 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Driver Modeling through Deep Reinforcement Learning and Behavioral Game Theory
Mar 24, 2020
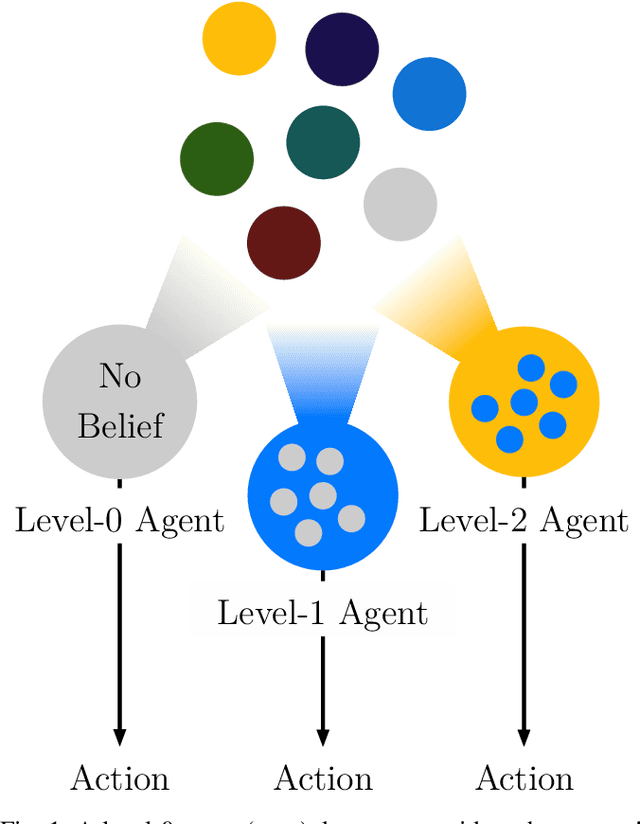
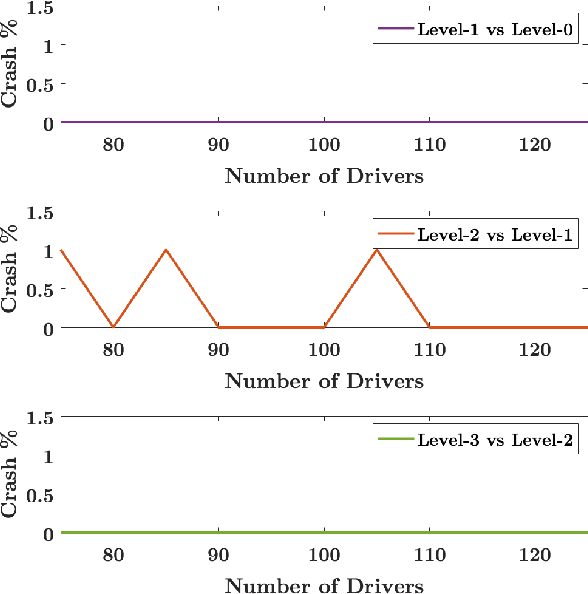
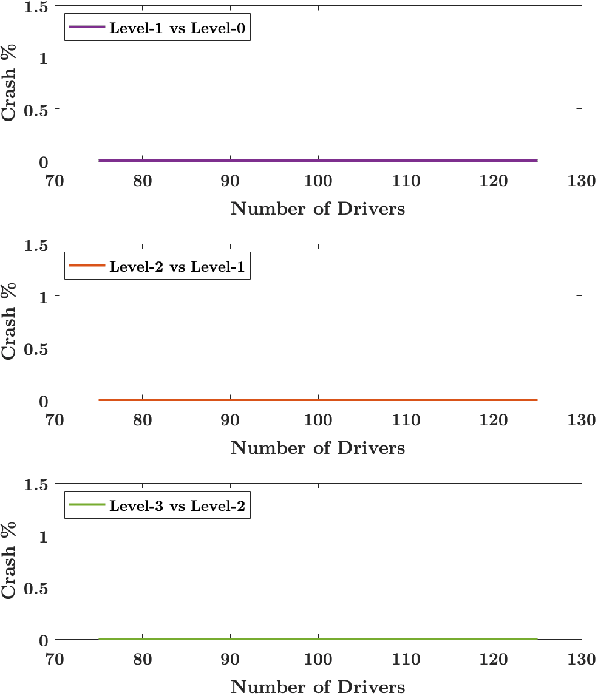
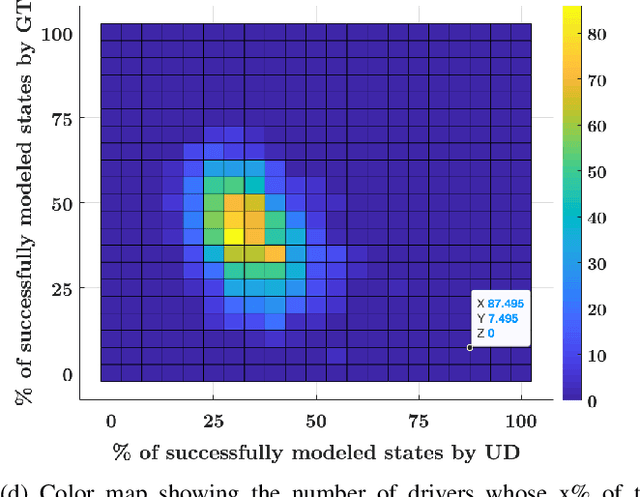
In this paper, a synergistic combination of deep reinforcement learning and hierarchical game theory is proposed as a modeling framework for behavioral predictions of drivers in highway driving scenarios. The need for a modeling framework that can address multiple human-human and human-automation interactions, where all the agents can be modeled as decision makers simultaneously, is the main motivation behind this work. Such a modeling framework may be utilized for the validation and verification of autonomous vehicles: It is estimated that for an autonomous vehicle to reach the same safety level of cars with drivers, millions of miles of driving tests are required. The modeling framework presented in this paper may be used in a high-fidelity traffic simulator consisting of multiple human decision makers to reduce the time and effort spent for testing by allowing safe and quick assessment of self-driving algorithms. To demonstrate the fidelity of the proposed modeling framework, game theoretical driver models are compared with real human driver behavior patterns extracted from traffic data.
