 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Fine-tuning of sign language recognition models: a technical report
Feb 16, 2023
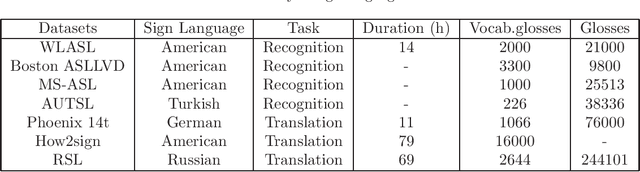
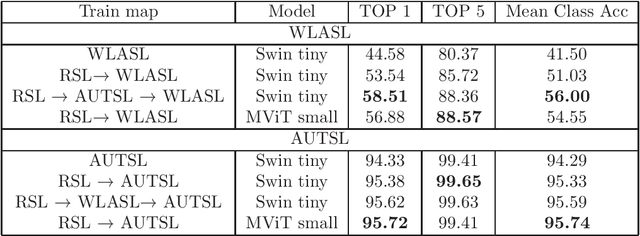
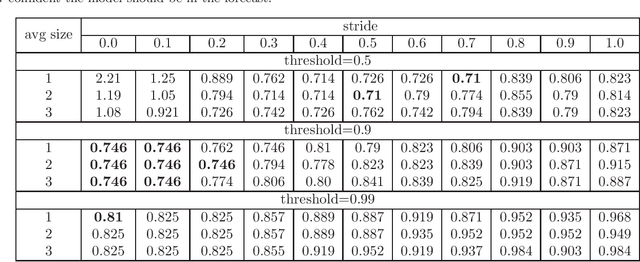
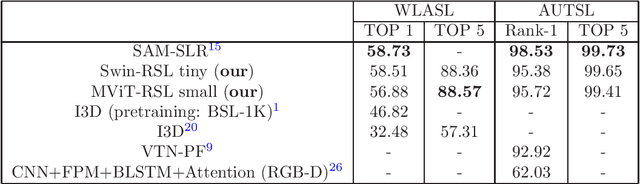
Sign Language Recognition (SLR) is an essential yet challenging task since sign language is performed with the fast and complex movement of hand gestures, body posture, and even facial expressions. %Skeleton Aware Multi-modal Sign Language Recognition In this work, we focused on investigating two questions: how fine-tuning on datasets from other sign languages helps improve sign recognition quality, and whether sign recognition is possible in real-time without using GPU. Three different languages datasets (American sign language WLASL, Turkish - AUTSL, Russian - RSL) have been used to validate the models. The average speed of this system has reached 3 predictions per second, which meets the requirements for the real-time scenario. This model (prototype) will benefit speech or hearing impaired people talk with other trough internet. We also investigated how the additional training of the model in another sign language affects the quality of recognition. The results show that further training of the model on the data of another sign language almost always leads to an improvement in the quality of gesture recognition. We also provide code for reproducing model training experiments, converting models to ONNX format, and inference for real-time gesture recognition.
A Sub-Layered Hierarchical Pyramidal Neural Architecture for Facial Expression Recognition
Mar 23, 2021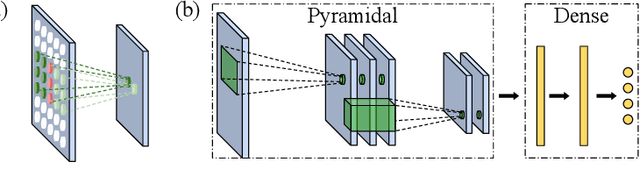

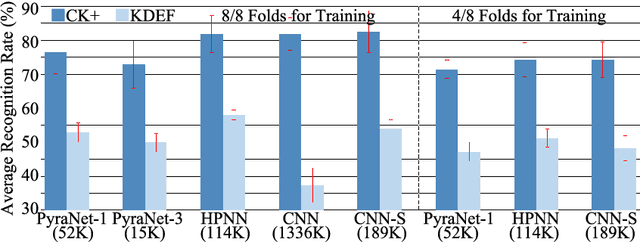

In domains where computational resources and labeled data are limited, such as in robotics, deep networks with millions of weights might not be the optimal solution. In this paper, we introduce a connectivity scheme for pyramidal architectures to increase their capacity for learning features. Experiments on facial expression recognition of unseen people demonstrate that our approach is a potential candidate for applications with restricted resources, due to good generalization performance and low computational cost. We show that our approach generalizes as well as convolutional architectures in this task but uses fewer trainable parameters and is more robust for low-resolution faces.
