 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Verisimilar Percept Sequences Tests for Autonomous Driving Intelligent Agent Assessment
May 07, 2018
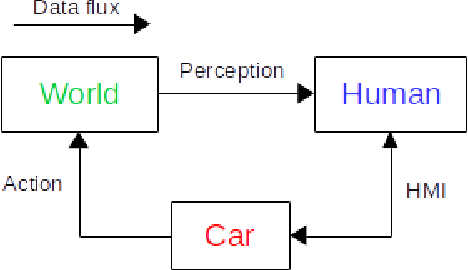
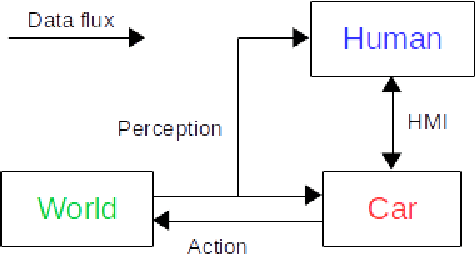
The autonomous car technology promises to replace human drivers with safer driving systems. But although autonomous cars can become safer than human drivers this is a long process that is going to be refined over time. Before these vehicles are deployed on urban roads a minimum safety level must be assured. Since the autonomous car technology is still under development there is no standard methodology to evaluate such systems. It is important to completely understand the technology that is being developed to design efficient means to evaluate it. In this paper we assume safety-critical systems reliability as a safety measure. We model an autonomous road vehicle as an intelligent agent and we approach its evaluation from an artificial intelligence perspective. Our focus is the evaluation of perception and decision making systems and also to propose a systematic method to evaluate their integration in the vehicle. We identify critical aspects of the data dependency from the artificial intelligence state of the art models and we also propose procedures to reproduce them.
Motion Sickness Modeling with Visual Vertical Estimation and Its Application to Autonomous Personal Mobility Vehicles
Feb 20, 2022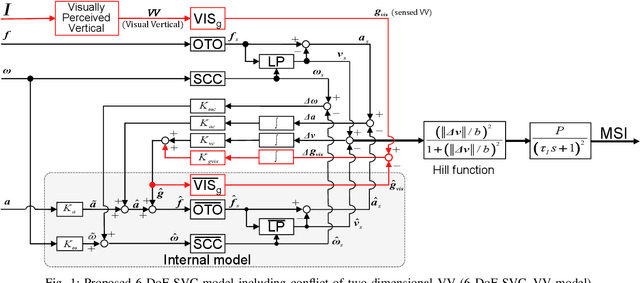


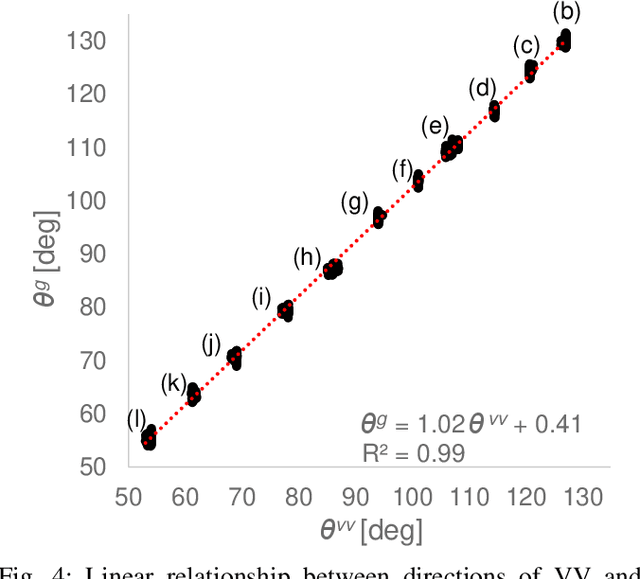
Passengers (drivers) of level 3-5 autonomous personal mobility vehicles (APMV) and cars can perform non-driving tasks, such as reading books and smartphones, while driving. It has been pointed out that such activities may increase motion sickness. Many studies have been conducted to build countermeasures, of which various computational motion sickness models have been developed. Many of these are based on subjective vertical conflict (SVC) theory, which describes vertical changes in direction sensed by human sensory organs vs. those expected by the central nervous system. Such models are expected to be applied to autonomous driving scenarios. However, no current computational model can integrate visual vertical information with vestibular sensations. We proposed a 6 DoF SVC-VV model which add a visually perceived vertical block into a conventional six-degrees-of-freedom SVC model to predict VV directions from image data simulating the visual input of a human. Hence, a simple image-based VV estimation method is proposed. As the validation of the proposed model, this paper focuses on describing the fact that the motion sickness increases as a passenger reads a book while using an AMPV, assuming that visual vertical (VV) plays an important role. In the static experiment, it is demonstrated that the estimated VV by the proposed method accurately described the gravitational acceleration direction with a low mean absolute deviation. In addition, the results of the driving experiment using an APMV demonstrated that the proposed 6 DoF SVC-VV model could describe that the increased motion sickness experienced when the VV and gravitational acceleration directions were different.
