 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
UrbanScene3D: A Large Scale Urban Scene Dataset and Simulator
Jul 09, 2021
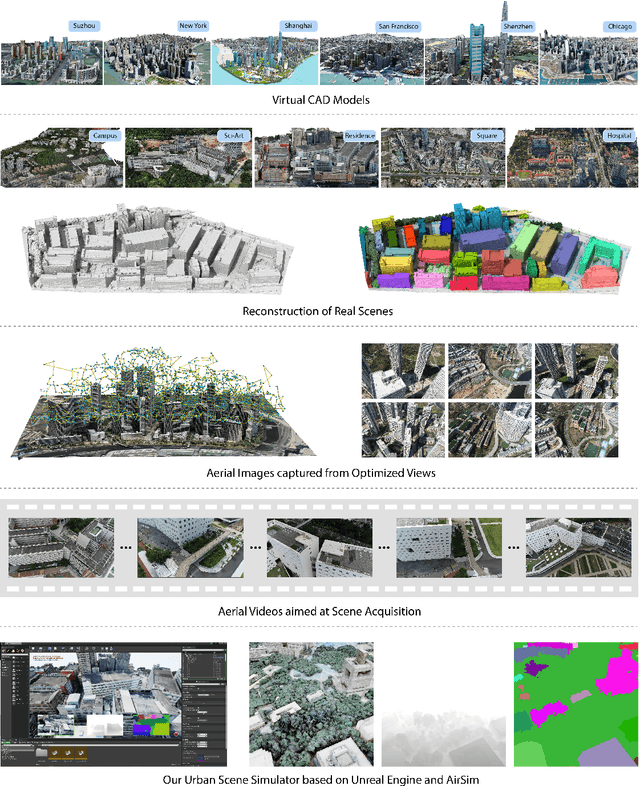
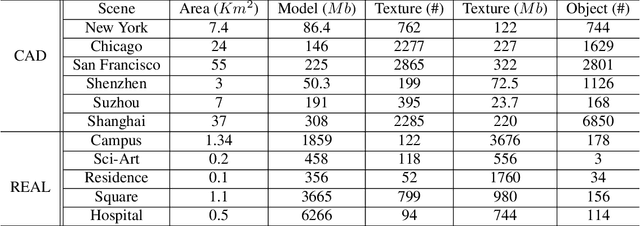
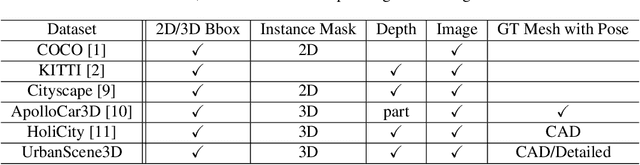
The ability to perceive the environments in different ways is essential to robotic research. This involves the analysis of both 2D and 3D data sources. We present a large scale urban scene dataset associated with a handy simulator based on Unreal Engine 4 and AirSim, which consists of both man-made and real-world reconstruction scenes in different scales, referred to as UrbanScene3D. Unlike previous works that purely based on 2D information or man-made 3D CAD models, UrbanScene3D contains both compact man-made models and detailed real-world models reconstructed by aerial images. Each building has been manually extracted from the entire scene model and then has been assigned with a unique label, forming an instance segmentation map. The provided 3D ground-truth textured models with instance segmentation labels in UrbanScene3D allow users to obtain all kinds of data they would like to have: instance segmentation map, depth map in arbitrary resolution, 3D point cloud/mesh in both visible and invisible places, etc. In addition, with the help of AirSim, users can also simulate the robots (cars/drones)to test a variety of autonomous tasks in the proposed city environment. Please refer to our paper and website(https://vcc.tech/UrbanScene3D/) for further details and applications.