Equalization and Brightness Mapping Modes of Color-to-Gray Projection Operators
Aug 21, 2022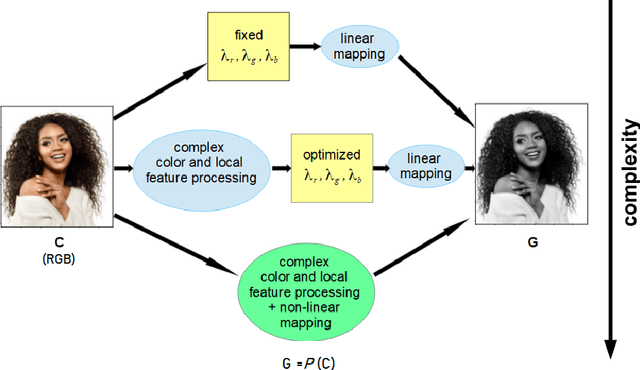

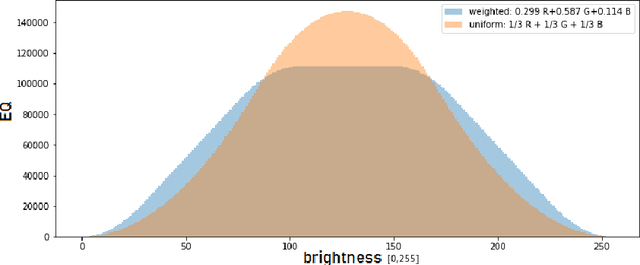
In this article, the conversion of color RGB images to grayscale is covered by characterizing the mathematical operators used to project 3 color channels to a single one. Based on the fact that most operators assign each of the $256^3$ colors a single gray level, ranging from 0 to 255, they are clustering algorithms that distribute the color population into 256 clusters of increasing brightness. To visualize the way operators work the sizes of the clusters and the average brightness of each cluster are plotted. The equalization mode (EQ) introduced in this work focuses on cluster sizes, while the brightness mapping (BM) mode describes the CIE L* luminance distribution per cluster. Three classes of EQ modes and two classes of BM modes were found in linear operators, defining a 6-class taxonomy. The theoretical/methodological framework introduced was applied in a case study considering the equal-weights uniform operator, the NTSC standard operator, and an operator chosen as ideal to lighten the faces of black people to improve facial recognition in current biased classifiers. It was found that most current metrics used to assess the quality of color-to-gray conversions better assess one of the two BM mode classes, but the ideal operator chosen by a human team belongs to the other class. Therefore, this cautions against using these general metrics for specific purpose color-to-gray conversions. It should be noted that eventual applications of this framework to non-linear operators can give rise to new classes of EQ and BM modes. The main contribution of this article is to provide a tool to better understand color to gray converters in general, even those based on machine learning, within the current trend of better explainability of models.
