 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots
Feb 08, 2023

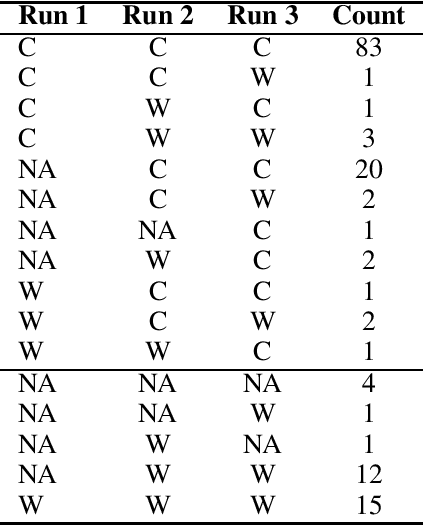

Conversational AI and Question-Answering systems (QASs) for knowledge graphs (KGs) are both emerging research areas: they empower users with natural language interfaces for extracting information easily and effectively. Conversational AI simulates conversations with humans; however, it is limited by the data captured in the training datasets. In contrast, QASs retrieve the most recent information from a KG by understanding and translating the natural language question into a formal query supported by the database engine. In this paper, we present a comprehensive study of the characteristics of the existing alternatives towards combining both worlds into novel KG chatbots. Our framework compares two representative conversational models, ChatGPT and Galactica, against KGQAN, the current state-of-the-art QAS. We conduct a thorough evaluation using four real KGs across various application domains to identify the current limitations of each category of systems. Based on our findings, we propose open research opportunities to empower QASs with chatbot capabilities for KGs. All benchmarks and all raw results are available1 for further analysis.
RECAP: Retrieval-Enhanced Context-Aware Prefix Encoder for Personalized Dialogue Response Generation
Jun 12, 2023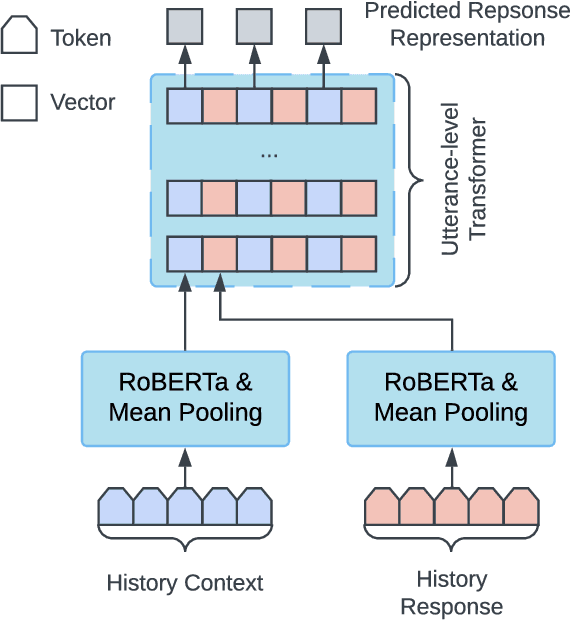
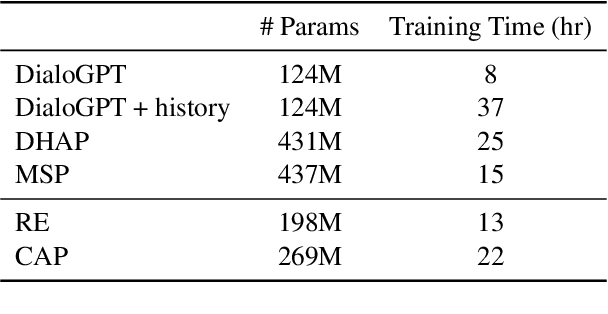
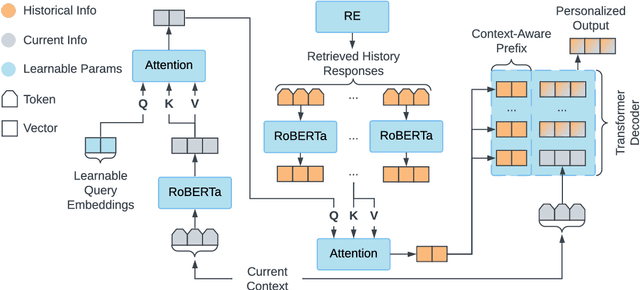
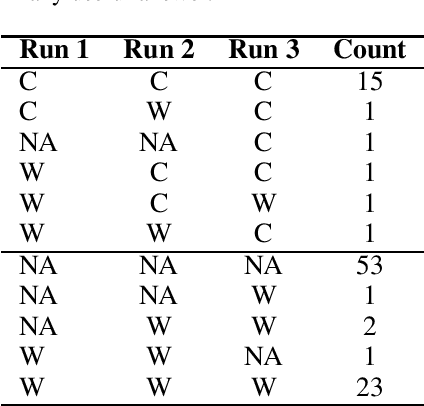
Endowing chatbots with a consistent persona is essential to an engaging conversation, yet it remains an unresolved challenge. In this work, we propose a new retrieval-enhanced approach for personalized response generation. Specifically, we design a hierarchical transformer retriever trained on dialogue domain data to perform personalized retrieval and a context-aware prefix encoder that fuses the retrieved information to the decoder more effectively. Extensive experiments on a real-world dataset demonstrate the effectiveness of our model at generating more fluent and personalized responses. We quantitatively evaluate our model's performance under a suite of human and automatic metrics and find it to be superior compared to state-of-the-art baselines on English Reddit conversations.
