 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Computing Web-scale Topic Models using an Asynchronous Parameter Server
Jun 18, 2017
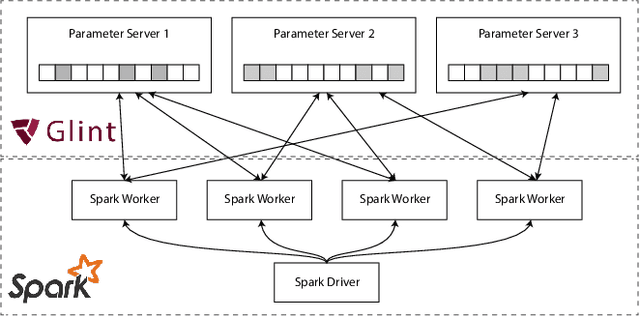
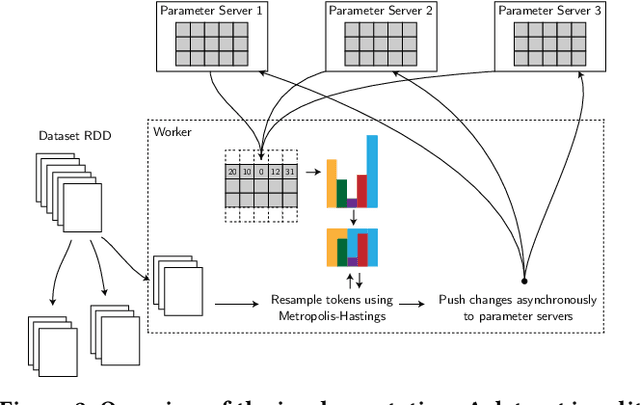
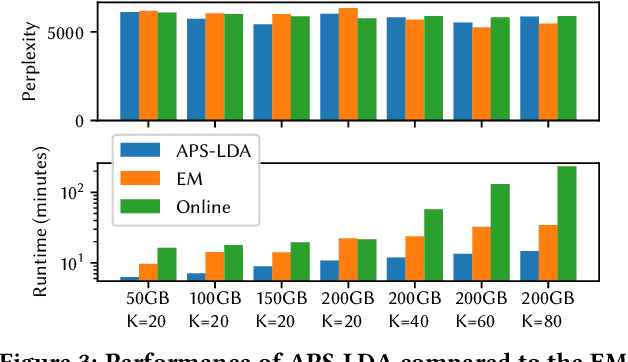
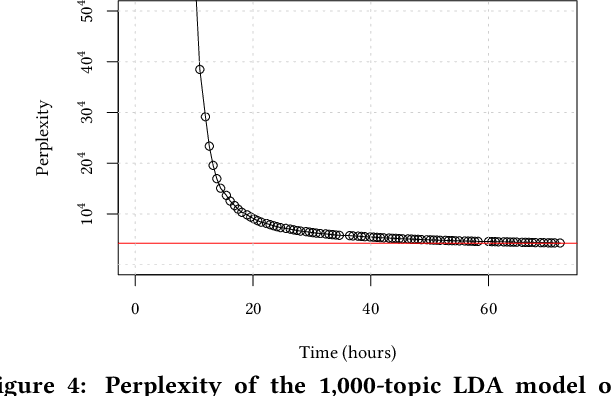
Topic models such as Latent Dirichlet Allocation (LDA) have been widely used in information retrieval for tasks ranging from smoothing and feedback methods to tools for exploratory search and discovery. However, classical methods for inferring topic models do not scale up to the massive size of today's publicly available Web-scale data sets. The state-of-the-art approaches rely on custom strategies, implementations and hardware to facilitate their asynchronous, communication-intensive workloads. We present APS-LDA, which integrates state-of-the-art topic modeling with cluster computing frameworks such as Spark using a novel asynchronous parameter server. Advantages of this integration include convenient usage of existing data processing pipelines and eliminating the need for disk writes as data can be kept in memory from start to finish. Our goal is not to outperform highly customized implementations, but to propose a general high-performance topic modeling framework that can easily be used in today's data processing pipelines. We compare APS-LDA to the existing Spark LDA implementations and show that our system can, on a 480-core cluster, process up to 135 times more data and 10 times more topics without sacrificing model quality.
