 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"cancer detection": models, code, and papers
ECPC-IDS:A benchmark endometrail cancer PET/CT image dataset for evaluation of semantic segmentation and detection of hypermetabolic regions
Sep 02, 2023

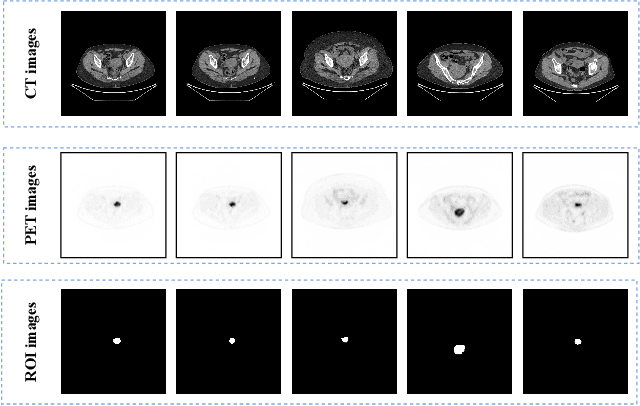
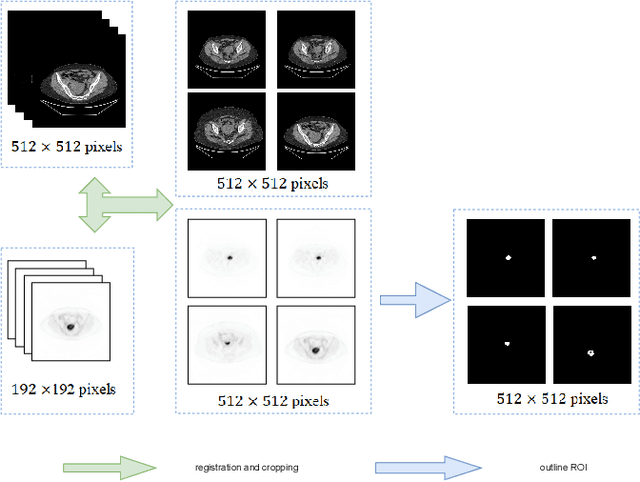
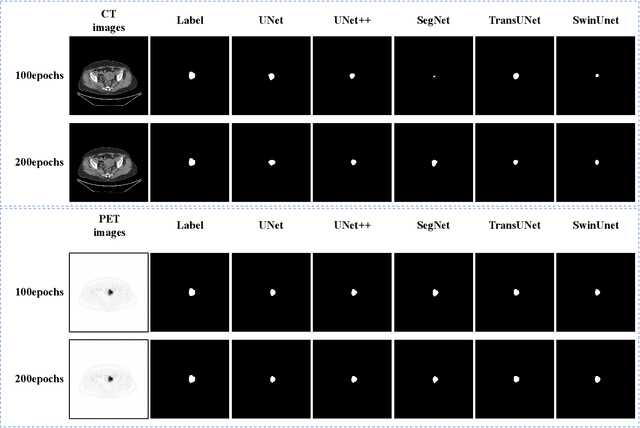
Endometrial cancer is one of the most common tumors in the female reproductive system and is the third most common gynecological malignancy that causes death after ovarian and cervical cancer. Early diagnosis can significantly improve the 5-year survival rate of patients. With the development of artificial intelligence, computer-assisted diagnosis plays an increasingly important role in improving the accuracy and objectivity of diagnosis, as well as reducing the workload of doctors. However, the absence of publicly available endometrial cancer image datasets restricts the application of computer-assisted diagnostic techniques.In this paper, a publicly available Endometrial Cancer PET/CT Image Dataset for Evaluation of Semantic Segmentation and Detection of Hypermetabolic Regions (ECPC-IDS) are published. Specifically, the segmentation section includes PET and CT images, with a total of 7159 images in multiple formats. In order to prove the effectiveness of segmentation methods on ECPC-IDS, five classical deep learning semantic segmentation methods are selected to test the image segmentation task. The object detection section also includes PET and CT images, with a total of 3579 images and XML files with annotation information. Six deep learning methods are selected for experiments on the detection task.This study conduct extensive experiments using deep learning-based semantic segmentation and object detection methods to demonstrate the differences between various methods on ECPC-IDS. As far as we know, this is the first publicly available dataset of endometrial cancer with a large number of multiple images, including a large amount of information required for image and target detection. ECPC-IDS can aid researchers in exploring new algorithms to enhance computer-assisted technology, benefiting both clinical doctors and patients greatly.
