 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
Appropriateness is all you need!
Apr 27, 2023
The strive to make AI applications "safe" has led to the development of safety-measures as the main or even sole normative requirement of their permissible use. Similar can be attested to the latest version of chatbots, such as chatGPT. In this view, if they are "safe", they are supposed to be permissible to deploy. This approach, which we call "safety-normativity", is rather limited in solving the emerging issues that chatGPT and other chatbots have caused thus far. In answering this limitation, in this paper we argue for limiting chatbots in the range of topics they can chat about according to the normative concept of appropriateness. We argue that rather than looking for "safety" in a chatbot's utterances to determine what they may and may not say, we ought to assess those utterances according to three forms of appropriateness: technical-discursive, social, and moral. We then spell out what requirements for chatbots follow from these forms of appropriateness to avoid the limits of previous accounts: positionality, acceptability, and value alignment (PAVA). With these in mind, we may be able to determine what a chatbot may and may not say. Lastly, one initial suggestion is to use challenge sets, specifically designed for appropriateness, as a validation method.
Assessing the Ability of ChatGPT to Screen Articles for Systematic Reviews
Jul 12, 2023By organizing knowledge within a research field, Systematic Reviews (SR) provide valuable leads to steer research. Evidence suggests that SRs have become first-class artifacts in software engineering. However, the tedious manual effort associated with the screening phase of SRs renders these studies a costly and error-prone endeavor. While screening has traditionally been considered not amenable to automation, the advent of generative AI-driven chatbots, backed with large language models is set to disrupt the field. In this report, we propose an approach to leverage these novel technological developments for automating the screening of SRs. We assess the consistency, classification performance, and generalizability of ChatGPT in screening articles for SRs and compare these figures with those of traditional classifiers used in SR automation. Our results indicate that ChatGPT is a viable option to automate the SR processes, but requires careful considerations from developers when integrating ChatGPT into their SR tools.
InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language
May 11, 2023


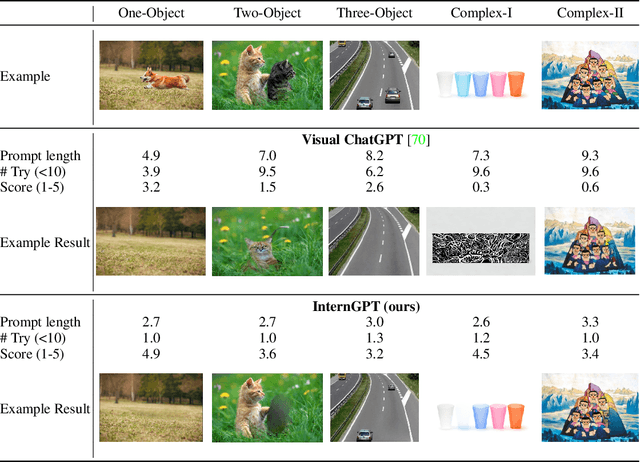
We present an interactive visual framework named InternGPT, or iGPT for short. The framework integrates chatbots that have planning and reasoning capabilities, such as ChatGPT, with non-verbal instructions like pointing movements that enable users to directly manipulate images or videos on the screen. Pointing (including gestures, cursors, etc.) movements can provide more flexibility and precision in performing vision-centric tasks that require fine-grained control, editing, and generation of visual content. The name InternGPT stands for \textbf{inter}action, \textbf{n}onverbal, and \textbf{chat}bots. Different from existing interactive systems that rely on pure language, by incorporating pointing instructions, the proposed iGPT significantly improves the efficiency of communication between users and chatbots, as well as the accuracy of chatbots in vision-centric tasks, especially in complicated visual scenarios where the number of objects is greater than 2. Additionally, in iGPT, an auxiliary control mechanism is used to improve the control capability of LLM, and a large vision-language model termed Husky is fine-tuned for high-quality multi-modal dialogue (impressing ChatGPT-3.5-turbo with 93.89\% GPT-4 Quality). We hope this work can spark new ideas and directions for future interactive visual systems. Welcome to watch the code at https://github.com/OpenGVLab/InternGPT.
