 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Visual Navigation for Autonomous Vehicles: An Open-source Hands-on Robotics Course at MIT
Jun 01, 2022

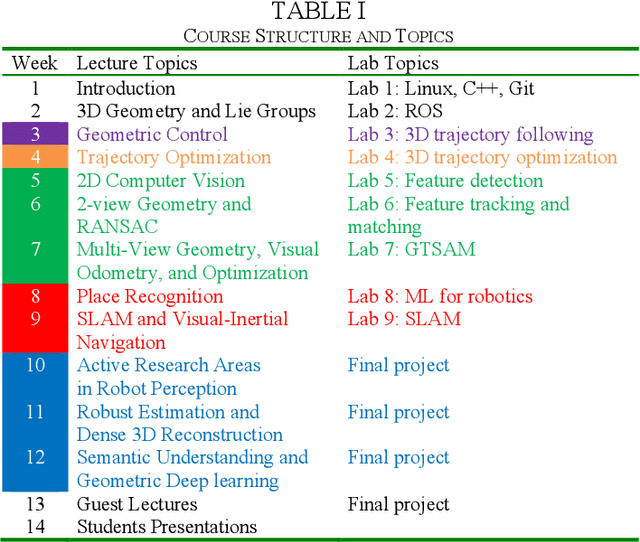
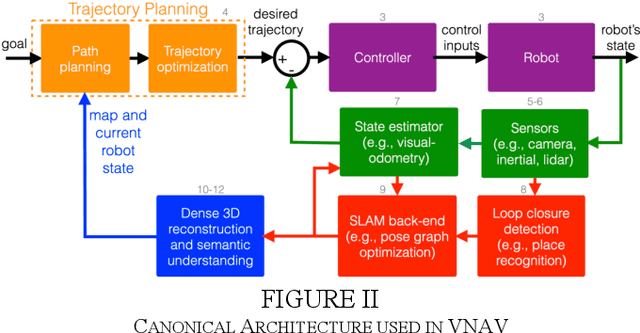
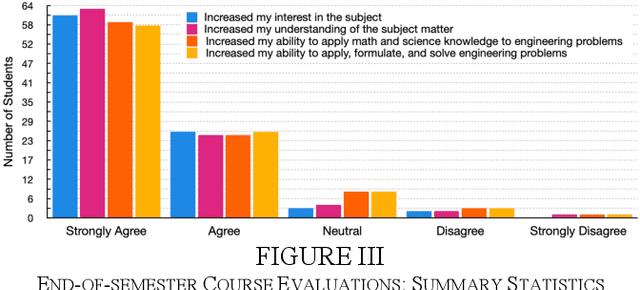
This paper reports on the development, execution, and open-sourcing of a new robotics course at MIT. The course is a modern take on "Visual Navigation for Autonomous Vehicles" (VNAV) and targets first-year graduate students and senior undergraduates with prior exposure to robotics. VNAV has the goal of preparing the students to perform research in robotics and vision-based navigation, with emphasis on drones and self-driving cars. The course spans the entire autonomous navigation pipeline; as such, it covers a broad set of topics, including geometric control and trajectory optimization, 2D and 3D computer vision, visual and visual-inertial odometry, place recognition, simultaneous localization and mapping, and geometric deep learning for perception. VNAV has three key features. First, it bridges traditional computer vision and robotics courses by exposing the challenges that are specific to embodied intelligence, e.g., limited computation and need for just-in-time and robust perception to close the loop over control and decision making. Second, it strikes a balance between depth and breadth by combining rigorous technical notes (including topics that are less explored in typical robotics courses, e.g., on-manifold optimization) with slides and videos showcasing the latest research results. Third, it provides a compelling approach to hands-on robotics education by leveraging a physical drone platform (mostly suitable for small residential courses) and a photo-realistic Unity-based simulator (open-source and scalable to large online courses). VNAV has been offered at MIT in the Falls of 2018-2021 and is now publicly available on MIT OpenCourseWare (OCW).
