 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Detecting New Word Meanings: A Comparison of Word Embedding Models in Spanish
Jan 12, 2020
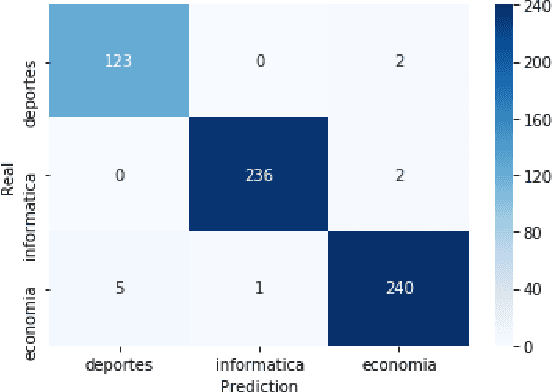
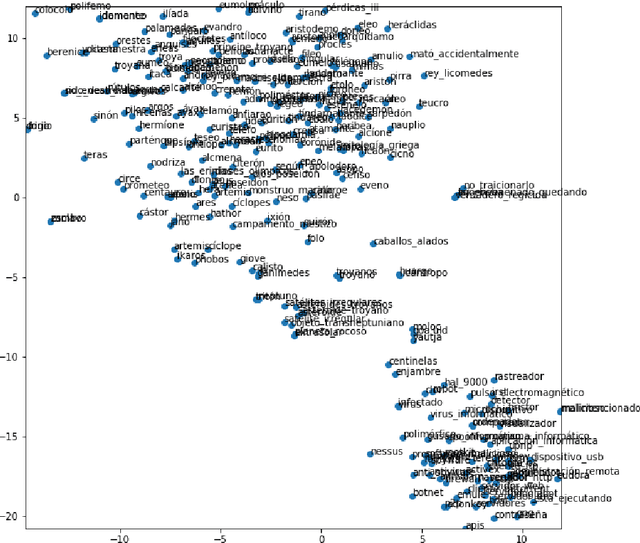
Semantic neologisms (SN) are defined as words that acquire a new word meaning while maintaining their form. Given the nature of this kind of neologisms, the task of identifying these new word meanings is currently performed manually by specialists at observatories of neology. To detect SN in a semi-automatic way, we developed a system that implements a combination of the following strategies: topic modeling, keyword extraction, and word sense disambiguation. The role of topic modeling is to detect the themes that are treated in the input text. Themes within a text give clues about the particular meaning of the words that are used, for example: viral has one meaning in the context of computer science (CS) and another when talking about health. To extract keywords, we used TextRank with POS tag filtering. With this method, we can obtain relevant words that are already part of the Spanish lexicon. We use a deep learning model to determine if a given keyword could have a new meaning. Embeddings that are different from all the known meanings (or topics) indicate that a word might be a valid SN candidate. In this study, we examine the following word embedding models: Word2Vec, Sense2Vec, and FastText. The models were trained with equivalent parameters using Wikipedia in Spanish as corpora. Then we used a list of words and their concordances (obtained from our database of neologisms) to show the different embeddings that each model yields. Finally, we present a comparison of these outcomes with the concordances of each word to show how we can determine if a word could be a valid candidate for SN.
* 16 pages, 3 figures
Identifying Editor Roles in Argumentative Writing from Student Revision Histories
Sep 03, 2019

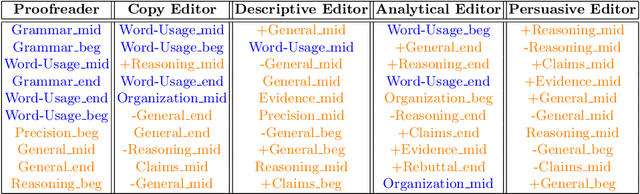

We present a method for identifying editor roles from students' revision behaviors during argumentative writing. We first develop a method for applying a topic modeling algorithm to identify a set of editor roles from a vocabulary capturing three aspects of student revision behaviors: operation, purpose, and position. We validate the identified roles by showing that modeling the editor roles that students take when revising a paper not only accounts for the variance in revision purposes in our data, but also relates to writing improvement.
