 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Facial Expression Recognition on a Quantum Computer
Feb 09, 2021

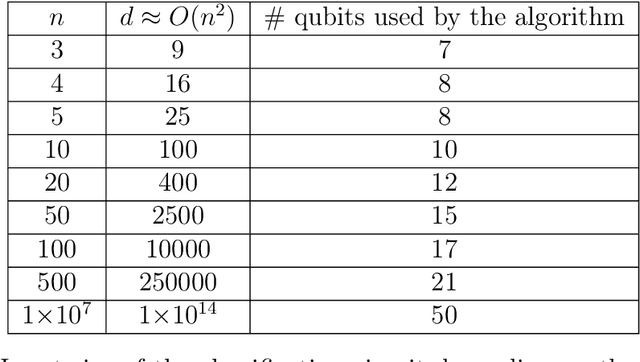

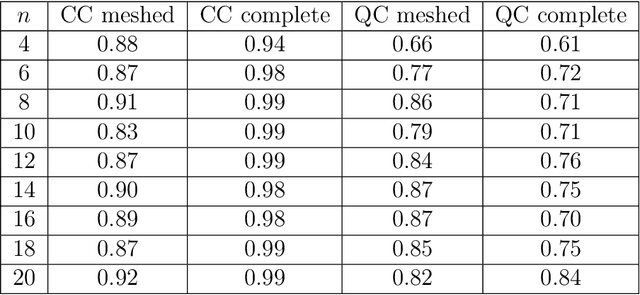
We address the problem of facial expression recognition and show a possible solution using a quantum machine learning approach. In order to define an efficient classifier for a given dataset, our approach substantially exploits quantum interference. By representing face expressions via graphs, we define a classifier as a quantum circuit that manipulates the graphs adjacency matrices encoded into the amplitudes of some appropriately defined quantum states. We discuss the accuracy of the quantum classifier evaluated on the quantum simulator available on the IBM Quantum Experience cloud platform, and compare it with the accuracy of one of the best classical classifier.
Are Commercial Face Detection Models as Biased as Academic Models?
Jan 25, 2022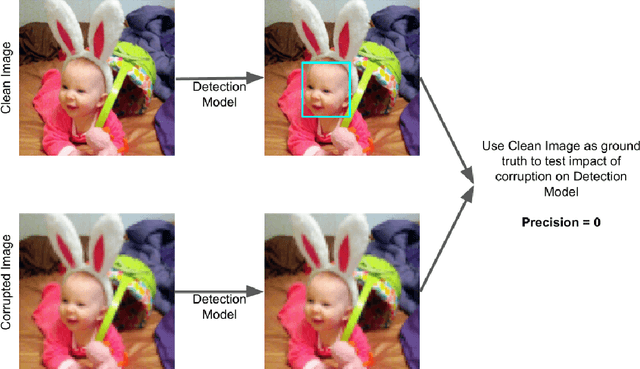
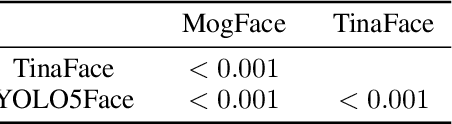
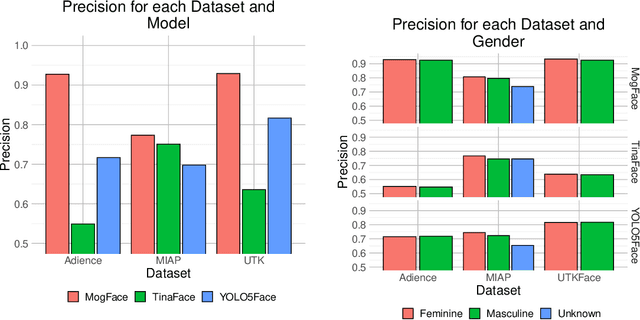
As facial recognition systems are deployed more widely, scholars and activists have studied their biases and harms. Audits are commonly used to accomplish this and compare the algorithmic facial recognition systems' performance against datasets with various metadata labels about the subjects of the images. Seminal works have found discrepancies in performance by gender expression, age, perceived race, skin type, etc. These studies and audits often examine algorithms which fall into two categories: academic models or commercial models. We present a detailed comparison between academic and commercial face detection systems, specifically examining robustness to noise. We find that state-of-the-art academic face detection models exhibit demographic disparities in their noise robustness, specifically by having statistically significant decreased performance on older individuals and those who present their gender in a masculine manner. When we compare the size of these disparities to that of commercial models, we conclude that commercial models - in contrast to their relatively larger development budget and industry-level fairness commitments - are always as biased or more biased than an academic model.
