 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Towards Transparency in Dermatology Image Datasets with Skin Tone Annotations by Experts, Crowds, and an Algorithm
Jul 06, 2022
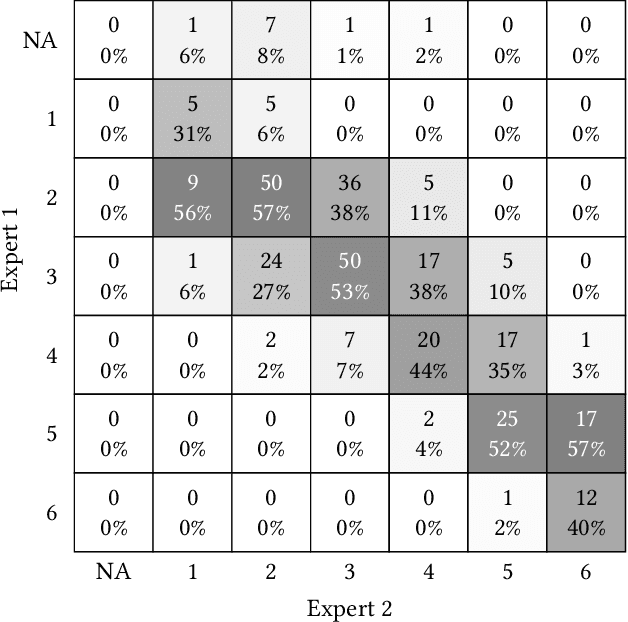
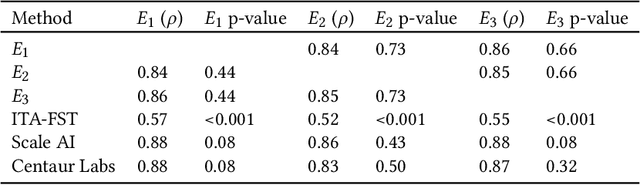
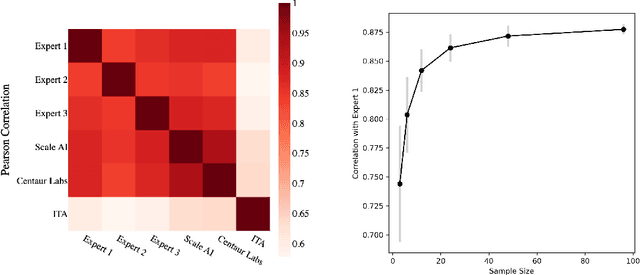
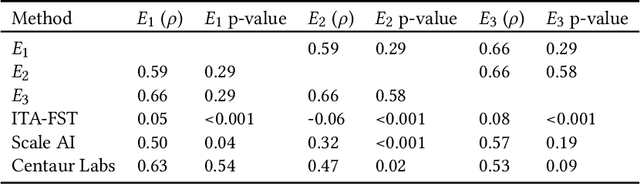
While artificial intelligence (AI) holds promise for supporting healthcare providers and improving the accuracy of medical diagnoses, a lack of transparency in the composition of datasets exposes AI models to the possibility of unintentional and avoidable mistakes. In particular, public and private image datasets of dermatological conditions rarely include information on skin color. As a start towards increasing transparency, AI researchers have appropriated the use of the Fitzpatrick skin type (FST) from a measure of patient photosensitivity to a measure for estimating skin tone in algorithmic audits of computer vision applications including facial recognition and dermatology diagnosis. In order to understand the variability of estimated FST annotations on images, we compare several FST annotation methods on a diverse set of 460 images of skin conditions from both textbooks and online dermatology atlases. We find the inter-rater reliability between three board-certified dermatologists is comparable to the inter-rater reliability between the board-certified dermatologists and two crowdsourcing methods. In contrast, we find that the Individual Typology Angle converted to FST (ITA-FST) method produces annotations that are significantly less correlated with the experts' annotations than the experts' annotations are correlated with each other. These results demonstrate that algorithms based on ITA-FST are not reliable for annotating large-scale image datasets, but human-centered, crowd-based protocols can reliably add skin type transparency to dermatology datasets. Furthermore, we introduce the concept of dynamic consensus protocols with tunable parameters including expert review that increase the visibility of crowdwork and provide guidance for future crowdsourced annotations of large image datasets.
