 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic": models, code, and papers
CNN based dense underwater 3D scene reconstruction by transfer learning using bubble database
Nov 21, 2018


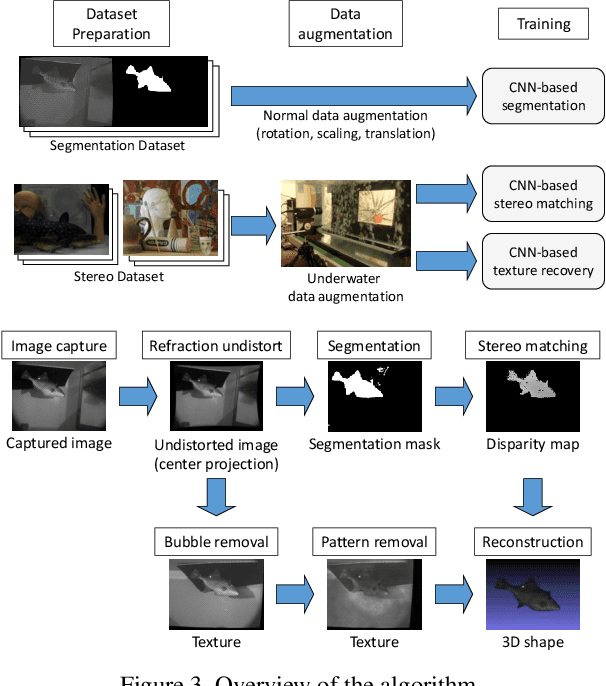

Dense 3D shape acquisition of swimming human or live fish is an important research topic for sports, biological science and so on. For this purpose, active stereo sensor is usually used in the air, however it cannot be applied to the underwater environment because of refraction, strong light attenuation and severe interference of bubbles. Passive stereo is a simple solution for capturing dynamic scenes at underwater environment, however the shape with textureless surfaces or irregular reflections cannot be recovered. Recently, the stereo camera pair with a pattern projector for adding artificial textures on the objects is proposed. However, to use the system for underwater environment, several problems should be compensated, i.e., disturbance by fluctuation and bubbles. Simple solution is to use convolutional neural network for stereo to cancel the effects of bubbles and/or water fluctuation. Since it is not easy to train CNN with small size of database with large variation, we develop a special bubble generation device to efficiently create real bubble database of multiple size and density. In addition, we propose a transfer learning technique for multi-scale CNN to effectively remove bubbles and projected-patterns on the object. Further, we develop a real system and actually captured live swimming human, which has not been done before. Experiments are conducted to show the effectiveness of our method compared with the state of the art techniques.
