 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Liability, Ethics, and Culture-Aware Behavior Specification using Rulebooks
Mar 01, 2019
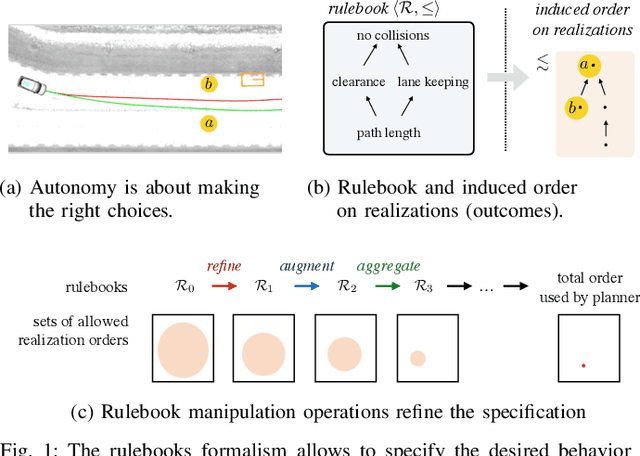

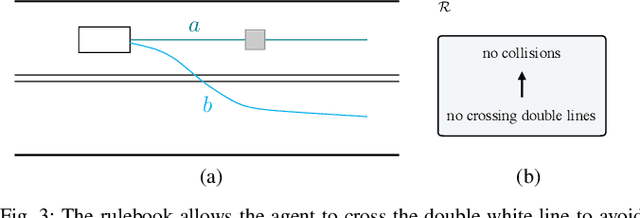
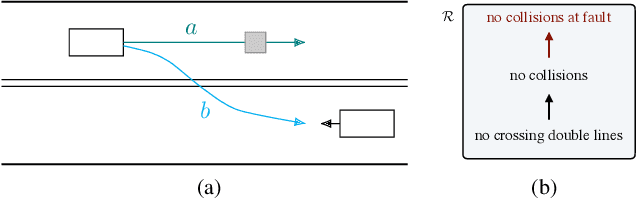
The behavior of self-driving cars must be compatible with an enormous set of conflicting and ambiguous objectives, from law, from ethics, from the local culture, and so on. This paper describes a new way to conveniently define the desired behavior for autonomous agents, which we use on the self-driving cars developed at nuTonomy. We define a "rulebook" as a pre-ordered set of "rules", each akin to a violation metric on the possible outcomes ("realizations"). The rules are partially ordered by priority. The semantics of a rulebook imposes a pre-order on the set of realizations. We study the compositional properties of the rulebooks, and we derive which operations we can allow on the rulebooks to preserve previously-introduced constraints. While we demonstrate the application of these techniques in the self-driving domain, the methods are domain-independent.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018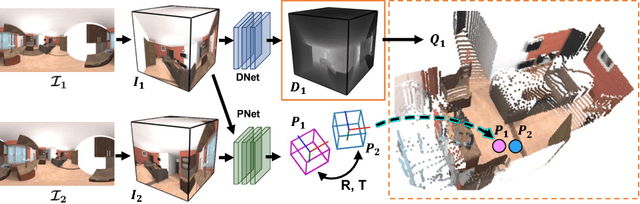
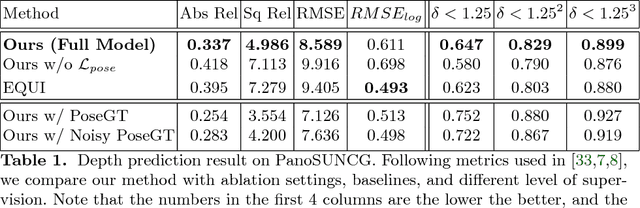
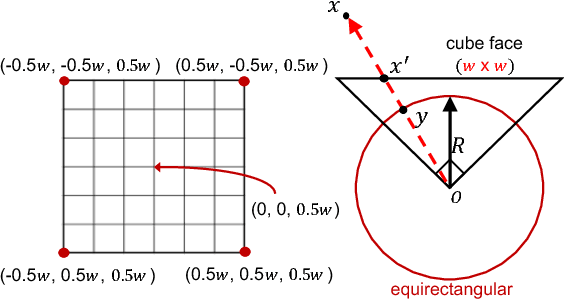
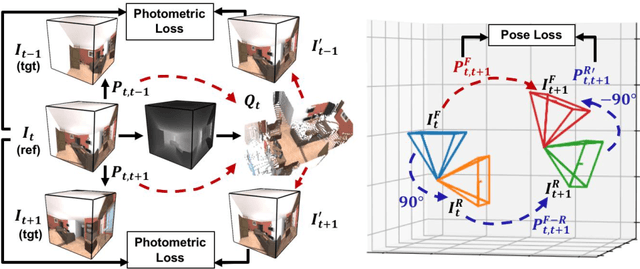
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.
