 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Optimal Transport-based Identity Matching for Identity-invariant Facial Expression Recognition
Sep 25, 2022
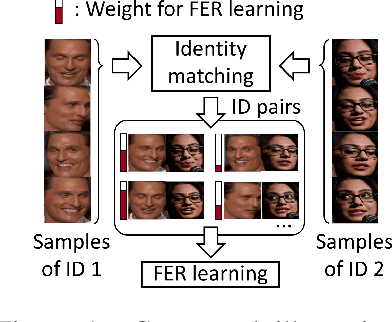
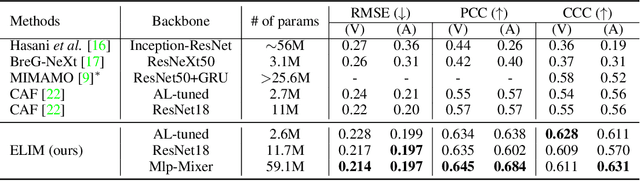
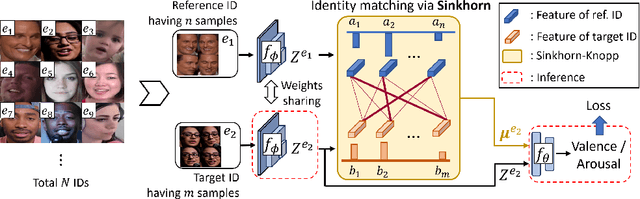
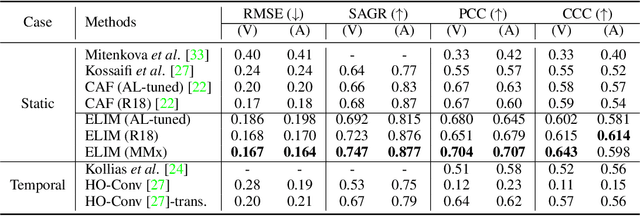
Identity-invariant facial expression recognition (FER) has been one of the challenging computer vision tasks. Since conventional FER schemes do not explicitly address the inter-identity variation of facial expressions, their neural network models still operate depending on facial identity. This paper proposes to quantify the inter-identity variation by utilizing pairs of similar expressions explored through a specific matching process. We formulate the identity matching process as an Optimal Transport (OT) problem. Specifically, to find pairs of similar expressions from different identities, we define the inter-feature similarity as a transportation cost. Then, optimal identity matching to find the optimal flow with minimum transportation cost is performed by Sinkhorn-Knopp iteration. The proposed matching method is not only easy to plug in to other models, but also requires only acceptable computational overhead. Extensive simulations prove that the proposed FER method improves the PCC/CCC performance by up to 10\% or more compared to the runner-up on wild datasets. The source code and software demo are available at https://github.com/kdhht2334/ELIM_FER.
Fair Multi-Exit Framework for Facial Attribute Classification
Jan 08, 2023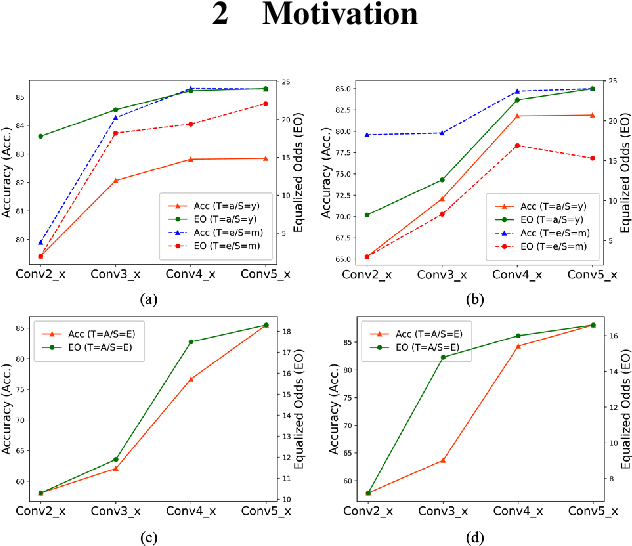
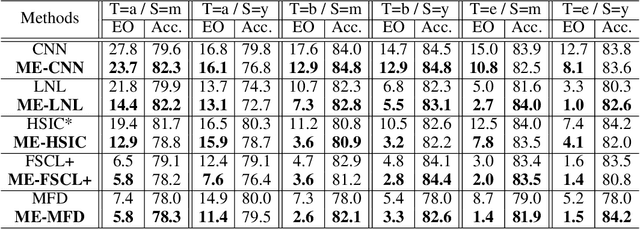
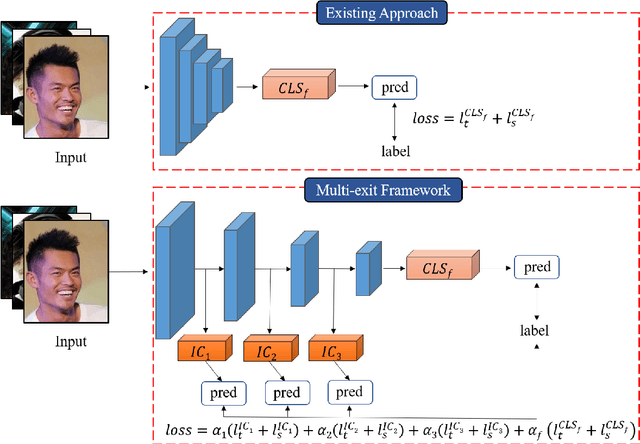
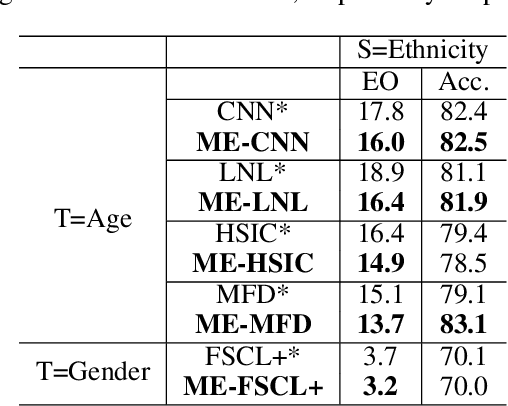
