 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
AI-Assisted Authentication: State of the Art, Taxonomy and Future Roadmap
Apr 25, 2022

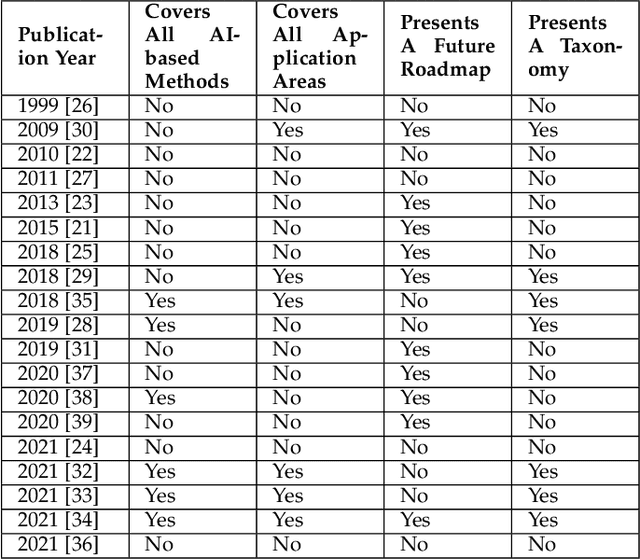
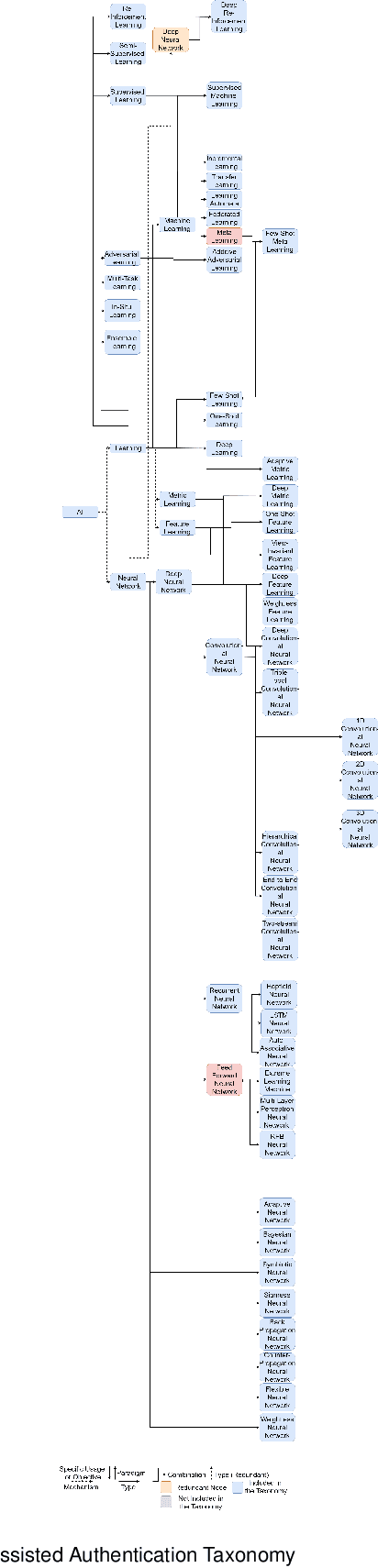
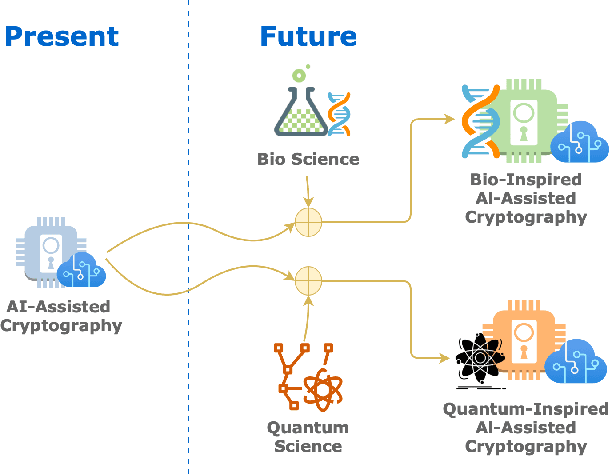
Artificial Intelligence (AI) has found its applications in a variety of environments ranging from data science to cybersecurity. AI helps break through the limitations of traditional algorithms and provides more efficient and flexible methods for solving problems. In this paper, we focus on the applications of artificial intelligence in authentication, which is used in a wide range of scenarios including facial recognition to access buildings, keystroke dynamics to unlock smartphones. With the emerging AI-assisted authentication schemes, our comprehensive survey provides an overall understanding on a high level, which paves the way for future research in this area. In contrast to other relevant surveys, our research is the first of its kind to focus on the roles of AI in authentication.
