 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Analysis of Semi-Supervised Methods for Facial Expression Recognition
Jul 31, 2022
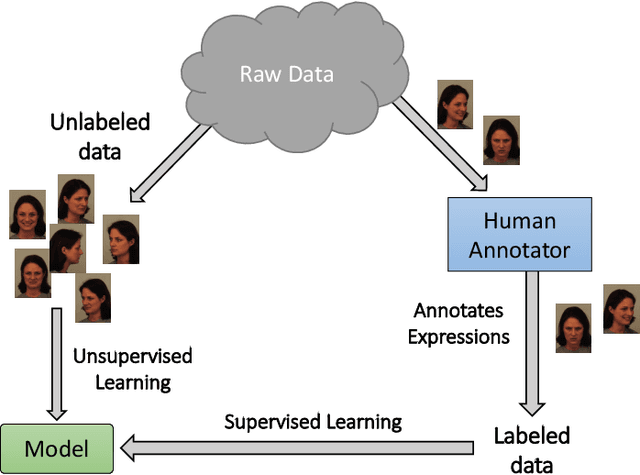
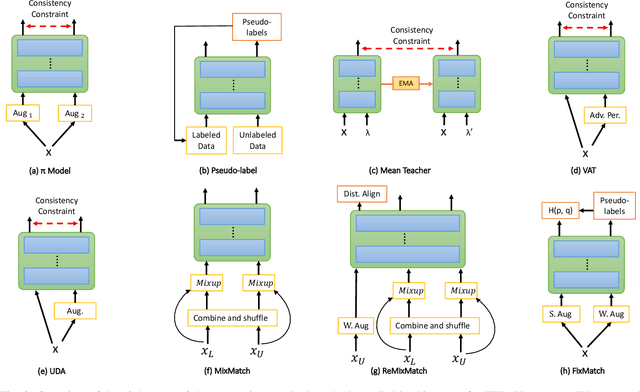


Training deep neural networks for image recognition often requires large-scale human annotated data. To reduce the reliance of deep neural solutions on labeled data, state-of-the-art semi-supervised methods have been proposed in the literature. Nonetheless, the use of such semi-supervised methods has been quite rare in the field of facial expression recognition (FER). In this paper, we present a comprehensive study on recently proposed state-of-the-art semi-supervised learning methods in the context of FER. We conduct comparative study on eight semi-supervised learning methods, namely Pi-Model, Pseudo-label, Mean-Teacher, VAT, MixMatch, ReMixMatch, UDA, and FixMatch, on three FER datasets (FER13, RAF-DB, and AffectNet), when various amounts of labeled samples are used. We also compare the performance of these methods against fully-supervised training. Our study shows that when training existing semi-supervised methods on as little as 250 labeled samples per class can yield comparable performances to that of fully-supervised methods trained on the full labeled datasets. To facilitate further research in this area, we make our code publicly available at: https://github.com/ShuvenduRoy/SSL_FER
SS-MFAR : Semi-supervised Multi-task Facial Affect Recognition
Jul 19, 2022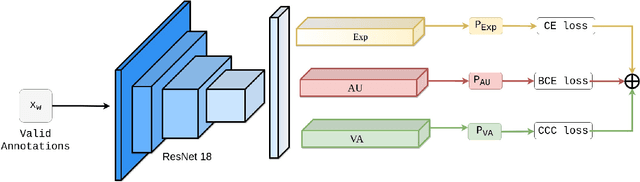
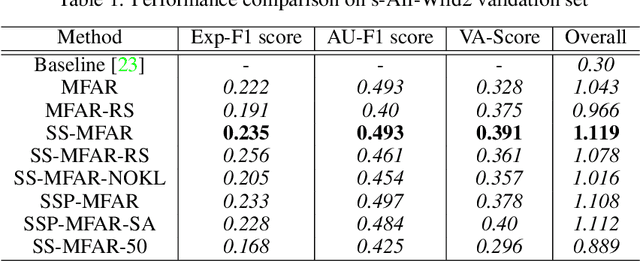
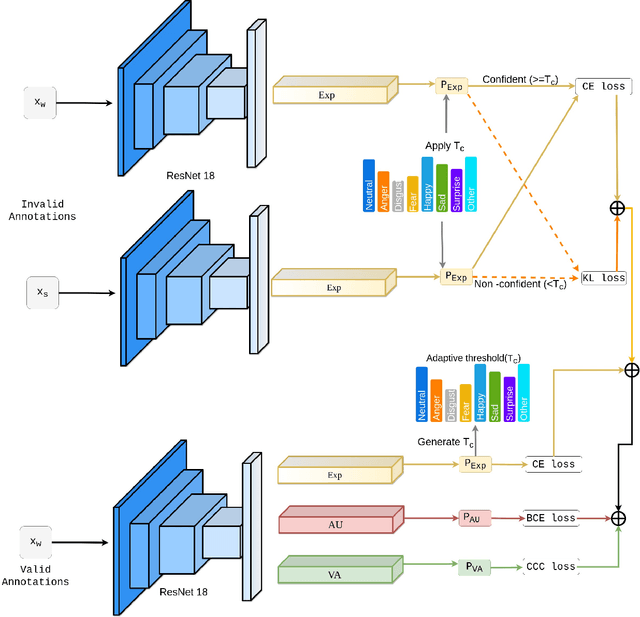