Fairness has become increasingly pivotal in facial recognition. Without bias mitigation, deploying unfair AI would harm the interest of the underprivileged population. In this paper, we observe that though the higher accuracy that features from the deeper layer of a neural networks generally offer, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit framework. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented, where the internal classifiers are trained to be more accurate and fairer. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Moreover, our framework can be applied to most existing fairness-aware frameworks. Experiment results show that the proposed framework can largely improve the fairness condition over the state-of-the-art in CelebA and UTK Face datasets.
TempT: Temporal consistency for Test-time adaptation
Mar 19, 2023
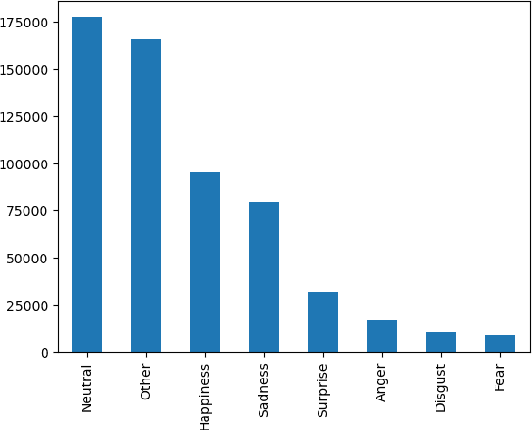
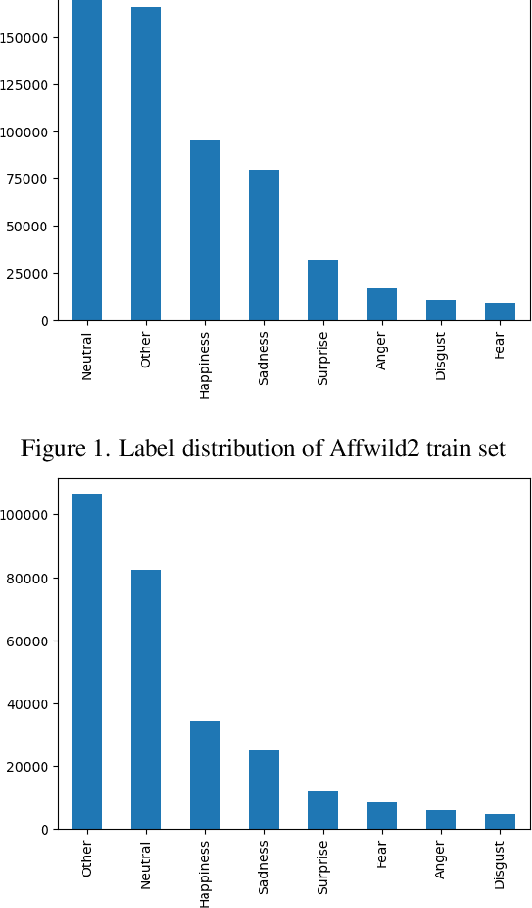

In this technical report, we introduce TempT, a novel method for test time adaptation on videos by ensuring temporal coherence of predictions across sequential frames. TempT is a powerful tool with broad applications in computer vision tasks, including facial expression recognition (FER) in videos. We evaluate TempT's performance on the AffWild2 dataset as part of the Expression Classification Challenge at the 5th Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). Our approach focuses solely on the unimodal visual aspect of the data and utilizes a popular 2D CNN backbone, in contrast to larger sequential or attention based models. Our experimental results demonstrate that TempT has competitive performance in comparison to previous years reported performances, and its efficacy provides a compelling proof of concept for its use in various real world applications.
Understanding bias in facial recognition technologies
Oct 05, 2020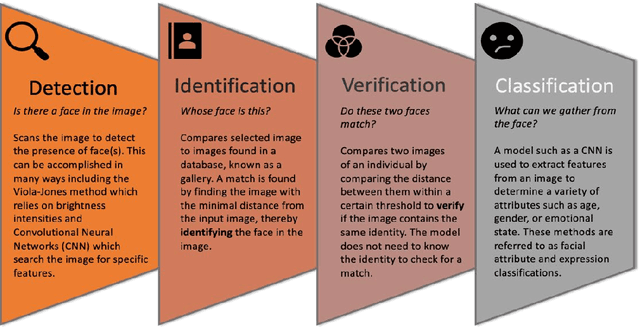