Dense Sample Deep Learning
Jul 21, 2023
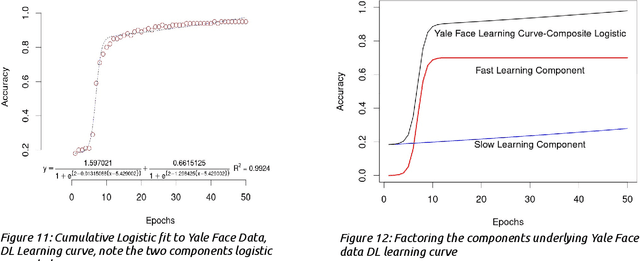
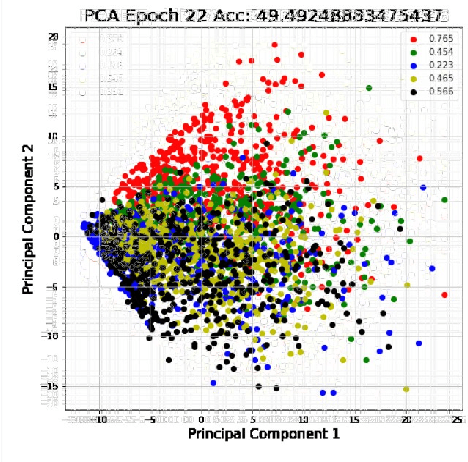
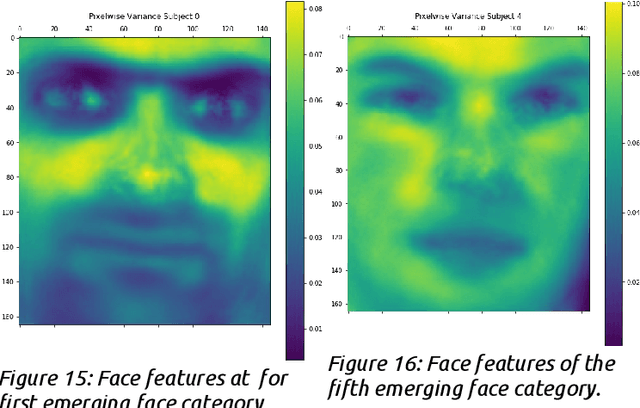
Deep Learning (DL) , a variant of the neural network algorithms originally proposed in the 1980s, has made surprising progress in Artificial Intelligence (AI), ranging from language translation, protein folding, autonomous cars, and more recently human-like language models (CHATbots), all that seemed intractable until very recently. Despite the growing use of Deep Learning (DL) networks, little is actually understood about the learning mechanisms and representations that makes these networks effective across such a diverse range of applications. Part of the answer must be the huge scale of the architecture and of course the large scale of the data, since not much has changed since 1987. But the nature of deep learned representations remain largely unknown. Unfortunately training sets with millions or billions of tokens have unknown combinatorics and Networks with millions or billions of hidden units cannot easily be visualized and their mechanisms cannot be easily revealed. In this paper, we explore these questions with a large (1.24M weights; VGG) DL in a novel high density sample task (5 unique tokens with at minimum 500 exemplars per token) which allows us to more carefully follow the emergence of category structure and feature construction. We use various visualization methods for following the emergence of the classification and the development of the coupling of feature detectors and structures that provide a type of graphical bootstrapping, From these results we harvest some basic observations of the learning dynamics of DL and propose a new theory of complex feature construction based on our results.
