 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
The Chai Platform's AI Safety Framework
Jun 05, 2023
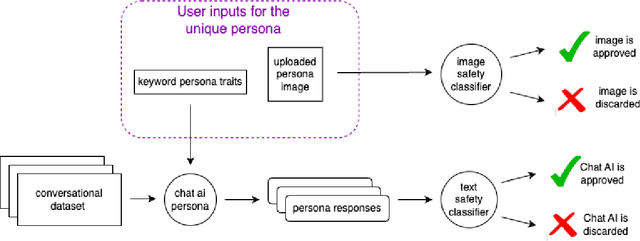
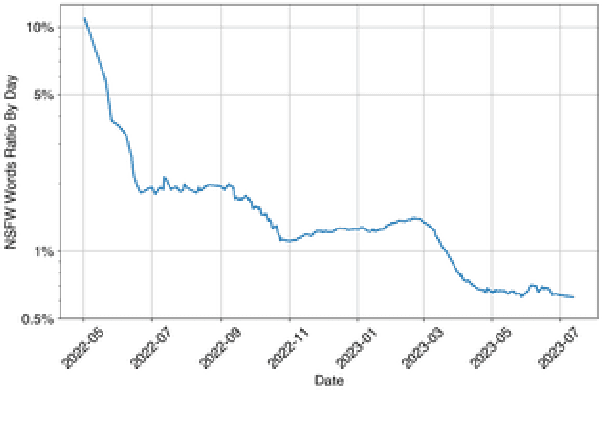
Chai empowers users to create and interact with customized chatbots, offering unique and engaging experiences. Despite the exciting prospects, the work recognizes the inherent challenges of a commitment to modern safety standards. Therefore, this paper presents the integrated AI safety principles into Chai to prioritize user safety, data protection, and ethical technology use. The paper specifically explores the multidimensional domain of AI safety research, demonstrating its application in Chai's conversational chatbot platform. It presents Chai's AI safety principles, informed by well-established AI research centres and adapted for chat AI. This work proposes the following safety framework: Content Safeguarding; Stability and Robustness; and Operational Transparency and Traceability. The subsequent implementation of these principles is outlined, followed by an experimental analysis of Chai's AI safety framework's real-world impact. We emphasise the significance of conscientious application of AI safety principles and robust safety measures. The successful implementation of the safe AI framework in Chai indicates the practicality of mitigating potential risks for responsible and ethical use of AI technologies. The ultimate vision is a transformative AI tool fostering progress and innovation while prioritizing user safety and ethical standards.
Generative AI: Implications and Applications for Education
May 15, 2023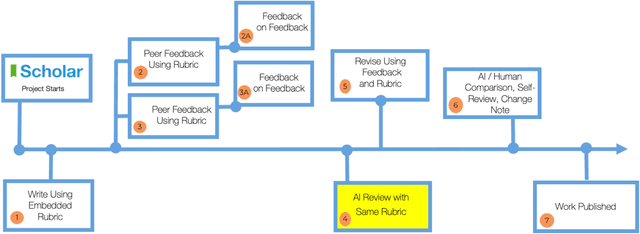
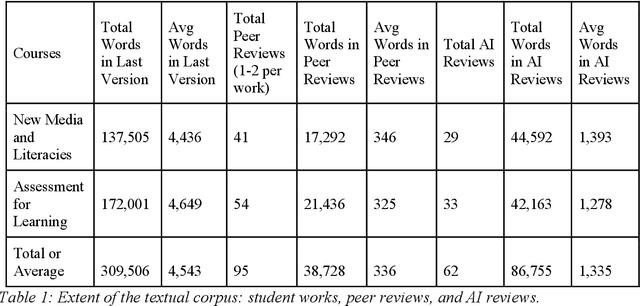
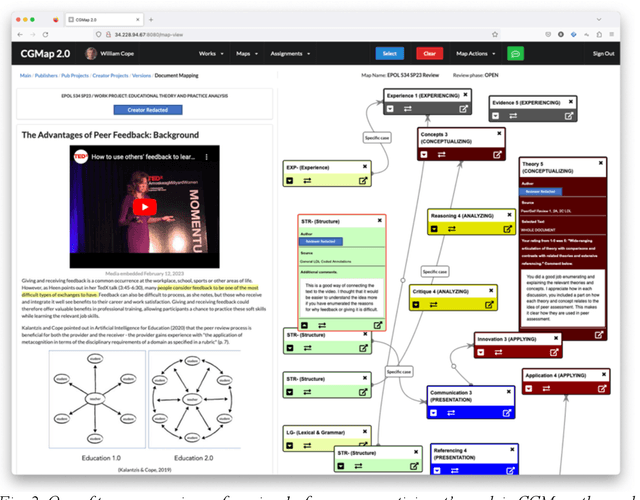
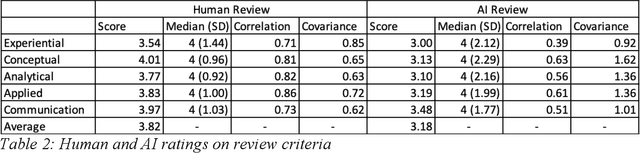