Over the past couple of years, the growing debate around automated facial recognition has reached a boiling point. As developers have continued to swiftly expand the scope of these kinds of technologies into an almost unbounded range of applications, an increasingly strident chorus of critical voices has sounded concerns about the injurious effects of the proliferation of such systems. Opponents argue that the irresponsible design and use of facial detection and recognition technologies (FDRTs) threatens to violate civil liberties, infringe on basic human rights and further entrench structural racism and systemic marginalisation. They also caution that the gradual creep of face surveillance infrastructures into every domain of lived experience may eventually eradicate the modern democratic forms of life that have long provided cherished means to individual flourishing, social solidarity and human self-creation. Defenders, by contrast, emphasise the gains in public safety, security and efficiency that digitally streamlined capacities for facial identification, identity verification and trait characterisation may bring. In this explainer, I focus on one central aspect of this debate: the role that dynamics of bias and discrimination play in the development and deployment of FDRTs. I examine how historical patterns of discrimination have made inroads into the design and implementation of FDRTs from their very earliest moments. And, I explain the ways in which the use of biased FDRTs can lead distributional and recognitional injustices. The explainer concludes with an exploration of broader ethical questions around the potential proliferation of pervasive face-based surveillance infrastructures and makes some recommendations for cultivating more responsible approaches to the development and governance of these technologies.