Proximity Queries for Absolutely Continuous Parametric Curves
Apr 09, 2019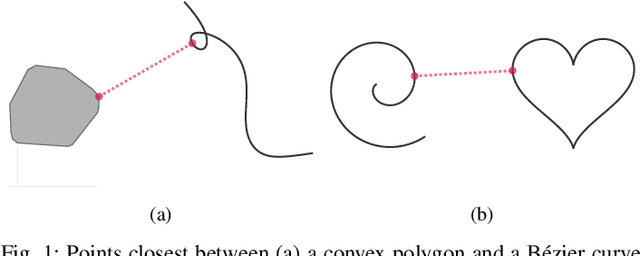

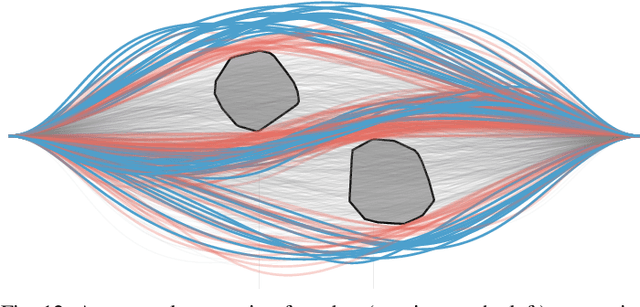
In motion planning problems for autonomous robots, such as self-driving cars, the robot must ensure that its planned path is not in close proximity to obstacles in the environment. However, the problem of evaluating the proximity is generally non-convex and serves as a significant computational bottleneck for motion planning algorithms. In this paper, we present methods for a general class of absolutely continuous parametric curves to compute: (i) the minimum separating distance, (ii) tolerance verification, and (iii) collision detection. Our methods efficiently compute bounds on obstacle proximity by bounding the curve in a convex region. This bound is based on an upper bound on the curve arc length that can be expressed in closed form for a useful class of parametric curves including curves with trigonometric or polynomial bases. We demonstrate the computational efficiency and accuracy of our approach through numerical simulations of several proximity problems.
