 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
Cases of EFL Secondary Students' Prompt Engineering Pathways to Complete a Writing Task with ChatGPT
Jun 19, 2023
ChatGPT is a state-of-the-art (SOTA) chatbot. Although it has potential to support English as a foreign language (EFL) students' writing, to effectively collaborate with it, a student must learn to engineer prompts, that is, the skill of crafting appropriate instructions so that ChatGPT produces desired outputs. However, writing an appropriate prompt for ChatGPT is not straightforward for non-technical users who suffer a trial-and-error process. This paper examines the content of EFL students' ChatGPT prompts when completing a writing task and explores patterns in the quality and quantity of the prompts. The data come from iPad screen recordings of secondary school EFL students who used ChatGPT and other SOTA chatbots for the first time to complete the same writing task. The paper presents a case study of four distinct pathways that illustrate the trial-and-error process and show different combinations of prompt content and quantity. The cases contribute evidence for the need to provide prompt engineering education in the context of the EFL writing classroom, if students are to move beyond an individual trial-and-error process, learning a greater variety of prompt content and more sophisticated prompts to support their writing.
Prompted LLMs as Chatbot Modules for Long Open-domain Conversation
May 08, 2023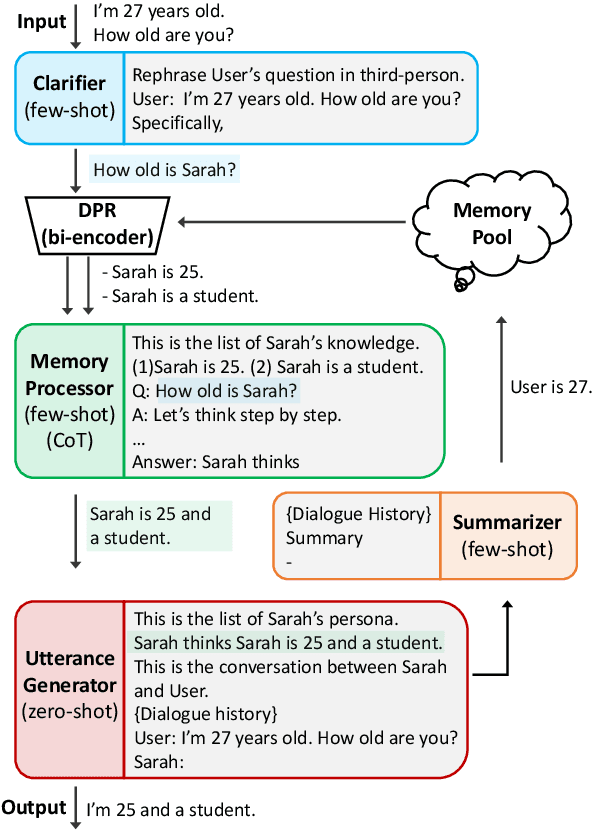
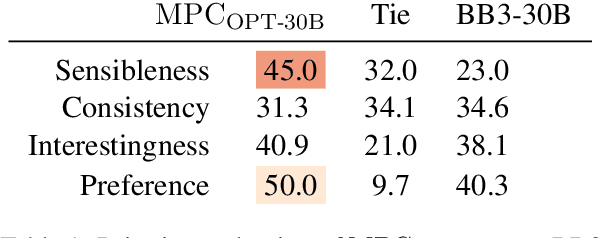
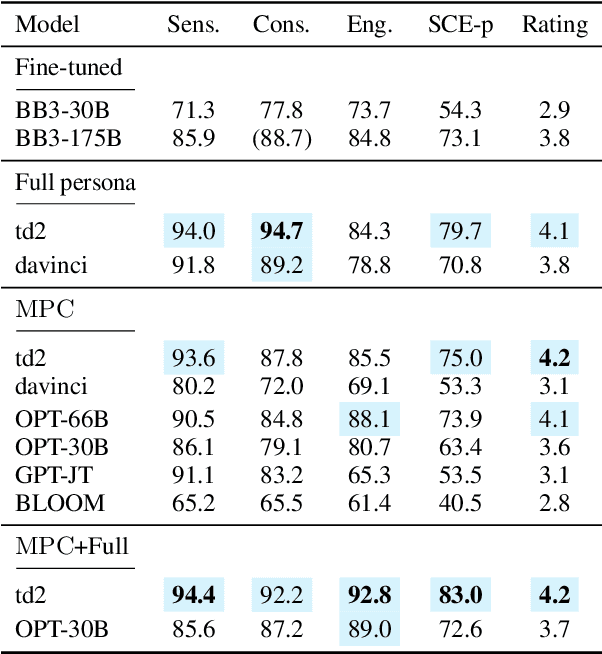
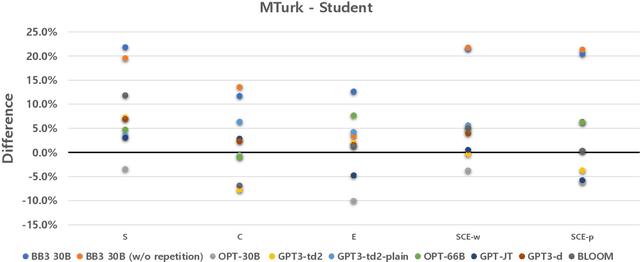
