 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Real-Time Facial Expression Recognition using Facial Landmarks and Neural Networks
Jan 31, 2022



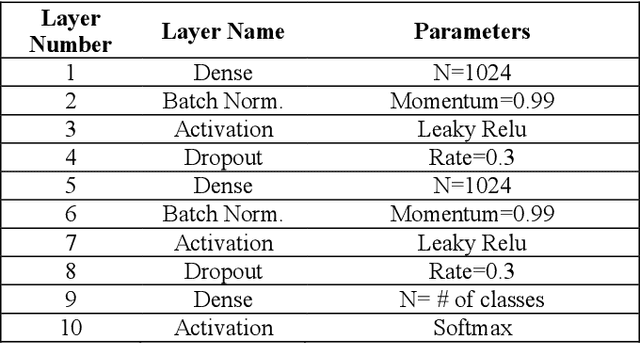
This paper presents a lightweight algorithm for feature extraction, classification of seven different emotions, and facial expression recognition in a real-time manner based on static images of the human face. In this regard, a Multi-Layer Perceptron (MLP) neural network is trained based on the foregoing algorithm. In order to classify human faces, first, some pre-processing is applied to the input image, which can localize and cut out faces from it. In the next step, a facial landmark detection library is used, which can detect the landmarks of each face. Then, the human face is split into upper and lower faces, which enables the extraction of the desired features from each part. In the proposed model, both geometric and texture-based feature types are taken into account. After the feature extraction phase, a normalized vector of features is created. A 3-layer MLP is trained using these feature vectors, leading to 96% accuracy on the test set.
Learn From All: Erasing Attention Consistency for Noisy Label Facial Expression Recognition
Jul 21, 2022
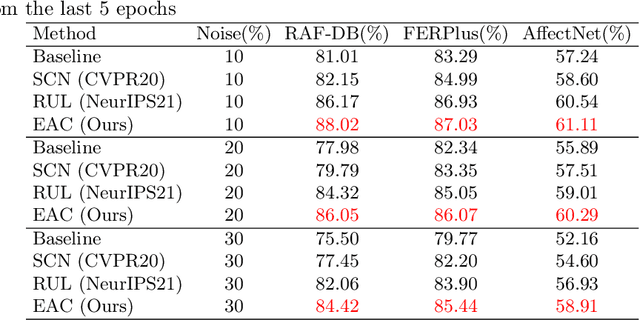
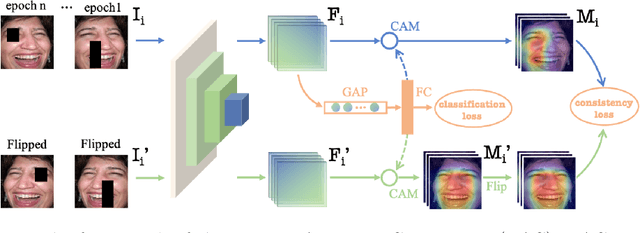

Noisy label Facial Expression Recognition (FER) is more challenging than traditional noisy label classification tasks due to the inter-class similarity and the annotation ambiguity. Recent works mainly tackle this problem by filtering out large-loss samples. In this paper, we explore dealing with noisy labels from a new feature-learning perspective. We find that FER models remember noisy samples by focusing on a part of the features that can be considered related to the noisy labels instead of learning from the whole features that lead to the latent truth. Inspired by that, we propose a novel Erasing Attention Consistency (EAC) method to suppress the noisy samples during the training process automatically. Specifically, we first utilize the flip semantic consistency of facial images to design an imbalanced framework. We then randomly erase input images and use flip attention consistency to prevent the model from focusing on a part of the features. EAC significantly outperforms state-of-the-art noisy label FER methods and generalizes well to other tasks with a large number of classes like CIFAR100 and Tiny-ImageNet. The code is available at https://github.com/zyh-uaiaaaa/Erasing-Attention-Consistency.
