 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 18, 2023

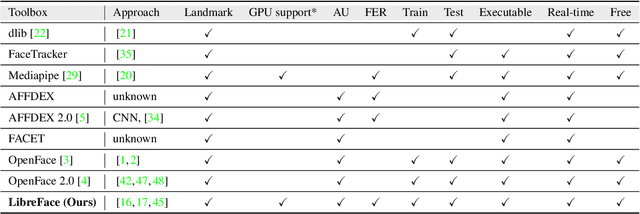
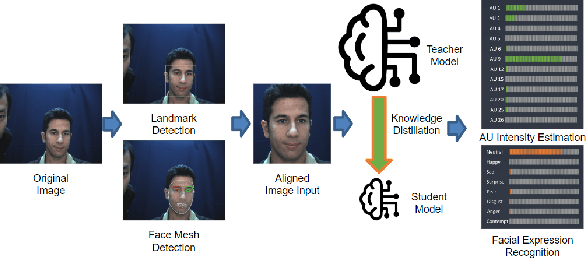

Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAFDB. Our code will be released at https://github.com/ihp-lab/LibreFace
CLIPER: A Unified Vision-Language Framework for In-the-Wild Facial Expression Recognition
Mar 01, 2023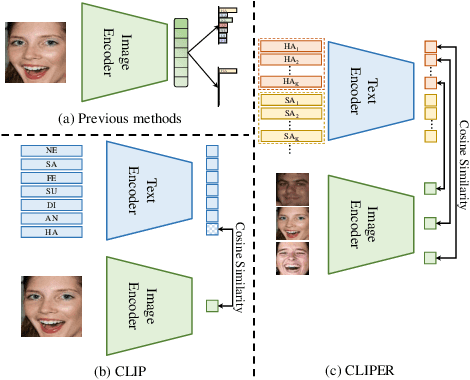
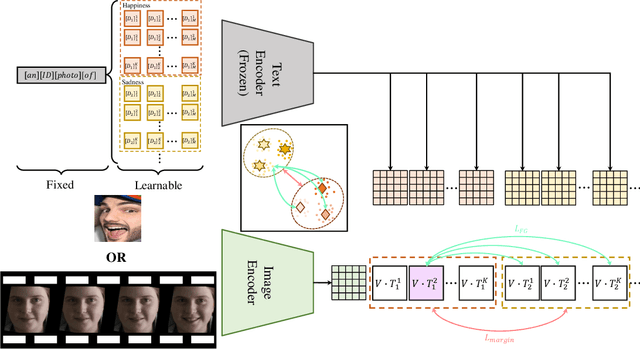

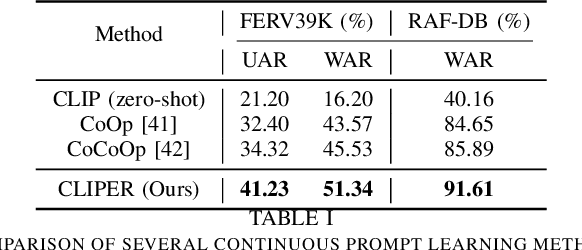
Facial expression recognition (FER) is an essential task for understanding human behaviors. As one of the most informative behaviors of humans, facial expressions are often compound and variable, which is manifested by the fact that different people may express the same expression in very different ways. However, most FER methods still use one-hot or soft labels as the supervision, which lack sufficient semantic descriptions of facial expressions and are less interpretable. Recently, contrastive vision-language pre-training (VLP) models (e.g., CLIP) use text as supervision and have injected new vitality into various computer vision tasks, benefiting from the rich semantics in text. Therefore, in this work, we propose CLIPER, a unified framework for both static and dynamic facial Expression Recognition based on CLIP. Besides, we introduce multiple expression text descriptors (METD) to learn fine-grained expression representations that make CLIPER more interpretable. We conduct extensive experiments on several popular FER benchmarks and achieve state-of-the-art performance, which demonstrates the effectiveness of CLIPER.
Learning Full-Head 3D GANs from a Single-View Portrait Dataset
Jul 27, 2023