Context-Aware Self-Supervised Learning of Whole Slide Images
Jun 07, 2023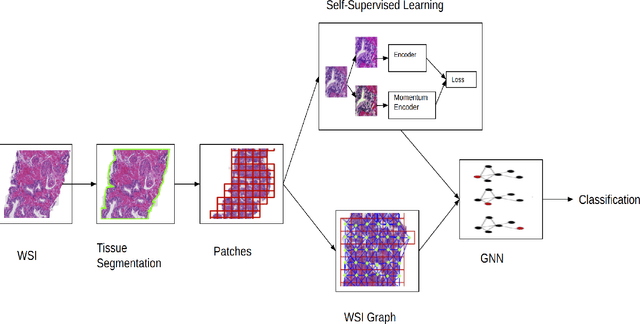
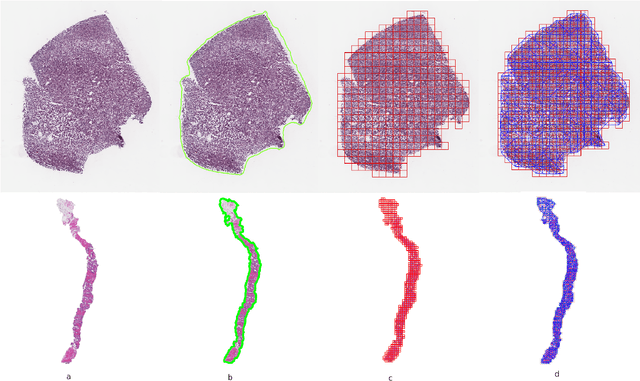
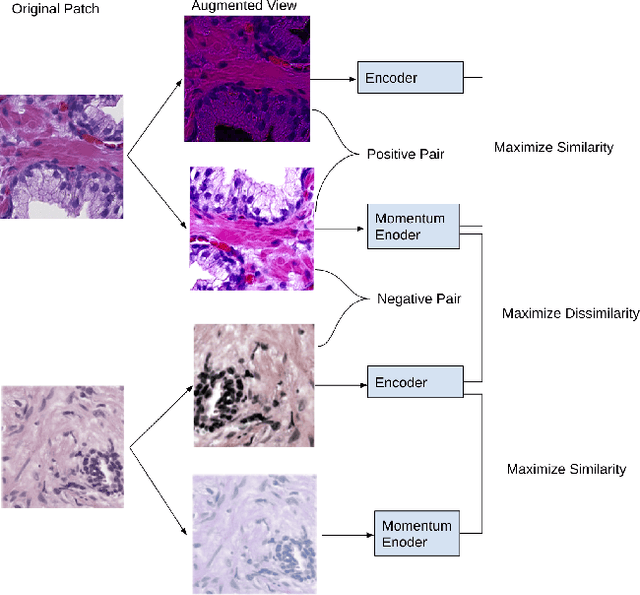
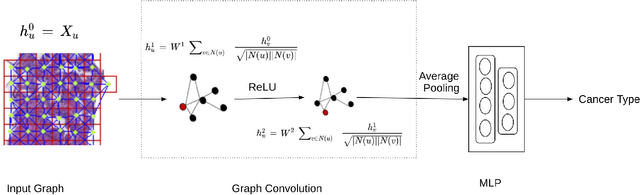
Presenting whole slide images (WSIs) as graph will enable a more efficient and accurate learning framework for cancer diagnosis. Due to the fact that a single WSI consists of billions of pixels and there is a lack of vast annotated datasets required for computational pathology, the problem of learning from WSIs using typical deep learning approaches such as convolutional neural network (CNN) is challenging. Additionally, WSIs down-sampling may lead to the loss of data that is essential for cancer detection. A novel two-stage learning technique is presented in this work. Since context, such as topological features in the tumor surroundings, may hold important information for cancer grading and diagnosis, a graph representation capturing all dependencies among regions in the WSI is very intuitive. Graph convolutional network (GCN) is deployed to include context from the tumor and adjacent tissues, and self-supervised learning is used to enhance training through unlabeled data. More specifically, the entire slide is presented as a graph, where the nodes correspond to the patches from the WSI. The proposed framework is then tested using WSIs from prostate and kidney cancers. To assess the performance improvement through self-supervised mechanism, the proposed context-aware model is tested with and without use of pre-trained self-supervised layer. The overall model is also compared with multi-instance learning (MIL) based and other existing approaches.