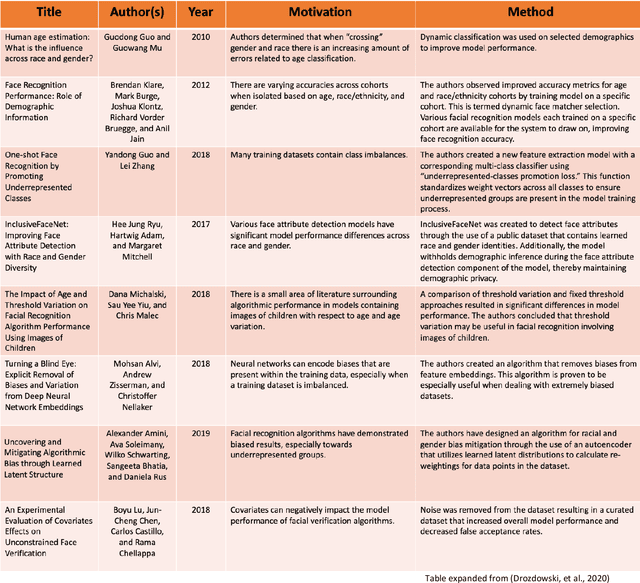
Emotion Recognition for Challenged People Facial Appearance in Social using Neural Network
May 11, 2023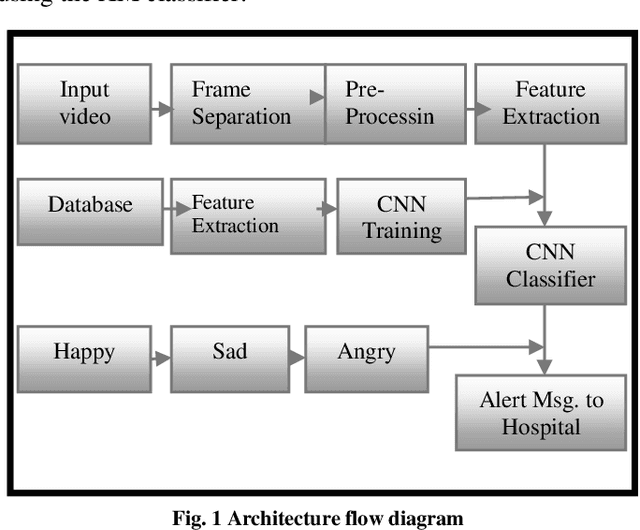
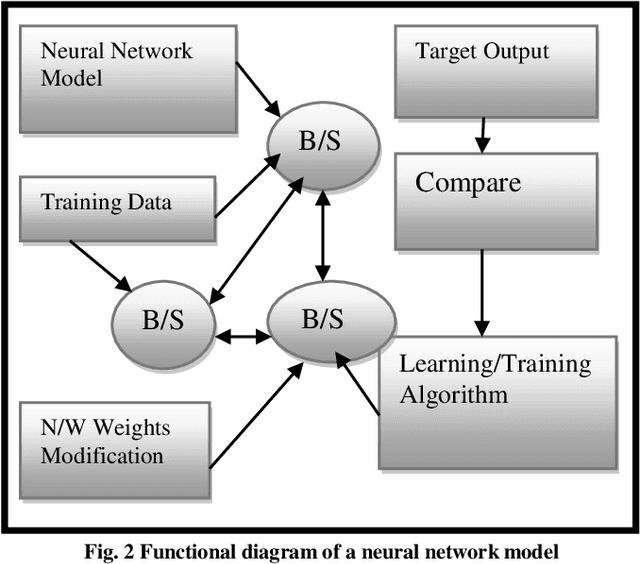
Human communication is the vocal and non verbal signal to communicate with others. Human expression is a significant biometric object in picture and record databases of surveillance systems. Face appreciation has a serious role in biometric methods and is good-looking for plentiful applications, including visual scrutiny and security. Facial expressions are a form of nonverbal communication; recognizing them helps improve the human machine interaction. This paper proposes an idea for face and enlightenment invariant credit of facial expressions by the images. In order on, the person's face can be computed. Face expression is used in CNN classifier to categorize the acquired picture into different emotion categories. It is a deep, feed-forward artificial neural network. Outcome surpasses human presentation and shows poses alternate performance. Varying lighting conditions can influence the fitting process and reduce recognition precision. Results illustrate that dependable facial appearance credited with changing lighting conditions for separating reasonable facial terminology display emotions is an efficient representation of clean and assorted moving expressions. This process can also manage the proportions of dissimilar basic affecting expressions of those mixed jointly to produce sensible emotional facial expressions. Our system contains a pre-defined data set, which was residential by a statistics scientist and includes all pure and varied expressions. On average, a data set has achieved 92.4% exact validation of the expressions synthesized by our technique. These facial expressions are compared through the pre-defined data-position inside our system. If it recognizes the person in an abnormal condition, an alert will be passed to the nearby hospital/doctor seeing that a message.