Efficient Autonomy Validation in Simulation with Adaptive Stress Testing
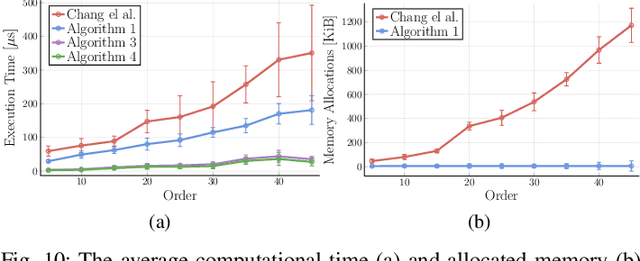
Jul 16, 2019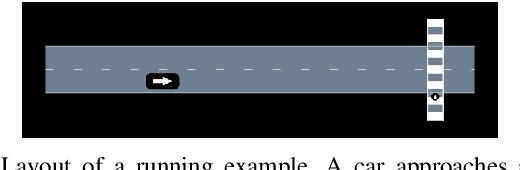
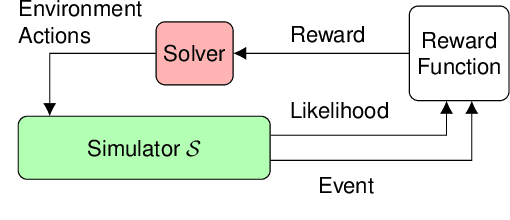
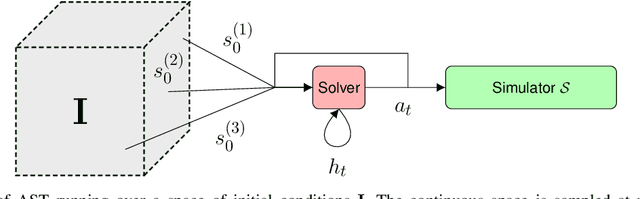
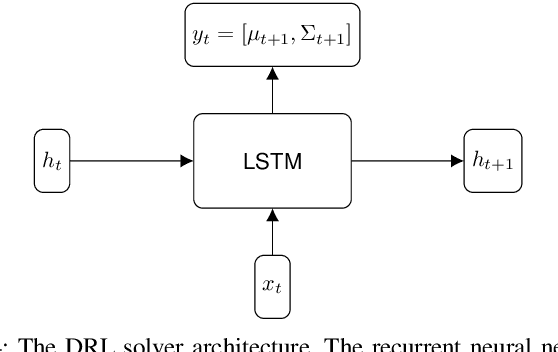
During the development of autonomous systems such as driverless cars, it is important to characterize the scenarios that are most likely to result in failure. Adaptive Stress Testing (AST) provides a way to search for the most-likely failure scenario as a Markov decision process (MDP). Our previous work used a deep reinforcement learning (DRL) solver to identify likely failure scenarios. However, the solver's use of a feed-forward neural network with a discretized space of possible initial conditions poses two major problems. First, the system is not treated as a black box, in that it requires analyzing the internal state of the system, which leads to considerable implementation complexities. Second, in order to simulate realistic settings, a new instance of the solver needs to be run for each initial condition. Running a new solver for each initial condition not only significantly increases the computational complexity, but also disregards the underlying relationship between similar initial conditions. We provide a solution to both problems by employing a recurrent neural network that takes a set of initial conditions from a continuous space as input. This approach enables robust and efficient detection of failures because the solution generalizes across the entire space of initial conditions. By simulating an instance where an autonomous car drives while a pedestrian is crossing a road, we demonstrate the solver is now capable of finding solutions for problems that would have previously been intractable.
