 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Detection and Classification of Industrial Signal Lights for Factory Floors
Apr 23, 2020
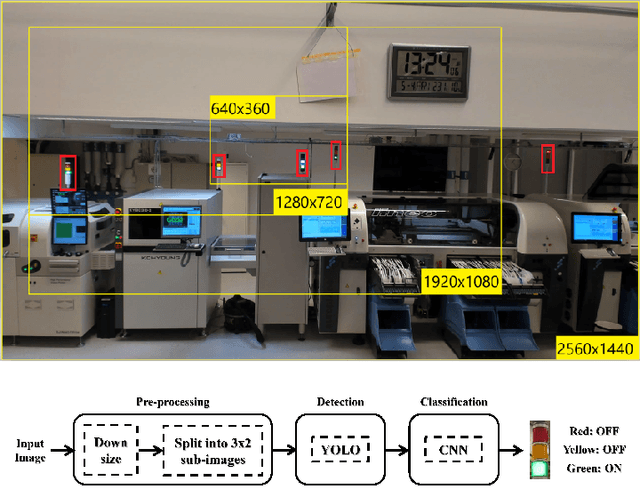
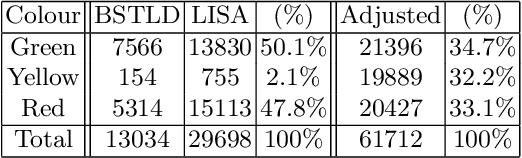

Industrial manufacturing has developed during the last decades from a labor-intensive manual control of machines to a fully-connected automated process. The next big leap is known as industry 4.0, or smart manufacturing. With industry 4.0 comes increased integration between IT systems and the factory floor from the customer order system to final delivery of the product. One benefit of this integration is mass production of individually customized products. However, this has proven challenging to implement into existing factories, considering that their lifetime can be up to 30 years. The single most important parameter to measure in a factory is the operating hours of each machine. Operating hours can be affected by machine maintenance as well as re-configuration for different products. For older machines without connectivity, the operating state is typically indicated by signal lights of green, yellow and red colours. Accordingly, the goal is to develop a solution which can measure the operational state using the input from a video camera capturing a factory floor. Using methods commonly employed for traffic light recognition in autonomous cars, a system with an accuracy of over 99% in the specified conditions is presented. It is believed that if more diverse video data becomes available, a system with high reliability that generalizes well could be developed using a similar methodology.
Generate (non-software) Bugs to Fool Classifiers
Nov 20, 2019


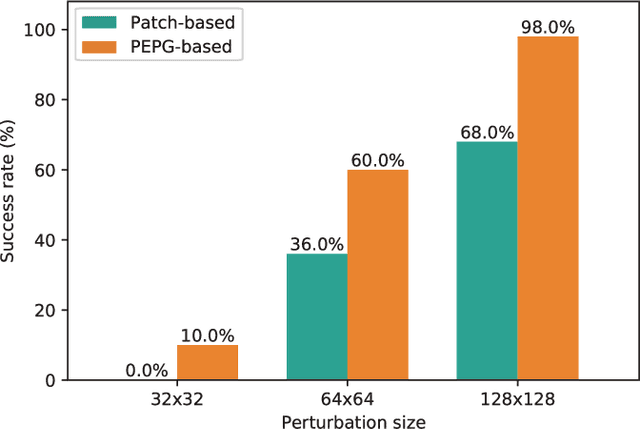
In adversarial attacks intended to confound deep learning models, most studies have focused on limiting the magnitude of the modification so that humans do not notice the attack. On the other hand, during an attack against autonomous cars, for example, most drivers would not find it strange if a small insect image were placed on a stop sign, or they may overlook it. In this paper, we present a systematic approach to generate natural adversarial examples against classification models by employing such natural-appearing perturbations that imitate a certain object or signal. We first show the feasibility of this approach in an attack against an image classifier by employing generative adversarial networks that produce image patches that have the appearance of a natural object to fool the target model. We also introduce an algorithm to optimize placement of the perturbation in accordance with the input image, which makes the generation of adversarial examples fast and likely to succeed. Moreover, we experimentally show that the proposed approach can be extended to the audio domain, for example, to generate perturbations that sound like the chirping of birds to fool a speech classifier.