Automatic affect recognition has applications in many areas such as education, gaming, software development, automotives, medical care, etc. but it is non trivial task to achieve appreciable performance on in-the-wild data sets. In-the-wild data sets though represent real-world scenarios better than synthetic data sets, the former ones suffer from the problem of incomplete labels. Inspired by semi-supervised learning, in this paper, we introduce our submission to the Multi-Task-Learning Challenge at the 4th Affective Behavior Analysis in-the-wild (ABAW) 2022 Competition. The three tasks that are considered in this challenge are valence-arousal(VA) estimation, classification of expressions into 6 basic (anger, disgust, fear, happiness, sadness, surprise), neutral, and the 'other' category and 12 action units(AU) numbered AU-\{1,2,4,6,7,10,12,15,23,24,25,26\}. Our method Semi-supervised Multi-task Facial Affect Recognition titled \textbf{SS-MFAR} uses a deep residual network with task specific classifiers for each of the tasks along with adaptive thresholds for each expression class and semi-supervised learning for the incomplete labels. Source code is available at https://github.com/1980x/ABAW2022DMACS.
AU-Supervised Convolutional Vision Transformers for Synthetic Facial Expression Recognition
Jul 22, 2022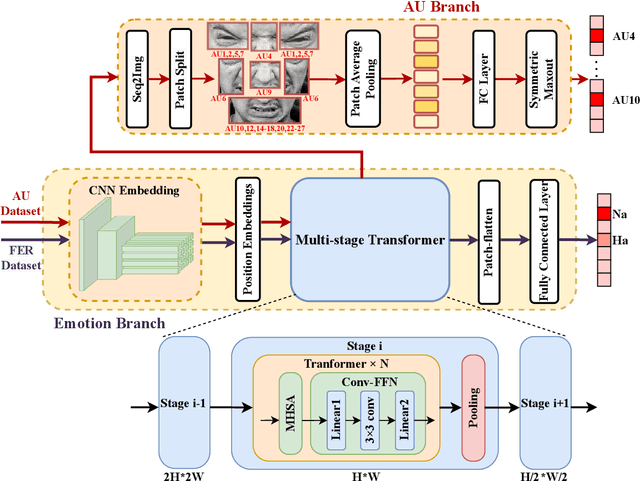
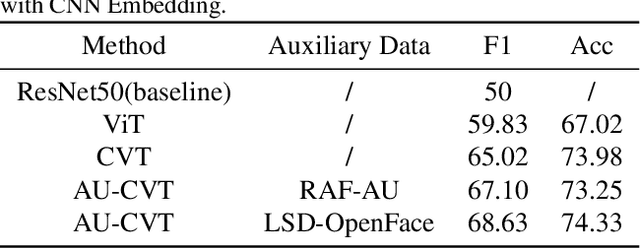
The paper describes our proposed methodology for the six basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2022. In Learing from Synthetic Data(LSD) task, facial expression recognition (FER) methods aim to learn the representation of expression from the artificially generated data and generalise to real data. Because of the ambiguous of the synthetic data and the objectivity of the facial Action Unit (AU), we resort to the AU information for performance boosting, and make contributions as follows. First, to adapt the model to synthetic scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose a conceptually-new framework, termed as AU-Supervised Convolutional Vision Transformers (AU-CVT), which clearly improves the performance of FER by jointly training auxiliary datasets with AU or pseudo AU labels. Our AU-CVT achieved F1 score as $0.6863$, accuracy as $0.7433$ on the validation set. The source code of our work is publicly available online: https://github.com/msy1412/ABAW4
Attention Based Relation Network for Facial Action Units Recognition
Oct 23, 2022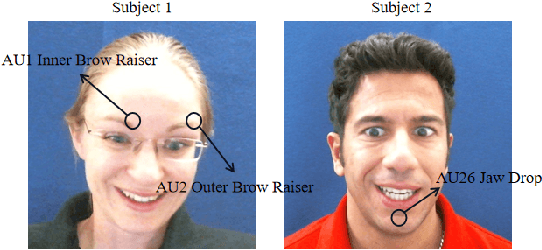
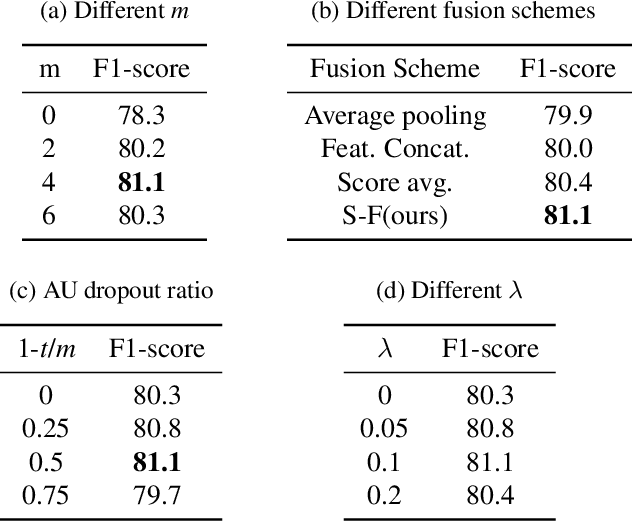
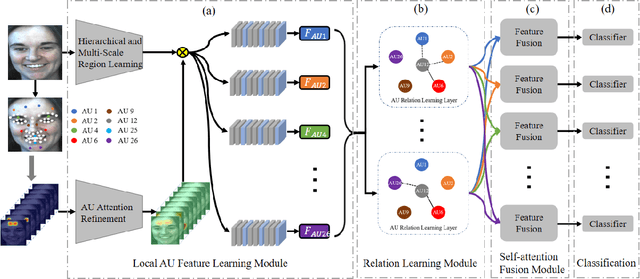
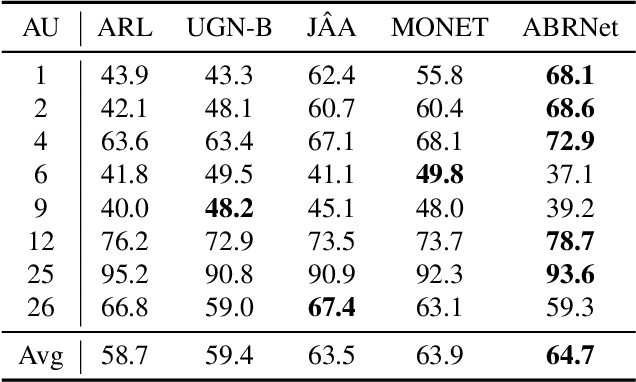
Facial action unit (AU) recognition is essential to facial expression analysis. Since there are highly positive or negative correlations between AUs, some existing AU recognition works have focused on modeling AU relations. However, previous relationship-based approaches typically embed predefined rules into their models and ignore the impact of various AU relations in different crowds. In this paper, we propose a novel Attention Based Relation Network (ABRNet) for AU recognition, which can automatically capture AU relations without unnecessary or even disturbing predefined rules. ABRNet uses several relation learning layers to automatically capture different AU relations. The learned AU relation features are then fed into a self-attention fusion module, which aims to refine individual AU features with attention weights to enhance the feature robustness. Furthermore, we propose an AU relation dropout strategy and AU relation loss (AUR-Loss) to better model AU relations, which can further improve AU recognition. Extensive experiments show that our approach achieves state-of-the-art performance on the DISFA and DISFA+ datasets.
