 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Top2Vec: Distributed Representations of Topics
Aug 19, 2020



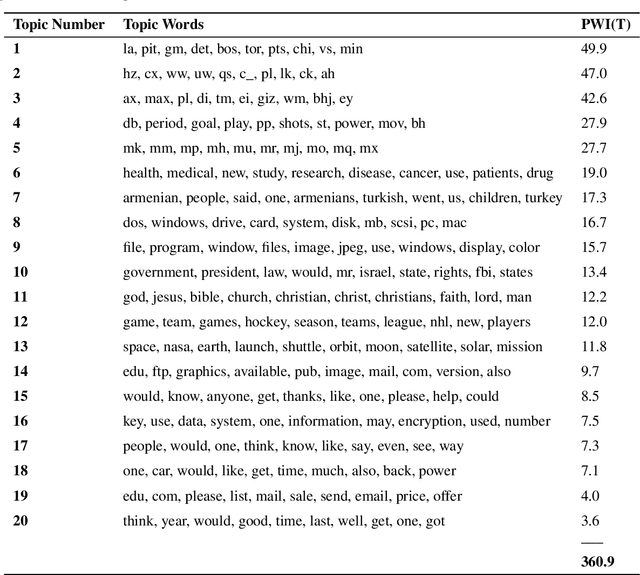
Topic modeling is used for discovering latent semantic structure, usually referred to as topics, in a large collection of documents. The most widely used methods are Latent Dirichlet Allocation and Probabilistic Latent Semantic Analysis. Despite their popularity they have several weaknesses. In order to achieve optimal results they often require the number of topics to be known, custom stop-word lists, stemming, and lemmatization. Additionally these methods rely on bag-of-words representation of documents which ignore the ordering and semantics of words. Distributed representations of documents and words have gained popularity due to their ability to capture semantics of words and documents. We present $\texttt{top2vec}$, which leverages joint document and word semantic embedding to find $\textit{topic vectors}$. This model does not require stop-word lists, stemming or lemmatization, and it automatically finds the number of topics. The resulting topic vectors are jointly embedded with the document and word vectors with distance between them representing semantic similarity. Our experiments demonstrate that $\texttt{top2vec}$ finds topics which are significantly more informative and representative of the corpus trained on than probabilistic generative models.
Topic Modeling of Behavioral Modes Using Sensor Data
Nov 16, 2015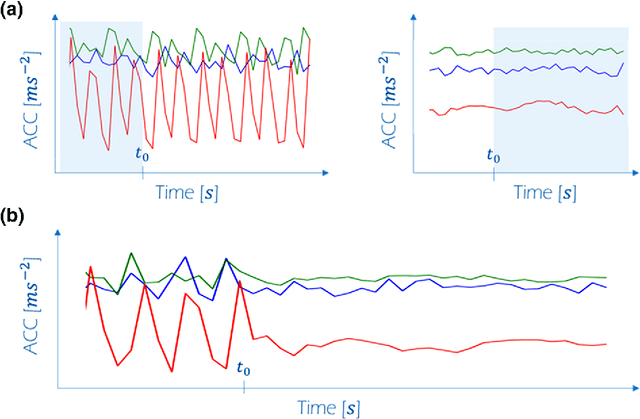
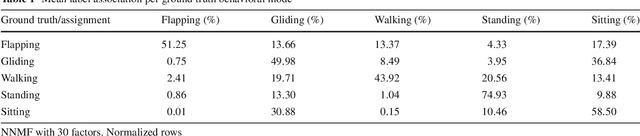
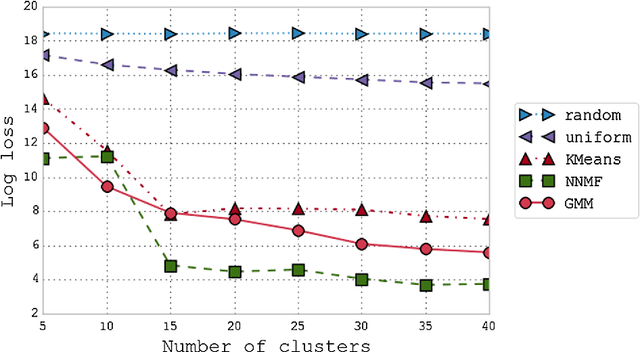
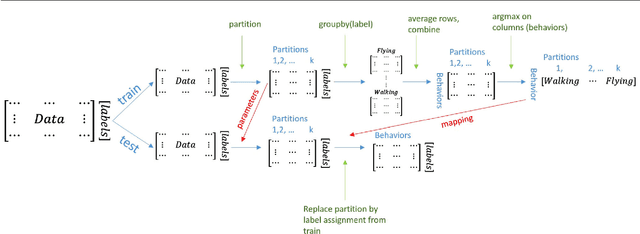