Learning Person-specific Network Representation for Apparent Personality Traits Recognition
Mar 01, 2023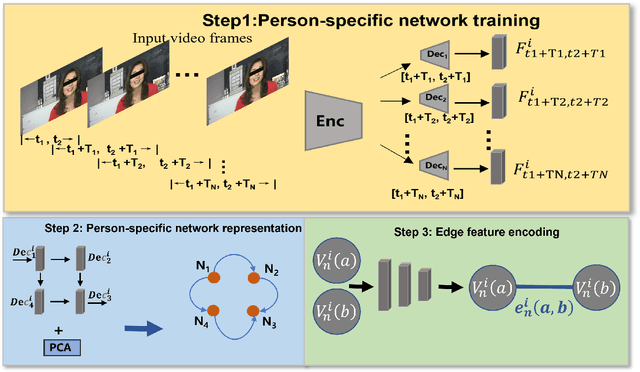
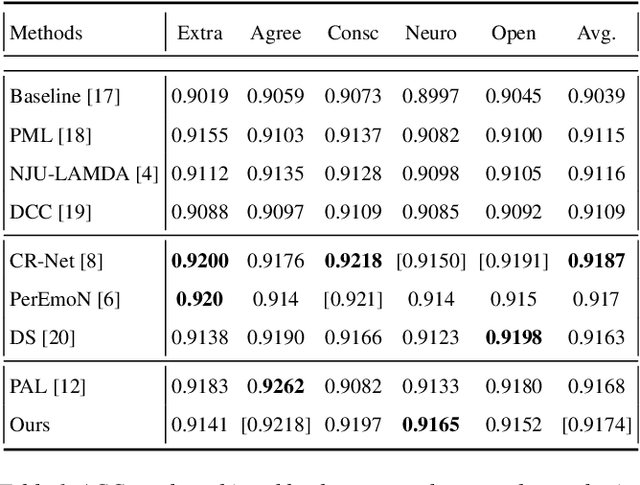
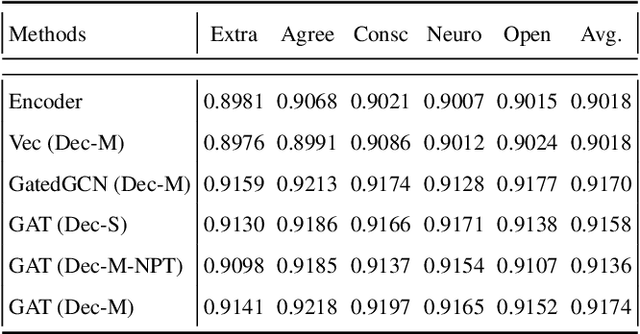
Recent studies show that apparent personality traits can be reflected from human facial behavior dynamics. However, most existing methods can only encode single-scale short-term facial behaviors in the latent features for personality recognition. In this paper, we propose to recognize apparent personality recognition approach which first trains a person-specific network for each subject, modelling multi-scale long-term person-specific behavior evolution of the subject. Consequently, we hypothesize that the weights of the network contain the person-specific facial behavior-related cues of the subject. Then, we propose to encode the weights of the person-specific network to a graph representation, as the personality representation for the subject, allowing them to be processed by standard Graph Neural Networks (GNNs) for personality traits recognition. The experimental results show that our novel network weights-based approach achieved superior performance than most traditional latent feature-based approaches, and has comparable performance to the state-of-the-art method. Importantly, the produced graph representations produce robust results when using different GNNs. This paper further validated that person-specific network's weights are correlated to the subject's personality.