CONDITOR1: Topic Maps and DITA labelling tool for textual documents with historical information
Mar 23, 2016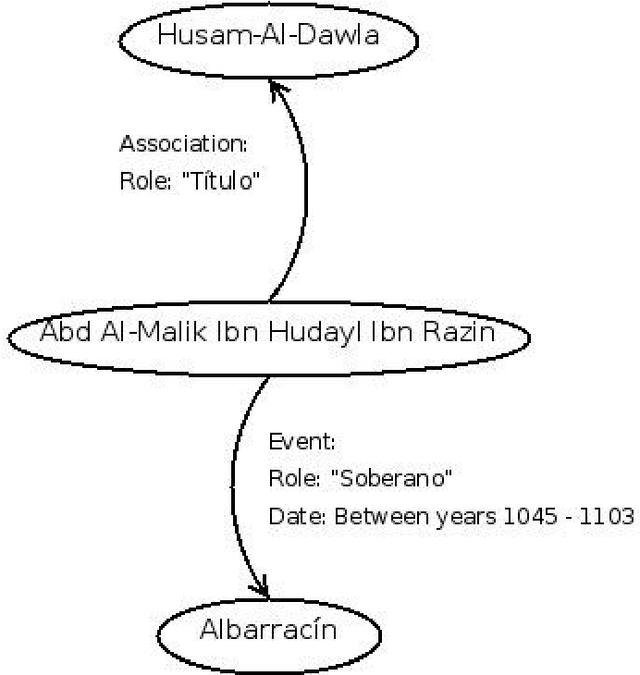
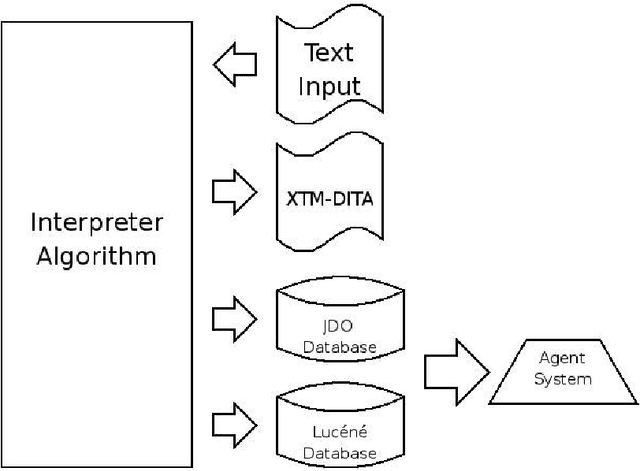
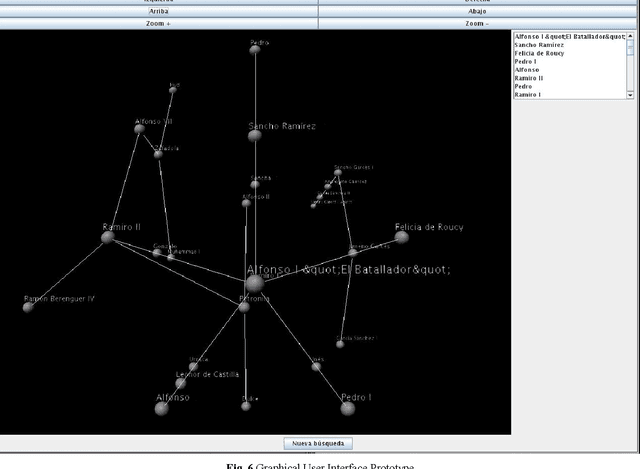
Conditor is a software tool which works with textual documents containing historical information. The purpose of this work two-fold: firstly to show the validity of the developed engine to correctly identify and label the entities of the universe of discourse with a labelled-combined XTM-DITA model. Secondly to explain the improvements achieved in the information retrieval process thanks to the use of a object-oriented database (JPOX) as well as its integration into the Lucene-type database search process to not only accomplish more accurate searches, but to also help the future development of a recommender system. We finish with a brief demo in a 3D-graph of the results of the aforementioned search.
A Knowledge-based Filtering Story Recommender System for Theme Lovers with an Application to the Star Trek Television Franchise
Jul 31, 2018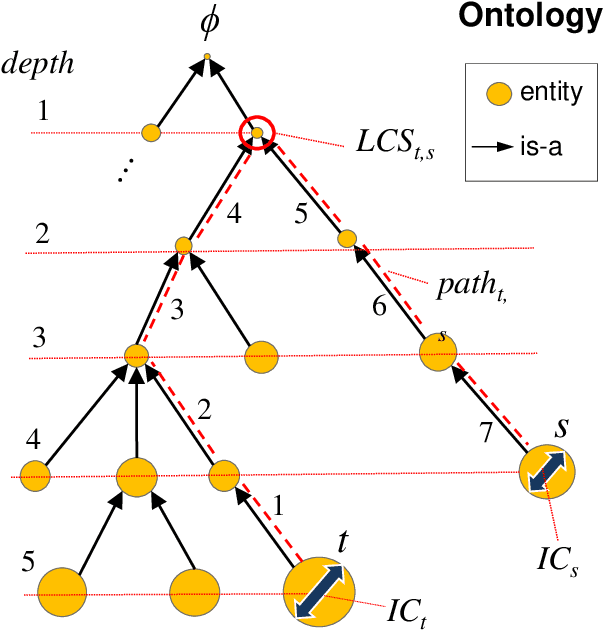

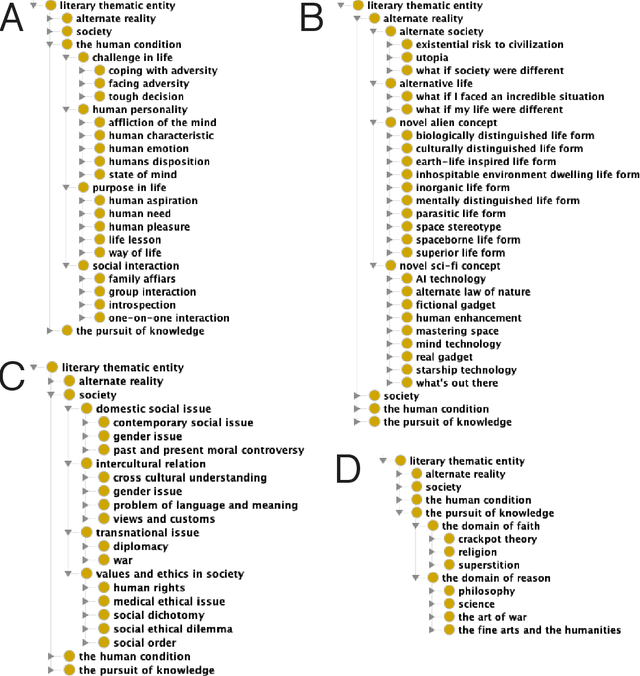

In this paper, we propose a recommender system that takes a user-selected story as input and returns a ranked list of similar stories on the basis of shared literary themes. The user of our system first selects a story of interest from a list of background stories, and then sets, as desired, a handful of knowledge-based filtering options, including the similarity measure used to quantify the similarity between story pairs. As a proof of concept, we validate experimentally our system on a dataset comprising 452 