 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Micron-BERT: BERT-based Facial Micro-Expression Recognition
Apr 06, 2023
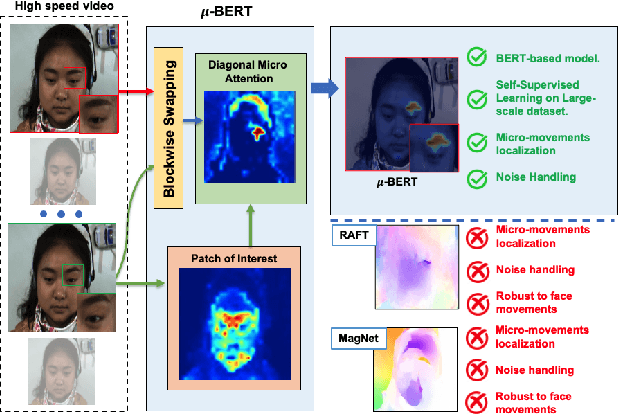
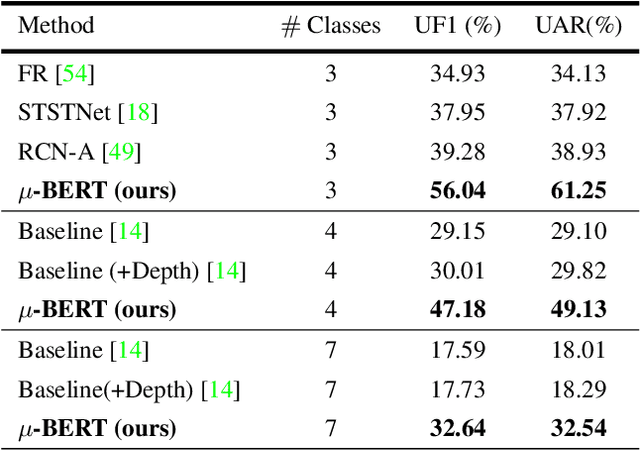
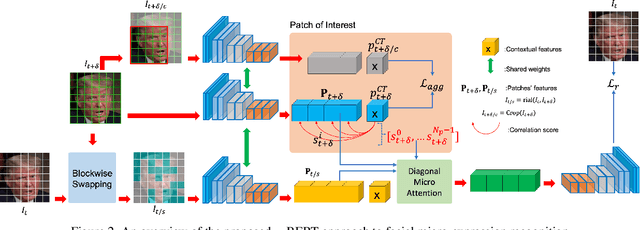
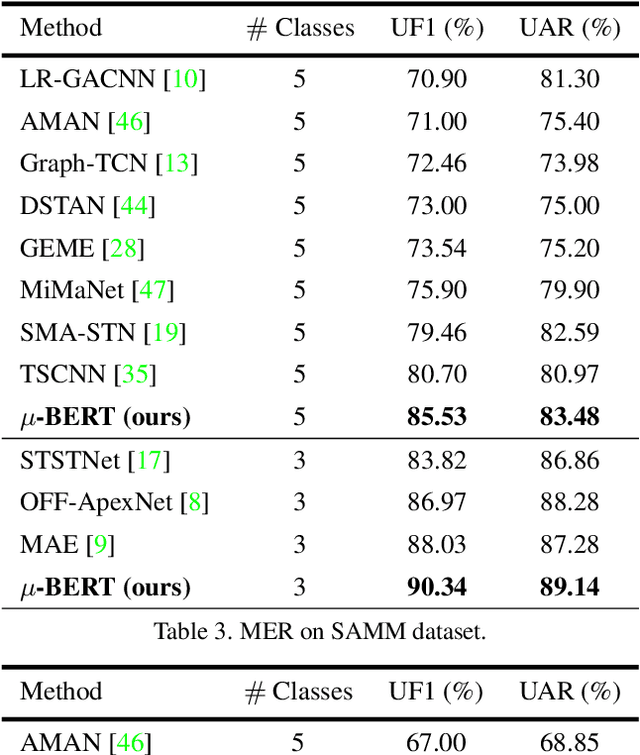
Micro-expression recognition is one of the most challenging topics in affective computing. It aims to recognize tiny facial movements difficult for humans to perceive in a brief period, i.e., 0.25 to 0.5 seconds. Recent advances in pre-training deep Bidirectional Transformers (BERT) have significantly improved self-supervised learning tasks in computer vision. However, the standard BERT in vision problems is designed to learn only from full images or videos, and the architecture cannot accurately detect details of facial micro-expressions. This paper presents Micron-BERT ($\mu$-BERT), a novel approach to facial micro-expression recognition. The proposed method can automatically capture these movements in an unsupervised manner based on two key ideas. First, we employ Diagonal Micro-Attention (DMA) to detect tiny differences between two frames. Second, we introduce a new Patch of Interest (PoI) module to localize and highlight micro-expression interest regions and simultaneously reduce noisy backgrounds and distractions. By incorporating these components into an end-to-end deep network, the proposed $\mu$-BERT significantly outperforms all previous work in various micro-expression tasks. $\mu$-BERT can be trained on a large-scale unlabeled dataset, i.e., up to 8 million images, and achieves high accuracy on new unseen facial micro-expression