The field of Movement Ecology, like so many other fields, is experiencing a period of rapid growth in availability of data. As the volume rises, traditional methods are giving way to machine learning and data science, which are playing an increasingly large part it turning this data into science-driving insights. One rich and interesting source is the bio-logger. These small electronic wearable devices are attached to animals free to roam in their natural habitats, and report back readings from multiple sensors, including GPS and accelerometer bursts. A common use of accelerometer data is for supervised learning of behavioral modes. However, we need unsupervised analysis tools as well, in order to overcome the inherent difficulties of obtaining a labeled dataset, which in some cases is either infeasible or does not successfully encompass the full repertoire of behavioral modes of interest. Here we present a matrix factorization based topic-model method for accelerometer bursts, derived using a linear mixture property of patch features. Our method is validated via comparison to a labeled dataset, and is further compared to standard clustering algorithms.
* Invited Extended version of a paper \cite{resheffmatrix} presented at the international conference \textit{Data Science and Advanced Analytics}, Paris, France, 19-21 OCtober 2015
Identifying Reference Spans: Topic Modeling and Word Embeddings help IR
Aug 09, 2017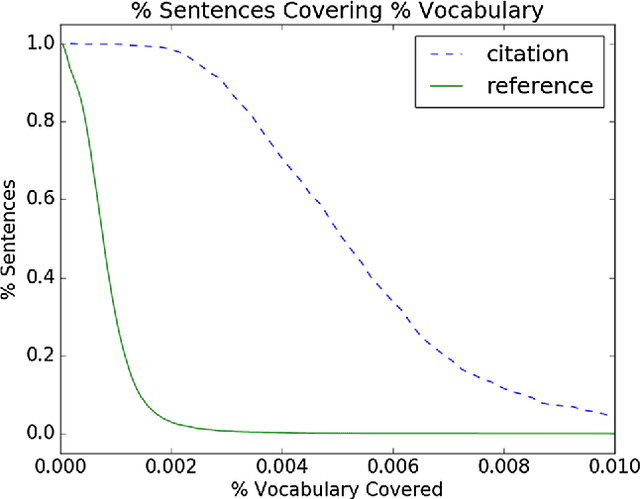
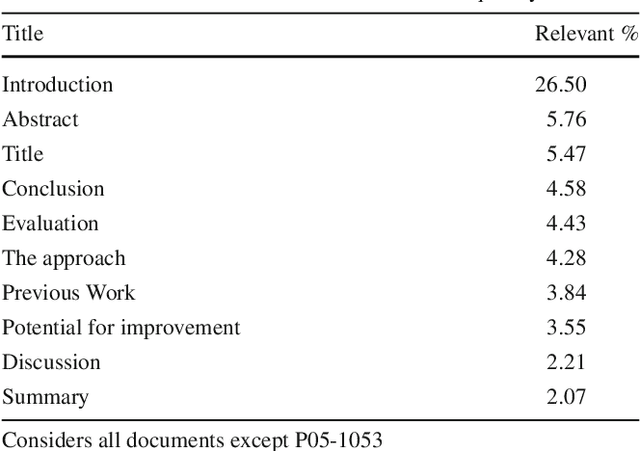

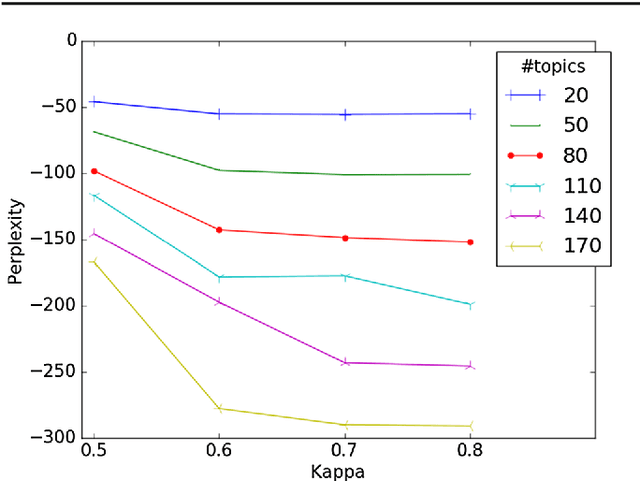
The CL-SciSumm 2016 shared task introduced an interesting problem: given a document D and a piece of text that cites D, how do we identify the text spans of D being referenced by the piece of text? The shared task provided the first annotated dataset for studying this problem. We present an analysis of our continued work in improving our system's performance on this task. We demonstrate how topic models and word embeddings can be used to surpass the previously best performing system.