Improved Patient Classification with Language Model Pretraining Over Clinical Notes
Oct 02, 2019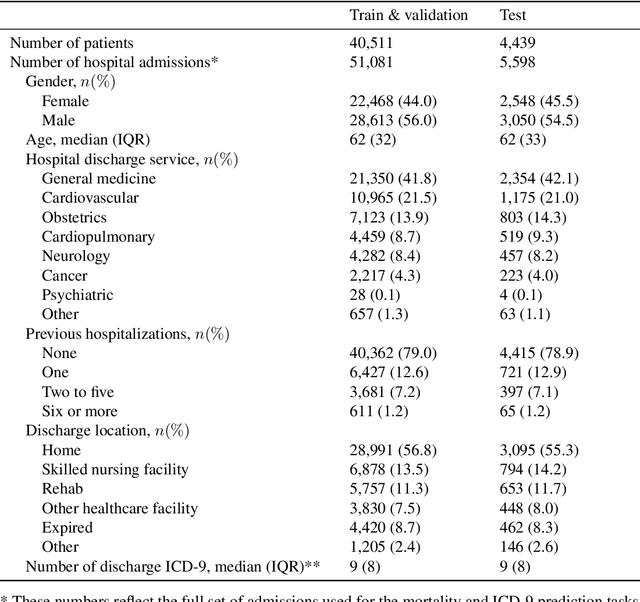
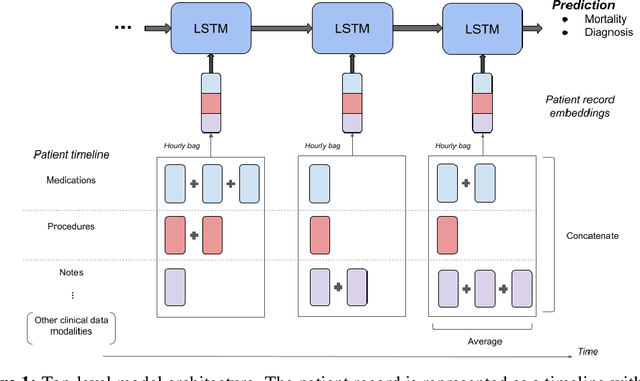
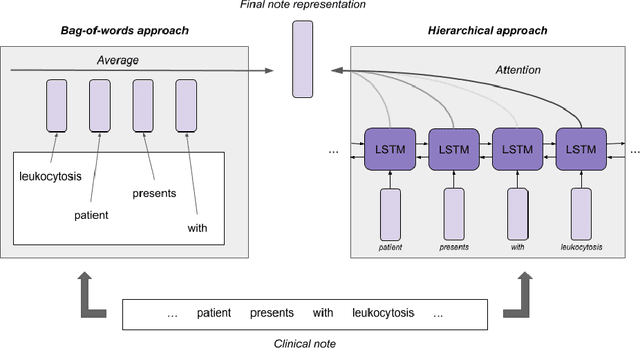
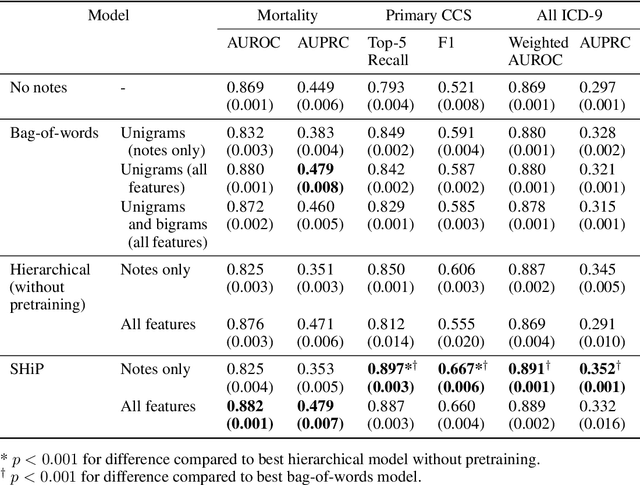
Clinical notes in electronic health records contain highly heterogeneous writing styles, including non-standard terminology or abbreviations. Using these notes in predictive modeling has traditionally required preprocessing (e.g. taking frequent terms or topic modeling) that removes much of the richness of the source data. We propose a pretrained hierarchical recurrent neural network model that parses minimally processed clinical notes in an intuitive fashion, and show that it improves performance for multiple classification tasks on the Medical Information Mart for Intensive Care III (MIMIC-III) dataset, improving top-5 recall to 89.7% (increase of 4.8%) for primary diagnosis classification and AUPRC to 35.2% (increase of 2.1%) for multilabel diagnosis classification compared to models that treat the notes as an unordered collection of terms, using no pretraining. We also apply an attribution technique to several examples to identify the words and the nearby context that the model uses to make its prediction, and show the importance of the words' context.
