 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Formula RL: Deep Reinforcement Learning for Autonomous Racing using Telemetry Data
Apr 22, 2021
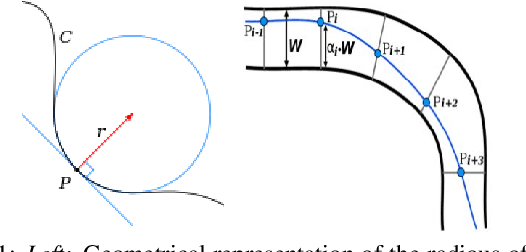

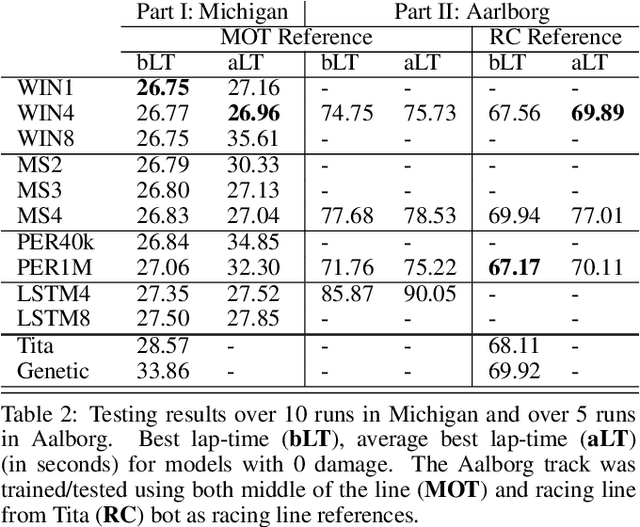
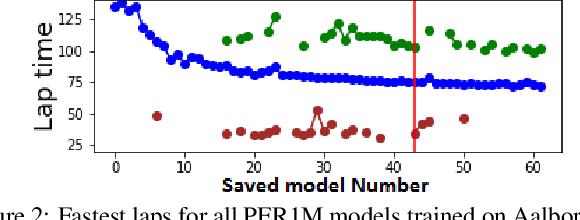
This paper explores the use of reinforcement learning (RL) models for autonomous racing. In contrast to passenger cars, where safety is the top priority, a racing car aims to minimize the lap-time. We frame the problem as a reinforcement learning task with a multidimensional input consisting of the vehicle telemetry, and a continuous action space. To find out which RL methods better solve the problem and whether the obtained models generalize to driving on unknown tracks, we put 10 variants of deep deterministic policy gradient (DDPG) to race in two experiments: i)~studying how RL methods learn to drive a racing car and ii)~studying how the learning scenario influences the capability of the models to generalize. Our studies show that models trained with RL are not only able to drive faster than the baseline open source handcrafted bots but also generalize to unknown tracks.
Learning-Based Safety-Stability-Driven Control for Safety-Critical Systems under Model Uncertainties
Aug 27, 2020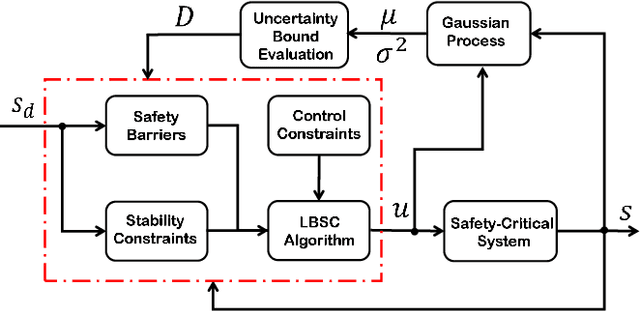
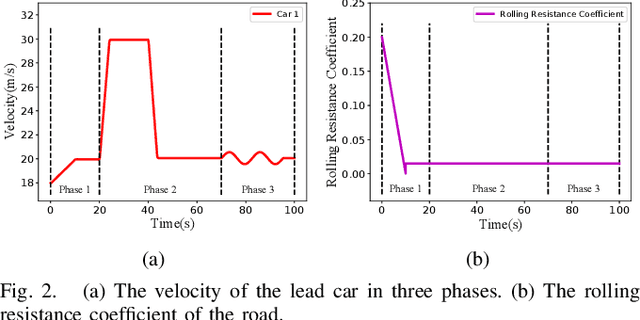
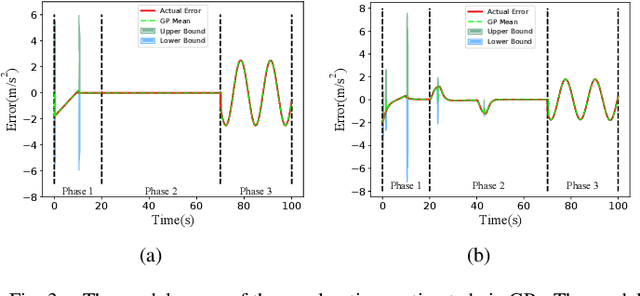
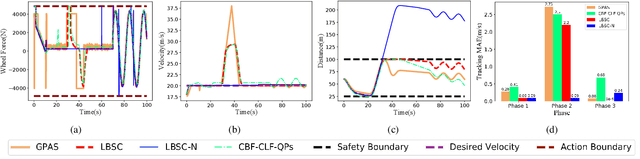
Safety and tracking stability are crucial for safety-critical systems such as self-driving cars, autonomous mobile robots, industrial manipulators. To efficiently control safety-critical systems to ensure their safety and achieve tracking stability, accurate system dynamic models are usually required. However, accurate system models are not always available in practice. In this paper, a learning-based safety-stability-driven