How to Boost Face Recognition with StyleGAN?
Oct 18, 2022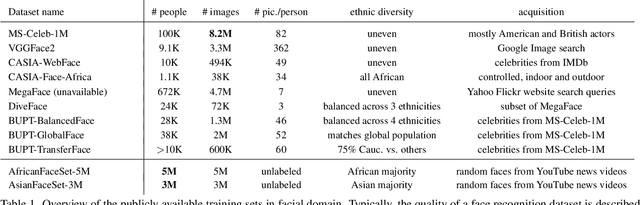
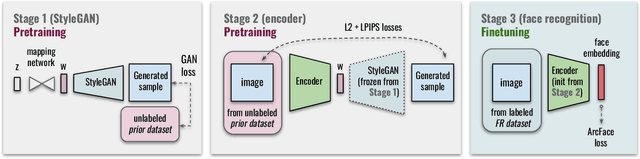
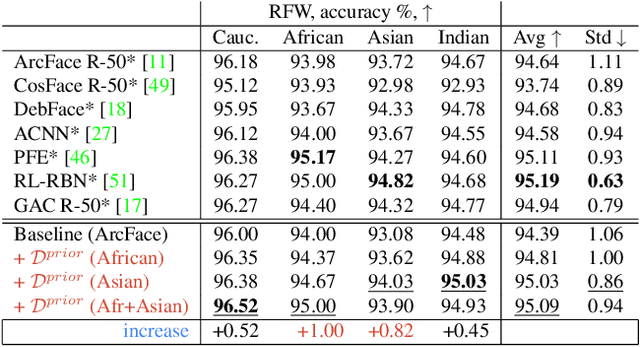

State-of-the-art face recognition systems require huge amounts of labeled training data. Given the priority of privacy in face recognition applications, the data is limited to celebrity web crawls, which have issues such as skewed distributions of ethnicities and limited numbers of identities. On the other hand, the self-supervised revolution in the industry motivates research on adaptation of the related techniques to facial recognition. One of the most popular practical tricks is to augment the dataset by the samples drawn from the high-resolution high-fidelity models (e.g. StyleGAN-like), while preserving the identity. We show that a simple approach based on fine-tuning an encoder for StyleGAN allows to improve upon the state-of-the-art facial recognition and performs better compared to training on synthetic face identities. We also collect large-scale unlabeled datasets with controllable ethnic constitution -- AfricanFaceSet-5M (5 million images of different people) and AsianFaceSet-3M (3 million images of different people) and we show that pretraining on each of them improves recognition of the respective ethnicities (as well as also others), while combining all unlabeled datasets results in the biggest performance increase. Our self-supervised strategy is the most useful with limited amounts of labeled training data, which can be beneficial for more tailored face recognition tasks and when facing privacy concerns. Evaluation is provided based on a standard RFW dataset and a new large-scale RB-WebFace benchmark.