Separable Convolutional LSTMs for Faster Video Segmentation
Jul 16, 2019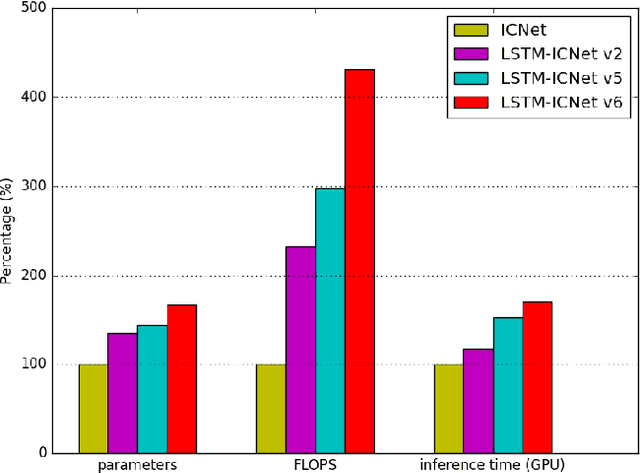

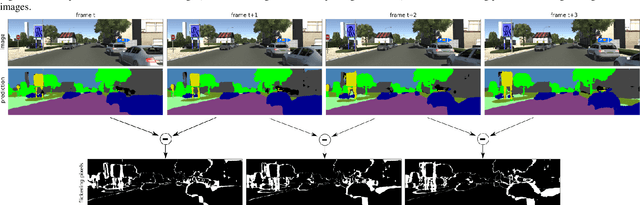
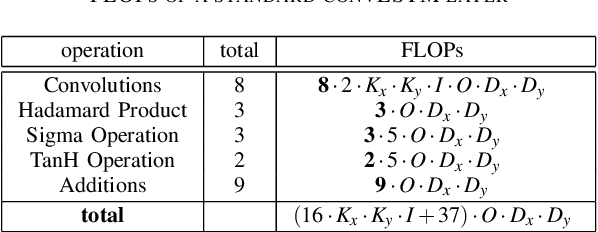
Semantic Segmentation is an important module for autonomous robots such as self-driving cars. The advantage of video segmentation approaches compared to single image segmentation is that temporal image information is considered, and their performance increases due to this. Hence, single image segmentation approaches are extended by recurrent units such as convolutional LSTM (convLSTM) cells, which are placed at suitable positions in the basic network architecture. However, a major critique of video segmentation approaches based on recurrent neural networks is their large parameter count and their computational complexity, and so, their inference time of one video frame takes up to 66 percent longer than their basic version. Inspired by the success of the spatial and depthwise separable convolutional neural networks, we generalize these techniques for convLSTMs in this work, so that the number of parameters and the required FLOPs are reduced significantly. Experiments on different datasets show that the segmentation approaches using the proposed, modified convLSTM cells achieve similar or slightly worse accuracy, but are up to 15 percent faster on a GPU than the ones using the standard convLSTM cells. Furthermore, a new evaluation metric is introduced, which measures the amount of flickering pixels in the segmented video sequence.
JuncNet: A Deep Neural Network for Road Junction Disambiguation for Autonomous Vehicles
Aug 31, 2018


With a great amount of research going on in the field of autonomous vehicles or self-driving cars, there has been considerable progress in road detection and tracking algorithms. Most of these algorithms use GPS to handle road junctions and its subsequent decisions. However, there are places in the urban environment where it becomes difficult to get GPS fixes which render the junction decision handling erroneous or possibly risky. Vision-based junction detection, however, does not have such problems. This paper proposes a novel deep convolutional neural network architecture for disambiguation of junctions from roads with a high degree of accuracy. This network is benchmarked against other well known classifying network architectures like AlexNet and VGGnet. Further, we discuss a potential road navigation methodology which uses the proposed network model. We conclude by performing an experimental validation of the trained network and the navigational method on the roads of the Indian Institute of Science (IISc).
