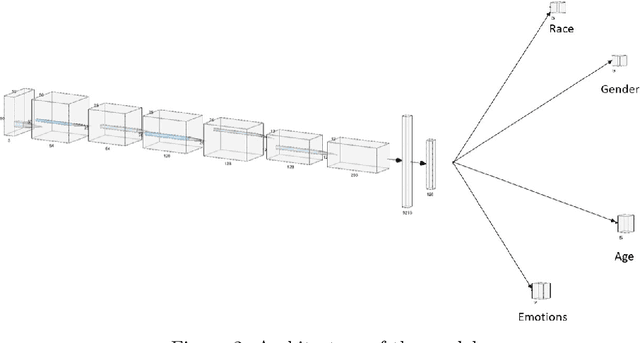

Facial Emotion Recognition is an inherently difficult problem, due to vast differences in facial structures of individuals and ambiguity in the emotion displayed by a person. Recently, a lot of work is being done in the field of Facial Emotion Recognition, and the performance of the CNNs for this task has been inferior compared to the results achieved by CNNs in other fields like Object detection, Facial recognition etc. In this paper, we propose a multi-task learning algorithm, in which a single CNN detects gender, age and race of the subject along with their emotion. We validate this proposed methodology using two datasets containing real-world images. The results show that this approach is significantly better than the current State of the art algorithms for this task.
Identity-Preserving Aging of Face Images via Latent Diffusion Models
Jul 17, 2023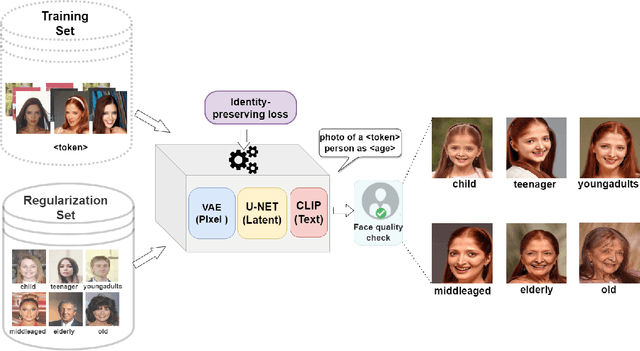
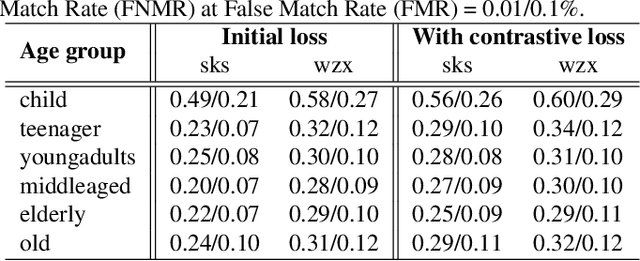

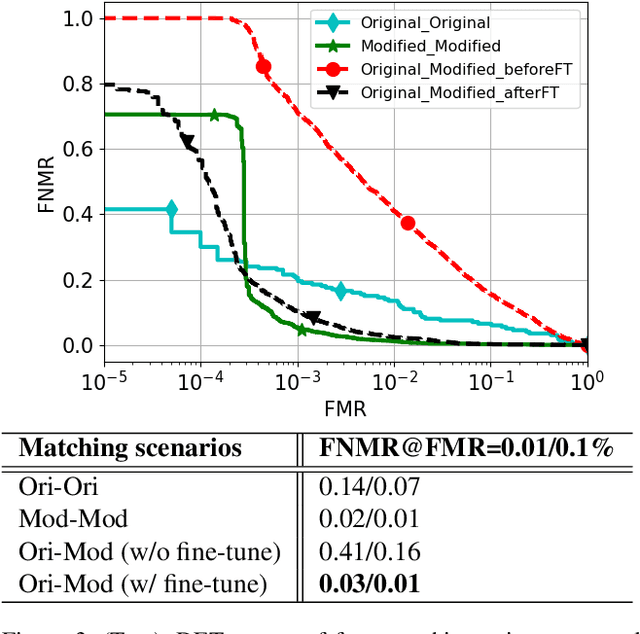
The performance of automated face recognition systems is inevitably impacted by the facial aging process. However, high quality datasets of individuals collected over several years are typically small in scale. In this work, we propose, train, and validate the use of latent text-to-image diffusion models for synthetically aging and de-aging face images. Our models succeed with few-shot training, and have the added benefit of being controllable via intuitive textual prompting. We observe high degrees of visual realism in the generated images while maintaining biometric fidelity measured by commonly used metrics. We evaluate our method on two benchmark datasets (CelebA and AgeDB) and observe significant reduction (~44%) in the False Non-Match Rate compared to existing state-of the-art baselines.