Revisiting Few-Shot Learning for Facial Expression Recognition
Dec 11, 2019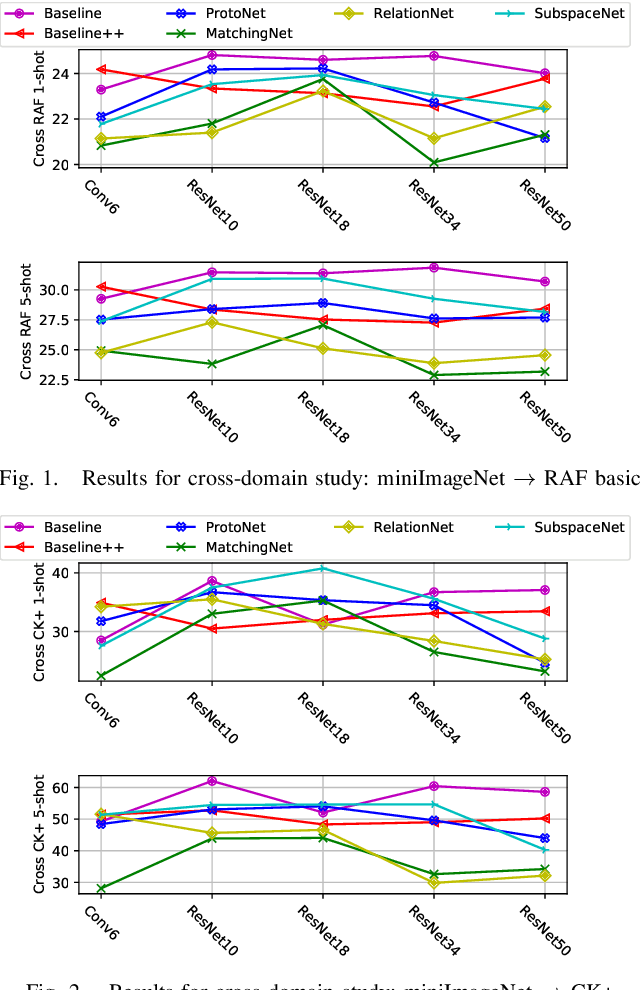
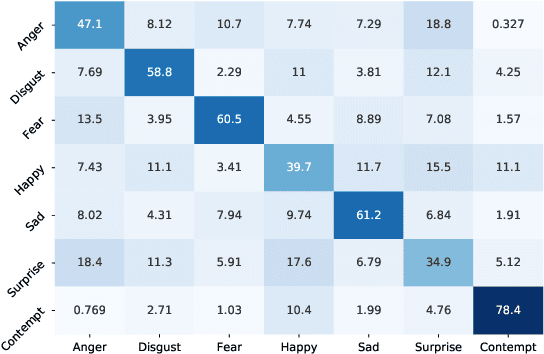
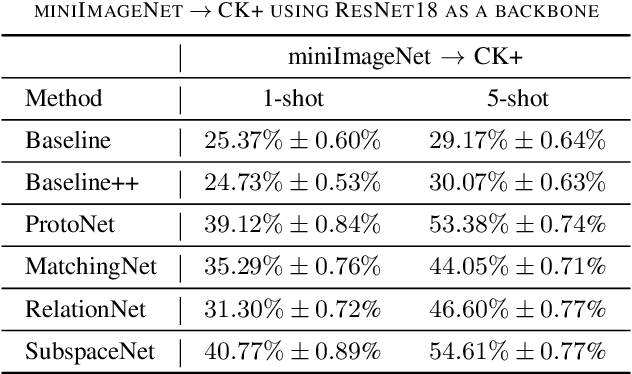
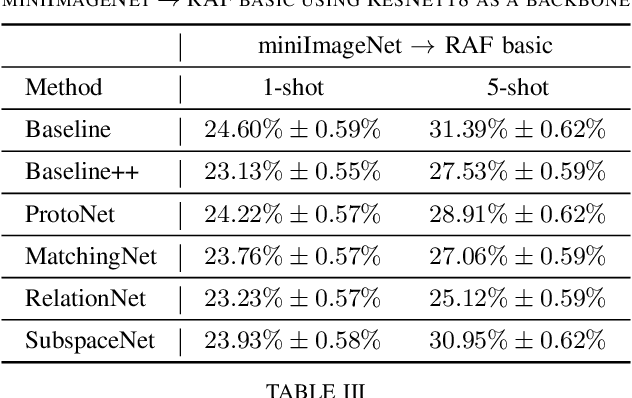
Most of the existing deep neural nets on automatic facial expression recognition focus on a set of predefined emotion classes, where the amount of training data has the biggest impact on performance. However, in the standard setting over-parameterised neural networks are not amenable for learning from few samples as they can quickly over-fit. In addition, these approaches do not have such a strong generalisation ability to identify a new category, where the data of each category is too limited and significant variations exist in the expression within the same semantic category. We embrace these challenges and formulate the problem as a low-shot learning, where once the base classifier is deployed, it must rapidly adapt to recognise novel classes using a few samples. In this paper, we revisit and compare existing few-shot learning methods for the low-shot facial expression recognition in terms of their generalisation ability via episode-training. In particular, we extend our analysis on the cross-domain generalisation, where training and test tasks are not drawn from the same distribution. We demonstrate the efficacy of low-shot learning methods through extensive experiments.