Social Cohesion in Autonomous Driving
Aug 27, 2018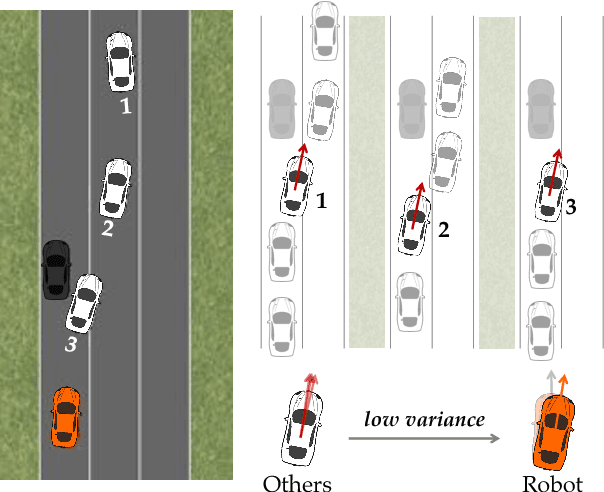

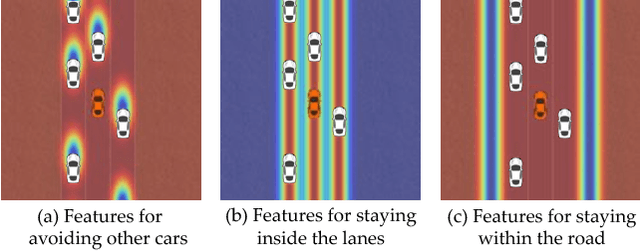
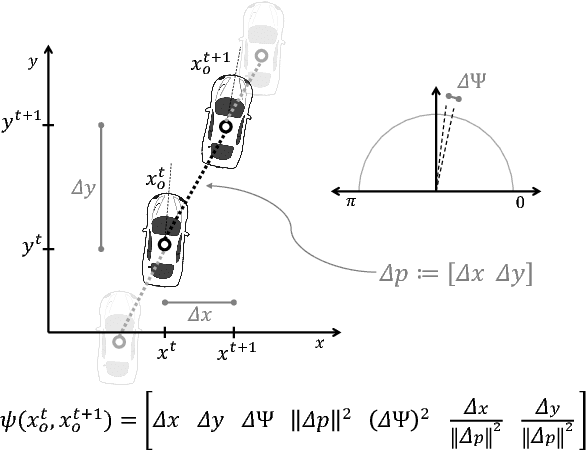
Autonomous cars can perform poorly for many reasons. They may have perception issues, incorrect dynamics models, be unaware of obscure rules of human traffic systems, or follow certain rules too conservatively. Regardless of the exact failure mode of the car, often human drivers around the car are behaving correctly. For example, even if the car does not know that it should pull over when an ambulance races by, other humans on the road will know and will pull over. We propose to make socially cohesive cars that leverage the behavior of nearby human drivers to act in ways that are safer and more socially acceptable. The simple intuition behind our algorithm is that if all the humans are consistently behaving in a particular way, then the autonomous car probably should too. We analyze the performance of our algorithm in a variety of scenarios and conduct a user study to assess people's attitudes towards socially cohesive cars. We find that people are surprisingly tolerant of mistakes that cohesive cars might make in order to get the benefits of driving in a car with a safer, or even just more socially acceptable behavior.
