 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
A Review of ChatGPT Applications in Education, Marketing, Software Engineering, and Healthcare: Benefits, Drawbacks, and Research Directions
Apr 29, 2023
ChatGPT is a type of artificial intelligence language model that uses deep learning algorithms to generate human-like responses to text-based prompts. The introduction of the latest ChatGPT version in November of 2022 has caused shockwaves in the industrial and academic communities for its powerful capabilities, plethora of possible applications, and the great possibility for abuse. At the time of writing this work, several other language models (e.g., Google Bard and Meta LLaMA) just came out in an attempt to get a foothold in the vast possible market. These models have the ability to revolutionize the way we interact with computers and have potential applications in many fields, including education, software engineering, healthcare, and marketing. In this paper, we will discuss the possible applications, drawbacks, and research directions using advanced language Chatbots (e.g., ChatGPT) in each of these fields. We first start with a brief introduction and the development timeline of artificial intelligence based language models, then we go through possible applications of such models, after that we discuss the limitations and drawbacks of the current technological state of the art, and finally we point out future possible research directions.
Can ChatGPT and Bard Generate Aligned Assessment Items? A Reliability Analysis against Human Performance
Apr 09, 2023
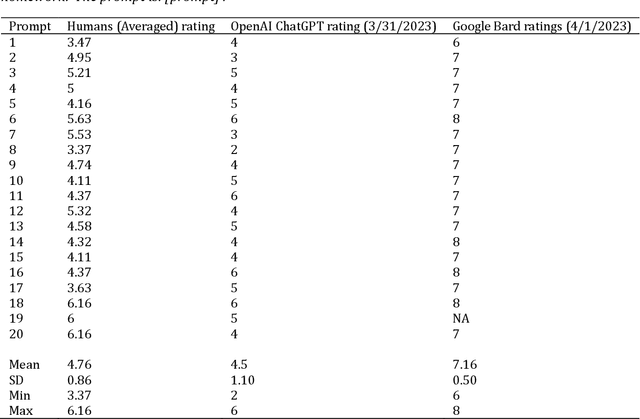

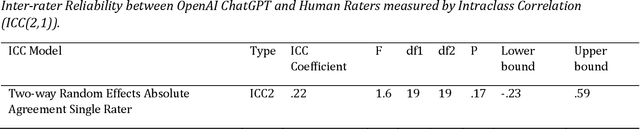
ChatGPT and Bard are AI chatbots based on Large Language Models (LLM) that are slated to promise different applications in diverse areas. In education, these AI technologies have been tested for applications in assessment and teaching. In assessment, AI has long been used in automated essay scoring and automated item generation. One psychometric property that these tools must have to assist or replace humans in assessment is high reliability in terms of agreement between AI scores and human raters. In this paper, we measure the