33D-aware face generators are commonly trained on 2D real-life face image datasets. Nevertheless, existing facial recognition methods often struggle to extract face data captured from various camera angles. Furthermore, in-the-wild images with diverse body poses introduce a high-dimensional challenge for 3D-aware generators, making it difficult to utilize data that contains complete neck and shoulder regions. Consequently, these face image datasets often contain only near-frontal face data, which poses challenges for 3D-aware face generators to construct \textit{full-head} 3D portraits. To this end, we first create the dataset {$\it{360}^{\circ}$}-\textit{Portrait}-\textit{HQ} (\textit{$\it{360}^{\circ}$PHQ}), which consists of high-quality single-view real portraits annotated with a variety of camera parameters {(the yaw angles span the entire $360^{\circ}$ range)} and body poses. We then propose \textit{3DPortraitGAN}, the first 3D-aware full-head portrait generator that learns a canonical 3D avatar distribution from the body-pose-various \textit{$\it{360}^{\circ}$PHQ} dataset with body pose self-learning. Our model can generate view-consistent portrait images from all camera angles (${360}^{\circ}$) with a full-head 3D representation. We incorporate a mesh-guided deformation field into volumetric rendering to produce deformed results to generate portrait images that conform to the body pose distribution of the dataset using our canonical generator. We integrate two pose predictors into our framework to predict more accurate body poses to address the issue of inaccurately estimated body poses in our dataset. Our experiments show that the proposed framework can generate view-consistent, realistic portrait images with complete geometry from all camera angles and accurately predict portrait body pose.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023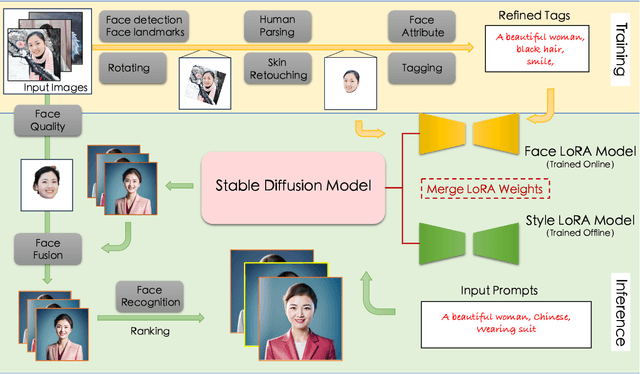

Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
Neural Architecture Search Using Genetic Algorithm for Facial Expression Recognition
Apr 12, 2023Facial expression is one of the most powerful, natural, and universal signals for human beings to express emotional states and intentions. Thus, it is evident the importance of correct and innovative facial expression recognition (FER) approaches in Artificial Intelligence. The current common practice for FER is to correctly design convolutional neural networks' architectures (CNNs) using human expertise. However, finding a well-performing architecture is often a very tedious and error-prone process for deep learning researchers. Neural architecture search (NAS) is an area of growing interest as demonstrated by the large number of scientific works published in recent years thanks to the impressive results achieved in recent years. We propose a genetic algorithm approach that uses an ingenious encoding-decoding mechanism that allows to automatically evolve CNNs on FER tasks attaining high accuracy classification rates. The experimental results demonstrate that the proposed algorithm achieves the best-known results on the CK+ and FERG datasets as well as competitive results on the JAFFE dataset.
Deep Ensemble Learning with Frame Skipping for Face Anti-Spoofing
Jul 11, 2023
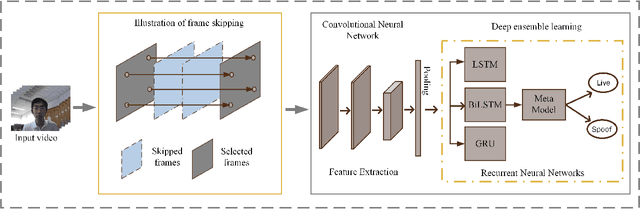
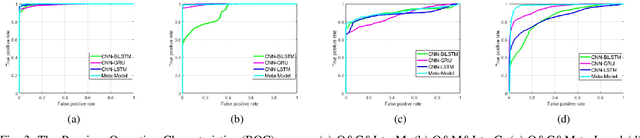
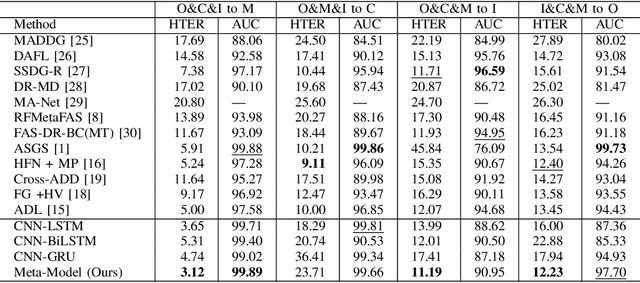
Face presentation attacks (PA), also known as spoofing attacks, pose a substantial threat to biometric systems that rely on facial recognition systems, such as access control systems, mobile payments, and identity verification systems. To mitigate the spoofing risk, several video-based methods have been presented in the literature that analyze facial motion in successive video frames. However, estimating the motion between adjacent frames is a challenging task and requires high computational cost. In this paper, we rephrase the face anti-spoofing task as a motion prediction problem and introduce a deep ensemble learning model with a frame skipping mechanism. In particular, the proposed frame skipping adopts a uniform sampling approach by dividing the original video into video clips of fixed size. By doing so, every nth frame of the clip is selected to ensure that the temporal patterns can easily be perceived during the training of three different recurrent neural networks (RNNs). Motivated by the performance of individual RNNs, a meta-model is developed to improve the overall detection performance by combining the prediction of individual RNNs. Extensive experiments were performed on four datasets, and state-of-the-art performance is reported on MSU-MFSD (3.12%), Replay-Attack (11.19%), and OULU-NPU (12.23%) databases by using half total error rates (HTERs) in the most challenging cross-dataset testing scenario.
RidgeBase: A Cross-Sensor Multi-Finger Contactless Fingerprint Dataset
Jul 09, 2023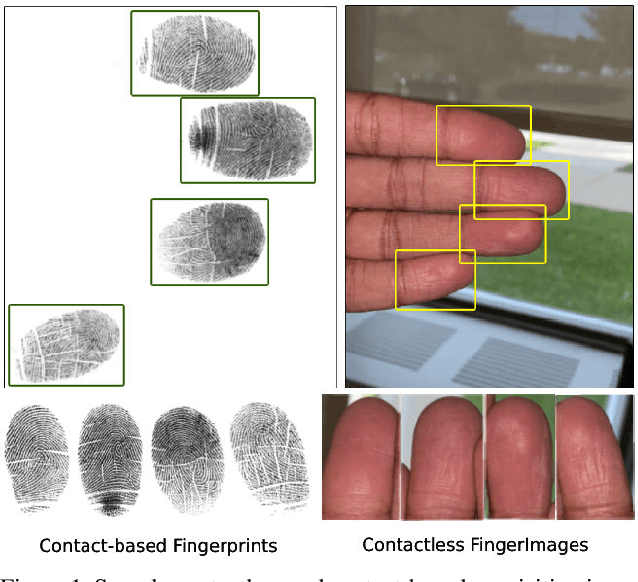