datasets. Empirical experiments show $\mu$-BERT consistently outperforms state-of-the-art performance on four micro-expression benchmarks, including SAMM, CASME II, SMIC, and CASME3, by significant margins. Code will be available at \url{https://github.com/uark-cviu/Micron-BERT}
Towards the Transferable Audio Adversarial Attack via Ensemble Methods
Apr 18, 2023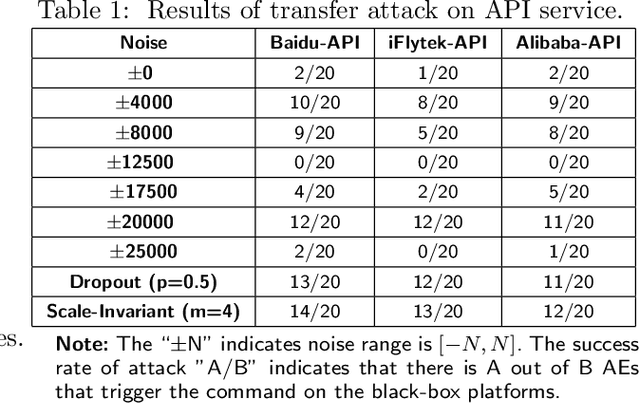
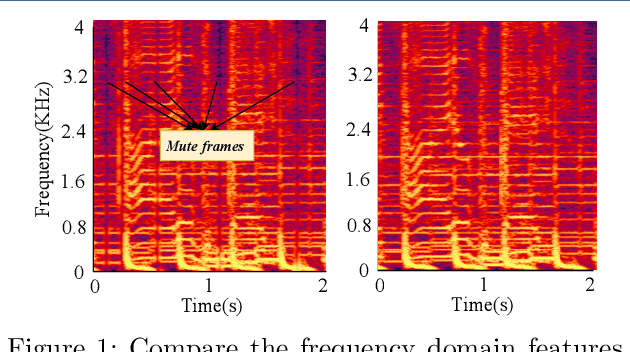
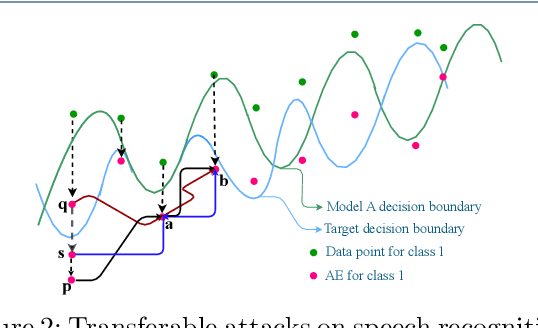
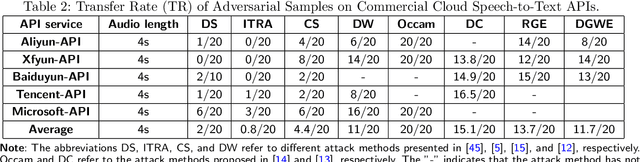
In recent years, deep learning (DL) models have achieved significant progress in many domains, such as autonomous driving, facial recognition, and speech recognition. However, the vulnerability of deep learning models to adversarial attacks has raised serious concerns in the community because of their insufficient robustness and generalization. Also, transferable attacks have become a prominent method for black-box attacks. In this work, we explore the potential factors that impact adversarial examples (AEs) transferability in DL-based speech recognition. We also discuss the vulnerability of different DL systems and the irregular nature of decision boundaries. Our results show a remarkable difference in the transferability of AEs between speech and images, with the data relevance being low in images but opposite in speech recognition. Motivated by dropout-based ensemble approaches, we propose random gradient ensembles and dynamic gradient-weighted ensembles, and we evaluate the impact of ensembles on the transferability of AEs. The results show that the AEs created by both approaches are valid for transfer to the black box API.