Generating Dataset For Large-scale 3D Facial Emotion Recognition
Sep 16, 2021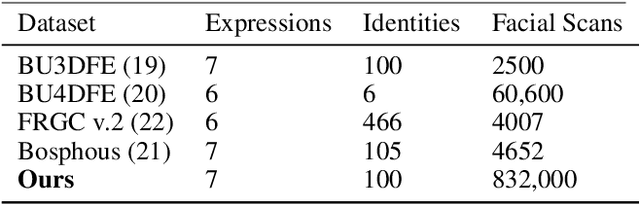
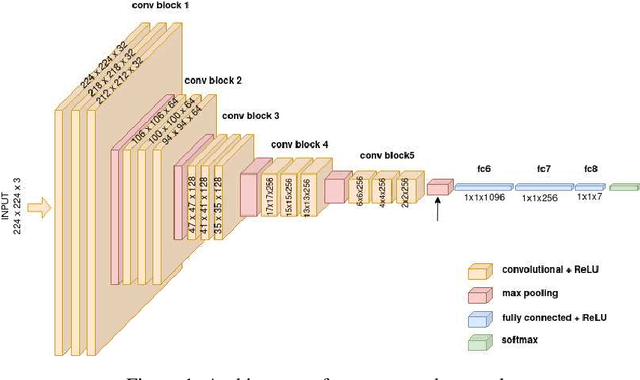
The tremendous development in deep learning has led facial expression recognition (FER) to receive much attention in the past few years. Although 3D FER has an inherent edge over its 2D counterpart, work on 2D images has dominated the field. The main reason for the slow development of 3D FER is the unavailability of large training and large test datasets. Recognition accuracies have already saturated on existing 3D emotion recognition datasets due to their small gallery sizes. Unlike 2D photographs, 3D facial scans are not easy to collect, causing a bottleneck in the development of deep 3D FER networks and datasets. In this work, we propose a method for generating a large dataset of 3D faces with labeled emotions. We also develop a deep convolutional neural network(CNN) for 3D FER trained on 624,000 3D facial scans. The test data comprises 208,000 3D facial scans.