control (LBSC) algorithm is presented to guarantee the safety and tracking stability for nonlinear safety-critical systems subject to control input constraints under model uncertainties. Gaussian Processes (GPs) are employed to learn the model error between the nominal model and the actual system dynamics, and the estimated mean and variance of the model error are used to quantify a high-confidence uncertainty bound. Using this estimated uncertainty bound, a safety barrier constraint is devised to ensure safety, and a stability constraint is developed to achieve rapid and accurate tracking. Then the proposed LBSC method is formulated as a quadratic program incorporating the safety barrier, the stability constraint, and the control constraints. The effectiveness of the LBSC method is illustrated on the safety-critical connected cruise control (CCC) system simulator under model uncertainties.
Game-Theoretic Modeling of Driver and Vehicle Interactions for Verification and Validation of Autonomous Vehicle Control Systems
Aug 30, 2016
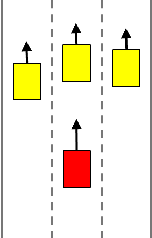
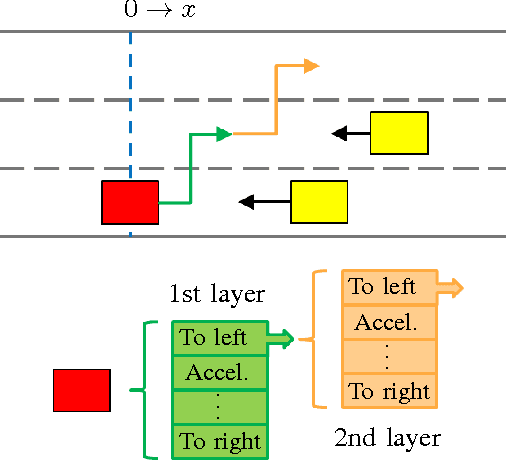
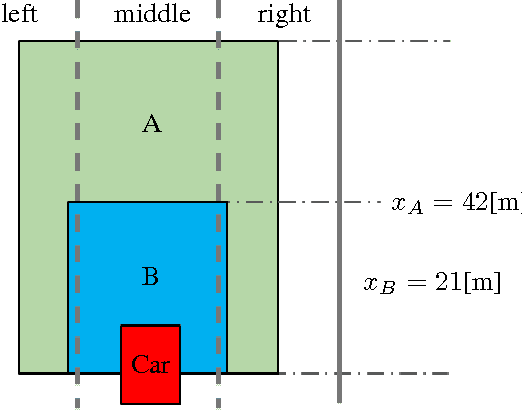
Autonomous driving has been the subject of increased interest in recent years both in industry and in academia. Serious efforts are being pursued to address legal, technical and logistical problems and make autonomous cars a viable option for everyday transportation. One significant challenge is the time and effort required for the verification and validation of the decision and control algorithms employed in these vehicles to ensure a safe and comfortable driving experience. Hundreds of thousands of miles of driving tests are required to achieve a well calibrated control system that is capable of operating an autonomous vehicle in an uncertain traffic environment where multiple