 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
MAFW: A Large-scale, Multi-modal, Compound Affective Database for Dynamic Facial Expression Recognition in the Wild
Aug 01, 2022

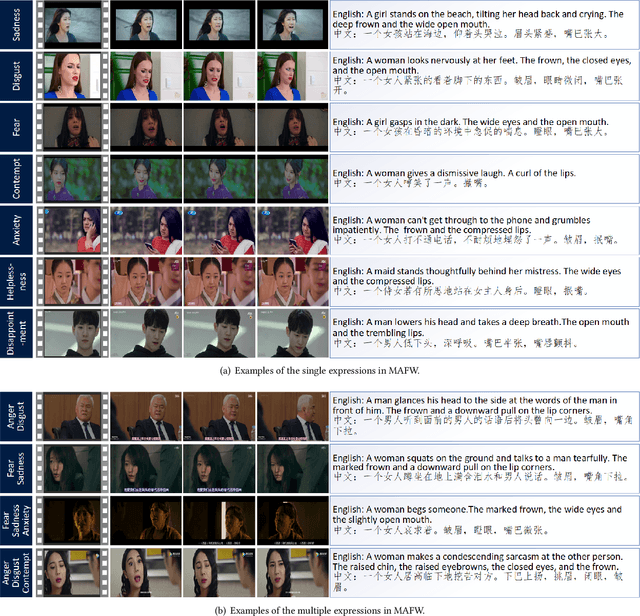
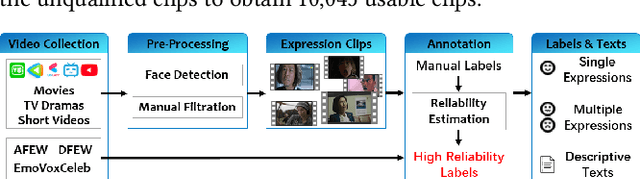
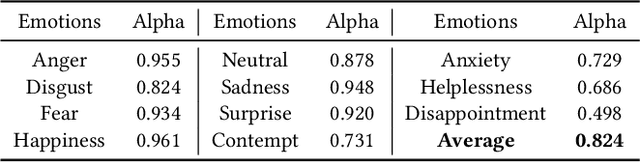
Dynamic facial expression recognition (FER) databases provide important data support for affective computing and applications. However, most FER databases are annotated with several basic mutually exclusive emotional categories and contain only one modality, e.g., videos. The monotonous labels and modality cannot accurately imitate human emotions and fulfill applications in the real world. In this paper, we propose MAFW, a large-scale multi-modal compound affective database with 10,045 video-audio clips in the wild. Each clip is annotated with a compound emotional category and a couple of sentences that describe the subjects' affective behaviors in the clip. For the compound emotion annotation, each clip is categorized into one or more of the 11 widely-used emotions, i.e., anger, disgust, fear, happiness, neutral, sadness, surprise, contempt, anxiety, helplessness, and disappointment. To ensure high quality of the labels, we filter out the unreliable annotations by an Expectation Maximization (EM) algorithm, and then obtain 11 single-label emotion categories and 32 multi-label emotion categories. To the best of our knowledge, MAFW is the first in-the-wild multi-modal database annotated with compound emotion annotations and emotion-related captions. Additionally, we also propose a novel Transformer-based expression snippet feature learning method to recognize the compound emotions leveraging the expression-change relations among different emotions and modalities. Extensive experiments on MAFW database show the advantages of the proposed method over other state-of-the-art methods for both uni- and multi-modal FER. Our MAFW database is publicly available from https://mafw-database.github.io/MAFW.