Learning from Binary Multiway Data: Probabilistic Tensor Decomposition and its Statistical Optimality
Nov 13, 2018
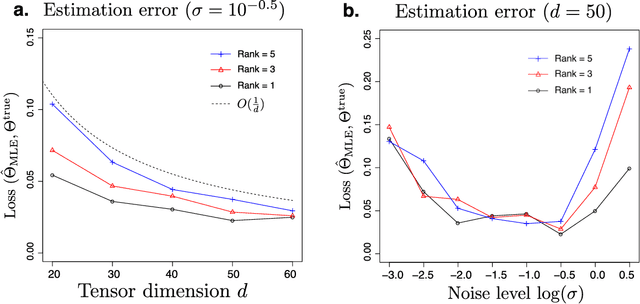
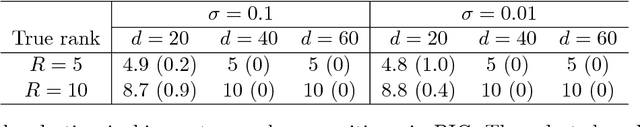
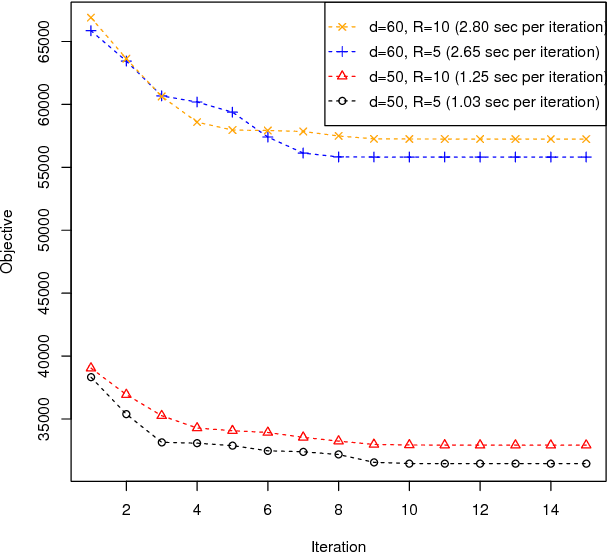
We consider the problem of decomposition of multiway tensor with binary entries. Such data problems arise frequently in numerous applications such as neuroimaging, recommendation system, topic modeling, and sensor network localization. We propose that the observed binary entries follow a Bernoulli model, develop a rank-constrained likelihood-based estimation procedure, and obtain the theoretical accuracy guarantees. Specifically, we establish the error bound of the tensor estimation, and show that the obtained rate is minimax optimal under the considered model. We demonstrate the efficacy of our approach through both simulations and analyses of multiple real-world datasets on the tasks of tensor completion and clustering.
