 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
2D+3D facial expression recognition via embedded tensor manifold regularization
Jan 29, 2022
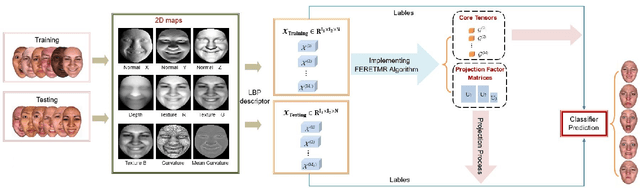
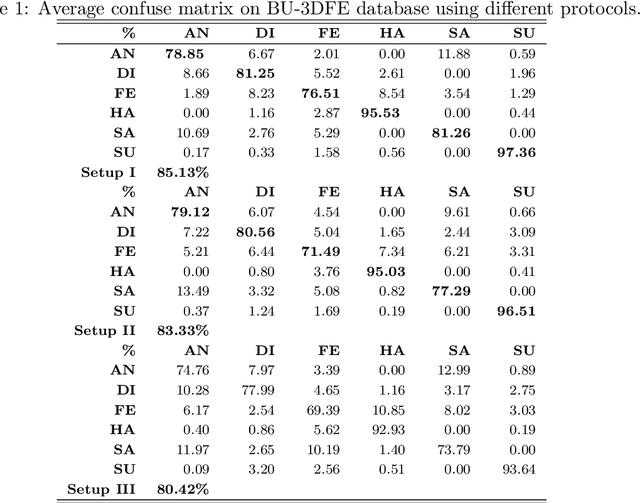
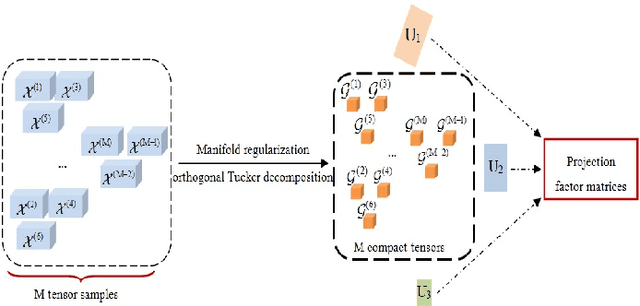
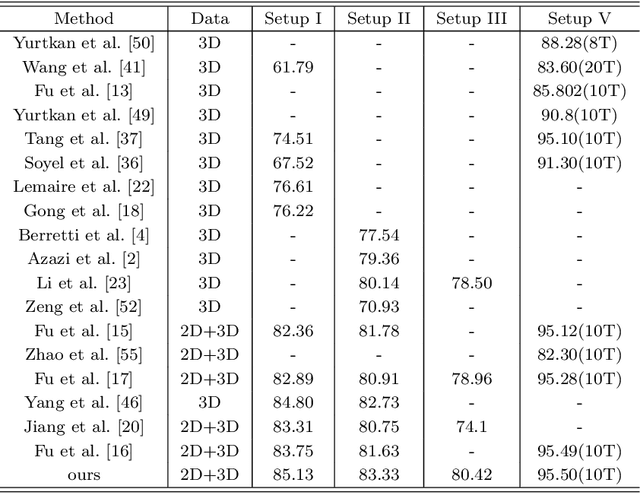
In this paper, a novel approach via embedded tensor manifold regularization for 2D+3D facial expression recognition (FERETMR) is proposed. Firstly, 3D tensors are constructed from 2D face images and 3D face shape models to keep the structural information and correlations. To maintain the local structure (geometric information) of 3D tensor samples in the low-dimensional tensors space during the dimensionality reduction, the $\ell_0$-norm of the core tensors and a tensor manifold regularization scheme embedded on core tensors are adopted via a low-rank truncated Tucker decomposition on the generated tensors. As a result, the obtained factor matrices will be used for facial expression classification prediction. To make the resulting tensor optimization more tractable, $\ell_1$-norm surrogate is employed to relax $\ell_0$-norm and hence the resulting tensor optimization problem has a nonsmooth objective function due to the $\ell_1$-norm and orthogonal constraints from the orthogonal Tucker decomposition. To efficiently tackle this tensor optimization problem, we establish the first-order optimality condition in terms of stationary points, and then design a block coordinate descent (BCD) algorithm with convergence analysis and the computational complexity. Numerical results on BU-3DFE database and Bosphorus databases demonstrate the effectiveness of our proposed approach.