Generation of artificial facial drug abuse images using Deep De-identified anonymous Dataset augmentation through Genetics Algorithm (3DG-GA)
Apr 12, 2023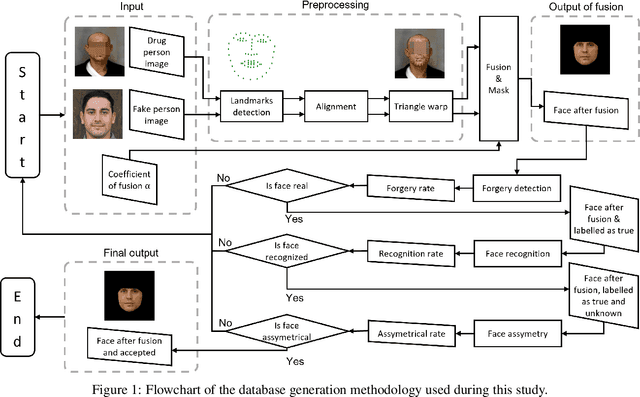


In biomedical research and artificial intelligence, access to large, well-balanced, and representative datasets is crucial for developing trustworthy applications that can be used in real-world scenarios. However, obtaining such datasets can be challenging, as they are often restricted to hospitals and specialized facilities. To address this issue, the study proposes to generate highly realistic synthetic faces exhibiting drug abuse traits through augmentation. The proposed method, called "3DG-GA", Deep De-identified anonymous Dataset Generation, uses Genetics Algorithm as a strategy for synthetic faces generation. The algorithm includes GAN artificial face generation, forgery detection, and face recognition. Initially, a dataset of 120 images of actual facial drug abuse is used. By preserving, the drug traits, the 3DG-GA provides a dataset containing 3000 synthetic facial drug abuse images. The dataset will be open to the scientific community, which can reproduce our results and benefit from the generated datasets while avoiding legal or ethical restrictions.
Progressive Spatio-Temporal Bilinear Network with Monte Carlo Dropout for Landmark-based Facial Expression Recognition with Uncertainty Estimation
Jun 08, 2021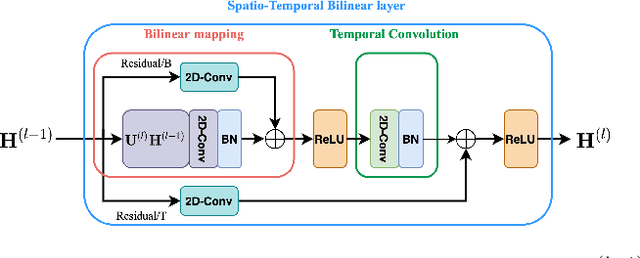
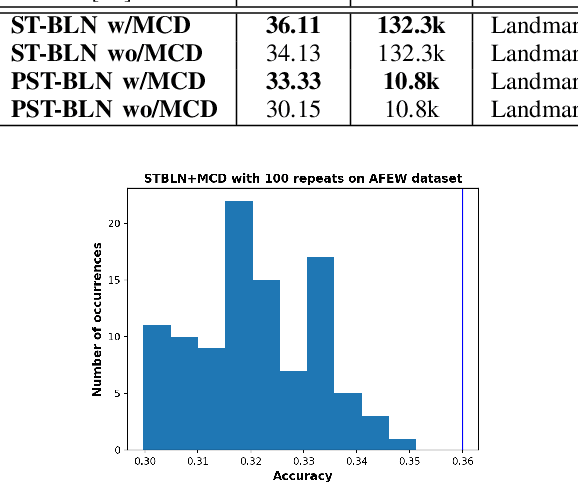
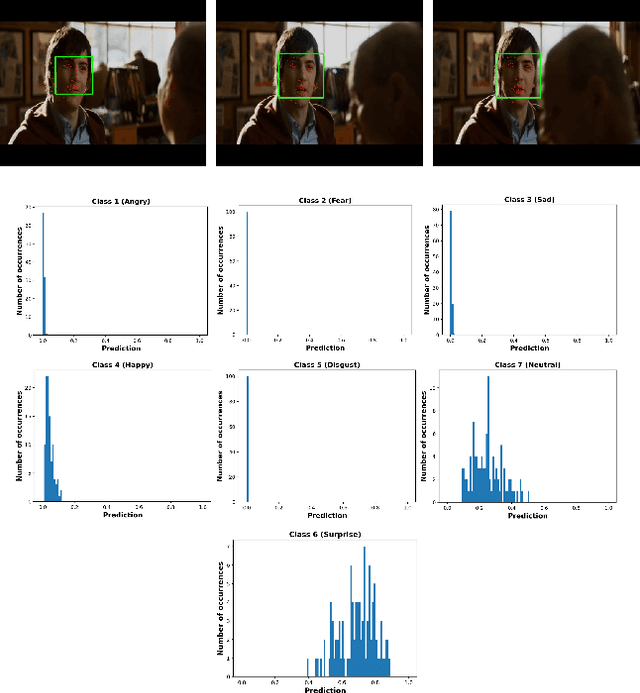
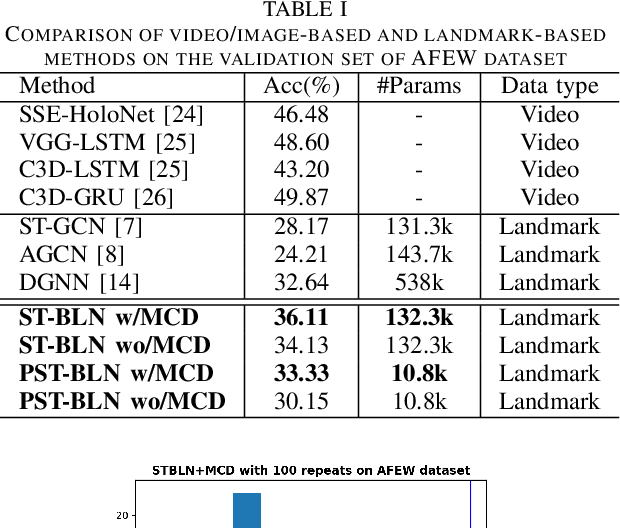
Deep neural networks have been widely used for feature learning in facial expression recognition systems. However, small datasets and large intra-class variability can lead to overfitting. In this paper, we propose a method which learns an optimized compact network topology for real-time facial expression recognition utilizing localized facial landmark features. Our method employs a spatio-temporal bilinear layer as backbone to capture the motion of facial landmarks during the execution of a facial expression effectively. Besides, it takes advantage of Monte Carlo Dropout to capture the model's uncertainty which is of great importance to analyze and treat uncertain cases. The performance of our method is evaluated on three widely used datasets and it is comparable to that of video-based state-of-the-art methods while it has much less complexity.
