 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Optimization-Based Autonomous Racing of 1:43 Scale RC Cars
Nov 20, 2017
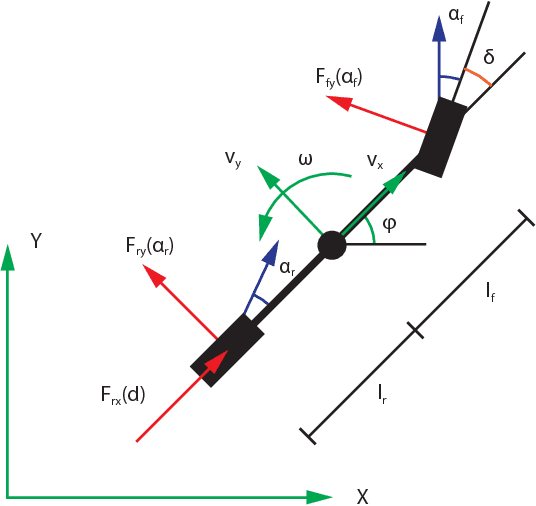
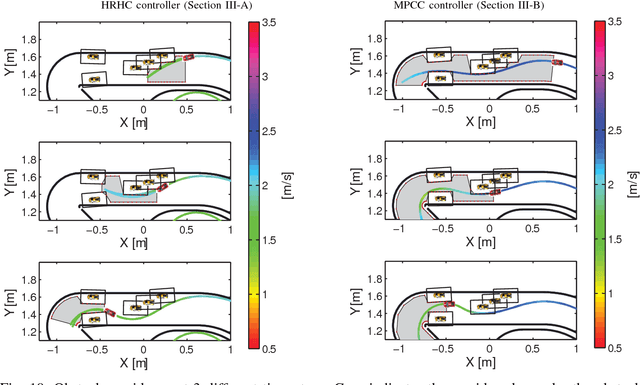
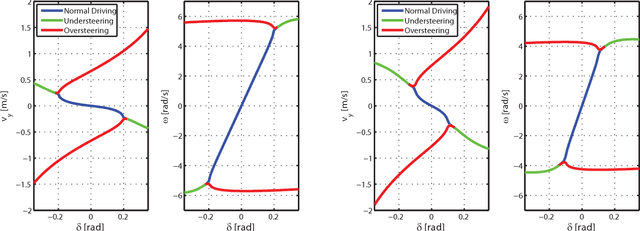
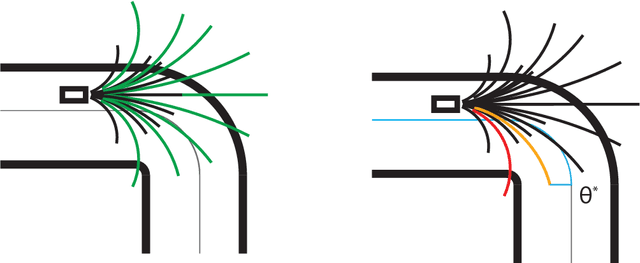
This paper describes autonomous racing of RC race cars based on mathematical optimization. Using a dynamical model of the vehicle, control inputs are computed by receding horizon based controllers, where the objective is to maximize progress on the track subject to the requirement of staying on the track and avoiding opponents. Two different control formulations are presented. The first controller employs a two-level structure, consisting of a path planner and a nonlinear model predictive controller (NMPC) for tracking. The second controller combines both tasks in one nonlinear optimization problem (NLP) following the ideas of contouring control. Linear time varying models obtained by linearization are used to build local approximations of the control NLPs in the form of convex quadratic programs (QPs) at each sampling time. The resulting QPs have a typical MPC structure and can be solved in the range of milliseconds by recent structure exploiting solvers, which is key to the real-time feasibility of the overall control scheme. Obstacle avoidance is incorporated by means of a high-level corridor planner based on dynamic programming, which generates convex constraints for the controllers according to the current position of opponents and the track layout. The control performance is investigated experimentally using 1:43 scale RC race cars, driven at speeds of more than 3 m/s and in operating regions with saturated rear tire forces (drifting). The algorithms run at 50 Hz sampling rate on embedded computing platforms, demonstrating the real-time feasibility and high performance of optimization-based approaches for autonomous racing.