Predictive Probability Path Planning Model For Dynamic Environments
Jul 29, 2020
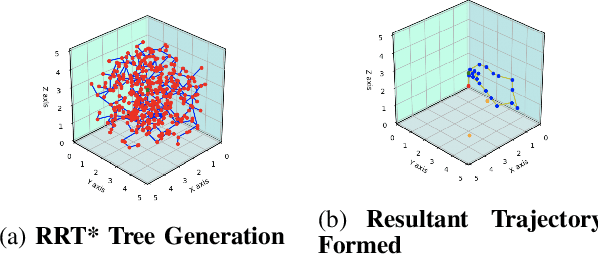
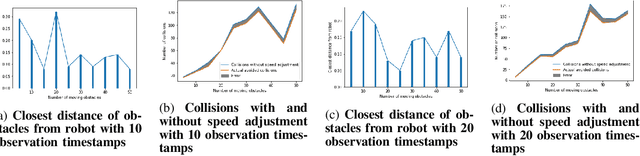
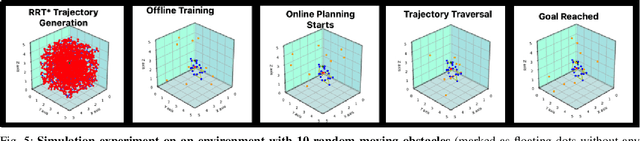
Path planning in dynamic environments is essential to high-risk applications such as unmanned aerial vehicles, self-driving cars, and autonomous underwater vehicles. In this paper, we generate collision-free trajectories for a robot within any given environment with temporal and spatial uncertainties caused due to randomly moving obstacles. We use two Poisson distributions to model the movements of obstacles across the generated trajectory of a robot in both space and time to determine the probability of collision with an obstacle. Measures are taken to avoid an obstacle by intelligently manipulating the speed of the robot at space-time intervals where a larger number of obstacles intersect the trajectory of the robot. Our method potentially reduces the use of computationally expensive collision detection libraries. Based on our experiments, there has been a significant improvement over existing methods in terms of safety, accuracy, execution time and computational cost. Our results show a high level of accuracy between the predicted and actual number of collisions with moving obstacles.
Adversarial Objects Against LiDAR-Based Autonomous Driving Systems
Jul 11, 2019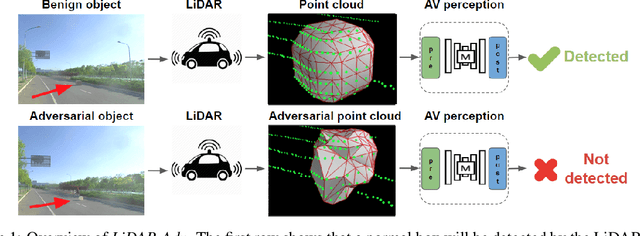


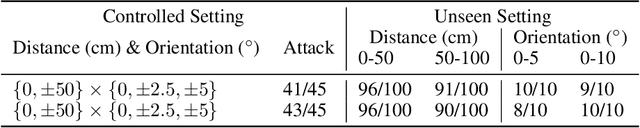
Deep neural networks (DNNs) are found to be vulnerable against adversarial examples, which are carefully crafted inputs with a small magnitude of perturbation aiming to induce arbitrarily incorrect predictions. Recent studies show that adversarial examples can pose a threat to real-world security-critical applications: a "physical adversarial Stop Sign" can be synthesized such that the autonomous driving cars will misrecognize it as others (e.g., a speed limit sign). However, these image-space adversarial examples cannot easily alter 3D scans of widely equipped LiDAR or radar on autonomous vehicles. In this paper, we reveal the potential vulnerabilities of LiDAR-based autonomous driving detection systems, by proposing an optimization based approach LiDAR-Adv to generate adversarial objects that can evade the LiDAR-based detection system under various conditions. We first show the vulnerabilities using a blackbox evolution-based algorithm, and then explore how much a strong adversary can do, using our gradient-based approach LiDAR-Adv. We test the generated adversarial objects on the Baidu Apollo autonomous driving platform and show that such physical systems are indeed vulnerable to the proposed attacks. We also 3D-print our adversarial objects and perform physical experiments to illustrate that such vulnerability exists in the real world. Please find more visualizations and results on the anonymous website: https://sites.google.com/view/lidar-adv.