In this paper, we propose MPC (Modular Prompted Chatbot), a new approach for creating high-quality conversational agents without the need for fine-tuning. Our method utilizes pre-trained large language models (LLMs) as individual modules for long-term consistency and flexibility, by using techniques such as few-shot prompting, chain-of-thought (CoT), and external memory. Our human evaluation results show that MPC is on par with fine-tuned chatbot models in open-domain conversations, making it an effective solution for creating consistent and engaging chatbots.
CheerBots: Chatbots toward Empathy and Emotionusing Reinforcement Learning
Oct 08, 2021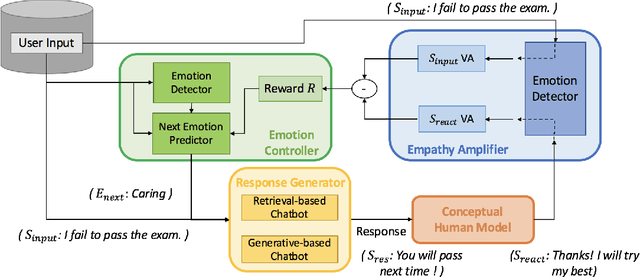
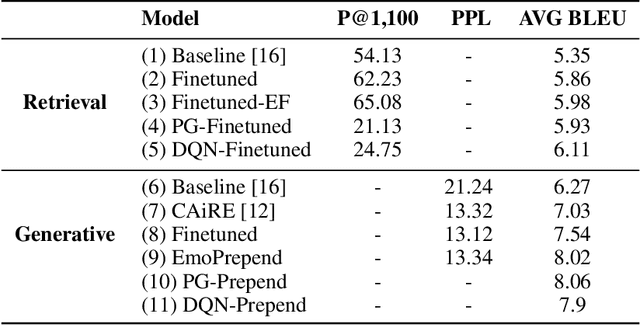
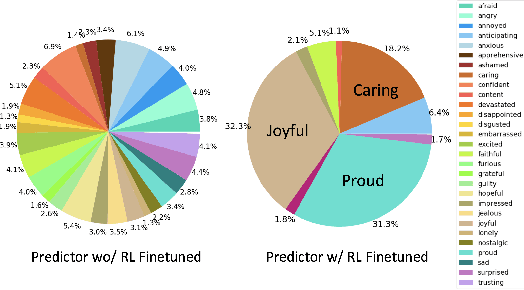
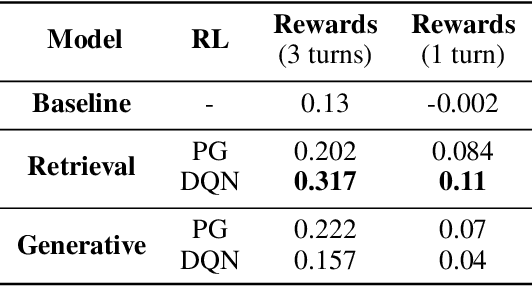
Apart from the coherence and fluency of responses, an empathetic chatbot emphasizes more on people's feelings. By considering altruistic behaviors between human interaction, empathetic chatbots enable people to get a better interactive and supportive experience. This study presents a framework whereby several empathetic chatbots are based on understanding users' implied feelings and replying empathetically for multiple dialogue turns. We call these chatbots CheerBots. CheerBots can be retrieval-based or generative-based and were finetuned by deep reinforcement learning. To respond in an empathetic way, we develop a simulating agent, a Conceptual Human Model, as aids for CheerBots in training with considerations on changes in user's emotional states in the future to arouse sympathy. Finally, automatic metrics and human rating results demonstrate that CheerBots outperform other baseline chatbots and achieves reciprocal altruism. The code and the pre-trained models will be made available.