Driving Safety Prediction and Safe Route Mapping Using In-vehicle and Roadside Data
Sep 12, 2022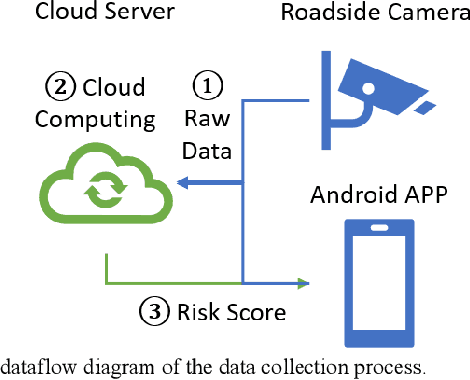
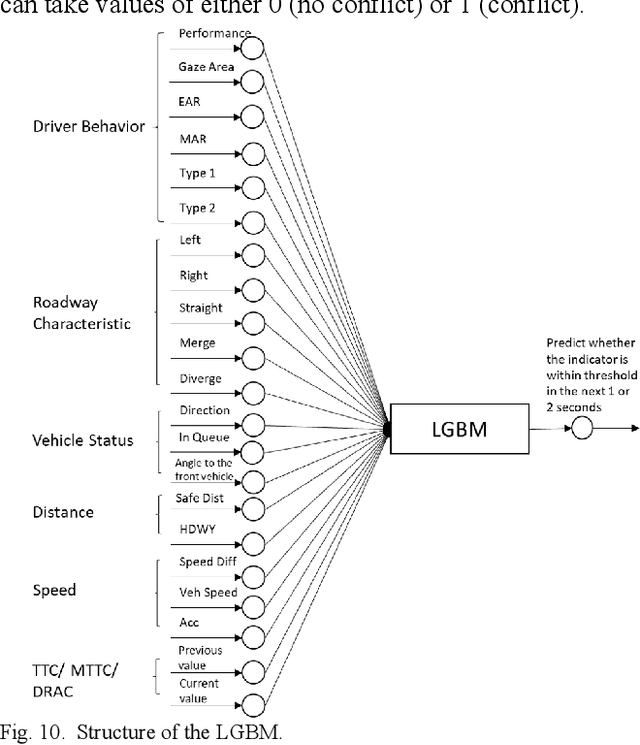
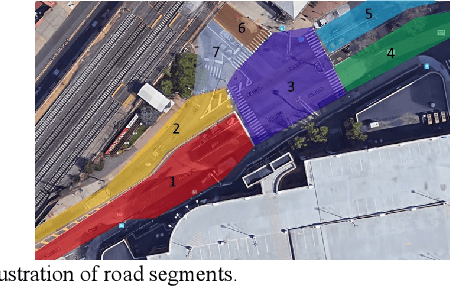
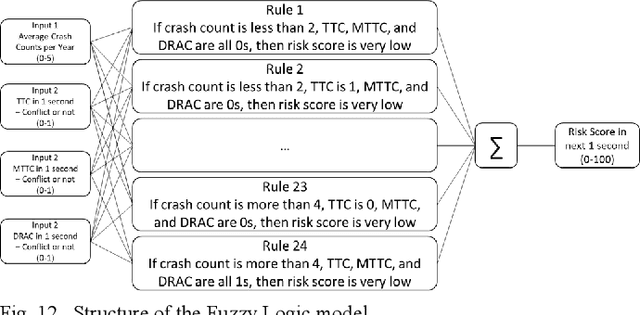
Risk assessment of roadways is commonly practiced based on historical crash data. Information on driver behaviors and real-time traffic situations is sometimes missing. In this paper, the Safe Route Mapping (SRM) model, a methodology for developing dynamic risk heat maps of roadways, is extended to consider driver behaviors when making predictions. An Android App is designed to gather drivers' information and upload it to a server. On the server, facial recognition extracts drivers' data, such as facial landmarks, gaze directions, and emotions. The driver's drowsiness and distraction are detected, and driving performance is evaluated. Meanwhile, dynamic traffic information is captured by a roadside camera and uploaded to the same server. A longitudinal-scanline-based arterial traffic video analytics is applied to recognize vehicles from the video to build speed and trajectory profiles. Based on these data, a LightGBM model is introduced to predict conflict indices for drivers in the next one or two seconds. Then, multiple data sources, including historical crash counts and predicted traffic conflict indicators, are combined using a Fuzzy logic model to calculate risk scores for road segments. The proposed SRM model is illustrated using data collected from an actual traffic intersection and a driving simulation platform. The prediction results show that the model is accurate, and the added driver behavior features will improve the model's performance. Finally, risk heat maps are generated for visualization purposes. The authorities can use the dynamic heat map to designate safe corridors and dispatch law enforcement and drivers for early warning and trip planning.