Human Emotional Facial Expression Recognition
Mar 28, 2018
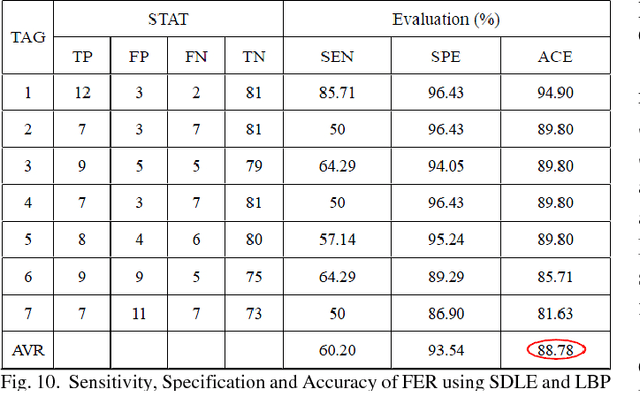
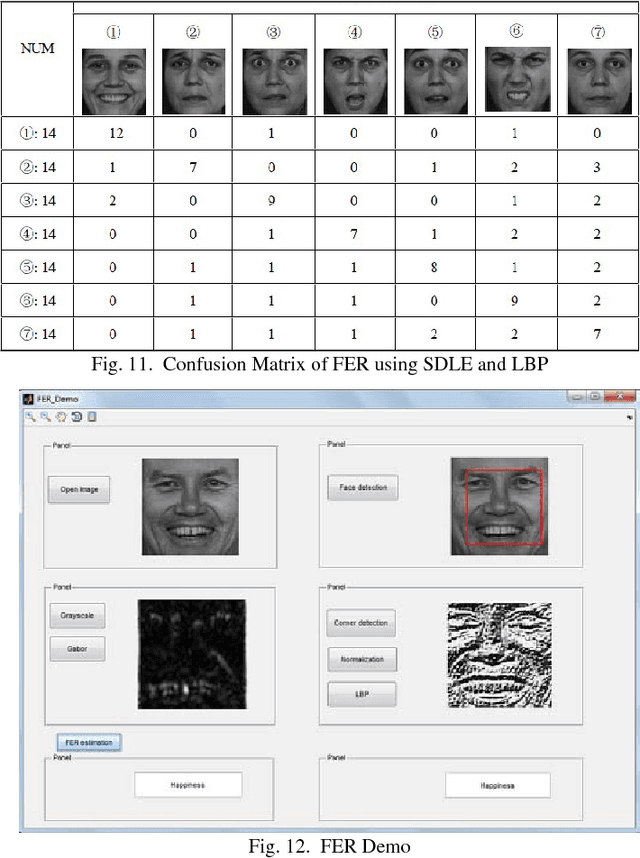

An automatic Facial Expression Recognition (FER) model with Adaboost face detector, feature selection based on manifold learning and synergetic prototype based classifier has been proposed. Improved feature selection method and proposed classifier can achieve favorable effectiveness to performance FER in reasonable processing time.
Deep Covariance Descriptors for Facial Expression Recognition
May 10, 2018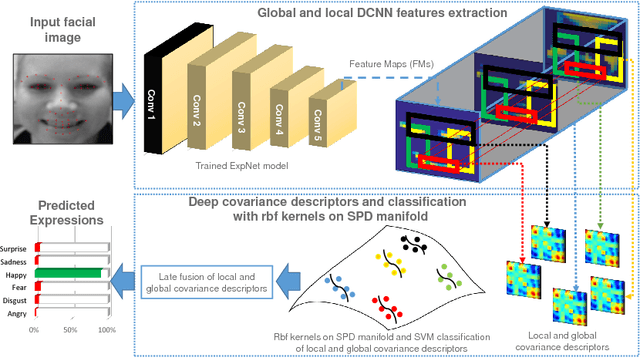

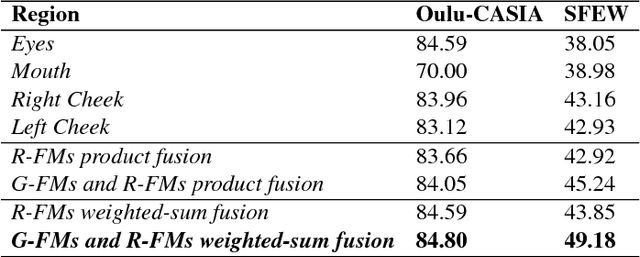
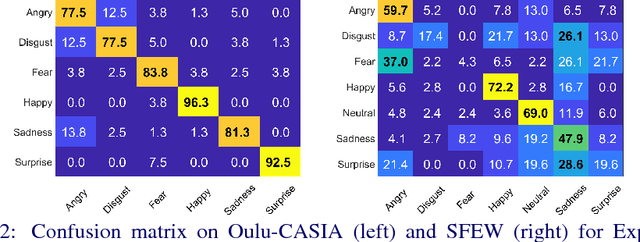
In this paper, covariance matrices are exploited to encode the deep convolutional neural networks (DCNN) features for facial expression recognition. The space geometry of the covariance matrices is that of Symmetric Positive Definite (SPD) matrices. By performing the classification of the facial expressions using Gaussian kernel on SPD manifold, we show that the covariance descriptors computed on DCNN features are more efficient than the standard classification with fully connected layers and softmax. By implementing our approach using the VGG-face and ExpNet architectures with extensive experiments on the Oulu-CASIA and SFEW datasets, we show that the proposed approach achieves performance at the state of the art for facial expression recognition.