Fairness Properties of Face Recognition and Obfuscation Systems
Aug 05, 2021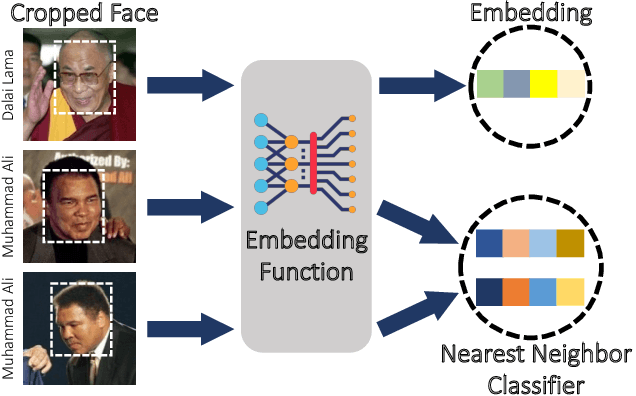
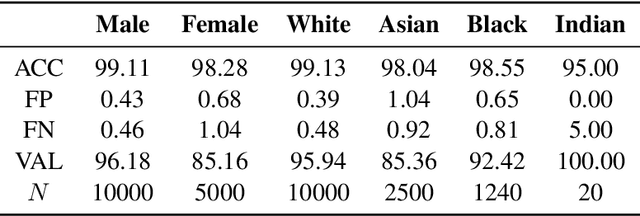
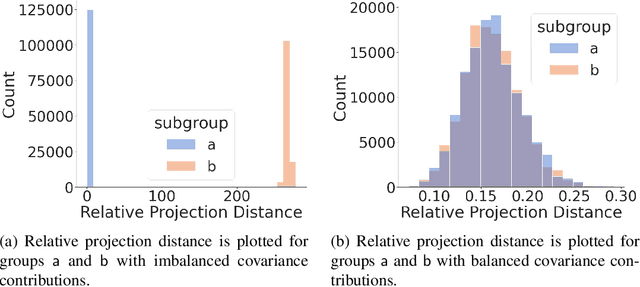
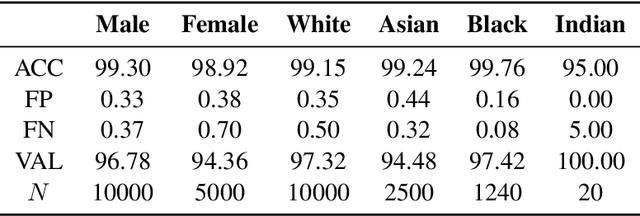
The proliferation of automated facial recognition in various commercial and government sectors has caused significant privacy concerns for individuals. A recent and popular approach to address these privacy concerns is to employ evasion attacks against the metric embedding networks powering facial recognition systems. Face obfuscation systems generate imperceptible perturbations, when added to an image, cause the facial recognition system to misidentify the user. The key to these approaches is the generation of perturbations using a pre-trained metric embedding network followed by their application to an online system, whose model might be proprietary. This dependence of face obfuscation on metric embedding networks, which are known to be unfair in the context of facial recognition, surfaces the question of demographic fairness -- \textit{are there demographic disparities in the performance of face obfuscation systems?} To address this question, we perform an analytical and empirical exploration of the performance of recent face obfuscation systems that rely on deep embedding networks. We find that metric embedding networks are demographically aware; they cluster faces in the embedding space based on their demographic attributes. We observe that this effect carries through to the face obfuscation systems: faces belonging to minority groups incur reduced utility compared to those from majority groups. For example, the disparity in average obfuscation success rate on the online Face++ API can reach up to 20 percentage points. Further, for some demographic groups, the average perturbation size increases by up to 17\% when choosing a target identity belonging to a different demographic group versus the same demographic group. Finally, we present a simple analytical model to provide insights into these phenomena.