interactions between vehicles and drivers simultaneously occur. Traffic simulators where these interactions can be modeled and represented with reasonable fidelity can help decrease the time and effort necessary for the development of the autonomous driving control algorithms by providing a venue where acceptable initial control calibrations can be achieved quickly and safely before actual road tests. In this paper, we present a game theoretic traffic model that can be used to 1) test and compare various autonomous vehicle decision and control systems and 2) calibrate the parameters of an existing control system. We demonstrate two example case studies, where, in the first case, we test and quantitatively compare two autonomous vehicle control systems in terms of their safety and performance, and, in the second case, we optimize the parameters of an autonomous vehicle control system, utilizing the proposed traffic model and simulation environment.
Spatiotemporal Deformable Models for Long-Term Complex Activity Detection
Apr 16, 2021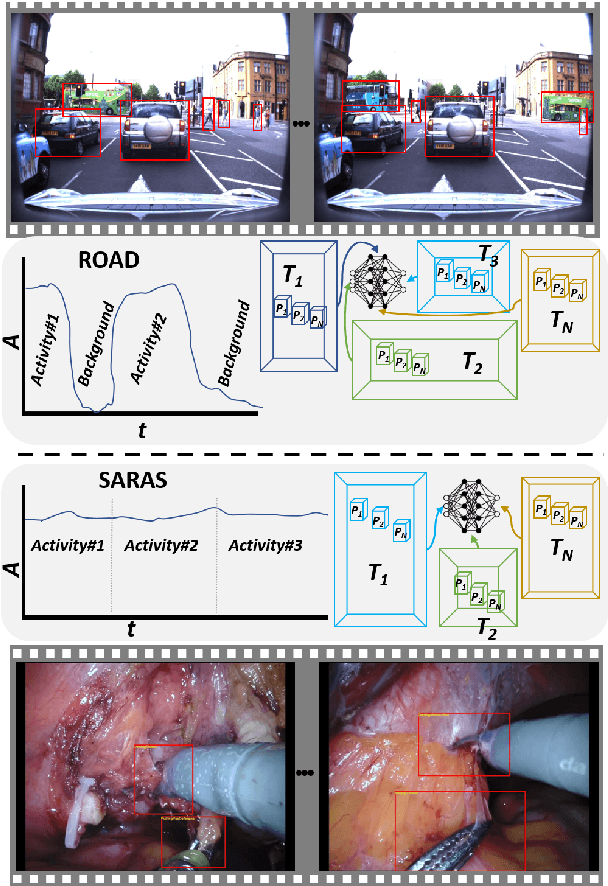
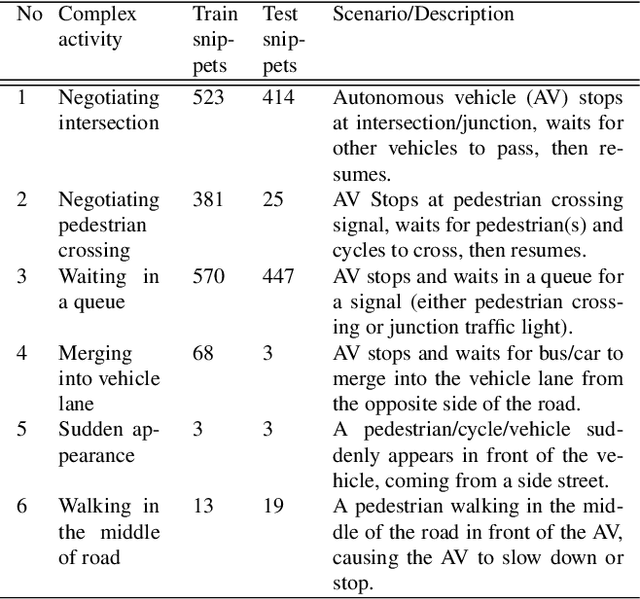
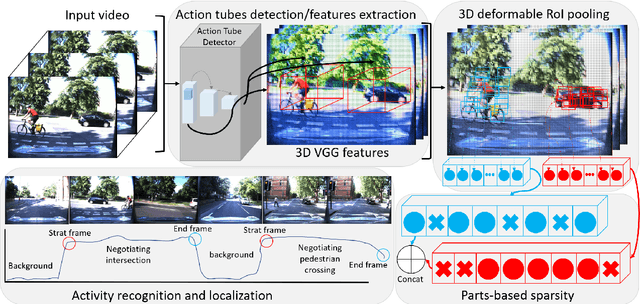
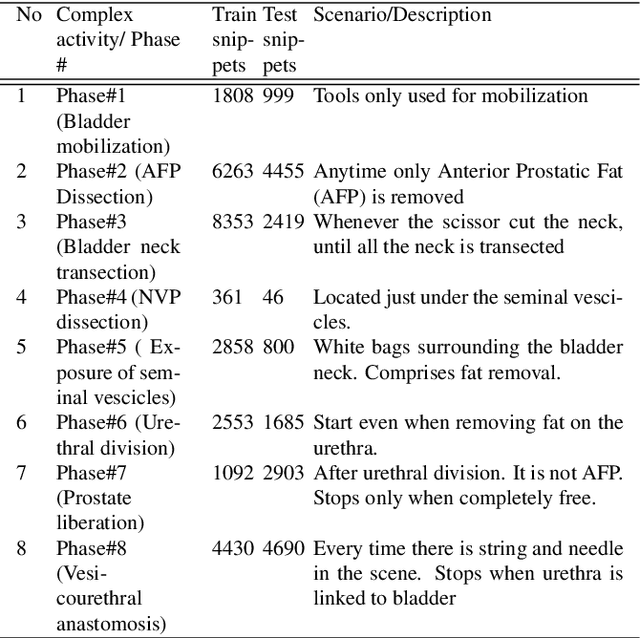
Long-term complex activity recognition and localisation can be crucial for the decision-making process of several autonomous systems, such as smart cars and surgical robots. Nonetheless, most current methods are designed to merely localise short-term action/activities or combinations of atomic actions that only last for a few frames or seconds. In this paper, we address the problem of long-term complex activity detection via a novel deformable, spatiotemporal parts-based model. Our framework consists of three main building blocks: (i) action tube detection, (ii) the modelling of the deformable geometry of parts, and (iii) a sparsity