AdaScale: Towards Real-time Video Object Detection Using Adaptive Scaling
Feb 08, 2019
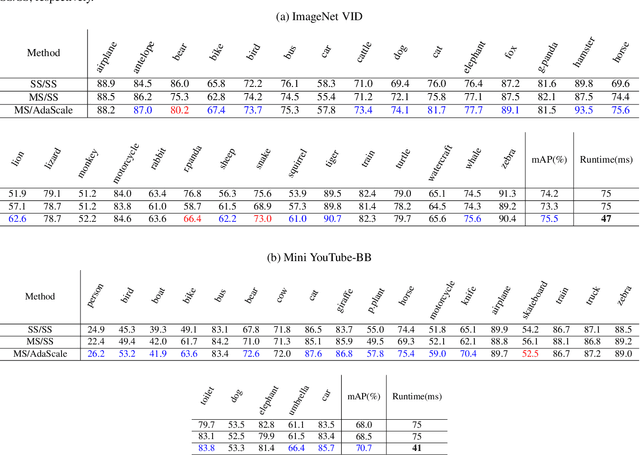

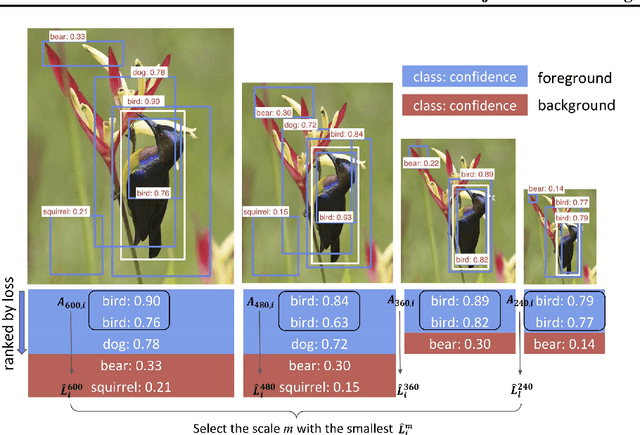
In vision-enabled autonomous systems such as robots and autonomous cars, video object detection plays a crucial role, and both its speed and accuracy are important factors to provide reliable operation. The key insight we show in this paper is that speed and accuracy are not necessarily a trade-off when it comes to image scaling. Our results show that re-scaling the image to a lower resolution will sometimes produce better accuracy. Based on this observation, we propose a novel approach, dubbed AdaScale, which adaptively selects the input image scale that improves both accuracy and speed for video object detection. To this end, our results on ImageNet VID and mini YouTube-BoundingBoxes datasets demonstrate 1.3 points and 2.7 points mAP improvement with 1.6x and 1.8x speedup, respectively. Additionally, we improve state-of-the-art video acceleration work by an extra 1.25x speedup with slightly better mAP on ImageNet VID dataset.