Application of Facial Recognition using Convolutional Neural Networks for Entry Access Control
Nov 23, 2020
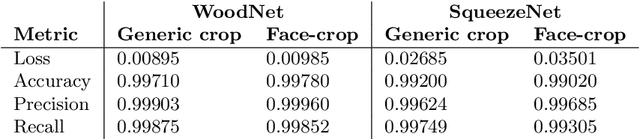
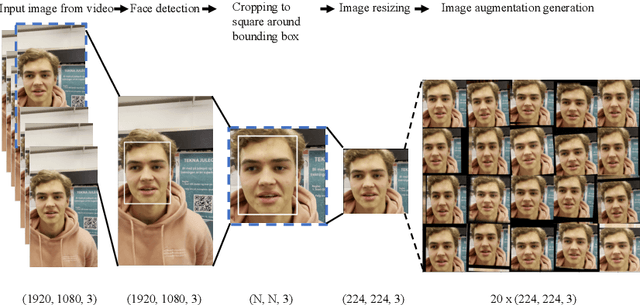
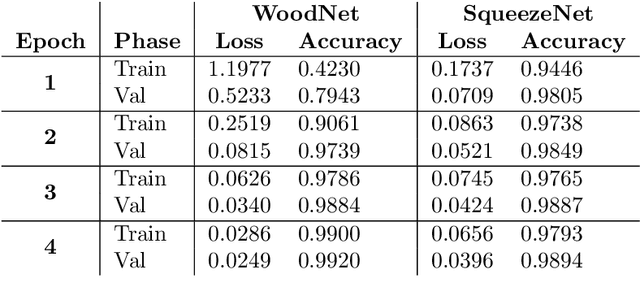
The purpose of this paper is to design a solution to the problem of facial recognition by use of convolutional neural networks, with the intention of applying the solution in a camera-based home-entry access control system. More specifically, the paper focuses on solving the supervised classification problem of taking images of people as input and classifying the person in the image as one of the authors or not. Two approaches are proposed: (1) building and training a neural network called WoodNet from scratch and (2) leveraging transfer learning by utilizing a network pre-trained on the ImageNet database and adapting it to this project's data and classes. In order to train the models to recognize the authors, a dataset containing more than 150 000 images has been created, balanced over the authors and others. Image extraction from videos and image augmentation techniques were instrumental for dataset creation. The results are two models classifying the individuals in the dataset with high accuracy, achieving over 99% accuracy on held-out test data. The pre-trained model fitted significantly faster than WoodNet, and seems to generalize better. However, these results come with a few caveats. Because of the way the dataset was compiled, as well as the high accuracy, one has reason to believe the models over-fitted to the data to some degree. An added consequence of the data compilation method is that the test dataset may not be sufficiently different from the training data, limiting its ability to validate generalization of the models. However, utilizing the models in a web-cam based system, classifying faces in real-time, shows promising results and indicates that the models generalized fairly well for at least some of the classes (see the accompanying video).