Blaming humans in autonomous vehicle accidents: Shared responsibility across levels of automation
Mar 21, 2018
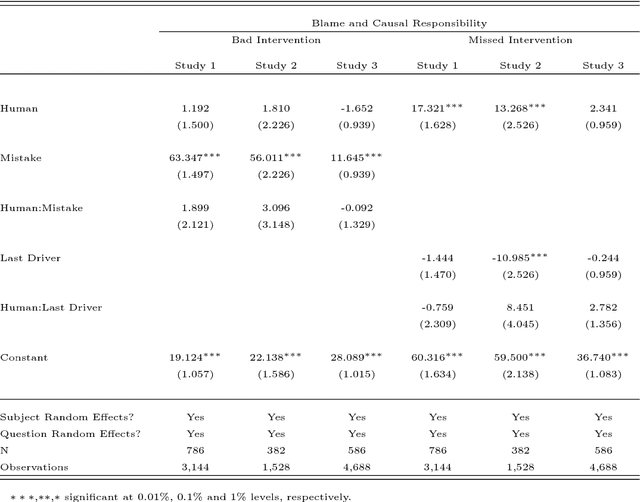
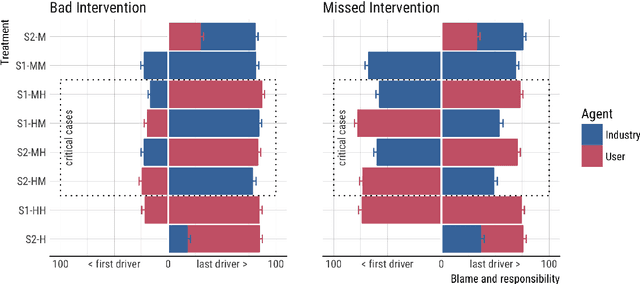
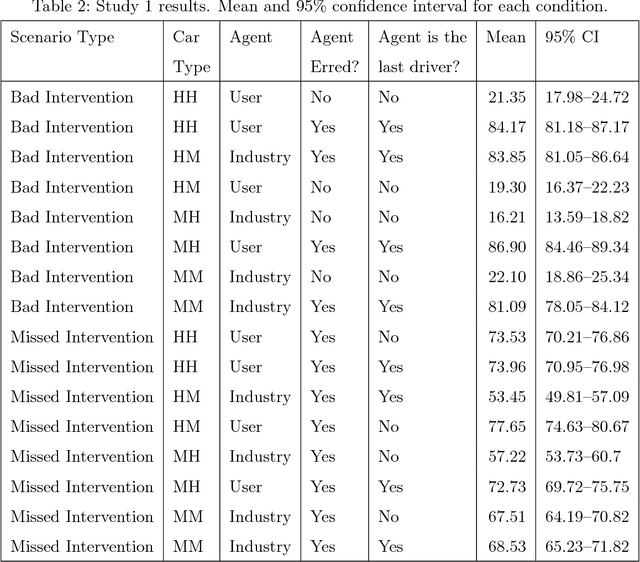
When a semi-autonomous car crashes and harms someone, how are blame and causal responsibility distributed across the human and machine drivers? In this article, we consider cases in which a pedestrian was hit and killed by a car being operated under shared control of a primary and a secondary driver. We find that when only one driver makes an error, that driver receives the blame and is considered causally responsible for the harm, regardless of whether that driver is a machine or a human. However, when both drivers make errors in cases of shared control between a human and a machine, the blame and responsibility attributed to the machine is reduced. This finding portends a public under-reaction to the malfunctioning AI components of semi-autonomous cars and therefore has a direct policy implication: a bottom-up regulatory scheme (which operates through tort law that is adjudicated through the jury system) could fail to properly regulate the safety of shared-control vehicles; instead, a top-down scheme (enacted through federal laws) may be called for.