Facebook Ad Engagement in the Russian Active Measures Campaign of 2016
Dec 23, 2020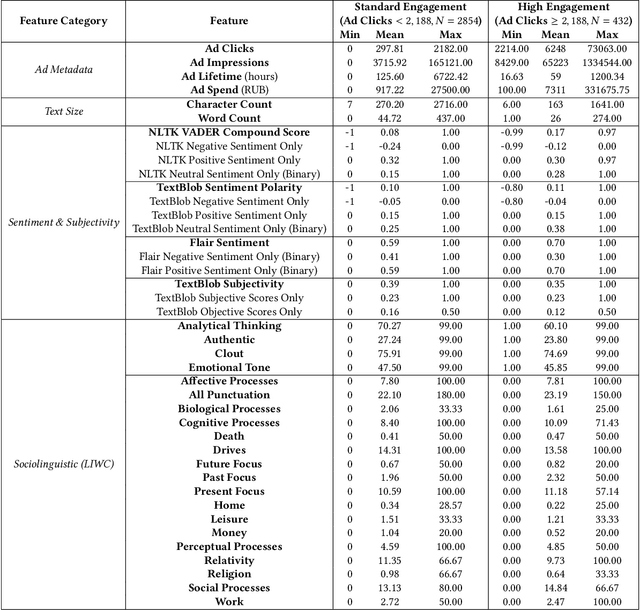
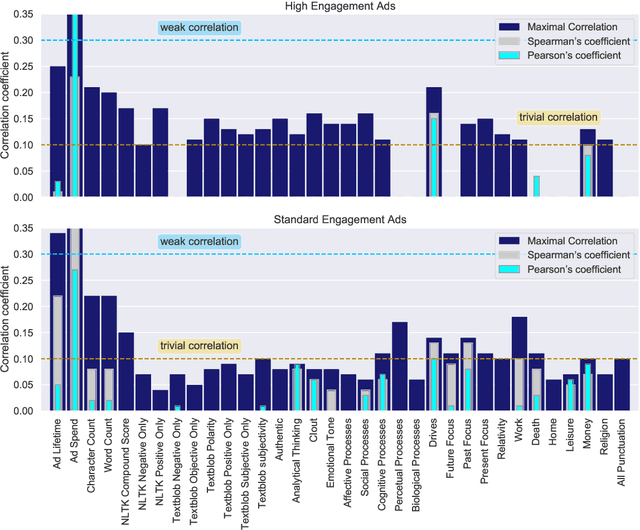
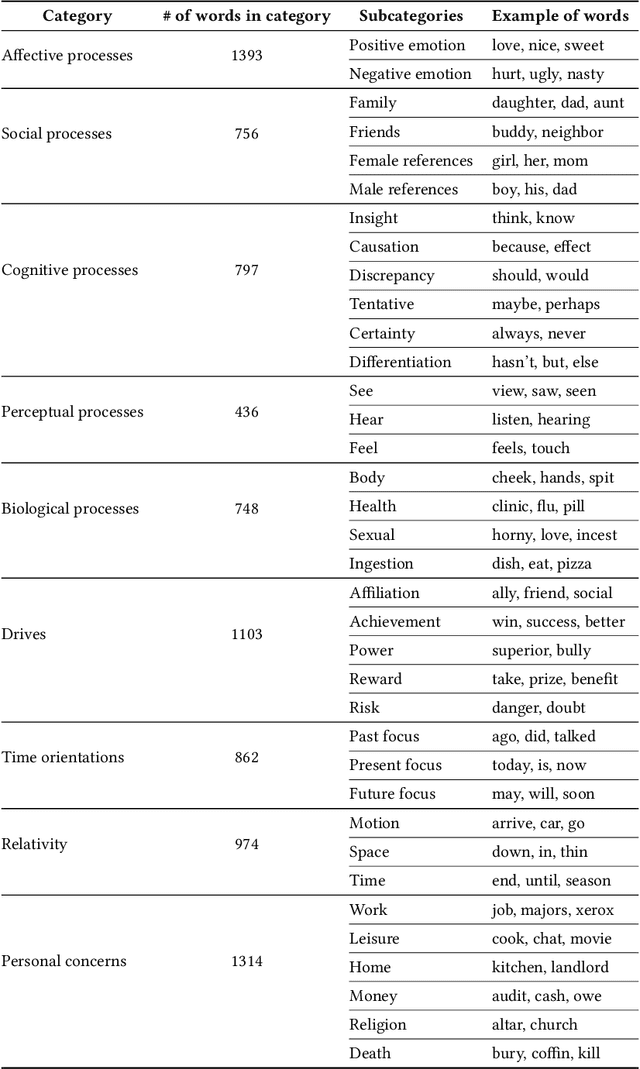
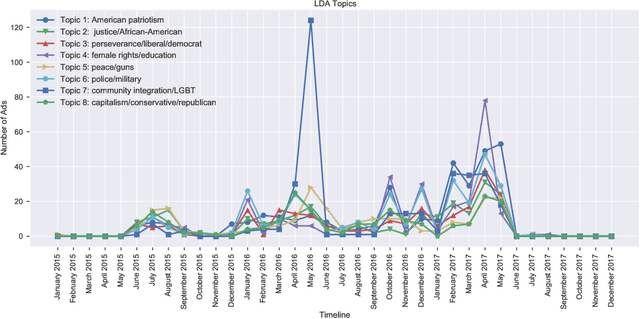
This paper examines 3,517 Facebook ads created by Russia's Internet Research Agency (IRA) between June 2015 and August 2017 in its active measures disinformation campaign targeting the 2016 U.S. general election. We aimed to unearth the relationship between ad engagement (as measured by ad clicks) and 41 features related to ads' metadata, sociolinguistic structures, and sentiment. Our analysis was three-fold: (i) understand the relationship between engagement and features via correlation analysis; (ii) find the most relevant feature subsets to predict engagement via feature selection; and (iii) find the semantic topics that best characterize the dataset via topic modeling. We found that ad expenditure, text size, ad lifetime, and sentiment were the top features predicting users' engagement to the ads. Additionally, positive sentiment ads were more engaging than negative ads, and sociolinguistic features (e.g., use of religion-relevant words) were identified as highly important in the makeup of an engaging ad. Linear SVM and Logistic Regression classifiers achieved the highest mean F-scores (93.6% for both models), determining that the optimal feature subset contains 12 and 6 features, respectively. Finally, we corroborate the findings of related works that the IRA specifically targeted Americans on divisive ad topics (e.g., LGBT rights, African American reparations).