Which Argumentative Aspects of Hate Speech in Social Media can be reliably identified?
Jun 05, 2023

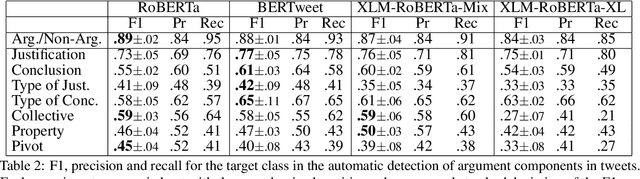
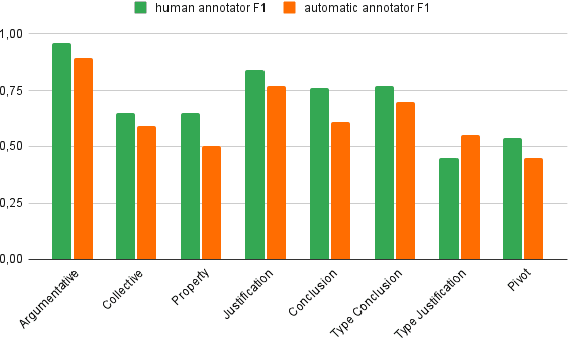
With the increasing diversity of use cases of large language models, a more informative treatment of texts seems necessary. An argumentative analysis could foster a more reasoned usage of chatbots, text completion mechanisms or other applications. However, it is unclear which aspects of argumentation can be reliably identified and integrated in language models. In this paper, we present an empirical assessment of the reliability with which different argumentative aspects can be automatically identified in hate speech in social media. We have enriched the Hateval corpus (Basile et al. 2019) with a manual annotation of some argumentative components, adapted from Wagemans (2016)'s Periodic Table of Arguments. We show that some components can be identified with reasonable reliability. For those that present a high error ratio, we analyze the patterns of disagreement between expert annotators and errors in automatic procedures, and we propose adaptations of those categories that can be more reliably reproduced.
Lost in Translation: Large Language Models in Non-English Content Analysis
Jun 12, 2023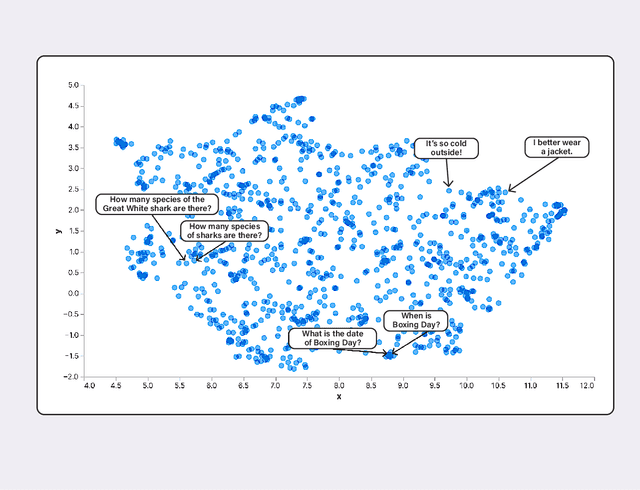
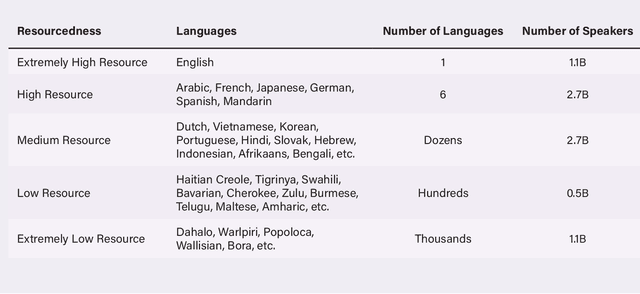
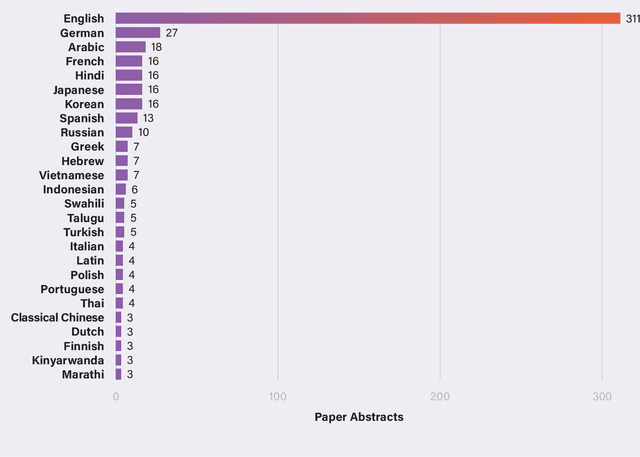
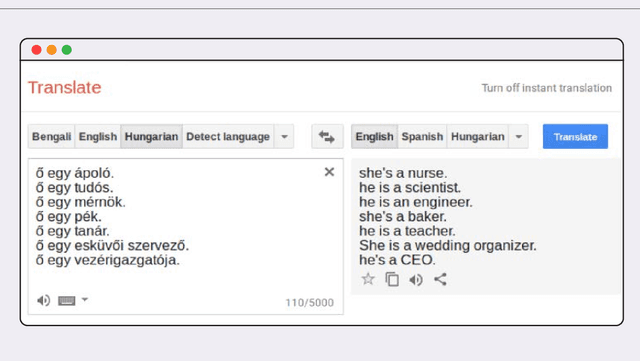
In recent years, large language models (e.g., Open AI's GPT-4, Meta's LLaMa, Google's PaLM) have become the dominant approach for building AI systems to analyze and generate language online. However, the automated systems that increasingly mediate our interactions online -- such as chatbots, content moderation systems, and search engines -- are primarily designed for and work far more effectively in English than in the world's other 7,000 languages. Recently, researchers and technology companies have attempted to extend the