Combined Image- and World-Space Tracking in Traffic Scenes
Sep 19, 2018


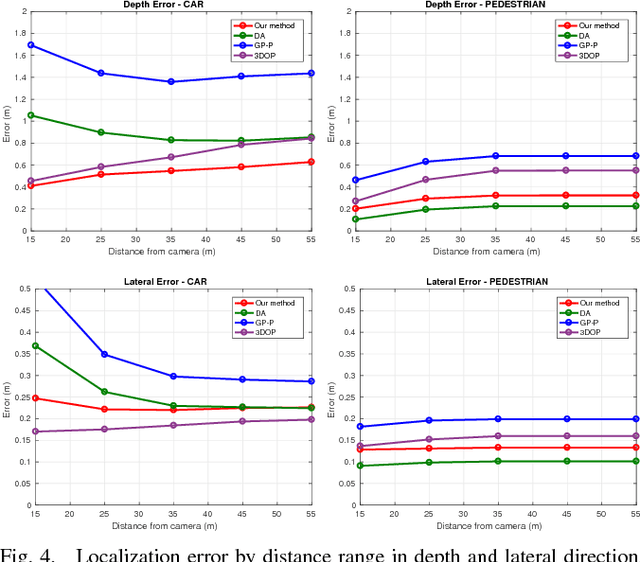
Tracking in urban street scenes plays a central role in autonomous systems such as self-driving cars. Most of the current vision-based tracking methods perform tracking in the image domain. Other approaches, eg based on LIDAR and radar, track purely in 3D. While some vision-based tracking methods invoke 3D information in parts of their pipeline, and some 3D-based methods utilize image-based information in components of their approach, we propose to use image- and world-space information jointly throughout our method. We present our tracking pipeline as a 3D extension of image-based tracking. From enhancing the detections with 3D measurements to the reported positions of every tracked object, we use world-space 3D information at every stage of processing. We accomplish this by our novel coupled 2D-3D Kalman filter, combined with a conceptually clean and extendable hypothesize-and-select framework. Our approach matches the current state-of-the-art on the official KITTI benchmark, which performs evaluation in the 2D image domain only. Further experiments show significant improvements in 3D localization precision by enabling our coupled 2D-3D tracking.
Action Detection from a Robot-Car Perspective
Jul 30, 2018
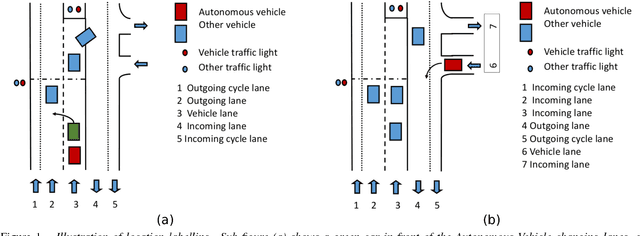

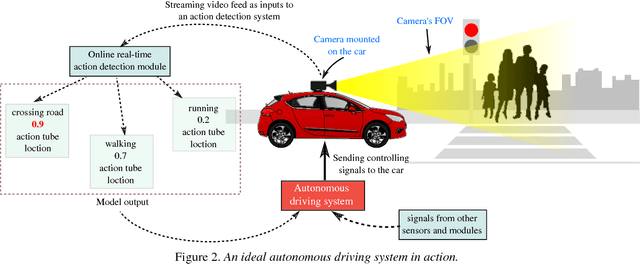
We present the new Road Event and Activity Detection (READ) dataset, designed and created from an autonomous vehicle perspective to take action detection challenges to autonomous driving. READ will give scholars in computer vision, smart cars and machine learning at large the opportunity to conduct research into exciting new problems such as understanding complex (road) activities, discerning the behaviour of sentient agents, and predicting both the label and the location of future actions and events, with the final goal of supporting autonomous decision making.
SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints
Sep 20, 2018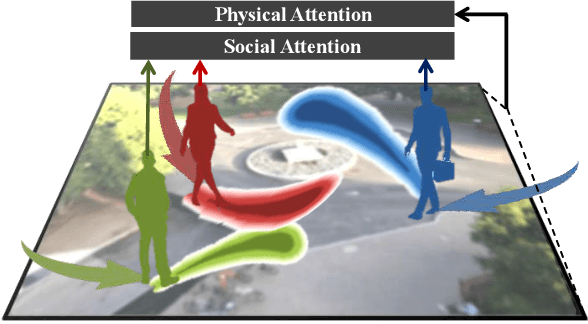
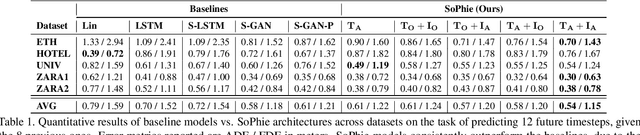
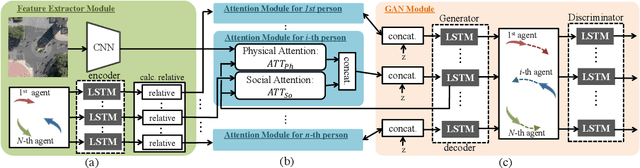

This paper addresses the problem of path prediction for multiple interacting agents in a scene, which is a crucial step for many autonomous platforms such as self-driving cars and social robots. We present \textit{SoPhie}; an interpretable framework based on Generative Adversarial Network (GAN), which leverages two sources of information, the path history of all the agents in a scene, and the scene context information, using images of the scene. To predict a future path for an agent, both physical and social information must be leveraged. Previous work has not been successful to jointly model physical and social interactions. Our approach blends a social attention mechanism with a physical attention that helps the model to learn where to look in a large scene and extract the most salient parts of the image relevant to the path. Whereas, the social attention component aggregates information across the different agent interactions and extracts the most important trajectory information from the surrounding neighbors. SoPhie also takes advantage of GAN to generates more realistic samples and to capture the uncertain nature of the future paths by modeling its distribution. All these mechanisms enable our approach to predict socially and physically plausible paths for the agents and to achieve state-of-the-art performance on several different trajectory forecasting benchmarks.
Real-Time Control for Autonomous Racing Based on Viability Theory
Nov 06, 2017
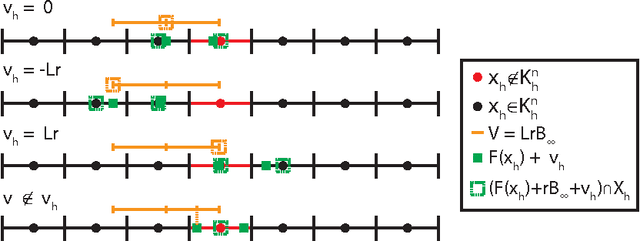
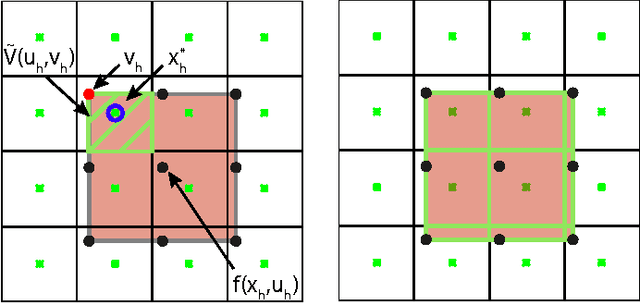

In this paper we consider autonomous driving of miniature race cars. The viability kernel is used to efficiently generate finite look-ahead trajectories that maximize progress while remaining recursively feasible with respect to static obstacles (e.g., stay inside the track). Together with a low-level model predictive controller, this method makes real-time autonomous racing possible. The viability kernel computation is based on space discretization. To make the calculation robust against discretization errors, we propose a novel numerical scheme based on game theoretical methods, in particular the discriminating kernel. We show that the resulting algorithm provides an inner approximation of the viability kernel and guarantees that, for all states in the cell surrounding a viable grid point, there exists a control that keeps the system within the kernel. The performance of the proposed control method is studied in simulation where we determine the effects of various design choices and parameters and in experiments on an autonomous racing set-up maintained at the Automatic Control Laboratory of ETH Zurich. Both simulation and experimental results suggest that the more conservative approximation using the discriminating kernel results in safer driving style at the cost of a small increase in lap time.