Complexer-YOLO: Real-Time 3D Object Detection and Tracking on Semantic Point Clouds
Apr 16, 2019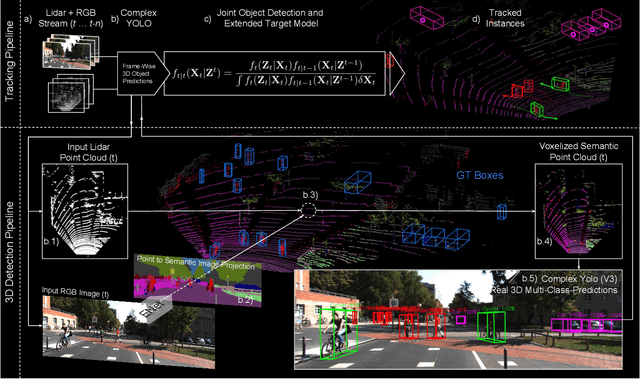
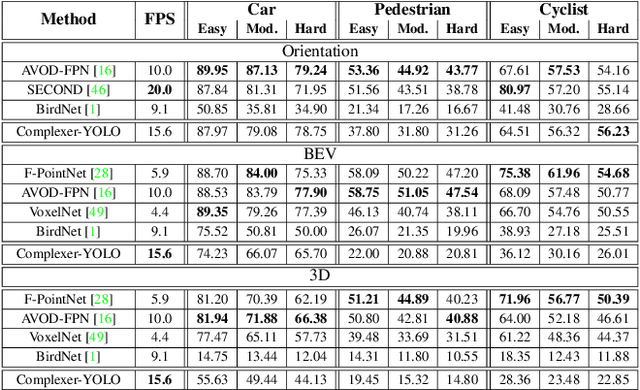
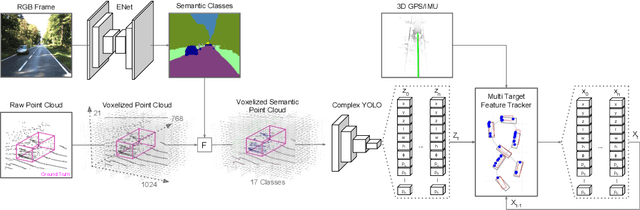
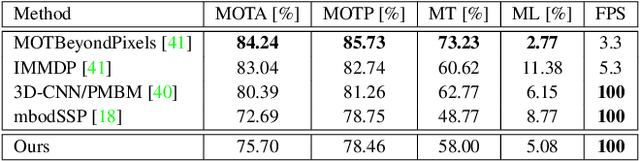
Accurate detection of 3D objects is a fundamental problem in computer vision and has an enormous impact on autonomous cars, augmented/virtual reality and many applications in robotics. In this work we present a novel fusion of neural network based state-of-the-art 3D detector and visual semantic segmentation in the context of autonomous driving. Additionally, we introduce Scale-Rotation-Translation score (SRTs), a fast and highly parameterizable evaluation metric for comparison of object detections, which speeds up our inference time up to 20\% and halves training time. On top, we apply state-of-the-art online multi target feature tracking on the object measurements to