Facial Expression Recognition and Image Description Generation in Vietnamese
Aug 12, 2022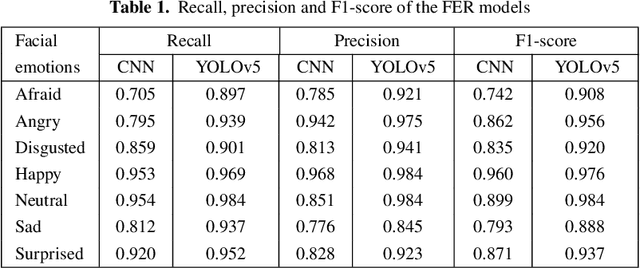
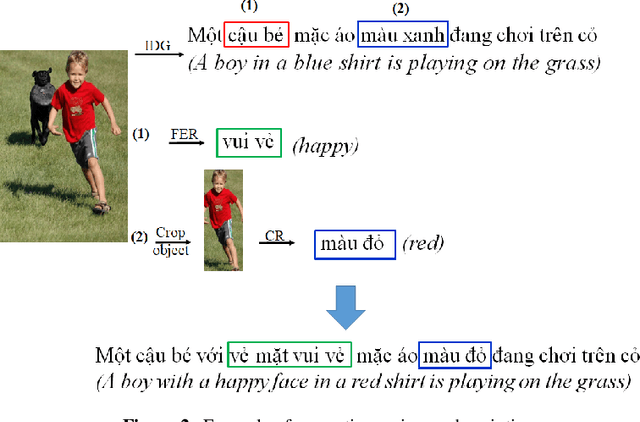

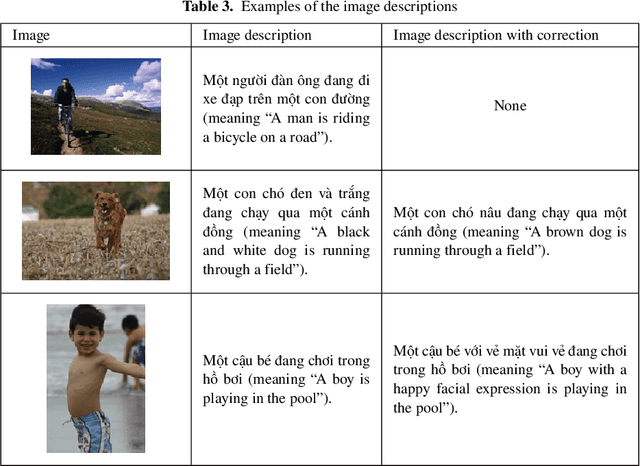
This paper discusses a facial expression recognition model and a description generation model to build descriptive sentences for images and facial expressions of people in images. Our study shows that YOLOv5 achieves better results than a traditional CNN for all emotions on the KDEF dataset. In particular, the accuracies of the CNN and YOLOv5 models for emotion recognition are 0.853 and 0.938, respectively. A model for generating descriptions for images based on a merged architecture is proposed using VGG16 with the descriptions encoded over an LSTM model. YOLOv5 is also used to recognize dominant colors of objects in the images and correct the color words in the descriptions generated if it is necessary. If the description contains words referring to a person, we recognize the emotion of the person in the image. Finally, we combine the results of all models to create sentences that describe the visual content and the human emotions in the images. Experimental results on the Flickr8k dataset in Vietnamese achieve BLEU-1, BLEU-2, BLEU-3, BLEU-4 scores of 0.628; 0.425; 0.280; and 0.174, respectively.