The launch of ChatGPT in November 2022 precipitated a panic among some educators while prompting qualified enthusiasm from others. Under the umbrella term Generative AI, ChatGPT is an example of a range of technologies for the delivery of computer-generated text, image, and other digitized media. This paper examines the implications for education of one generative AI technology, chatbots responding from large language models, or C-LLM. It reports on an application of a C-LLM to AI review and assessment of complex student work. In a concluding discussion, the paper explores the intrinsic limits of generative AI, bound as it is to language corpora and their textual representation through binary notation. Within these limits, we suggest the range of emerging and potential applications of Generative AI in education.
A Framework for Designing Foundation Model based Systems
May 21, 2023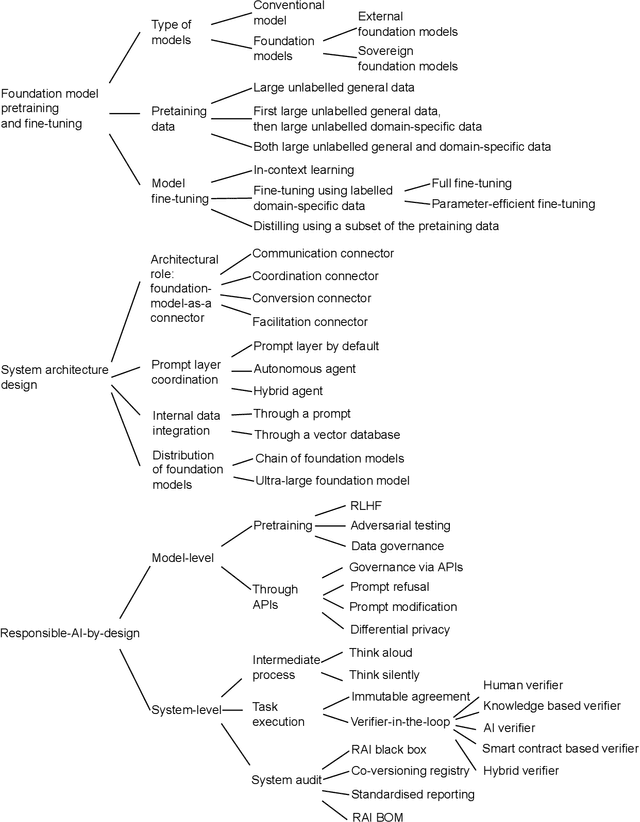
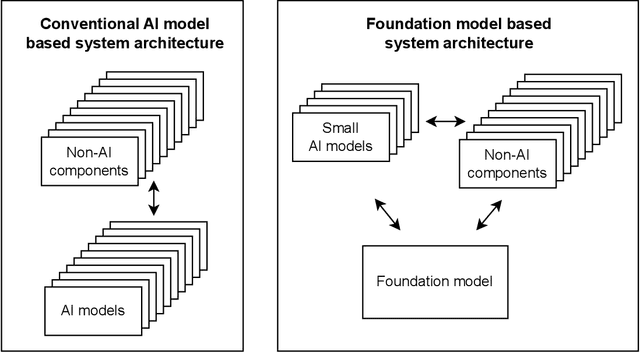
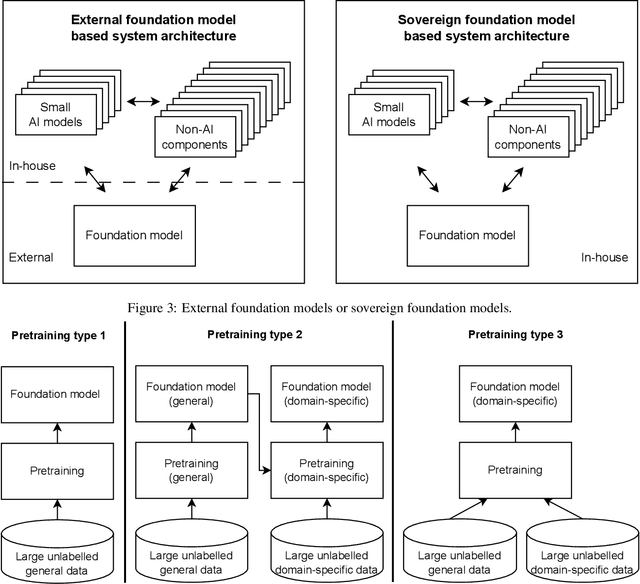
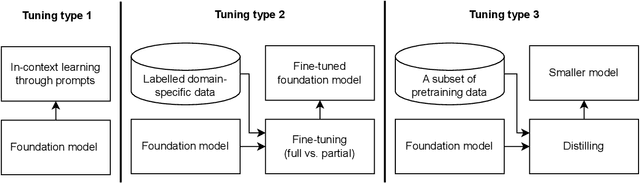
The recent release of large language model (LLM) based chatbots, such as ChatGPT, has attracted significant attention on foundation models. It is widely believed that foundation models will serve as the fundamental building blocks for future AI systems. As foundation models are in their early stages, the design of foundation model based systems has not yet been systematically explored. There is little understanding about the impact of introducing foundation models in software architecture. Therefore, in this paper, we propose a taxonomy of foundation model based systems, which classifies and compares the characteristics of foundation models and design options of foundation model based systems. Our taxonomy comprises