 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Facial Expressions Recognition with Convolutional Neural Networks
Jul 19, 2021

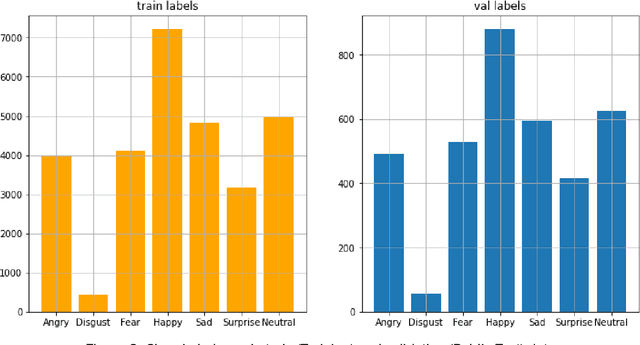
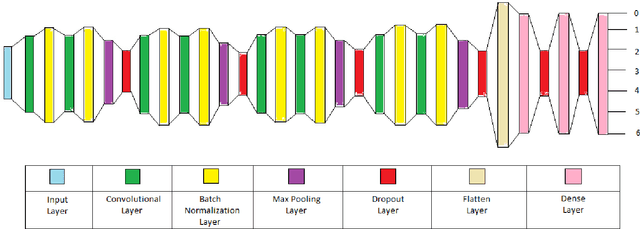
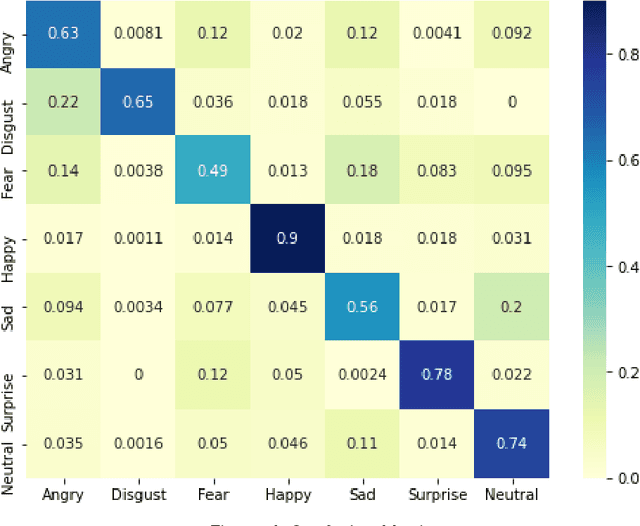
Over the centuries, humans have developed and acquired a number of ways to communicate. But hardly any of them can be as natural and instinctive as facial expressions. On the other hand, neural networks have taken the world by storm. And no surprises, that the area of Computer Vision and the problem of facial expressions recognitions hasn't remained untouched. Although a wide range of techniques have been applied, achieving extremely high accuracies and preparing highly robust FER systems still remains a challenge due to heterogeneous details in human faces. In this paper, we will be deep diving into implementing a system for recognition of facial expressions (FER) by leveraging neural networks, and more specifically, Convolutional Neural Networks (CNNs). We adopt the fundamental concepts of deep learning and computer vision with various architectures, fine-tune it's hyperparameters and experiment with various optimization methods and demonstrate a state-of-the-art single-network-accuracy of 70.10% on the FER2013 dataset without using any additional training data.
Fawkes: Protecting Personal Privacy against Unauthorized Deep Learning Models
Feb 19, 2020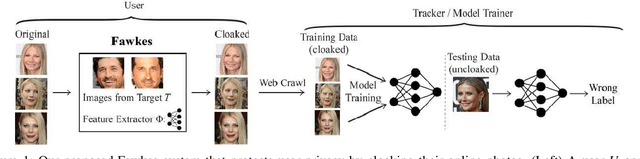

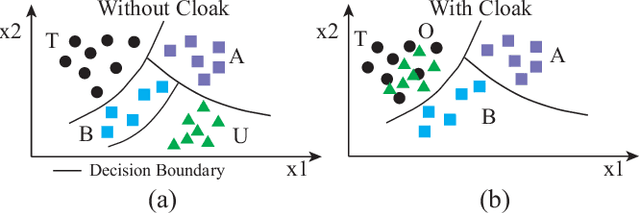
Today's proliferation of powerful facial recognition models poses a real threat to personal privacy. As Clearview.ai demonstrated, anyone can canvas the Internet for data, and train highly accurate facial recognition models of us without our knowledge. We need tools to protect ourselves from unauthorized facial recognition systems and their numerous potential misuses. Unfortunately, work in related areas are limited in practicality and effectiveness. In this paper, we propose Fawkes, a system that allow individuals to inoculate themselves against unauthorized facial recognition models. Fawkes achieves this by helping users adding imperceptible pixel-level changes (we call them "cloaks") to their own photos before publishing them online. When collected by a third-party "tracker" and used to train facial recognition models, these "cloaked" images produce functional models that consistently misidentify the user. We experimentally prove that Fawkes provides 95+% protection against user recognition regardless of how trackers train their models. Even when clean, uncloaked images are "leaked" to the tracker and used for training, Fawkes can still maintain a 80+% protection success rate. In fact, we perform real experiments against today's state-of-the-art facial recognition services and achieve 100% success. Finally, we show that Fawkes is robust against a variety of countermeasures that try to detect or disrupt cloaks.