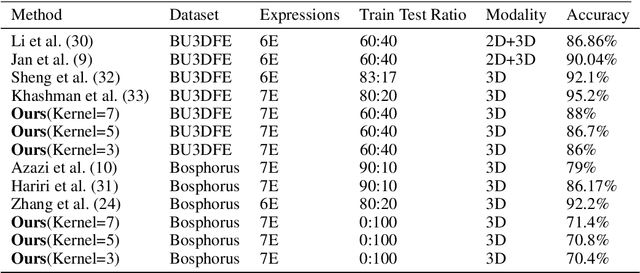
Deep and Shallow Covariance Feature Quantization for 3D Facial Expression Recognition
May 12, 2021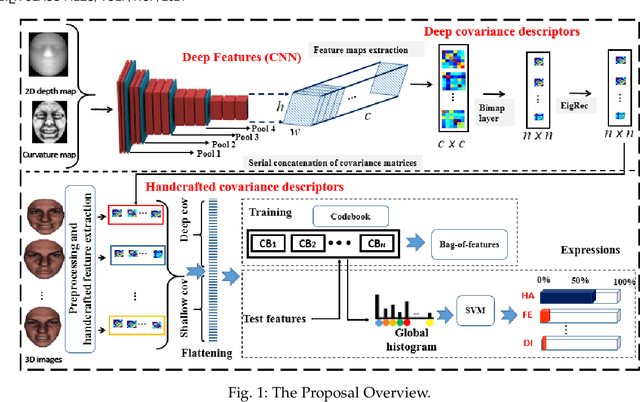
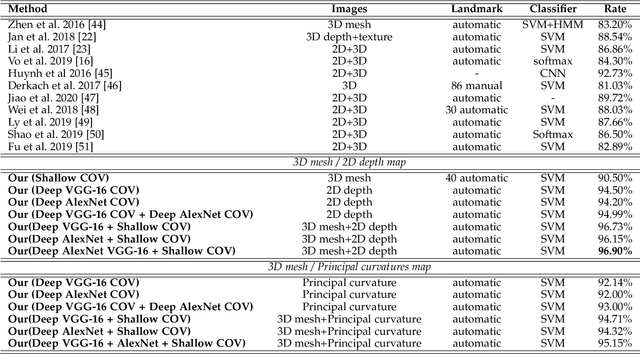
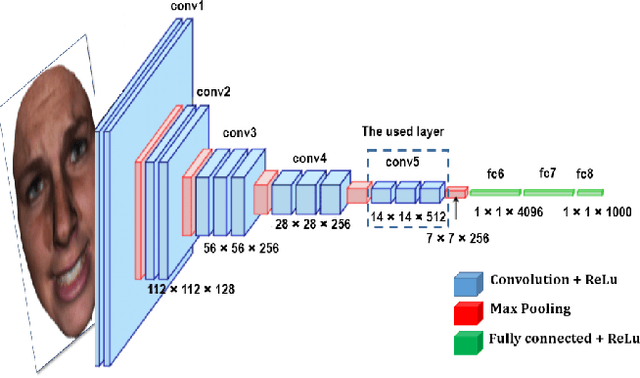
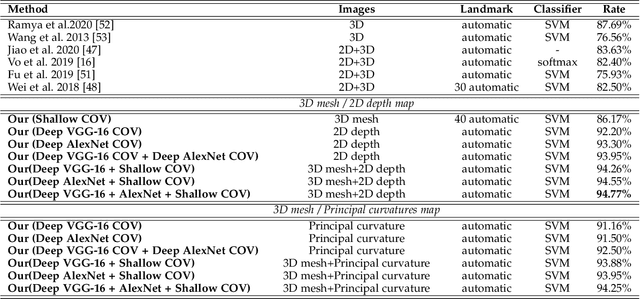
Facial expressions recognition (FER) of 3D face scans has received a significant amount of attention in recent years. Most of the facial expression recognition methods have been proposed using mainly 2D images. These methods suffer from several issues like illumination changes and pose variations. Moreover, 2D mapping from 3D images may lack some geometric and topological characteristics of the face. Hence, to overcome this problem, a multi-modal 2D + 3D feature-based method is proposed. We extract shallow features from the 3D images, and deep features using Convolutional Neural Networks (CNN) from the transformed 2D images. Combining these features into a compact representation uses covariance matrices as descriptors for both features instead of single-handedly descriptors. A covariance matrix learning is used as a manifold layer to reduce the deep covariance matrices size and enhance their discrimination power while preserving their manifold structure. We then use the Bag-of-Features (BoF) paradigm to quantize the covariance matrices after flattening. Accordingly, we obtained two codebooks using shallow and deep features. The global codebook is then used to feed an SVM classifier. High classification performances have been achieved on the BU-3DFE and Bosphorus datasets compared to the state-of-the-art methods.
