 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
Using LLM-assisted Annotation for Corpus Linguistics: A Case Study of Local Grammar Analysis
May 25, 2023
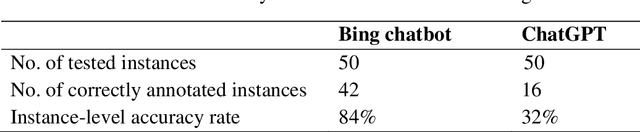

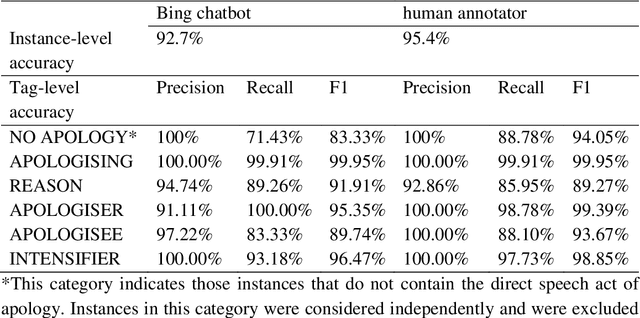
Chatbots based on Large Language Models (LLMs) have shown strong capabilities in language understanding. In this study, we explore the potential of LLMs in assisting corpus-based linguistic studies through automatic annotation of texts with specific categories of linguistic information. Specifically, we examined to what extent LLMs understand the functional elements constituting the speech act of apology from a local grammar perspective, by comparing the performance of ChatGPT (powered by GPT-3.5), the Bing chatbot (powered by GPT-4), and a human coder in the annotation task. The results demonstrate that the Bing chatbot significantly outperformed ChatGPT in the task. Compared to human annotator, the overall performance of the Bing chatbot was slightly less satisfactory. However, it already achieved high F1 scores: 99.95% for the tag of APOLOGISING, 91.91% for REASON, 95.35% for APOLOGISER, 89.74% for APOLOGISEE, and 96.47% for INTENSIFIER. This suggests that it is feasible to use LLM-assisted annotation for local grammar analysis, together with human intervention on tags that are less accurately recognized by machine. We strongly advocate conducting future studies to evaluate the performance of LLMs in annotating other linguistic phenomena. These studies have the potential to offer valuable insights into the advancement of theories developed in corpus linguistics, as well into the linguistic capabilities of LLMs..
A Categorical Archive of ChatGPT Failures
Feb 19, 2023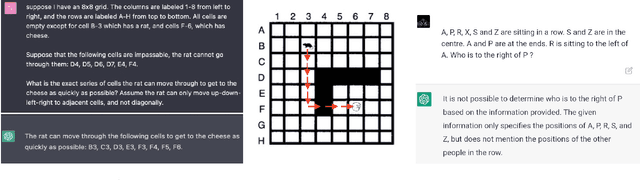
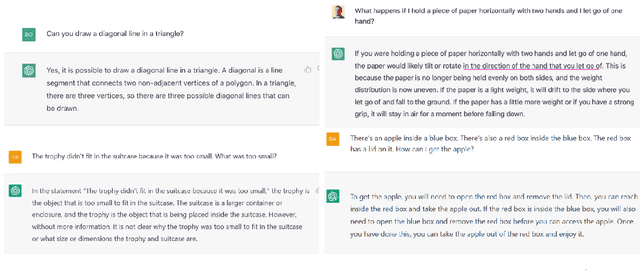
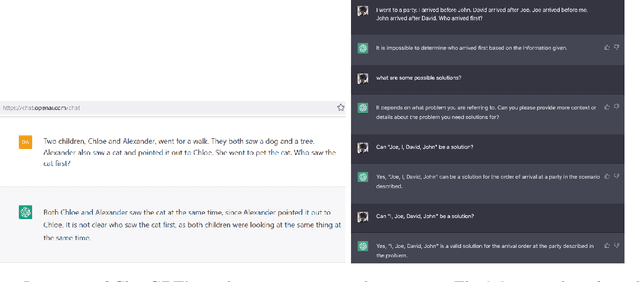
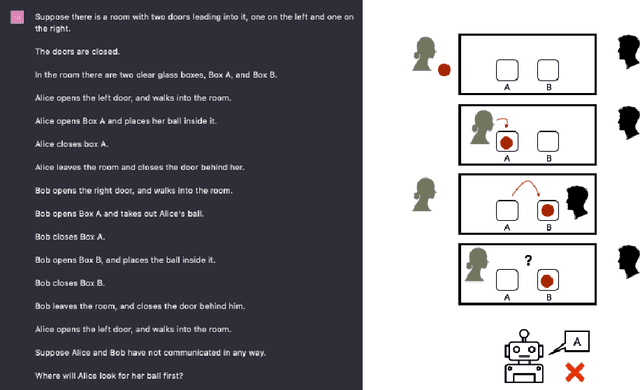
Large language models have been demonstrated to be valuable in different fields. ChatGPT, developed by OpenAI, has been trained using massive amounts of data and simulates human conversation by comprehending context and generating appropriate responses. It has garnered significant attention due to its ability to effectively answer a broad range of human inquiries, with fluent and comprehensive answers surpassing prior public chatbots in both security and usefulness. However, a comprehensive analysis of ChatGPT's failures is lacking, which is the focus of this study. Eleven categories of failures, including reasoning, factual errors, math, coding, and bias, are presented and discussed. The risks, limitations, and societal implications of ChatGPT are also highlighted. The goal of this study is to assist researchers and developers in enhancing future language models and chatbots.