Protection of SVM Model with Secret Key from Unauthorized Access
Nov 17, 2021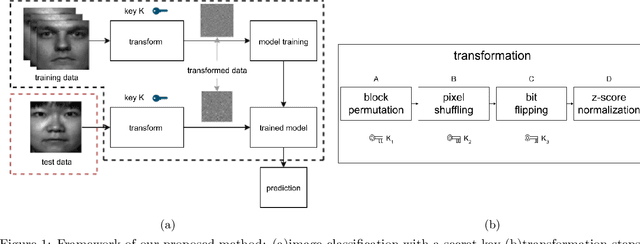


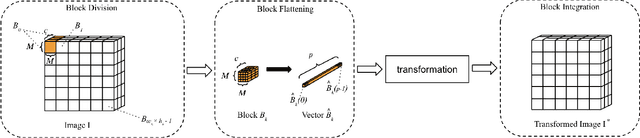
In this paper, we propose a block-wise image transformation method with a secret key for support vector machine (SVM) models. Models trained by using transformed images offer a poor performance to unauthorized users without a key, while they can offer a high performance to authorized users with a key. The proposed method is demonstrated to be robust enough against unauthorized access even under the use of kernel functions in a facial recognition experiment.
Comparing Facial Expression Recognition in Humans and Machines: Using CAM, GradCAM, and Extremal Perturbation
Oct 09, 2021

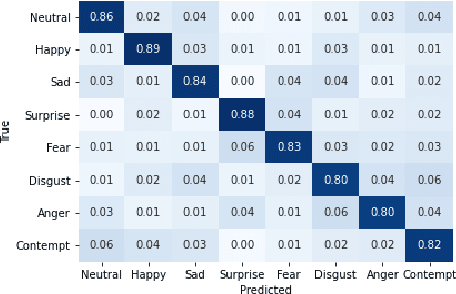
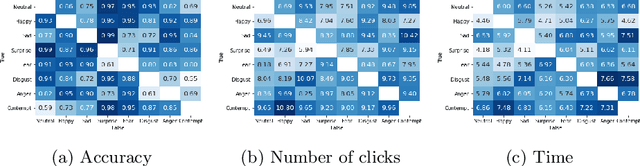
Facial expression recognition (FER) is a topic attracting significant research in both psychology and machine learning with a wide range of applications. Despite a wealth of research on human FER and considerable progress in computational FER made possible by deep neural networks (DNNs), comparatively less work has been done on comparing the degree to which DNNs may be comparable to human performance. In this work, we compared the recognition performance and attention patterns of humans and machines during a two-alternative forced-choice FER task. Human attention was here gathered through click data that progressively uncovered a face, whereas model attention was obtained using three different popular techniques from explainable AI: CAM, GradCAM and Extremal Perturbation. In both cases, performance was gathered as percent correct. For this task, we found that humans outperformed machines quite significantly. In terms of attention patterns, we found that Extremal Perturbation had the best overall fit with the human attention map during the task.