Cloud2Edge Elastic AI Framework for Prototyping and Deployment of AI Inference Engines in Autonomous Vehicles
Sep 23, 2020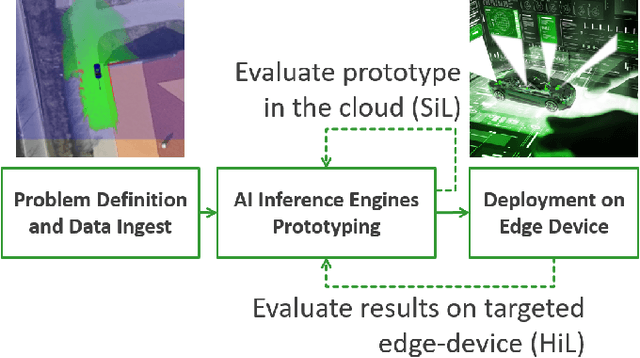
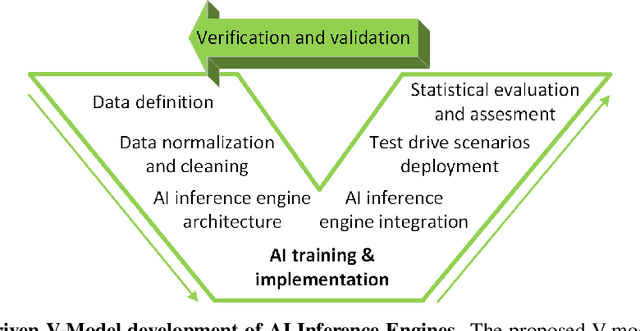
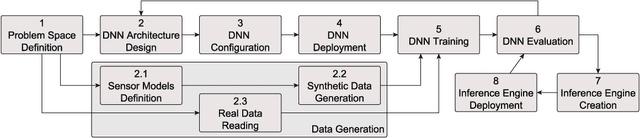
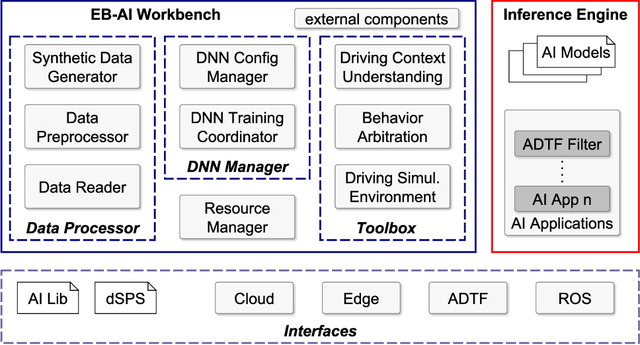
Self-driving cars and autonomous vehicles are revolutionizing the automotive sector, shaping the future of mobility altogether. Although the integration of novel technologies such as Artificial Intelligence (AI) and Cloud/Edge computing provides golden opportunities to improve autonomous driving applications, there is the need to modernize accordingly the whole prototyping and deployment cycle of AI components. This paper proposes a novel framework for developing so-called AI Inference Engines for autonomous driving applications based on deep learning modules, where training tasks are deployed elastically over both Cloud and Edge resources, with the purpose of reducing the required network bandwidth, as well as mitigating privacy issues. Based on our proposed data driven V-Model, we introduce a simple yet elegant solution for the AI components development cycle, where prototyping takes place in the cloud according to the Software-in-the-Loop (SiL) paradigm, while deployment and evaluation on the target ECUs (Electronic Control Units) is performed as Hardware-in-the-Loop (HiL) testing. The effectiveness of the proposed framework is demonstrated using two real-world use-cases of AI inference engines for autonomous vehicles, that is environment perception and most probable path prediction.