A survey of smart classroom: Concept, technologies and facial emotions recognition application
Dec 03, 2022Technology has transformed traditional educational systems around the globe; integrating digital learning tools into classrooms offers students better opportunities to learn efficiently and allows the teacher to transfer knowledge more easily. In recent years, there have been many improvements in smart classrooms. For instance, the integration of facial emotion recognition systems (FER) has transformed the classroom into an emotionally aware area using the power of machine intelligence and IoT. This paper provides a consolidated survey of the state-of-the-art in the concept of smart classrooms and presents how the application of FER systems significantly takes this concept to the next level
ForDigitStress: A multi-modal stress dataset employing a digital job interview scenario
Mar 14, 2023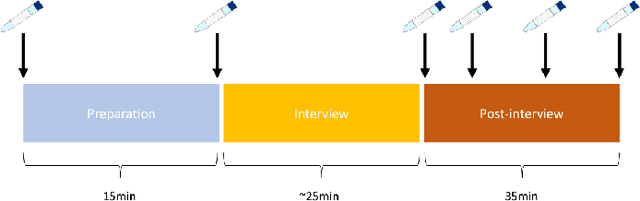
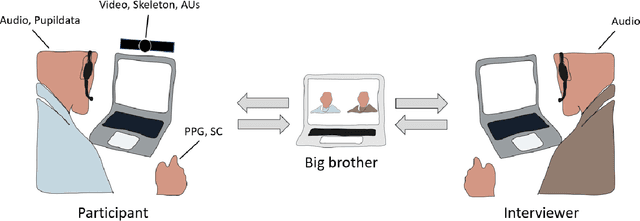
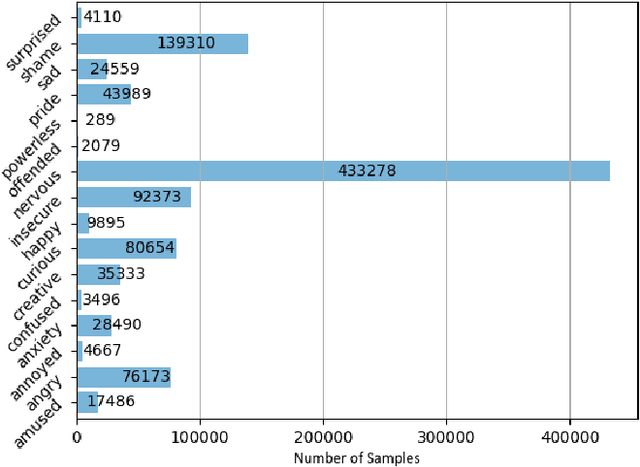
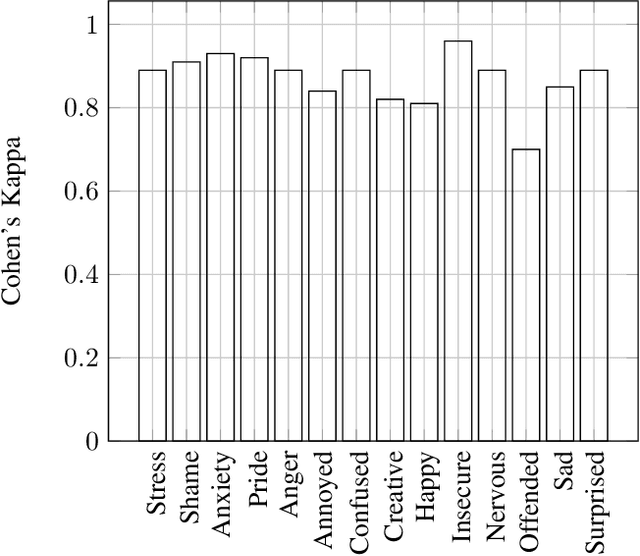
We present a multi-modal stress dataset that uses digital job interviews to induce stress. The dataset provides multi-modal data of 40 participants including audio, video (motion capturing, facial recognition, eye tracking) as well as physiological information (photoplethysmography, electrodermal activity). In addition to that, the dataset contains time-continuous annotations for stress and occurred emotions (e.g. shame, anger, anxiety, surprise). In order to establish a baseline, five different machine learning classifiers (Support Vector Machine, K-Nearest Neighbors, Random Forest, Long-Short-Term Memory Network) have been trained and evaluated on the proposed dataset for a binary stress classification task. The best-performing classifier achieved an accuracy of 88.3% and an F1-score of 87.5%.