Efficient Web-based Facial Recognition System Employing 2DHOG
Feb 11, 2012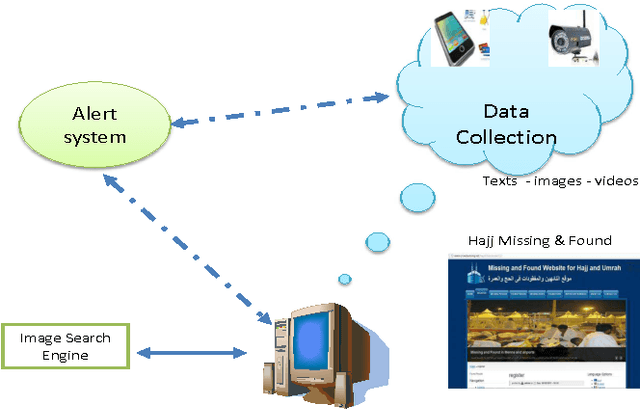
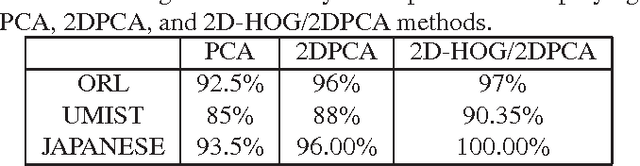
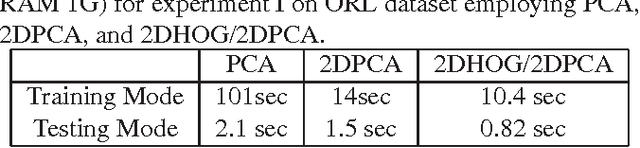
In this paper, a system for facial recognition to identify missing and found people in Hajj and Umrah is described as a web portal. Explicitly, we present a novel algorithm for recognition and classifications of facial images based on applying 2DPCA to a 2D representation of the Histogram of oriented gradients (2D-HOG) which maintains the spatial relation between pixels of the input images. This algorithm allows a compact representation of the images which reduces the computational complexity and the storage requirments, while maintaining the highest reported recognition accuracy. This promotes this method for usage with very large datasets. Large dataset was collected for people in Hajj. Experimental results employing ORL, UMIST, JAFFE, and HAJJ datasets confirm these excellent properties.
Facial Emotion Recognition Using Deep Learning
Oct 19, 2019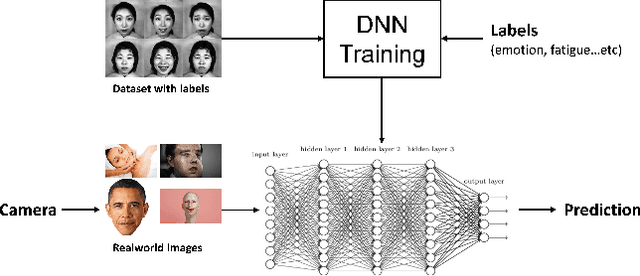
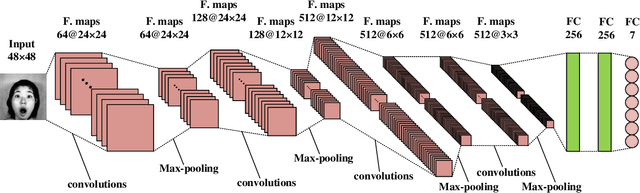
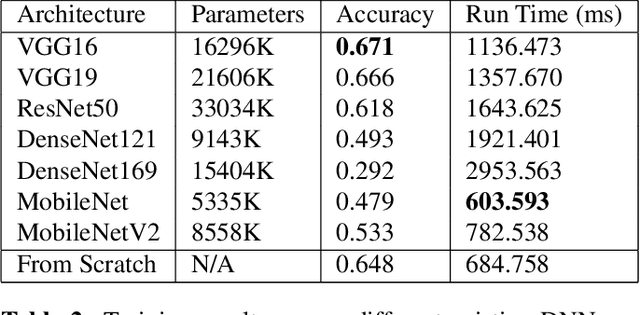
We aim to construct a system that captures real-world facial images through the front camera on a laptop. The system is capable of processing/recognizing the captured image and predict a result in real-time. In this system, we exploit the power of deep learning technique to learn a facial emotion recognition (FER) model based on a set of labeled facial images. Finally, experiments are conducted to evaluate our model using largely used public database.