* 7 pages
Hybrid Facial Expression Recognition (FER2013) Model for Real-Time Emotion Classification and Prediction
Jun 19, 2022

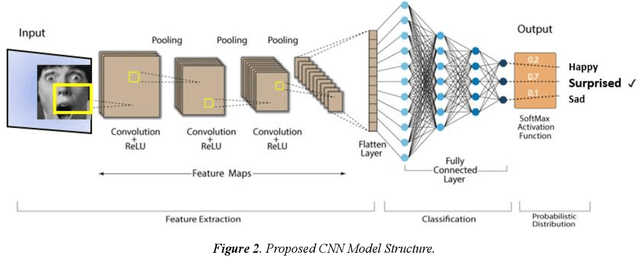

Facial Expression Recognition is a vital research topic in most fields ranging from artificial intelligence and gaming to Human-Computer Interaction (HCI) and Psychology. This paper proposes a hybrid model for Facial Expression recognition, which comprises a Deep Convolutional Neural Network (DCNN) and Haar Cascade deep learning architectures. The objective is to classify real-time and digital facial images into one of the seven facial emotion categories considered. The DCNN employed in this research has more convolutional layers, ReLU Activation functions, and multiple kernels to enhance filtering depth and facial feature extraction. In addition, a haar cascade model was also mutually used to detect facial features in real-time images and video frames. Grayscale images from the Kaggle repository (FER-2013) and then exploited Graphics Processing Unit (GPU) computation to expedite the training and validation process. Pre-processing and data augmentation techniques are applied to improve training efficiency and classification performance. The experimental results show a significantly improved classification performance compared to state-of-the-art (SoTA) experiments and research. Also, compared to other conventional models, this paper validates that the proposed architecture is superior in classification performance with an improvement of up to 6%, totaling up to 70% accuracy, and with less execution time of 2098.8s.
Performance analysis of facial recognition: A critical review through glass factor
Apr 04, 2021
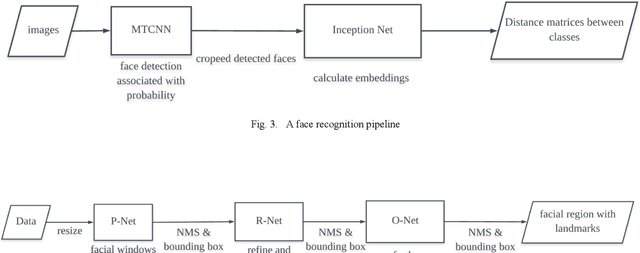
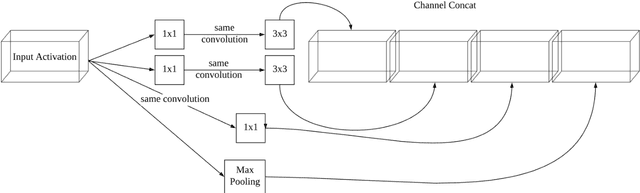

COVID-19 pandemic and social distancing urge a reliable human face recognition system in different abnormal situations. However, there is no research which studies the influence of glass factor in facial recognition system. This paper provides a comprehensive review of glass factor. The study contains two steps: data collection and accuracy test. Data collection includes collecting human face images through different situations, such as clear glasses, glass with water and glass with mist. Based on the collected data, an existing state-of-the-art face detection and recognition system built upon MTCNN and Inception V1 deep nets is tested for further analysis. Experimental data supports that 1) the system is robust for classification when comparing real-time images and 2) it fails at determining if two images are of same person by comparing real-time disturbed image with the frontal ones.