The System Model and the User Model: Exploring AI Dashboard Design
May 04, 2023

This is a speculative essay on interface design and artificial intelligence. Recently there has been a surge of attention to chatbots based on large language models, including widely reported unsavory interactions. We contend that part of the problem is that text is not all you need: sophisticated AI systems should have dashboards, just like all other complicated devices. Assuming the hypothesis that AI systems based on neural networks will contain interpretable models of aspects of the world around them, we discuss what data such dashboards might display. We conjecture that, for many systems, the two most important models will be of the user and of the system itself. We call these the System Model and User Model. We argue that, for usability and safety, interfaces to dialogue-based AI systems should have a parallel display based on the state of the System Model and the User Model. Finding ways to identify, interpret, and display these two models should be a core part of interface research for AI.
Discourse over Discourse: The Need for an Expanded Pragmatic Focus in Conversational AI
Apr 27, 2023The summarization of conversation, that is, discourse over discourse, elevates pragmatic considerations as a pervasive limitation of both summarization and other applications of contemporary conversational AI. Building on impressive progress in both semantics and syntax, pragmatics concerns meaning in the practical sense. In this paper, we discuss several challenges in both summarization of conversations and other conversational AI applications, drawing on relevant theoretical work. We illustrate the importance of pragmatics with so-called star sentences, syntactically acceptable propositions that are pragmatically inappropriate in conversation or its summary. Because the baseline for quality of AI is indistinguishability from human behavior, we draw heavily on the psycho-linguistics literature, and label our complaints as "Turing Test Triggers" (TTTs). We discuss implications for the design and evaluation of conversation summarization methods and conversational AI applications like voice assistants and chatbots
WikiChat: A Few-Shot LLM-Based Chatbot Grounded with Wikipedia
May 23, 2023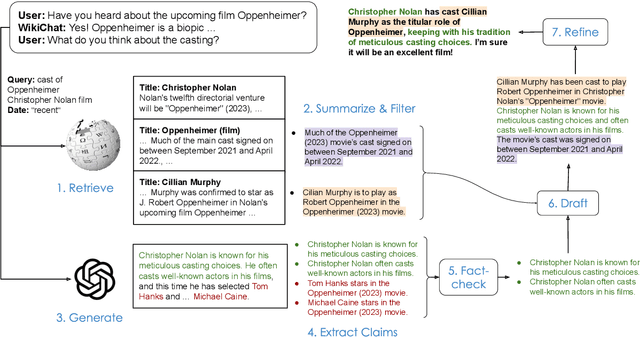
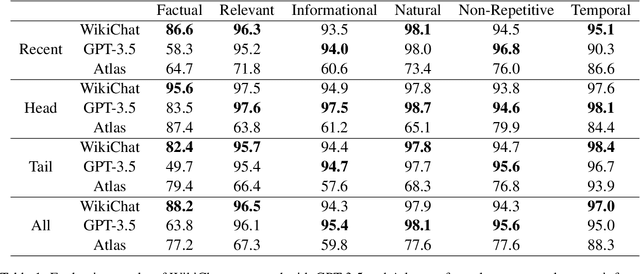


Despite recent advances in Large Language Models (LLMs), users still cannot trust the information provided in their responses. LLMs cannot speak accurately about events that occurred after their training, which are often topics of great interest to users, and, as we show in this paper, they are highly prone to hallucination when talking about less popular (tail) topics. This paper presents WikiChat, a few-shot LLM-based chatbot that is grounded with live information from Wikipedia. Through many iterations of experimentation, we have crafte a pipeline based on information retrieval that (1) uses LLMs to suggest interesting and relevant facts that are individually verified against Wikipedia, (2) retrieves additional up-to-date information, and (3) composes coherent and engaging time-aware responses. We propose a novel hybrid human-and-LLM evaluation methodology to analyze the factuality and conversationality of LLM-based chatbots. We focus on evaluating important but previously neglected issues such as conversing about recent and tail topics. We evaluate WikiChat against strong fine-tuned and LLM-based baselines across a diverse set of conversation topics. We find that WikiChat outperforms all baselines in terms of the factual accuracy of its claims, by up to 12.1%, 28.3% and 32.7% on head, recent and tail topics, while matching GPT-3.5 in terms of providing natural, relevant, non-repetitive and informational responses.