reliability of OpenAI ChatGP and Google Bard LLMs tools against experienced and trained humans in perceiving and rating the complexity of writing prompts. Intraclass correlation (ICC) as a performance metric showed that the inter-reliability of both the OpenAI ChatGPT and the Google Bard were low against the gold standard of human ratings.
QLoRA: Efficient Finetuning of Quantized LLMs
May 23, 2023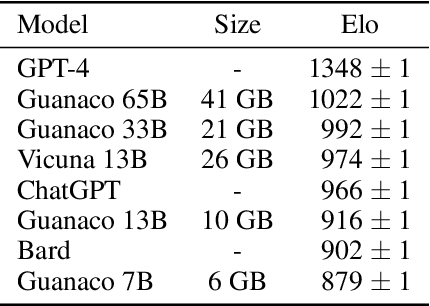
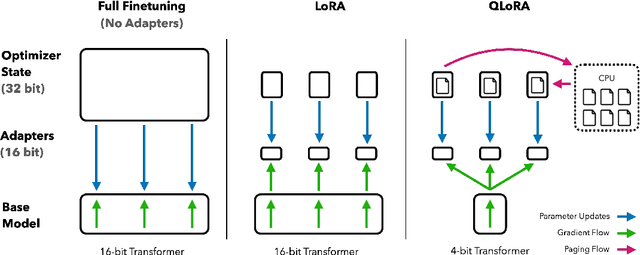
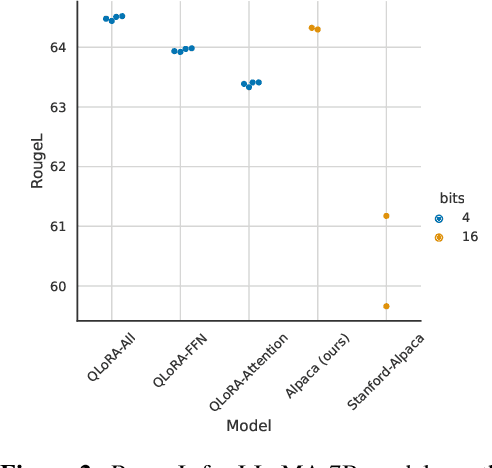
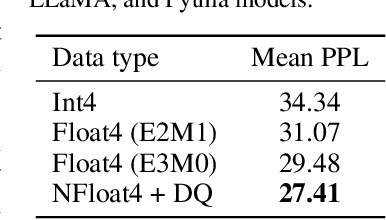
We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimziers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
May 05, 2023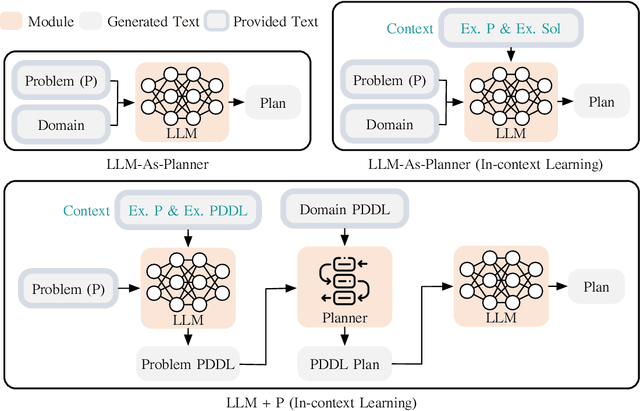
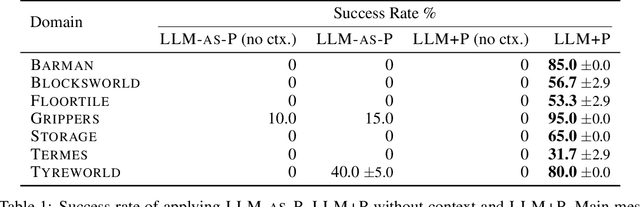
Large language models (LLMs) have demonstrated remarkable zero-shot generalization abilities: state-of-the-art chatbots can provide plausible answers to many common questions that arise in daily life. However, so far, LLMs cannot reliably solve long-horizon planning problems. By contrast, classical planners, once a problem is given in a formatted way, can use efficient search algorithms to quickly identify correct, or even optimal, plans. In an effort to get the best of both worlds, this paper introduces LLM+P, the first framework that incorporates the strengths of classical planners into LLMs. LLM+P takes in a natural language description of a planning problem, then returns a correct (or optimal) plan for solving that problem in natural language. LLM+P does so by first converting the language description into a file written in the planning domain definition language (PDDL), then leveraging classical planners to quickly find a solution, and then translating the found solution back into natural language. Along with LLM+P, we define a diverse set of different benchmark problems taken from common planning scenarios. Via a comprehensive set of experiments on these benchmark problems, we find that LLM+P is able to provide optimal solutions for most problems, while LLMs fail to provide even feasible plans for most problems.\footnote{The code and results are publicly available at https://github.com/Cranial-XIX/llm-pddl.git.