Temporal Topic Modeling to Assess Associations between News Trends and Infectious Disease Outbreaks
Jun 01, 2016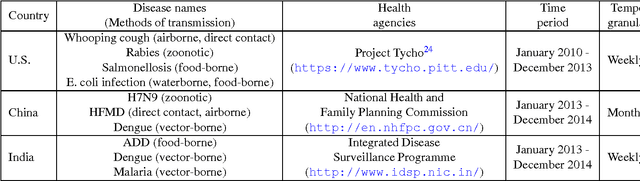
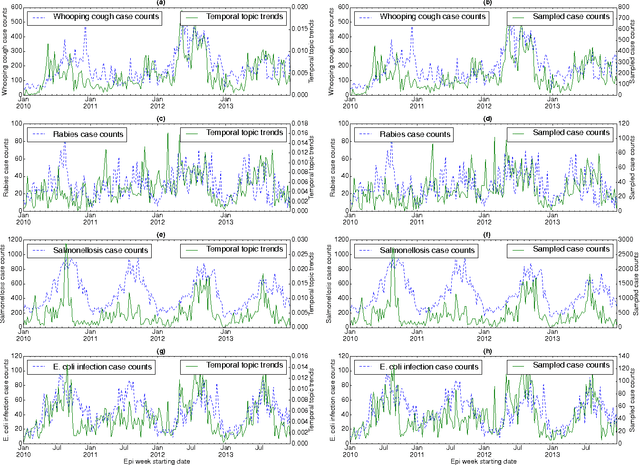

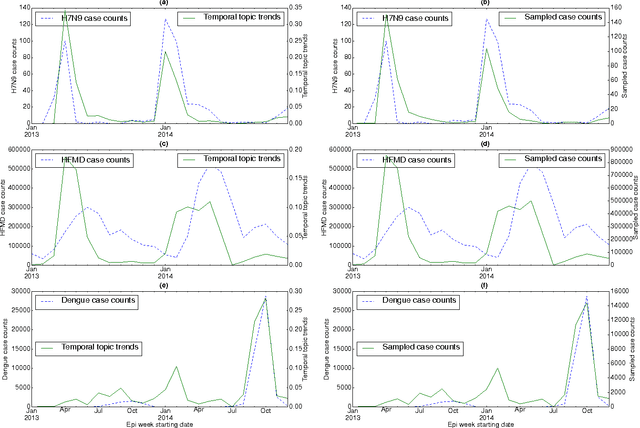
In retrospective assessments, internet news reports have been shown to capture early reports of unknown infectious disease transmission prior to official laboratory confirmation. In general, media interest and reporting peaks and wanes during the course of an outbreak. In this study, we quantify the extent to which media interest during infectious disease outbreaks is indicative of trends of reported incidence. We introduce an approach that uses supervised temporal topic models to transform large corpora of news articles into temporal topic trends. The key advantages of this approach include, applicability to a wide range of diseases, and ability to capture disease dynamics - including seasonality, abrupt peaks and troughs. We evaluated the method using data from multiple infectious disease outbreaks reported in the United States of America (U.S.), China and India. We noted that temporal topic trends extracted from disease-related news reports successfully captured the dynamics of multiple outbreaks such as whooping cough in U.S. (2012), dengue outbreaks