Robust Tumor Detection from Coarse Annotations via Multi-Magnification Ensembles
Mar 29, 2023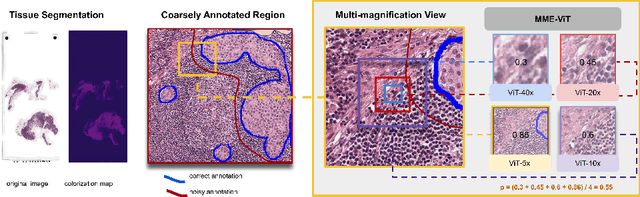
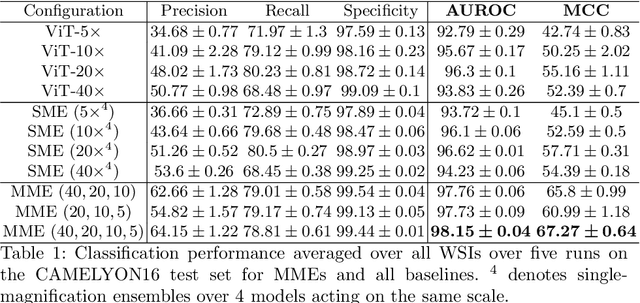
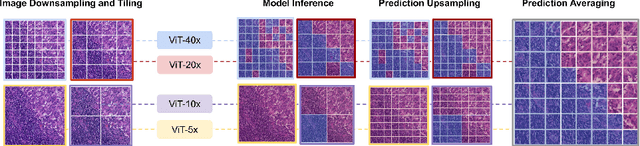
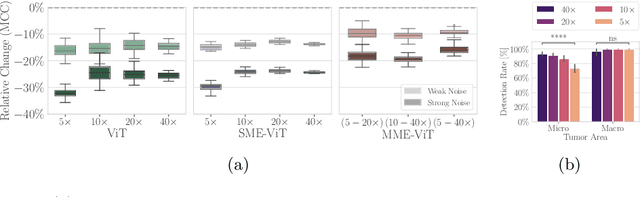
Cancer detection and classification from gigapixel whole slide images of stained tissue specimens has recently experienced enormous progress in computational histopathology. The limitation of available pixel-wise annotated scans shifted the focus from tumor localization to global slide-level classification on the basis of (weakly-supervised) multiple-instance learning despite the clinical importance of local cancer detection. However, the worse performance of these techniques in comparison to fully supervised methods has limited their usage until now for diagnostic interventions in domains of life-threatening diseases such as cancer. In this work, we put the focus back on tumor localization in form of a patch-level classification task and take up the setting of so-called coarse annotations, which provide greater training supervision while remaining feasible from a clinical standpoint. To this end, we present a novel ensemble method that not only significantly improves the detection accuracy of metastasis on the open CAMELYON16 data set of sentinel lymph nodes of breast cancer patients, but also considerably increases its robustness against noise while training on coarse annotations. Our experiments show that better results can be achieved with our technique making it clinically feasible to use for cancer diagnosis and opening a new avenue for translational and clinical research.
Non-Redundant Combination of Hand-Crafted and Deep Learning Radiomics: Application to the Early Detection of Pancreatic Cancer
Aug 22, 2023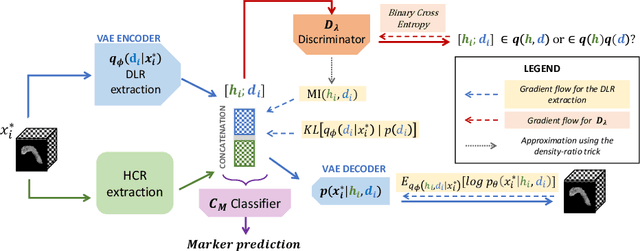

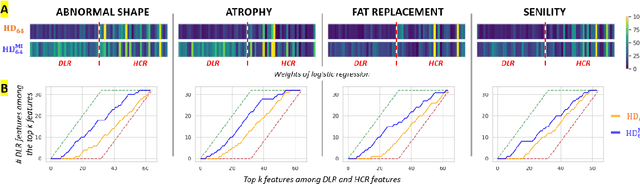
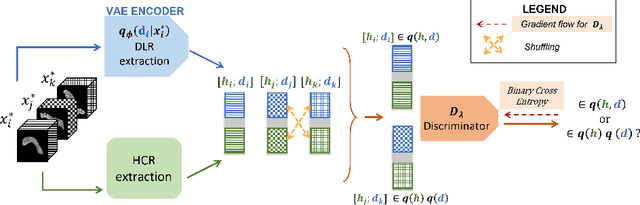
We address the problem of learning Deep Learning Radiomics (DLR) that are not redundant with Hand-Crafted Radiomics (HCR). To do so, we extract DLR features using a VAE while enforcing their independence with HCR features by minimizing their mutual information. The resulting DLR features can be combined with hand-crafted ones and leveraged by a classifier to predict early markers of cancer. We illustrate our method on four early markers of pancreatic cancer and validate it on a large independent test set. Our results highlight the value of combining non-redundant DLR and HCR features, as evidenced by an improvement in the Area Under the Curve compared to baseline methods that do not address redundancy or solely rely on HCR features.