A Systematic Evaluation of Domain Adaptation in Facial Expression Recognition
Jun 29, 2021
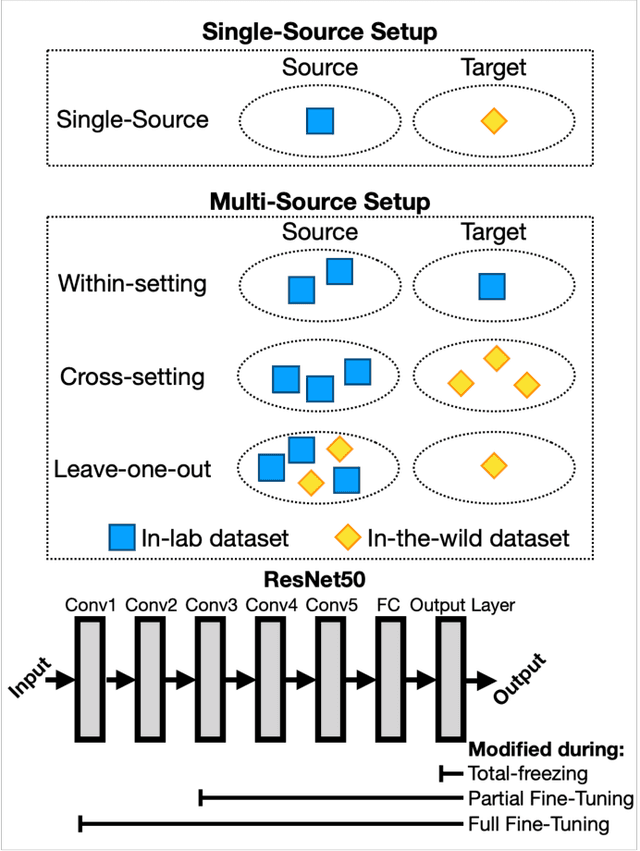

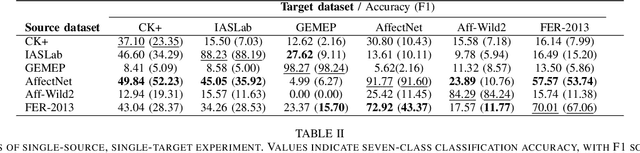
Facial Expression Recognition is a commercially important application, but one common limitation is that applications often require making predictions on out-of-sample distributions, where target images may have very different properties from the images that the model was trained on. How well, or badly, do these models do on unseen target domains? In this paper, we provide a systematic evaluation of domain adaptation in facial expression recognition. Using state-of-the-art transfer learning techniques and six commonly-used facial expression datasets (three collected in the lab and three "in-the-wild"), we conduct extensive round-robin experiments to examine the classification accuracies for a state-of-the-art CNN model. We also perform multi-source experiments where we examine a model's ability to transfer from multiple source datasets, including (i) within-setting (e.g., lab to lab), (ii) cross-setting (e.g., in-the-wild to lab), (iii) mixed-setting (e.g., lab and wild to lab) transfer learning experiments. We find sobering results that the accuracy of transfer learning is not high, and varies idiosyncratically with the target dataset, and to a lesser extent the source dataset. Generally, the best settings for transfer include fine-tuning the weights of a pre-trained model, and we find that training with more datasets, regardless of setting, improves transfer performance. We end with a discussion of the need for more -- and regular -- systematic investigations into the generalizability of FER models, especially for deployed applications.
Does lossy image compression affect racial bias within face recognition?