in India (2013) and China (2014). Our observations also suggest that efficient modeling of temporal topic trends using time-series regression techniques can estimate disease case counts with increased precision before official reports by health organizations.
Exploratory Analysis of COVID-19 Related Tweets in North America to Inform Public Health Institutes
Jul 05, 2020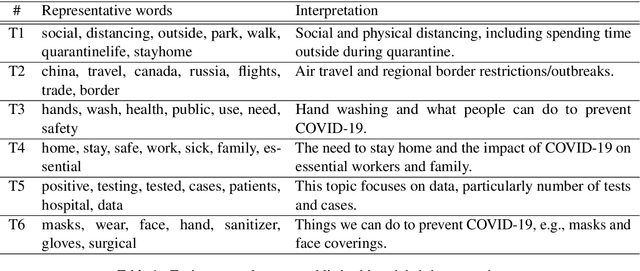
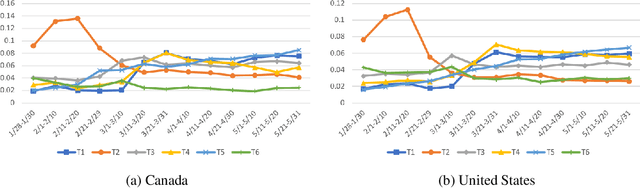

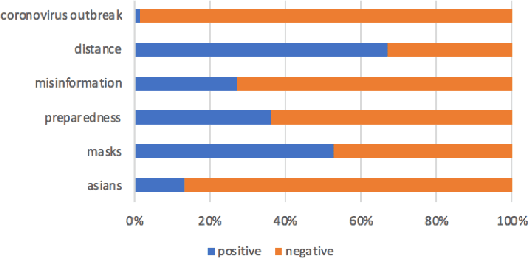
Social media is a rich source where we can learn about people's reactions to social issues. As COVID-19 has significantly impacted on people's lives, it is essential to capture how people react to public health interventions and understand their concerns. In this paper, we aim to investigate people's reactions and concerns about COVID-19 in North America, especially focusing on Canada. We analyze COVID-19 related tweets using topic modeling and aspect-based sentiment analysis, and interpret the results with public health experts. We compare timeline of topics discussed with timing of implementation of public health interventions for COVID-19. We also examine people's sentiment about COVID-19 related issues. We discuss how the results can be helpful for public health agencies when designing a policy for new interventions. Our work shows how Natural Language Processing (NLP) techniques could be applied to public health questions with domain expert involvement.