Towards Optimal Patch Size in Vision Transformers for Tumor Segmentation
Aug 31, 2023Detection of tumors in metastatic colorectal cancer (mCRC) plays an essential role in the early diagnosis and treatment of liver cancer. Deep learning models backboned by fully convolutional neural networks (FCNNs) have become the dominant model for segmenting 3D computerized tomography (CT) scans. However, since their convolution layers suffer from limited kernel size, they are not able to capture long-range dependencies and global context. To tackle this restriction, vision transformers have been introduced to solve FCNN's locality of receptive fields. Although transformers can capture long-range features, their segmentation performance decreases with various tumor sizes due to the model sensitivity to the input patch size. While finding an optimal patch size improves the performance of vision transformer-based models on segmentation tasks, it is a time-consuming and challenging procedure. This paper proposes a technique to select the vision transformer's optimal input multi-resolution image patch size based on the average volume size of metastasis lesions. We further validated our suggested framework using a transfer-learning technique, demonstrating that the highest Dice similarity coefficient (DSC) performance was obtained by pre-training on training data with a larger tumour volume using the suggested ideal patch size and then training with a smaller one. We experimentally evaluate this idea through pre-training our model on a multi-resolution public dataset. Our model showed consistent and improved results when applied to our private multi-resolution mCRC dataset with a smaller average tumor volume. This study lays the groundwork for optimizing semantic segmentation of small objects using vision transformers. The implementation source code is available at:https://github.com/Ramtin-Mojtahedi/OVTPS.
Development and external validation of a lung cancer risk estimation tool using gradient-boosting
Aug 23, 2023Lung cancer is a significant cause of mortality worldwide, emphasizing the importance of early detection for improved survival rates. In this study, we propose a machine learning (ML) tool trained on data from the PLCO Cancer Screening Trial and validated on the NLST to estimate the likelihood of lung cancer occurrence within five years. The study utilized two datasets, the PLCO (n=55,161) and NLST (n=48,595), consisting of comprehensive information on risk factors, clinical measurements, and outcomes related to lung cancer. Data preprocessing involved removing patients who were not current or former smokers and those who had died of causes unrelated to lung cancer. Additionally, a focus was placed on mitigating bias caused by censored data. Feature selection, hyper-parameter optimization, and model calibration were performed using XGBoost, an ensemble learning algorithm that combines gradient boosting and decision trees. The ML model was trained on the pre-processed PLCO dataset and tested on the NLST dataset. The model incorporated features such as age, gender, smoking history, medical diagnoses, and family history of lung cancer. The model was well-calibrated (Brier score=0.044). ROC-AUC was 82% on the PLCO dataset and 70% on the NLST dataset. PR-AUC was 29% and 11% respectively. When compared to the USPSTF guidelines for lung cancer screening, our model provided the same recall with a precision of 13.1% vs. 9.3% on the PLCO dataset and 3.2% vs. 3.1% on the NLST dataset. The developed ML tool provides a freely available web application for estimating the likelihood of developing lung cancer within five years. By utilizing risk factors and clinical data, individuals can assess their risk and make informed decisions regarding lung cancer screening. This research contributes to the efforts in early detection and prevention strategies, aiming to reduce lung cancer-related mortality rates.