I am Only Happy When There is Light: The Impact of Environmental Changes on Affective Facial Expressions Recognition
Oct 28, 2022
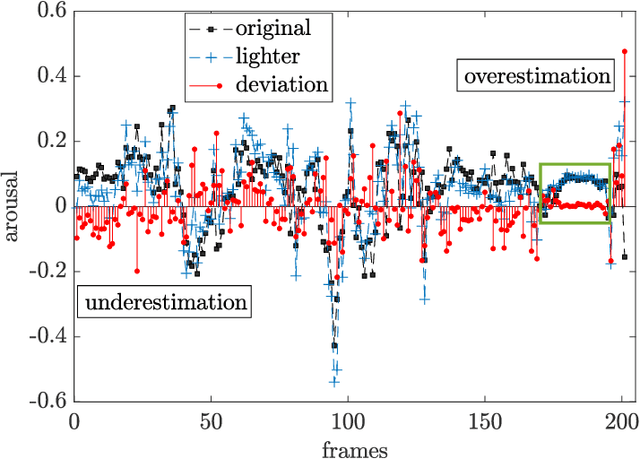
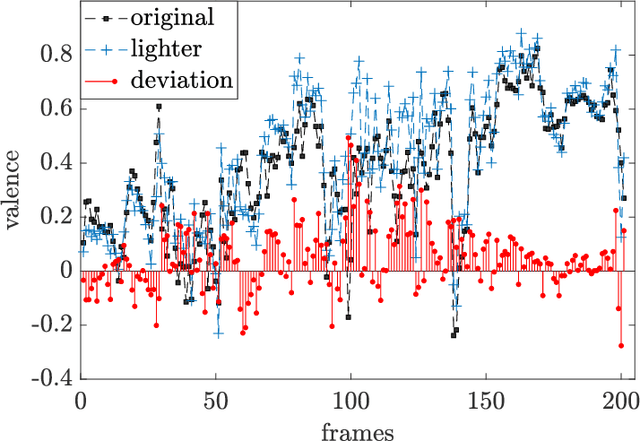
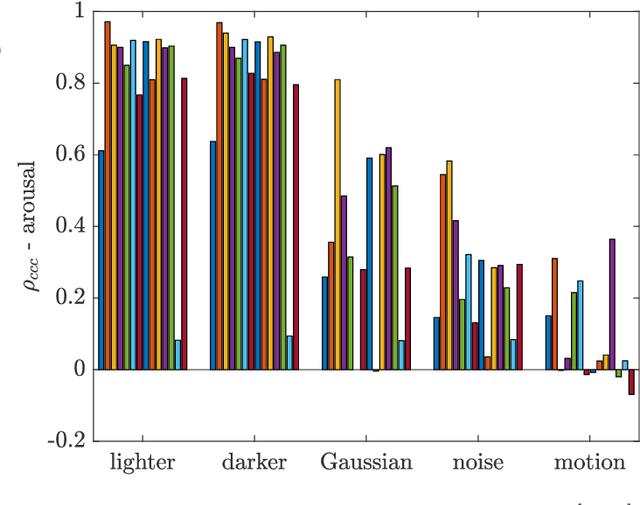
Human-robot interaction (HRI) benefits greatly from advances in the machine learning field as it allows researchers to employ high-performance models for perceptual tasks like detection and recognition. Especially deep learning models, either pre-trained for feature extraction or used for classification, are now established methods to characterize human behaviors in HRI scenarios and to have social robots that understand better those behaviors. As HRI experiments are usually small-scale and constrained to particular lab environments, the questions are how well can deep learning models generalize to specific interaction scenarios, and further, how good is their robustness towards environmental changes? These questions are important to address if the HRI field wishes to put social robotic companions into real environments acting consistently, i.e. changing lighting conditions or moving people should still produce the same recognition results. In this paper, we study the impact of different image conditions on the recognition of arousal and valence from human facial expressions using the FaceChannel framework \cite{Barro20}. Our results show how the interpretation of human affective states can differ greatly in either the positive or negative direction even when changing only slightly the image properties. We conclude the paper with important points to consider when employing deep learning models to ensure sound interpretation of HRI experiments.