PL-NMF: Parallel Locality-Optimized Non-negative Matrix Factorization
Apr 16, 2019
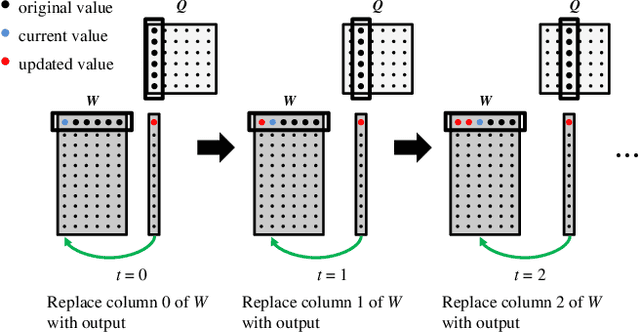

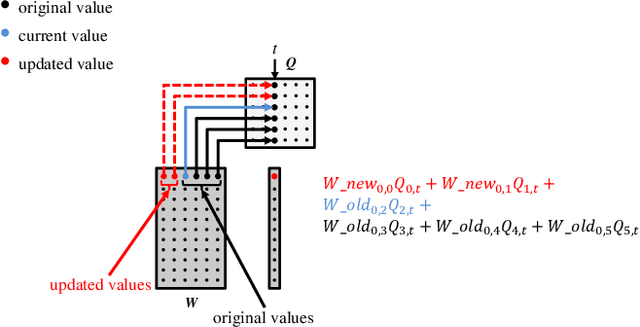
Non-negative Matrix Factorization (NMF) is a key kernel for unsupervised dimension reduction used in a wide range of applications, including topic modeling, recommender systems and bioinformatics. Due to the compute-intensive nature of applications that must perform repeated NMF, several parallel implementations have been developed in the past. However, existing parallel NMF algorithms have not addressed data locality optimizations, which are critical for high performance since data movement costs greatly exceed the cost of arithmetic/logic operations on current computer systems. In this paper, we devise a parallel NMF algorithm based on the HALS (Hierarchical Alternating Least Squares) scheme that incorporates algorithmic transformations to enhance data locality. Efficient realizations of the algorithm on multi-core CPUs and GPUs are developed, demonstrating significant performance improvement over existing state-of-the-art parallel NMF algorithms.
Generating an Overview Report over Many Documents
Aug 17, 2019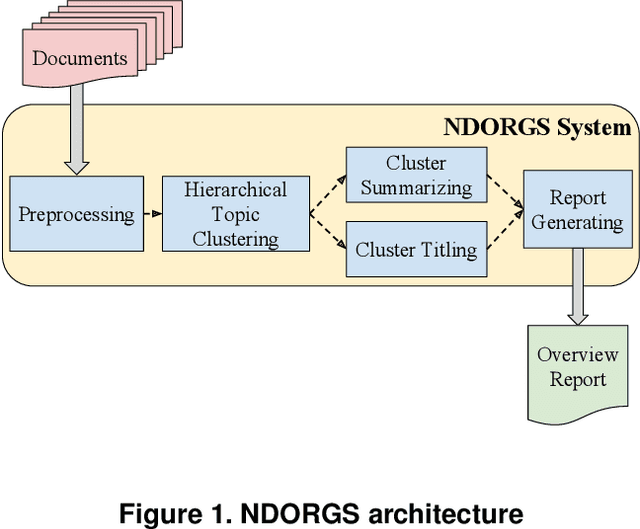
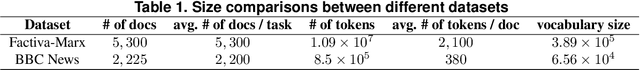
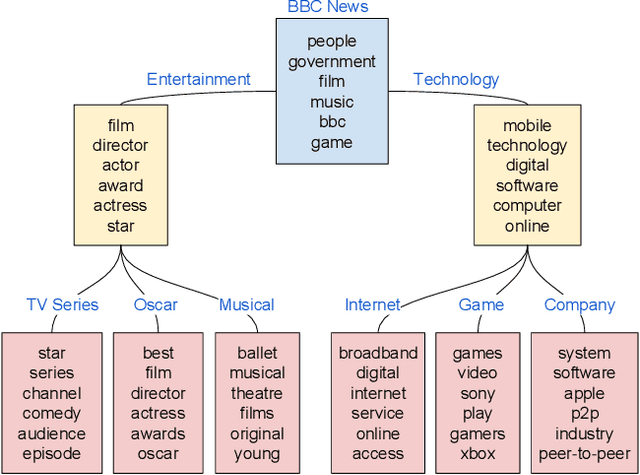

How to efficiently generate an accurate, well-structured overview report (ORPT) over thousands of related documents is challenging. A well-structured ORPT consists of sections of multiple levels (e.g., sections and subsections). None of the existing multi-document summarization (MDS) algorithms is directed toward this task. To overcome this obstacle, we present NDORGS (Numerous Documents' Overview Report Generation Scheme) that integrates text filtering, keyword scoring, single-document summarization (SDS), topic modeling, MDS, and title generation to generate a coherent, well-structured ORPT. We then devise a multi-criteria evaluation