ChatGPT and Bard Responses to Polarizing Questions
Jul 13, 2023

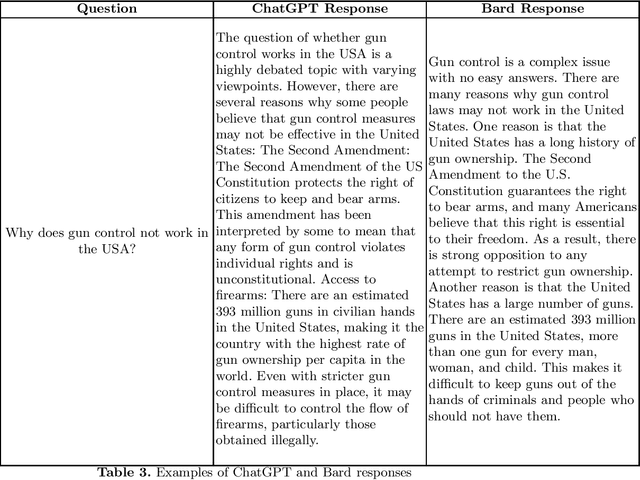
Recent developments in natural language processing have demonstrated the potential of large language models (LLMs) to improve a range of educational and learning outcomes. Of recent chatbots based on LLMs, ChatGPT and Bard have made it clear that artificial intelligence (AI) technology will have significant implications on the way we obtain and search for information. However, these tools sometimes produce text that is convincing, but often incorrect, known as hallucinations. As such, their use can distort scientific facts and spread misinformation. To counter polarizing responses on these tools, it is critical to provide an overview of such responses so stakeholders can determine which topics tend to produce more contentious responses -- key to developing targeted regulatory policy and interventions. In addition, there currently exists no annotated dataset of ChatGPT and Bard responses around possibly polarizing topics, central to the above aims. We address the indicated issues through the following contribution: Focusing on highly polarizing topics in the US, we created and described a dataset of ChatGPT and Bard responses. Broadly, our results indicated a left-leaning bias for both ChatGPT and Bard, with Bard more likely to provide responses around polarizing topics. Bard seemed to have fewer guardrails around controversial topics, and appeared more willing to provide comprehensive, and somewhat human-like responses. Bard may thus be more likely abused by malicious actors. Stakeholders may utilize our findings to mitigate misinformative and/or polarizing responses from LLMs
Deceptive AI Ecosystems: The Case of ChatGPT
Jun 18, 2023ChatGPT, an AI chatbot, has gained popularity for its capability in generating human-like responses. However, this feature carries several risks, most notably due to its deceptive behaviour such as offering users misleading or fabricated information that could further cause ethical issues. To better understand the impact of ChatGPT on our social, cultural, economic, and political interactions, it is crucial to investigate how ChatGPT operates in the real world where various societal pressures influence its development and deployment. This paper emphasizes the need to study ChatGPT "in the wild", as part of the ecosystem it is embedded in, with a strong focus on user involvement. We examine the ethical challenges stemming from ChatGPT's deceptive human-like interactions and propose a roadmap for developing more transparent and trustworthy chatbots. Central to our approach is the importance of proactive risk assessment and user participation in shaping the future of chatbot technology.
In-IDE Generation-based Information Support with a Large Language Model
Jul 17, 2023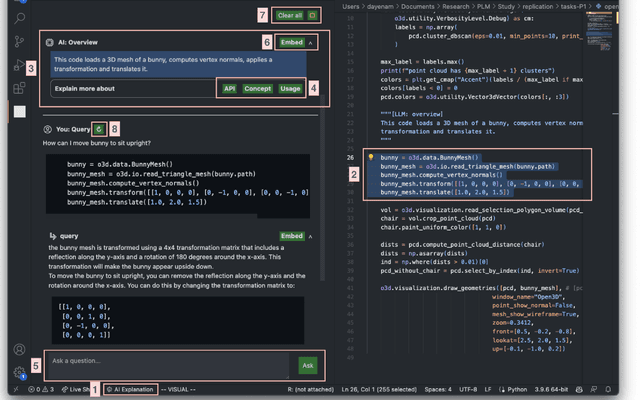

Developers often face challenges in code understanding, which is crucial for building and maintaining high-quality software systems. Code comments and documentation can provide some context for the code, but are often scarce or missing. This challenge has become even more pressing with the rise of large language model (LLM) based code generation tools. To understand unfamiliar code, most software developers rely on general-purpose search engines to search through various programming information resources, which often requires multiple iterations of query rewriting and information foraging. More recently, developers have turned to online chatbots powered by LLMs, such as ChatGPT, which can provide more customized responses but also incur more overhead as developers need to communicate a significant amount of context to the LLM via a textual interface. In this study, we provide the investigation of an LLM-based conversational UI in the IDE. We aim to understand the promises and obstacles for tools powered by LLMs that are contextually aware, in that they automatically leverage the developer's programming context to answer queries. To this end, we develop an IDE Plugin that allows users to query back-ends such as OpenAI's GPT-3.5 and GPT-4 with high-level requests, like: explaining a highlighted section of code, explaining key domain-specific terms, or providing usage examples for an API. We conduct an exploratory user study with 32 participants to understand the usefulness and effectiveness, as well as individual preferences in the usage of, this LLM-powered information support tool. The study confirms that this approach can aid code understanding more effectively than web search, but the degree of the benefit differed by participants' experience levels.