Using LDA and LSTM Models to Study Public Opinions and Critical Groups Towards Congestion Pricing in New York City through 2007 to 2019
Aug 01, 2020
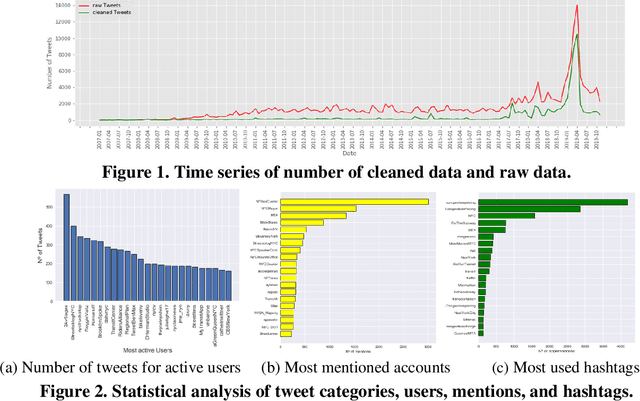

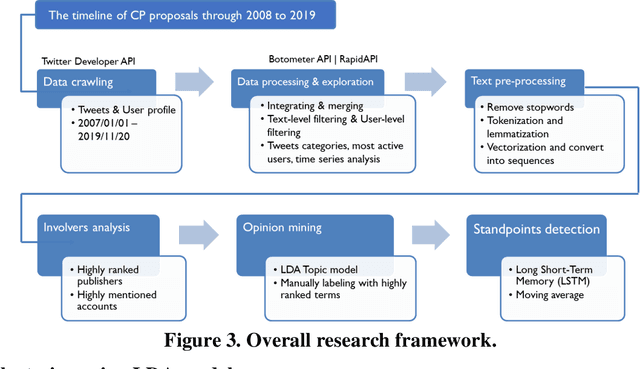
This study explores how people view and respond to the proposals of NYC congestion pricing evolve in time. To understand these responses, Twitter data is collected and analyzed. Critical groups in the recurrent process are detected by statistically analyzing the active users and the most mentioned accounts, and the trends of people's attitudes and concerns over the years are identified with text mining and hybrid Nature Language Processing techniques, including LDA topic modeling and LSTM sentiment classification. The result shows that multiple interest groups were involved and played crucial roles during the proposal, especially Mayor and Governor, MTA, and outer-borough representatives. The public shifted the concern of focus from the plan details to a wider city's sustainability and fairness. Furthermore, the plan's approval relies on several elements, the joint agreement reached in the political process, strong motivation in the real-world, the scheme based on balancing multiple interests, and groups' awareness of tolling's benefits and necessity.