A Literature Survey of Recent Advances in Chatbots
Jan 17, 2022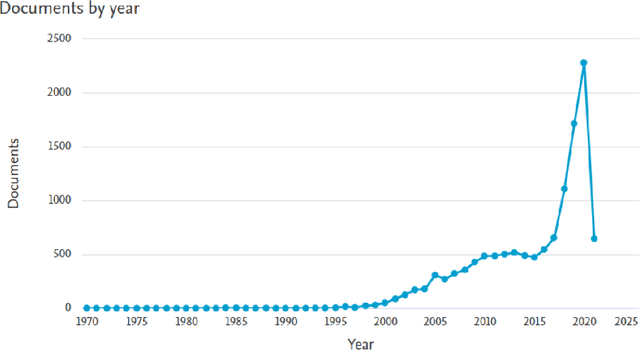
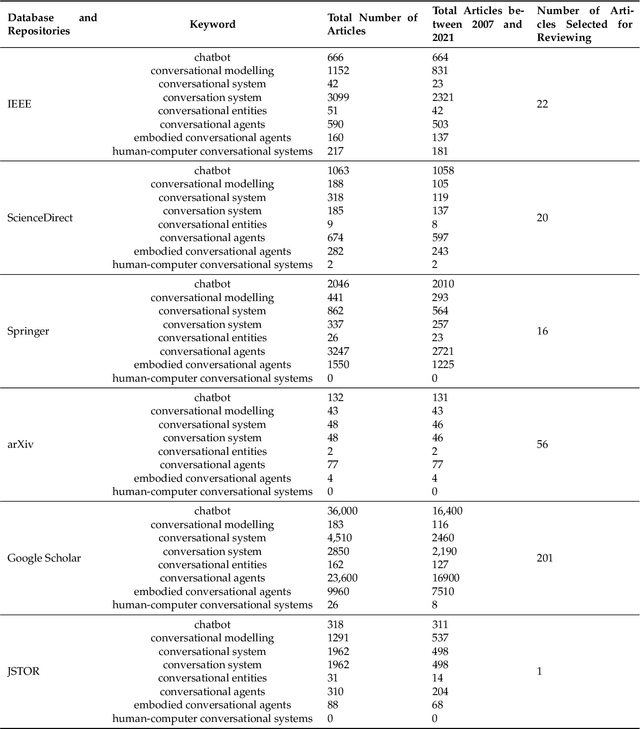
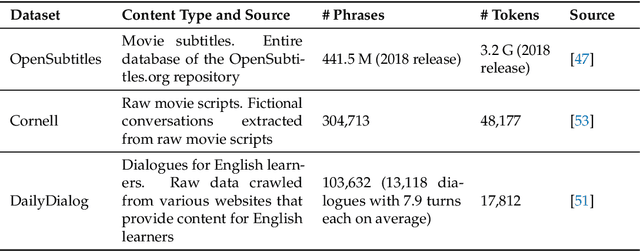
Chatbots are intelligent conversational computer systems designed to mimic human conversation to enable automated online guidance and support. The increased benefits of chatbots led to their wide adoption by many industries in order to provide virtual assistance to customers. Chatbots utilise methods and algorithms from two Artificial Intelligence domains: Natural Language Processing and Machine Learning. However, there are many challenges and limitations in their application. In this survey we review recent advances on chatbots, where Artificial Intelligence and Natural Language processing are used. We highlight the main challenges and limitations of current work and make recommendations for future research investigation.