(AF)2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network
Feb 08, 2021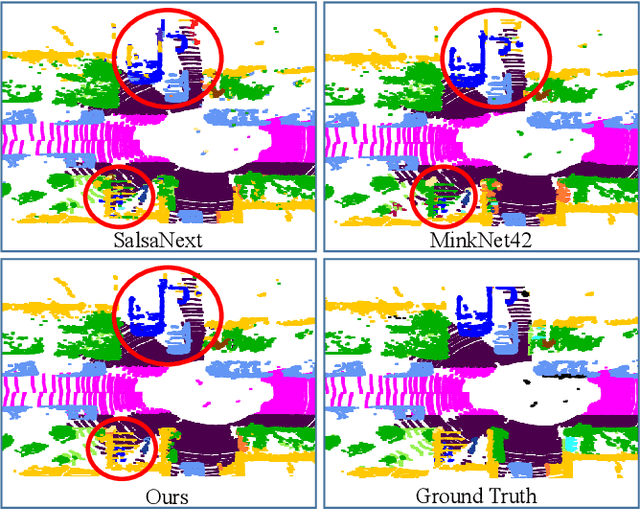
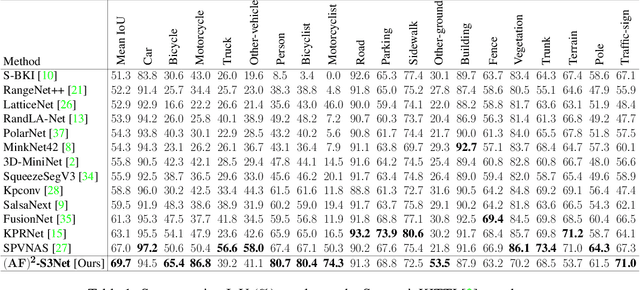
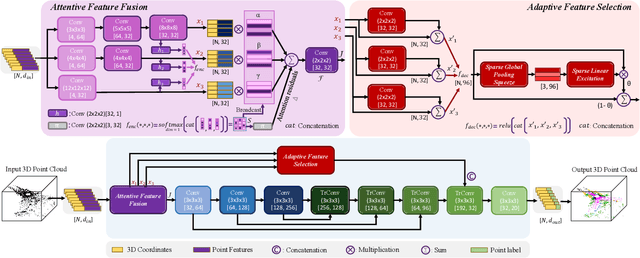

Autonomous robotic systems and self driving cars rely on accurate perception of their surroundings as the safety of the passengers and pedestrians is the top priority. Semantic segmentation is one the essential components of environmental perception that provides semantic information of the scene. Recently, several methods have been introduced for 3D LiDAR semantic segmentation. While, they can lead to improved performance, they are either afflicted by high computational complexity, therefore are inefficient, or lack fine details of smaller instances. To alleviate this problem, we propose AF2-S3Net, an end-to-end encoder-decoder CNN network for 3D LiDAR semantic segmentation. We present a novel multi-branch attentive feature fusion module in the encoder and a unique adaptive feature selection module with feature map re-weighting in the decoder. Our AF2-S3Net fuses the voxel based learning and point-based learning into a single framework to effectively process the large 3D scene. Our experimental results show that the proposed method outperforms the state-of-the-art approaches on the large-scale SemanticKITTI benchmark, ranking 1st on the competitive public leaderboard competition upon publication.
Probabilistic Safety-Assured Adaptive Merging Control for Autonomous Vehicles
Apr 29, 2021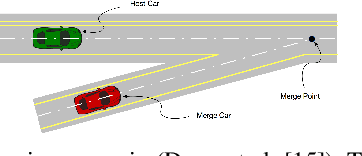
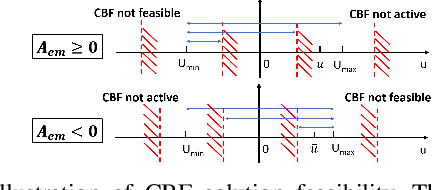
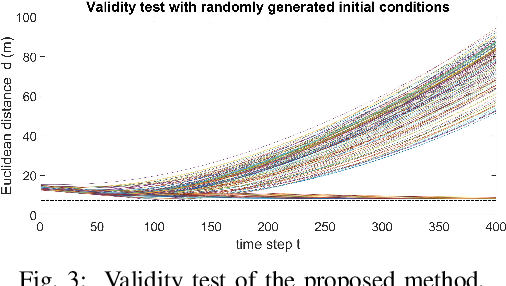
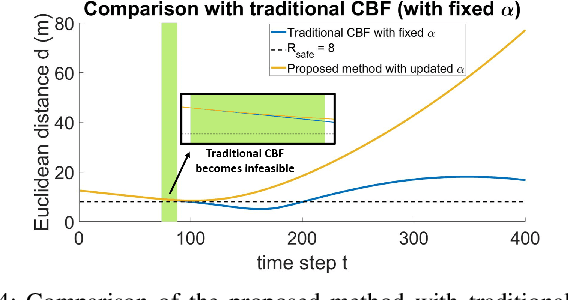
Autonomous vehicles face tremendous challenges while interacting with human drivers in different kinds of scenarios. Developing control methods with safety guarantees while performing interactions with uncertainty is an ongoing research goal. In this paper, we present a real-time safe control framework using bi-level optimization with Control Barrier Function (CBF) that enables an autonomous ego vehicle to interact with human-driven cars in ramp merging scenarios with a consistent safety guarantee. In order to explicitly address motion uncertainty, we propose a novel extension of control barrier functions to a probabilistic setting with provable chance-constrained safety and analyze the feasibility of our control design. The formulated bi-level optimization framework entails first choosing the ego vehicle's optimal driving style in terms of safety and primary objective, and then minimally modifying a nominal controller in the context of quadratic programming subject to the probabilistic safety constraints. This allows for adaptation to different driving strategies with a formally provable feasibility guarantee for the ego vehicle's safe controller. Experimental results are provided to demonstrate the effectiveness of our proposed approach.