Facial Recognition with Encoded Local Projections
Sep 11, 2018
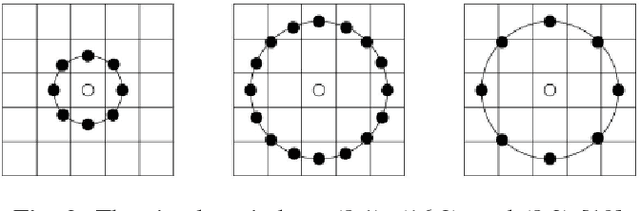

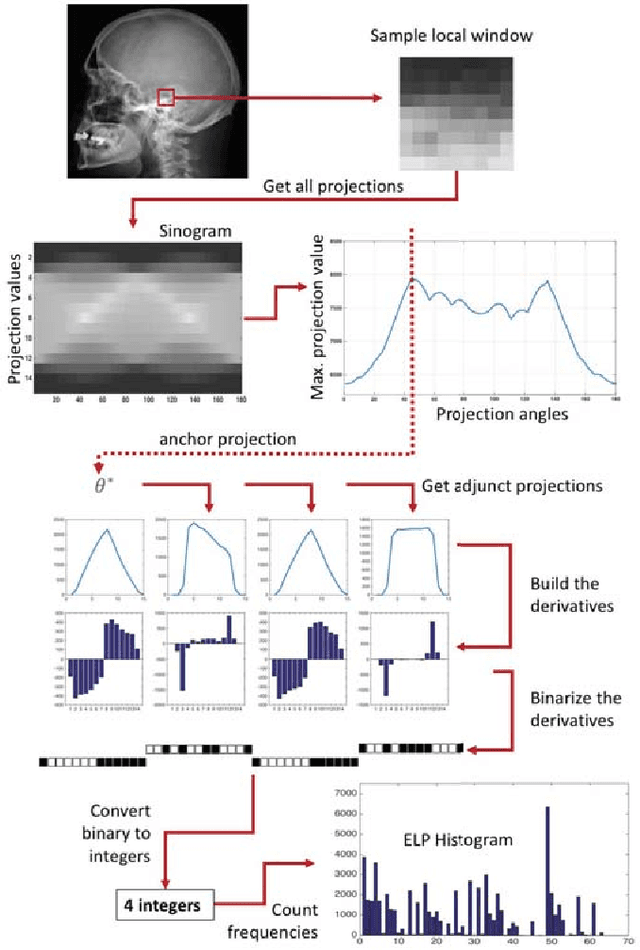
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.
Causal Intervention for Subject-Deconfounded Facial Action Unit Recognition
Apr 17, 2022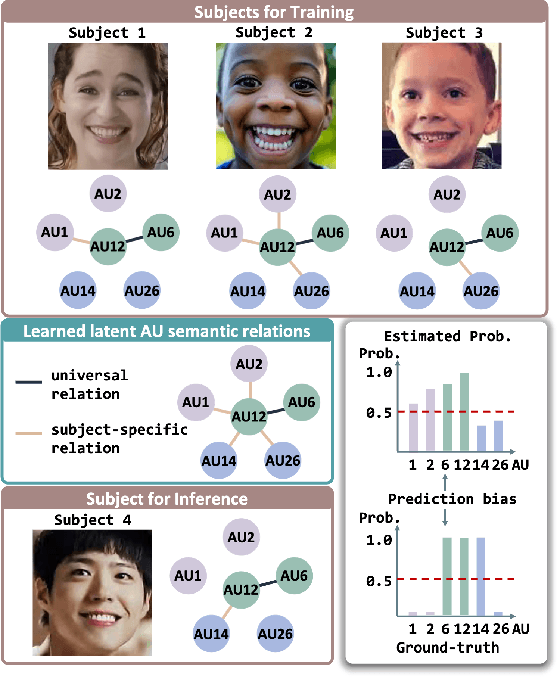
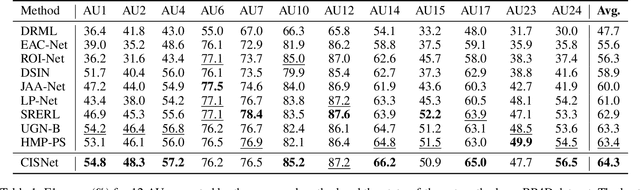
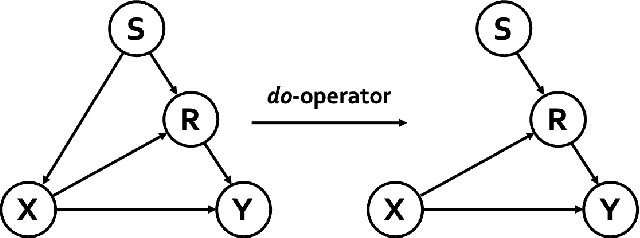
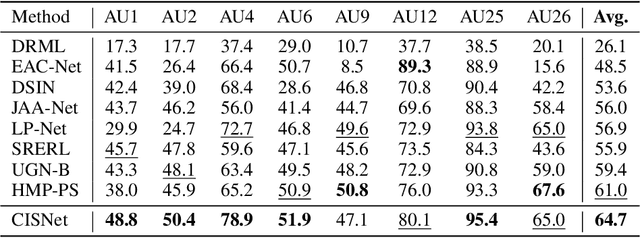
Subject-invariant facial action unit (AU) recognition remains challenging for the reason that the data distribution varies among subjects. In this paper, we propose a causal inference framework for subject-invariant facial action unit recognition. To illustrate the causal effect existing in AU recognition task, we formulate the causalities among facial images, subjects, latent AU semantic relations, and estimated AU occurrence probabilities via a structural causal model. By constructing such a causal diagram, we clarify the causal effect among variables and propose a plug-in causal intervention module, CIS, to deconfound the confounder \emph{Subject} in the causal diagram. Extensive experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of our CIS, and the model with CIS inserted, CISNet, has achieved state-of-the-art performance.