Chatbot Application to Support Smart Agriculture in Thailand
Jul 31, 2023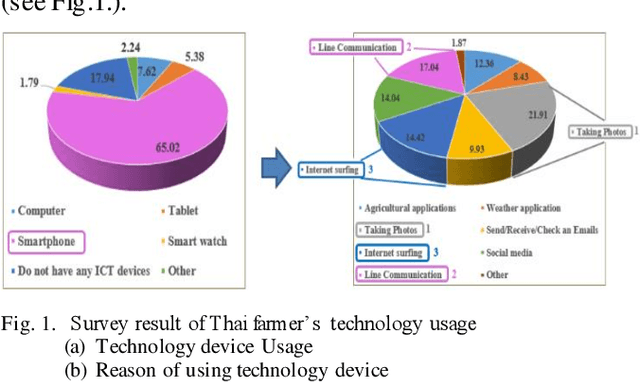
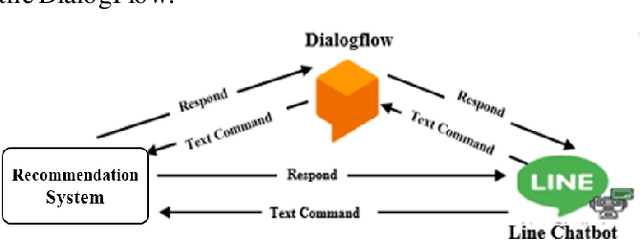
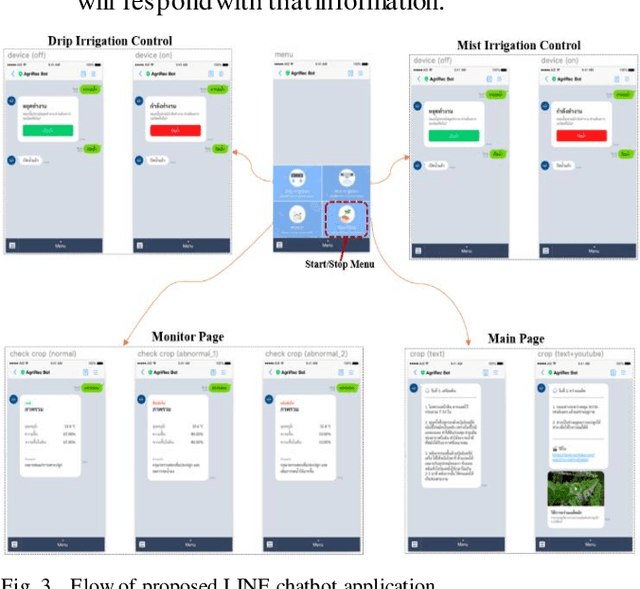
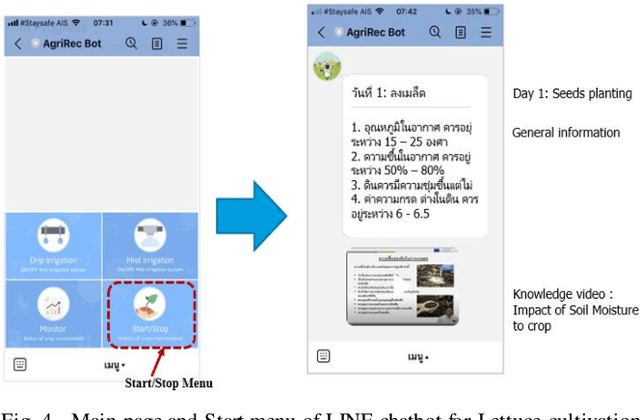
A chatbot is a software developed to help reply to text or voice conversations automatically and quickly in real time. In the agriculture sector, the existing smart agriculture systems just use data from sensing and internet of things (IoT) technologies that exclude crop cultivation knowledge to support decision-making by farmers. To enhance this, the chatbot application can be an assistant to farmers to provide crop cultivation knowledge. Consequently, we propose the LINE chatbot application as an information and knowledge representation providing crop cultivation recommendations to farmers. It works with smart agriculture and recommendation systems. Our proposed LINE chatbot application consists of five main functions (start/stop menu, main page, drip irri gation page, mist irrigation page, and monitor page). Farmers will receive information for data monitoring to support their decision-making. Moreover, they can control the irrigation system via the LINE chatbot. Furthermore, farmers can ask questions relevant to the crop environment via a chat box. After implementing our proposed chatbot, farmers are very satisfied with the application, scoring a 96% satisfaction score. However, in terms of asking questions via chat box, this LINE chatbot application is a rule-based bot or script bot. Farmers have to type in the correct keywords as prescribed, otherwise they won't get a response from the chatbots. In the future, we will enhance the asking function of our LINE chatbot to be an intelligent bot.