Conditional Hierarchical Bayesian Tucker Decomposition
Dec 12, 2019
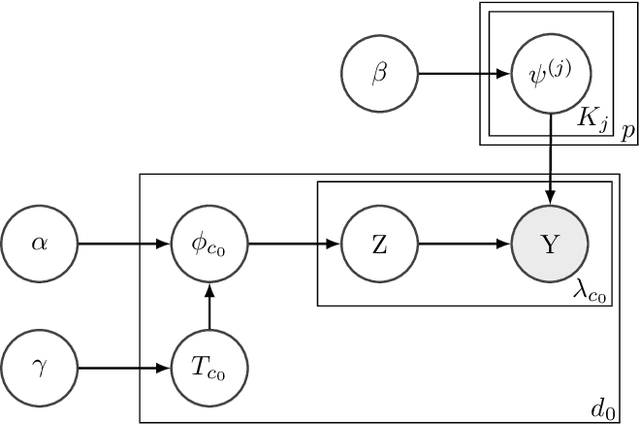
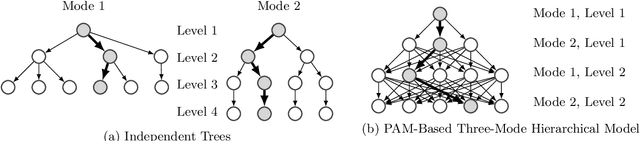

Our research focuses on studying and developing methods for reducing the dimensionality of large datasets, common in biomedical applications. A major problem when learning information about patients based on genetic sequencing data is that there are often more feature variables (genetic data) than observations (patients). This makes direct supervised learning difficult. One way of reducing the feature space is to use latent Dirichlet allocation in order to group genetic variants in an unsupervised manner. Latent Dirichlet allocation is a common model in natural language processing, which describes a document as a mixture of topics, each with a probability of generating certain words. This can be generalized as a Bayesian tensor decomposition to account for multiple feature variables. While we made some progress improving and modifying these methods, our significant contributions are with hierarchical topic modeling. We developed distinct methods of incorporating hierarchical topic modeling, based on nested Chinese restaurant processes and Pachinko Allocation Machine, into Bayesian tensor decompositions. We apply these models to predict whether or not patients have autism spectrum disorder based on genetic sequencing data. We examine a dataset from National Database for Autism Research consisting of paired siblings -- one with autism, and the other without -- and counts of their genetic variants. Additionally, we linked the genes with their Reactome biological pathways. We combine this information into a tensor of patients, counts of their genetic variants, and the membership of these genes in pathways. Once we decompose this tensor, we use logistic regression on the reduced features in order to predict if patients have autism. We also perform a similar analysis of a dataset of patients with one of four common types of cancer (breast, lung, prostate, and colorectal).