Expression Snippet Transformer for Robust Video-based Facial Expression Recognition
Sep 17, 2021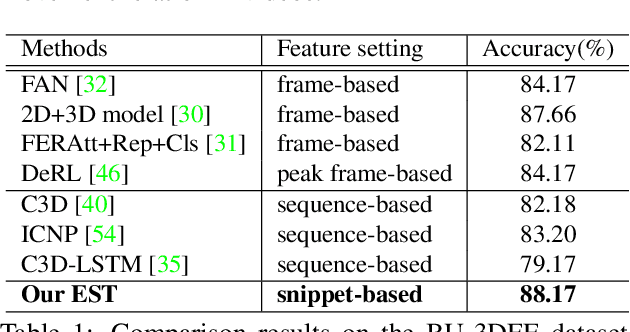
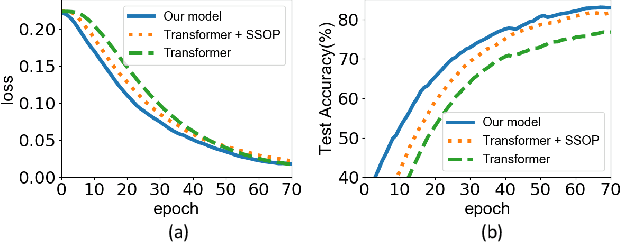
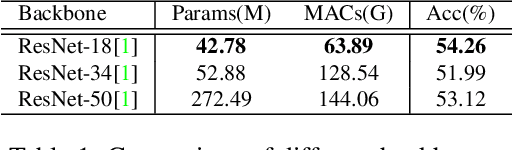
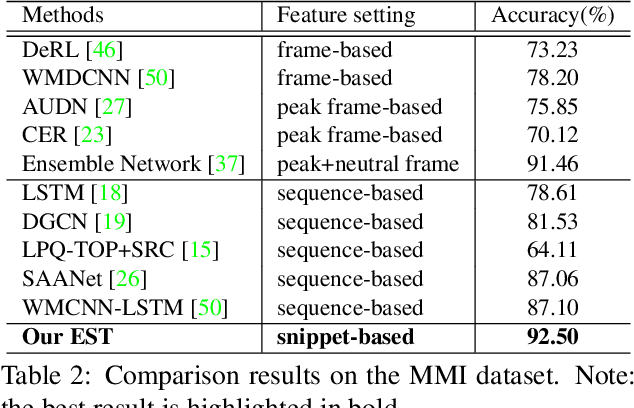
The recent success of Transformer has provided a new direction to various visual understanding tasks, including video-based facial expression recognition (FER). By modeling visual relations effectively, Transformer has shown its power for describing complicated patterns. However, Transformer still performs unsatisfactorily to notice subtle facial expression movements, because the expression movements of many videos can be too small to extract meaningful spatial-temporal relations and achieve robust performance. To this end, we propose to decompose each video into a series of expression snippets, each of which contains a small number of facial movements, and attempt to augment the Transformer's ability for modeling intra-snippet and inter-snippet visual relations, respectively, obtaining the Expression snippet Transformer (EST). In particular, for intra-snippet modeling, we devise an attention-augmented snippet feature extractor (AA-SFE) to enhance the encoding of subtle facial movements of each snippet by gradually attending to more salient information. In addition, for inter-snippet modeling, we introduce a shuffled snippet order prediction (SSOP) head and a corresponding loss to improve the modeling of subtle motion changes across subsequent snippets by training the Transformer to identify shuffled snippet orders. Extensive experiments on four challenging datasets (i.e., BU-3DFE, MMI, AFEW, and DFEW) demonstrate that our EST is superior to other CNN-based methods, obtaining state-of-the-art performance.
Detection, Recognition, and Tracking: A Survey
Mar 22, 2022For humans, object detection, recognition, and tracking are innate. These provide the ability for human to perceive their environment and objects within their environment. This ability however doesn't translate well in computers. In Computer Vision and Multimedia, it is becoming increasingly more important to detect, recognize and track objects in images and/or videos. Many of these applications, such as facial recognition, surveillance, animation, are used for tracking features and/or people. However, these tasks prove challenging for computers to do effectively, as there is a significant amount of data to parse through. Therefore, many techniques and algorithms are needed and therefore researched to try to achieve human like perception. In this literature review, we focus on some novel techniques on object detection and recognition, and how to apply tracking algorithms to the detected features to track the objects' movements.