One-Step Time-Dependent Future Video Frame Prediction with a Convolutional Encoder-Decoder Neural Network
Jul 24, 2017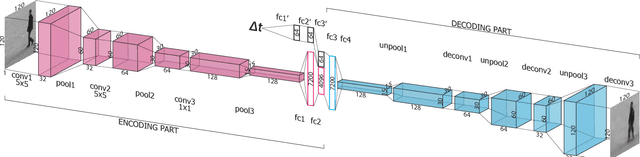
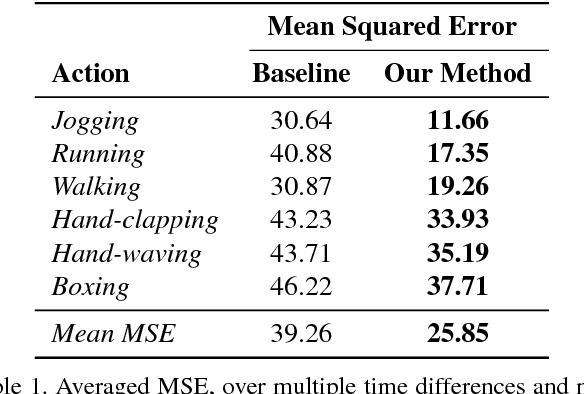


There is an inherent need for autonomous cars, drones, and other robots to have a notion of how their environment behaves and to anticipate changes in the near future. In this work, we focus on anticipating future appearance given the current frame of a video. Existing work focuses on either predicting the future appearance as the next frame of a video, or predicting future motion as optical flow or motion trajectories starting from a single video frame. This work stretches the ability of CNNs (Convolutional Neural Networks) to predict an anticipation of appearance at an arbitrarily given future time, not necessarily the next video frame. We condition our predicted future appearance on a continuous time variable that allows us to anticipate future frames at a given temporal distance, directly from the input video frame. We show that CNNs can learn an intrinsic representation of typical appearance changes over time and successfully generate realistic predictions at a deliberate time difference in the near future.
Provably Safe Robot Navigation with Obstacle Uncertainty
May 31, 2017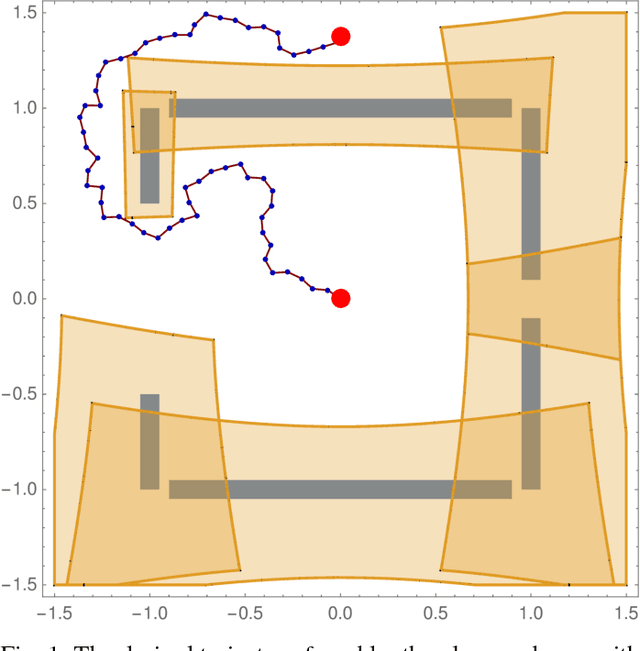
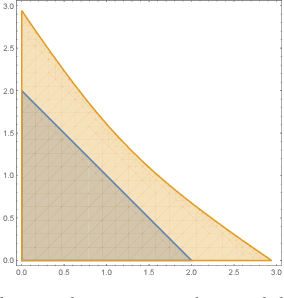
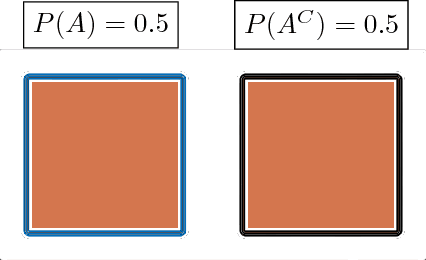

As drones and autonomous cars become more widespread it is becoming increasingly important that robots can operate safely under realistic conditions. The noisy information fed into real systems means that robots must use estimates of the environment to plan navigation. Efficiently guaranteeing that the resulting motion plans are safe under these circumstances has proved difficult. We examine how to guarantee that a trajectory or policy is safe with only imperfect observations of the environment. We examine the implications of various mathematical formalisms of safety and arrive at a mathematical notion of safety of a long-term execution, even when conditioned on observational information. We present efficient algorithms that can prove that trajectories or policies are safe with much tighter bounds than in previous work. Notably, the complexity of the environment does not affect our methods ability to evaluate if a trajectory or policy is safe. We then use these safety checking methods to design a safe variant of the RRT planning algorithm.