AU-Expression Knowledge Constrained Representation Learning for Facial Expression Recognition
Dec 29, 2020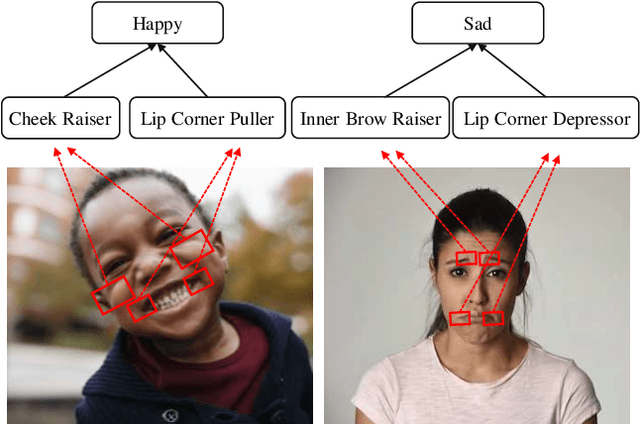
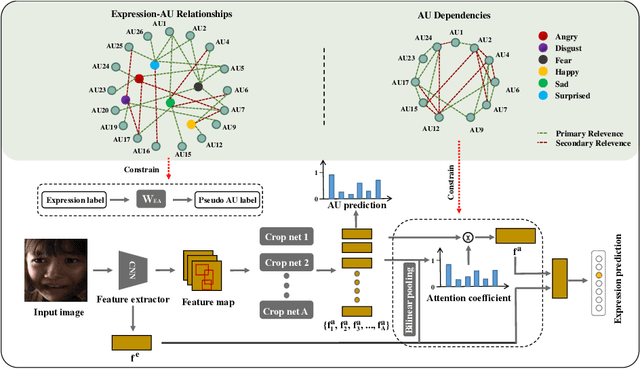
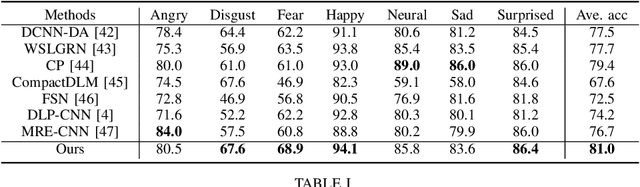

Recognizing human emotion/expressions automatically is quite an expected ability for intelligent robotics, as it can promote better communication and cooperation with humans. Current deep-learning-based algorithms may achieve impressive performance in some lab-controlled environments, but they always fail to recognize the expressions accurately for the uncontrolled in-the-wild situation. Fortunately, facial action units (AU) describe subtle facial behaviors, and they can help distinguish uncertain and ambiguous expressions. In this work, we explore the correlations among the action units and facial expressions, and devise an AU-Expression Knowledge Constrained Representation Learning (AUE-CRL) framework to learn the AU representations without AU annotations and adaptively use representations to facilitate facial expression recognition. Specifically, it leverages AU-expression correlations to guide the learning of the AU classifiers, and thus it can obtain AU representations without incurring any AU annotations. Then, it introduces a knowledge-guided attention mechanism that mines useful AU representations under the constraint of AU-expression correlations. In this way, the framework can capture local discriminative and complementary features to enhance facial representation for facial expression recognition. We conduct experiments on the challenging uncontrolled datasets to demonstrate the superiority of the proposed framework over current state-of-the-art methods.