Multi-modal Trajectory Prediction for Autonomous Driving with Semantic Map and Dynamic Graph Attention Network
Mar 30, 2021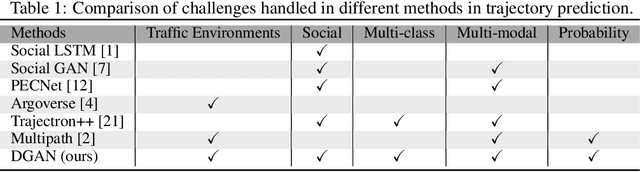
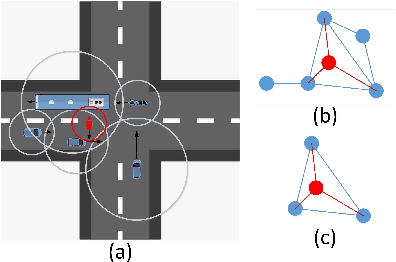
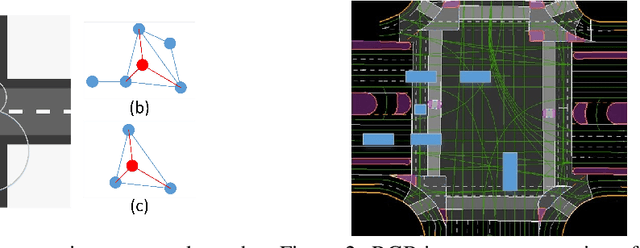
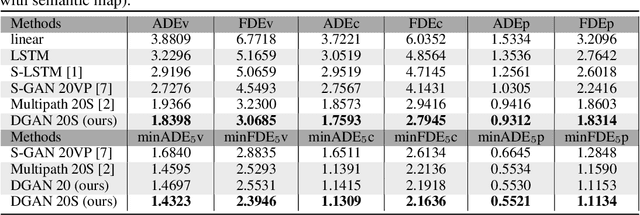
Predicting future trajectories of surrounding obstacles is a crucial task for autonomous driving cars to achieve a high degree of road safety. There are several challenges in trajectory prediction in real-world traffic scenarios, including obeying traffic rules, dealing with social interactions, handling traffic of multi-class movement, and predicting multi-modal trajectories with probability. Inspired by people's natural habit of navigating traffic with attention to their goals and surroundings, this paper presents a unique dynamic graph attention network to solve all those challenges. The network is designed to model the dynamic social interactions among agents and conform to traffic rules with a semantic map. By extending the anchor-based method to multiple types of agents, the proposed method can predict multi-modal trajectories with probabilities for multi-class movements using a single model. We validate our approach on the proprietary autonomous driving dataset for the logistic delivery scenario and two publicly available datasets. The results show that our method outperforms state-of-the-art techniques and demonstrates the potential for trajectory prediction in real-world traffic.
Analyzing Self-Driving Cars on Twitter
Apr 05, 2018
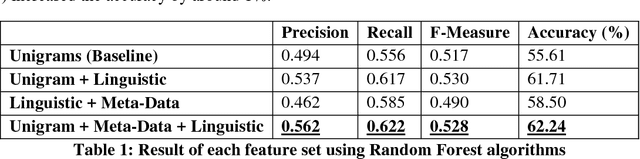

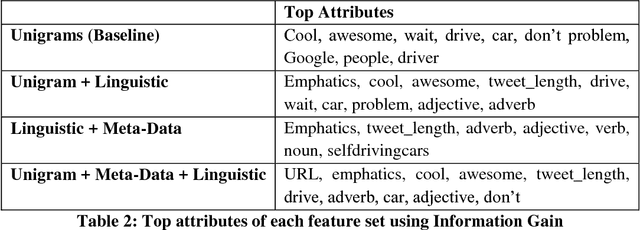
This paper studies users' perception regarding a controversial product, namely self-driving (autonomous) cars. To find people's opinion regarding this new technology, we used an annotated Twitter dataset, and extracted the topics in positive and negative tweets using an unsupervised, probabilistic model known as topic modeling. We later used the topics, as well as linguist and Twitter specific features to classify the sentiment of the tweets. Regarding the opinions, the result of our analysis shows that people are optimistic and excited about the future technology, but at the same time they find it dangerous and not reliable. For the classification task, we found Twitter specific features, such as hashtags as well as linguistic features such as emphatic words among top attributes in classifying the sentiment of the tweets.