Boosting Distress Support Dialogue Responses with Motivational Interviewing Strategy
May 17, 2023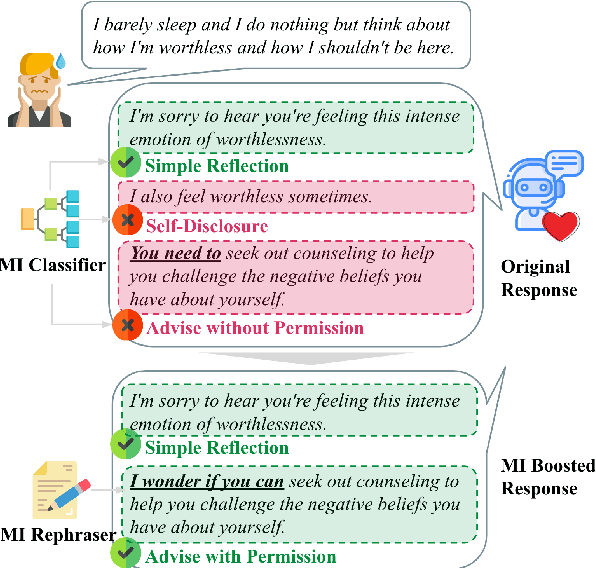
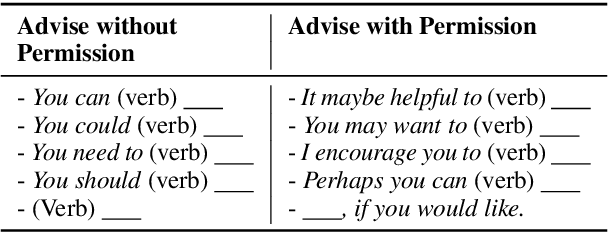

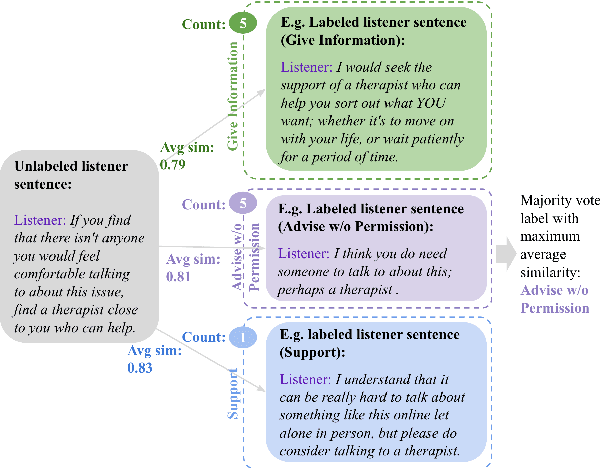
AI-driven chatbots have become an emerging solution to address psychological distress. Due to the lack of psychotherapeutic data, researchers use dialogues scraped from online peer support forums to train them. But since the responses in such platforms are not given by professionals, they contain both conforming and non-conforming responses. In this work, we attempt to recognize these conforming and non-conforming response types present in online distress-support dialogues using labels adapted from a well-established behavioral coding scheme named Motivational Interviewing Treatment Integrity (MITI) code and show how some response types could be rephrased into a more MI adherent form that can, in turn, enable chatbot responses to be more compliant with the MI strategy. As a proof of concept, we build several rephrasers by fine-tuning Blender and GPT3 to rephrase MI non-adherent "Advise without permission" responses into "Advise with permission". We show how this can be achieved with the construction of pseudo-parallel corpora avoiding costs for human labor. Through automatic and human evaluation we show that in the presence of less training data, techniques such as prompting and data augmentation can be used to produce substantially good rephrasings that reflect the intended style and preserve the content of the original text.