Object Tracking by Detection with Visual and Motion Cues
Jan 19, 2021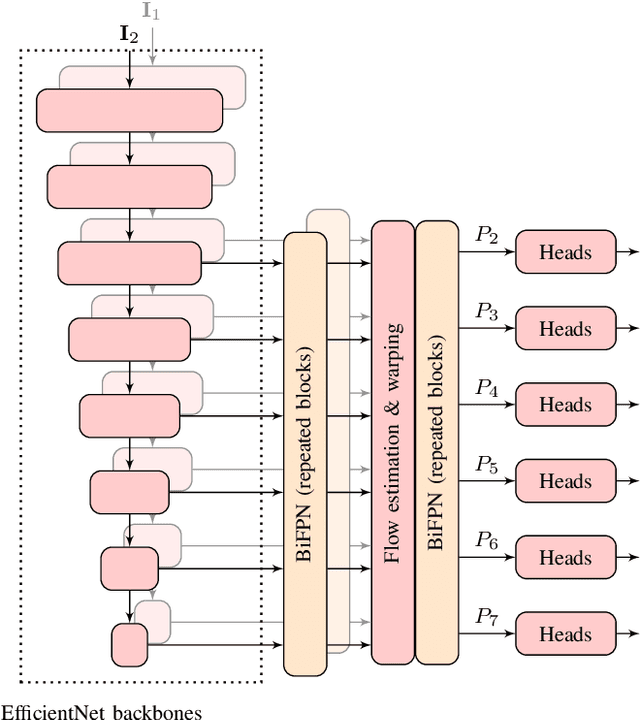
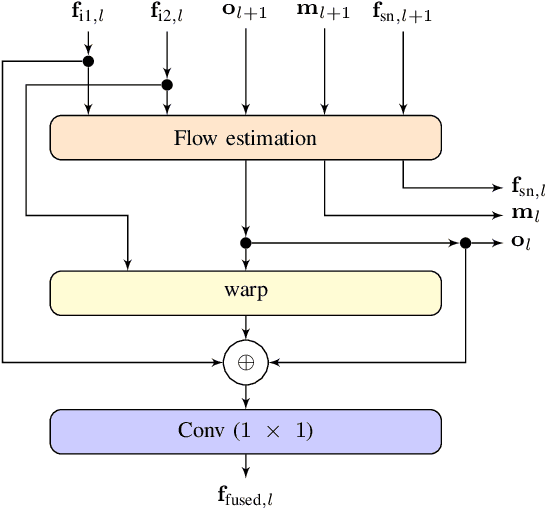
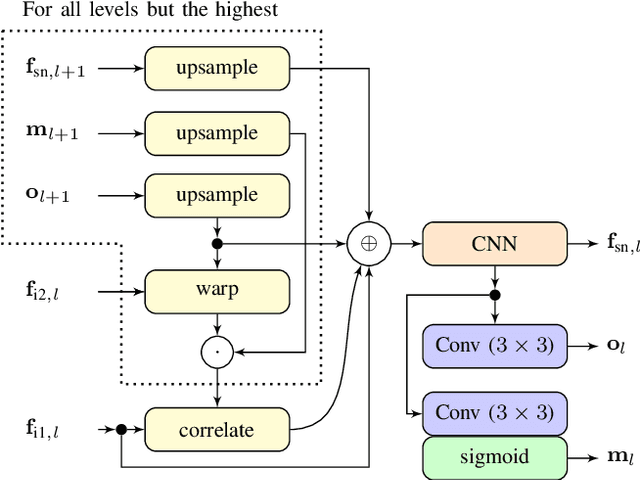
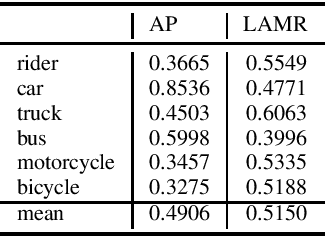
Self-driving cars and other autonomous vehicles need to detect and track objects in camera images. We present a simple online tracking algorithm that is based on a constant velocity motion model with a Kalman filter, and an assignment heuristic. The assignment heuristic relies on four metrics: An embedding vector that describes the appearance of objects and can be used to re-identify them, a displacement vector that describes the object movement between two consecutive video frames, the Mahalanobis distance between the Kalman filter states and the new detections, and a class distance. These metrics are combined with a linear SVM, and then the assignment problem is solved by the Hungarian algorithm. We also propose an efficient CNN architecture that estimates these metrics. Our multi-frame model accepts two consecutive video frames which are processed individually in the backbone, and then optical flow is estimated on the resulting feature maps. This allows the network heads to estimate the displacement vectors. We evaluate our approach on the challenging BDD100K tracking dataset. Our multi-frame model achieves a good MOTA value of 39.1% with low localization error of 0.206 in MOTP. Our fast single-frame model achieves an even lower localization error of 0.202 in MOTP, and a MOTA value of 36.8%.