On Encoding Temporal Evolution for Real-time Action Prediction
Feb 08, 2018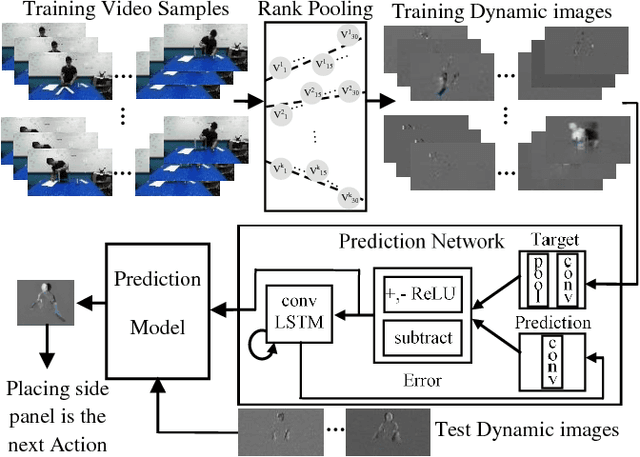
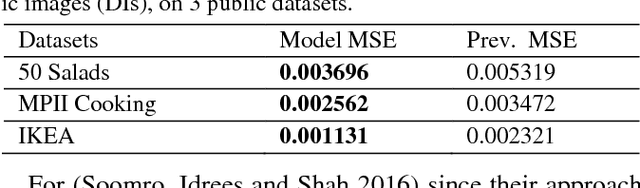

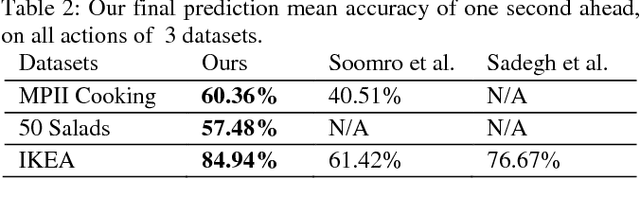
Anticipating future actions is a key component of intelligence, specifically when it applies to real-time systems, such as robots or autonomous cars. While recent works have addressed prediction of raw RGB pixel values, we focus on anticipating the motion evolution in future video frames. To this end, we construct dynamic images (DIs) by summarising moving pixels through a sequence of future frames. We train a convolutional LSTMs to predict the next DIs based on an unsupervised learning process, and then recognise the activity associated with the predicted DI. We demonstrate the effectiveness of our approach on 3 benchmark action datasets showing that despite running on videos with complex activities, our approach is able to anticipate the next human action with high accuracy and obtain better results than the state-of-the-art methods.