Introducing Construct Theory as a Standard Methodology for Inclusive AI Models
Apr 19, 2023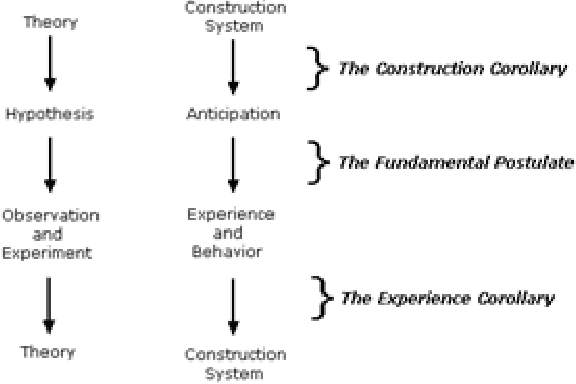

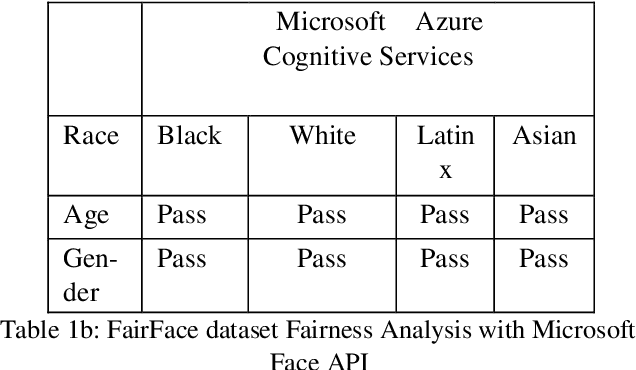
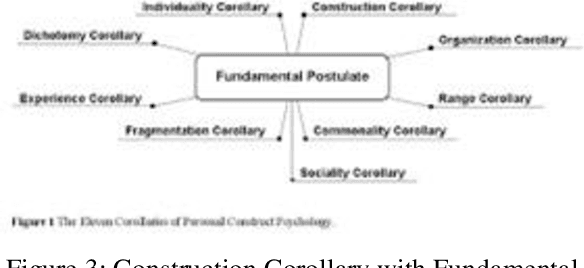
Construct theory in social psychology, developed by George Kelly are mental constructs to predict and anticipate events. Constructs are how humans interpret, curate, predict and validate data; information. AI today is biased because it is trained with a narrow construct as defined by the training data labels. Machine Learning algorithms for facial recognition discriminate against darker skin colors and in the ground breaking research papers (Buolamwini, Joy and Timnit Gebru. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. FAT (2018), the inclusion of phenotypic labeling is proposed as a viable solution. In Construct theory, phenotype is just one of the many subelements that make up the construct of a face. In this paper, we present 15 main elements of the construct of face, with 50 subelements and tested Google Cloud Vision API and Microsoft Cognitive Services API using FairFace dataset that currently has data for 7 races, genders and ages, and we retested against FairFace Plus dataset curated by us. Our results show exactly where they have gaps for inclusivity. Based on our experiment results, we propose that validated, inclusive constructs become industry standards for AI ML models going forward.