Human Expression Recognition using Facial Shape Based Fourier Descriptors Fusion
Dec 28, 2020Dynamic facial expression recognition has many useful applications in social networks, multimedia content analysis, security systems and others. This challenging process must be done under recurrent problems of image illumination and low resolution which changes at partial occlusions. This paper aims to produce a new facial expression recognition method based on the changes in the facial muscles. The geometric features are used to specify the facial regions i.e., mouth, eyes, and nose. The generic Fourier shape descriptor in conjunction with elliptic Fourier shape descriptor is used as an attribute to represent different emotions under frequency spectrum features. Afterwards a multi-class support vector machine is applied for classification of seven human expression. The statistical analysis showed our approach obtained overall competent recognition using 5-fold cross validation with high accuracy on well-known facial expression dataset.
Deep Convolutional Neural Network Based Facial Expression Recognition in the Wild
Oct 03, 2020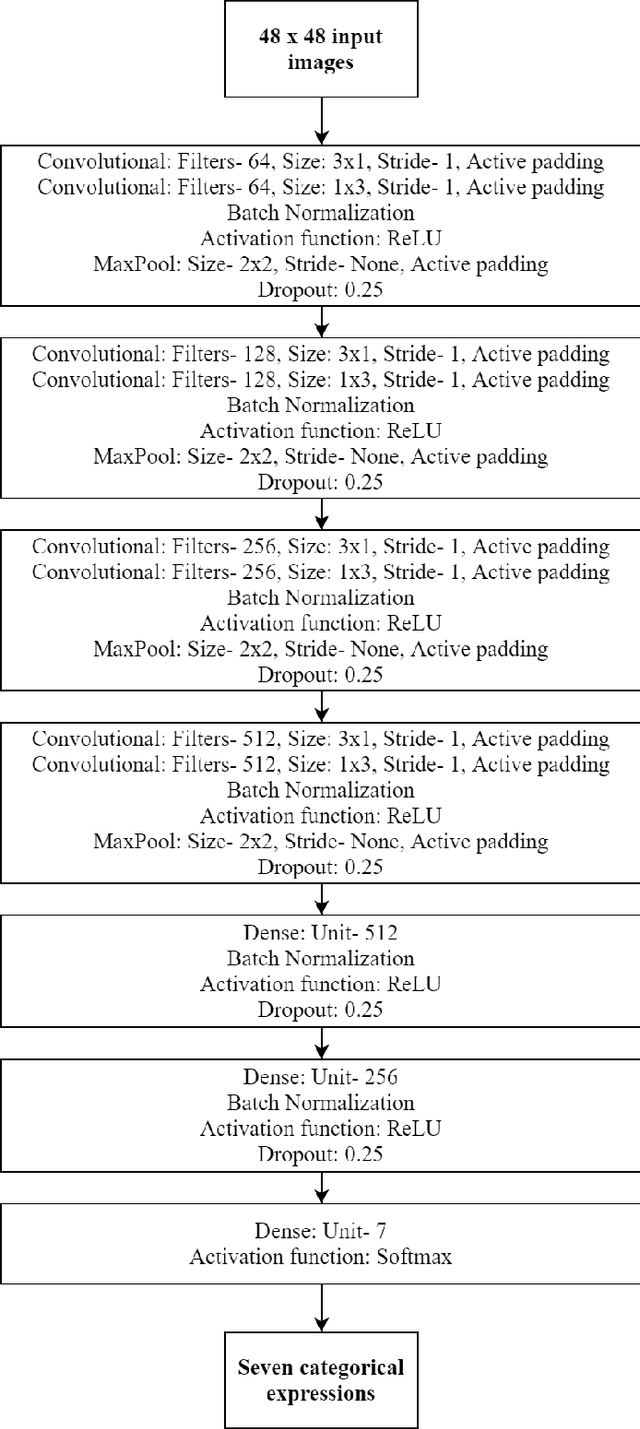
This paper describes the proposed methodology, data used and the results of our participation in the ChallengeTrack 2 (Expr Challenge Track) of the Affective Behavior Analysis in-the-wild (ABAW) Competition 2020. In this competition, we have used a proposed deep convolutional neural network (CNN) model to perform automatic facial expression recognition (AFER) on the given dataset. Our proposed model has achieved an accuracy of 50.77% and an F1 score of 29.16% on the validation set.