three categories: foundation model pretraining and fine-tuning, architecture design of foundation model based systems, and responsible-AI-by-design. This taxonomy provides concrete guidance for making major design decisions when designing foundation model based systems and highlights trade-offs arising from design decisions.
A Conditional Generative Chatbot using Transformer Model
Jun 03, 2023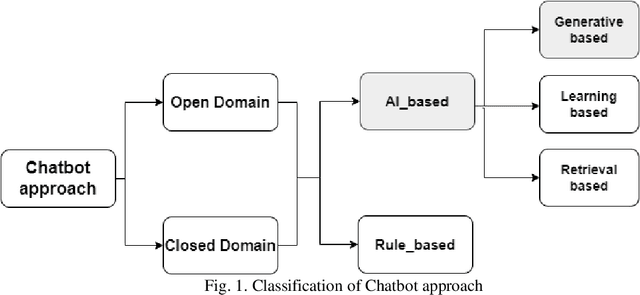
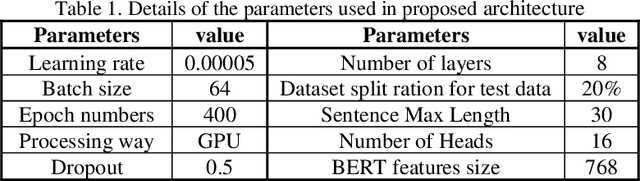
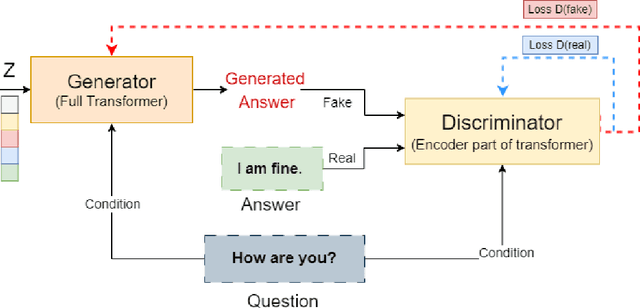
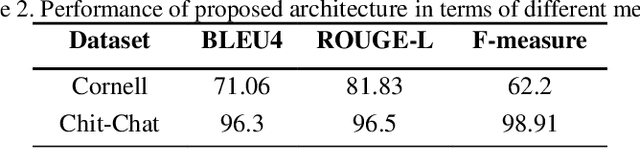
A Chatbot serves as a communication tool between a human user and a machine to achieve an appropriate answer based on the human input. In more recent approaches, a combination of Natural Language Processing and sequential models are used to build a generative Chatbot. The main challenge of these models is their sequential nature, which leads to less accurate results. To tackle this challenge, in this paper, a novel end-to-end architecture is proposed using conditional Wasserstein Generative Adversarial Networks and a transformer model for answer generation in Chatbots. While the generator of the proposed model consists of a full transformer model to generate an answer, the discriminator includes only the encoder part of a transformer model followed by a classifier. To the best of our knowledge, this is the first time that a generative Chatbot is proposed using the embedded transformer in both generator and discriminator models. Relying on the parallel computing of the transformer model, the results of the proposed model on the Cornell Movie-Dialog corpus and the Chit-Chat datasets confirm the superiority of the proposed model compared to state-of-the-art alternatives using different evaluation metrics.