Masked Student Dataset of Expressions
Apr 07, 2023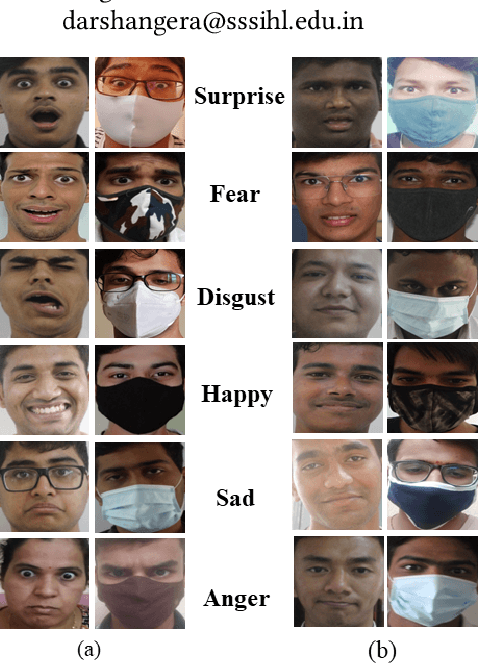

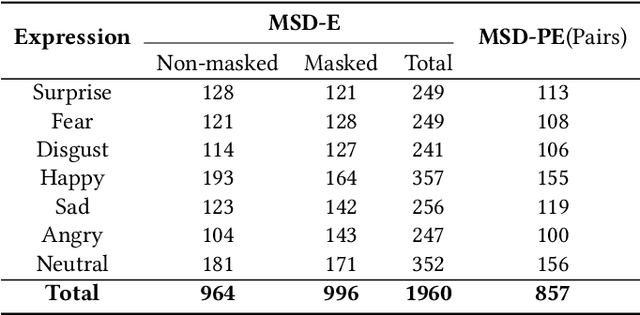
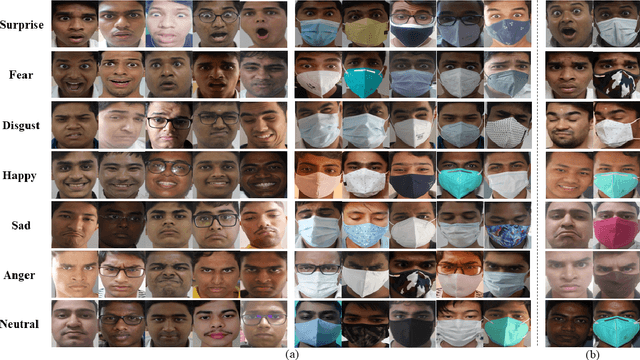
Facial expression recognition (FER) algorithms work well in constrained environments with little or no occlusion of the face. However, real-world face occlusion is prevalent, most notably with the need to use a face mask in the current Covid-19 scenario. While there are works on the problem of occlusion in FER, little has been done before on the particular face mask scenario. Moreover, the few works in this area largely use synthetically created masked FER datasets. Motivated by these challenges posed by the pandemic to FER, we present a novel dataset, the Masked Student Dataset of Expressions or MSD-E, consisting of 1,960 real-world non-masked and masked facial expression images collected from 142 individuals. Along with the issue of obfuscated facial features, we illustrate how other subtler issues in masked FER are represented in our dataset. We then provide baseline results using ResNet-18, finding that its performance dips in the non-masked case when trained for FER in the presence of masks. To tackle this, we test two training paradigms: contrastive learning and knowledge distillation, and find that they increase the model's performance in the masked scenario while maintaining its non-masked performance. We further visualise our results using t-SNE plots and Grad-CAM, demonstrating that these paradigms capitalise on the limited features available in the masked scenario. Finally, we benchmark SOTA methods on MSD-E.