Learning Where to Attend Like a Human Driver
May 09, 2017
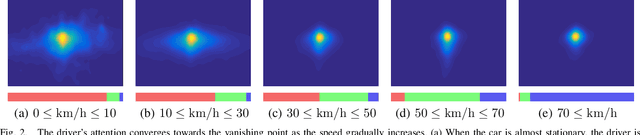


Despite the advent of autonomous cars, it's likely - at least in the near future - that human attention will still maintain a central role as a guarantee in terms of legal responsibility during the driving task. In this paper we study the dynamics of the driver's gaze and use it as a proxy to understand related attentional mechanisms. First, we build our analysis upon two questions: where and what the driver is looking at? Second, we model the driver's gaze by training a coarse-to-fine convolutional network on short sequences extracted from the DR(eye)VE dataset. Experimental comparison against different baselines reveal that the driver's gaze can indeed be learnt to some extent, despite i) being highly subjective and ii) having only one driver's gaze available for each sequence due to the irreproducibility of the scene. Eventually, we advocate for a new assisted driving paradigm which suggests to the driver, with no intervention, where she should focus her attention.
Deep Lidar CNN to Understand the Dynamics of Moving Vehicles
Aug 30, 2018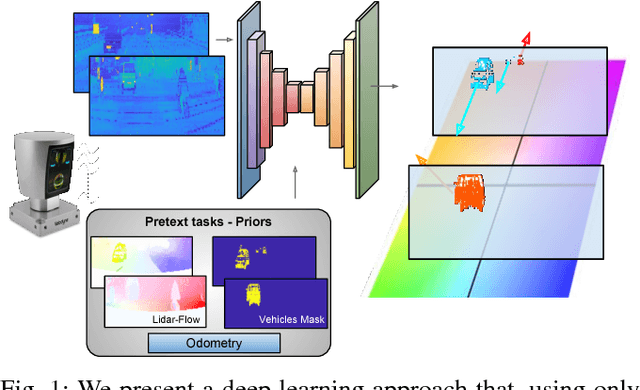
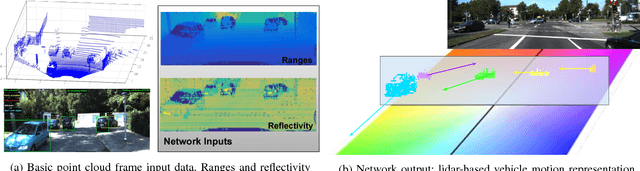
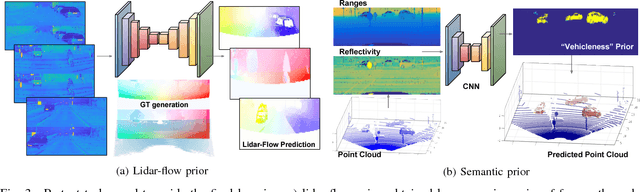
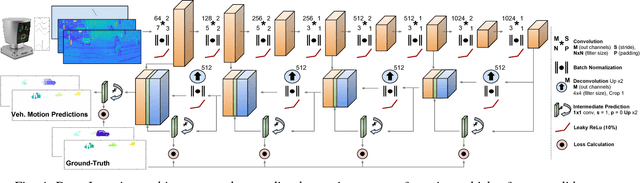
Perception technologies in Autonomous Driving are experiencing their golden age due to the advances in Deep Learning. Yet, most of these systems rely on the semantically rich information of RGB images. Deep Learning solutions applied to the data of other sensors typically mounted on autonomous cars (e.g. lidars or radars) are not explored much. In this paper we propose a novel solution to understand the dynamics of moving vehicles of the scene from only lidar information. The main challenge of this problem stems from the fact that we need to disambiguate the proprio-motion of the 'observer' vehicle from that of the external 'observed' vehicles. For this purpose, we devise a CNN architecture which at testing time is fed with pairs of consecutive lidar scans. However, in order to properly learn the parameters of this network, during training we introduce a series of so-called pretext tasks which also leverage on image data. These tasks include semantic information about vehicleness and a novel lidar-flow feature which combines standard image-based optical flow with lidar scans. We obtain very promising results and show that including distilled image information only during training, allows improving the inference results of the network at test time, even when image data is no longer used.