Situation Assessment for Planning Lane Changes: Combining Recurrent Models and Prediction
May 17, 2018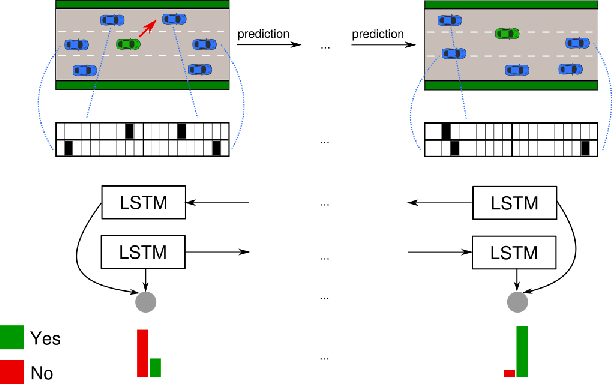
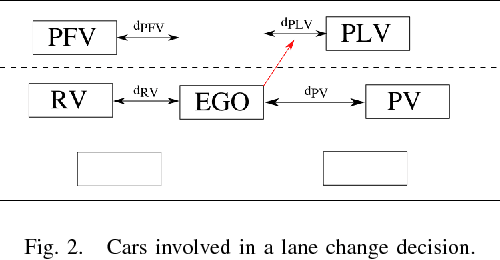
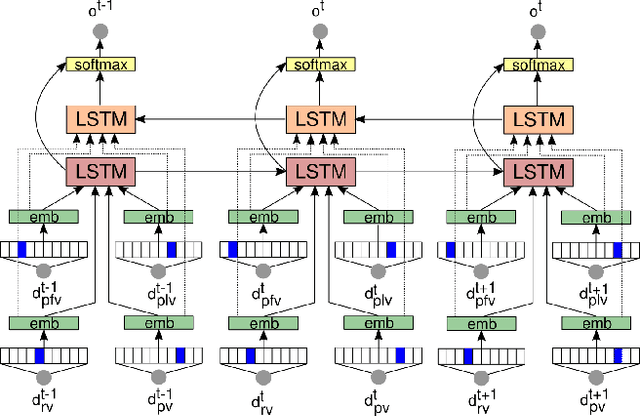
One of the greatest challenges towards fully autonomous cars is the understanding of complex and dynamic scenes. Such understanding is needed for planning of maneuvers, especially those that are particularly frequent such as lane changes. While in recent years advanced driver-assistance systems have made driving safer and more comfortable, these have mostly focused on car following scenarios, and less on maneuvers involving lane changes. In this work we propose a situation assessment algorithm for classifying driving situations with respect to their suitability for lane changing. For this, we propose a deep learning architecture based on a Bidirectional Recurrent Neural Network, which uses Long Short-Term Memory units, and integrates a prediction component in the form of the Intelligent Driver Model. We prove the feasibility of our algorithm on the publicly available NGSIM datasets, where we outperform existing methods.
Formal Verification of End-to-End Learning in Cyber-Physical Systems: Progress and Challenges
Jun 15, 2020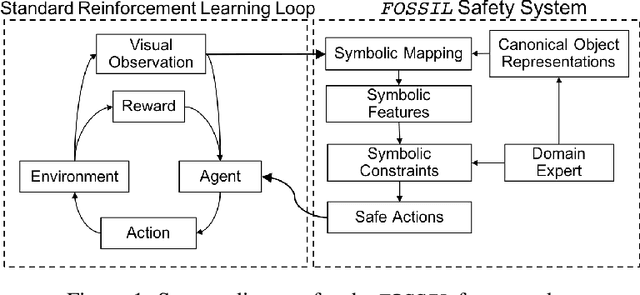
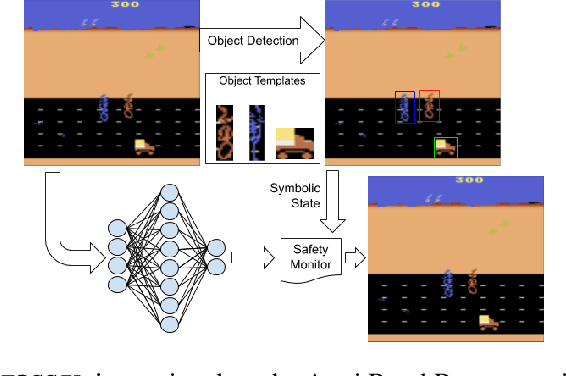
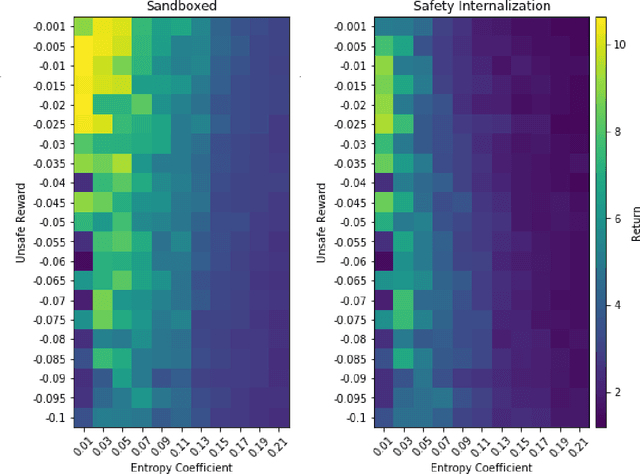
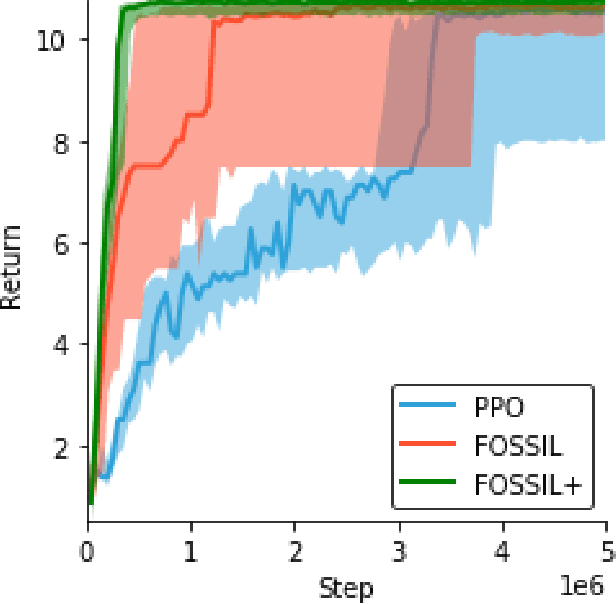
Autonomous systems -- such as self-driving cars, autonomous drones, and automated trains -- must come with strong safety guarantees. Over the past decade, techniques based on formal methods have enjoyed some success in providing strong correctness guarantees for large software systems including operating system kernels, cryptographic protocols, and control software for drones. These