Improving unsupervised neural aspect extraction for online discussions using out-of-domain classification
Jun 17, 2020
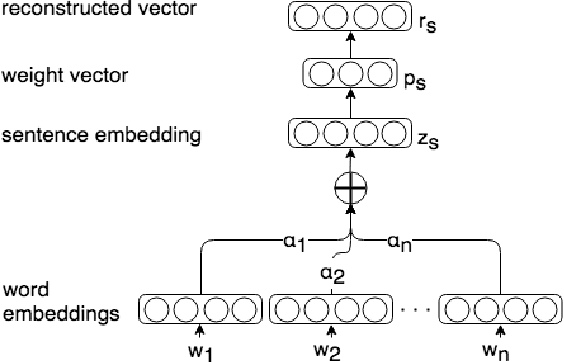
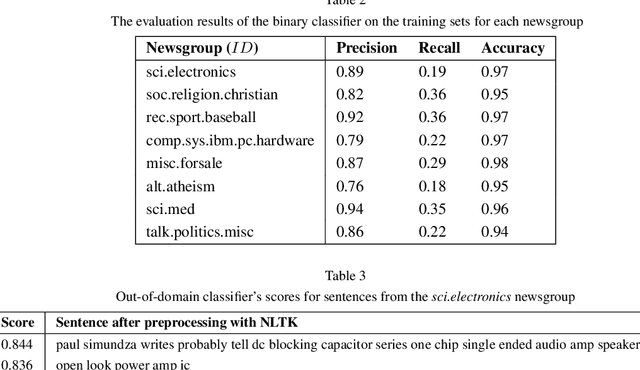
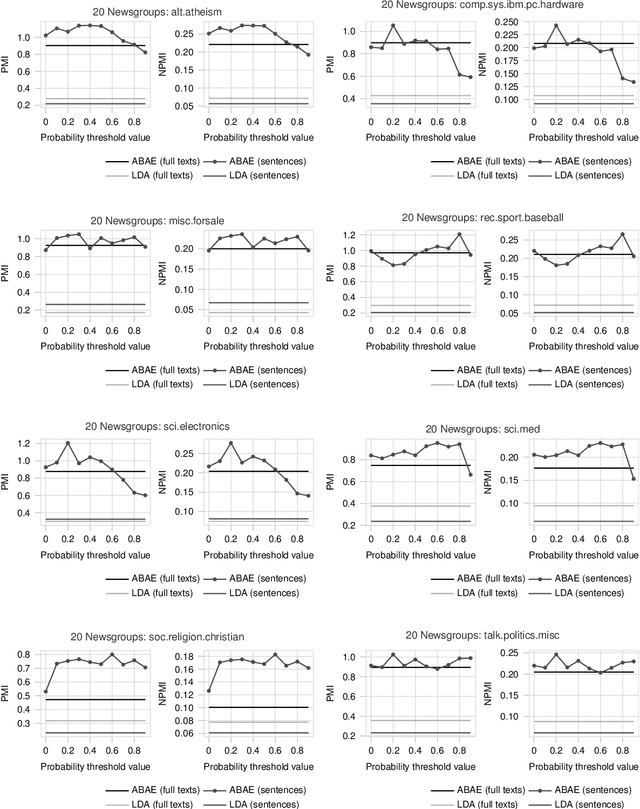
Deep learning architectures based on self-attention have recently achieved and surpassed state of the art results in the task of unsupervised aspect extraction and topic modeling. While models such as neural attention-based aspect extraction (ABAE) have been successfully applied to user-generated texts, they are less coherent when applied to traditional data sources such as news articles and newsgroup documents. In this work, we introduce a simple approach based on sentence filtering in order to improve topical aspects learned from newsgroups-based content without modifying the basic mechanism of ABAE. We train a probabilistic classifier to distinguish between out-of-domain texts (outer dataset) and in-domain texts (target dataset). Then, during data preparation we filter out sentences that have a low probability of being in-domain and train the neural model on the remaining sentences. The positive effect of sentence filtering on topic coherence is demonstrated in comparison to aspect extraction models trained on unfiltered texts.
Streaming dynamic and distributed inference of latent geometric structures
Sep 24, 2018
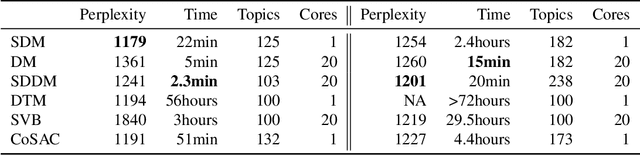
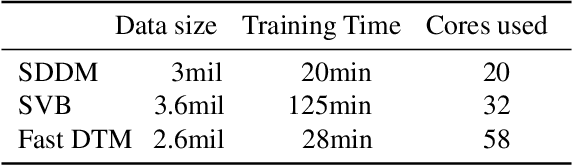
We develop new models and algorithms for learning the temporal dynamics of the topic polytopes and related geometric objects that arise in topic model based inference. Our model is nonparametric Bayesian and the corresponding inference algorithm is able to discover new topics as the time progresses. By exploiting the connection between the modeling of topic polytope evolution, Beta-Bernoulli process and the Hungarian matching algorithm, our method is shown to be several orders of magnitude faster than existing topic modeling approaches, as demonstrated by experiments working with several million documents in a dozen minutes.