A New Simulation Metric to Determine Safe Environments and Controllers for Systems with Unknown Dynamics
Feb 27, 2019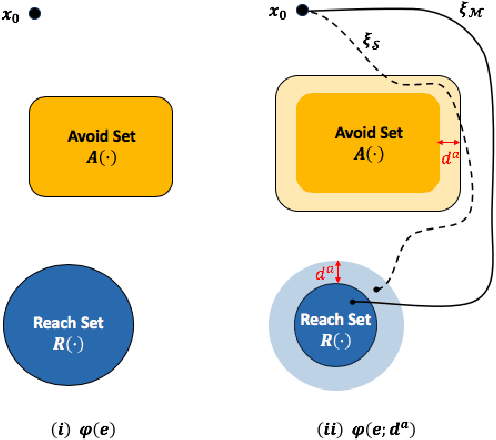
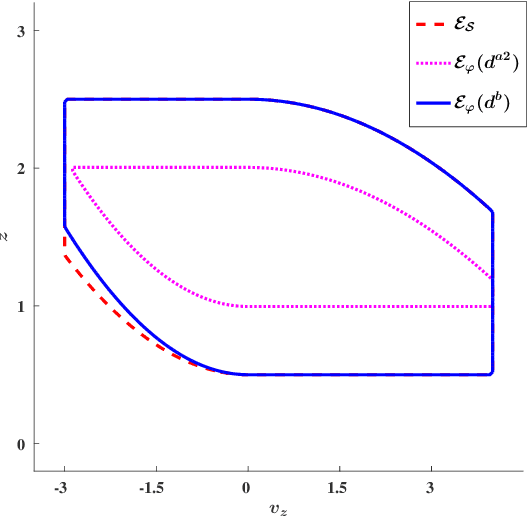
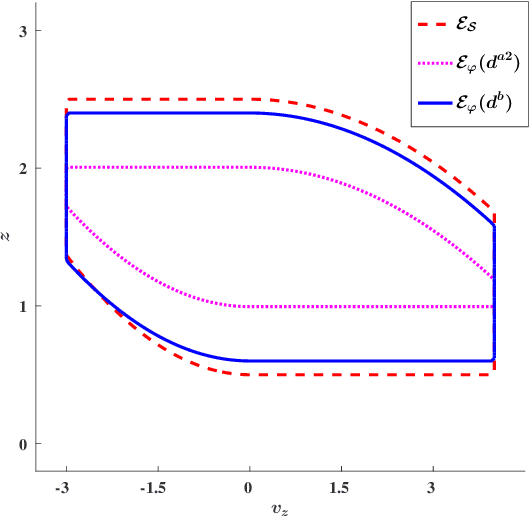

We consider the problem of extracting safe environments and controllers for reach-avoid objectives for systems with known state and control spaces, but unknown dynamics. In a given environment, a common approach is to synthesize a controller from an abstraction or a model of the system (potentially learned from data). However, in many situations, the relationship between the dynamics of the model and the \textit{actual system} is not known; and hence it is difficult to provide safety guarantees for the system. In such cases, the Standard Simulation Metric (SSM), defined as the worst-case norm distance between the model and the system output trajectories, can be used to modify a reach-avoid specification for the system into a more stringent specification for the abstraction. Nevertheless, the obtained distance, and hence the modified specification, can be quite conservative. This limits the set of environments for which a safe controller can be obtained. We propose SPEC, a specification-centric simulation metric, which overcomes these limitations by computing the distance using only the trajectories that violate the specification for the system. We show that modifying a reach-avoid specification with SPEC allows us to synthesize a safe controller for a larger set of environments compared to SSM. We also propose a probabilistic method to compute SPEC for a general class of systems. Case studies using simulators for quadrotors and autonomous cars illustrate the advantages of the proposed metric for determining safe environment sets and controllers.