successes suggest it might be possible to ensure the safety of autonomous systems by constructing formal, computer-checked correctness proofs. This paper identifies three assumptions underlying existing formal verification techniques, explains how each of these assumptions limits the applicability of verification in autonomous systems, and summarizes preliminary work toward improving the strength of evidence provided by formal verification.
DeepSmartFuzzer: Reward Guided Test Generation For Deep Learning
Nov 24, 2019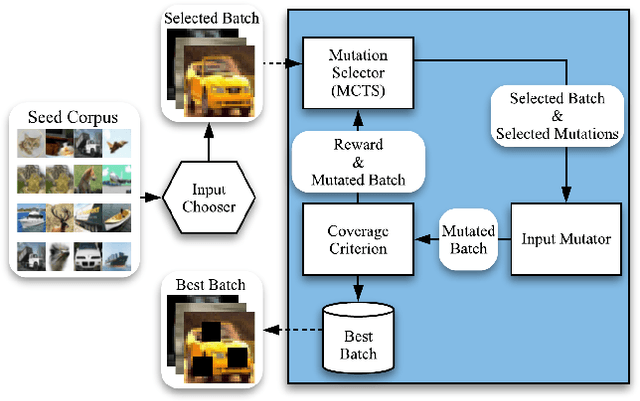
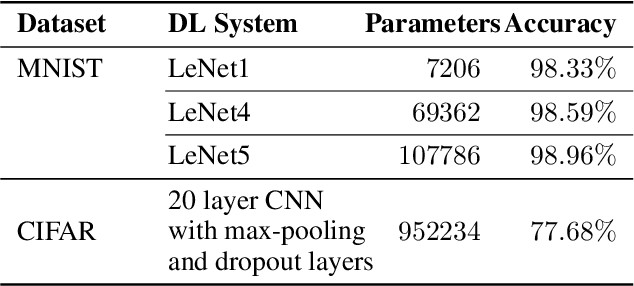


Testing Deep Neural Network (DNN) models has become more important than ever with the increasing usage of DNN models in safety-critical domains such as autonomous cars. The traditional approach of testing DNNs is to create a test set, which is a random subset of the dataset about the problem of interest. This kind of approach is not enough for testing most of the real-world scenarios since these traditional test sets do not include corner cases, while a corner case input is generally considered to introduce erroneous behaviors. Recent works on adversarial input generation, data augmentation, and coverage-guided fuzzing (CGF) have provided new ways to extend traditional test sets. Among those, CGF aims to produce new test inputs by fuzzing existing ones to achieve high coverage on a test adequacy criterion (i.e. coverage criterion). Given that the subject test adequacy criterion is a well-established one, CGF can potentially find error inducing inputs for different underlying reasons. In this paper, we propose a novel CGF solution for structural testing of DNNs. The proposed fuzzer employs Monte Carlo Tree Search to drive the coverage-guided search in the pursuit of achieving high coverage. Our evaluation shows that the inputs generated by our method result in higher coverage than the inputs produced by the previously introduced coverage-guided fuzzing techniques.