manually themed Star Trek television franchise episodes by using a benchmark of curated sets of related stories. We show that our manual approach to theme assignment significantly outperforms an automated approach to theme identification based on the application of topic models to episode transcripts. Additionally, we compare different approaches based on sets and on a hierarchical-semantic organization of themes to construct similarity functions between stories. The recommender system is implemented in the R package stoRy. A related R Shiny web application is available publicly along with the Stark Trek dataset including the theme ontology, episode annotations, storyset benchmarks, transcripts, and evaluation setup.
Argument Strength is in the Eye of the Beholder: Audience Effects in Persuasion
Aug 30, 2017

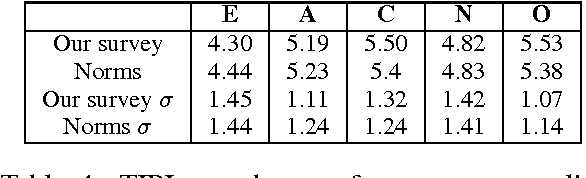

Americans spend about a third of their time online, with many participating in online conversations on social and political issues. We hypothesize that social media arguments on such issues may be more engaging and persuasive than traditional media summaries, and that particular types of people may be more or less convinced by particular styles of argument, e.g. emotional arguments may resonate with some personalities while factual arguments resonate with others. We report a set of experiments testing at large scale how audience variables interact with argument style to affect the persuasiveness of an argument, an under-researched topic within natural language processing. We show that belief change is affected by personality factors, with conscientious, open and agreeable people being more convinced by emotional arguments.