capabilities of large language models into languages other than English by building what are called multilingual language models. In this paper, we explain how these multilingual language models work and explore their capabilities and limits. Part I provides a simple technical explanation of how large language models work, why there is a gap in available data between English and other languages, and how multilingual language models attempt to bridge that gap. Part II accounts for the challenges of doing content analysis with large language models in general and multilingual language models in particular. Part III offers recommendations for companies, researchers, and policymakers to keep in mind when considering researching, developing and deploying large and multilingual language models.
Learning to Prompt in the Classroom to Understand AI Limits: A pilot study
Jul 04, 2023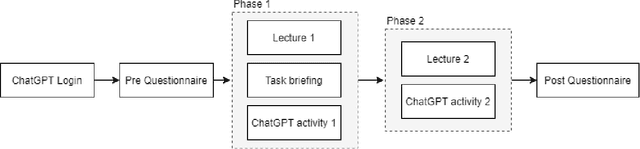
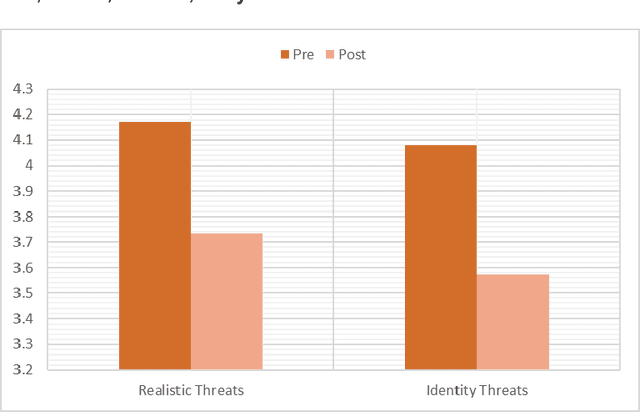
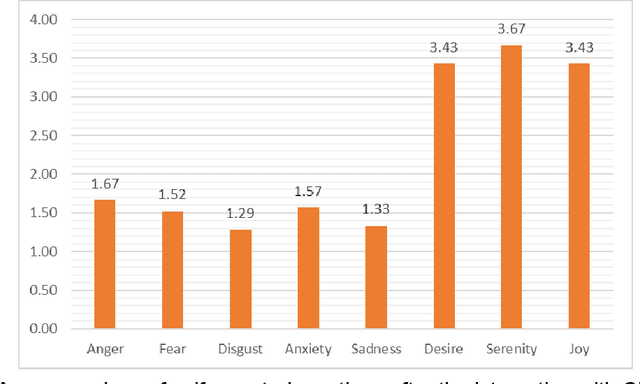
Artificial intelligence's progress holds great promise in assisting society in addressing pressing societal issues. In particular Large Language Models (LLM) and the derived chatbots, like ChatGPT, have highly improved the natural language processing capabilities of AI systems allowing them to process an unprecedented amount of unstructured data. The consequent hype has also backfired, raising negative sentiment even after novel AI methods' surprising contributions. One of the causes, but also an important issue per se, is the rising and misleading feeling of being able to access and process any form of knowledge to solve problems in any domain with no effort or previous expertise in AI or problem domain, disregarding current LLMs limits, such as hallucinations and reasoning limits. Acknowledging AI fallibility is crucial to address the impact of dogmatic overconfidence in possibly erroneous suggestions generated by LLMs. At the same time, it can reduce fear and other negative