Logical Consistency and Greater Descriptive Power for Facial Hair Attribute Learning
Feb 22, 2023
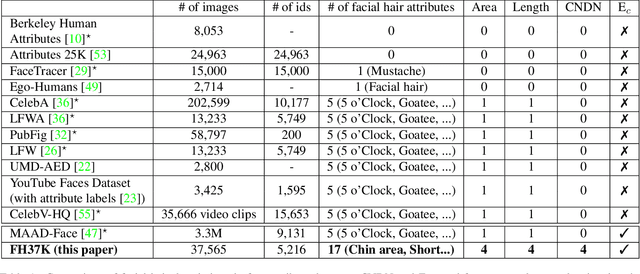

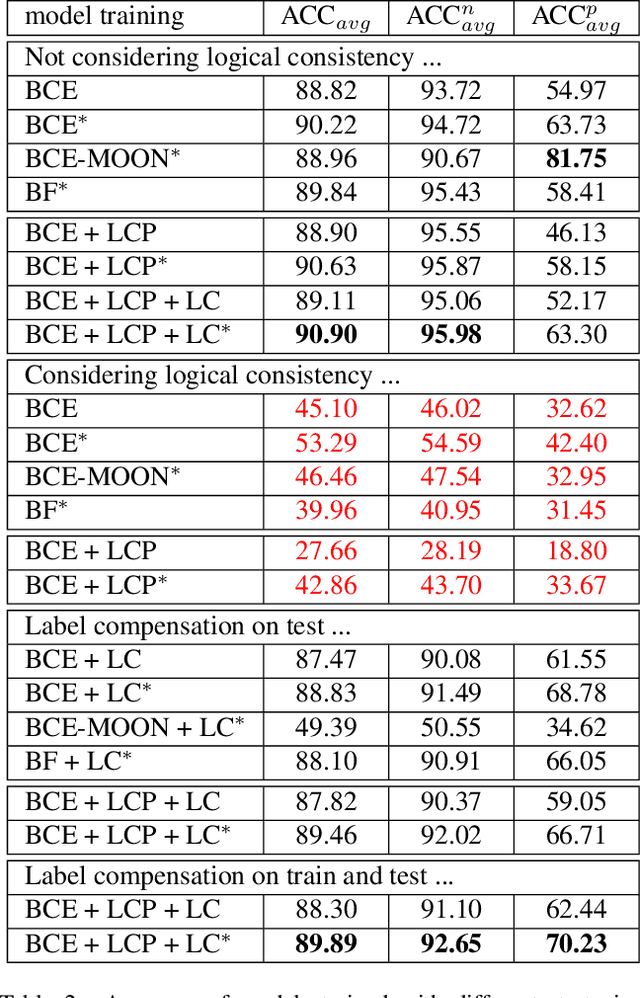
Face attribute research has so far used only simple binary attributes for facial hair; e.g., beard / no beard. We have created a new, more descriptive facial hair annotation scheme and applied it to create a new facial hair attribute dataset, FH37K. Face attribute research also so far has not dealt with logical consistency and completeness. For example, in prior research, an image might be classified as both having no beard and also having a goatee (a type of beard). We show that the test accuracy of previous classification methods on facial hair attribute classification drops significantly if logical consistency of classifications is enforced. We propose a logically consistent prediction loss, LCPLoss, to aid learning of logical consistency across attributes, and also a label compensation training strategy to eliminate the problem of no positive prediction across a set of related attributes. Using an attribute classifier trained on FH37K, we investigate how facial hair affects face recognition accuracy, including variation across demographics. Results show that similarity and difference in facial hairstyle have important effects on the impostor and genuine score distributions in face recognition.