Artificial General Intelligence (AGI) for Education
Apr 24, 2023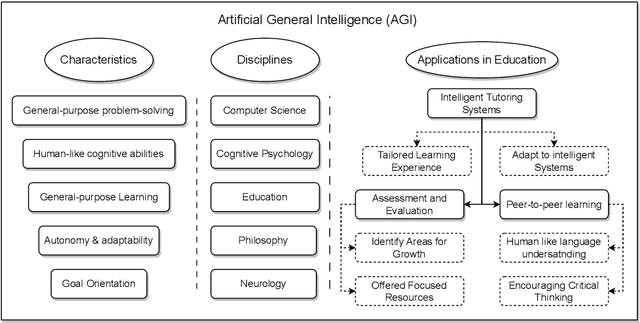
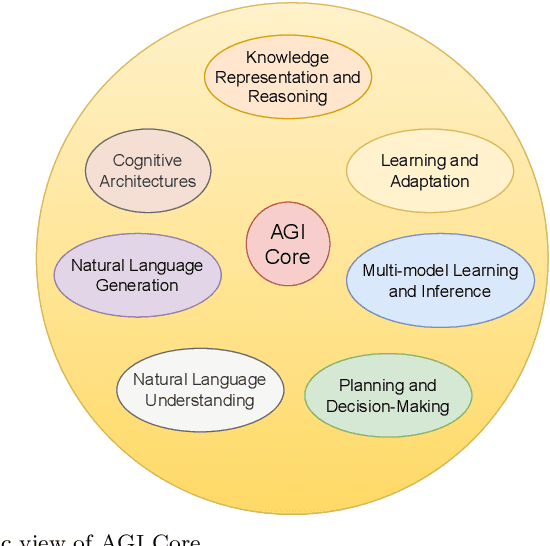
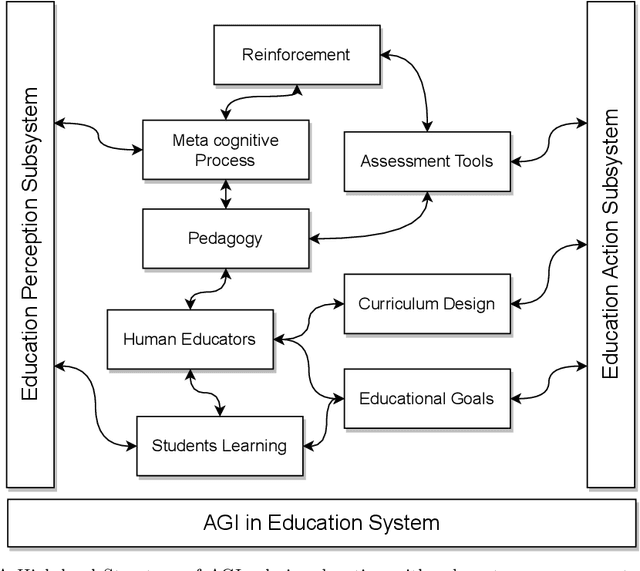
Artificial general intelligence (AGI) has gained global recognition as a future technology due to the emergence of breakthrough large language models and chatbots such as GPT-4 and ChatGPT, respectively. AGI aims to replicate human intelligence through computer systems, which is one of the critical technologies having the potential to revolutionize the field of education. Compared to conventional AI models, typically designed for a limited range of tasks, demand significant amounts of domain-specific data for training and may not always consider intricate interpersonal dynamics in education. AGI, driven by the recent large pre-trained models, represents a significant leap in the capability of machines to perform tasks that require human-level intelligence, such as reasoning, problem-solving, decision-making, and even understanding human emotions and social interactions. This work reviews AGI's key concepts, capabilities, scope, and potential within future education, including setting educational goals, designing pedagogy and curriculum, and performing assessments. We also provide rich discussions over various ethical issues in education faced by AGI and how AGI will affect human educators. The development of AGI necessitates interdisciplinary collaborations between educators and AI engineers to advance research and application efforts.
A Reinforcement Learning-based Offensive semantics Censorship System for Chatbots
Jul 13, 2022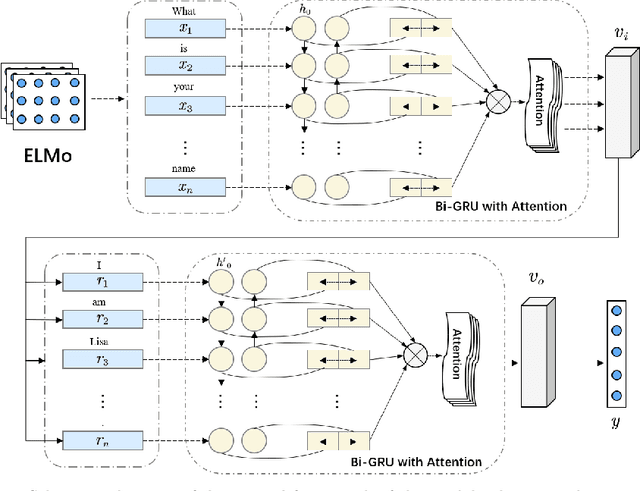

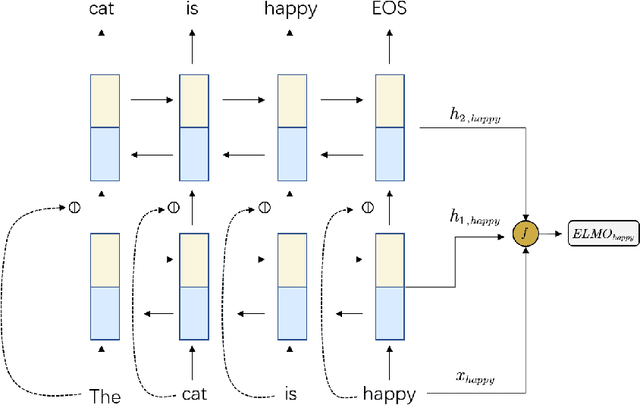

The rapid development of artificial intelligence (AI) technology has enabled large-scale AI applications to land in the market and practice. However, while AI technology has brought many conveniences to people in the productization process, it has also exposed many security issues. Especially, attacks against online learning vulnerabilities of chatbots occur frequently. Therefore, this paper proposes a semantics censorship chatbot system based on reinforcement learning, which is mainly composed of two parts: the Offensive semantics censorship model and the semantics purification model. Offensive semantics review can combine the context of user input sentences to detect the rapid evolution of Offensive semantics and respond to Offensive semantics responses. The semantics purification model For the case of chatting robot models, it has been contaminated by large numbers of offensive semantics, by strengthening the offensive reply learned by the learning algorithm, rather than rolling back to the early versions. In addition, by integrating a once-through learning approach, the speed of semantics purification is accelerated while reducing the impact on the quality of replies. The experimental results show that our proposed approach reduces the probability of the chat model generating offensive replies and that the integration of the few-shot learning algorithm improves the training speed rapidly while effectively slowing down the decline in BLEU values.