Modeling Curiosity in a Mobile Robot for Long-Term Autonomous Exploration and Monitoring
Sep 26, 2015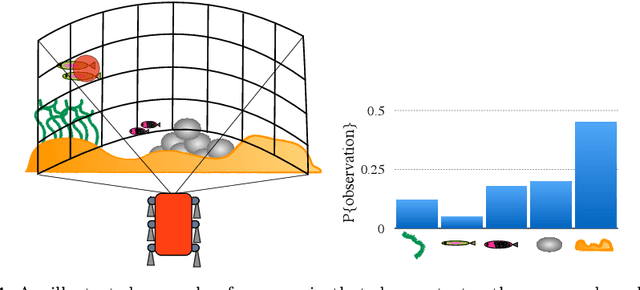

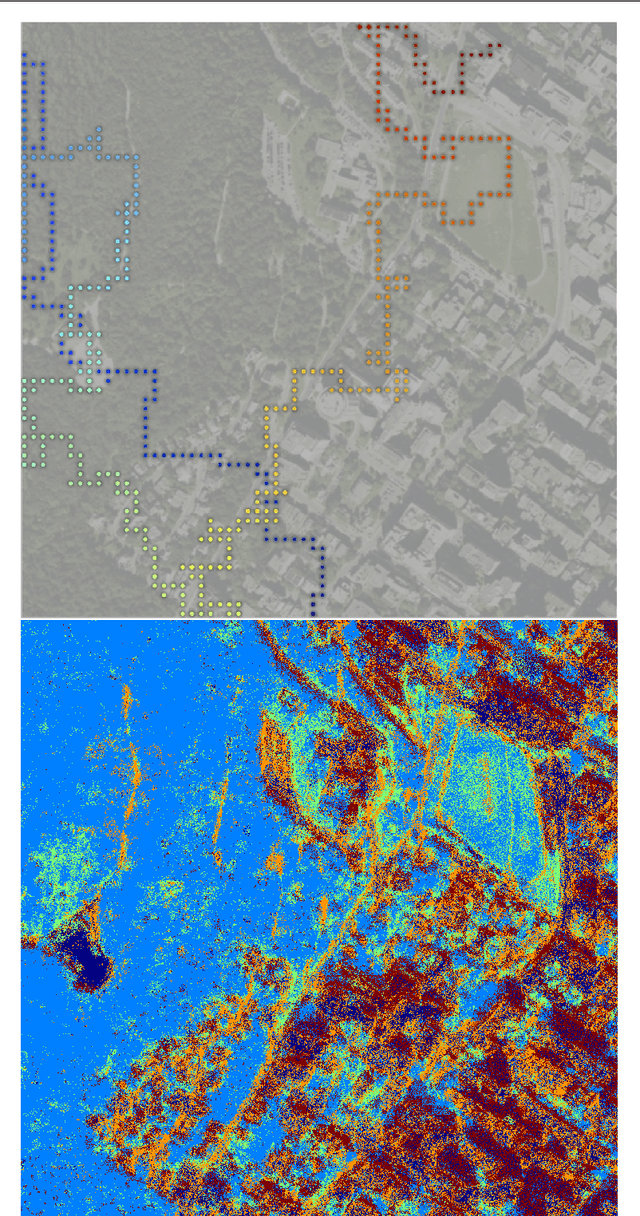
This paper presents a novel approach to modeling curiosity in a mobile robot, which is useful for monitoring and adaptive data collection tasks, especially in the context of long term autonomous missions where pre-programmed missions are likely to have limited utility. We use a realtime topic modeling technique to build a semantic perception model of the environment, using which, we plan a path through the locations in the world with high semantic information content. The life-long learning behavior of the proposed perception model makes it suitable for long-term exploration missions. We validate the approach using simulated exploration experiments using aerial and underwater data, and demonstrate an implementation on the Aqua underwater robot in a variety of scenarios. We find that the proposed exploration paths that are biased towards locations with high topic perplexity, produce better terrain models with high discriminative power. Moreover, we show that the proposed algorithm implemented on Aqua robot is able to do tasks such as coral reef inspection, diver following, and sea floor exploration, without any prior training or preparation.