Leveraging Natural Language Processing to Mine Issues on Twitter During the COVID-19 Pandemic
Nov 03, 2020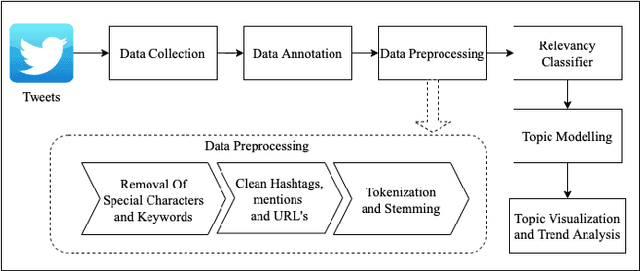
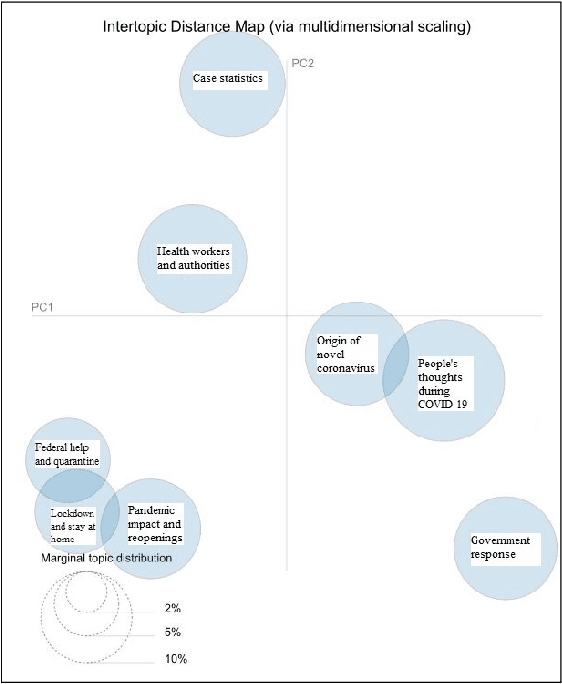
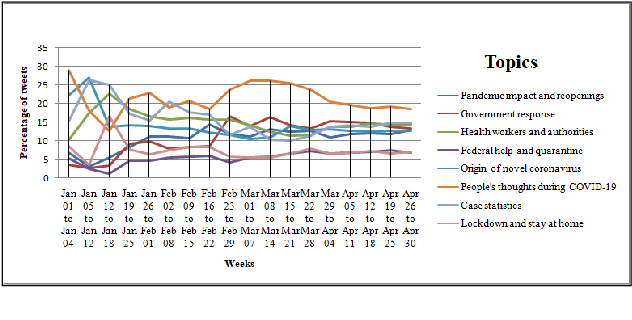
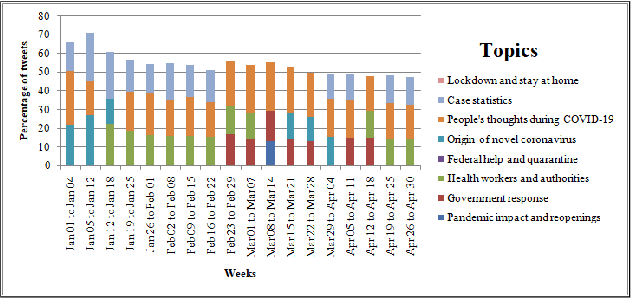
The recent global outbreak of the coronavirus disease (COVID-19) has spread to all corners of the globe. The international travel ban, panic buying, and the need for self-quarantine are among the many other social challenges brought about in this new era. Twitter platforms have been used in various public health studies to identify public opinion about an event at the local and global scale. To understand the public concerns and responses to the pandemic, a system that can leverage machine learning techniques to filter out irrelevant tweets and identify the important topics of discussion on social media platforms like Twitter is needed. In this study, we constructed a system to identify the relevant tweets related to the COVID-19 pandemic throughout January 1st, 2020 to April 30th, 2020, and explored topic modeling to identify the most discussed topics and themes during this period in our data set. Additionally, we analyzed the temporal changes in the topics with respect to the events that occurred during this pandemic. We found out that eight topics were sufficient to identify the themes in our corpus. These topics depicted a temporal trend. The dominant topics vary over time and align with the events related to the COVID-19 pandemic.