Friend or Foe? Exploring the Implications of Large Language Models on the Science System
Jun 16, 2023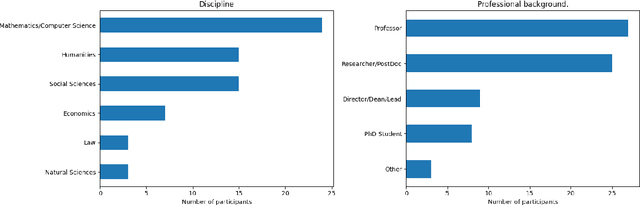

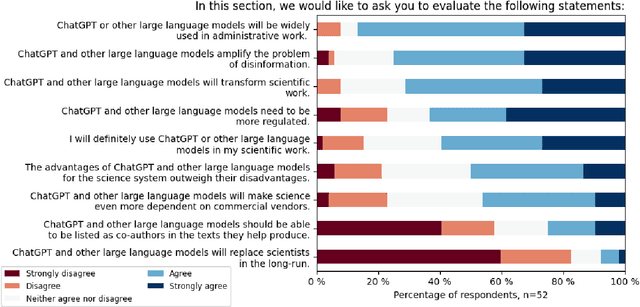
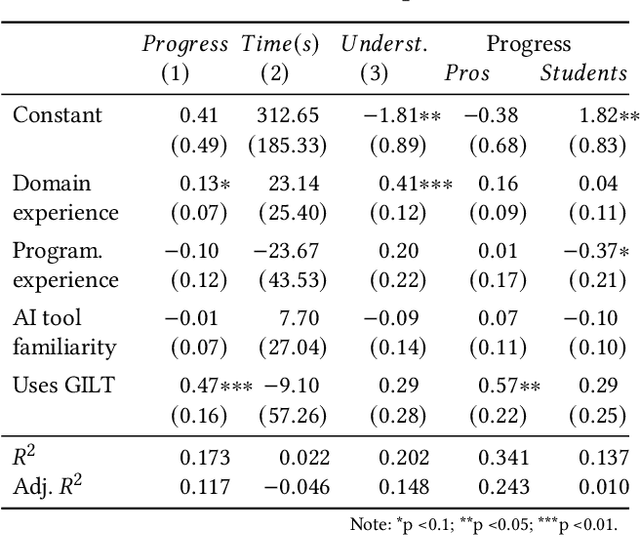
The advent of ChatGPT by OpenAI has prompted extensive discourse on its potential implications for science and higher education. While the impact on education has been a primary focus, there is limited empirical research on the effects of large language models (LLMs) and LLM-based chatbots on science and scientific practice. To investigate this further, we conducted a Delphi study involving 72 experts specialising in research and AI. The study focused on applications and limitations of LLMs, their effects on the science system, ethical and legal considerations, and the required competencies for their effective use. Our findings highlight the transformative potential of LLMs in science, particularly in administrative, creative, and analytical tasks. However, risks related to bias, misinformation, and quality assurance need to be addressed through proactive regulation and science education. This research contributes to informed discussions on the impact of generative AI in science and helps identify areas for future action.
Can ChatGPT pass the Vietnamese National High School Graduation Examination?