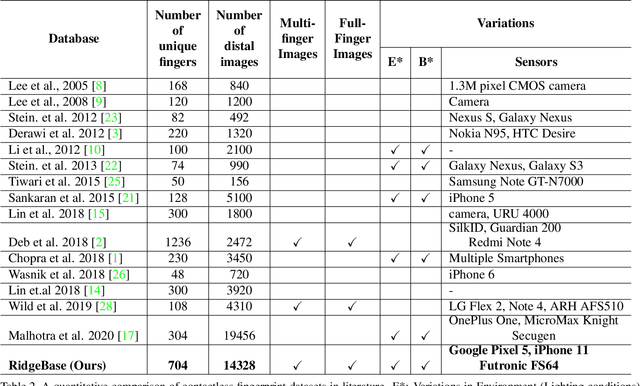
Contactless fingerprint matching using smartphone cameras can alleviate major challenges of traditional fingerprint systems including hygienic acquisition, portability and presentation attacks. However, development of practical and robust contactless fingerprint matching techniques is constrained by the limited availability of large scale real-world datasets. To motivate further advances in contactless fingerprint matching across sensors, we introduce the RidgeBase benchmark dataset. RidgeBase consists of more than 15,000 contactless and contact-based fingerprint image pairs acquired from 88 individuals under different background and lighting conditions using two smartphone cameras and one flatbed contact sensor. Unlike existing datasets, RidgeBase is designed to promote research under different matching scenarios that include Single Finger Matching and Multi-Finger Matching for both contactless- to-contactless (CL2CL) and contact-to-contactless (C2CL) verification and identification. Furthermore, due to the high intra-sample variance in contactless fingerprints belonging to the same finger, we propose a set-based matching protocol inspired by the advances in facial recognition datasets. This protocol is specifically designed for pragmatic contactless fingerprint matching that can account for variances in focus, polarity and finger-angles. We report qualitative and quantitative baseline results for different protocols using a COTS fingerprint matcher (Verifinger) and a Deep CNN based approach on the RidgeBase dataset. The dataset can be downloaded here: https://www.buffalo.edu/cubs/research/datasets/ridgebase-benchmark-dataset.html
* Paper accepted at IJCB 2022
Exploring Large-scale Unlabeled Faces to Enhance Facial Expression Recognition
Mar 19, 2023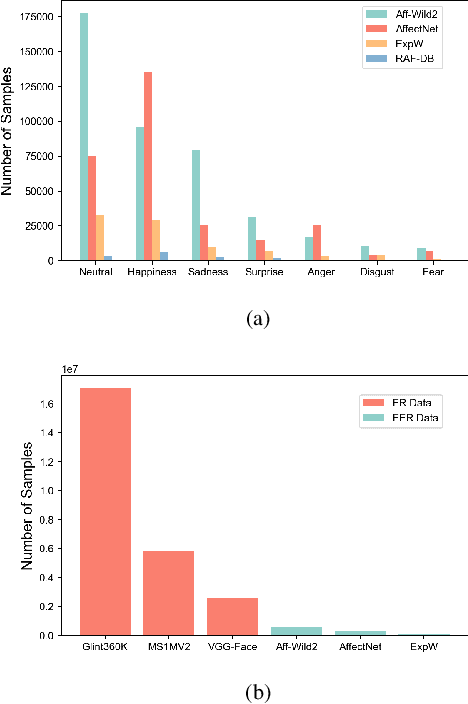