Practical Digital Disguises: Leveraging Face Swaps to Protect Patient Privacy
Apr 13, 2022
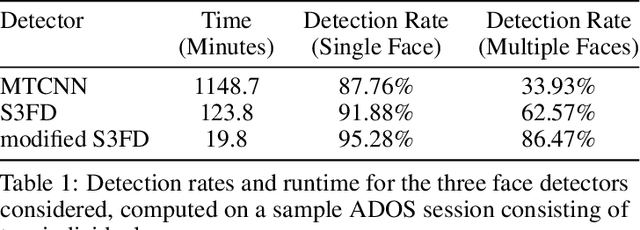
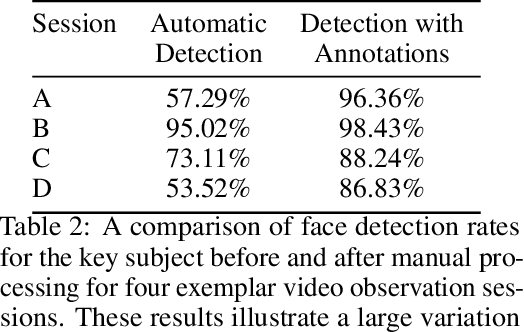
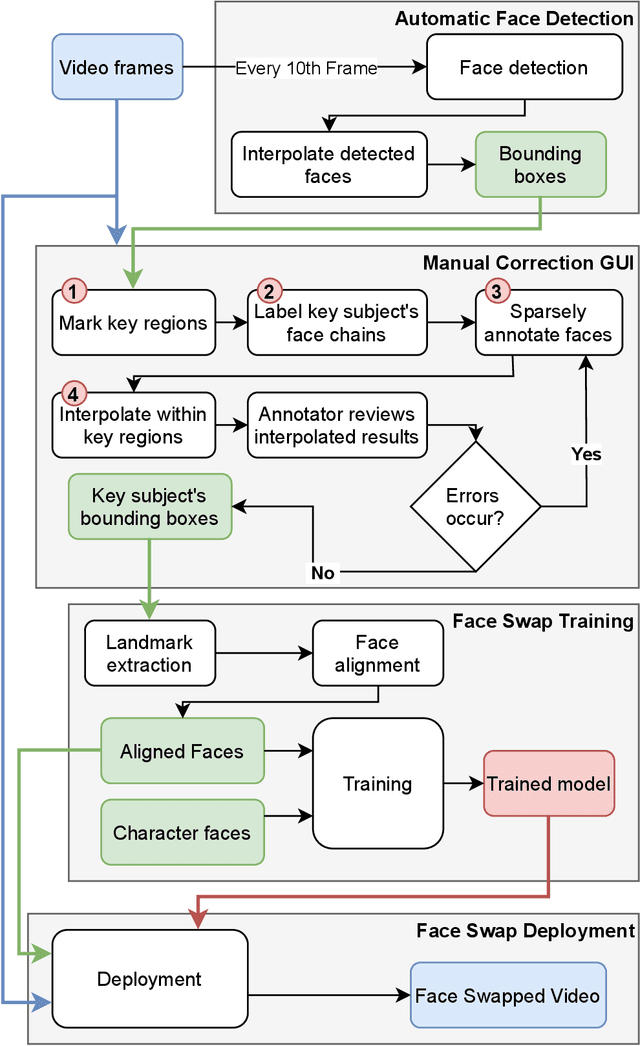
With rapid advancements in image generation technology, face swapping for privacy protection has emerged as an active area of research. The ultimate benefit is improved access to video datasets, e.g. in healthcare settings. Recent literature has proposed deep network-based architectures to perform facial swaps and reported the associated reduction in facial recognition accuracy. However, there is not much reporting on how well these methods preserve the types of semantic information needed for the privatized videos to remain useful for their intended application. Our main contribution is a novel end-to-end face swapping pipeline for recorded videos of standardized assessments of autism symptoms in children. Through this design, we are the first to provide a methodology for assessing the privacy-utility trade-offs for the face swapping approach to patient privacy protection. Our methodology can show, for example, that current deep network based face swapping is bottle-necked by face detection in real world videos, and the extent to which gaze and expression information is preserved by face swaps relative to baseline privatization methods such as blurring.