Pose Impact Estimation on Face Recognition using 3D-Aware Synthetic Data with Application to Quality Assessment
Mar 01, 2023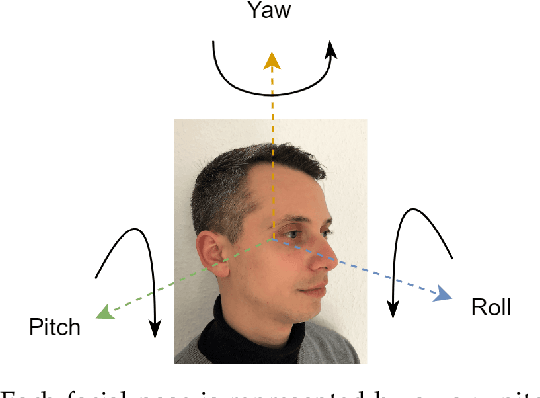



Evaluating the quality of facial images is essential for operating face recognition systems with sufficient accuracy. The recent advances in face quality standardisation (ISO/IEC WD 29794-5) recommend the usage of component quality measures for breaking down face quality into its individual factors, hence providing valuable feedback for operators to re-capture low-quality images. In light of recent advances in 3D-aware generative adversarial networks, we propose a novel dataset, "Syn-YawPitch", comprising 1,000 identities with varying yaw-pitch angle combinations. Utilizing this dataset, we demonstrate that pitch angles beyond 30 degrees have a significant impact on the biometric performance of current face recognition systems. Furthermore, we propose a lightweight and efficient pose quality predictor that adheres to the standards of ISO/IEC WD 29794-5 and is freely available for use at https://github.com/datasciencegrimmer/Syn-YawPitch/.
Facial Recognition in Collaborative Learning Videos
Oct 25, 2021
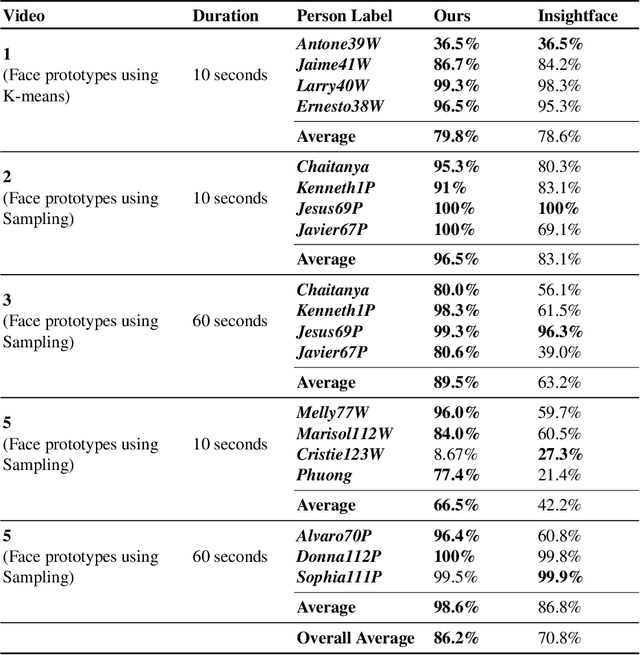
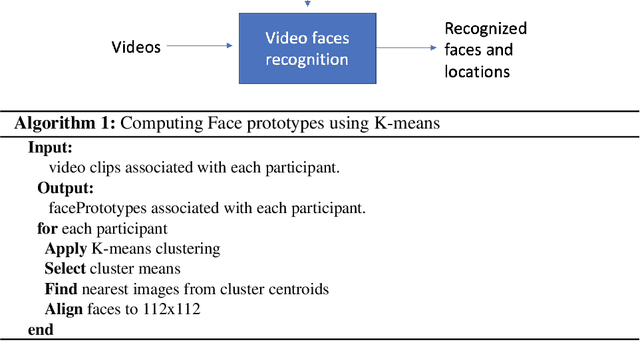
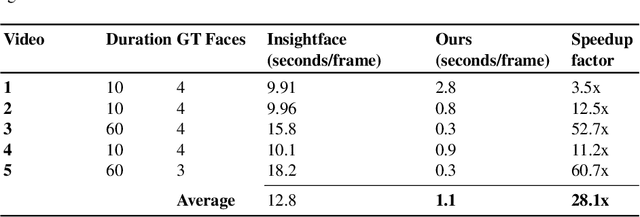
Face recognition in collaborative learning videos presents many challenges. In collaborative learning videos, students sit around a typical table at different positions to the recording camera, come and go, move around, get partially or fully occluded. Furthermore, the videos tend to be very long, requiring the development of fast and accurate methods. We develop a dynamic system of recognizing participants in collaborative learning systems. We address occlusion and recognition failures by using past information about the face detection history. We address the need for detecting faces from different poses and the need for speed by associating each participant with a collection of prototype faces computed through sampling or K-means clustering. Our results show that the proposed system is proven to be very fast and accurate. We also compare our system against a baseline system that uses InsightFace [2] and the original training video segments. We achieved an average accuracy of 86.2% compared to 70.8% for the baseline system. On average, our recognition rate was 28.1 times faster than the baseline system.