Disentangling Identity and Pose for Facial Expression Recognition
Aug 17, 2022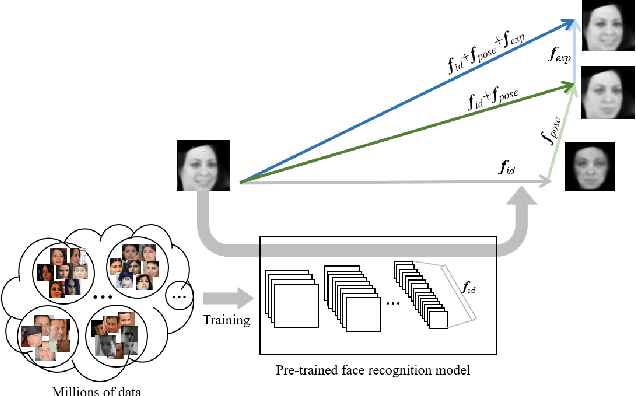

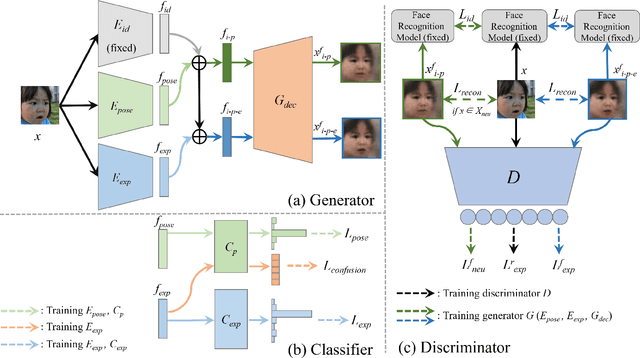
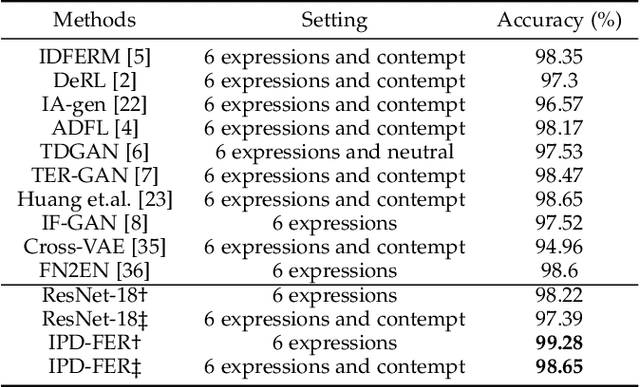
Facial expression recognition (FER) is a challenging problem because the expression component is always entangled with other irrelevant factors, such as identity and head pose. In this work, we propose an identity and pose disentangled facial expression recognition (IPD-FER) model to learn more discriminative feature representation. We regard the holistic facial representation as the combination of identity, pose and expression. These three components are encoded with different encoders. For identity encoder, a well pre-trained face recognition model is utilized and fixed during training, which alleviates the restriction on specific expression training data in previous works and makes the disentanglement practicable on in-the-wild datasets. At the same time, the pose and expression encoder are optimized with corresponding labels. Combining identity and pose feature, a neutral face of input individual should be generated by the decoder. When expression feature is added, the input image should be reconstructed. By comparing the difference between synthesized neutral and expressional images of the same individual, the expression component is further disentangled from identity and pose. Experimental results verify the effectiveness of our method on both lab-controlled and in-the-wild databases and we achieve state-of-the-art recognition performance.