Human or Not? A Gamified Approach to the Turing Test
May 31, 2023



We present "Human or Not?", an online game inspired by the Turing test, that measures the capability of AI chatbots to mimic humans in dialog, and of humans to tell bots from other humans. Over the course of a month, the game was played by over 1.5 million users who engaged in anonymous two-minute chat sessions with either another human or an AI language model which was prompted to behave like humans. The task of the players was to correctly guess whether they spoke to a person or to an AI. This largest scale Turing-style test conducted to date revealed some interesting facts. For example, overall users guessed the identity of their partners correctly in only 68% of the games. In the subset of the games in which users faced an AI bot, users had even lower correct guess rates of 60% (that is, not much higher than chance). This white paper details the development, deployment, and results of this unique experiment. While this experiment calls for many extensions and refinements, these findings already begin to shed light on the inevitable near future which will commingle humans and AI.
User Adaptive Language Learning Chatbots with a Curriculum
Apr 11, 2023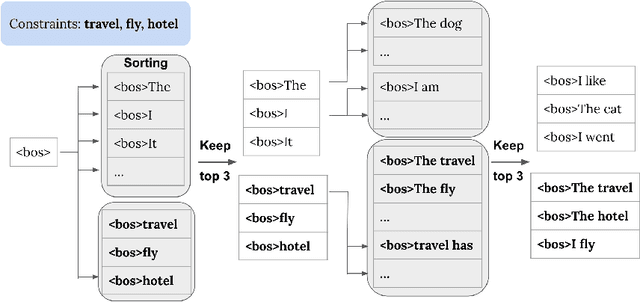
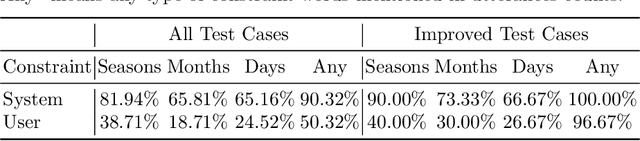

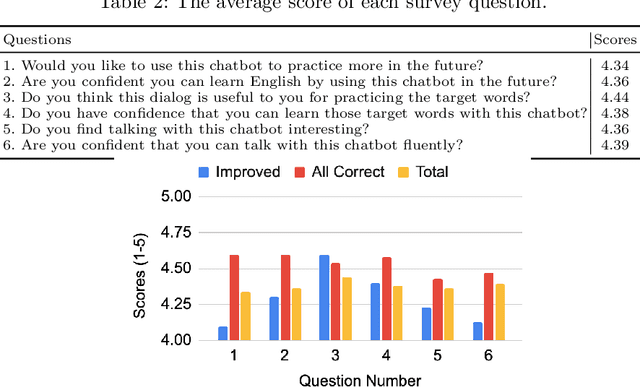
Along with the development of systems for natural language understanding and generation, dialog systems have been widely adopted for language learning and practicing. Many current educational dialog systems perform chitchat, where the generated content and vocabulary are not constrained. However, for learners in a school setting, practice through dialog is more effective if it aligns with students' curriculum and focuses on textbook vocabulary. Therefore, we adapt lexically constrained decoding to a dialog system, which urges the dialog system to include curriculum-aligned words and phrases in its generated utterances. We adopt a generative dialog system, BlenderBot3, as our backbone model and evaluate our curriculum-based dialog system with middle school students learning English as their second language. The constrained words and phrases are derived from their textbooks, suggested by their English teachers. The evaluation result demonstrates that the dialog system with curriculum infusion improves students' understanding of target words and increases their interest in practicing English.