further increase accuracy and robustness utilizing temporal information. Our experiments on KITTI show that we achieve same results as state-of-the-art in all related categories, while maintaining the performance and accuracy trade-off and still run in real-time. Furthermore, our model is the first one that fuses visual semantic with 3D object detection.
Resilient Sensor Architecture Design and Tradespace Analysis for Autonomous Vehicle Localization and Mapping
Jul 19, 2019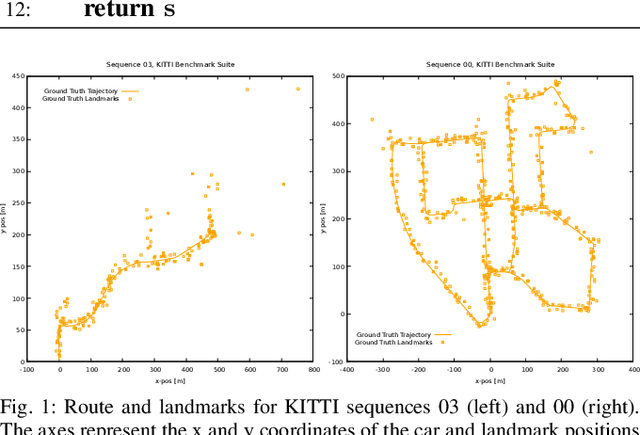
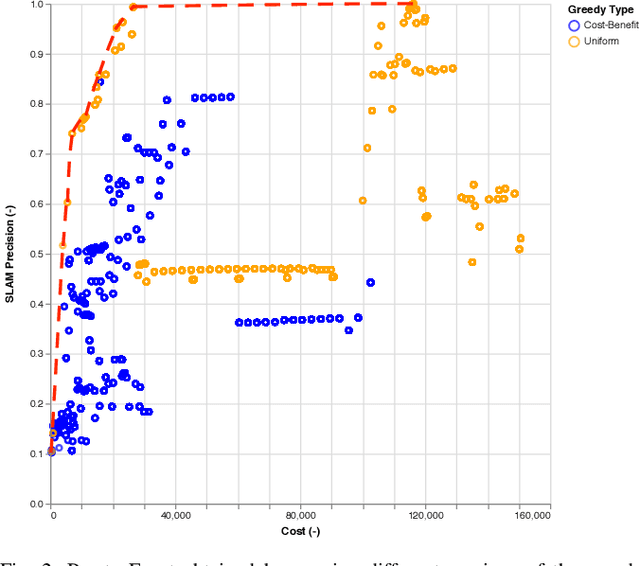
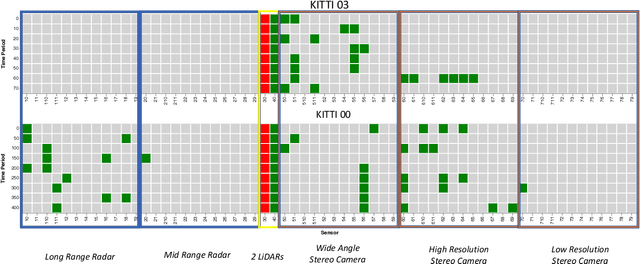
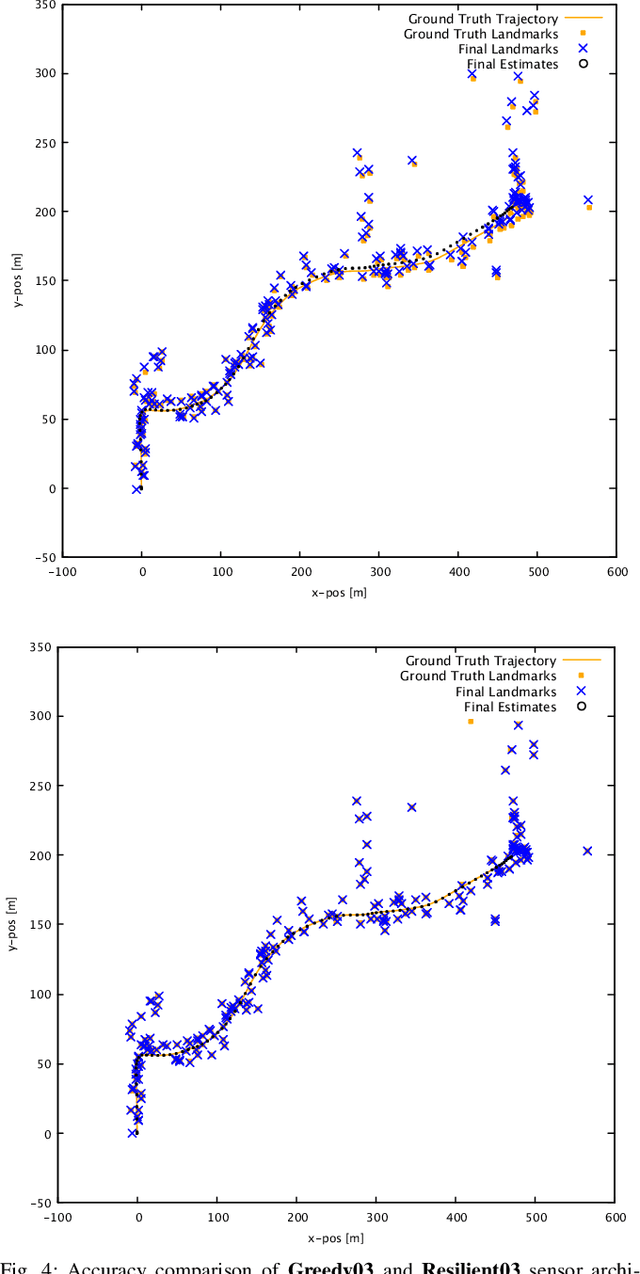
As autonomous cars are rolled out into new environments, their ability to solve the simultaneous localization and mapping (SLAM) problem becomes critical. In order to tackle this problem, autonomous vehicles rely on sensor suites that provide them with information about their operating environment. When large scale production is taken into consideration, a trade-off between an acceptable sensor suite cost and its resulting performance characteristics arises. Furthermore, guaranteeing the system's performance requires a resilient sensor network design. This work seeks to address such trade-offs by introducing a method that takes into account the performance, cost, and resiliency of distinct sensor selections. As a result, this method is able to offer sensor combination recommendations based on the vehicle's operating environment. It is found that the structure of the environment influences sensor placement, and that the design of a resilient sensor network involves careful consideration of both environmental attributes such as landmark density and location, as well as the available types of complimentary sensors. Demonstration of the proposed approach is shown by evaluating it using sequences from the KITTI Benchmark Suite.