A survey on facial image deblurring
Feb 10, 2023
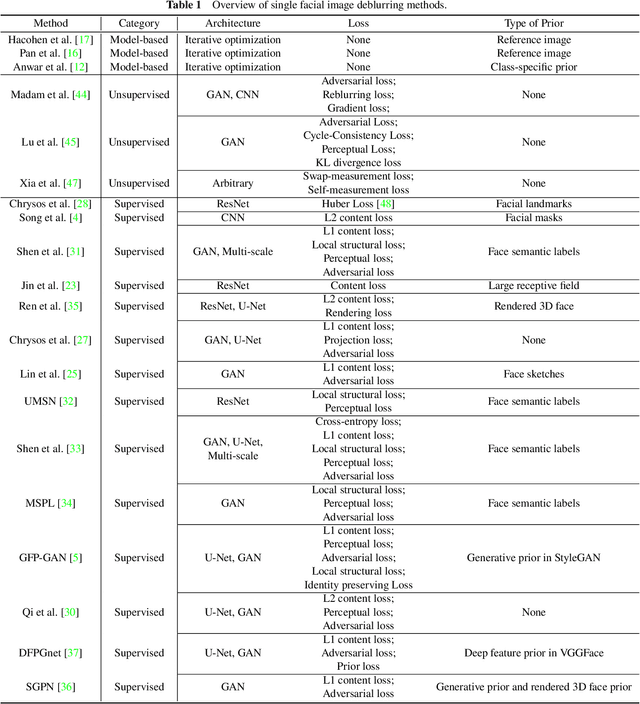
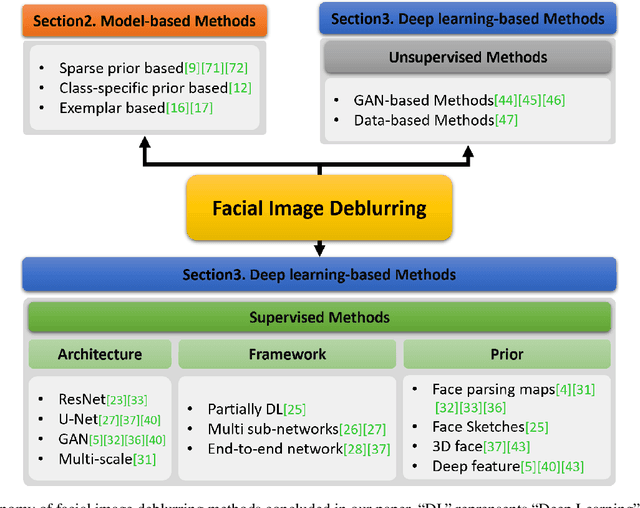
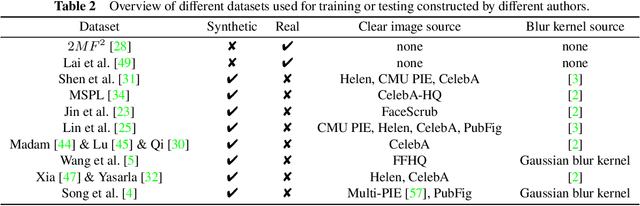
When the facial image is blurred, it has a great impact on high-level vision tasks such as face recognition. The purpose of facial image deblurring is to recover a clear image from a blurry input image, which can improve the recognition accuracy and so on. General deblurring methods can not perform well on facial images. So some face deblurring methods are proposed to improve the performance by adding semantic or structural information as specific priors according to the characteristics of facial images. This paper surveys and summarizes recently published methods for facial image deblurring, most of which are based on deep learning. Firstly, we give a brief introduction to the modeling of image blur. Next, we summarize face deblurring methods into two categories, namely model-based methods and deep learning-based methods. Furthermore, we summarize the datasets, loss functions, and performance evaluation metrics commonly used in the neural network training process. We show the performance of classical methods on these datasets and metrics and give a brief discussion on the differences of model-based and learning-based methods. Finally, we discuss current challenges and possible future research directions.