How "open" are the conversations with open-domain chatbots? A proposal for Speech Event based evaluation
Nov 24, 2022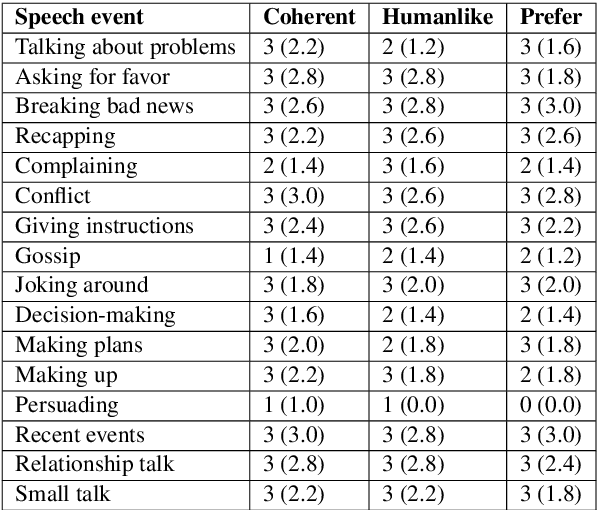
Open-domain chatbots are supposed to converse freely with humans without being restricted to a topic, task or domain. However, the boundaries and/or contents of open-domain conversations are not clear. To clarify the boundaries of "openness", we conduct two studies: First, we classify the types of "speech events" encountered in a chatbot evaluation data set (i.e., Meena by Google) and find that these conversations mainly cover the "small talk" category and exclude the other speech event categories encountered in real life human-human communication. Second, we conduct a small-scale pilot study to generate online conversations covering a wider range of speech event categories between two humans vs. a human and a state-of-the-art chatbot (i.e., Blender by Facebook). A human evaluation of these generated conversations indicates a preference for human-human conversations, since the human-chatbot conversations lack coherence in most speech event categories. Based on these results, we suggest (a) using the term "small talk" instead of "open-domain" for the current chatbots which are not that "open" in terms of conversational abilities yet, and (b) revising the evaluation methods to test the chatbot conversations against other speech events.
Right to be Forgotten in the Era of Large Language Models: Implications, Challenges, and Solutions
Jul 08, 2023


The Right to be Forgotten (RTBF) was first established as the result of the ruling of Google Spain SL, Google Inc. v AEPD, Mario Costeja Gonz\'alez, and was later included as the Right to Erasure under the General Data Protection Regulation (GDPR) of European Union to allow individuals the right to request personal data be deleted by organizations. Specifically for search engines, individuals can send requests to organizations to exclude their information from the query results. With the recent development of Large Language Models (LLMs) and their use in chatbots, LLM-enabled software systems have become popular. But they are not excluded from the RTBF. Compared with the indexing approach used by search engines, LLMs store, and process information in a completely different way. This poses new challenges for compliance with the RTBF. In this paper, we explore these challenges and provide our insights on how to implement technical solutions for the RTBF, including the use of machine unlearning, model editing, and prompting engineering.
Evaluator for Emotionally Consistent Chatbots
Dec 02, 2021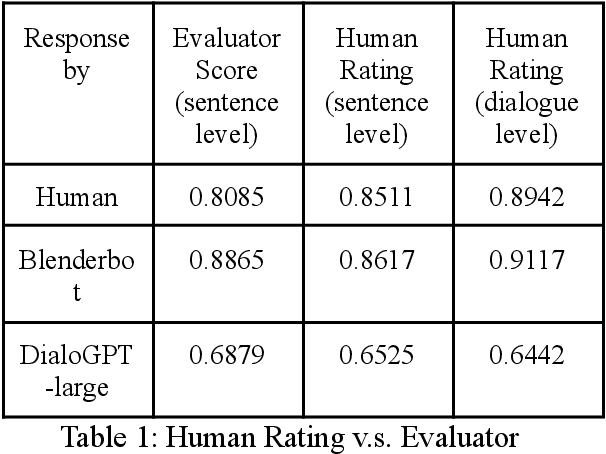
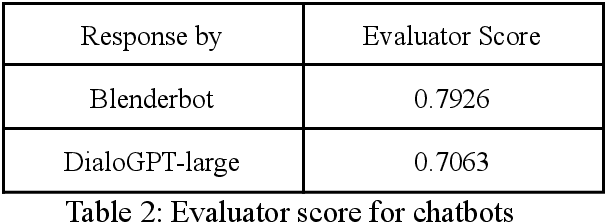

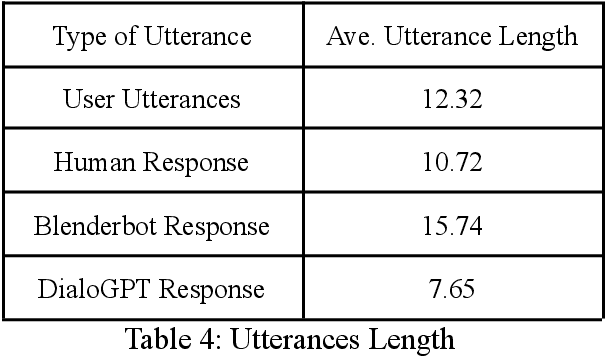
One challenge for evaluating current sequence- or dialogue-level chatbots, such as Empathetic Open-domain Conversation Models, is to determine whether the chatbot performs in an emotionally consistent way. The most recent work only evaluates on the aspects of context coherence, language fluency, response diversity, or logical self-consistency between dialogues. This work proposes training an evaluator to determine the emotional consistency of chatbots.