Aug 16, 2022
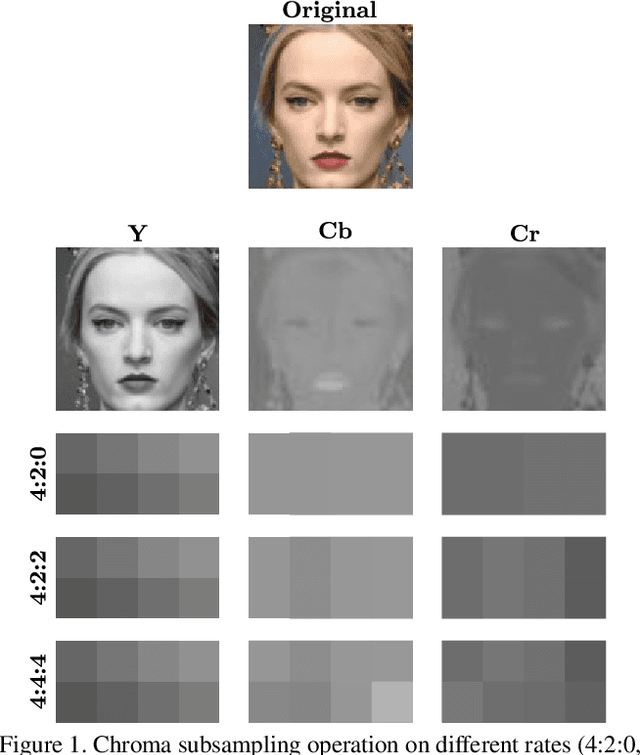
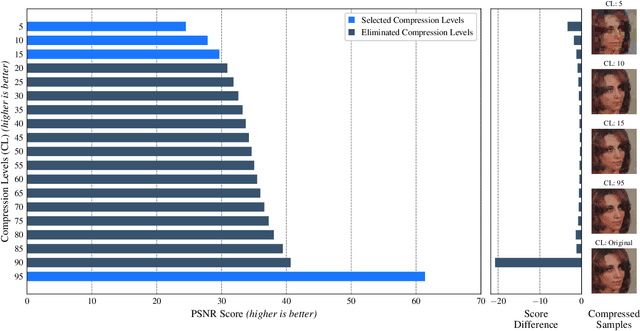
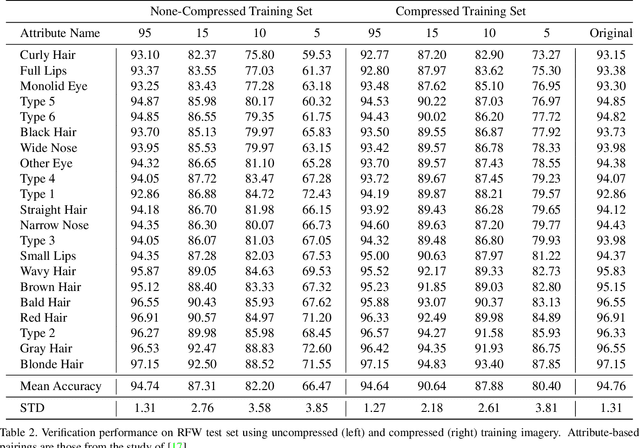
Yes - This study investigates the impact of commonplace lossy image compression on face recognition algorithms with regard to the racial characteristics of the subject. We adopt a recently proposed racial phenotype-based bias analysis methodology to measure the effect of varying levels of lossy compression across racial phenotype categories. Additionally, we determine the relationship between chroma-subsampling and race-related phenotypes for recognition performance. Prior work investigates the impact of lossy JPEG compression algorithm on contemporary face recognition performance. However, there is a gap in how this impact varies with different race-related inter-sectional groups and the cause of this impact. Via an extensive experimental setup, we demonstrate that common lossy image compression approaches have a more pronounced negative impact on facial recognition performance for specific racial phenotype categories such as darker skin tones (by up to 34.55\%). Furthermore, removing chroma-subsampling during compression improves the false matching rate (up to 15.95\%) across all phenotype categories affected by the compression, including darker skin tones, wide noses, big lips, and monolid eye categories. In addition, we outline the characteristics that may be attributable as the underlying cause of such phenomenon for lossy compression algorithms such as JPEG.