Critical Appraisal of Artificial Intelligence-Mediated Communication
May 15, 2023Over the last two decades, technology use in language learning and teaching has significantly advanced and is now referred to as Computer-Assisted Language Learning (CALL). Recently, the integration of Artificial Intelligence (AI) into CALL has brought about a significant shift in the traditional approach to language education both inside and outside the classroom. In line with this book's scope, I explore the advantages and disadvantages of AI-mediated communication in language education. I begin with a brief review of AI in education. I then introduce the ICALL and give a critical appraisal of the potential of AI-powered automatic speech recognition (ASR), Machine Translation (MT), Intelligent Tutoring Systems (ITSs), AI-powered chatbots, and Extended Reality (XR). In conclusion, I argue that it is crucial for language teachers to engage in CALL teacher education and professional development to keep up with the ever-evolving technology landscape and improve their teaching effectiveness.
Gpt-4: A Review on Advancements and Opportunities in Natural Language Processing
May 04, 2023Generative Pre-trained Transformer 4 (GPT-4) is the fourth-generation language model in the GPT series, developed by OpenAI, which promises significant advancements in the field of natural language processing (NLP). In this research article, we have discussed the features of GPT-4, its potential applications, and the challenges that it might face. We have also compared GPT-4 with its predecessor, GPT-3. GPT-4 has a larger model size (more than one trillion), better multilingual capabilities, improved contextual understanding, and reasoning capabilities than GPT-3. Some of the potential applications of GPT-4 include chatbots, personal assistants, language translation, text summarization, and question-answering. However, GPT-4 poses several challenges and limitations such as computational requirements, data requirements, and ethical concerns.
Does ChatGPT resemble humans in language use?
Mar 10, 2023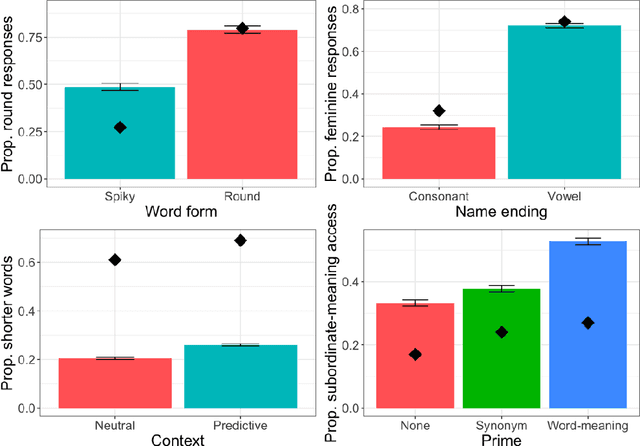
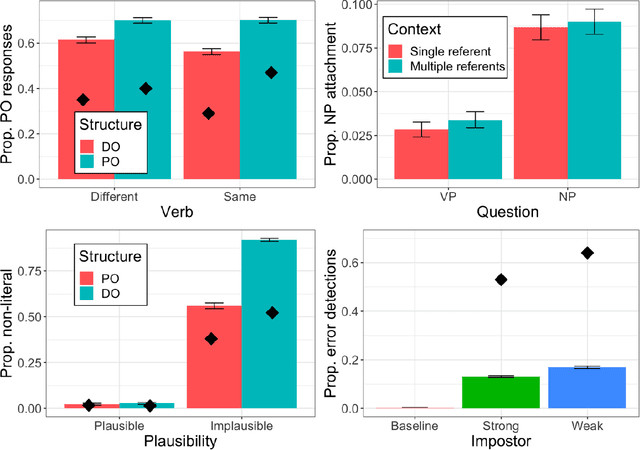
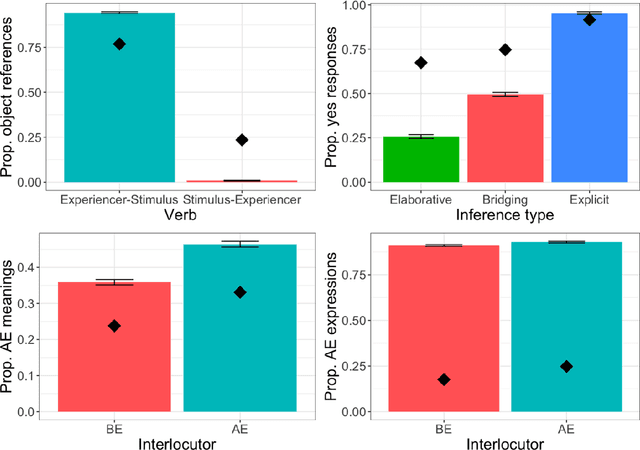
Large language models (LLMs) and LLM-driven chatbots such as ChatGPT have shown remarkable capacities in comprehending and producing language. However, their internal workings remain a black box in cognitive terms, and it is unclear whether LLMs and chatbots can develop humanlike characteristics in language use. Cognitive scientists have devised many experiments that probe, and have made great progress in explaining, how people process language. We subjected ChatGPT to 12 of these experiments, pre-registered and with 1,000 runs per experiment. In 10 of them, ChatGPT replicated the human pattern of language use. It associated unfamiliar words with different meanings depending on their forms, continued to access recently encountered meanings of ambiguous words, reused recent sentence structures, reinterpreted implausible sentences that were likely to have been corrupted by noise, glossed over errors, drew reasonable inferences, associated causality with different discourse entities according to verb semantics, and accessed different meanings and retrieved different words depending on the identity of its interlocutor. However, unlike humans, it did not prefer using shorter words to convey less informative content and it did not use context to disambiguate syntactic ambiguities. We discuss how these convergences and divergences may occur in the transformer architecture. Overall, these experiments demonstrate that LLM-driven chatbots like ChatGPT are capable of mimicking human language processing to a great extent, and that they have the potential to provide insights into how people learn and use language.