Few-Shot Meta Learning for Recognizing Facial Phenotypes of Genetic Disorders
Oct 23, 2022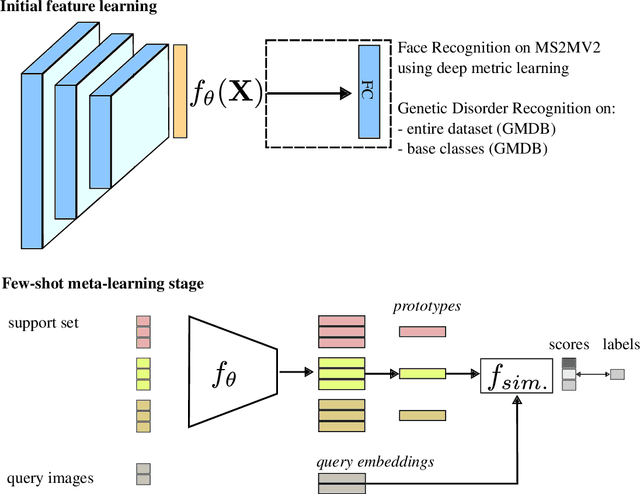
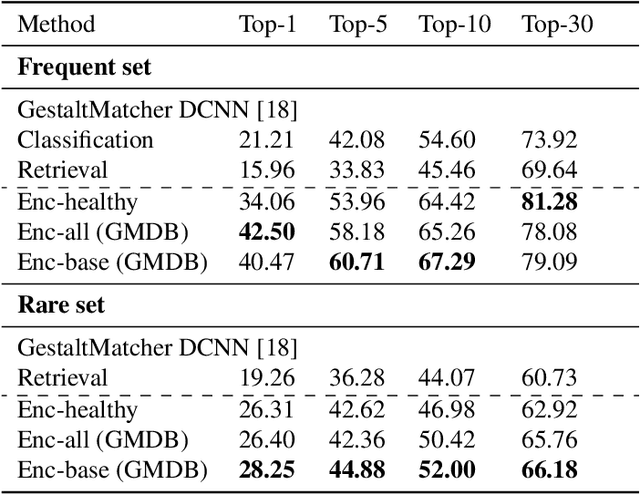
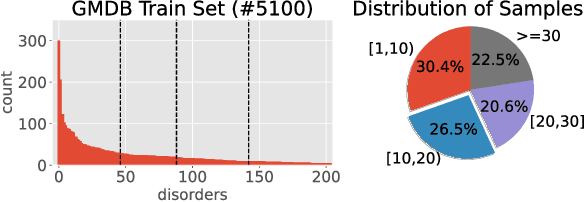
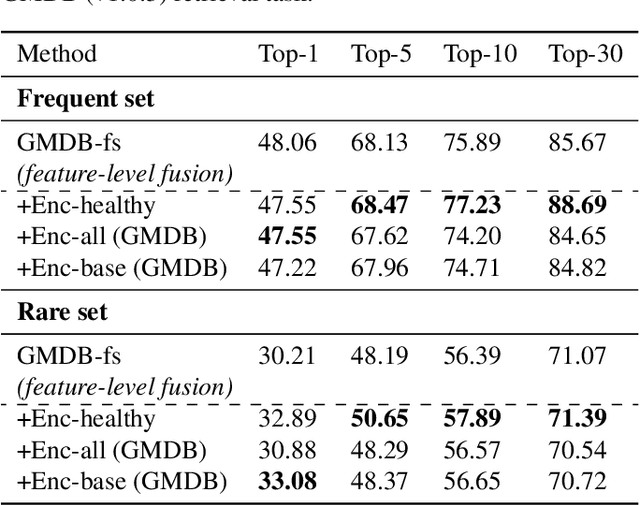
Computer vision-based methods have valuable use cases in precision medicine, and recognizing facial phenotypes of genetic disorders is one of them. Many genetic disorders are known to affect faces' visual appearance and geometry. Automated classification and similarity retrieval aid physicians in decision-making to diagnose possible genetic conditions as early as possible. Previous work has addressed the problem as a classification problem and used deep learning methods. The challenging issue in practice is the sparse label distribution and huge class imbalances across categories. Furthermore, most disorders have few labeled samples in training sets, making representation learning and generalization essential to acquiring a reliable feature descriptor. In this study, we used a facial recognition model trained on a large corpus of healthy individuals as a pre-task and transferred it to facial phenotype recognition. Furthermore, we created simple baselines of few-shot meta-learning methods to improve our base feature descriptor. Our quantitative results on GestaltMatcher Database show that our CNN baseline surpasses previous works, including GestaltMatcher, and few-shot meta-learning strategies improve retrieval performance in frequent and rare classes.