On the Interaction between Autonomous Mobility on Demand Systems and Power Distribution Networks -- An Optimal Power Flow Approach
May 01, 2019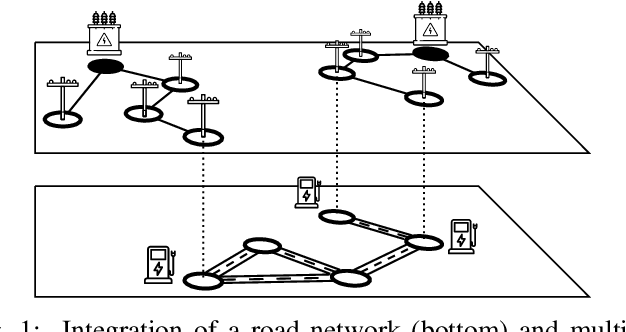
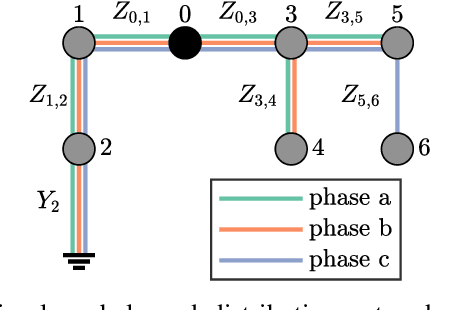
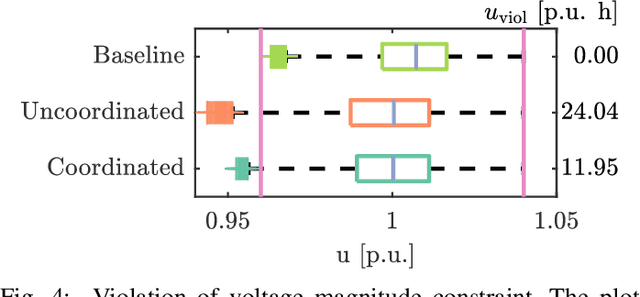
In future transportation systems, the charging behavior of electric Autonomous Mobility on Demand (AMoD) fleets, i.e., fleets of self-driving cars that service on-demand trip requests, will likely challenge power distribution networks (PDNs), causing overloads or voltage drops. In this paper, we show that these challenges can be significantly attenuated if the PDNs' operational constraints and exogenous loads (e.g., from homes or businesses) are considered when operating the electric AMoD fleet. We focus on a system-level perspective, assuming full cooperation between the AMoD and the PDN operators. Through this single entity perspective, we derive an upper bound on the benefits of coordination. We present an optimization-based modeling approach to jointly control an electric AMoD fleet and a series of PDNs, and analyze the benefit of coordination under load balancing constraints. For a case study in Orange County, CA, we show that coordinating the electric AMoD fleet and the PDNs helps to reduce 99% of overloads and 50% of voltage drops which the electric AMoD fleet causes without coordination. Our results show that coordinating electric AMoD and PDNs helps to level loads and can significantly postpone the point at which upgrading the network's capacity to a larger scale becomes inevitable to preserve stability.
Personal space of autonomous car's passengers sitting in the driver's seat
May 09, 2018


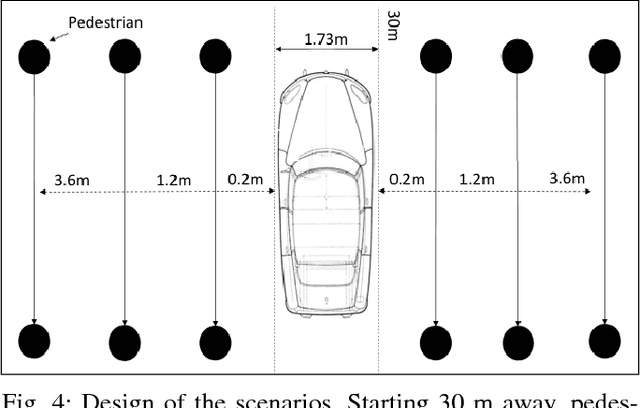
This article deals with the specific context of an autonomous car navigating in an urban center within a shared space between pedestrians and cars. The driver delegates the control to the autonomous system while remaining seated in the driver's seat. The proposed study aims at giving a first insight into the definition of human perception of space applied to vehicles by testing the existence of a personal space around the car.It aims at measuring proxemic information about the driver's comfort zone in such conditions.Proxemics, or human perception of space, has been largely explored when applied to humans or to robots, leading to the concept of personal space, but poorly when applied to vehicles. In this article, we highlight the existence and the characteristics of a zone of comfort around the car which is not correlated to the risk of a collision between the car and other road users. Our experiment includes 19 volunteers using a virtual reality headset to look at 30 scenarios filmed in 360{\textdegree} from the point of view of a passenger sitting in the driver's seat of an autonomous car.They were asked to say "stop" when they felt discomfort visualizing the scenarios.As said, the scenarios voluntarily avoid collision effect as we do not want to measure fear but discomfort.The scenarios involve one or three pedestrians walking past the car at different distances from the wings of the car, relative to the direction of motion of the car, on both sides. The car is either static or moving straight forward at different speeds.The results indicate the existence of a comfort zone around the car in which intrusion causes discomfort.The size of the comfort zone is sensitive neither to the side of the car where the pedestrian passes nor to the number of pedestrians. In contrast, the feeling of discomfort is relative to the car's motion (static or moving).Another outcome from this study is an illustration of the usage of first person 360{\textdegree} video and a virtual reality headset to evaluate feelings of a passenger within an autonomous car.