Kinship Representation Learning with Face Componential Relation
Apr 22, 2023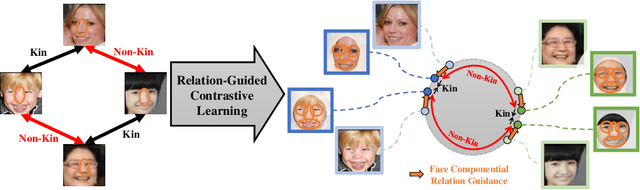
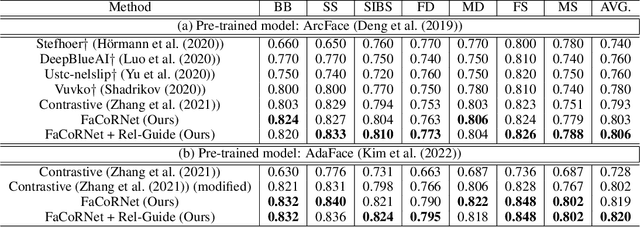
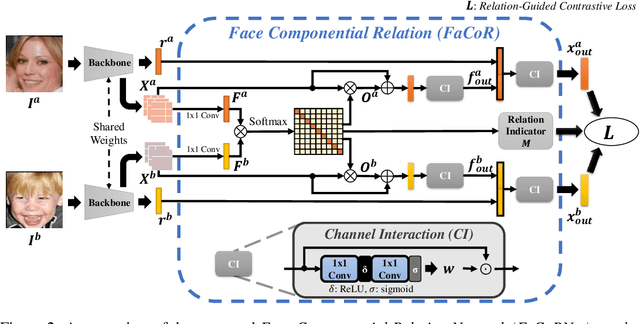
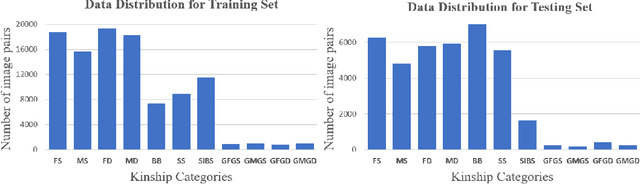
Kinship recognition aims to determine whether the subjects in two facial images are kin or non-kin, which is an emerging and challenging problem. However, most previous methods focus on heuristic designs without considering the spatial correlation between face images. In this paper, we aim to learn discriminative kinship representations embedded with the relation information between face components (e.g., eyes, nose, etc.). To achieve this goal, we propose the Face Componential Relation Network, which learns the relationship between face components among images with a cross-attention mechanism, which automatically learns the important facial regions for kinship recognition. Moreover, we propose Face Componential Relation Network (FaCoRNet), which adapts the loss function by the guidance from cross-attention to learn more discriminative feature representations. The proposed FaCoRNet outperforms previous state-of-the-art methods by large margins for the largest public kinship recognition FIW benchmark. The code will be publicly released upon acceptance.
Coarse-to-Fine Cascaded Networks with Smooth Predicting for Video Facial Expression Recognition
Mar 28, 2022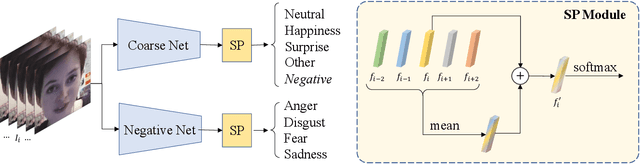
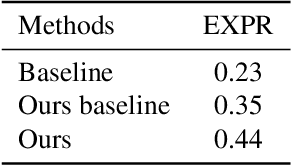

Facial expression recognition plays an important role in human-computer interaction. In this paper, we propose the Coarse-to-Fine Cascaded network with Smooth Predicting (CFC-SP) to improve the performance of facial expression recognition. CFC-SP contains two core components, namely Coarse-to-Fine Cascaded networks (CFC) and Smooth Predicting (SP). For CFC, it first groups several similar emotions to form a rough category, and then employs a network to conduct a coarse but accurate classification. Later, an additional network for these grouped emotions is further used to obtain fine-grained predictions. For SP, it improves the recognition capability of the model by capturing both universal and unique expression features. To be specific, the universal features denote the general characteristic of facial emotions within a period and the unique features denote the specific characteristic at this moment. Experiments on Aff-Wild2 show the effectiveness of the proposed CFSP.