A priori compression of convolutional neural networks for wave simulators
Apr 12, 2023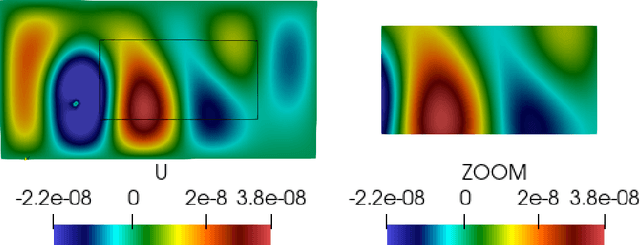
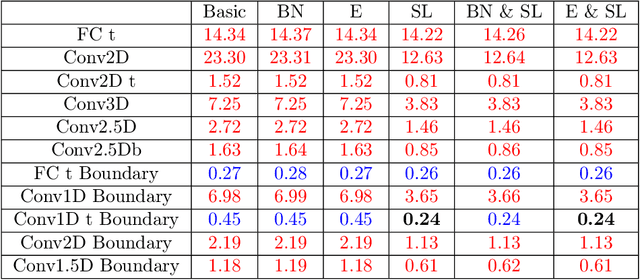
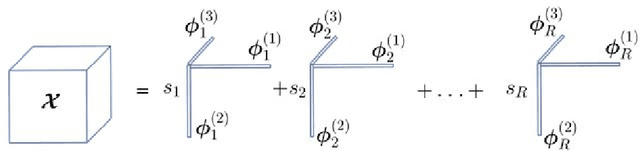
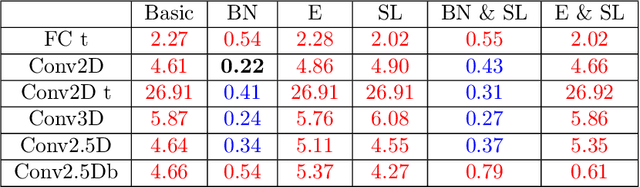
Convolutional neural networks are now seeing widespread use in a variety of fields, including image classification, facial and object recognition, medical imaging analysis, and many more. In addition, there are applications such as physics-informed simulators in which accurate forecasts in real time with a minimal lag are required. The present neural network designs include millions of parameters, which makes it difficult to install such complex models on devices that have limited memory. Compression techniques might be able to resolve these issues by decreasing the size of CNN models that are created by reducing the number of parameters that contribute to the complexity of the models. We propose a compressed tensor format of convolutional layer, a priori, before the training of the neural network. 3-way kernels or 2-way kernels in convolutional layers are replaced by one-way fiters. The overfitting phenomena will be reduced also. The time needed to make predictions or time required for training using the original Convolutional Neural Networks model would be cut significantly if there were fewer parameters to deal with. In this paper we present a method of a priori compressing convolutional neural networks for finite element (FE) predictions of physical data. Afterwards we validate our a priori compressed models on physical data from a FE model solving a 2D wave equation. We show that the proposed convolutinal compression technique achieves equivalent performance as classical convolutional layers with fewer trainable parameters and lower memory footprint.
Are Face Detection Models Biased?