A Geometric Approach to On-road Motion Planning for Long and Multi-Body Heavy-Duty Vehicles
Oct 15, 2020
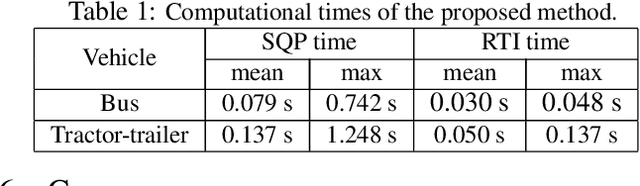
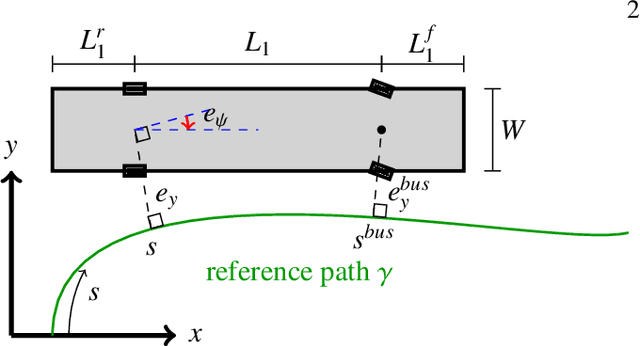
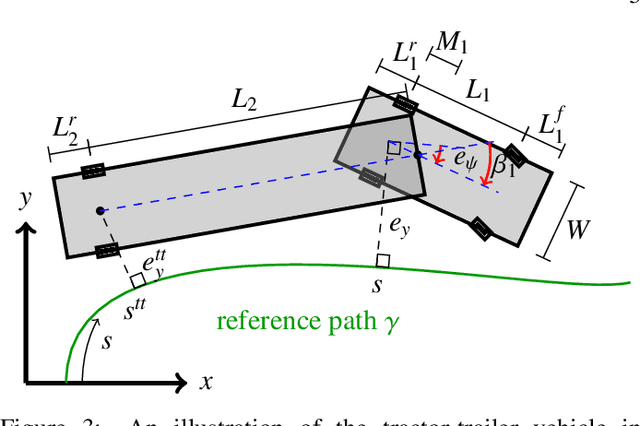
Driving heavy-duty vehicles, such as buses and tractor-trailer vehicles, is a difficult task in comparison to passenger cars. Most research on motion planning for autonomous vehicles has focused on passenger vehicles, and many unique challenges associated with heavy-duty vehicles remain open. However, recent works have started to tackle the particular difficulties related to on-road motion planning for buses and tractor-trailer vehicles using numerical optimization approaches. In this work, we propose a framework to design an optimization objective to be used in motion planners. Based on geometric derivations, the method finds the optimal trade-off between the conflicting objectives of centering different axles of the vehicle in the lane. For the buses, we consider the front and rear axles trade-off, whereas for articulated vehicles, we consider the tractor and trailer rear axles trade-off. Our results show that the proposed design strategy results in planned paths that considerably improve the behavior of heavy-duty vehicles by keeping the whole vehicle body in the center of the lane.
Just Go with the Flow: Self-Supervised Scene Flow Estimation
Dec 01, 2019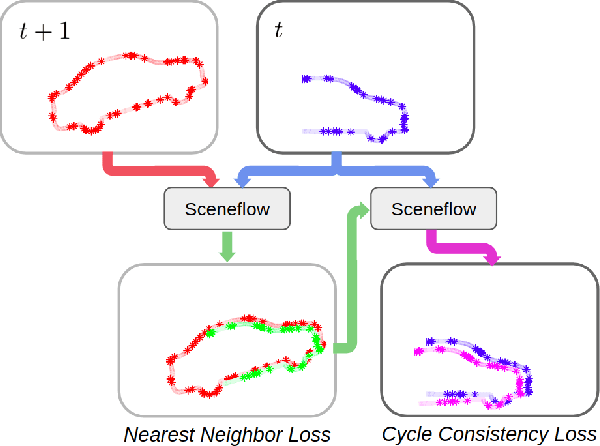

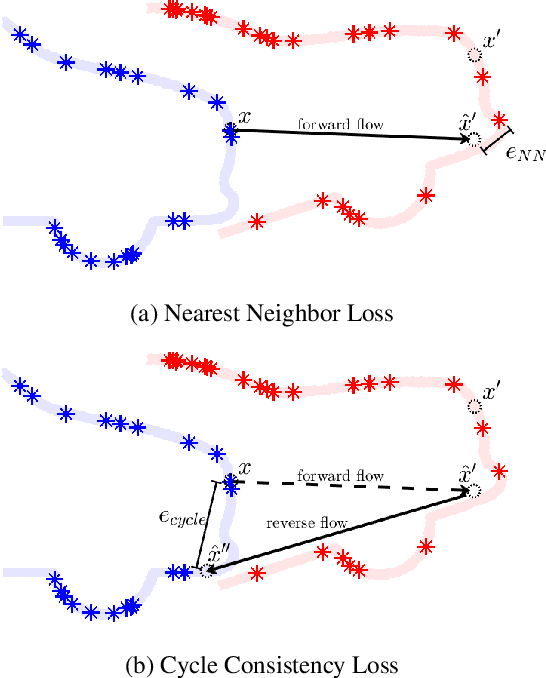
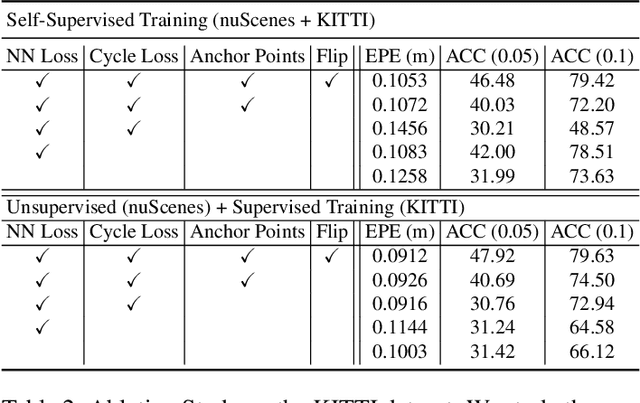
When interacting with highly dynamic environments, scene flow allows autonomous systems to reason about the non-rigid motion of multiple independent objects. This is of particular interest in the field of autonomous driving, in which many cars, people, bicycles, and other objects need to be accurately