Speaker Recognition in Realistic Scenario Using Multimodal Data
Feb 25, 2023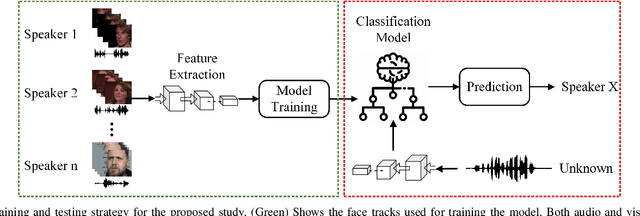
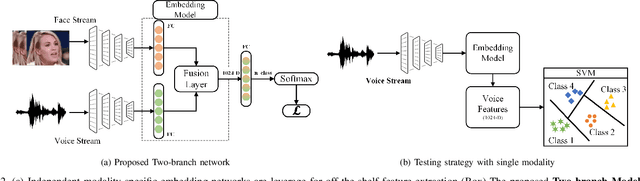
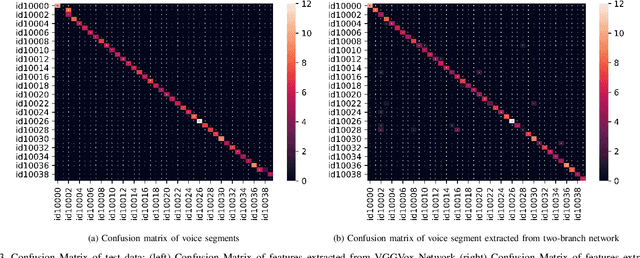
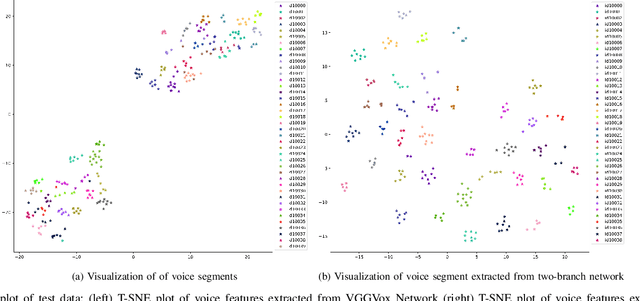
In recent years, an association is established between faces and voices of celebrities leveraging large scale audio-visual information from YouTube. The availability of large scale audio-visual datasets is instrumental in developing speaker recognition methods based on standard Convolutional Neural Networks. Thus, the aim of this paper is to leverage large scale audio-visual information to improve speaker recognition task. To achieve this task, we proposed a two-branch network to learn joint representations of faces and voices in a multimodal system. Afterwards, features are extracted from the two-branch network to train a classifier for speaker recognition. We evaluated our proposed framework on a large scale audio-visual dataset named VoxCeleb$1$. Our results show that addition of facial information improved the performance of speaker recognition. Moreover, our results indicate that there is an overlap between face and voice.