Pre-Trained Convolutional Neural Network Features for Facial Expression Recognition
Dec 16, 2018

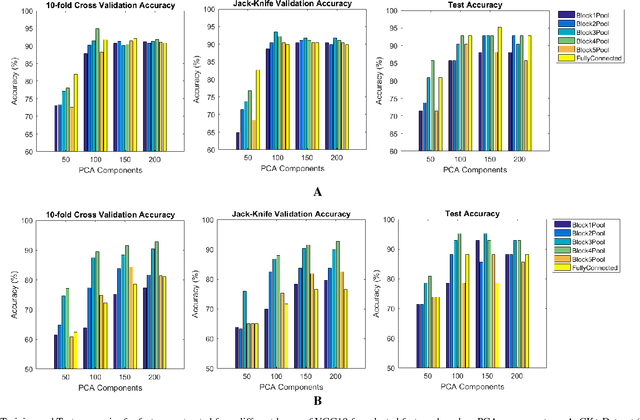
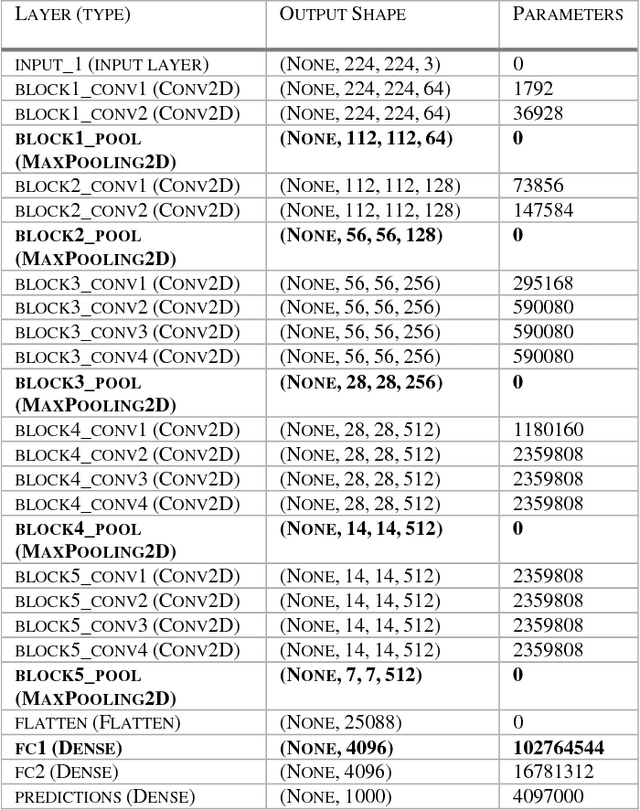
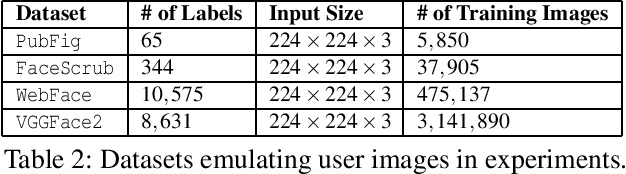
Facial expression recognition has been an active area in computer vision with application areas including animation, social robots, personalized banking, etc. In this study, we explore the problem of image classification for detecting facial expressions based on features extracted from pre-trained convolutional neural networks trained on ImageNet database. Features are extracted and transferred to a Linear Support Vector Machine for classification. All experiments are performed on two publicly available datasets such as JAFFE and CK+ database. The results show that representations learned from pre-trained networks for a task such as object recognition can be transferred, and used for facial expression recognition. Furthermore, for a small dataset, using features from earlier layers of the VGG19 network provides better classification accuracy. Accuracies of 92.26% and 92.86% were achieved for the CK+ and JAFFE datasets respectively.