Kinship Representation Learning with Face Componential Relation
Apr 12, 2023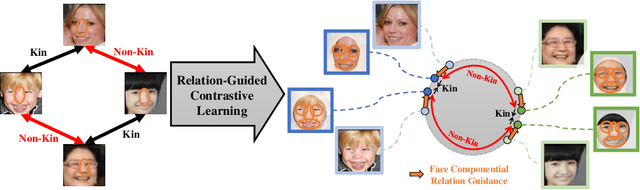
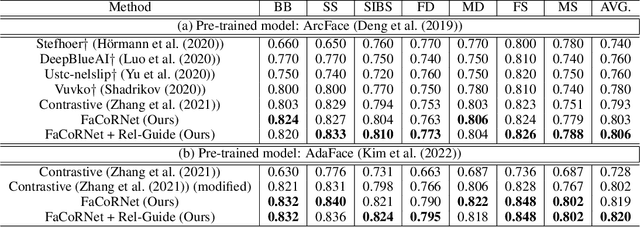
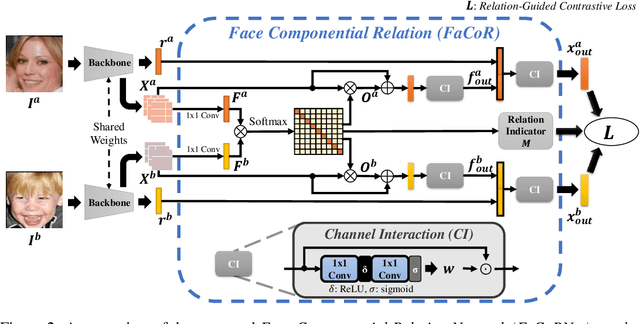
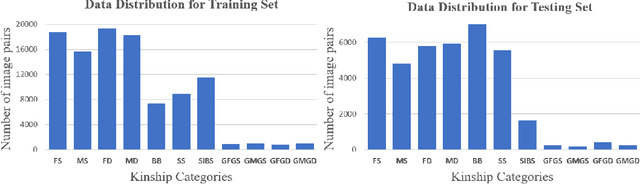
Kinship recognition aims to determine whether the subjects in two facial images are kin or non-kin, which is an emerging and challenging problem. However, most previous methods focus on heuristic designs without considering the spatial correlation between face images. In this paper, we aim to learn discriminative kinship representations embedded with the relation information between face components (e.g., eyes, nose, etc.). To achieve this goal, we propose the Face Componential Relation Network, which learns the relationship between face components among images with a cross-attention mechanism, which automatically learns the important facial regions for kinship recognition. Moreover, we propose Face Componential Relation Network (FaCoRNet), which adapts the loss function by the guidance from cross-attention to learn more discriminative feature representations. The proposed \MainMethodAbbr~outperforms previous state-of-the-art methods by large margins for the largest public kinship recognition FIW benchmark. The code will be publicly released upon acceptance.