A Non-Cooperative Game Approach to Autonomous Racing
Jan 10, 2019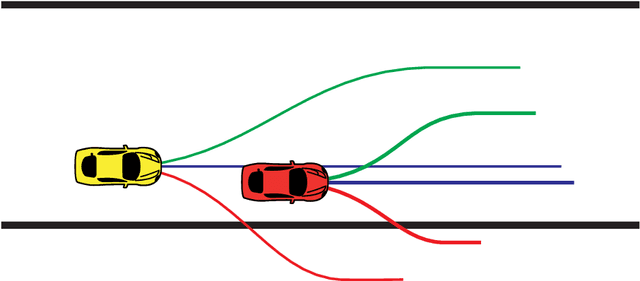
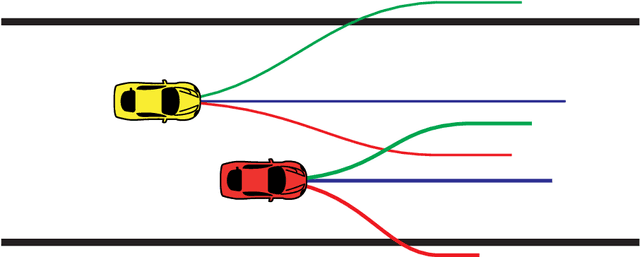
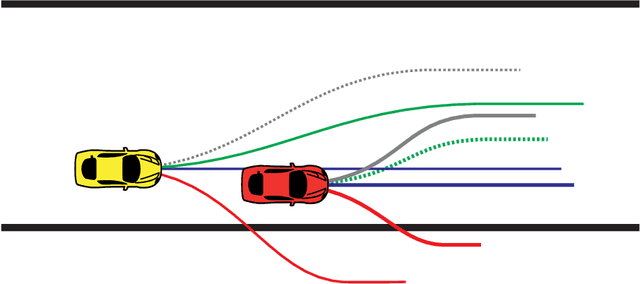
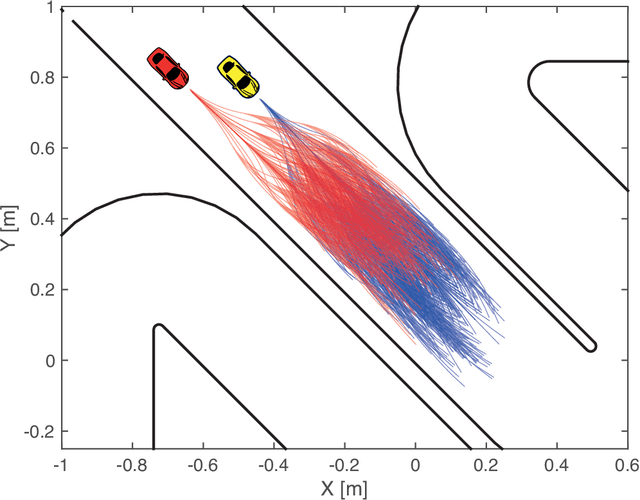
We consider autonomous racing of two cars and present an approach to formulate racing decisions as a non-cooperative non-zero-sum game. We design three different games where the players aim to fulfill static track constraints as well as avoid collision with each other; the latter constraint depends on the combined actions of the two players. The difference between the games are the collision constraints and the payoff. In the first game collision avoidance is only considered by the follower, and each player maximizes their own progress towards the finish line. We show that, thanks to the sequential structure of this game, equilibria can be computed through an efficient sequential maximization approach. Further, we show these actions, if feasible, are also a Stackelberg and Nash equilibrium in pure strategies of our second game where both players consider the collision constraints. The payoff of our third game is designed to promote blocking, by additionally rewarding the cars for staying ahead at the end of the horizon. We show that this changes the Stackelberg equilibrium, but has a minor influence on the Nash equilibria. For online implementation, we propose to play the games in a moving horizon fashion, and discuss two methods for guaranteeing feasibility of the resulting coupled repeated games. Finally, we study the performance of the proposed approaches in simulation for a set-up that replicates the miniature race car tested at the Automatic Control Laboratory of ETH Zurich. The simulation study shows that the presented games can successfully model different racing behaviors and generate interesting racing situations.