Human Face Recognition from Part of a Facial Image based on Image Stitching
Mar 10, 2022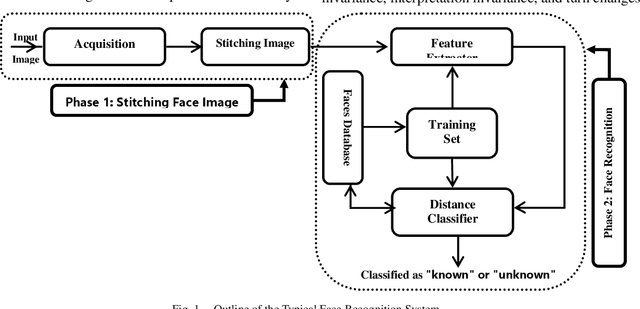
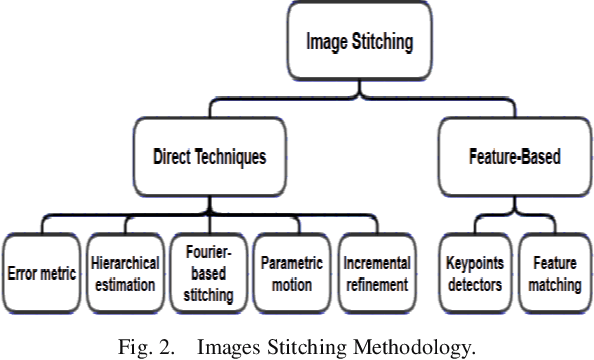


Most of the current techniques for face recognition require the presence of a full face of the person to be recognized, and this situation is difficult to achieve in practice, the required person may appear with a part of his face, which requires prediction of the part that did not appear. Most of the current forecasting processes are done by what is known as image interpolation, which does not give reliable results, especially if the missing part is large. In this work, we adopted the process of stitching the face by completing the missing part with the flipping of the part shown in the picture, depending on the fact that the human face is characterized by symmetry in most cases. To create a complete model, two facial recognition methods were used to prove the efficiency of the algorithm. The selected face recognition algorithms that are applied here are Eigenfaces and geometrical methods. Image stitching is the process during which distinctive photographic images are combined to make a complete scene or a high-resolution image. Several images are integrated to form a wide-angle panoramic image. The quality of the image stitching is determined by calculating the similarity among the stitched image and original images and by the presence of the seam lines through the stitched images. The Eigenfaces approach utilizes PCA calculation to reduce the feature vector dimensions. It provides an effective approach for discovering the lower-dimensional space. In addition, to enable the proposed algorithm to recognize the face, it also ensures a fast and effective way of classifying faces. The phase of feature extraction is followed by the classifier phase.