Assessing Demographic Bias Transfer from Dataset to Model: A Case Study in Facial Expression Recognition
May 20, 2022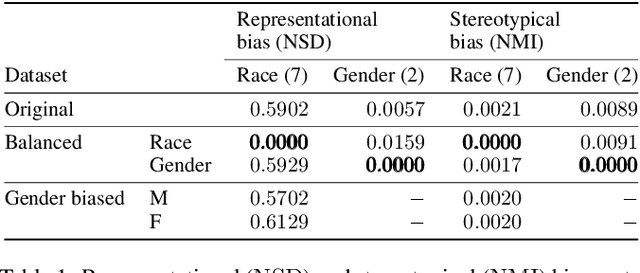
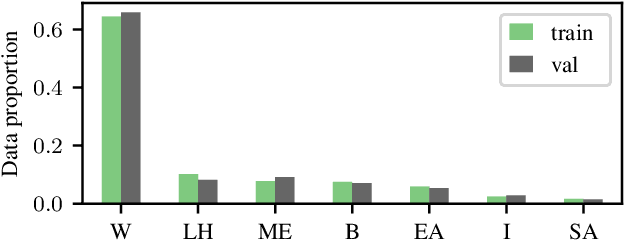
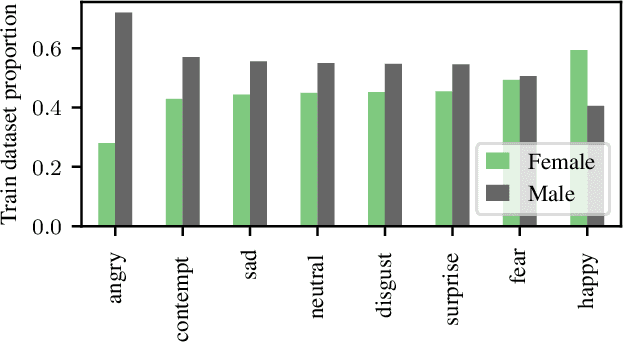
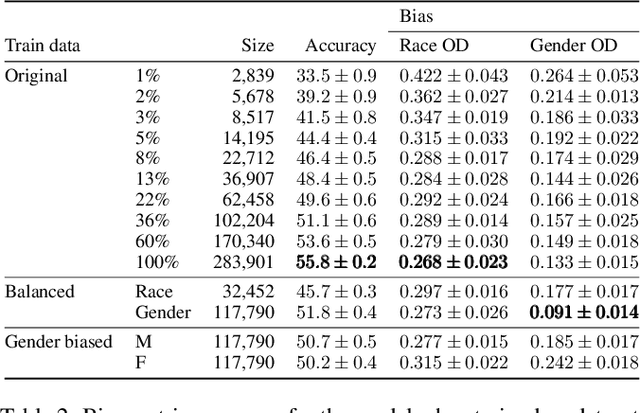
The increasing amount of applications of Artificial Intelligence (AI) has led researchers to study the social impact of these technologies and evaluate their fairness. Unfortunately, current fairness metrics are hard to apply in multi-class multi-demographic classification problems, such as Facial Expression Recognition (FER). We propose a new set of metrics to approach these problems. Of the three metrics proposed, two focus on the representational and stereotypical bias of the dataset, and the third one on the residual bias of the trained model. These metrics combined can potentially be used to study and compare diverse bias mitigation methods. We demonstrate the usefulness of the metrics by applying them to a FER problem based on the popular Affectnet dataset. Like many other datasets for FER, Affectnet is a large Internet-sourced dataset with 291,651 labeled images. Obtaining images from the Internet raises some concerns over the fairness of any system trained on this data and its ability to generalize properly to diverse populations. We first analyze the dataset and some variants, finding substantial racial bias and gender stereotypes. We then extract several subsets with different demographic properties and train a model on each one, observing the amount of residual bias in the different setups. We also provide a second analysis on a different dataset, FER+.