Understanding Cross Domain Presentation Attack Detection for Visible Face Recognition
Nov 03, 2021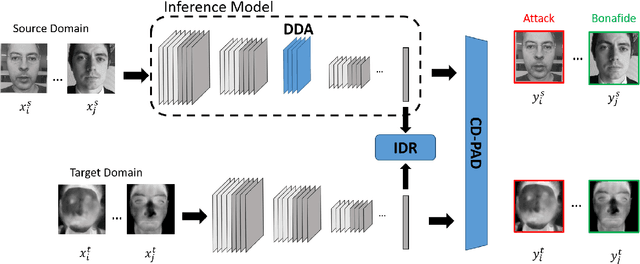
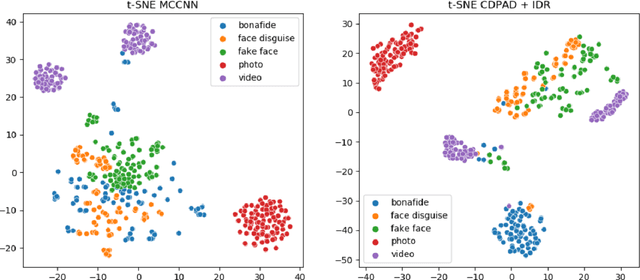
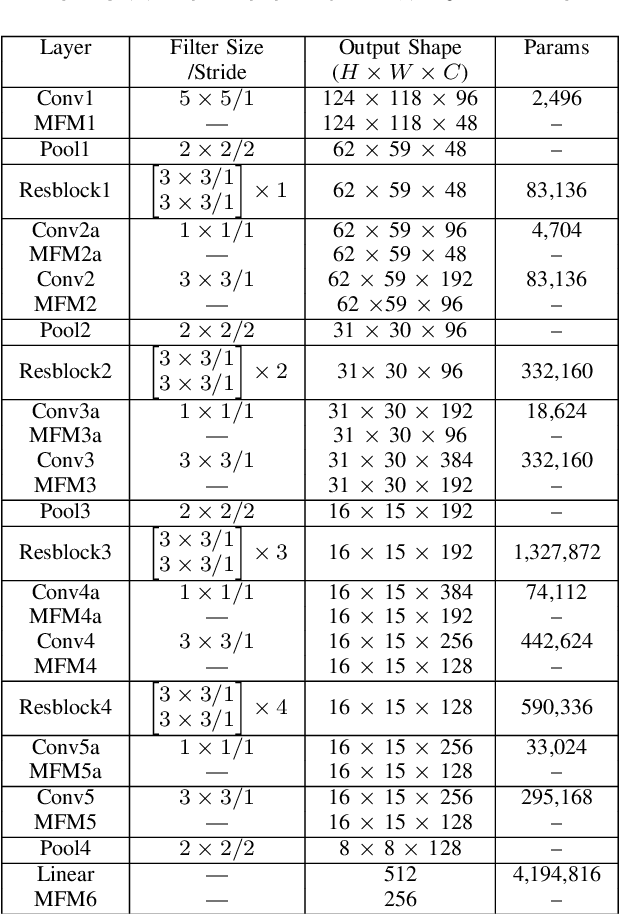

Face signatures, including size, shape, texture, skin tone, eye color, appearance, and scars/marks, are widely used as discriminative, biometric information for access control. Despite recent advancements in facial recognition systems, presentation attacks on facial recognition systems have become increasingly sophisticated. The ability to detect presentation attacks or spoofing attempts is a pressing concern for the integrity, security, and trust of facial recognition systems. Multi-spectral imaging has been previously introduced as a way to improve presentation attack detection by utilizing sensors that are sensitive to different regions of the electromagnetic spectrum (e.g., visible, near infrared, long-wave infrared). Although multi-spectral presentation attack detection systems may be discriminative, the need for additional sensors and computational resources substantially increases complexity and costs. Instead, we propose a method that exploits information from infrared imagery during training to increase the discriminability of visible-based presentation attack detection systems. We introduce (1) a new cross-domain presentation attack detection framework that increases the separability of bonafide and presentation attacks using only visible spectrum imagery, (2) an inverse domain regularization technique for added training stability when optimizing our cross-domain presentation attack detection framework, and (3) a dense domain adaptation subnetwork to transform representations between visible and non-visible domains.