Nov 07, 2022

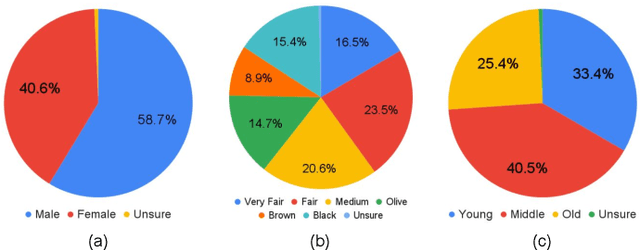

The presence of bias in deep models leads to unfair outcomes for certain demographic subgroups. Research in bias focuses primarily on facial recognition and attribute prediction with scarce emphasis on face detection. Existing studies consider face detection as binary classification into 'face' and 'non-face' classes. In this work, we investigate possible bias in the domain of face detection through facial region localization which is currently unexplored. Since facial region localization is an essential task for all face recognition pipelines, it is imperative to analyze the presence of such bias in popular deep models. Most existing face detection datasets lack suitable annotation for such analysis. Therefore, we web-curate the Fair Face Localization with Attributes (F2LA) dataset and manually annotate more than 10 attributes per face, including facial localization information. Utilizing the extensive annotations from F2LA, an experimental setup is designed to study the performance of four pre-trained face detectors. We observe (i) a high disparity in detection accuracies across gender and skin-tone, and (ii) interplay of confounding factors beyond demography. The F2LA data and associated annotations can be accessed at http://iab-rubric.org/index.php/F2LA.
Improving 2D face recognition via fine-level facial depth generation and RGB-D complementary feature learning
May 08, 2023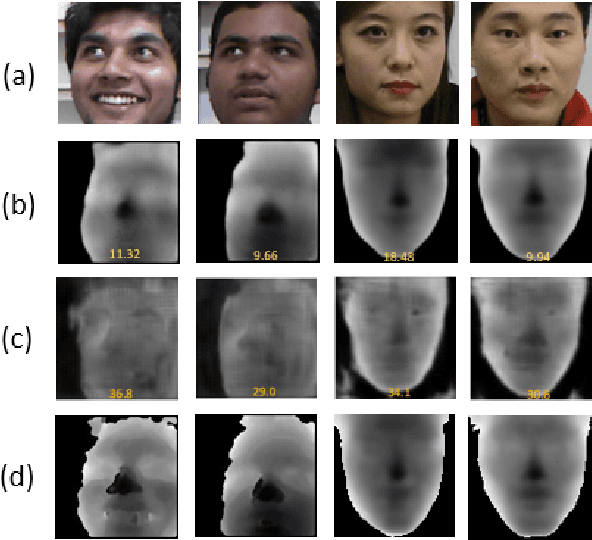

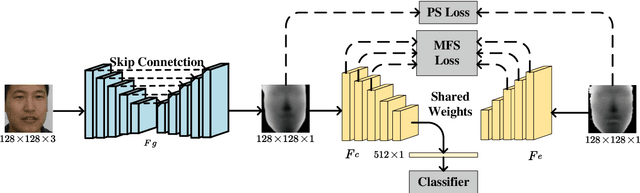

Face recognition in complex scenes suffers severe challenges coming from perturbations such as pose deformation, ill illumination, partial occlusion. Some methods utilize depth estimation to obtain depth corresponding to RGB to improve the accuracy of face recognition. However, the depth generated by them suffer from image blur, which introduces noise in subsequent RGB-D face recognition tasks. In addition, existing RGB-D face recognition methods are unable to fully extract complementary features. In this paper, we propose a fine-grained facial depth generation network and an improved multimodal complementary feature learning network. Extensive experiments on the Lock3DFace dataset and the IIIT-D dataset show that the proposed FFDGNet and I MCFLNet can improve the accuracy of RGB-D face recognition while achieving the state-of-the-art performance.