Using Deep Autoencoders for Facial Expression Recognition
Jan 25, 2018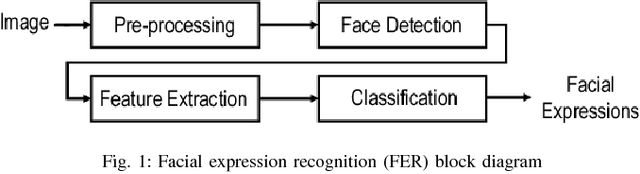
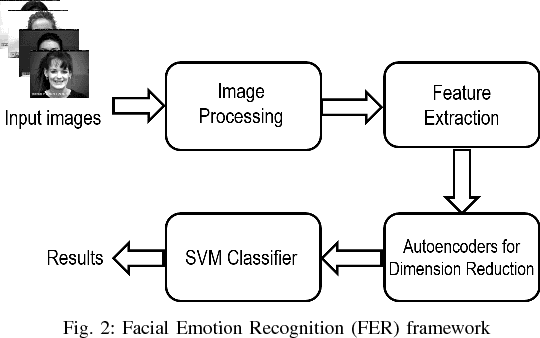

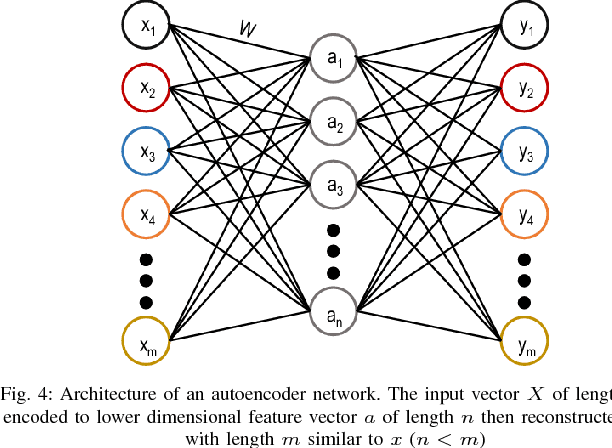
Feature descriptors involved in image processing are generally manually chosen and high dimensional in nature. Selecting the most important features is a very crucial task for systems like facial expression recognition. This paper investigates the performance of deep autoencoders for feature selection and dimension reduction for facial expression recognition on multiple levels of hidden layers. The features extracted from the stacked autoencoder outperformed when compared to other state-of-the-art feature selection and dimension reduction techniques.
Dynamic Facial Expression Recognition under Partial Occlusion with Optical Flow Reconstruction
Dec 24, 2020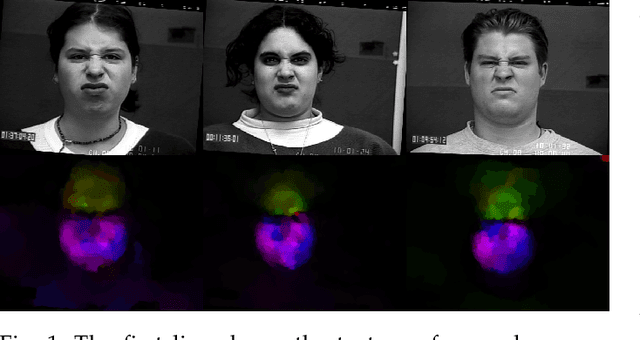
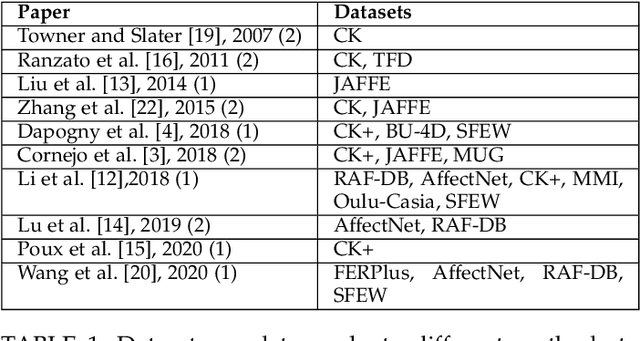
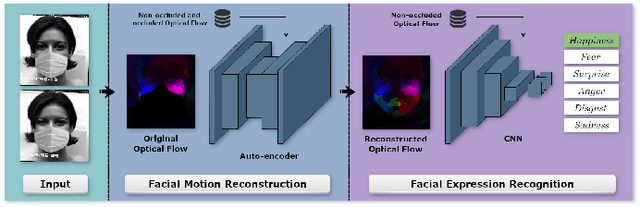
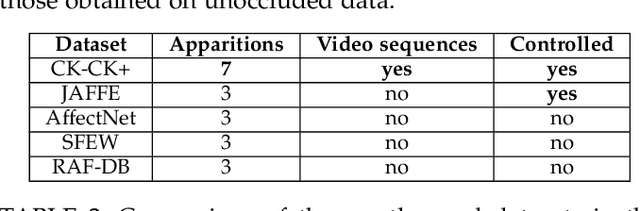
Video facial expression recognition is useful for many applications and received much interest lately. Although some solutions give really good results in a controlled environment (no occlusion), recognition in the presence of partial facial occlusion remains a challenging task. To handle occlusions, solutions based on the reconstruction of the occluded part of the face have been proposed. These solutions are mainly based on the texture or the geometry of the face. However, the similarity of the face movement between different persons doing the same expression seems to be a real asset for the reconstruction. In this paper we exploit this asset and propose a new solution based on an auto-encoder with skip connections to reconstruct the occluded part of the face in the optical flow domain. To the best of our knowledge, this is the first proposition to directly reconstruct the movement for facial expression recognition. We validated our approach in the controlled dataset CK+ on which different occlusions were generated. Our experiments show that the proposed method reduce significantly the gap, in terms of recognition accuracy, between occluded and non-occluded situations. We also compare our approach with existing state-of-the-art solutions. In order to lay the basis of a reproducible and fair comparison in the future, we also propose a new experimental protocol that includes occlusion generation and reconstruction evaluation.