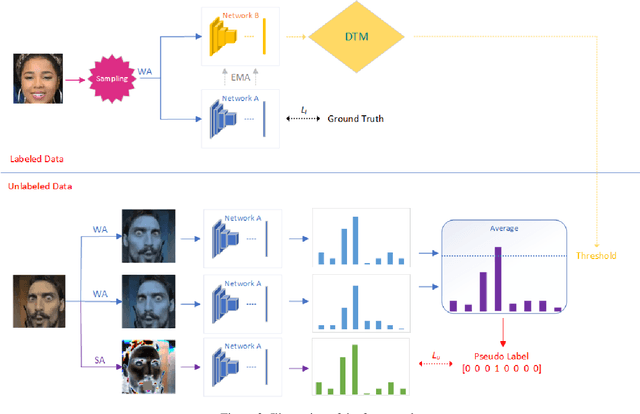
Facial Expression Recognition (FER) is an important task in computer vision and has wide applications in human-computer interaction, intelligent security, emotion analysis, and other fields. However, the limited size of FER datasets limits the generalization ability of expression recognition models, resulting in ineffective model performance. To address this problem, we propose a semi-supervised learning framework that utilizes unlabeled face data to train expression recognition models effectively. Our method uses a dynamic threshold module (\textbf{DTM}) that can adaptively adjust the confidence threshold to fully utilize the face recognition (FR) data to generate pseudo-labels, thus improving the model's ability to model facial expressions. In the ABAW5 EXPR task, our method achieved excellent results on the official validation set.
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition
May 05, 2023
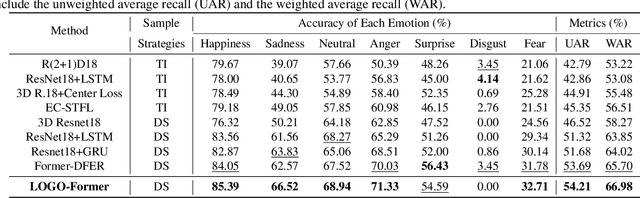
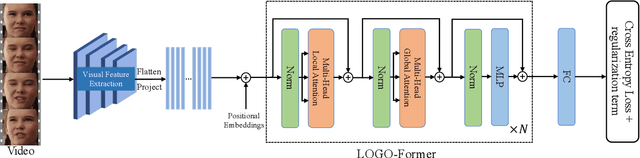
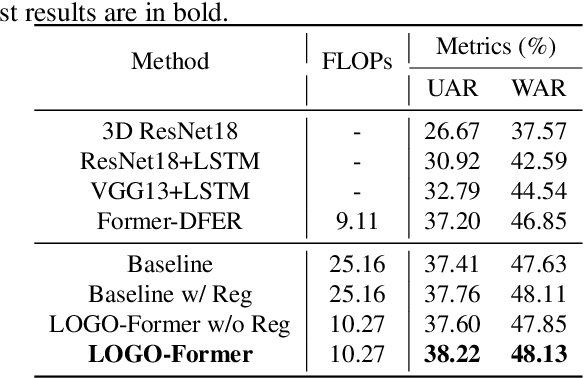
Previous methods for dynamic facial expression recognition (DFER) in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. Transformer-based methods for DFER can achieve better performances but result in higher FLOPs and computational costs. To solve these problems, the local-global spatio-temporal Transformer (LOGO-Former) is proposed to capture discriminative features within each frame and model contextual relationships among frames while balancing the complexity. Based on the priors that facial muscles move locally and facial expressions gradually change, we first restrict both the space attention and the time attention to a local window to capture local interactions among feature tokens. Furthermore, we perform the global attention by querying a token with features from each local window iteratively to obtain long-range information of the whole video sequence. In addition, we propose the compact loss regularization term to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39K) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for DFER.