tracked. Current state of the art methods require annotated scene flow data from autonomous driving scenes to train scene flow networks with supervised learning. As an alternative, we present a method of training scene flow that uses two self-supervised losses, based on nearest neighbors and cycle consistency. These self-supervised losses allow us to train our method on large unlabeled autonomous driving datasets; the resulting method matches current state-of-the-art supervised performance using no real world annotations and exceeds state-of-the-art performance when combining our self-supervised approach with supervised learning on a smaller labeled dataset.
Plane-extraction from depth-data using a Gaussian mixture regression model
Mar 30, 2018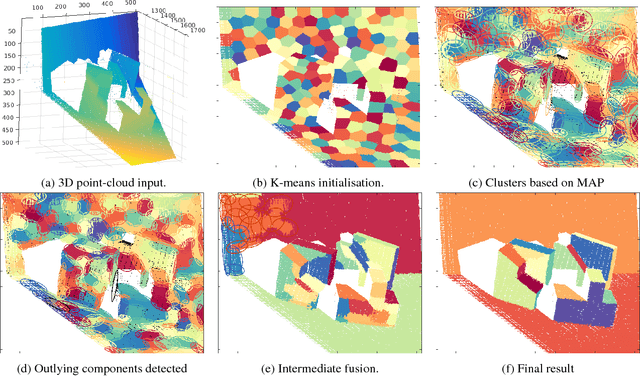
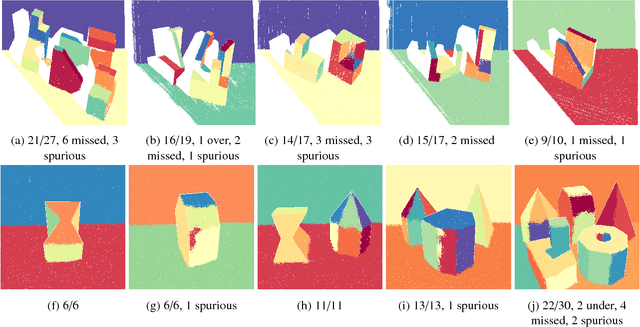
We propose a novel algorithm for unsupervised extraction of piecewise planar models from depth-data. Among other applications, such models are a good way of enabling autonomous agents (robots, cars, drones, etc.) to effectively perceive their surroundings and to navigate in three dimensions. We propose to do this by fitting the data with a piecewise-linear Gaussian mixture regression model whose components are skewed over planes, making them flat in appearance rather than being ellipsoidal, by embedding an outlier-trimming process that is formally incorporated into the proposed expectation-maximization algorithm, and by selectively fusing contiguous, coplanar components. Part of our motivation is an attempt to estimate more accurate plane-extraction by allowing each model component to make use of all available data through probabilistic clustering. The algorithm is thoroughly evaluated against a standard benchmark and is shown to rank among the best of the existing state-of-the-art methods.