Robust Facial Expression Recognition with Convolutional Visual Transformers
Mar 31, 2021
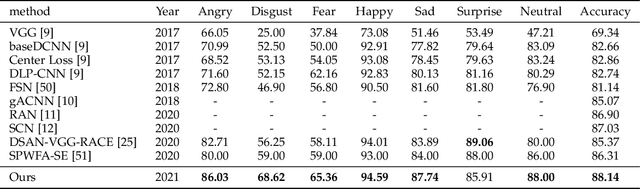
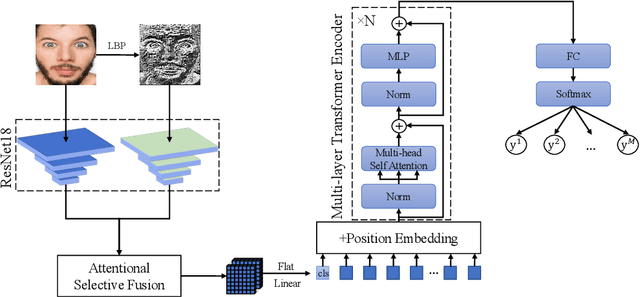
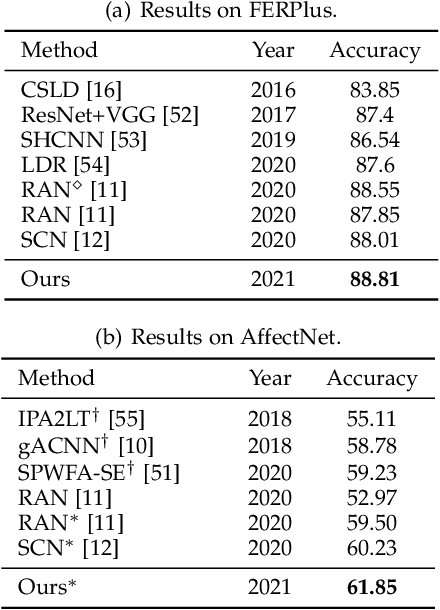
Facial Expression Recognition (FER) in the wild is extremely challenging due to occlusions, variant head poses, face deformation and motion blur under unconstrained conditions. Although substantial progresses have been made in automatic FER in the past few decades, previous studies are mainly designed for lab-controlled FER. Real-world occlusions, variant head poses and other issues definitely increase the difficulty of FER on account of these information-deficient regions and complex backgrounds. Different from previous pure CNNs based methods, we argue that it is feasible and practical to translate facial images into sequences of visual words and perform expression recognition from a global perspective. Therefore, we propose Convolutional Visual Transformers to tackle FER in the wild by two main steps. First, we propose an attentional selective fusion (ASF) for leveraging the feature maps generated by two-branch CNNs. The ASF captures discriminative information by fusing multiple features with global-local attention. The fused feature maps are then flattened and projected into sequences of visual words. Second, inspired by the success of Transformers in natural language processing, we propose to model relationships between these visual words with global self-attention. The proposed method are evaluated on three public in-the-wild facial expression datasets (RAF-DB, FERPlus and AffectNet). Under the same settings, extensive experiments demonstrate that our method shows superior performance over other methods, setting new state of the art on RAF-DB with 88.14%, FERPlus with 88.81% and AffectNet with 61.85%. We also conduct cross-dataset evaluation on CK+ show the generalization capability of the proposed method.
Facial emotion expressions in human-robot interaction: A survey
Mar 12, 2021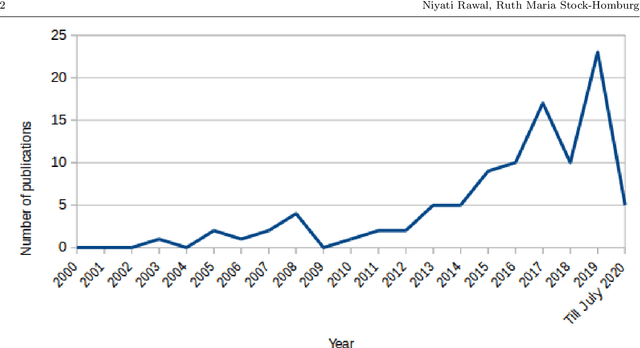
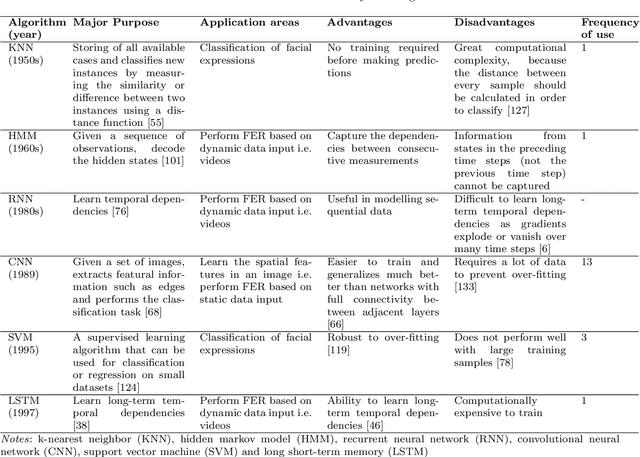
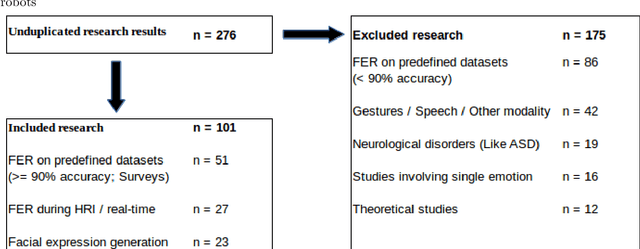
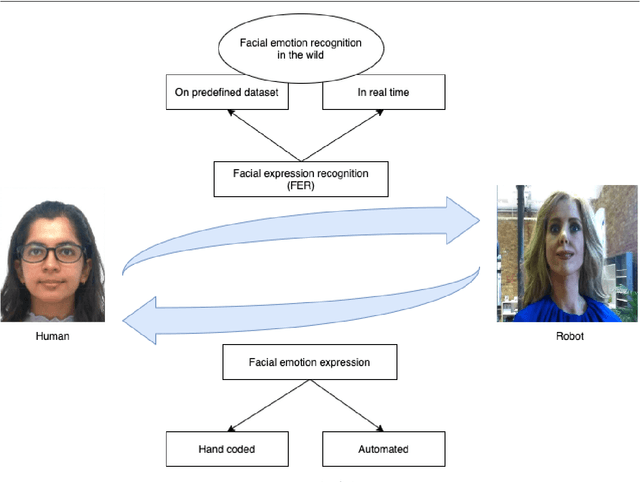