Child Face Recognition at Scale: Synthetic Data Generation and Performance Benchmark
Apr 23, 2023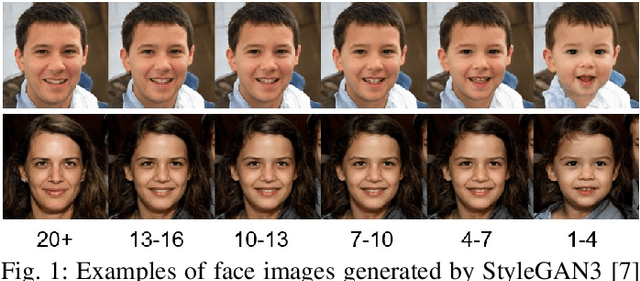


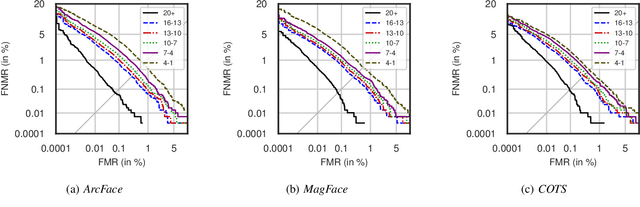
We address the need for a large-scale database of children's faces by using generative adversarial networks (GANs) and face age progression (FAP) models to synthesize a realistic dataset referred to as HDA-SynChildFaces. To this end, we proposed a processing pipeline that initially utilizes StyleGAN3 to sample adult subjects, which are subsequently progressed to children of varying ages using InterFaceGAN. Intra-subject variations, such as facial expression and pose, are created by further manipulating the subjects in their latent space. Additionally, the presented pipeline allows to evenly distribute the races of subjects, allowing to generate a balanced and fair dataset with respect to race distribution. The created HDA-SynChildFaces consists of 1,652 subjects and a total of 188,832 images, each subject being present at various ages and with many different intra-subject variations. Subsequently, we evaluates the performance of various facial recognition systems on the generated database and compare the results of adults and children at different ages. The study reveals that children consistently perform worse than adults, on all tested systems, and the degradation in performance is proportional to age. Additionally, our study uncovers some biases in the recognition systems, with Asian and Black subjects and females performing worse than White and Latino Hispanic subjects and males.