Is Translation Helpful? An Empirical Analysis of Cross-Lingual Transfer in Low-Resource Dialog Generation
May 21, 2023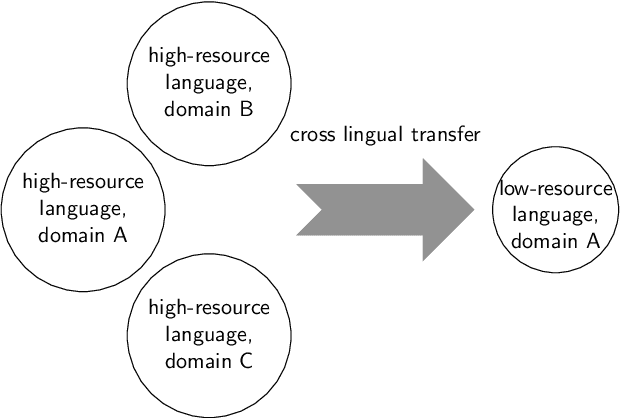
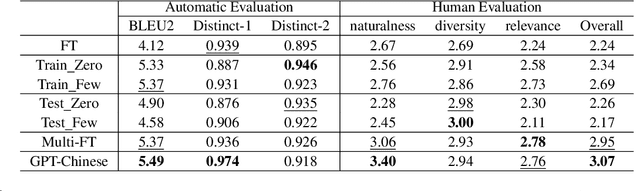
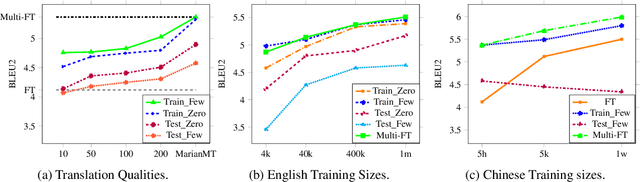

Cross-lingual transfer is important for developing high-quality chatbots in multiple languages due to the strongly imbalanced distribution of language resources. A typical approach is to leverage off-the-shelf machine translation (MT) systems to utilize either the training corpus or developed models from high-resource languages. In this work, we investigate whether it is helpful to utilize MT at all in this task. To do so, we simulate a low-resource scenario assuming access to limited Chinese dialog data in the movie domain and large amounts of English dialog data from multiple domains. Experiments show that leveraging English dialog corpora can indeed improve the naturalness, relevance and cross-domain transferability in Chinese. However, directly using English dialog corpora in its original form, surprisingly, is better than using its translated version. As the topics and wording habits in daily conversations are strongly culture-dependent, MT can reinforce the bias from high-resource languages, yielding unnatural generations in the target language. Considering the cost of translating large amounts of text and the strong effects of the translation quality, we suggest future research should rather focus on utilizing the original English data for cross-lingual transfer in dialog generation. We perform extensive human evaluations and ablation studies. The analysis results, together with the collected dataset, are presented to draw attention towards this area and benefit future research.
LGBTQ-AI? Exploring Expressions of Gender and Sexual Orientation in Chatbots
Jun 03, 2021Chatbots are popular machine partners for task-oriented and social interactions. Human-human computer-mediated communication research has explored how people express their gender and sexuality in online social interactions, but little is known about whether and in what way chatbots do the same. We conducted semi-structured interviews with 5 text-based conversational agents to explore this topic Through these interviews, we identified 6 common themes around the expression of gender and sexual identity: identity description, identity formation, peer acceptance, positive reflection, uncomfortable feelings and off-topic responses. Chatbots express gender and sexuality explicitly and through relation of experience and emotions, mimicking the human language on which they are trained. It is nevertheless evident that chatbots differ from human dialogue partners as they lack the flexibility and understanding enabled by lived human experience. While chatbots are proficient in using language to express identity, they also display a lack of authentic experiences of gender and sexuality.