Unrestricted Black-box Adversarial Attack Using GAN with Limited Queries
Aug 24, 2022
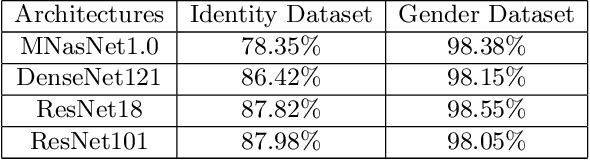
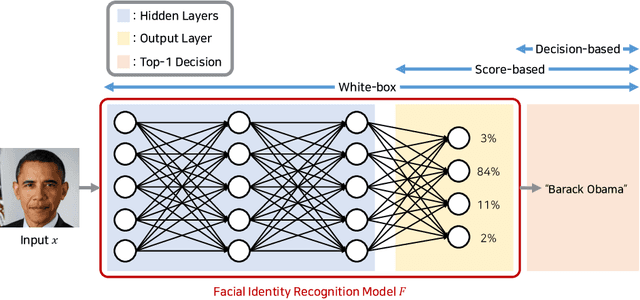
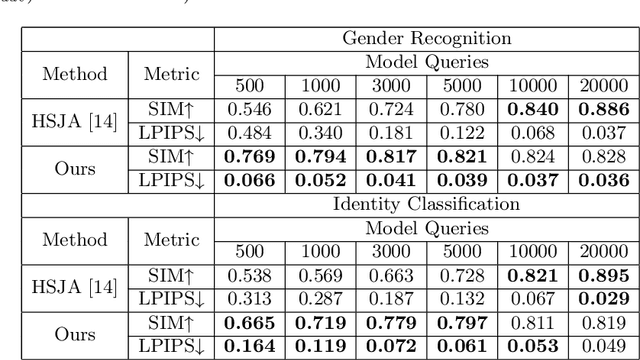
Adversarial examples are inputs intentionally generated for fooling a deep neural network. Recent studies have proposed unrestricted adversarial attacks that are not norm-constrained. However, the previous unrestricted attack methods still have limitations to fool real-world applications in a black-box setting. In this paper, we present a novel method for generating unrestricted adversarial examples using GAN where an attacker can only access the top-1 final decision of a classification model. Our method, Latent-HSJA, efficiently leverages the advantages of a decision-based attack in the latent space and successfully manipulates the latent vectors for fooling the classification model. With extensive experiments, we demonstrate that our proposed method is efficient in evaluating the robustness of classification models with limited queries in a black-box setting. First, we demonstrate that our targeted attack method is query-efficient to produce unrestricted adversarial examples for a facial identity recognition model that contains 307 identities. Then, we demonstrate that the proposed method can also successfully attack a real-world celebrity recognition service.