Atlas Fusion -- Modern Framework for Autonomous Agent Sensor Data Fusion
Oct 22, 2020
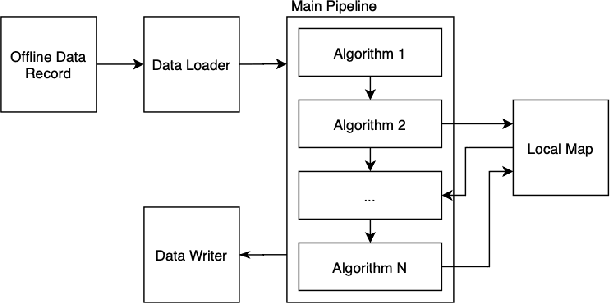
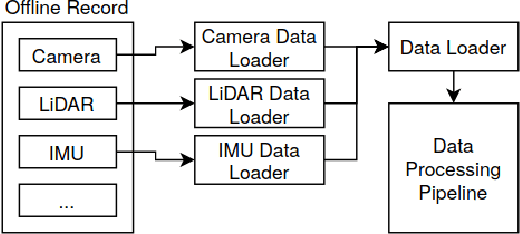
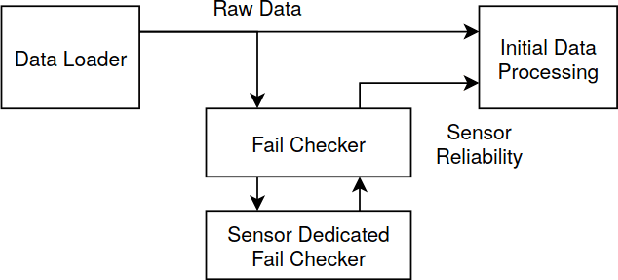
In this paper, we present our new sensor fusion framework for self-driving cars and other autonomous robots. We have designed our framework as a universal and scalable platform for building up a robust 3D model of the agent's surrounding environment by fusing a wide range of various sensors into the data model that we can use as a basement for the decision making and planning algorithms. Our software currently covers the data fusion of the RGB and thermal cameras, 3D LiDARs, 3D IMU, and a GNSS positioning. The framework covers a complete pipeline from data loading, filtering, preprocessing, environment model construction, visualization, and data storage. The architecture allows the community to modify the existing setup or to extend our solution with new ideas. The entire software is fully compatible with ROS (Robotic Operation System), which allows the framework to cooperate with other ROS-based software. The source codes are fully available as an open-source under the MIT license. See https://github.com/Robotics-BUT/Atlas-Fusion.