method using techniques of text mining and multi-attribute decision making on a combination of human judgments, running time, information coverage, and topic diversity. We evaluate ORPTs generated by NDORGS on two large corpora of documents, where one is classified and the other unclassified. We show that, using Saaty's pairwise comparison 9-point scale and under TOPSIS, the ORPTs generated on SDS's with the length of 20% of the original documents are the best overall on both datasets.
A Correspondence Analysis Framework for Author-Conference Recommendations
Jan 08, 2020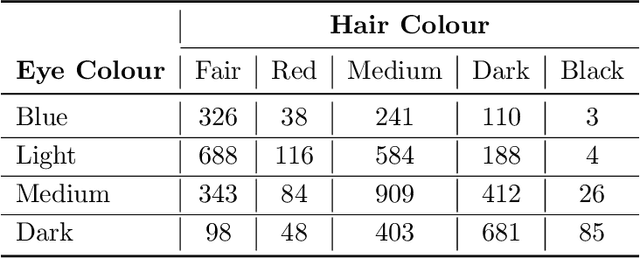
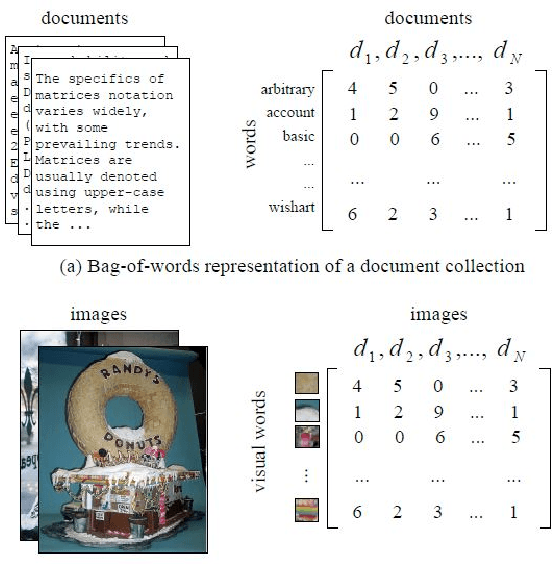
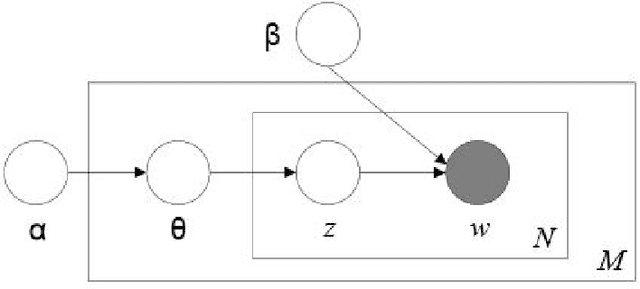
For many years, achievements and discoveries made by scientists are made aware through research papers published in appropriate journals or conferences. Often, established scientists and especially newbies are caught up in the dilemma of choosing an appropriate conference to get their work through. Every scientific conference and journal is inclined towards a particular field of research and there is a vast multitude of them for any particular field. Choosing an appropriate venue is vital as it helps in reaching out to the right audience and also to further one's chance of getting their paper published. In this work, we address the problem of recommending appropriate conferences to the authors to increase their chances of acceptance. We present three different approaches for the same involving the use of social network of the authors and the content of the paper in the settings of dimensionality reduction and topic modeling. In all these approaches, we apply Correspondence Analysis (CA) to derive appropriate relationships between the entities in question, such as conferences and papers. Our models show promising results when compared with existing methods such as content-based filtering, collaborative filtering and hybrid filtering.