* 11 pages, 2 figures, 1 table
Monitoring and Diagnosability of Perception Systems
May 27, 2020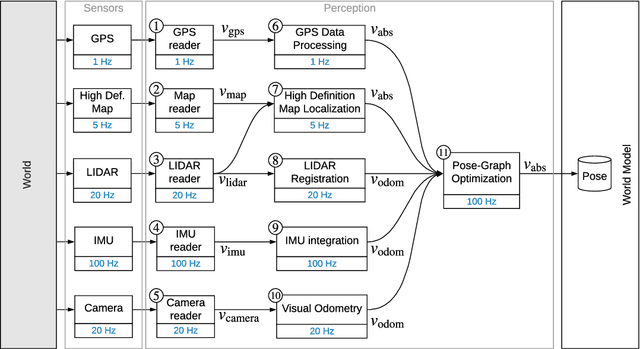
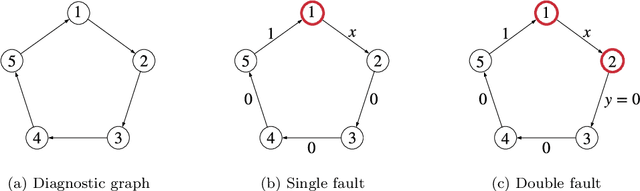
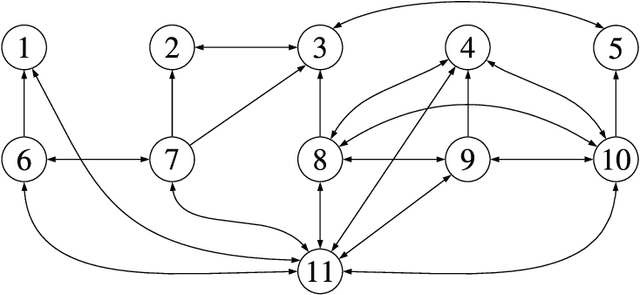
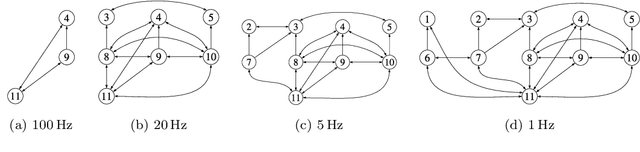
Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving cars. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies relies on the development of methodologies to guarantee and monitor safe operation as well as detect and mitigate failures. Despite the paramount importance of perception systems, currently there is no formal approach for system-level monitoring. In this work, we propose a mathematical model for runtime monitoring and fault detection of perception systems. Towards this goal, we draw connections with the literature on self-diagnosability for multiprocessor systems, and generalize it to (i) account for modules with heterogeneous outputs, and (ii) add a temporal dimension to the problem, which is crucial to model realistic perception systems where modules interact over time. This contribution results in a graph-theoretic approach that, given a perception system, is able to detect faults at runtime and allows computing an upper-bound on the number of faulty modules that can be detected. Our second contribution is to show that the proposed monitoring approach can be elegantly described with the language of topos theory, which allows formulating diagnosability over arbitrary time intervals.