Neural Network Facial Authentication for Public Electric Vehicle Charging Station
Jun 19, 2021
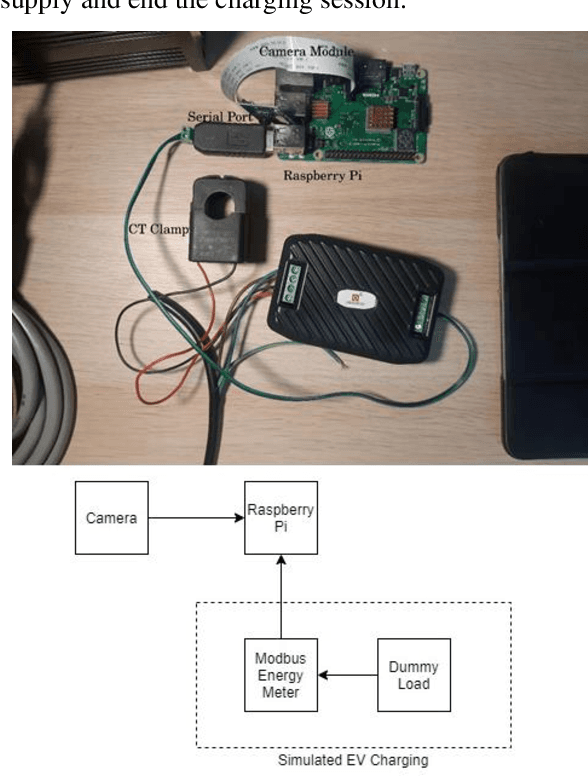

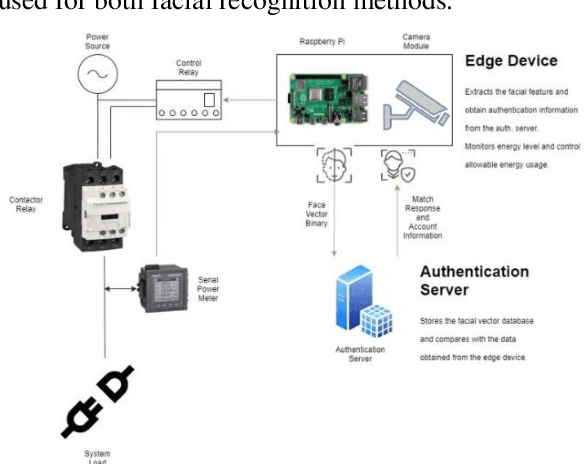
This study is to investigate and compare the facial recognition accuracy performance of Dlib ResNet against a K-Nearest Neighbour (KNN) classifier. Particularly when used against a dataset from an Asian ethnicity as Dlib ResNet was reported to have an accuracy deficiency when it comes to Asian faces. The comparisons are both implemented on the facial vectors extracted using the Histogram of Oriented Gradients (HOG) method and use the same dataset for a fair comparison. Authentication of a user by facial recognition in an electric vehicle (EV) charging station demonstrates a practical use case for such an authentication system.