Towards Multimodal Vision-Language Models Generating Non-Generic Text
Jul 09, 2022
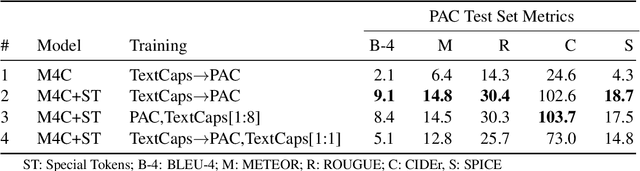
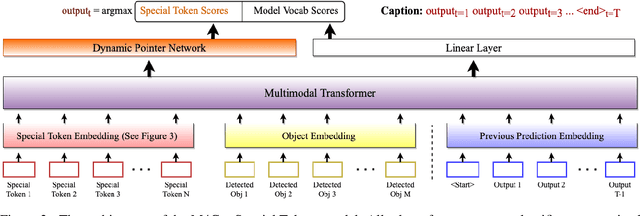

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.
Fairness Matters -- A Data-Driven Framework Towards Fair and High Performing Facial Recognition Systems
Sep 16, 2020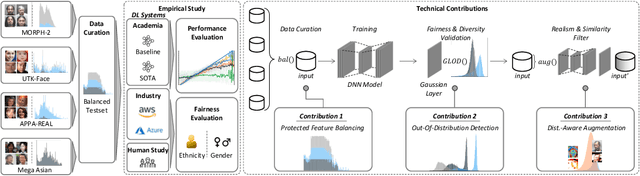


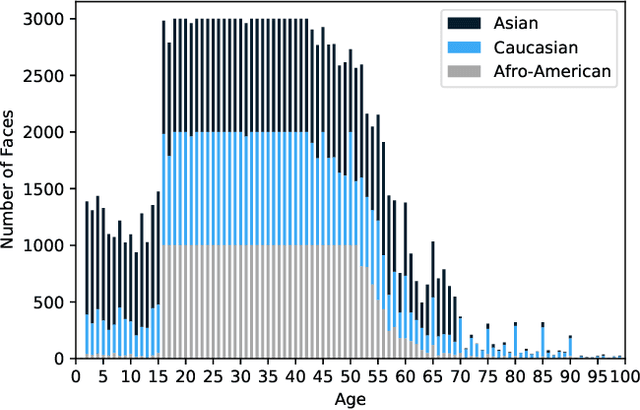
Facial recognition technologies are widely used in governmental and industrial applications. Together with the advancements in deep learning (DL), human-centric tasks such as accurate age prediction based on face images become feasible. However, the issue of fairness when predicting the age for different ethnicity and gender remains an open problem. Policing systems use age to estimate the likelihood of someone to commit a crime, where younger suspects tend to be more likely involved. Unfair age prediction may lead to unfair treatment of humans not only in crime prevention but also in marketing, identity acquisition and authentication. Therefore, this work follows two parts. First, an empirical study is conducted evaluating performance and fairness of state-of-the-art systems for age prediction including baseline and most recent works of academia and the main industrial service providers (Amazon AWS and Microsoft Azure). Building on the findings we present a novel approach to mitigate unfairness and enhance performance, using distribution-aware dataset curation and augmentation. Distribution-awareness is based on out-of-distribution detection which is utilized to validate equal and diverse DL system behavior towards e.g. ethnicity and gender. In total we train 24 DNN models and utilize one million data points to assess performance and fairness of the state-of-the-art for face recognition algorithms. We demonstrate an improvement in mean absolute age prediction error from 7.70 to 3.39 years and a 4-fold increase in fairness towards ethnicity when compared to related work. Utilizing the presented methodology we are able to outperform leading industry players such as Amazon AWS or Microsoft Azure in both fairness and age prediction accuracy and provide the necessary guidelines to assess quality and enhance face recognition systems based on DL techniques.