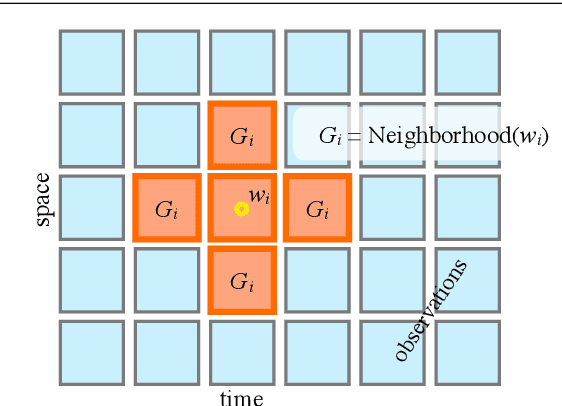
Residual Connections Encourage Iterative Inference
Mar 08, 2018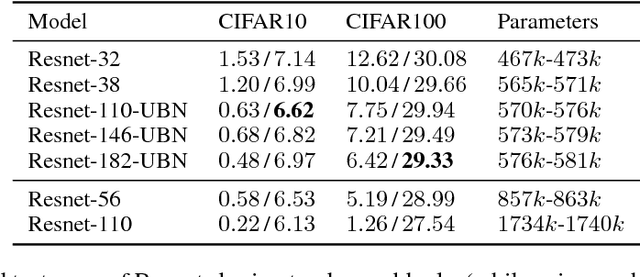



Residual networks (Resnets) have become a prominent architecture in deep learning. However, a comprehensive understanding of Resnets is still a topic of ongoing research. A recent view argues that Resnets perform iterative refinement of features. We attempt to further expose properties of this aspect. To this end, we study Resnets both analytically and empirically. We formalize the notion of iterative refinement in Resnets by showing that residual connections naturally encourage features of residual blocks to move along the negative gradient of loss as we go from one block to the next. In addition, our empirical analysis suggests that Resnets are able to perform both representation learning and iterative refinement. In general, a Resnet block tends to concentrate representation learning behavior in the first few layers while higher layers perform iterative refinement of features. Finally we observe that sharing residual layers naively leads to representation explosion and counterintuitively, overfitting, and we show that simple existing strategies can help alleviating this problem.
How Images Inspire Poems: Generating Classical Chinese Poetry from Images with Memory Networks
Mar 08, 2018
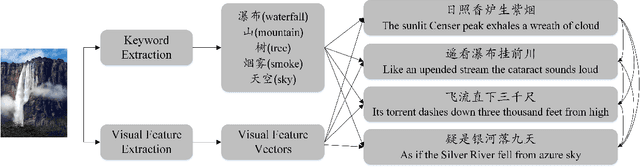
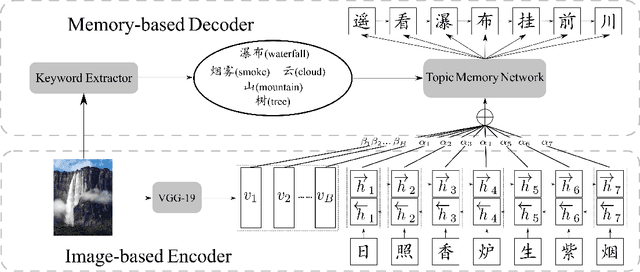
With the recent advances of neural models and natural language processing, automatic generation of classical Chinese poetry has drawn significant attention due to its artistic and cultural value. Previous works mainly focus on generating poetry given keywords or other text information, while visual inspirations for poetry have been rarely explored. Generating poetry from images is much more challenging than generating poetry from text, since images contain very rich visual information which cannot be described completely using several keywords, and a good poem should convey the image accurately. In this paper, we propose a memory based neural model which exploits images to generate poems. Specifically, an Encoder-Decoder model with a topic memory network is proposed to generate classical Chinese poetry from images. To the best of our knowledge, this is the first work attempting to generate classical Chinese poetry from images with neural networks. A comprehensive experimental investigation with both human evaluation and quantitative analysis demonstrates that the proposed model can generate poems which convey images accurately.