Latent Dirichlet Allocation (LDA) for Topic Modeling of the CFPB Consumer Complaints
Jul 18, 2018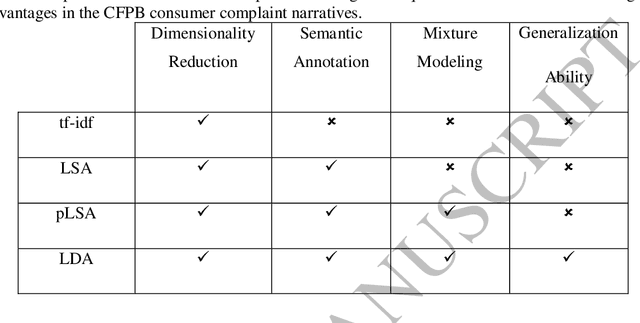
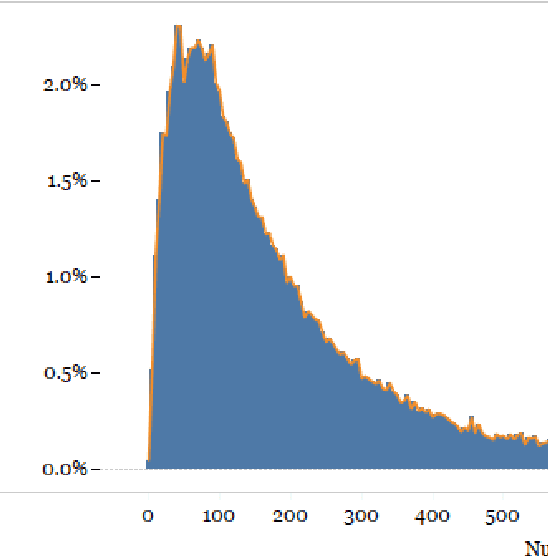
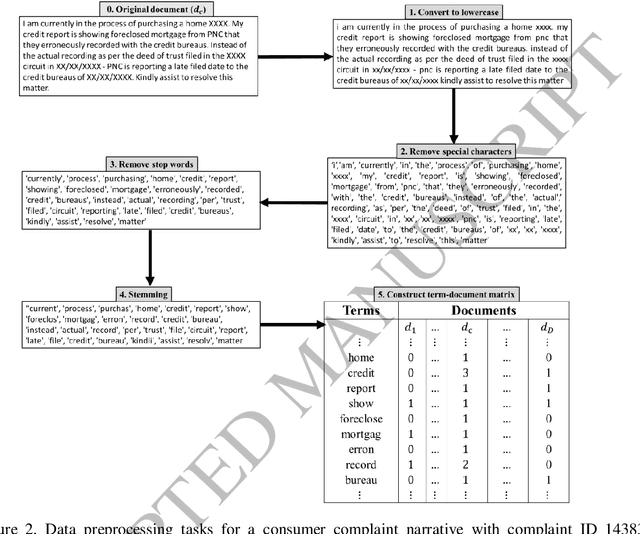
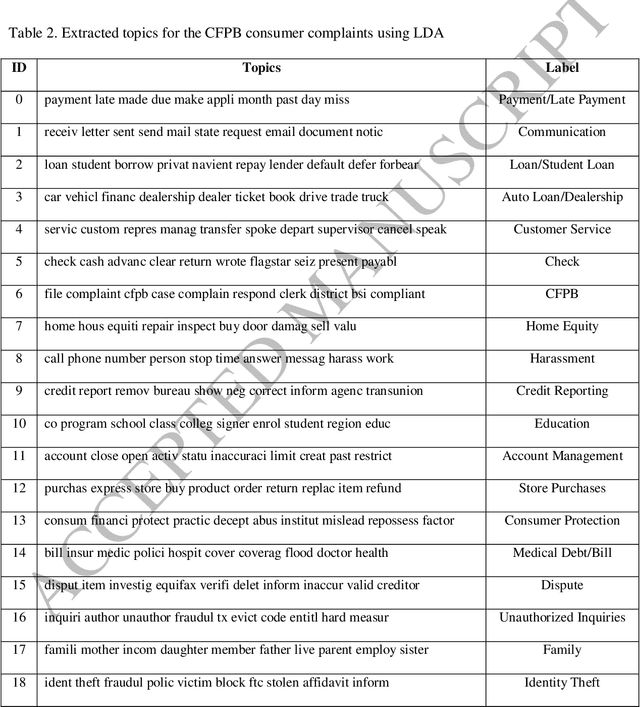
A text mining approach is proposed based on latent Dirichlet allocation (LDA) to analyze the Consumer Financial Protection Bureau (CFPB) consumer complaints. The proposed approach aims to extract latent topics in the CFPB complaint narratives, and explores their associated trends over time. The time trends will then be used to evaluate the effectiveness of the CFPB regulations and expectations on financial institutions in creating a consumer oriented culture that treats consumers fairly and prioritizes consumer protection in their decision making processes. The proposed approach can be easily operationalized as a decision support system to automate detection of emerging topics in consumer complaints. Hence, the technology-human partnership between the proposed approach and the CFPB team could certainly improve consumer protections from unfair, deceptive or abusive practices in the financial markets by providing more efficient and effective investigations of consumer complaint narratives.