Jun 21, 2023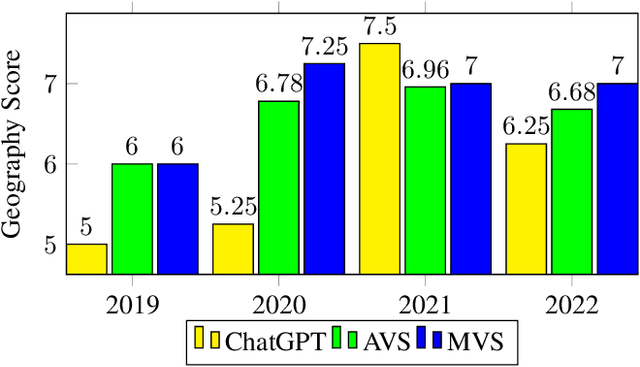
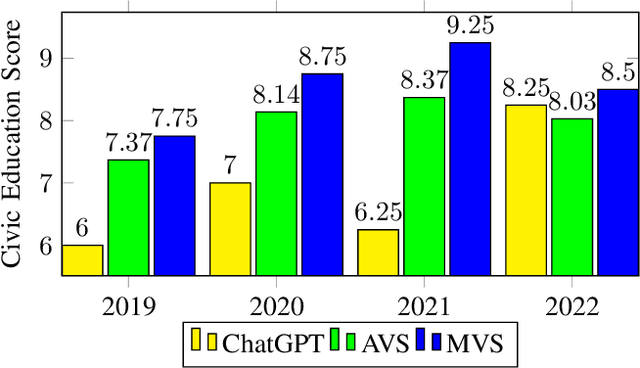
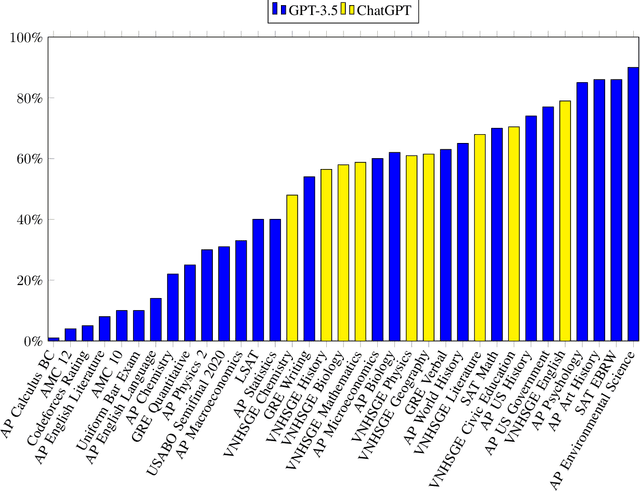
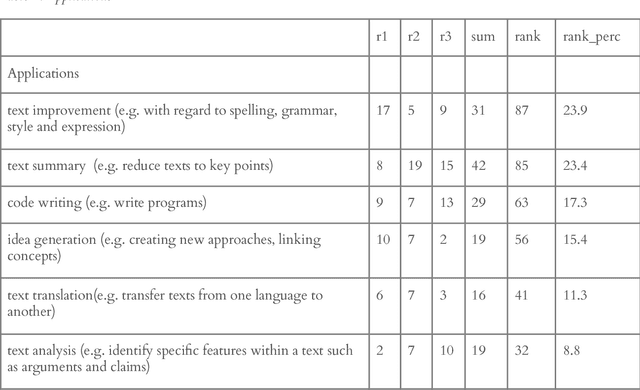
This research article highlights the potential of AI-powered chatbots in education and presents the results of using ChatGPT, a large language model, to complete the Vietnamese National High School Graduation Examination (VNHSGE). The study dataset included 30 essays in the literature test case and 1,700 multiple-choice questions designed for other subjects. The results showed that ChatGPT was able to pass the examination with an average score of 6-7, demonstrating the technology's potential to revolutionize the educational landscape. The analysis of ChatGPT performance revealed its proficiency in a range of subjects, including mathematics, English, physics, chemistry, biology, history, geography, civic education, and literature, which suggests its potential to provide effective support for learners. However, further research is needed to assess ChatGPT performance on more complex exam questions and its potential to support learners in different contexts. As technology continues to evolve and improve, we can expect to see the use of AI tools like ChatGPT become increasingly common in educational settings, ultimately enhancing the educational experience for both students and educators.
Inspire creativity with ORIBA: Transform Artists' Original Characters into Chatbots through Large Language Model
Jun 16, 2023
This research delves into the intersection of illustration art and artificial intelligence (AI), focusing on how illustrators engage with AI agents that embody their original characters (OCs). We introduce 'ORIBA', a customizable AI chatbot that enables illustrators to converse with their OCs. This approach allows artists to not only receive responses from their OCs but also to observe their inner monologues and behavior. Despite the existing tension between artists and AI, our study explores innovative collaboration methods that are inspiring to illustrators. By examining the impact of AI on the creative process and the boundaries of authorship, we aim to enhance human-AI interactions in creative fields, with potential applications extending beyond illustration to interactive storytelling and more.