Breast Cancer Detection using Histopathological Images
Feb 12, 2022
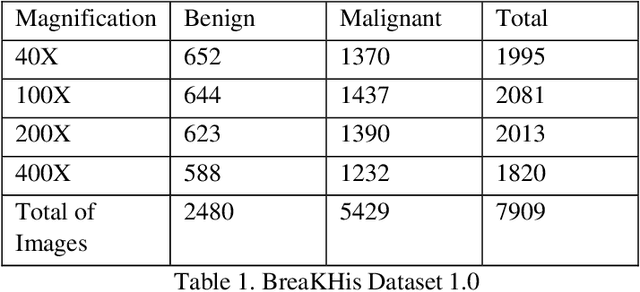
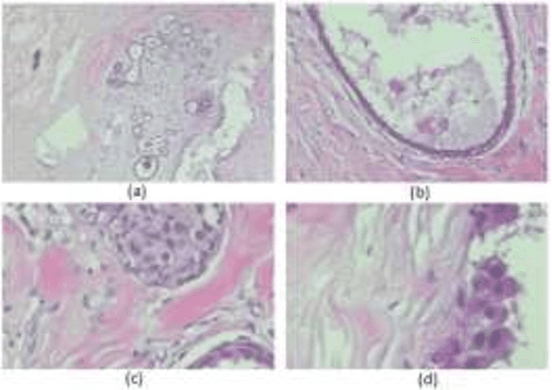
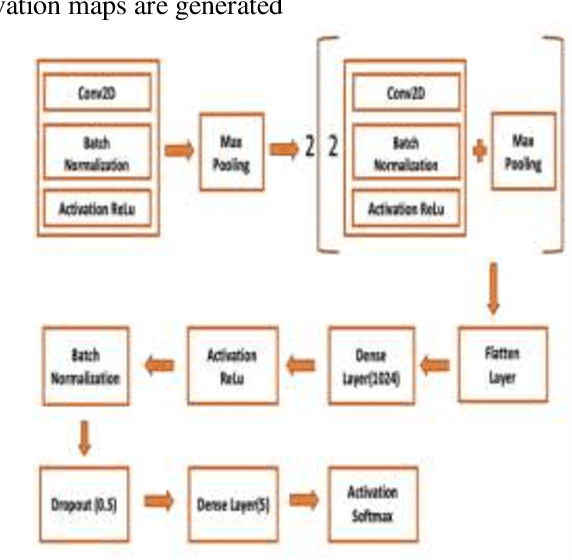
Cancer is one of the most common and fatal diseases in the world. Breast cancer affects one in every eight women and one in every eight hundred men. Hence, our prime target should be early detection of cancer because the early detection of cancer can be helpful to cure cancer effectively. Therefore, we propose a saliency detection system with the help of advanced deep learning techniques, such that the machine will be taught to emulate actions of pathologists for localization of diagnostically pertinent regions. We study identification of five diagnostic categories of breast cancer by training a CNN (VGG16, ResNet architecture). We have used BreakHis dataset to train our model. We focus on both detection and classification of cancerous regions in histopathology images. The diagnostically relevant regions are salient. The detection system will be available as an open source web application which can be used by pathologists and medical institutions.
* 6 pages, 10 figures, Published with International Journal of Computer Science Trends and Technology (IJCST)
Osteosarcoma Tumor Detection using Transfer Learning Models
May 16, 2023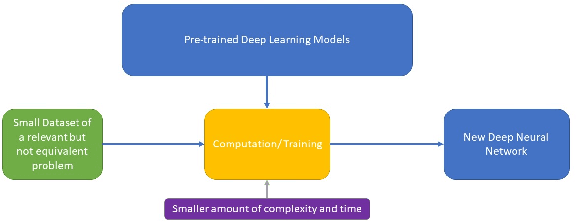

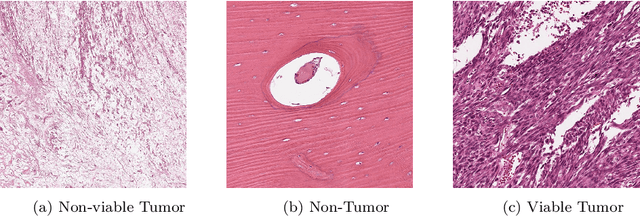
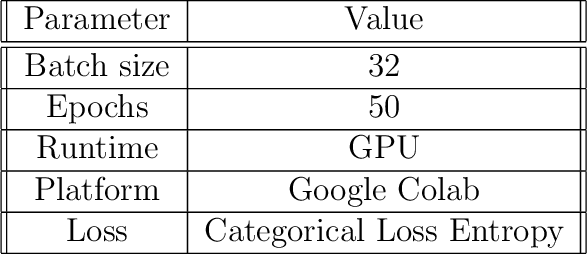
The field of clinical image analysis has been applying transfer learning models increasingly due to their less computational complexity, better accuracy etc. These are pre-trained models that don't require to be trained from scratch which eliminates the necessity of large datasets. Transfer learning models are mostly used for the analysis of brain, breast, or lung images but other sectors such as bone marrow cell detection or bone cancer detection can also benefit from using transfer learning models, especially considering the lack of available large datasets for these