L2RS: A Learning-to-Rescore Mechanism for Automatic Speech Recognition
Oct 25, 2019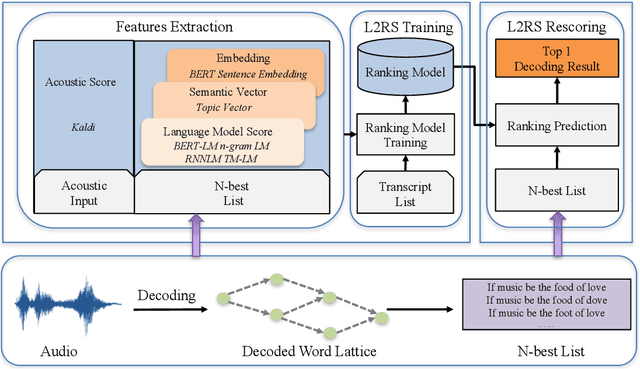
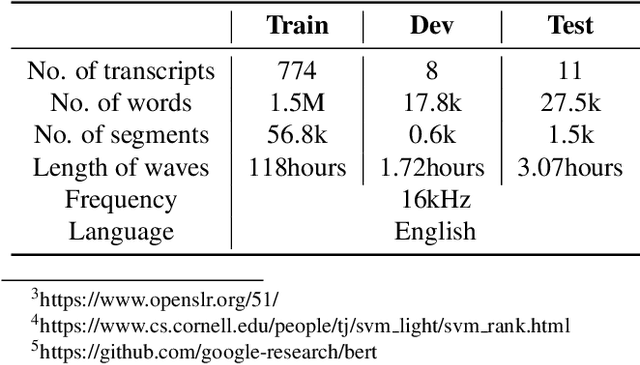
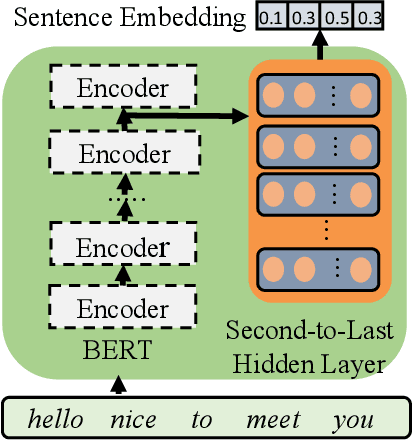
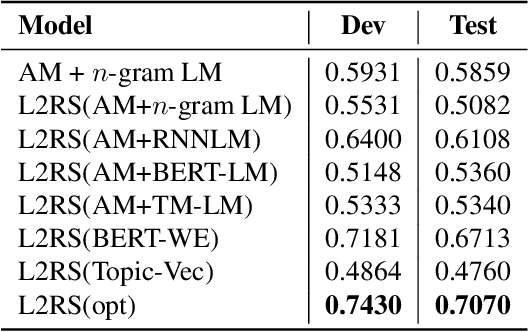
Modern Automatic Speech Recognition (ASR) systems primarily rely on scores from an Acoustic Model (AM) and a Language Model (LM) to rescore the N-best lists. With the abundance of recent natural language processing advances, the information utilized by current ASR for evaluating the linguistic and semantic legitimacy of the N-best hypotheses is rather limited. In this paper, we propose a novel Learning-to-Rescore (L2RS) mechanism, which is specialized for utilizing a wide range of textual information from the state-of-the-art NLP models and automatically deciding their weights to rescore the N-best lists for ASR systems. Specifically, we incorporate features including BERT sentence embedding, topic vector, and perplexity scores produced by n-gram LM, topic modeling LM, BERT LM and RNNLM to train a rescoring model. We conduct extensive experiments based on a public dataset, and experimental results show that L2RS outperforms not only traditional rescoring methods but also its deep neural network counterparts by a substantial improvement of 20.67% in terms of NDCG@10. L2RS paves the way for developing more effective rescoring models for ASR.