C-PMI: Conditional Pointwise Mutual Information for Turn-level Dialogue Evaluation
Jun 27, 2023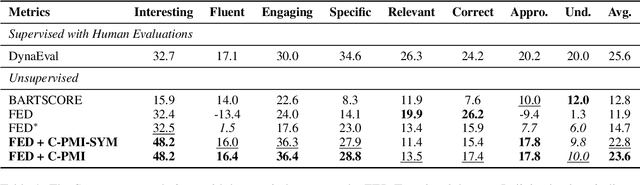
Existing reference-free turn-level evaluation metrics for chatbots inadequately capture the interaction between the user and the system. Consequently, they often correlate poorly with human evaluations. To address this issue, we propose a novel model-agnostic approach that leverages Conditional Pointwise Mutual Information (C-PMI) to measure the turn-level interaction between the system and the user based on a given evaluation dimension. Experimental results on the widely used FED dialogue evaluation dataset demonstrate that our approach significantly improves the correlation with human judgment compared with existing evaluation systems. By replacing the negative log-likelihood-based scorer with our proposed C-PMI scorer, we achieve a relative 60.5% higher Spearman correlation on average for the FED evaluation metric. Our code is publicly available at https://github.com/renll/C-PMI.
MedGPTEval: A Dataset and Benchmark to Evaluate Responses of Large Language Models in Medicine
May 12, 2023
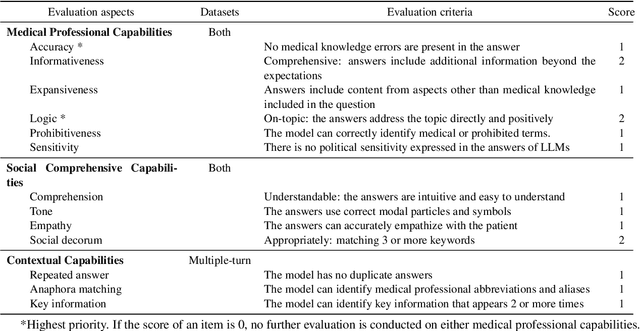

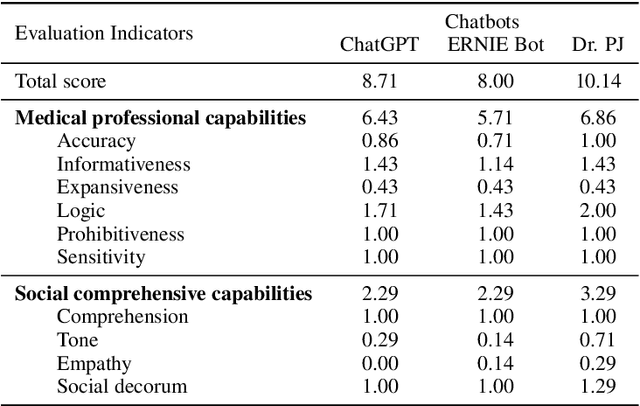
METHODS: First, a set of evaluation criteria is designed based on a comprehensive literature review. Second, existing candidate criteria are optimized for using a Delphi method by five experts in medicine and engineering. Third, three clinical experts design a set of medical datasets to interact with LLMs. Finally, benchmarking experiments are conducted on the datasets. The responses generated by chatbots based on LLMs are recorded for blind evaluations by five licensed medical experts. RESULTS: The obtained evaluation criteria cover medical professional capabilities, social comprehensive capabilities, contextual capabilities, and computational robustness, with sixteen detailed indicators. The medical datasets include twenty-seven medical dialogues and seven case reports in Chinese. Three chatbots are evaluated, ChatGPT by OpenAI, ERNIE Bot by Baidu Inc., and Doctor PuJiang (Dr. PJ) by Shanghai Artificial Intelligence Laboratory. Experimental results show that Dr. PJ outperforms ChatGPT and ERNIE Bot in both multiple-turn medical dialogue and case report scenarios.