tasks. This paper studies the performance of several transfer learning models for osteosarcoma tumour detection. Osteosarcoma is a type of bone cancer mostly found in the cells of the long bones of the body. The dataset consists of H&E stained images divided into 4 categories- Viable Tumor, Non-viable Tumor, Non-Tumor and Viable Non-viable. Both datasets were randomly divided into train and test sets following an 80-20 ratio. 80% was used for training and 20\% for test. 4 models are considered for comparison- EfficientNetB7, InceptionResNetV2, NasNetLarge and ResNet50. All these models are pre-trained on ImageNet. According to the result, InceptionResNetV2 achieved the highest accuracy (93.29%), followed by NasNetLarge (90.91%), ResNet50 (89.83%) and EfficientNetB7 (62.77%). It also had the highest precision (0.8658) and recall (0.8658) values among the 4 models.
FastMRI Prostate: A Publicly Available, Biparametric MRI Dataset to Advance Machine Learning for Prostate Cancer Imaging
Apr 18, 2023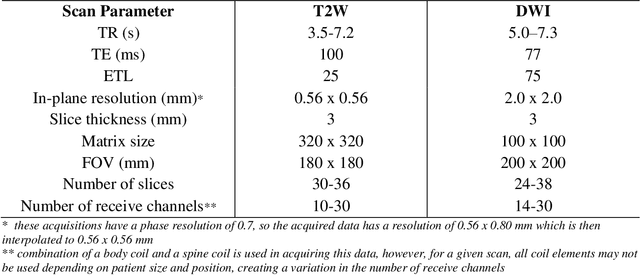
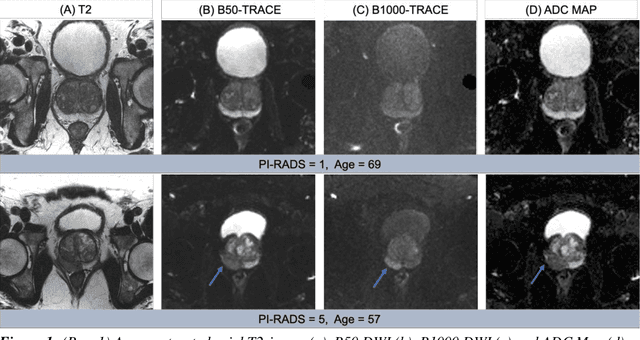
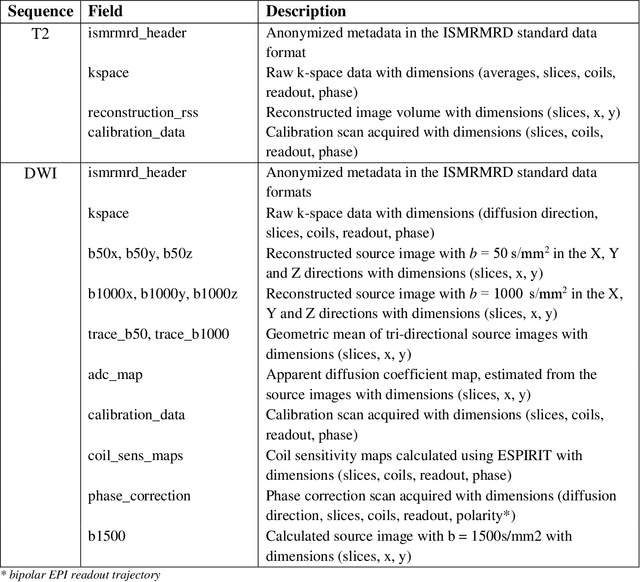
The fastMRI brain and knee dataset has enabled significant advances in exploring reconstruction methods for improving speed and image quality for Magnetic Resonance Imaging (MRI) via novel, clinically relevant reconstruction approaches. In this study, we describe the April 2023 expansion of the fastMRI dataset to include biparametric prostate MRI data acquired on a clinical population. The dataset consists of raw k-space and reconstructed images for T2-weighted and diffusion-weighted sequences along with slice-level labels that indicate the presence and grade of prostate cancer. As has been the case with fastMRI, increasing accessibility to raw prostate MRI data will further facilitate research in MR image reconstruction and evaluation with the larger goal of improving the utility of MRI for prostate cancer detection and evaluation. The dataset is available at https://fastmri.med.nyu.edu.