mechanism. Firstly, action tubes are detected in a series of snippets using an action tube detector. Next, a new 3D deformable RoI pooling layer is designed for learning the flexible, deformable geometry of the constellation of parts. Finally, a sparsity strategy differentiates between activated and deactivate features. We also provide temporal complex activity annotation for the recently released ROAD autonomous driving dataset and the SARAS-ESAD surgical action dataset, to validate our method and show the adaptability of our framework to different domains. As they both contain long videos portraying long-term activities they can be used as benchmarks for future work in this area.
An Efficient L-Shape Fitting Method for Vehicle Pose Detection with 2D LiDAR
Dec 23, 2018


Detecting vehicles with strong robustness and high efficiency has become one of the key capabilities of fully autonomous driving cars. This topic has already been widely studied by GPU-accelerated deep learning approaches using image sensors and 3D LiDAR, however, few studies seek to address it with a horizontally mounted 2D laser scanner. 2D laser scanner is equipped on almost every autonomous vehicle for its superiorities in the field of view, lighting invariance, high accuracy and relatively low price. In this paper, we propose a highly efficient search-based L-Shape fitting algorithm for detecting positions and orientations of vehicles with a 2D laser scanner. Differing from the approach to formulating LShape fitting as a complex optimization problem, our method decomposes the L-Shape fitting into two steps: L-Shape vertexes searching and L-Shape corner localization. Our approach is computationally efficient due to its minimized complexity. In on-road experiments, our approach is capable of adapting to various circumstances with high efficiency and robustness.