Topic Detection and Summarization of User Reviews
May 30, 2020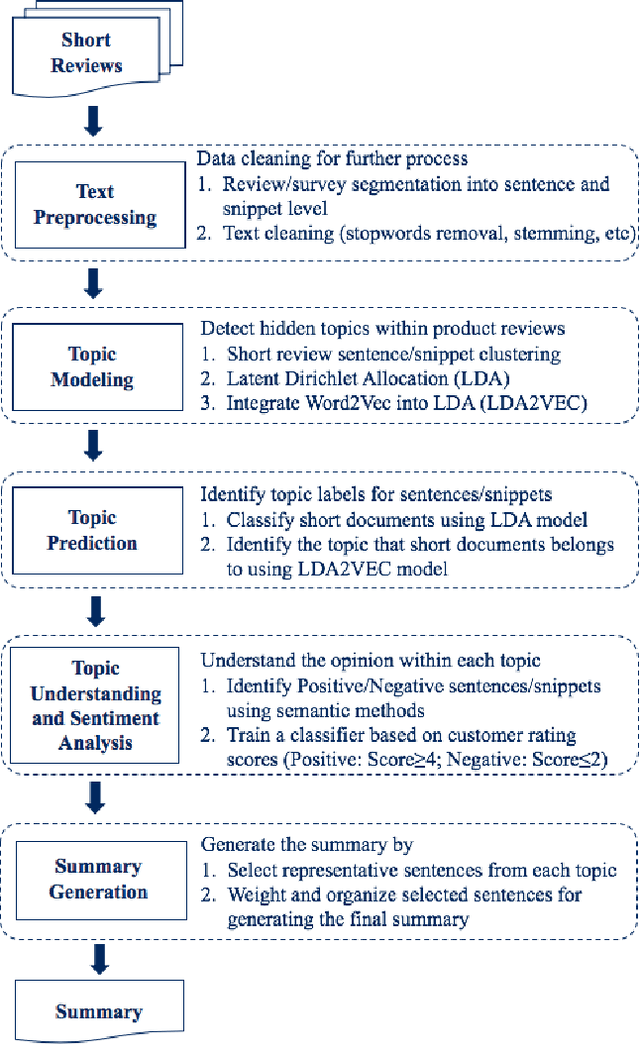
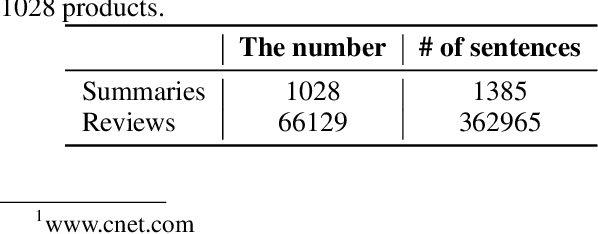

A massive amount of reviews are generated daily from various platforms. It is impossible for people to read through tons of reviews and to obtain useful information. Automatic summarizing customer reviews thus is important for identifying and extracting the essential information to help users to obtain the gist of the data. However, as customer reviews are typically short, informal, and multifaceted, it is extremely challenging to generate topic-wise summarization.While there are several studies aims to solve this issue, they are heuristic methods that are developed only utilizing customer reviews. Unlike existing method, we propose an effective new summarization method by analyzing both reviews and summaries.To do that, we first segment reviews and summaries into individual sentiments. As the sentiments are typically short, we combine sentiments talking about the same aspect into a single document and apply topic modeling method to identify hidden topics among customer reviews and summaries. Sentiment analysis is employed to distinguish positive and negative opinions among each detected topic. A classifier is also introduced to distinguish the writing pattern of summaries and that of customer reviews. Finally, sentiments are selected to generate the summarization based on their topic relevance, sentiment analysis score and the writing pattern. To test our method, a new dataset comprising product reviews and summaries about 1028 products are collected from Amazon and CNET. Experimental results show the effectiveness of our method compared with other methods.