Parallelized and Randomized Adversarial Imitation Learning for Safety-Critical Self-Driving Vehicles
Dec 26, 2021

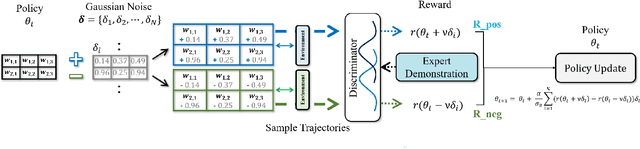
Self-driving cars and autonomous driving research has been receiving considerable attention as major promising prospects in modern artificial intelligence applications. According to the evolution of advanced driver assistance system (ADAS), the design of self-driving vehicle and autonomous driving systems becomes complicated and safety-critical. In general, the intelligent system simultaneously and efficiently activates ADAS functions. Therefore, it is essential to consider reliable ADAS function coordination to control the driving system, safely. In order to deal with this issue, this paper proposes a randomized adversarial imitation learning (RAIL) algorithm. The RAIL is a novel derivative-free imitation learning method for autonomous driving with various ADAS functions coordination; and thus it imitates the operation of decision maker that controls autonomous driving with various ADAS functions. The proposed method is able to train the decision maker that deals with the LIDAR data and controls the autonomous driving in multi-lane complex highway environments. The simulation-based evaluation verifies that the proposed method achieves desired performance.
SRVIO: Super Robust Visual Inertial Odometry for dynamic environments and challenging Loop-closure conditions
Jan 14, 2022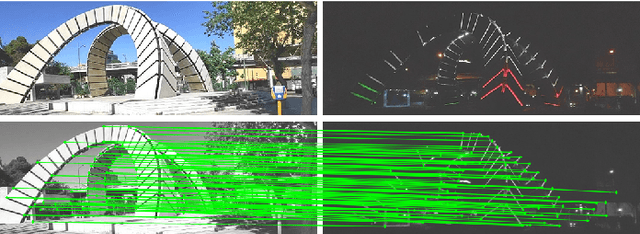
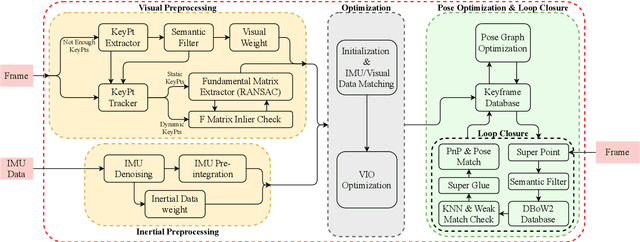

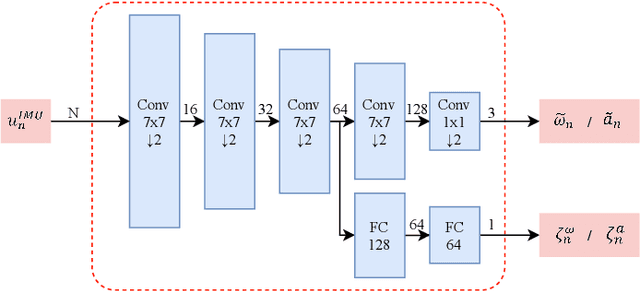
The visual localization or odometry problem is a well-known challenge in the field of autonomous robots and cars. Traditionally, this problem can ba tackled with the help of expensive sensors such as lidars. Nowadays, the leading research is on robust localization using economic sensors, such as cameras and IMUs. The geometric methods based on these sensors are pretty good in normal conditions withstable lighting and no dynamic objects. These methods suffer from significant loss and divergence in such challenging environments. The scientists came to use deep neural networks (DNNs) as the savior to mitigate this problem. The main idea behind using DNNs was to better understand the problem inside the data and overcome complex conditions (such as a dynamic object in front of the camera, extreme lighting conditions, keeping the track at high speeds, etc.) The prior endto-end DNN methods are able to overcome some of the mentioned challenges. However, no general and robust framework for all of these scenarios is available. In this paper, we have combined geometric and DNN based methods to have the pros of geometric SLAM frameworks and overcome the remaining challenges with the DNNs help. To do this, we have modified the Vins-Mono framework (the most robust and accurate framework till now) and we were able to achieve state-of-the-art results on TUM-Dynamic, TUM-VI, ADVIO and EuRoC datasets compared to geometric and end-to-end DNN based SLAMs. Our proposed framework was also able to achieve acceptable results on extreme simulated cases resembling the challenges mentioned earlier easy.
Rethinking Task and Metrics of Instance Segmentation on 3D Point Clouds
Sep 27, 2019

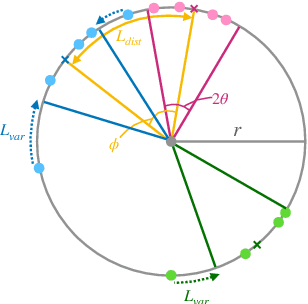
Instance segmentation on 3D point clouds is one of the most extensively researched areas toward the realization of autonomous cars and robots. Certain existing studies have split input point clouds into small regions such as 1m x 1m; one reason for this is that models in the studies cannot consume a large number of points because of the large space complexity. However, because such small regions occasionally include a very small number of instances belonging to the same class, an evaluation using existing metrics such as mAP is largely affected by the category recognition performance. To address these problems, we propose a new method with space complexity O(Np) such that large regions can be consumed, as well as novel metrics for tasks that are independent of the categories or size of the inputs. Our method learns a mapping from input point clouds to an embedding space, where the embeddings form clusters for each instance and distinguish instances using these clusters during testing. Our method achieves state-of-the-art performance using both existing and the proposed metrics. Moreover, we show that our new metric can evaluate the performance of a task without being affected by any other condition.