Lidar Light Scattering Augmentation (LISA): Physics-based Simulation of Adverse Weather Conditions for 3D Object Detection
Jul 14, 2021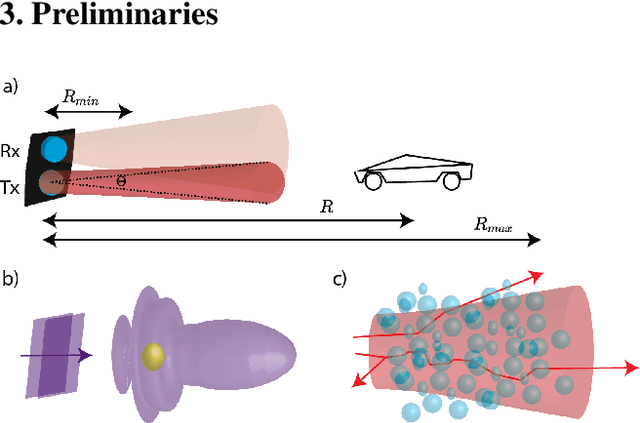
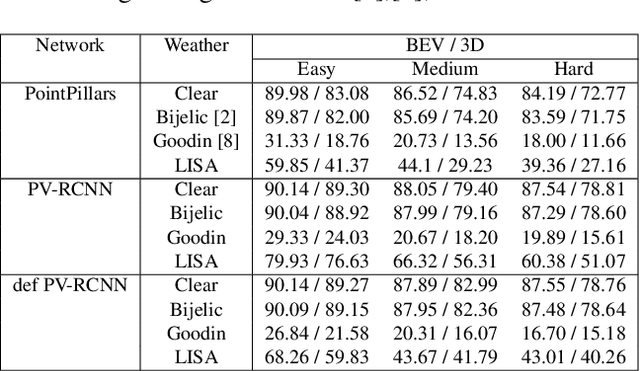
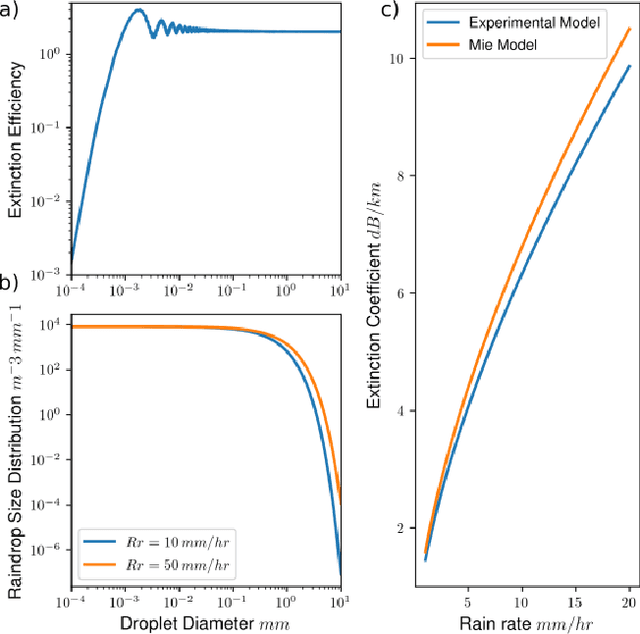
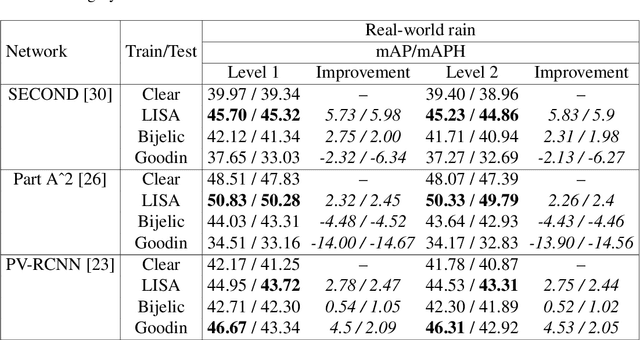
Lidar-based object detectors are critical parts of the 3D perception pipeline in autonomous navigation systems such as self-driving cars. However, they are known to be sensitive to adverse weather conditions such as rain, snow and fog due to reduced signal-to-noise ratio (SNR) and signal-to-background ratio (SBR). As a result, lidar-based object detectors trained on data captured in normal weather tend to perform poorly in such scenarios. However, collecting and labelling sufficient training data in a diverse range of adverse weather conditions is laborious and prohibitively expensive. To address this issue, we propose a physics-based approach to simulate lidar point clouds of scenes in adverse weather conditions. These augmented datasets can then be used to train lidar-based detectors to improve their all-weather reliability. Specifically, we introduce a hybrid Monte-Carlo based approach that treats (i) the effects of large particles by placing them randomly and comparing their back reflected power against the target, and (ii) attenuation effects on average through calculation of scattering efficiencies from