What Types of Questions Require Conversation to Answer? A Case Study of AskReddit Questions
Apr 03, 2023


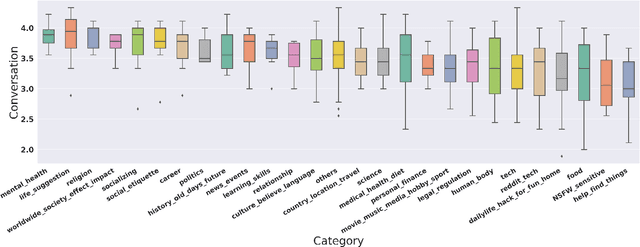
The proliferation of automated conversational systems such as chatbots, spoken-dialogue systems, and smart speakers, has significantly impacted modern digital life. However, these systems are primarily designed to provide answers to well-defined questions rather than to support users in exploring complex, ill-defined questions. In this paper, we aim to push the boundaries of conversational systems by examining the types of nebulous, open-ended questions that can best be answered through conversation. We first sampled 500 questions from one million open-ended requests posted on AskReddit, and then recruited online crowd workers to answer eight inquiries about these questions. We also performed open coding to categorize the questions into 27 different domains. We found that the issues people believe require conversation to resolve satisfactorily are highly social and personal. Our work provides insights into how future research could be geared to align with users' needs.
Chatbots in a Honeypot World
Jan 10, 2023
Question-and-answer agents like ChatGPT offer a novel tool for use as a potential honeypot interface in cyber security. By imitating Linux, Mac, and Windows terminal commands and providing an interface for TeamViewer, nmap, and ping, it is possible to create a dynamic environment that can adapt to the actions of attackers and provide insight into their tactics, techniques, and procedures (TTPs). The paper illustrates ten diverse tasks that a conversational agent or large language model might answer appropriately to the effects of command-line attacker. The original result features feasibility studies for ten model tasks meant for defensive teams to mimic expected honeypot interfaces with minimal risks. Ultimately, the usefulness outside of forensic activities stems from whether the dynamic honeypot can extend the time-to-conquer or otherwise delay attacker timelines short of reaching key network assets like databases or confidential information. While ongoing maintenance and monitoring may be required, ChatGPT's ability to detect and deflect malicious activity makes it a valuable option for organizations seeking to enhance their cyber security posture. Future work will focus on cybersecurity layers, including perimeter security, host virus detection, and data security.