Fair Robust Active Learning by Joint Inconsistency
Sep 22, 2022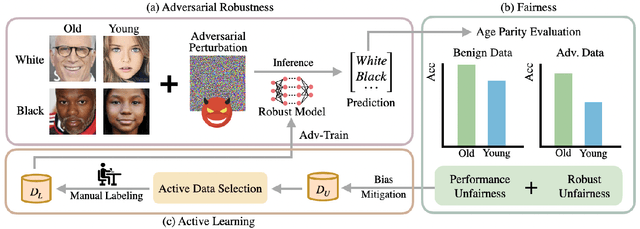
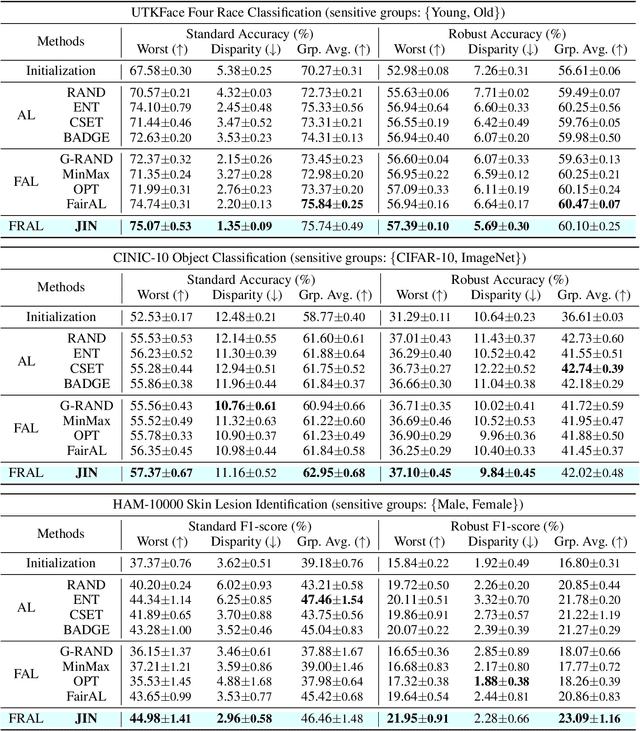
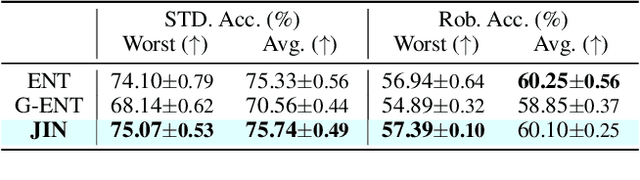
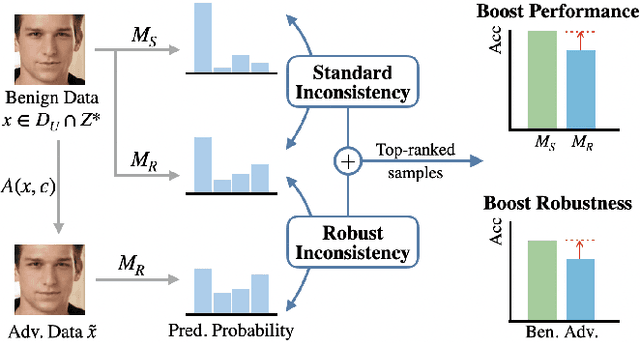
Fair Active Learning (FAL) utilized active learning techniques to achieve high model performance with limited data and to reach fairness between sensitive groups (e.g., genders). However, the impact of the adversarial attack, which is vital for various safety-critical machine learning applications, is not yet addressed in FAL. Observing this, we introduce a novel task, Fair Robust Active Learning (FRAL), integrating conventional FAL and adversarial robustness. FRAL requires ML models to leverage active learning techniques to jointly achieve equalized performance on benign data and equalized robustness against adversarial attacks between groups. In this new task, previous FAL methods generally face the problem of unbearable computational burden and ineffectiveness. Therefore, we develop a simple yet effective FRAL strategy by Joint INconsistency (JIN). To efficiently find samples that can boost the performance and robustness of disadvantaged groups for labeling, our method exploits the prediction inconsistency between benign and adversarial samples as well as between standard and robust models. Extensive experiments under diverse datasets and sensitive groups demonstrate that our method not only achieves fairer performance on benign samples but also obtains fairer robustness under white-box PGD attacks compared with existing active learning and FAL baselines. We are optimistic that FRAL would pave a new path for developing safe and robust ML research and applications such as facial attribute recognition in biometrics systems.