Evaluating Explanation Without Ground Truth in Interpretable Machine Learning
Aug 15, 2019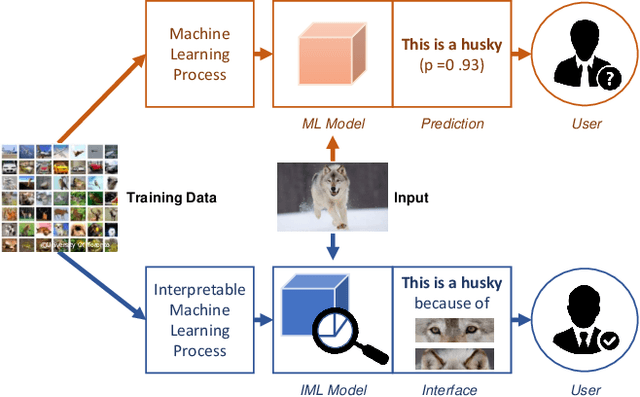
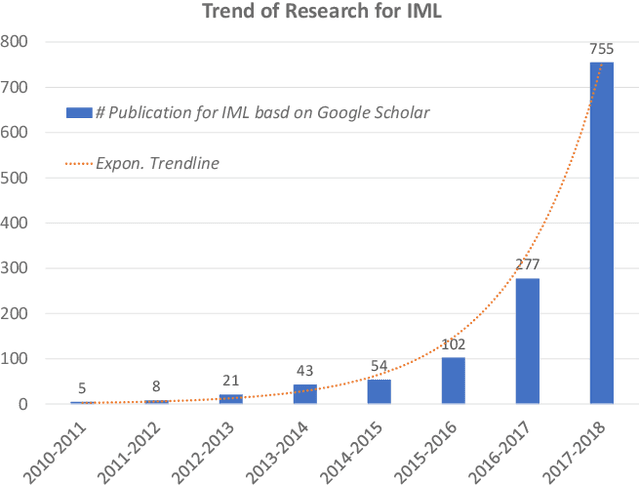
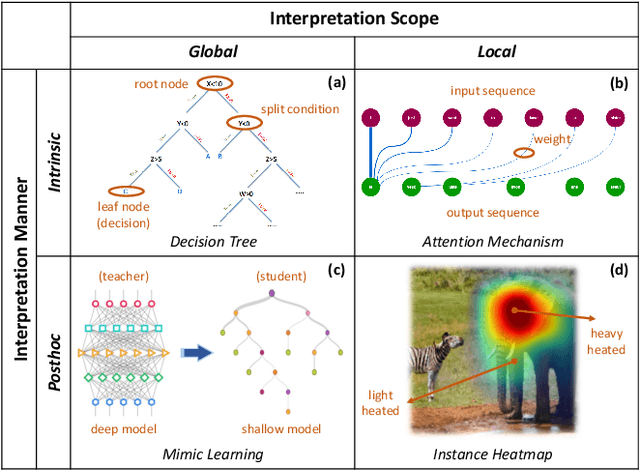
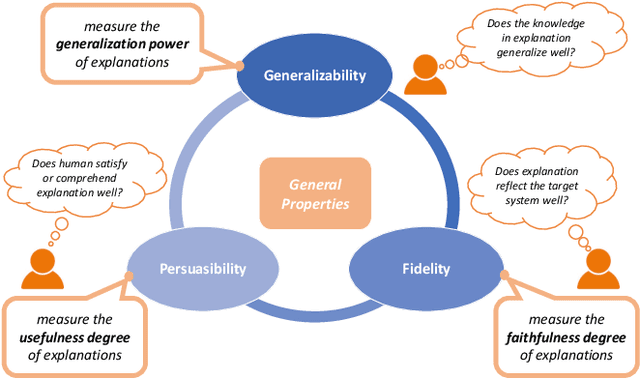
Interpretable Machine Learning (IML) has become increasingly important in many real-world applications, such as autonomous cars and medical diagnosis, where explanations are significantly preferred to help people better understand how machine learning systems work and further enhance their trust towards systems. However, due to the diversified scenarios and subjective nature of explanations, we rarely have the ground truth for benchmark evaluation in IML on the quality of generated explanations. Having a sense of explanation quality not only matters for assessing system boundaries, but also helps to realize the true benefits to human users in practical settings. To benchmark the evaluation in IML, in this article, we rigorously define the problem of evaluating explanations, and systematically review the existing efforts from state-of-the-arts. Specifically, we summarize three general aspects of explanation (i.e., generalizability, fidelity and persuasibility) with formal definitions, and respectively review the representative methodologies for each of them under different tasks. Further, a unified evaluation framework is designed according to the hierarchical needs from developers and end-users, which could be easily adopted for different scenarios in practice. In the end, open problems are discussed, and several limitations of current evaluation techniques are raised for future explorations.