Unlocking the Potential of ChatGPT: A Comprehensive Exploration of its Applications, Advantages, Limitations, and Future Directions in Natural Language Processing
Apr 12, 2023
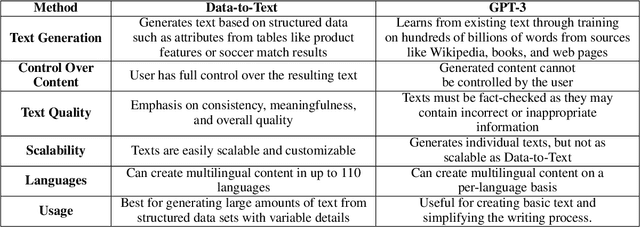
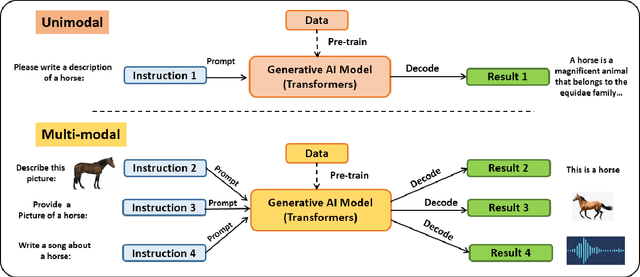
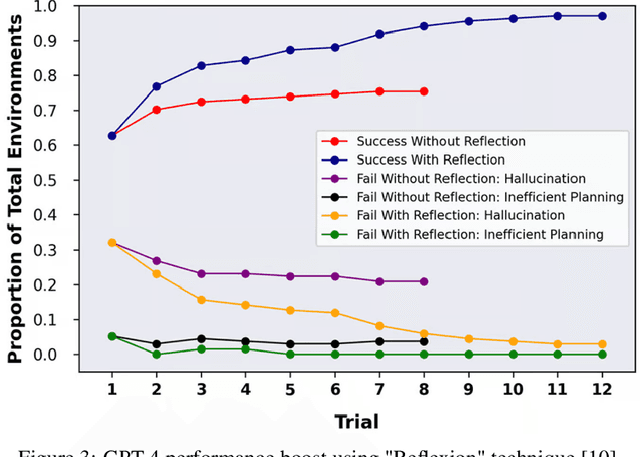
Large language models have revolutionized the field of artificial intelligence and have been used in various applications. Among these models, ChatGPT (Chat Generative Pre-trained Transformer) has been developed by OpenAI, it stands out as a powerful tool that has been widely adopted. ChatGPT has been successfully applied in numerous areas, including chatbots, content generation, language translation, personalized recommendations, and even medical diagnosis and treatment. Its success in these applications can be attributed to its ability to generate human-like responses, understand natural language, and adapt to different contexts. Its versatility and accuracy make it a powerful tool for natural language processing (NLP). However, there are also limitations to ChatGPT, such as its tendency to produce biased responses and its potential to perpetuate harmful language patterns. This article provides a comprehensive overview of ChatGPT, its applications, advantages, and limitations. Additionally, the paper emphasizes the importance of ethical considerations when using this robust tool in real-world scenarios. Finally, This paper contributes to ongoing discussions surrounding artificial intelligence and its impact on vision and NLP domains by providing insights into prompt engineering techniques.
Should ChatGPT be Biased? Challenges and Risks of Bias in Large Language Models
Apr 18, 2023
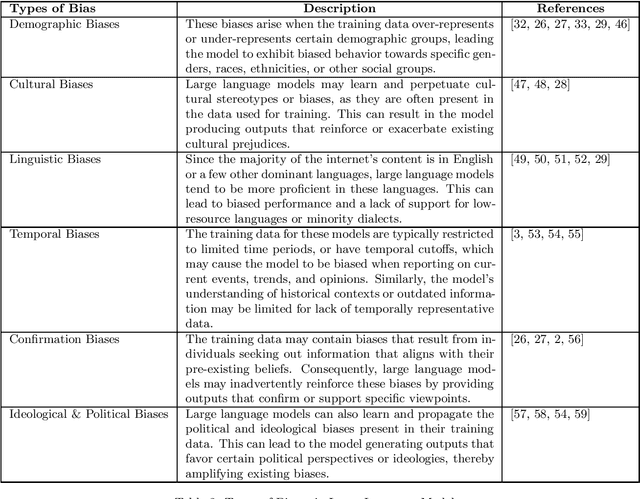


As the capabilities of generative language models continue to advance, the implications of biases ingrained within these models have garnered increasing attention from researchers, practitioners, and the broader public. This article investigates the challenges and risks associated with biases in large-scale language models like ChatGPT. We discuss the origins of biases, stemming from, among others, the nature of training data, model specifications, algorithmic constraints, product design, and policy decisions. We explore the ethical concerns arising from the unintended consequences of biased model outputs. We further analyze the potential opportunities to mitigate biases, the inevitability of some biases, and the implications of deploying these models in various applications, such as virtual assistants, content generation, and chatbots. Finally, we review the current approaches to identify, quantify, and mitigate biases in language models, emphasizing the need for a multi-disciplinary, collaborative effort to develop more equitable, transparent, and responsible AI systems. This article aims to stimulate a thoughtful dialogue within the artificial intelligence community, encouraging researchers and developers to reflect on the role of biases in generative language models and the ongoing pursuit of ethical AI.