Unsupervised Machine Learning for Networking: Techniques, Applications and Research Challenges
Sep 19, 2017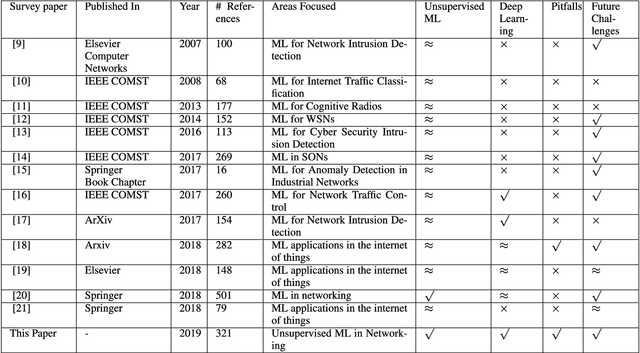
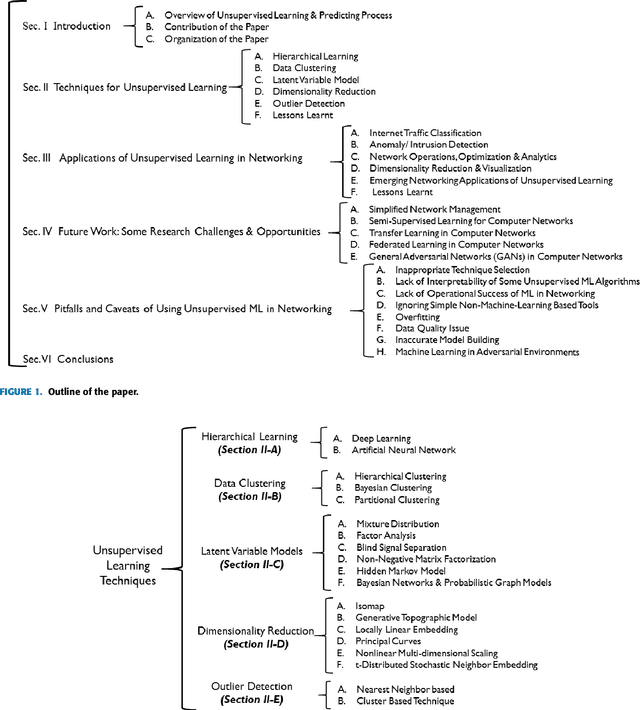
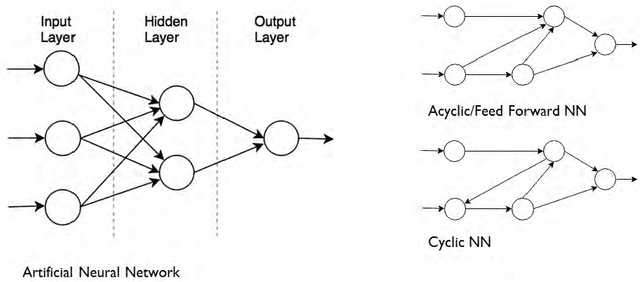
While machine learning and artificial intelligence have long been applied in networking research, the bulk of such works has focused on supervised learning. Recently there has been a rising trend of employing unsupervised machine learning using unstructured raw network data to improve network performance and provide services such as traffic engineering, anomaly detection, Internet traffic classification, and quality of service optimization. The interest in applying unsupervised learning techniques in networking emerges from their great success in other fields such as computer vision, natural language processing, speech recognition, and optimal control (e.g., for developing autonomous self-driving cars). Unsupervised learning is interesting since it can unconstrain us from the need of labeled data and manual handcrafted feature engineering thereby facilitating flexible, general, and automated methods of machine learning. The focus of this survey paper is to provide an overview of the applications of unsupervised learning in the domain of networking. We provide a comprehensive survey highlighting the recent advancements in unsupervised learning techniques and describe their applications for various learning tasks in the context of networking. We also provide a discussion on future directions and open research issues, while also identifying potential pitfalls. While a few survey papers focusing on the applications of machine learning in networking have previously been published, a survey of similar scope and breadth is missing in literature. Through this paper, we advance the state of knowledge by carefully synthesizing the insights from these survey papers while also providing contemporary coverage of recent advances.
Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
Mar 29, 2018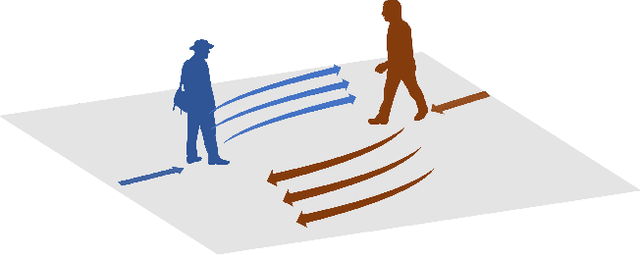
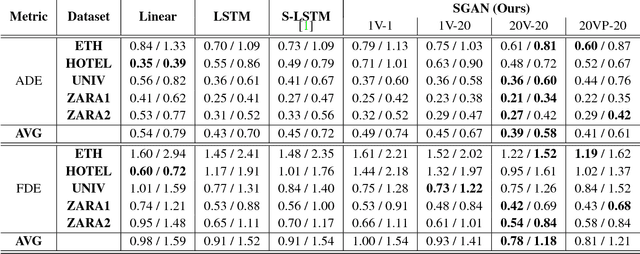
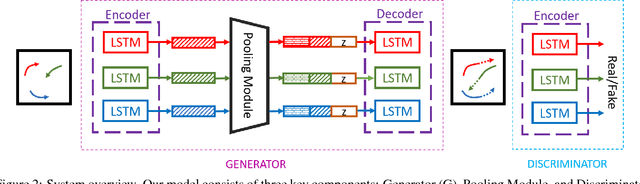
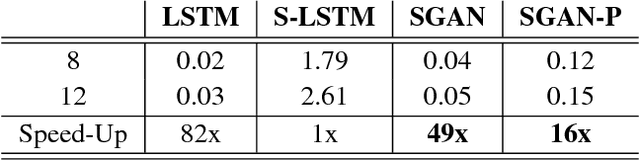
Understanding human motion behavior is critical for autonomous moving platforms (like self-driving cars and social robots) if they are to navigate human-centric environments. This is challenging because human motion is inherently multimodal: given a history of human motion paths, there are many socially plausible ways that people could move in the future. We tackle this problem by combining tools from sequence prediction and generative adversarial networks: a recurrent sequence-to-sequence model observes motion histories and predicts future behavior, using a novel pooling mechanism to aggregate information across people. We predict socially plausible futures by training adversarially against a recurrent discriminator, and encourage diverse predictions with a novel variety loss. Through experiments on several datasets we demonstrate that our approach outperforms prior work in terms of accuracy, variety, collision avoidance, and computational complexity.