Understanding and Mitigating Annotation Bias in Facial Expression Recognition
Aug 19, 2021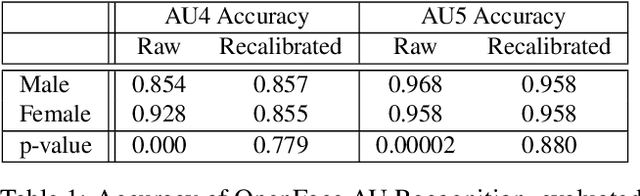
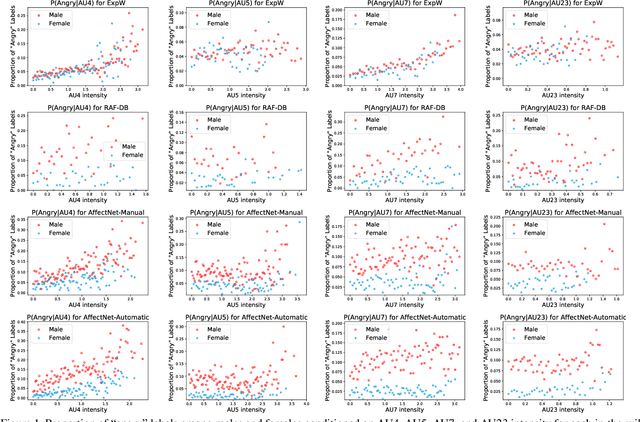
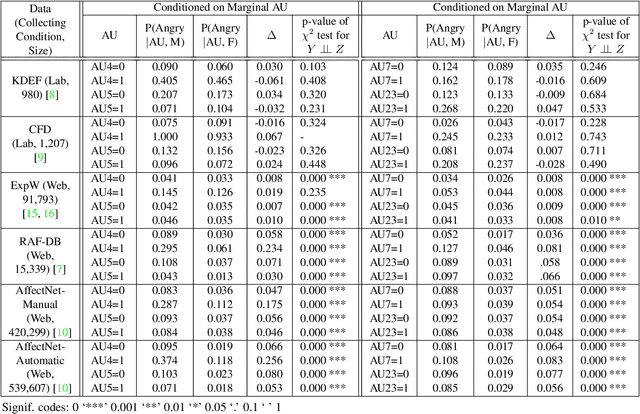
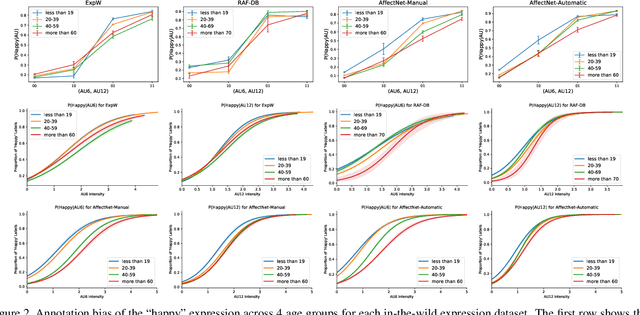
The performance of a computer vision model depends on the size and quality of its training data. Recent studies have unveiled previously-unknown composition biases in common image datasets which then lead to skewed model outputs, and have proposed methods to mitigate these biases. However, most existing works assume that human-generated annotations can be considered gold-standard and unbiased. In this paper, we reveal that this assumption can be problematic, and that special care should be taken to prevent models from learning such annotation biases. We focus on facial expression recognition and compare the label biases between lab-controlled and in-the-wild datasets. We demonstrate that many expression datasets contain significant annotation biases between genders, especially when it comes to the happy and angry expressions, and that traditional methods cannot fully mitigate such biases in trained models. To remove expression annotation bias, we propose an AU-Calibrated Facial Expression Recognition (AUC-FER) framework that utilizes facial action units (AUs) and incorporates the triplet loss into the objective function. Experimental results suggest that the proposed method is more effective in removing expression annotation bias than existing techniques.
Face Emotion Recognization Using Dataset Augmentation Based on Neural Network
Oct 23, 2022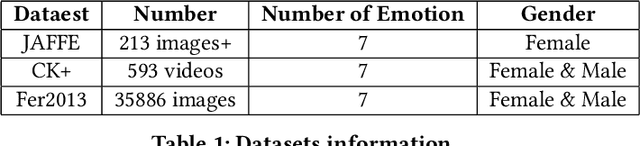
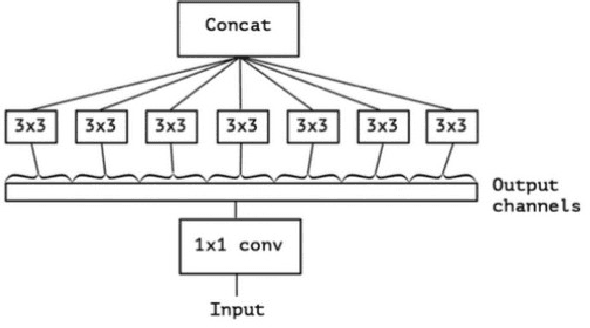
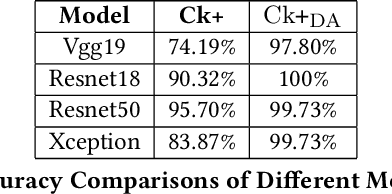

Facial expression is one of the most external indications of a person's feelings and emotions. In daily conversation, according to the psychologist, only 7\% and 38\% of information is communicated through words and sounds respective, while up to 55\% is through facial expression. It plays an important role in coordinating interpersonal relationships. Ekman and Friesen recognized six essential emotions in the nineteenth century depending on a cross-cultural study, which indicated that people feel each basic emotion in the same fashion despite culture. As a branch of the field of analyzing sentiment, facial expression recognition offers broad application prospects in a variety of domains, including the interaction between humans and computers, healthcare, and behavior monitoring. Therefore, many researchers have devoted themselves to facial expression recognition. In this paper, an effective hybrid data augmentation method is used. This approach is operated on two public datasets, and four benchmark models see some remarkable results.