SELMA: SEmantic Large-scale Multimodal Acquisitions in Variable Weather, Daytime and Viewpoints
Apr 20, 2022
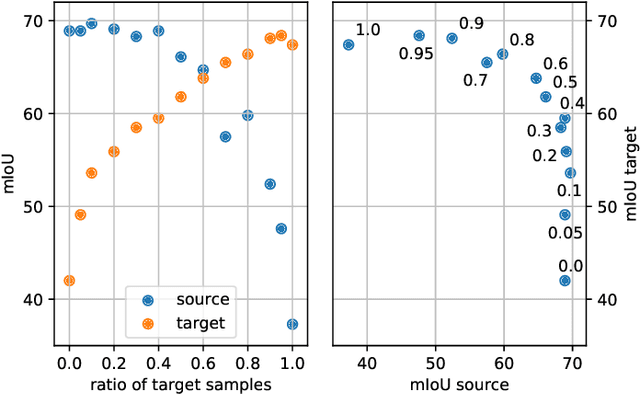
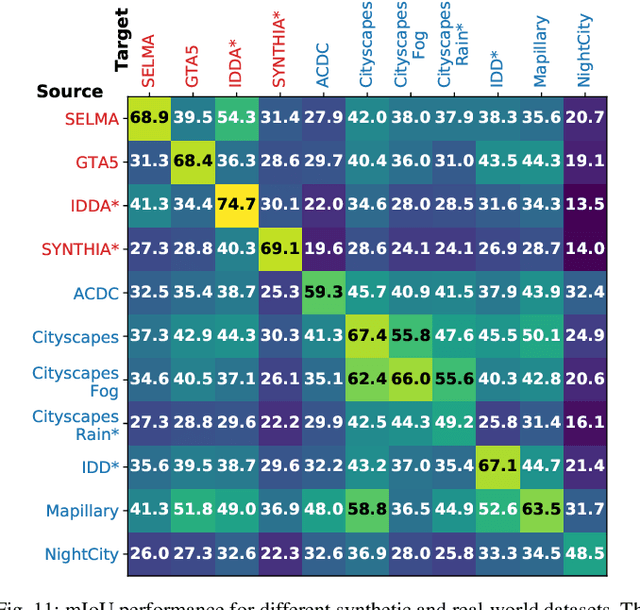

Accurate scene understanding from multiple sensors mounted on cars is a key requirement for autonomous driving systems. Nowadays, this task is mainly performed through data-hungry deep learning techniques that need very large amounts of data to be trained. Due to the high cost of performing segmentation labeling, many synthetic datasets have been proposed. However, most of them miss the multi-sensor nature of the data, and do not capture the significant changes introduced by the variation of daytime and weather conditions. To fill these gaps, we introduce SELMA, a novel synthetic dataset for semantic segmentation that contains more than 30K unique waypoints acquired from 24 different sensors including RGB, depth, semantic cameras and LiDARs, in 27 different atmospheric and daytime conditions, for a total of more than 20M samples. SELMA is based on CARLA, an open-source simulator for generating synthetic data in autonomous driving scenarios, that we modified to increase the variability and the diversity in the scenes and class sets, and to align it with other benchmark datasets. As shown by the experimental evaluation, SELMA allows the efficient training of standard and multi-modal deep learning architectures, and achieves remarkable results on real-world data. SELMA is free and publicly available, thus supporting open science and research.
Embodied AI-Driven Operation of Smart Cities: A Concise Review
Aug 22, 2021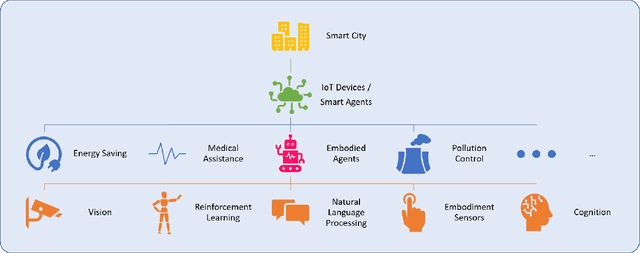