Hardware and Software Optimizations for Accelerating Deep Neural Networks: Survey of Current Trends, Challenges, and the Road Ahead
Dec 21, 2020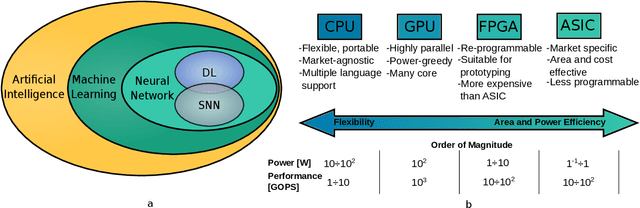

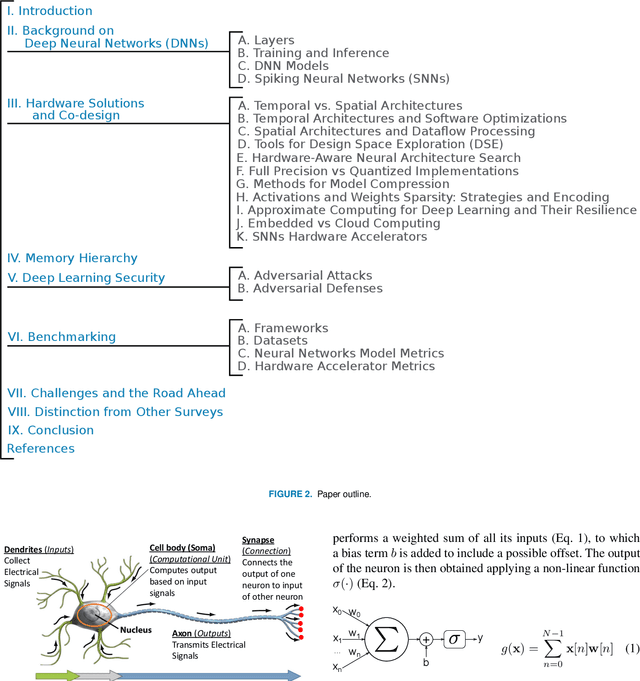
Currently, Machine Learning (ML) is becoming ubiquitous in everyday life. Deep Learning (DL) is already present in many applications ranging from computer vision for medicine to autonomous driving of modern cars as well as other sectors in security, healthcare, and finance. However, to achieve impressive performance, these algorithms employ very deep networks, requiring a significant computational power, both during the training and inference time. A single inference of a DL model may require billions of multiply-and-accumulated operations, making the DL extremely compute- and energy-hungry. In a scenario where several sophisticated algorithms need to be executed with limited energy and low latency, the need for cost-effective hardware platforms capable of implementing energy-efficient DL execution arises. This paper first introduces the key properties of two brain-inspired models like Deep Neural Network (DNN), and Spiking Neural Network (SNN), and then analyzes techniques to produce efficient and high-performance designs. This work summarizes and compares the works for four leading platforms for the execution of algorithms such as CPU, GPU, FPGA and ASIC describing the main solutions of the state-of-the-art, giving much prominence to the last two solutions since they offer greater design flexibility and bear the potential of high energy-efficiency, especially for the inference process. In addition to hardware solutions, this paper discusses some of the important security issues that these DNN and SNN models may have during their execution, and offers a comprehensive section on benchmarking, explaining how to assess the quality of different networks and hardware systems designed for them.
Attention-based 3D Object Reconstruction from a Single Image
Aug 11, 2020Recently, learning-based approaches for 3D reconstruction from 2D images have gained popularity due to its modern applications, e.g., 3D printers, autonomous robots, self-driving cars, virtual reality, and augmented reality. The computer vision community has applied a great effort in developing functions to reconstruct the full 3D geometry of objects and scenes. However, to extract image features, they rely on convolutional neural networks, which are ineffective in capturing long-range dependencies. In this paper, we propose to substantially improve Occupancy Networks, a state-of-the-art method for 3D object reconstruction. For such we apply the concept of self-attention within the network's encoder in order to leverage complementary input features rather than those based on local regions, helping the encoder to extract global information. With our approach, we were capable of improving the original work in 5.05% of mesh IoU, 0.83% of Normal Consistency, and more than 10X the Chamfer-L1 distance. We also perform a qualitative study that shows that our approach was able to generate much more consistent meshes, confirming its increased generalization power over the current state-of-the-art.
* 8 pages, 4 figures, 3 tables