Multi-task Cross Attention Network in Facial Behavior Analysis
Jul 21, 2022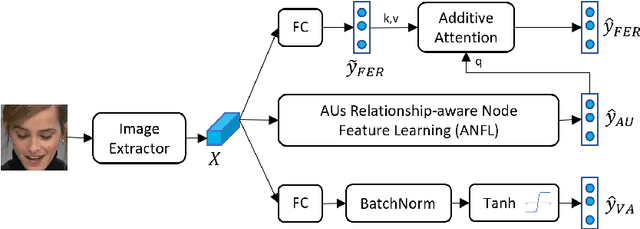

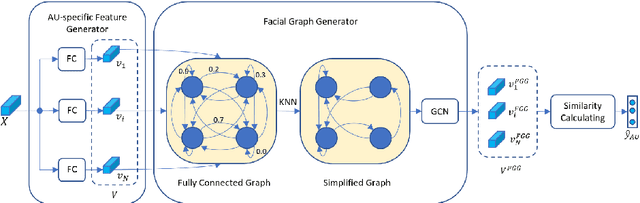
Facial behavior analysis is a broad topic with various categories such as facial emotion recognition, age and gender recognition, ... Many studies focus on individual tasks while the multi-task learning approach is still open and requires more research. In this paper, we present our solution and experiment result for the Multi-Task Learning challenge of the Affective Behavior Analysis in-the-wild competition. The challenge is a combination of three tasks: action unit detection, facial expression recognition and valance-arousal estimation. To address this challenge, we introduce a cross-attentive module to improve multi-task learning performance. Additionally, a facial graph is applied to capture the association among action units. As a result, we achieve the evaluation measure of 1.24 on the validation data provided by the organizers, which is better than the baseline result of 0.30.
Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence Margin
Mar 24, 2022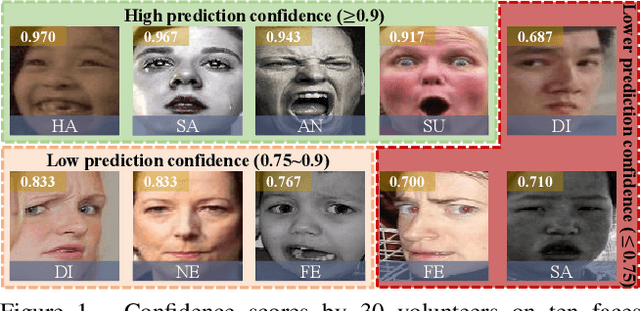
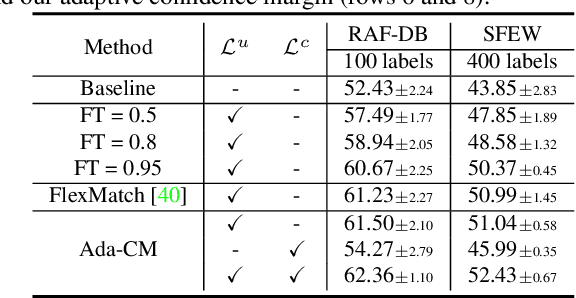
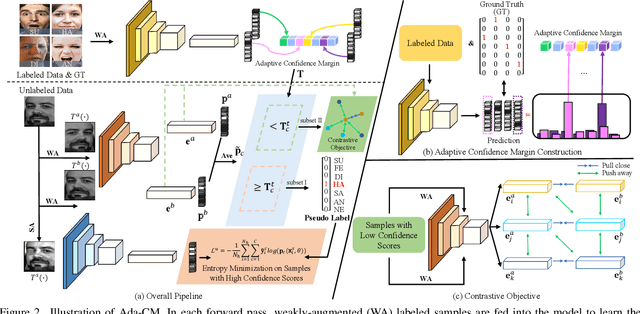
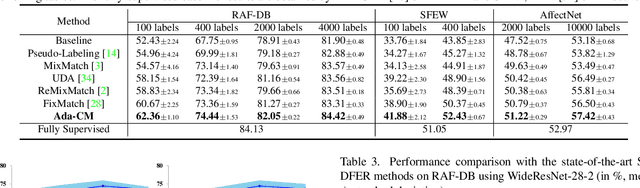
Only parts of unlabeled data are selected to train models for most semi-supervised learning methods, whose confidence scores are usually higher than the pre-defined threshold (i.e., the confidence margin). We argue that the recognition performance should be further improved by making full use of all unlabeled data. In this paper, we learn an Adaptive Confidence Margin (Ada-CM) to fully leverage all unlabeled data for semi-supervised deep facial expression recognition. All unlabeled samples are partitioned into two subsets by comparing their confidence scores with the adaptively learned confidence margin at each training epoch: (1) subset I including samples whose confidence scores are no lower than the margin; (2) subset II including samples whose confidence scores are lower than the margin. For samples in subset I, we constrain their predictions to match pseudo labels. Meanwhile, samples in subset II participate in the feature-level contrastive objective to learn effective facial expression features. We extensively evaluate Ada-CM on four challenging datasets, showing that our method achieves state-of-the-art performance, especially surpassing fully-supervised baselines in a semi-supervised manner. Ablation study further proves the effectiveness of our method. The source code is available at https://github.com/hangyu94/Ada-CM.