Ex-Twit: Explainable Twitter Mining on Health Data
May 24, 2019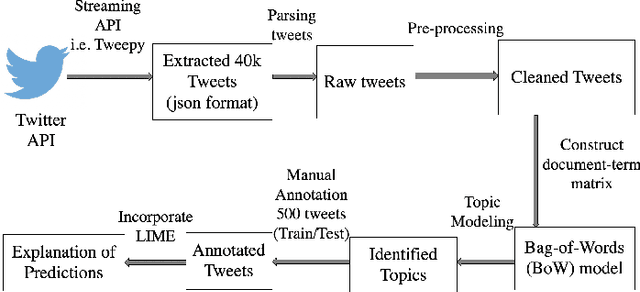
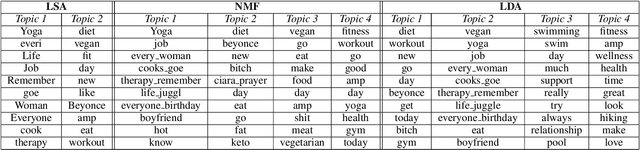
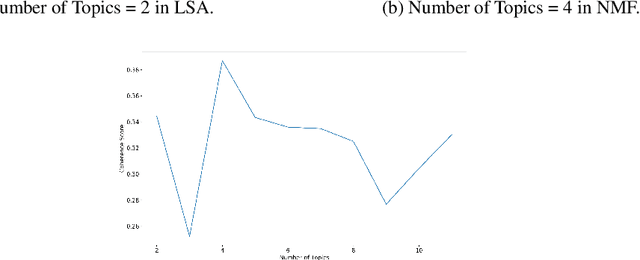
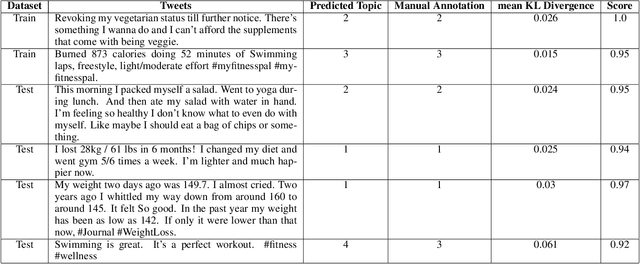
Since most machine learning models provide no explanations for the predictions, their predictions are obscure for the human. The ability to explain a model's prediction has become a necessity in many applications including Twitter mining. In this work, we propose a method called Explainable Twitter Mining (Ex-Twit) combining Topic Modeling and Local Interpretable Model-agnostic Explanation (LIME) to predict the topic and explain the model predictions. We demonstrate the effectiveness of Ex-Twit on Twitter health-related data.
Why Didn't You Listen to Me? Comparing User Control of Human-in-the-Loop Topic Models
May 23, 2019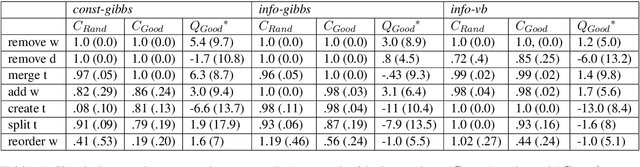
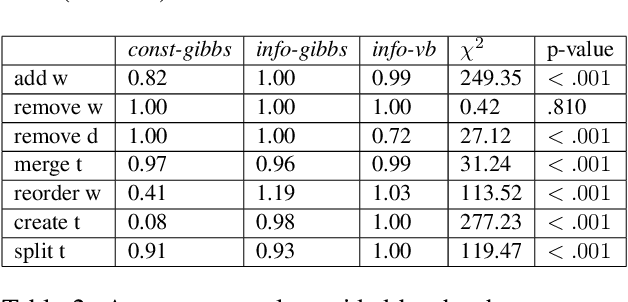
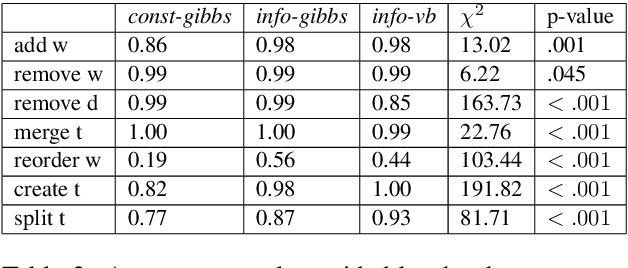
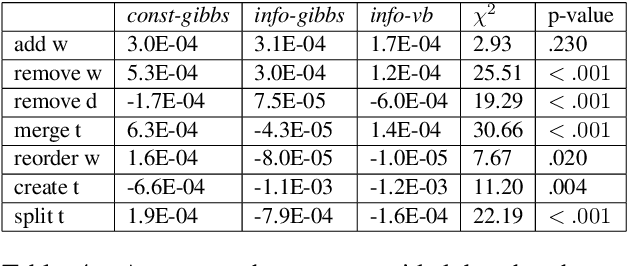
To address the lack of comparative evaluation of Human-in-the-Loop Topic Modeling (HLTM) systems, we implement and evaluate three contrasting HLTM approaches using simulation experiments. These approaches are based on previously proposed frameworks, including constraints and informed prior-based methods. User control is desired, so we propose a control metric to measure whether refinement operations are applied as users expect. Informed prior-based methods provide better control than constraints, but constraints yield higher quality topics.