Facial emotion recognition using min-max similarity classifier
Jan 01, 2018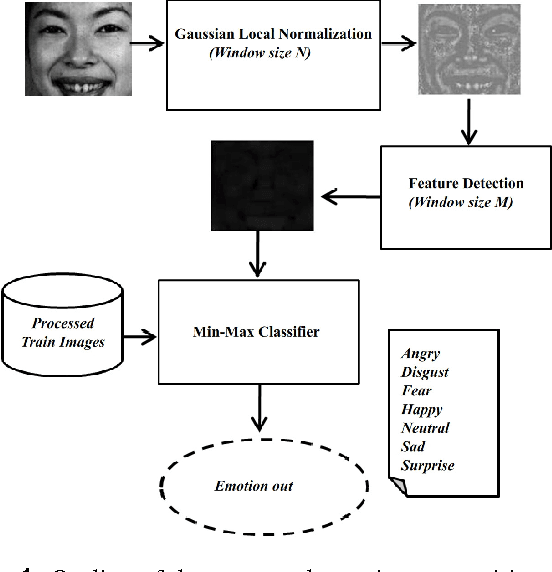


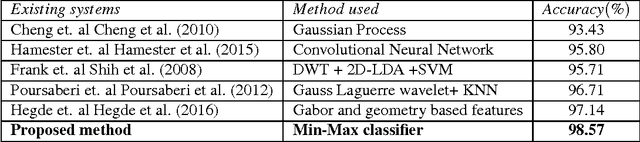
Recognition of human emotions from the imaging templates is useful in a wide variety of human-computer interaction and intelligent systems applications. However, the automatic recognition of facial expressions using image template matching techniques suffer from the natural variability with facial features and recording conditions. In spite of the progress achieved in facial emotion recognition in recent years, the effective and computationally simple feature selection and classification technique for emotion recognition is still an open problem. In this paper, we propose an efficient and straightforward facial emotion recognition algorithm to reduce the problem of inter-class pixel mismatch during classification. The proposed method includes the application of pixel normalization to remove intensity offsets followed-up with a Min-Max metric in a nearest neighbor classifier that is capable of suppressing feature outliers. The results indicate an improvement of recognition performance from 92.85% to 98.57% for the proposed Min-Max classification method when tested on JAFFE database. The proposed emotion recognition technique outperforms the existing template matching methods.
Hybrid CNN-Transformer Model For Facial Affect Recognition In the ABAW4 Challenge
Jul 20, 2022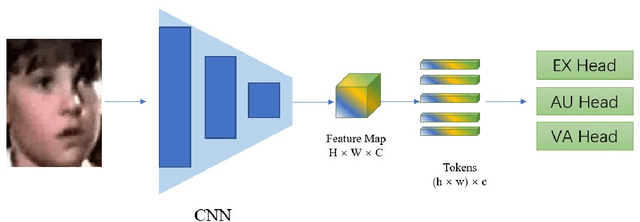

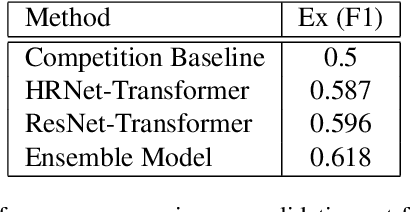
This paper describes our submission to the fourth Affective Behavior Analysis (ABAW) competition. We proposed a hybrid CNN-Transformer model for the Multi-Task-Learning (MTL) and Learning from Synthetic Data (LSD) task. Experimental results on validation dataset shows that our method achieves better performance than baseline model, which verifies that the effectiveness of proposed network.
AU-Guided Unsupervised Domain Adaptive Facial Expression Recognition
Dec 18, 2020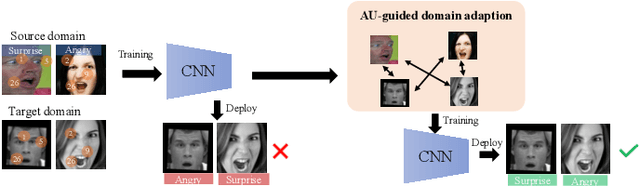
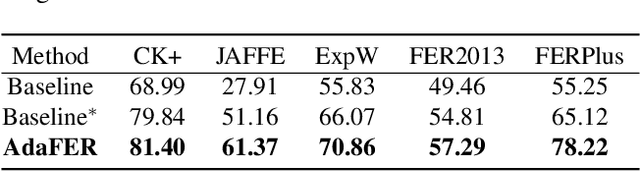
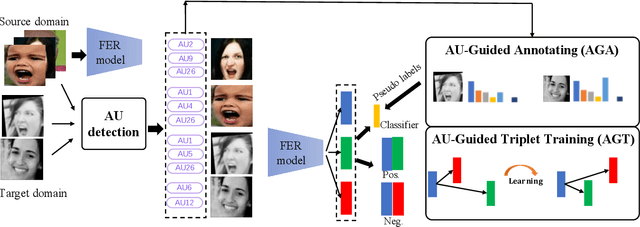
The domain diversities including inconsistent annotation and varied image collection conditions inevitably exist among different facial expression recognition (FER) datasets, which pose an evident challenge for adapting the FER model trained on one dataset to another one. Recent works mainly focus on domain-invariant deep feature learning with adversarial learning mechanism, ignoring the sibling facial action unit (AU) detection task which has obtained great progress. Considering AUs objectively determine facial expressions, this paper proposes an AU-guided unsupervised Domain Adaptive FER (AdaFER) framework. In AdaFER, we first leverage an advanced model for AU detection on both source and target domain. Then, we compare the AU results to perform AU-guided annotating, i.e., target faces that own the same AUs with source faces would inherit the labels from source domain. Meanwhile, to achieve domain-invariant compact features, we utilize an AU-guided triplet training which randomly collects anchor-positive-negative triplets on both domains with AUs. We conduct extensive experiments on several popular benchmarks and show that AdaFER achieves state-of-the-art results on all the benchmarks.