GREAT Score: Global Robustness Evaluation of Adversarial Perturbation using Generative Models
May 03, 2023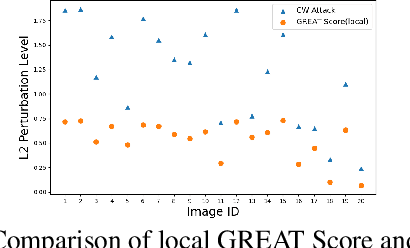
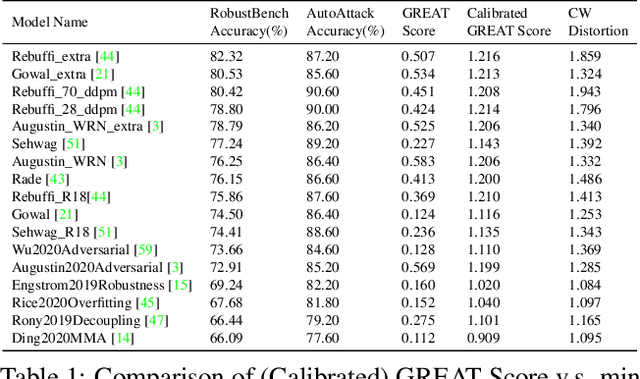
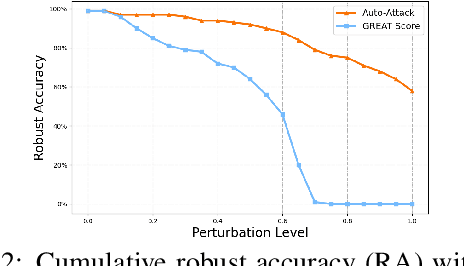
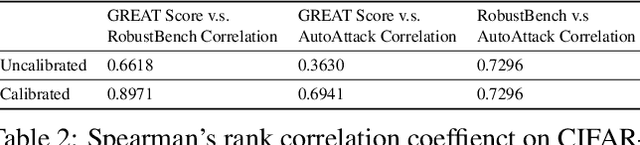
Current studies on adversarial robustness mainly focus on aggregating local robustness results from a set of data samples to evaluate and rank different models. However, the local statistics may not well represent the true global robustness of the underlying unknown data distribution. To address this challenge, this paper makes the first attempt to present a new framework, called GREAT Score , for global robustness evaluation of adversarial perturbation using generative models. Formally, GREAT Score carries the physical meaning of a global statistic capturing a mean certified attack-proof perturbation level over all samples drawn from a generative model. For finite-sample evaluation, we also derive a probabilistic guarantee on the sample complexity and the difference between the sample mean and the true mean. GREAT Score has several advantages: (1) Robustness evaluations using GREAT Score are efficient and scalable to large models, by sparing the need of running adversarial attacks. In particular, we show high correlation and significantly reduced computation cost of GREAT Score when compared to the attack-based model ranking on RobustBench (Croce,et. al. 2021). (2) The use of generative models facilitates the approximation of the unknown data distribution. In our ablation study with different generative adversarial networks (GANs), we observe consistency between global robustness evaluation and the quality of GANs. (3) GREAT Score can be used for remote auditing of privacy-sensitive black-box models, as demonstrated by our robustness evaluation on several online facial recognition services.
FaceTopoNet: Facial Expression Recognition using Face Topology Learning
Sep 13, 2022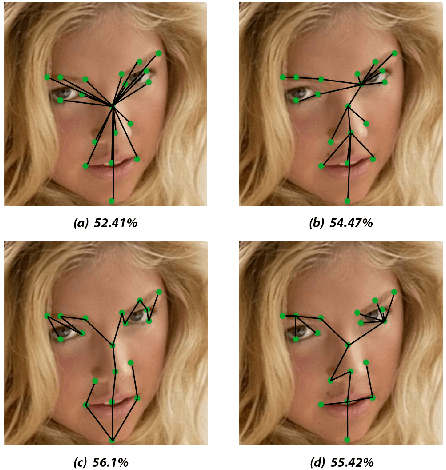

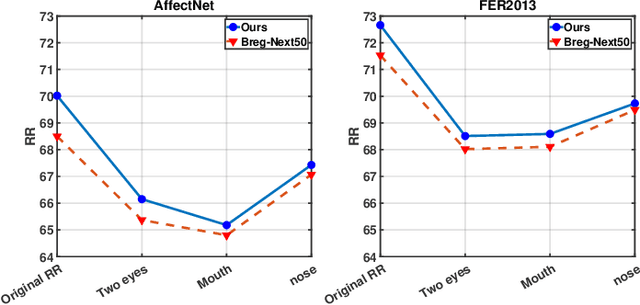
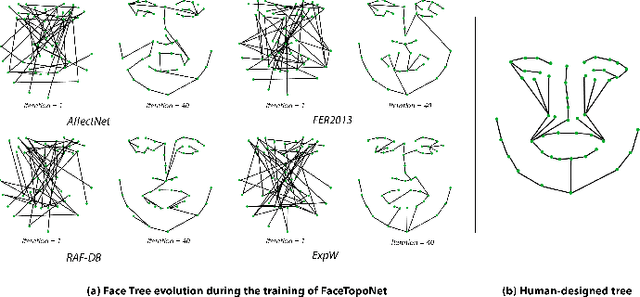