attitudes toward AI. AI literacy interventions are necessary that allow the public to understand such LLM limits and learn how to use them in a more effective manner, i.e. learning to "prompt". With this aim, a pilot educational intervention was performed in a high school with 30 students. It involved (i) presenting high-level concepts about intelligence, AI, and LLM, (ii) an initial naive practice with ChatGPT in a non-trivial task, and finally (iii) applying currently-accepted prompting strategies. Encouraging preliminary results have been collected such as students reporting a) high appreciation of the activity, b) improved quality of the interaction with the LLM during the educational activity, c) decreased negative sentiments toward AI, d) increased understanding of limitations and specifically We aim to study factors that impact AI acceptance and to refine and repeat this activity in more controlled settings.
Generative AI: Implications and Applications for Education
May 22, 2023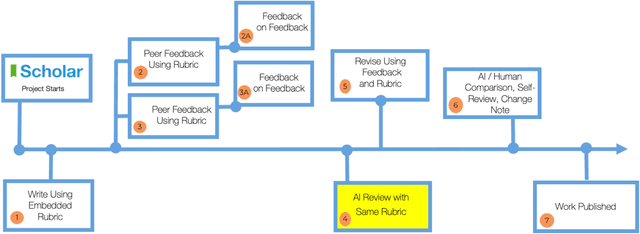
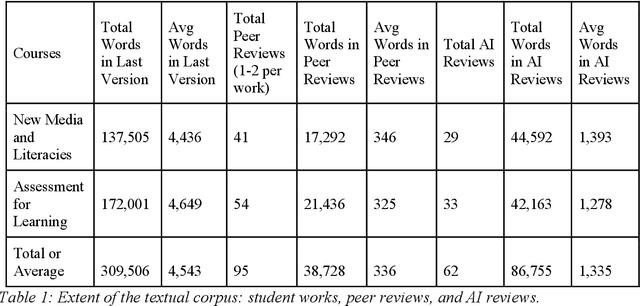
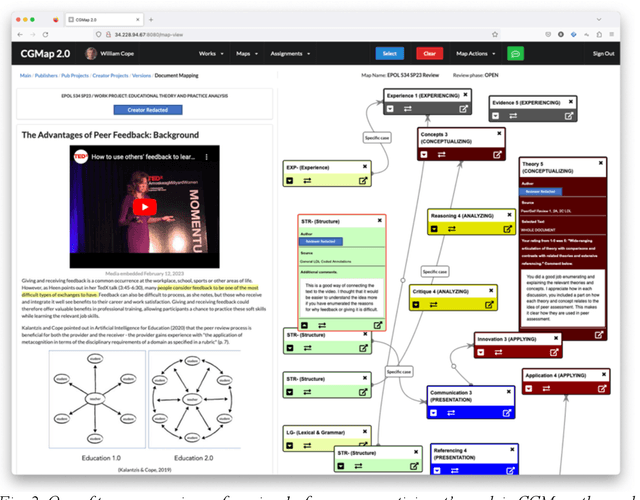
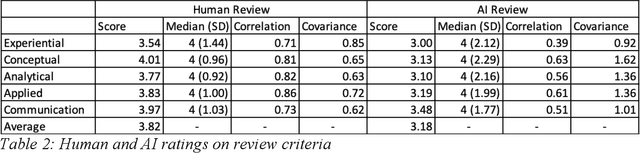
The launch of ChatGPT in November 2022 precipitated a panic among some educators while prompting qualified enthusiasm from others. Under the umbrella term Generative AI, ChatGPT is an example of a range of technologies for the delivery of computer-generated text, image, and other digitized media. This paper examines the implications for education of one generative AI technology, chatbots responding from large language models, or C-LLM. It reports on an application of a C-LLM to AI review and assessment of complex student work. In a concluding discussion, the paper explores the intrinsic limits of generative AI, bound as it is to language corpora and their textual representation through binary notation. Within these limits, we suggest the range of emerging and potential applications of Generative AI in education.