Seek and You Will Find: A New Optimized Framework for Efficient Detection of Pedestrian
Dec 21, 2019
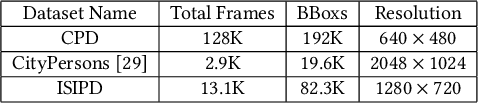
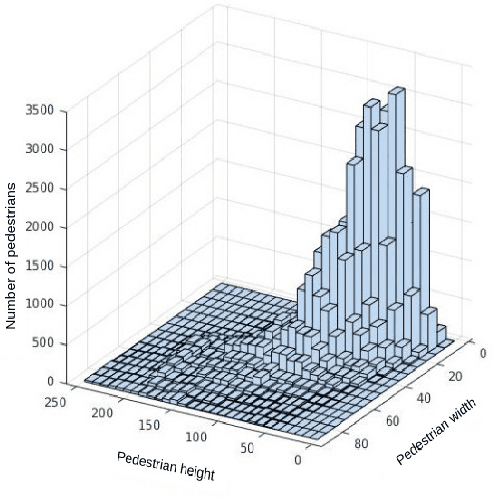
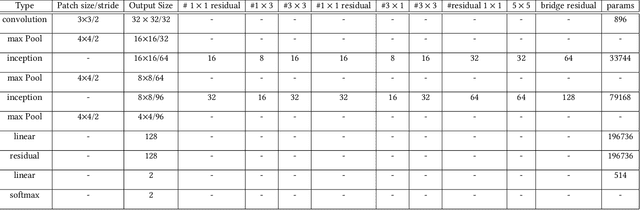
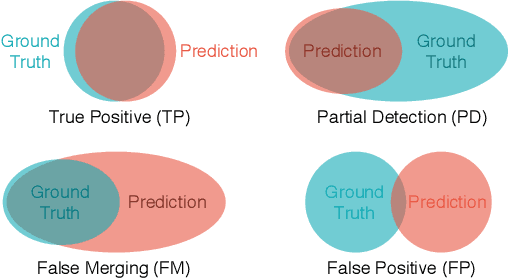
Studies of object detection and localization, particularly pedestrian detection have received considerable attention in recent times due to its several prospective applications such as surveillance, driving assistance, autonomous cars, etc. Also, a significant trend of latest research studies in related problem areas is the use of sophisticated Deep Learning based approaches to improve the benchmark performance on various standard datasets. A trade-off between the speed (number of video frames processed per second) and detection accuracy has often been reported in the existing literature. In this article, we present a new but simple deep learning based strategy for pedestrian detection that improves this trade-off. Since training of similar models using publicly available sample datasets failed to improve the detection performance to some significant extent, particularly for the instances of pedestrians of smaller sizes, we have developed a new sample dataset consisting of more than 80K annotated pedestrian figures in videos recorded under varying traffic conditions. Performance of the proposed model on the test samples of the new dataset and two other existing datasets, namely Caltech Pedestrian Dataset (CPD) and CityPerson Dataset (CD) have been obtained. Our proposed system shows nearly 16\% improvement over the existing state-of-the-art result.
End to End Vehicle Lateral Control Using a Single Fisheye Camera
Aug 20, 2018
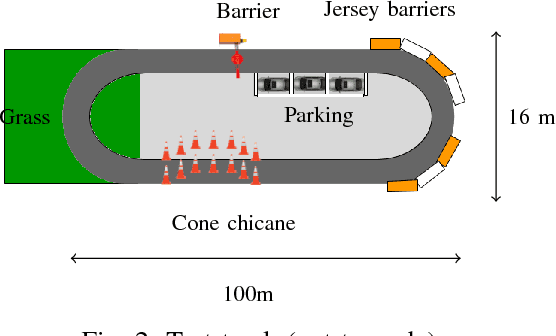

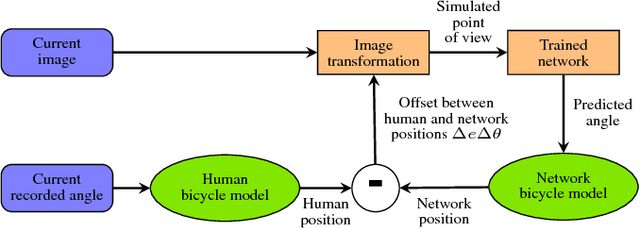
Convolutional neural networks are commonly used to control the steering angle for autonomous cars. Most of the time, multiple long range cameras are used to generate lateral failure cases. In this paper we present a novel model to generate this data and label augmentation using only one short range fisheye camera. We present our simulator and how it can be used as a consistent metric for lateral end-to-end control evaluation. Experiments are conducted on a custom dataset corresponding to more than 10000 km and 200 hours of open road driving. Finally we evaluate this model on real world driving scenarios, open road and a custom test track with challenging obstacle avoidance and sharp turns. In our simulator based on real-world videos, the final model was capable of more than 99% autonomy on urban road