Privacy-preserving Adversarial Facial Features
May 08, 2023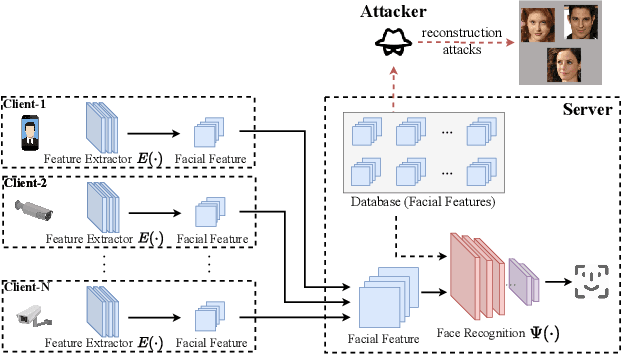

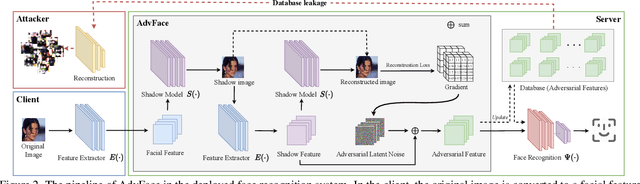

Face recognition service providers protect face privacy by extracting compact and discriminative facial features (representations) from images, and storing the facial features for real-time recognition. However, such features can still be exploited to recover the appearance of the original face by building a reconstruction network. Although several privacy-preserving methods have been proposed, the enhancement of face privacy protection is at the expense of accuracy degradation. In this paper, we propose an adversarial features-based face privacy protection (AdvFace) approach to generate privacy-preserving adversarial features, which can disrupt the mapping from adversarial features to facial images to defend against reconstruction attacks. To this end, we design a shadow model which simulates the attackers' behavior to capture the mapping function from facial features to images and generate adversarial latent noise to disrupt the mapping. The adversarial features rather than the original features are stored in the server's database to prevent leaked features from exposing facial information. Moreover, the AdvFace requires no changes to the face recognition network and can be implemented as a privacy-enhancing plugin in deployed face recognition systems. Extensive experimental results demonstrate that AdvFace outperforms the state-of-the-art face privacy-preserving methods in defending against reconstruction attacks while maintaining face recognition accuracy.
Mid-level Representation Enhancement and Graph Embedded Uncertainty Suppressing for Facial Expression Recognition
Jul 27, 2022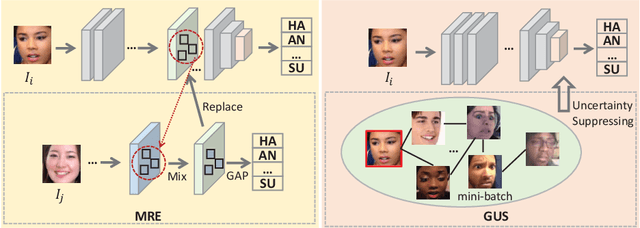
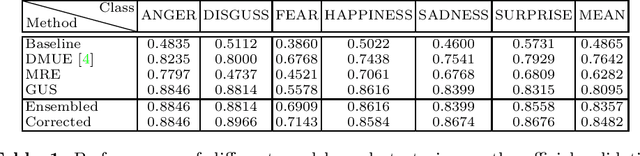
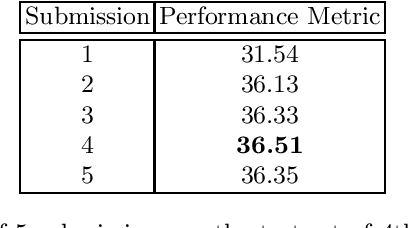
Facial expression is an essential factor in conveying human emotional states and intentions. Although remarkable advancement has been made in facial expression recognition (FER) task, challenges due to large variations of expression patterns and unavoidable data uncertainties still remain. In this paper, we propose mid-level representation enhancement (MRE) and graph embedded uncertainty suppressing (GUS) addressing these issues. On one hand, MRE is introduced to avoid expression representation learning being dominated by a limited number of highly discriminative patterns. On the other hand, GUS is introduced to suppress the feature ambiguity in the representation space. The proposed method not only has stronger generalization capability to handle different variations of expression patterns but also more robustness to capture expression representations. Experimental evaluation on Aff-Wild2 have verified the effectiveness of the proposed method.