the Mie theory and particle size distributions. Retraining networks with this augmented data improves mean average precision evaluated on real world rainy scenes and we observe greater improvement in performance with our model relative to existing models from the literature. Furthermore, we evaluate recent state-of-the-art detectors on the simulated weather conditions and present an in-depth analysis of their performance.
Inferring Temporal Logic Properties from Data using Boosted Decision Trees
May 24, 2021
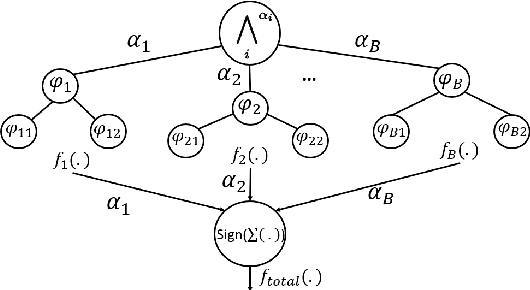
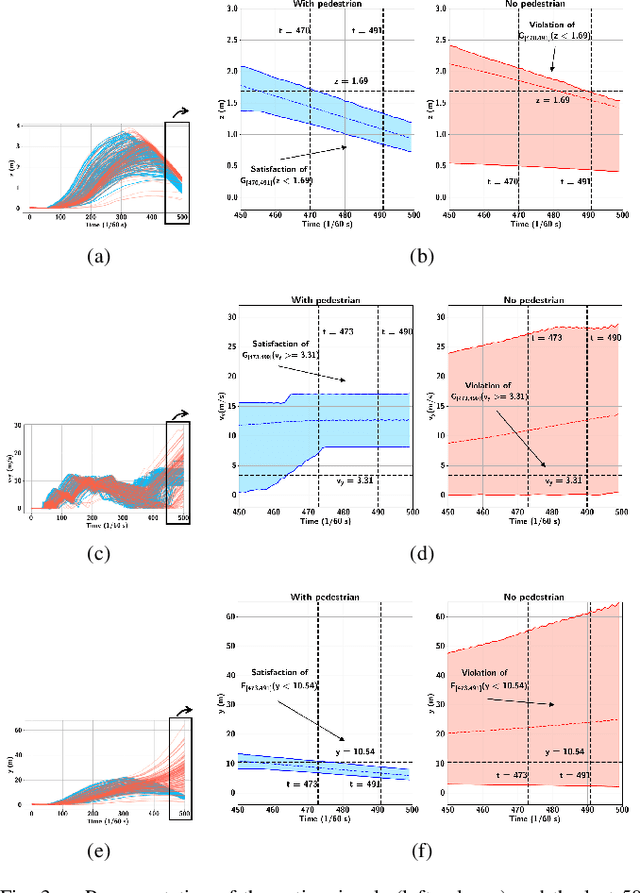
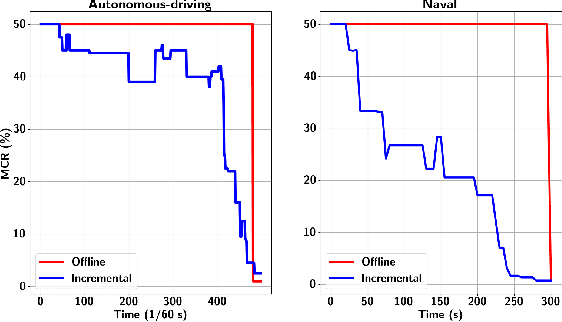
Many autonomous systems, such as robots and self-driving cars, involve real-time decision making in complex environments, and require prediction of future outcomes from limited data. Moreover, their decisions are increasingly required to be interpretable to humans for safe and trustworthy co-existence. This paper is a first step towards interpretable learning-based robot control. We introduce a novel learning problem, called incremental formula and predictor learning, to generate binary classifiers with temporal logic structure from time-series data. The classifiers are represented as pairs of Signal Temporal Logic (STL) formulae and predictors for their satisfaction. The incremental property provides prediction of labels for prefix signals that are revealed over time. We