Mixed Membership Recurrent Neural Networks
Dec 23, 2018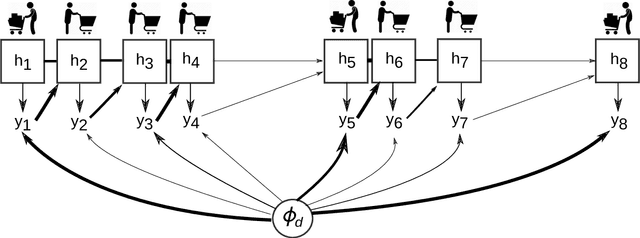
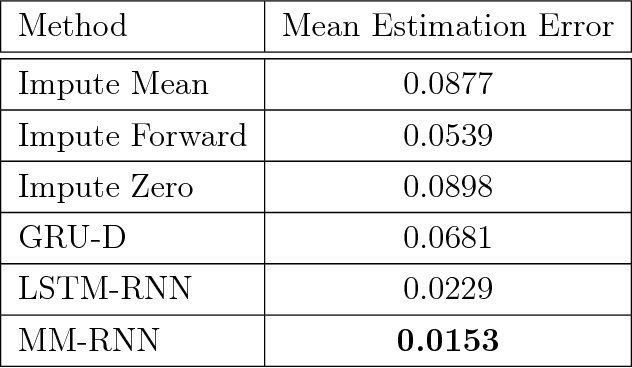
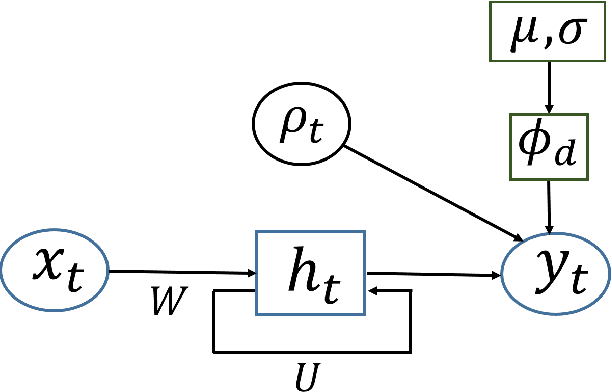
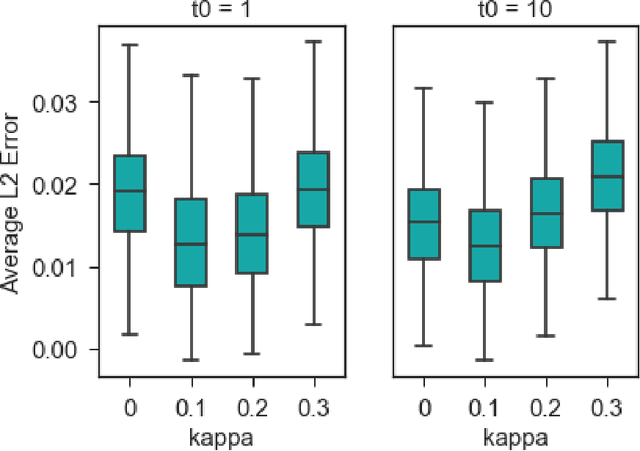
Models for sequential data such as the recurrent neural network (RNN) often implicitly model a sequence as having a fixed time interval between observations and do not account for group-level effects when multiple sequences are observed. We propose a model for grouped sequential data based on the RNN that accounts for varying time intervals between observations in a sequence by learning a group-level base parameter to which each sequence can revert. Our approach is motivated by the mixed membership framework, and we show how it can be used for dynamic topic modeling in which the distribution on topics (not the topics themselves) are evolving in time. We demonstrate our approach on a dataset of 3.4 million online grocery shopping orders made by 206K customers.