Local Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022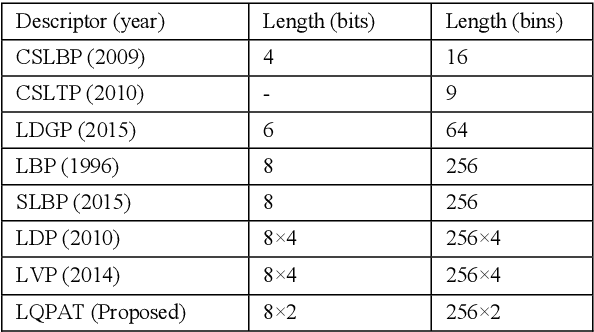
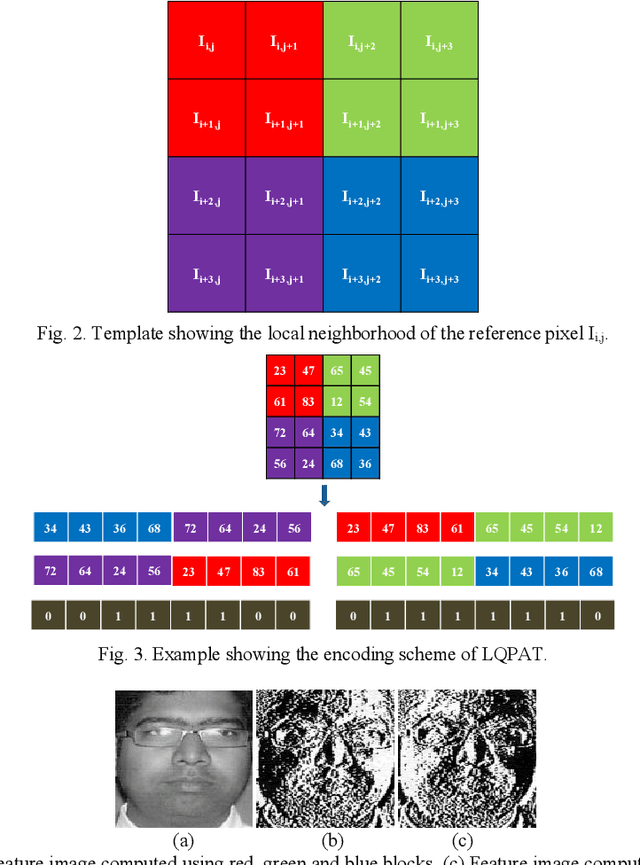
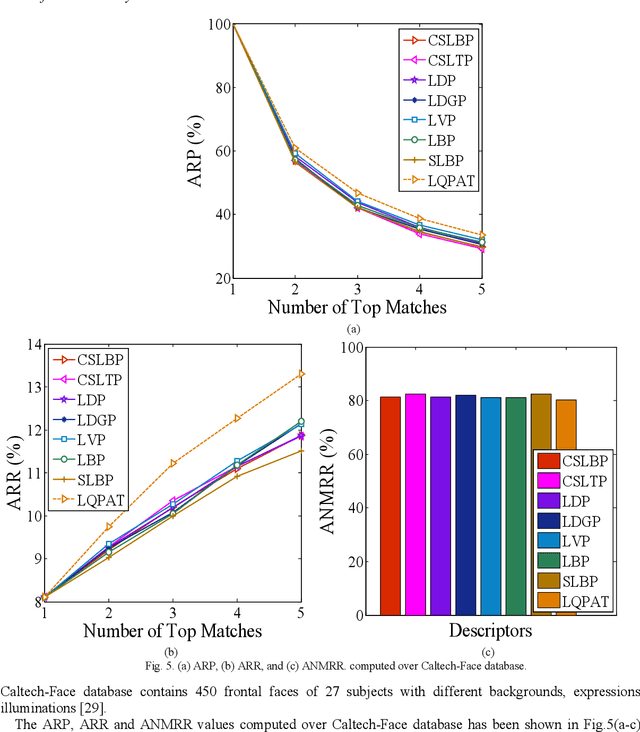
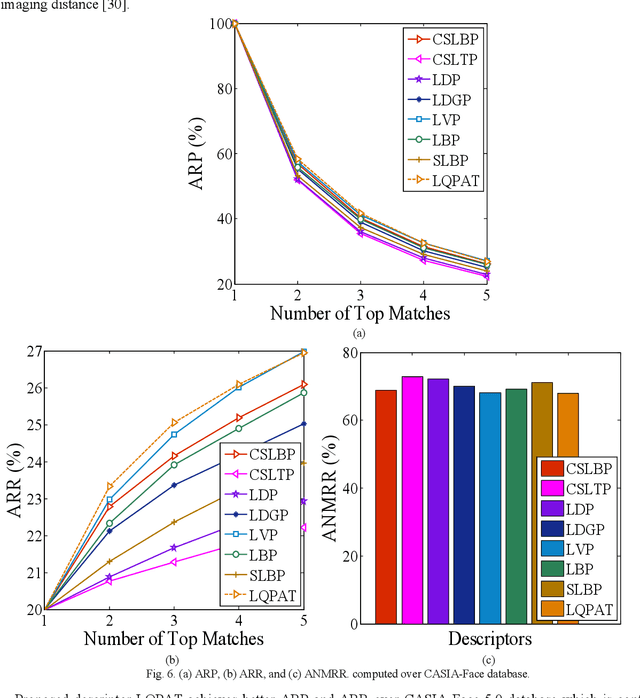
In this paper a novel hand crafted local quadruple pattern (LQPAT) is proposed for facial image recognition and retrieval. Most of the existing hand-crafted descriptors encodes only a limited number of pixels in the local neighbourhood. Under unconstrained environment the performance of these descriptors tends to degrade drastically. The major problem in increasing the local neighbourhood is that, it also increases the feature length of the descriptor. The proposed descriptor try to overcome these problems by defining an efficient encoding structure with optimal feature length. The proposed descriptor encodes relations amongst the neighbours in quadruple space. Two micro patterns are computed from the local relationships to form the descriptor. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand crafted descriptors on bench mark databases namely; Caltech-face, LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under uncontrolled variations in pose, illumination, background and expressions.