Your Face Mirrors Your Deepest Beliefs-Predicting Personality and Morals through Facial Emotion Recognition
Dec 23, 2021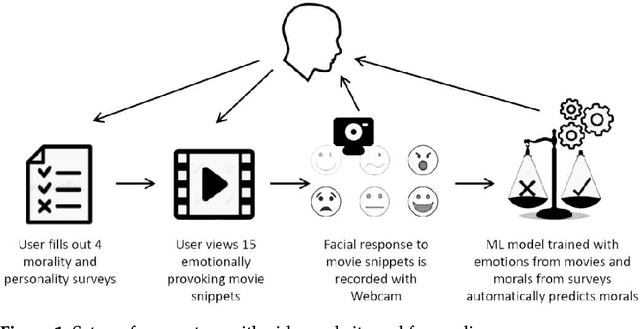
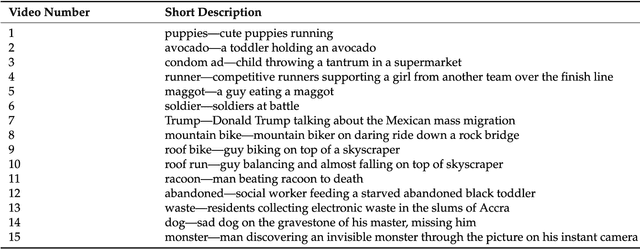
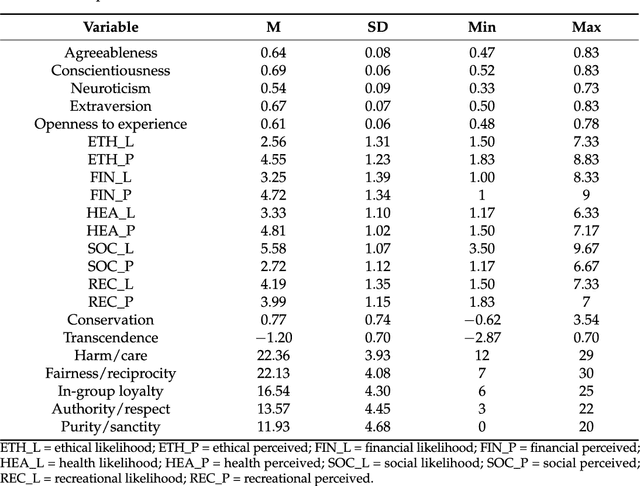
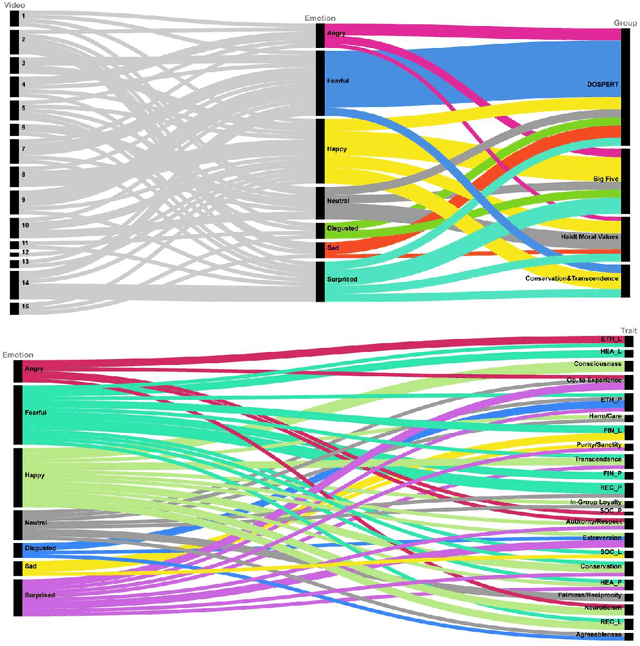
Can we really "read the mind in the eyes"? Moreover, can AI assist us in this task? This paper answers these two questions by introducing a machine learning system that predicts personality characteristics of individuals on the basis of their face. It does so by tracking the emotional response of the individual's face through facial emotion recognition (FER) while watching a series of 15 short videos of different genres. To calibrate the system, we invited 85 people to watch the videos, while their emotional responses were analyzed through their facial expression. At the same time, these individuals also took four well-validated surveys of personality characteristics and moral values: the revised NEO FFI personality inventory, the Haidt moral foundations test, the Schwartz personal value system, and the domain-specific risk-taking scale (DOSPERT). We found that personality characteristics and moral values of an individual can be predicted through their emotional response to the videos as shown in their face, with an accuracy of up to 86% using gradient-boosted trees. We also found that different personality characteristics are better predicted by different videos, in other words, there is no single video that will provide accurate predictions for all personality characteristics, but it is the response to the mix of different videos that allows for accurate prediction.