Liability, Ethics, and Culture-Aware Behavior Specification using Rulebooks
Mar 01, 2019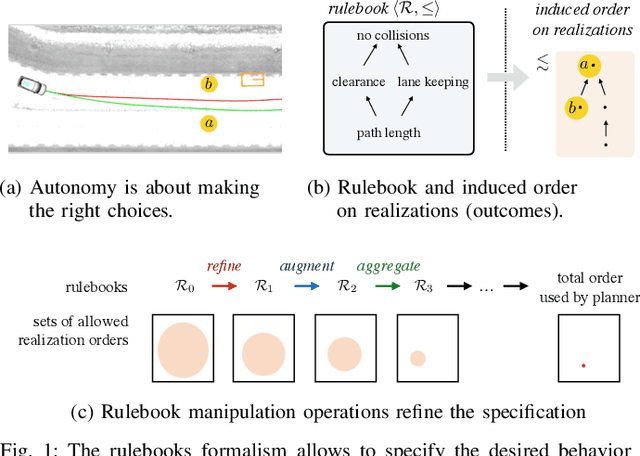

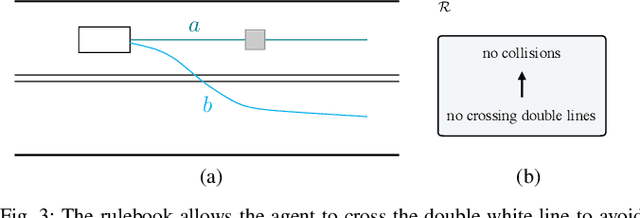
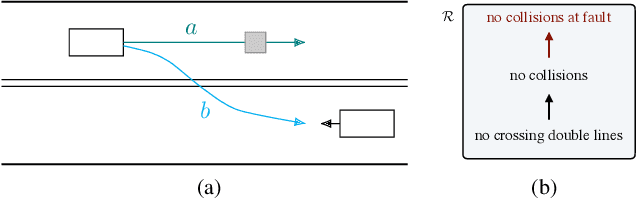
The behavior of self-driving cars must be compatible with an enormous set of conflicting and ambiguous objectives, from law, from ethics, from the local culture, and so on. This paper describes a new way to conveniently define the desired behavior for autonomous agents, which we use on the self-driving cars developed at nuTonomy. We define a "rulebook" as a pre-ordered set of "rules", each akin to a violation metric on the possible outcomes ("realizations"). The rules are partially ordered by priority. The semantics of a rulebook imposes a pre-order on the set of realizations. We study the compositional properties of the rulebooks, and we derive which operations we can allow on the rulebooks to preserve previously-introduced constraints. While we demonstrate the application of these techniques in the self-driving domain, the methods are domain-independent.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018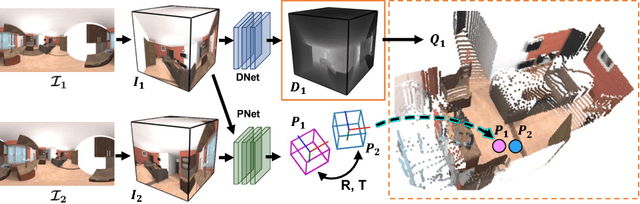
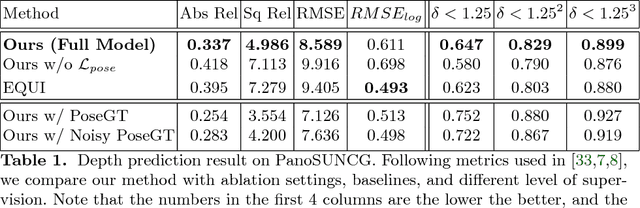
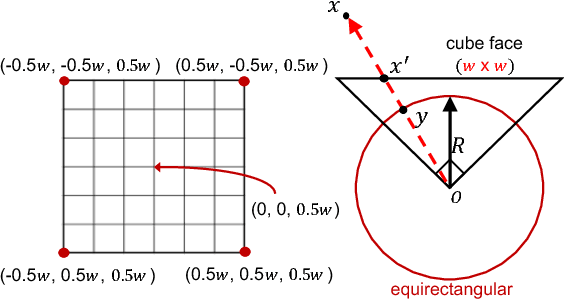
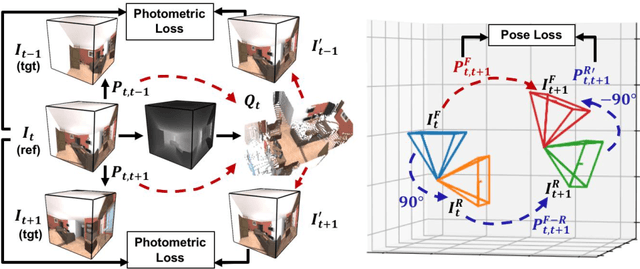
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.