* arXiv admin note: substantial text overlap with arXiv:2201.00504, arXiv:2201.00511
Are Commercial Face Detection Models as Biased as Academic Models?
Jan 25, 2022
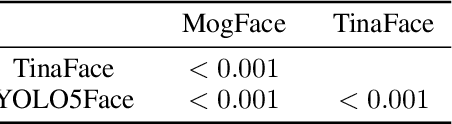
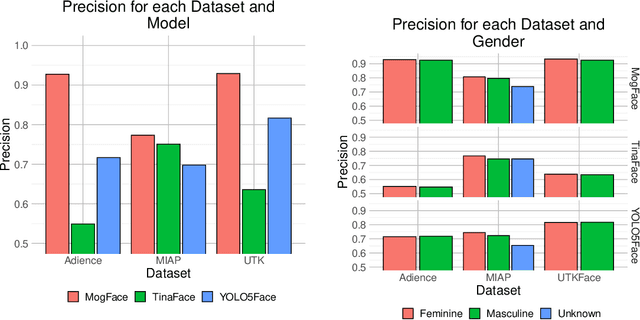
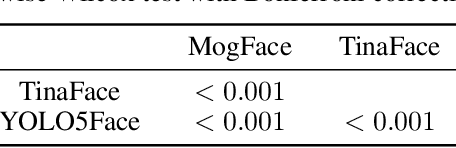
As facial recognition systems are deployed more widely, scholars and activists have studied their biases and harms. Audits are commonly used to accomplish this and compare the algorithmic facial recognition systems' performance against datasets with various metadata labels about the subjects of the images. Seminal works have found discrepancies in performance by gender expression, age, perceived race, skin type, etc. These studies and audits often examine algorithms which fall into two categories: academic models or commercial models. We present a detailed comparison between academic and commercial face detection systems, specifically examining robustness to noise. We find that state-of-the-art academic face detection models exhibit demographic disparities in their noise robustness, specifically by having statistically significant decreased performance on older individuals and those who present their gender in a masculine manner. When we compare the size of these disparities to that of commercial models, we conclude that commercial models - in contrast to their relatively larger development budget and industry-level fairness commitments - are always as biased or more biased than an academic model.
Facial Expression Recognition on a Quantum Computer
Feb 09, 2021
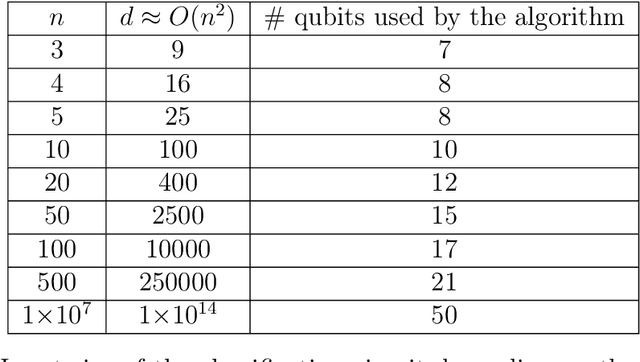

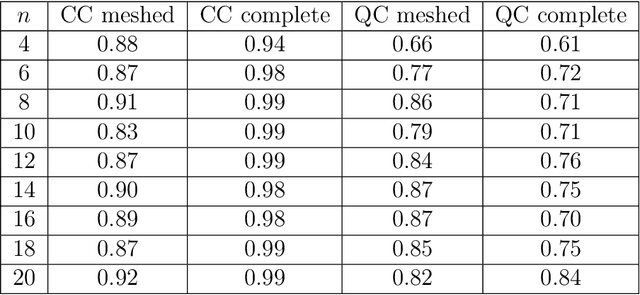
We address the problem of facial expression recognition and show a possible solution using a quantum machine learning approach. In order to define an efficient classifier for a given dataset, our approach substantially exploits quantum interference. By representing face expressions via graphs, we define a classifier as a quantum circuit that manipulates the graphs adjacency matrices encoded into the amplitudes of some appropriately defined quantum states. We discuss the accuracy of the quantum classifier evaluated on the quantum simulator available on the IBM Quantum Experience cloud platform, and compare it with the accuracy of one of the best classical classifier.