Systematic Testing of Convolutional Neural Networks for Autonomous Driving
Aug 11, 2017
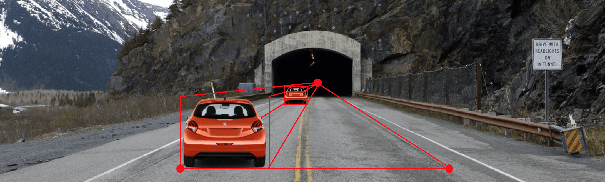
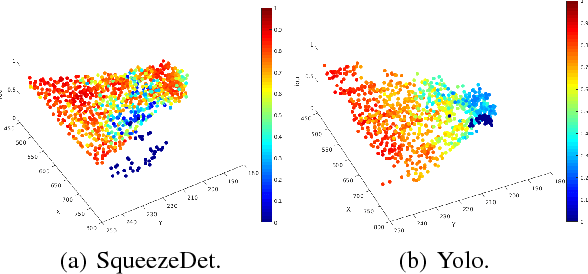
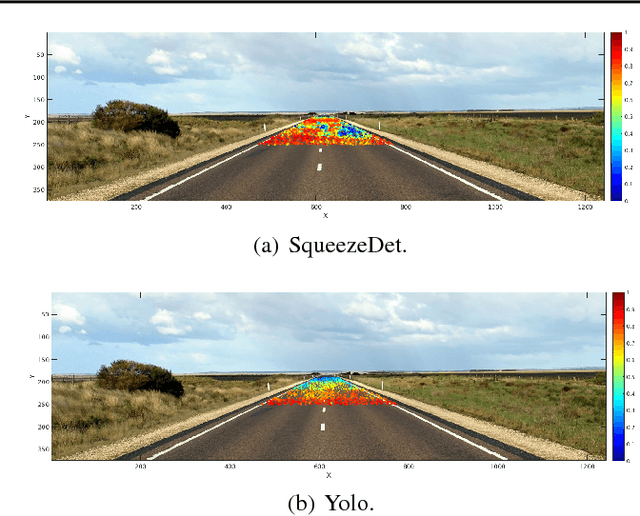
We present a framework to systematically analyze convolutional neural networks (CNNs) used in classification of cars in autonomous vehicles. Our analysis procedure comprises an image generator that produces synthetic pictures by sampling in a lower dimension image modification subspace and a suite of visualization tools. The image generator produces images which can be used to test the CNN and hence expose its vulnerabilities. The presented framework can be used to extract insights of the CNN classifier, compare across classification models, or generate training and validation datasets.
Real-Time Spatio-Temporal LiDAR Point Cloud Compression
Aug 16, 2020


Compressing massive LiDAR point clouds in real-time is critical to autonomous machines such as drones and self-driving cars. While most of the recent prior work has focused on compressing individual point cloud frames, this paper proposes a novel system that effectively compresses a sequence of point clouds. The idea to exploit both the spatial and temporal redundancies in a sequence of point cloud frames. We first identify a key frame in a point cloud sequence and spatially encode the key frame by iterative plane fitting. We then exploit the fact that consecutive point clouds have large overlaps in the physical space, and thus spatially encoded data can be (re-)used to encode the temporal stream. Temporal encoding by reusing spatial encoding data not only improves the compression rate, but also avoids redundant computations, which significantly improves the compression speed. Experiments show that our compression system achieves 40x to 90x compression rate, significantly higher than the MPEG's LiDAR point cloud compression standard, while retaining high end-to-end application accuracies. Meanwhile, our compression system has a compression speed that matches the point cloud generation rate by today LiDARs and out-performs existing compression systems, enabling real-time point cloud transmission.