STPrivacy: Spatio-Temporal Tubelet Sparsification and Anonymization for Privacy-preserving Action Recognition
Jan 08, 2023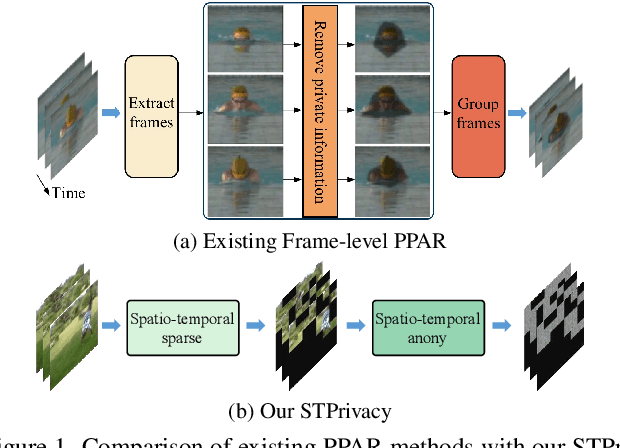
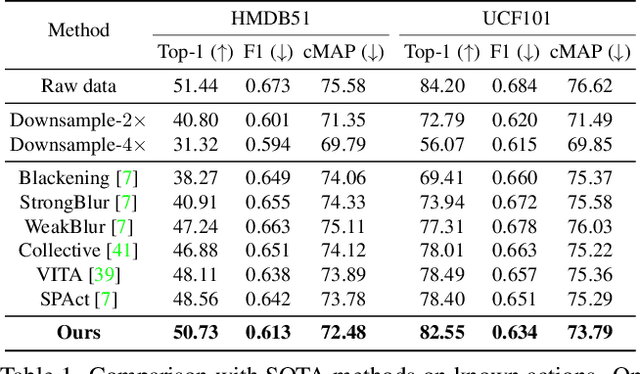
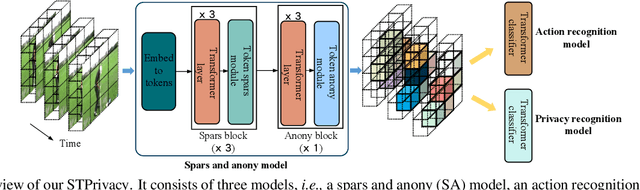
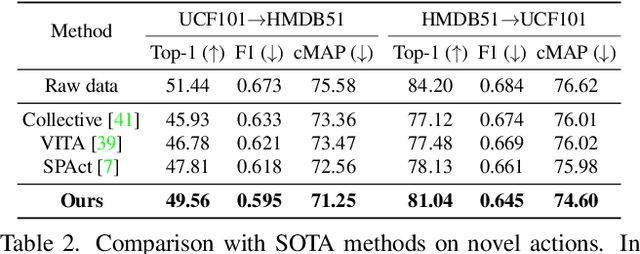
Recently privacy-preserving action recognition (PPAR) has been becoming an appealing video understanding problem. Nevertheless, existing works focus on the frame-level (spatial) privacy preservation, ignoring the privacy leakage from a whole video and destroying the temporal continuity of actions. In this paper, we present a novel PPAR paradigm, i.e., performing privacy preservation from both spatial and temporal perspectives, and propose a STPrivacy framework. For the first time, our STPrivacy applies vision Transformers to PPAR and regards a video as a sequence of spatio-temporal tubelets, showing outstanding advantages over previous convolutional methods. Specifically, our STPrivacy adaptively treats privacy-containing tubelets in two different manners. The tubelets irrelevant to actions are directly abandoned, i.e., sparsification, and not published for subsequent tasks. In contrast, those highly involved in actions are anonymized, i.e., anonymization, to remove private information. These two transformation mechanisms are complementary and simultaneously optimized in our unified framework. Because there is no large-scale benchmarks, we annotate five privacy attributes for two of the most popular action recognition datasets, i.e., HMDB51 and UCF101, and conduct extensive experiments on them. Moreover, to verify the generalization ability of our STPrivacy, we further introduce a privacy-preserving facial expression recognition task and conduct experiments on a large-scale video facial attributes dataset, i.e., Celeb-VHQ. The thorough comparisons and visualization analysis demonstrate our significant superiority over existing works. The appendix contains more details and visualizations.