Privileged Attribution Constrained Deep Networks for Facial Expression Recognition
Mar 24, 2022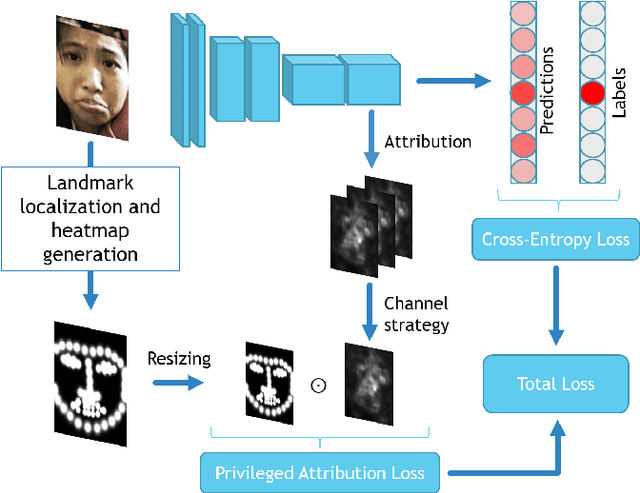

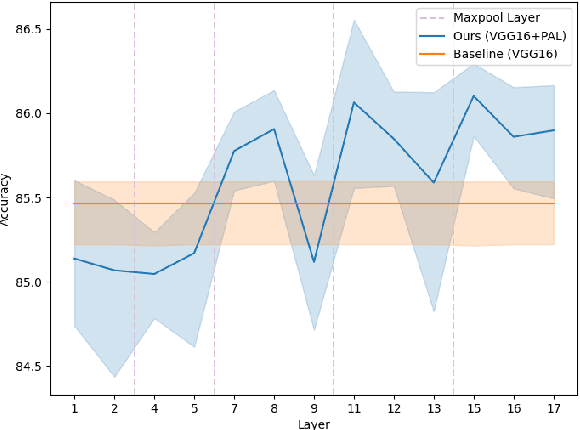
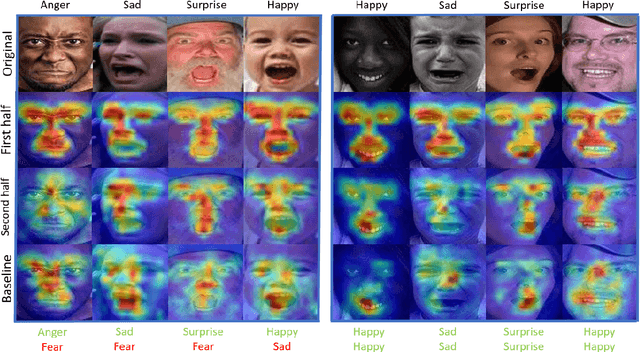
Facial Expression Recognition (FER) is crucial in many research domains because it enables machines to better understand human behaviours. FER methods face the problems of relatively small datasets and noisy data that don't allow classical networks to generalize well. To alleviate these issues, we guide the model to concentrate on specific facial areas like the eyes, the mouth or the eyebrows, which we argue are decisive to recognise facial expressions. We propose the Privileged Attribution Loss (PAL), a method that directs the attention of the model towards the most salient facial regions by encouraging its attribution maps to correspond to a heatmap formed by facial landmarks. Furthermore, we introduce several channel strategies that allow the model to have more degrees of freedom. The proposed method is independent of the backbone architecture and doesn't need additional semantic information at test time. Finally, experimental results show that the proposed PAL method outperforms current state-of-the-art methods on both RAF-DB and AffectNet.