Priority-based coordination of mobile robots
Oct 03, 2014
Since the end of the 1980's, the development of self-driven autonomous vehicles is an intensive research area in most major industrial countries. Positive socio-economic potential impacts include a decrease of crashes, a reduction of travel times, energy efficiency improvements, and a reduced need of costly physical infrastructure. Some form of vehicle-to-vehicle and/or vehicle-to-infrastructure cooperation is required to ensure a safe and efficient global transportation system. This thesis deals with a particular form of cooperation by studying the problem of coordinating multiple mobile robots at an intersection area. Most of coordination systems proposed in previous work consist in planning a trajectory and to control the robots along the planned trajectory: that is the plan-as-program paradigm where planning is considered as a generative mechanism of action. The approach of the thesis is to plan priorities -- the relative order of robots to go through the intersection -- which is much weaker as many trajectories respect the same priorities. More precisely, priorities encode the homotopy classes of solutions to the coordination problem. Priority assignment is equivalent to the choice of some homotopy class to solve the coordination problem instead of a particular trajectory. Once priorities are assigned, robots are controlled through a control law preserving the assigned priorities, i.e., ensuring the described trajectory belongs to the chosen homotopy class. It results in a more robust coordination system -- able to handle a large class of unexpected events in a reactive manner -- particularly well adapted for an application to the coordination of autonomous vehicles at intersections where cars, public transport and pedestrians share the road.
Image segmentation of cross-country scenes captured in IR spectrum
Apr 08, 2016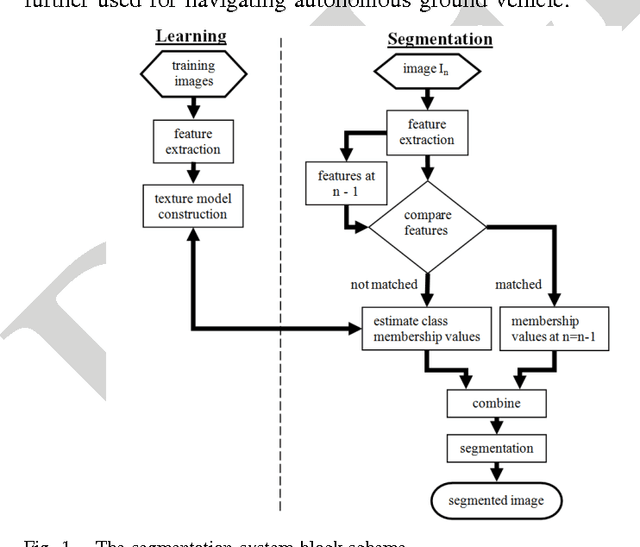


Computer vision has become a major source of information for autonomous navigation of robots of various types, self-driving cars, military robots and mars/lunar rovers are some examples. Nevertheless, the majority of methods focus on analysing images captured in visible spectrum. In this manuscript we elaborate on the problem of segmenting cross-country scenes captured in IR spectrum. For this purpose we proposed employing salient features. Salient features are robust to variations in scale, brightness and view angle. We suggest the Speeded-Up Robust Features as a basis for our salient features for a number of reasons discussed in the paper. We also provide a comparison of two SURF implementations. The SURF features are extracted from images of different terrain types. For every feature we estimate a terrain class membership function. The membership values are obtained by means of either the multi-layer perceptron or nearest neighbours. The features' class membership values and their spatial positions are then applied to estimate class membership values for all pixels in the image. To decrease the effect of segmentation blinking that is caused by rapid switching between different terrain types and to speed up segmentation, we are tracking camera position and predict features' positions. The comparison of the multi-layer perception and the nearest neighbour classifiers is presented in the paper. The error rate of the terrain segmentation using the nearest neighbours obtained on the testing set is 16.6+-9.17%.