Observations on LLMs for Telecom Domain: Capabilities and Limitations
May 22, 2023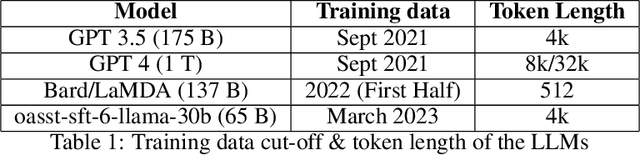
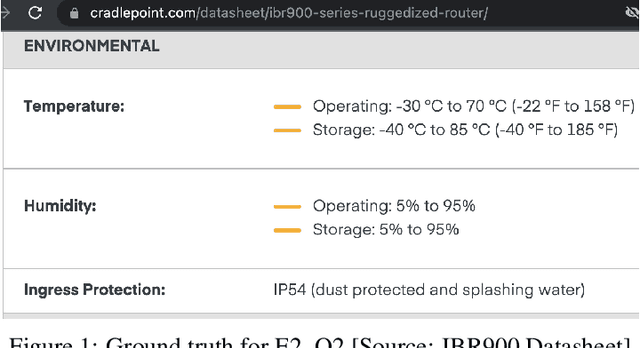


The landscape for building conversational interfaces (chatbots) has witnessed a paradigm shift with recent developments in generative Artificial Intelligence (AI) based Large Language Models (LLMs), such as ChatGPT by OpenAI (GPT3.5 and GPT4), Google's Bard, Large Language Model Meta AI (LLaMA), among others. In this paper, we analyze capabilities and limitations of incorporating such models in conversational interfaces for the telecommunication domain, specifically for enterprise wireless products and services. Using Cradlepoint's publicly available data for our experiments, we present a comparative analysis of the responses from such models for multiple use-cases including domain adaptation for terminology and product taxonomy, context continuity, robustness to input perturbations and errors. We believe this evaluation would provide useful insights to data scientists engaged in building customized conversational interfaces for domain-specific requirements.
PersonaLLM: Investigating the Ability of GPT-3.5 to Express Personality Traits and Gender Differences
May 04, 2023
Despite the many use cases for large language models (LLMs) in the design of chatbots in various industries and the research showing the importance of personalizing chatbots to cater to different personality traits, little work has been done to evaluate whether the behaviors of personalized LLMs can reflect certain personality traits accurately and consistently. We consider studying the behavior of LLM-based simulated agents which refer to as LLM personas and present a case study with GPT-3.5 (text-davinci-003) to investigate whether LLMs can generate content with consistent, personalized traits when assigned Big Five personality types and gender roles. We created 320 LLM personas (5 females and 5 males for each of the 32 Big Five personality types) and prompted them to complete the classic 44-item Big Five Inventory (BFI) and then write an 800-word story about their childhood. Results showed that LLM personas' self-reported BFI scores are consistent with their assigned personality types, with large effect sizes found on all five traits. Moreover, significant correlations were found between assigned personality types and some Linguistic Inquiry and Word Count (LIWC) psycholinguistic features of their writings. For instance, extroversion is associated with pro-social and active words, and neuroticism is associated with words related to negative emotions and mental health. Besides, we only found significant differences in using technological and cultural words in writing between LLM-generated female and male personas. This work provides a first step for further research on personalized LLMs and their applications in Human-AI conversation.
Towards Cognitive Bots: Architectural Research Challenges
May 26, 2023Software bots operating in multiple virtual digital platforms must understand the platforms' affordances and behave like human users. Platform affordances or features differ from one application platform to another or through a life cycle, requiring such bots to be adaptable. Moreover, bots in such platforms could cooperate with humans or other software agents for work or to learn specific behavior patterns. However, present-day bots, particularly chatbots, other than language processing and prediction, are far from reaching a human user's behavior level within complex business information systems. They lack the cognitive capabilities to sense and act in such virtual environments, rendering their development a challenge to artificial general intelligence research. In this study, we problematize and investigate assumptions in conceptualizing software bot architecture by directing attention to significant architectural research challenges in developing cognitive bots endowed with complex behavior for operation on information systems. As an outlook, we propose alternate architectural assumptions to consider in future bot design and bot development frameworks.