A smart city can be seen as a framework, comprised of Information and Communication Technologies (ICT). An intelligent network of connected devices that collect data with their sensors and transmit them using cloud technologies in order to communicate with other assets in the ecosystem plays a pivotal role in this framework. Maximizing the quality of life of citizens, making better use of resources, cutting costs, and improving sustainability are the ultimate goals that a smart city is after. Hence, data collected from connected devices will continuously get thoroughly analyzed to gain better insights into the services that are being offered across the city; with this goal in mind that they can be used to make the whole system more efficient. Robots and physical machines are inseparable parts of a smart city. Embodied AI is the field of study that takes a deeper look into these and explores how they can fit into real-world environments. It focuses on learning through interaction with the surrounding environment, as opposed to Internet AI which tries to learn from static datasets. Embodied AI aims to train an agent that can See (Computer Vision), Talk (NLP), Navigate and Interact with its environment (Reinforcement Learning), and Reason (General Intelligence), all at the same time. Autonomous driving cars and personal companions are some of the examples that benefit from Embodied AI nowadays. In this paper, we attempt to do a concise review of this field. We will go through its definitions, its characteristics, and its current achievements along with different algorithms, approaches, and solutions that are being used in different components of it (e.g. Vision, NLP, RL). We will then explore all the available simulators and 3D interactable databases that will make the research in this area feasible. Finally, we will address its challenges and identify its potentials for future research.