Streaming Coresets for Symmetric Tensor Factorization
Jun 01, 2020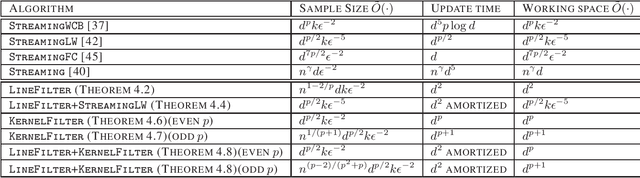
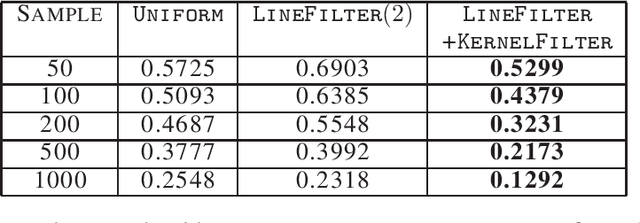
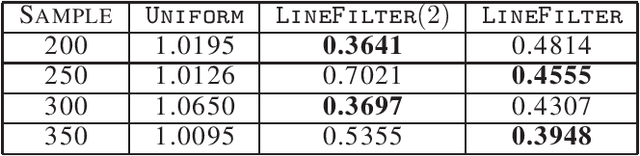
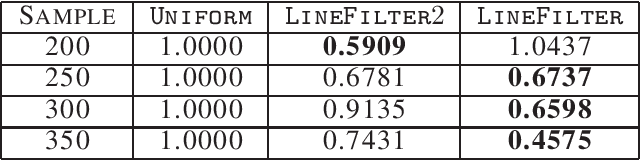
Factorizing tensors has recently become an important optimization module in a number of machine learning pipelines, especially in latent variable models. We show how to do this efficiently in the streaming setting. Given a set of $n$ vectors, each in $\mathbb{R}^d$, we present algorithms to select a sublinear number of these vectors as coreset, while guaranteeing that the CP decomposition of the $p$-moment tensor of the coreset approximates the corresponding decomposition of the $p$-moment tensor computed from the full data. We introduce two novel algorithmic techniques: online filtering and kernelization. Using these two, we present four algorithms that achieve different tradeoffs of coreset size, update time and working space, beating or matching various state of the art algorithms. In case of matrices (2-ordered tensor) our online row sampling algorithm guarantees $(1 \pm \epsilon)$ relative error spectral approximation. We show applications of our algorithms in learning single topic modeling.