Facial expressions are an ideal means of communicating one's emotions or intentions to others. This overview will focus on human facial expression recognition as well as robotic facial expression generation. In case of human facial expression recognition, both facial expression recognition on predefined datasets as well as in real time will be covered. For robotic facial expression generation, hand coded and automated methods i.e., facial expressions of a robot are generated by moving the features (eyes, mouth) of the robot by hand coding or automatically using machine learning techniques, will also be covered. There are already plenty of studies that achieve high accuracy for emotion expression recognition on predefined datasets, but the accuracy for facial expression recognition in real time is comparatively lower. In case of expression generation in robots, while most of the robots are capable of making basic facial expressions, there are not many studies that enable robots to do so automatically.
Convolutional Neural Network Based Partial Face Detection
Jun 29, 2022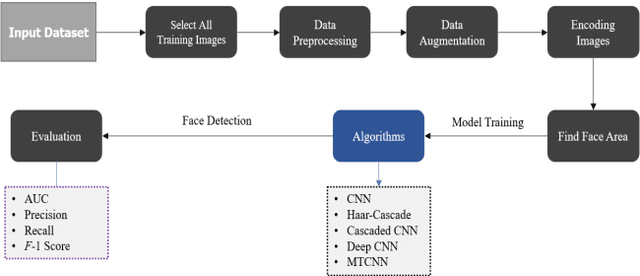

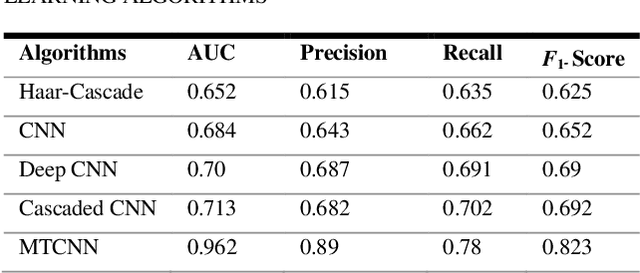

Due to the massive explanation of artificial intelligence, machine learning technology is being used in various areas of our day-to-day life. In the world, there are a lot of scenarios where a simple crime can be prevented before it may even happen or find the person responsible for it. A face is one distinctive feature that we have and can differentiate easily among many other species. But not just different species, it also plays a significant role in determining someone from the same species as us, humans. Regarding this critical feature, a single problem occurs most often nowadays. When the camera is pointed, it cannot detect a person's face, and it becomes a poor image. On the other hand, where there was a robbery and a security camera installed, the robber's identity is almost indistinguishable due to the low-quality camera. But just making an excellent algorithm to work and detecting a face reduces the cost of hardware, and it doesn't cost that much to focus on that area. Facial recognition, widget control, and such can be done by detecting the face correctly. This study aims to create and enhance a machine learning model that correctly recognizes faces. Total 627 Data have been collected from different Bangladeshi people's faces on four angels. In this work, CNN, Harr Cascade, Cascaded CNN, Deep CNN & MTCNN are these five machine learning approaches implemented to get the best accuracy of our dataset. After creating and running the model, Multi-Task Convolutional Neural Network (MTCNN) achieved 96.2% best model accuracy with training data rather than other machine learning models.