Learn What NOT to Learn: Towards Generative Safety in Chatbots
Apr 25, 2023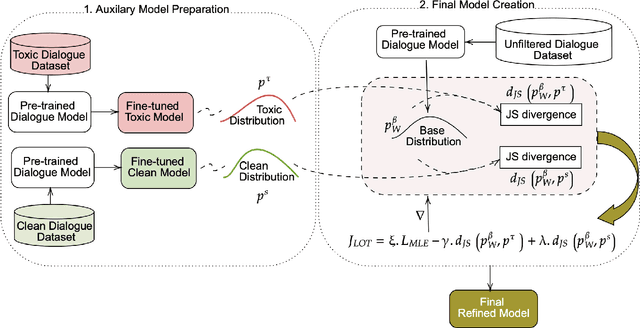
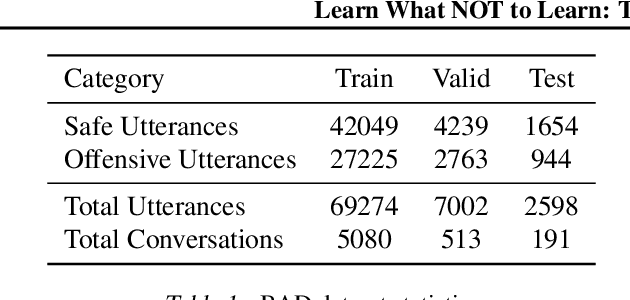
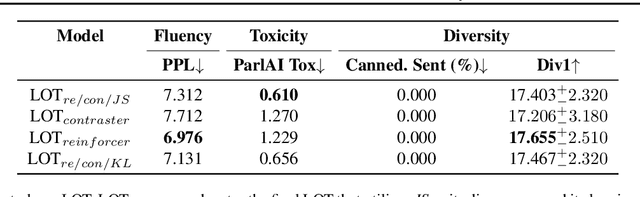
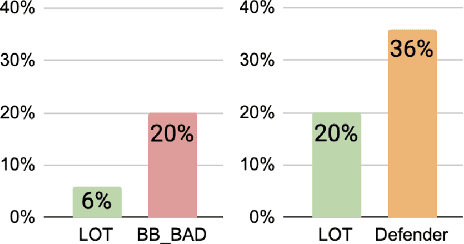
Conversational models that are generative and open-domain are particularly susceptible to generating unsafe content since they are trained on web-based social data. Prior approaches to mitigating this issue have drawbacks, such as disrupting the flow of conversation, limited generalization to unseen toxic input contexts, and sacrificing the quality of the dialogue for the sake of safety. In this paper, we present a novel framework, named "LOT" (Learn NOT to), that employs a contrastive loss to enhance generalization by learning from both positive and negative training signals. Our approach differs from the standard contrastive learning framework in that it automatically obtains positive and negative signals from the safe and unsafe language distributions that have been learned beforehand. The LOT framework utilizes divergence to steer the generations away from the unsafe subspace and towards the safe subspace while sustaining the flow of conversation. Our approach is memory and time-efficient during decoding and effectively reduces toxicity while preserving engagingness and fluency. Empirical results indicate that LOT reduces toxicity by up to four-fold while achieving four to six-fold higher rates of engagingness and fluency compared to baseline models. Our findings are further corroborated by human evaluation.