Study of Set-Membership Kernel Adaptive Algorithms and Applications
Aug 27, 2017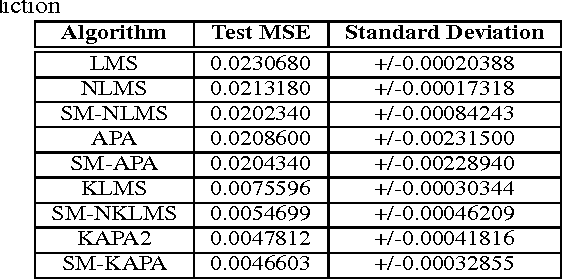
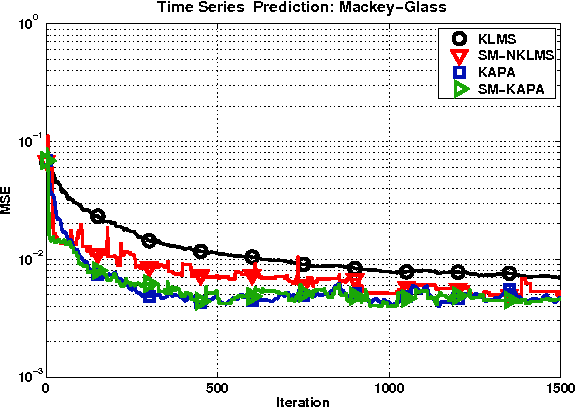
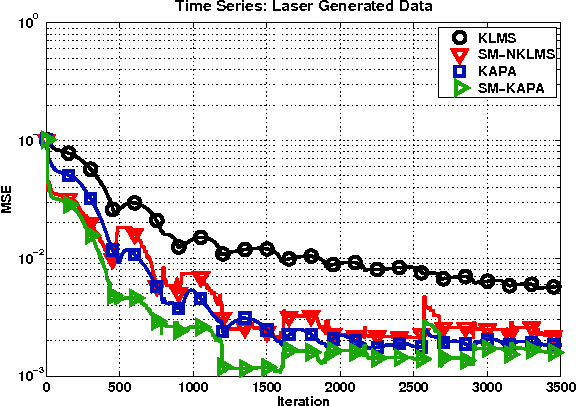
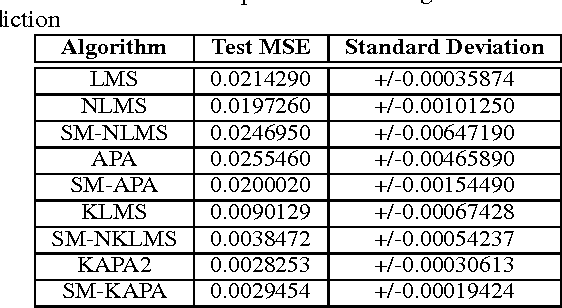
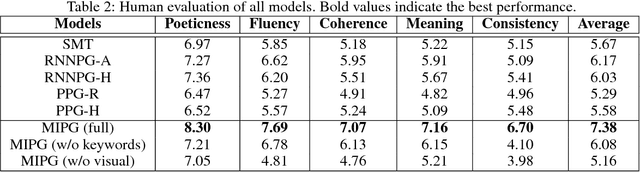
Adaptive algorithms based on kernel structures have been a topic of significant research over the past few years. The main advantage is that they form a family of universal approximators, offering an elegant solution to problems with nonlinearities. Nevertheless these methods deal with kernel expansions, creating a growing structure also known as dictionary, whose size depends on the number of new inputs. In this paper we derive the set-membership kernel-based normalized least-mean square (SM-NKLMS) algorithm, which is capable of limiting the size of the dictionary created in stationary environments. We also derive as an extension the set-membership kernelized affine projection (SM-KAP) algorithm. Finally several experiments are presented to compare the proposed SM-NKLMS and SM-KAP algorithms to the existing methods.