A Tutorial On Autonomous Vehicle Steering Controller Design, Simulation and Implementation
Mar 10, 2018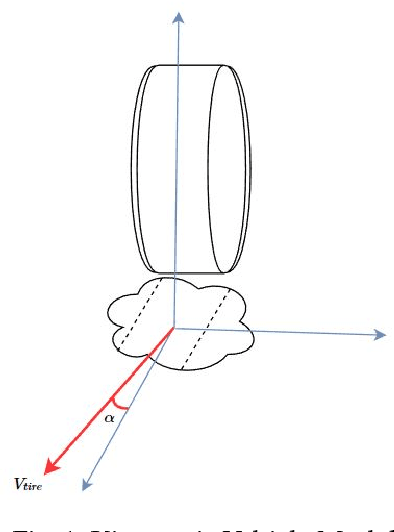
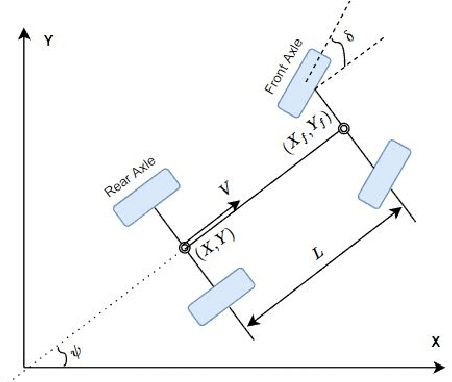
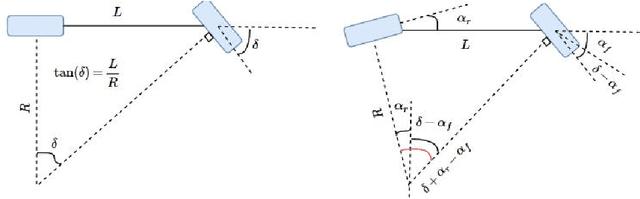
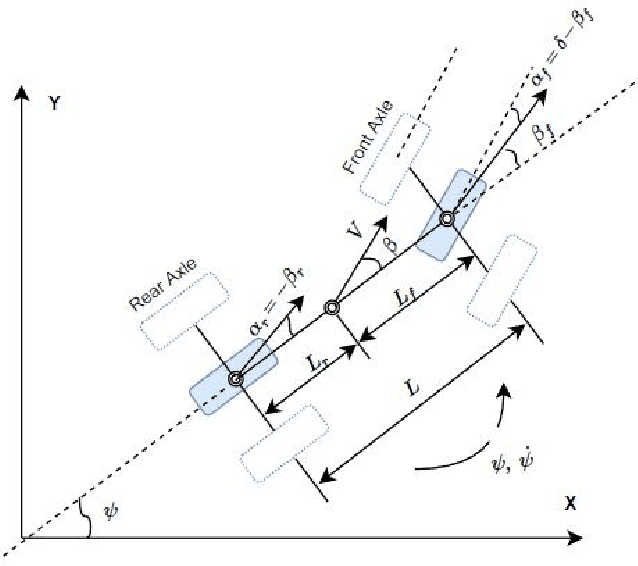
In this tutorial, we detailed simple controllers for autonomous parking and path following for self-driving cars and provided practical methods for curvature computation.
Input Prioritization for Testing Neural Networks
Jan 11, 2019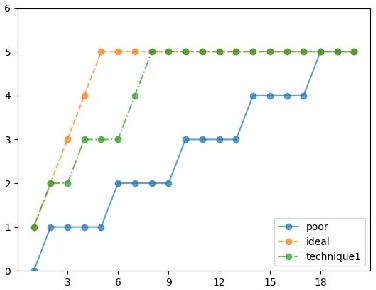
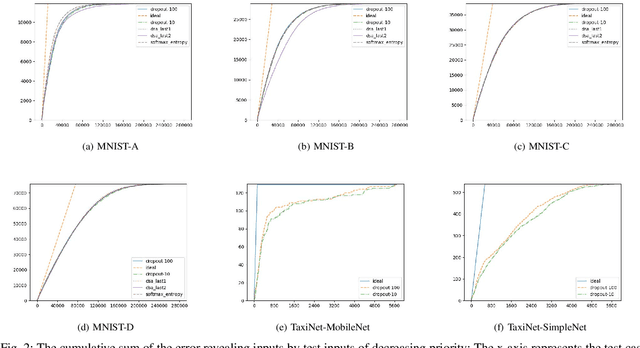


Deep neural networks (DNNs) are increasingly being adopted for sensing and control functions in a variety of safety and mission-critical systems such as self-driving cars, autonomous air vehicles, medical diagnostics, and industrial robotics. Failures of such systems can lead to loss of life or property, which necessitates stringent verification and validation for providing high assurance. Though formal verification approaches are being investigated, testing remains the primary technique for assessing the dependability of such systems. Due to the nature of the tasks handled by DNNs, the cost of obtaining test oracle data---the expected output, a.k.a. label, for a given input---is high, which significantly impacts the amount and quality of testing that can be performed. Thus, prioritizing input data for testing DNNs in meaningful ways to reduce the cost of labeling can go a long way in increasing testing efficacy. This paper proposes using gauges of the DNN's sentiment derived from the computation performed by the model, as a means to identify inputs that are likely to reveal weaknesses. We empirically assessed the efficacy of three such sentiment measures for prioritization---confidence, uncertainty, and surprise---and compare their effectiveness in terms of their fault-revealing capability and retraining effectiveness. The results indicate that sentiment measures can effectively flag inputs that expose unacceptable DNN behavior. For MNIST models, the average percentage of inputs correctly flagged ranged from 88% to 94.8%.