EZLDA: Efficient and Scalable LDA on GPUs
Jul 17, 2020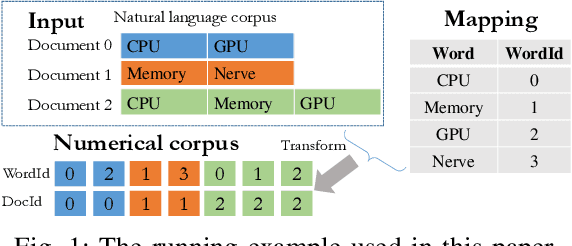
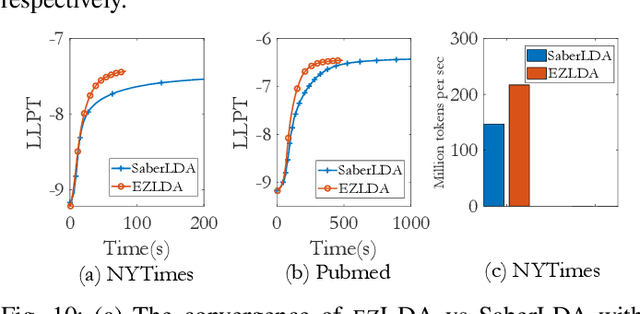
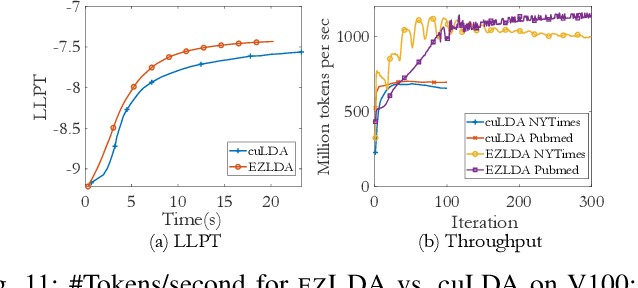
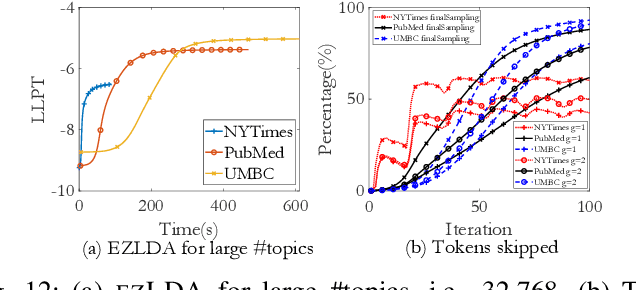
LDA is a statistical approach for topic modeling with a wide range of applications. However, there exist very few attempts to accelerate LDA on GPUs which come with exceptional computing and memory throughput capabilities. To this end, we introduce EZLDA which achieves efficient and scalable LDA training on GPUs with the following three contributions: First, EZLDA introduces three-branch sampling method which takes advantage of the convergence heterogeneity of various tokens to reduce the redundant sampling task. Second, to enable sparsity-aware format for both D and W on GPUs with fast sampling and updating, we introduce hybrid format for W along with corresponding token partition to T and inverted index designs. Third, we design a hierarchical workload balancing solution to address the extremely skewed workload imbalance problem on GPU and scaleEZLDA across multiple GPUs. Taken together, EZLDA achieves superior performance over the state-of-the-art attempts with lower memory consumption.