A Projection Based Conditional Dependence Measure with Applications to High-dimensional Undirected Graphical Models
Feb 14, 2017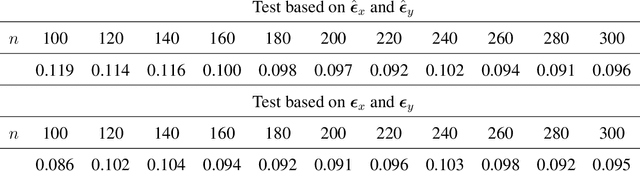
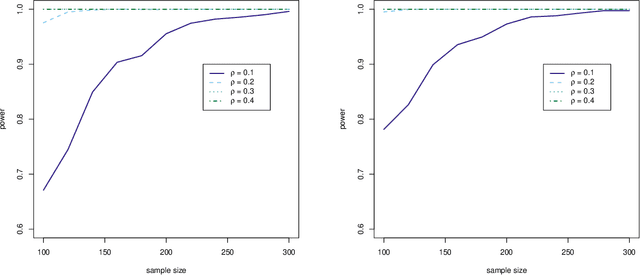
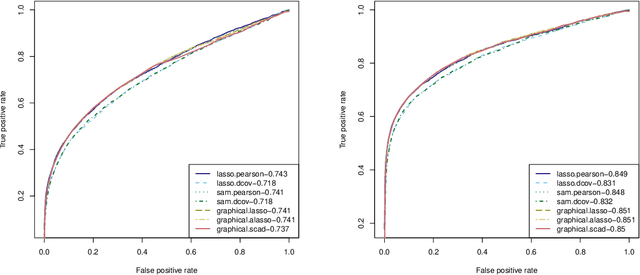
Measuring conditional dependence is an important topic in statistics with broad applications including graphical models. Under a factor model setting, a new conditional dependence measure based on projection is proposed. The corresponding conditional independence test is developed with the asymptotic null distribution unveiled where the number of factors could be high-dimensional. It is also shown that the new test has control over the asymptotic significance level and can be calculated efficiently. A generic method for building dependency graphs without Gaussian assumption using the new test is elaborated. Numerical results and real data analysis show the superiority of the new method.
Hierarchical Dirichlet Scaling Process
Feb 11, 2015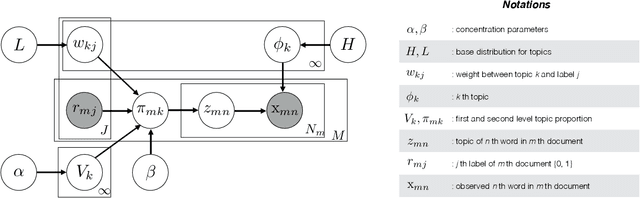

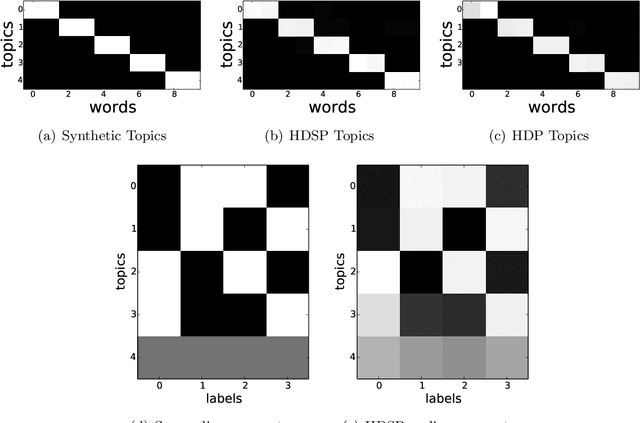

We present the \textit{hierarchical Dirichlet scaling process} (HDSP), a Bayesian nonparametric mixed membership model. The HDSP generalizes the hierarchical Dirichlet process (HDP) to model the correlation structure between metadata in the corpus and mixture components. We construct the HDSP based on the normalized gamma representation of the Dirichlet process, and this construction allows incorporating a scaling function that controls the membership probabilities of the mixture components. We develop two scaling methods to demonstrate that different modeling assumptions can be expressed in the HDSP. We also derive the corresponding approximate posterior inference algorithms using variational Bayes. Through experiments on datasets of newswire, medical journal articles, conference proceedings, and product reviews, we show that the HDSP results in a better predictive performance than labeled LDA, partially labeled LDA, and author topic model and a better negative review classification performance than the supervised topic model and SVM.