FERV39k: A Large-Scale Multi-Scene Dataset for Facial Expression Recognition in Videos
Mar 20, 2022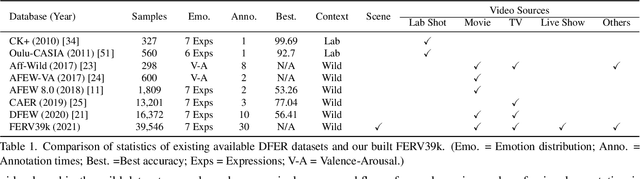
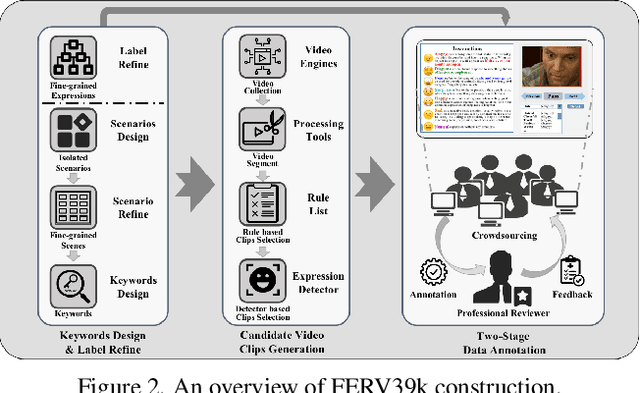
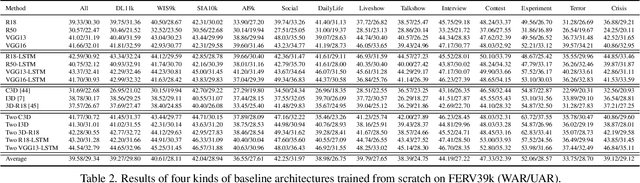
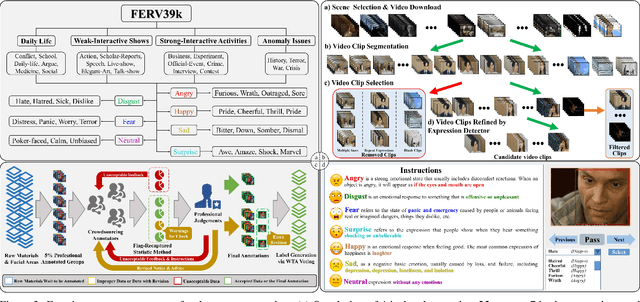
Current benchmarks for facial expression recognition (FER) mainly focus on static images, while there are limited datasets for FER in videos. It is still ambiguous to evaluate whether performances of existing methods remain satisfactory in real-world application-oriented scenes. For example, the "Happy" expression with high intensity in Talk-Show is more discriminating than the same expression with low intensity in Official-Event. To fill this gap, we build a large-scale multi-scene dataset, coined as FERV39k. We analyze the important ingredients of constructing such a novel dataset in three aspects: (1) multi-scene hierarchy and expression class, (2) generation of candidate video clips, (3) trusted manual labelling process. Based on these guidelines, we select 4 scenarios subdivided into 22 scenes, annotate 86k samples automatically obtained from 4k videos based on the well-designed workflow, and finally build 38,935 video clips labeled with 7 classic expressions. Experiment benchmarks on four kinds of baseline frameworks were also provided and further analysis on their performance across different scenes and some challenges for future research were given. Besides, we systematically investigate key components of DFER by ablation studies. The baseline framework and our project will be available.