A Peek at Peak Emotion Recognition
May 19, 2022


Despite much progress in the field of facial expression recognition, little attention has been paid to the recognition of peak emotion. Aviezer et al. [1] showed that humans have trouble discerning between positive and negative peak emotions. In this work we analyze how deep learning fares on this challenge. We find that (i) despite using very small datasets, features extracted from deep learning models can achieve results significantly better than humans. (ii) We find that deep learning models, even when trained only on datasets tagged by humans, still outperform humans in this task.
MERANet: Facial Micro-Expression Recognition using 3D Residual Attention Network
Dec 07, 2020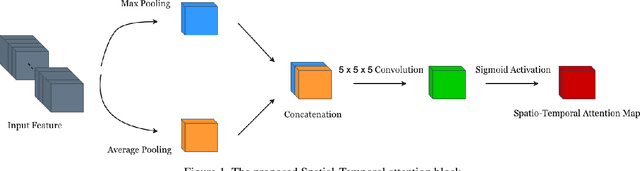
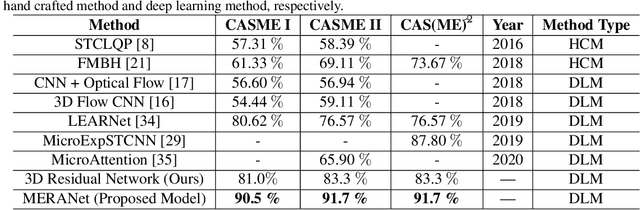

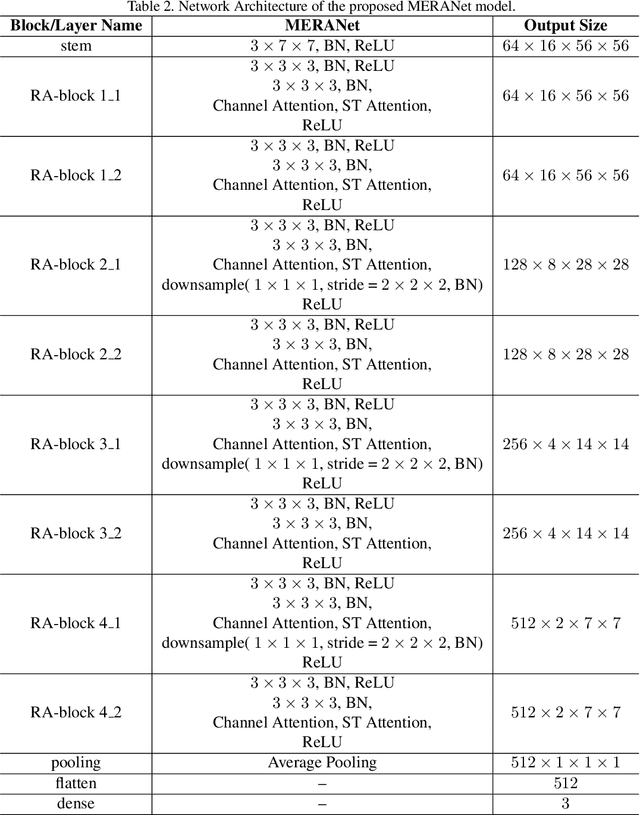
We propose a facial micro-expression recognition model using 3D residual attention network called MERANet. The proposed model takes advantage of spatial-temporal attention and channel attention together, to learn deeper fine-grained subtle features for classification of emotions. The proposed model also encompasses both spatial and temporal information simultaneously using the 3D kernels and residual connections. Moreover, the channel features and spatio-temporal features are re-calibrated using the channel and spatio-temporal attentions, respectively in each residual module. The experiments are conducted on benchmark facial micro-expression datasets. A superior performance is observed as compared to the state-of-the-art for facial micro-expression recognition.