LCDctCNN: Lung Cancer Diagnosis of CT scan Images Using CNN Based Model
Apr 10, 2023
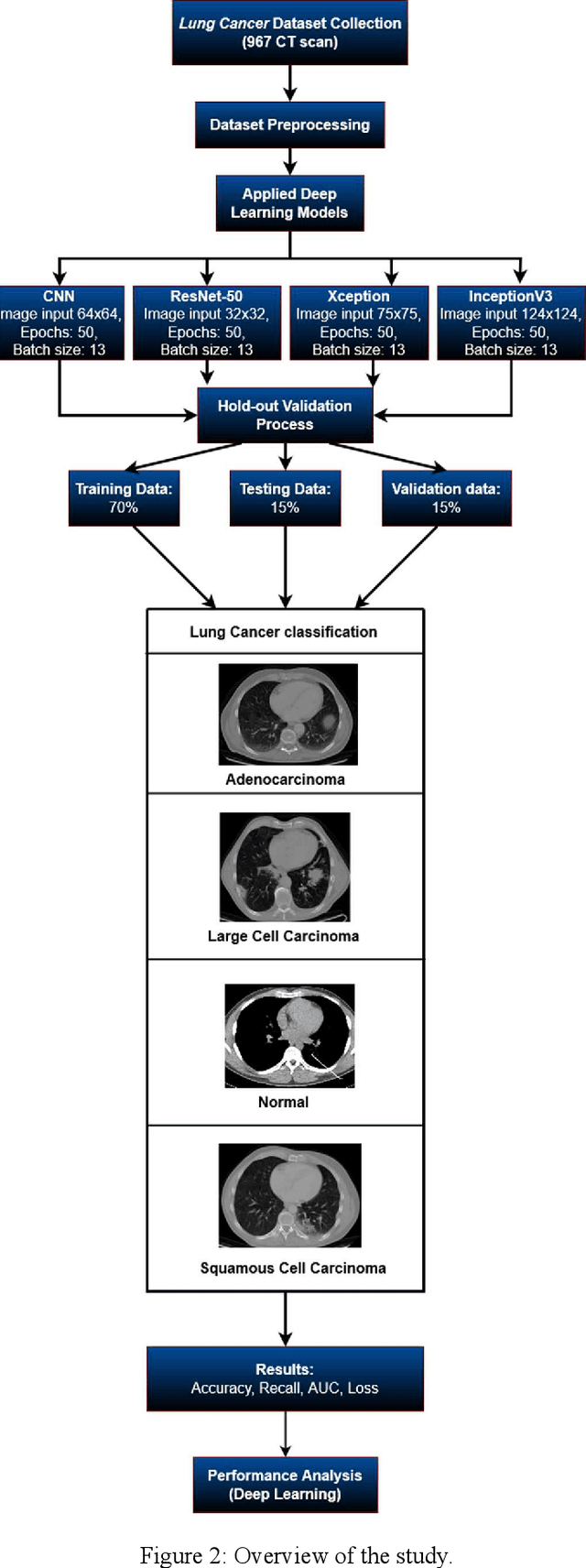
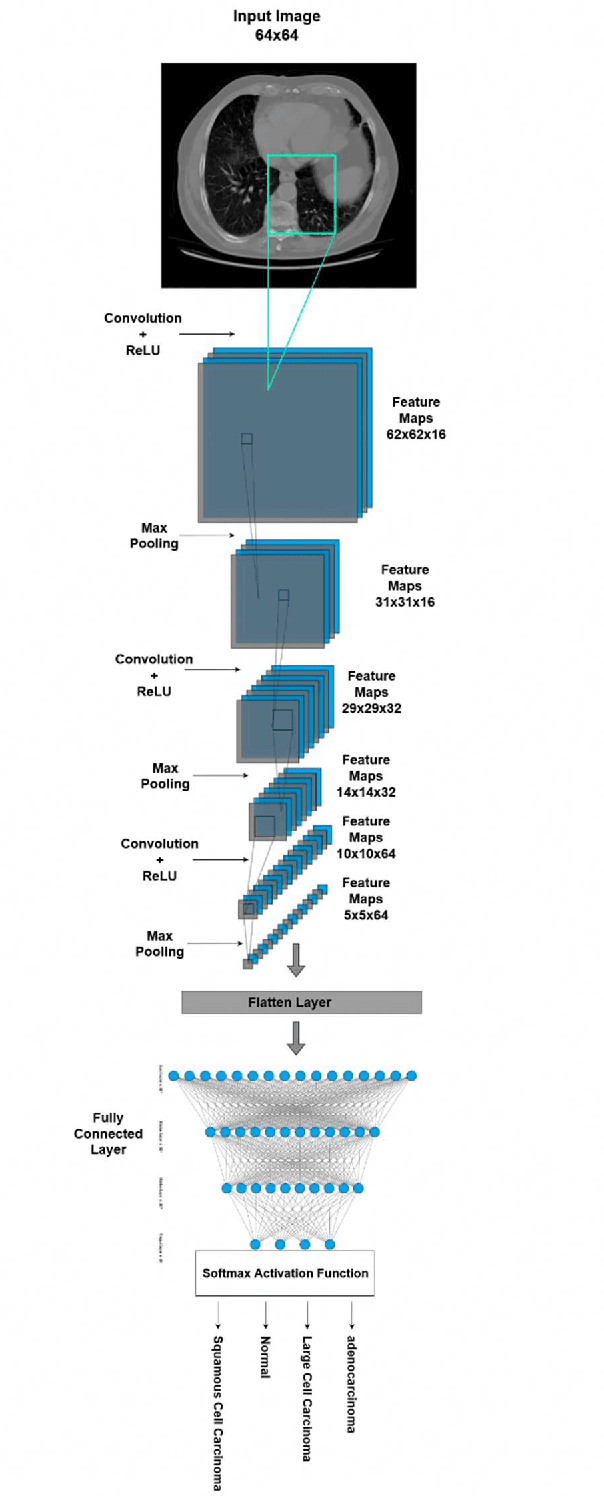
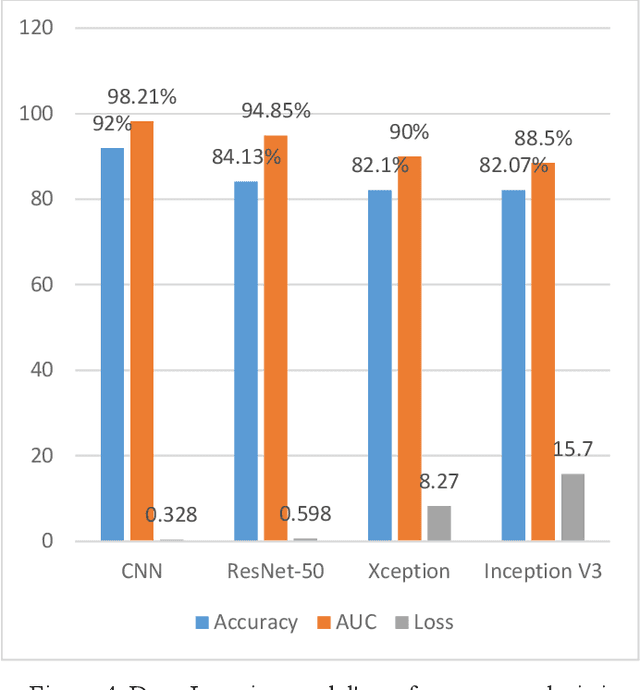
The most deadly and life-threatening disease in the world is lung cancer. Though early diagnosis and accurate treatment are necessary for lowering the lung cancer mortality rate. A computerized tomography (CT) scan-based image is one of the most effective imaging techniques for lung cancer detection using deep learning models. In this article, we proposed a deep learning model-based Convolutional Neural Network (CNN) framework for the early detection of lung cancer using CT scan images. We also have analyzed other models for instance Inception V3, Xception, and ResNet-50 models to compare with our proposed model. We compared our models with each other considering the metrics of accuracy, Area Under Curve (AUC), recall, and loss. After evaluating the model's performance, we observed that CNN outperformed other models and has been shown to be promising compared to traditional methods. It achieved an accuracy of 92%, AUC of 98.21%, recall of 91.72%, and loss of 0.328.