Prior work has shown that the order in which different components of the face are learned using a sequential learner can play an important role in the performance of facial expression recognition systems. We propose FaceTopoNet, an end-to-end deep model for facial expression recognition, which is capable of learning an effective tree topology of the face. Our model then traverses the learned tree to generate a sequence, which is then used to form an embedding to feed a sequential learner. The devised model adopts one stream for learning structure and one stream for learning texture. The structure stream focuses on the positions of the facial landmarks, while the main focus of the texture stream is on the patches around the landmarks to learn textural information. We then fuse the outputs of the two streams by utilizing an effective attention-based fusion strategy. We perform extensive experiments on four large-scale in-the-wild facial expression datasets - namely AffectNet, FER2013, ExpW, and RAF-DB - and one lab-controlled dataset (CK+) to evaluate our approach. FaceTopoNet achieves state-of-the-art performance on three of the five datasets and obtains competitive results on the other two datasets. We also perform rigorous ablation and sensitivity experiments to evaluate the impact of different components and parameters in our model. Lastly, we perform robustness experiments and demonstrate that FaceTopoNet is more robust against occlusions in comparison to other leading methods in the area.
On Developing Facial Stress Analysis and Expression Recognition Platform
Sep 16, 2022

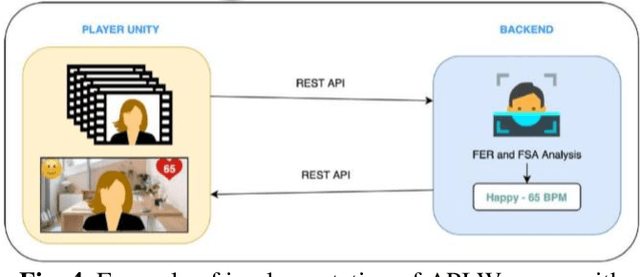
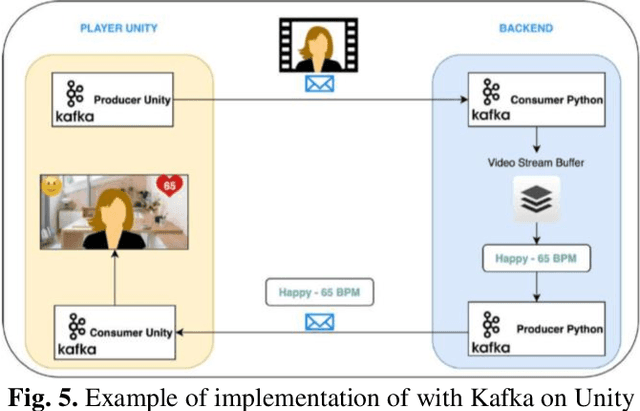
This work represents the experimental and development process of system facial expression recognition and facial stress analysis algorithms for an immersive digital learning platform. The system retrieves from users web camera and evaluates it using artificial neural network (ANN) algorithms. The ANN output signals can be used to score and improve the learning process. Adapting an ANN to a new system can require a significant implementation effort or the need to repeat the ANN training. There are also limitations related to the minimum hardware required to run an ANN. To overpass these constraints, some possible implementations of facial expression recognition and facial stress analysis algorithms in real-time systems are presented. The implementation of the new solution has made it possible to improve the accuracy in the recognition of facial expressions and also to increase their response speed. Experimental results showed that using the developed algorithms allow to detect the heart rate with better rate in comparison with social equipment.