propose a boosted decision-tree algorithm that leverages weak, but computationally inexpensive, learners to increase prediction and runtime performance. The effectiveness and classification accuracy of our algorithms are evaluated on autonomous-driving and naval surveillance case studies.
Full-Glow: Fully conditional Glow for more realistic image generation
Dec 10, 2020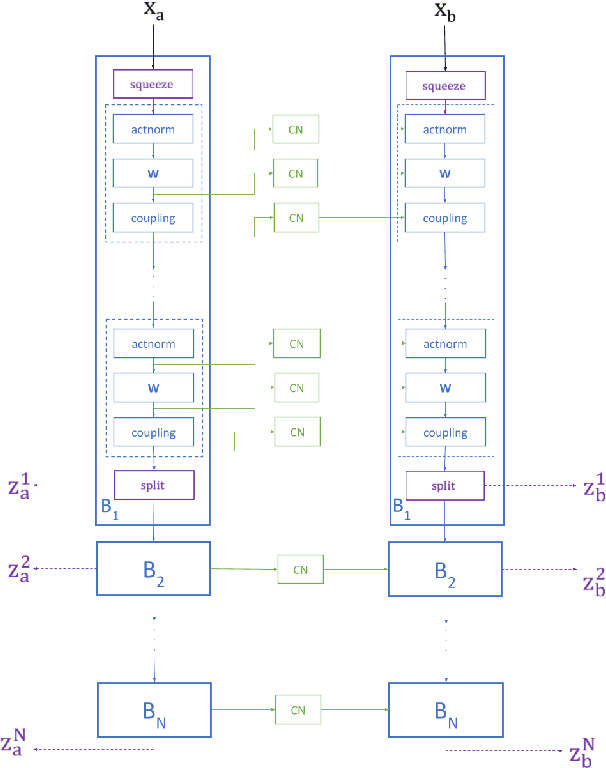
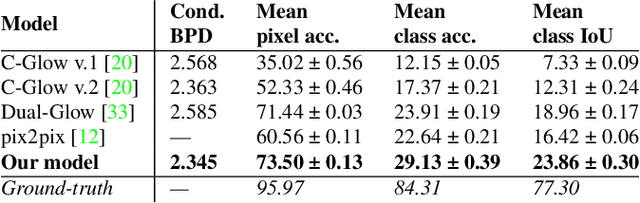


Autonomous agents, such as driverless cars, require large amounts of labeled visual data for their training. A viable approach for acquiring such data is training a generative model with collected real data, and then augmenting the collected real dataset with synthetic images from the model, generated with control of the scene layout and ground truth labeling. In this paper we propose Full-Glow, a fully conditional Glow-based architecture for generating plausible and realistic images of novel street scenes given a semantic segmentation map indicating the scene layout. Benchmark comparisons show our model to outperform recent works in terms of the semantic segmentation performance of a pretrained PSPNet. This indicates that images from our model are, to a higher degree than from other models, similar to real images of the same kinds of scenes and objects, making them suitable as training data for a visual semantic segmentation or object recognition system.