Pose Impact Estimation on Face Recognition using 3D-Aware Synthetic Data with Application to Quality Assessment
Mar 01, 2023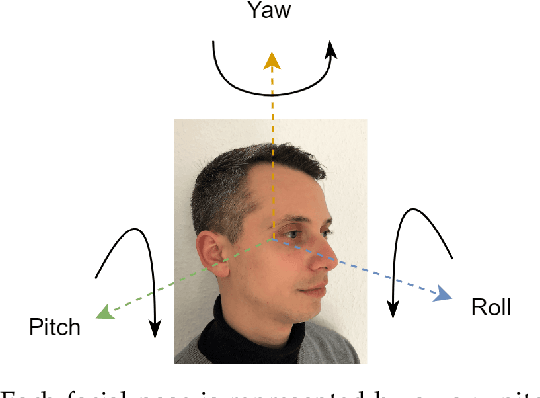



Evaluating the quality of facial images is essential for operating face recognition systems with sufficient accuracy. The recent advances in face quality standardisation (ISO/IEC WD 29794-5) recommend the usage of component quality measures for breaking down face quality into its individual factors, hence providing valuable feedback for operators to re-capture low-quality images. In light of recent advances in 3D-aware generative adversarial networks, we propose a novel dataset, "Syn-YawPitch", comprising 1,000 identities with varying yaw-pitch angle combinations. Utilizing this dataset, we demonstrate that pitch angles beyond 30 degrees have a significant impact on the biometric performance of current face recognition systems. Furthermore, we propose a lightweight and efficient pose quality predictor that adheres to the standards of ISO/IEC WD 29794-5 and is freely available for use at https://github.com/datasciencegrimmer/Syn-YawPitch/.
Generating Dataset For Large-scale 3D Facial Emotion Recognition
Sep 16, 2021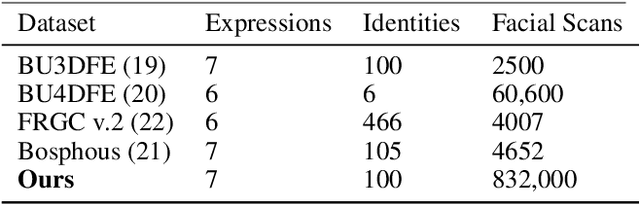
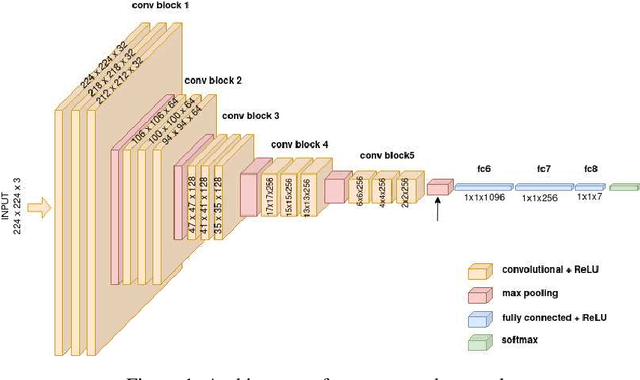
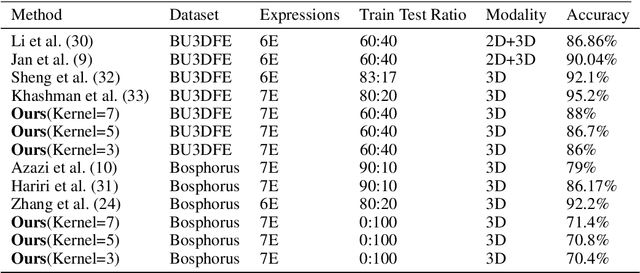
The tremendous development in deep learning has led facial expression recognition (FER) to receive much attention in the past few years. Although 3D FER has an inherent edge over its 2D counterpart, work on 2D images has dominated the field. The main reason for the slow development of 3D FER is the unavailability of large training and large test datasets. Recognition accuracies have already saturated on existing 3D emotion recognition datasets due to their small gallery sizes. Unlike 2D photographs, 3D facial scans are not easy to collect, causing a bottleneck in the development of deep 3D FER networks and datasets. In this work, we propose a method for generating a large dataset of 3D faces with labeled emotions. We also develop a deep convolutional neural network(CNN) for 3D FER trained on 624,000 3D facial scans. The test data comprises 208,000 3D facial scans.