 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
A Random Matrix Perspective on Random Tensors
Aug 02, 2021
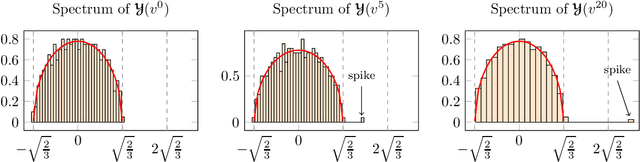
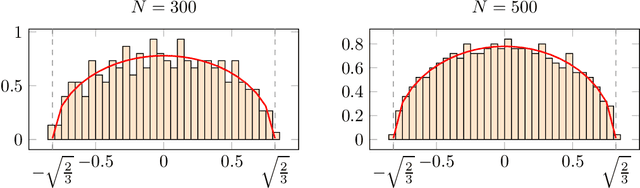
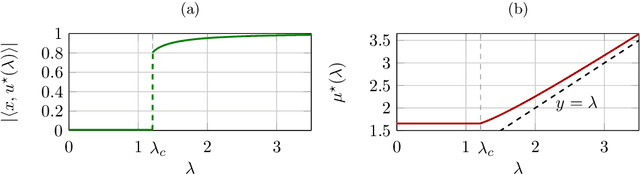
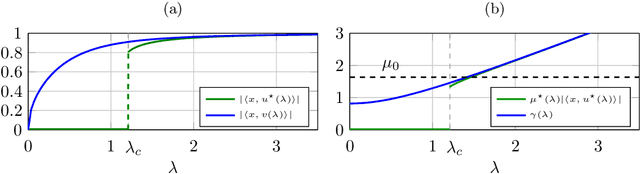
Tensor models play an increasingly prominent role in many fields, notably in machine learning. In several applications of such models, such as community detection, topic modeling and Gaussian mixture learning, one must estimate a low-rank signal from a noisy tensor. Hence, understanding the fundamental limits and the attainable performance of estimators of that signal inevitably calls for the study of random tensors. Substantial progress has been achieved on this subject thanks to recent efforts, under the assumption that the tensor dimensions grow large. Yet, some of the most significant among these results--in particular, a precise characterization of the abrupt phase transition (in terms of signal-to-noise ratio) that governs the performance of the maximum likelihood (ML) estimator of a symmetric rank-one model with Gaussian noise--were derived on the basis of statistical physics ideas, which are not easily accessible to non-experts. In this work, we develop a sharply distinct approach, relying instead on standard but powerful tools brought by years of advances in random matrix theory. The key idea is to study the spectra of random matrices arising from contractions of a given random tensor. We show how this gives access to spectral properties of the random tensor itself. In the specific case of a symmetric rank-one model with Gaussian noise, our technique yields a hitherto unknown characterization of the local maximum of the ML problem that is global above the phase transition threshold. This characterization is in terms of a fixed-point equation satisfied by a formula that had only been previously obtained via statistical physics methods. Moreover, our analysis sheds light on certain properties of the landscape of the ML problem in the large-dimensional setting. Our approach is versatile and can be extended to other models, such as asymmetric, non-Gaussian and higher-order ones.
Unsupervised Learning on 3D Point Clouds by Clustering and Contrasting
Feb 14, 2022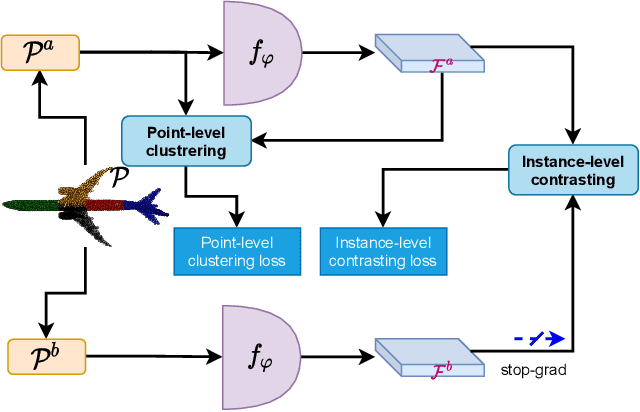
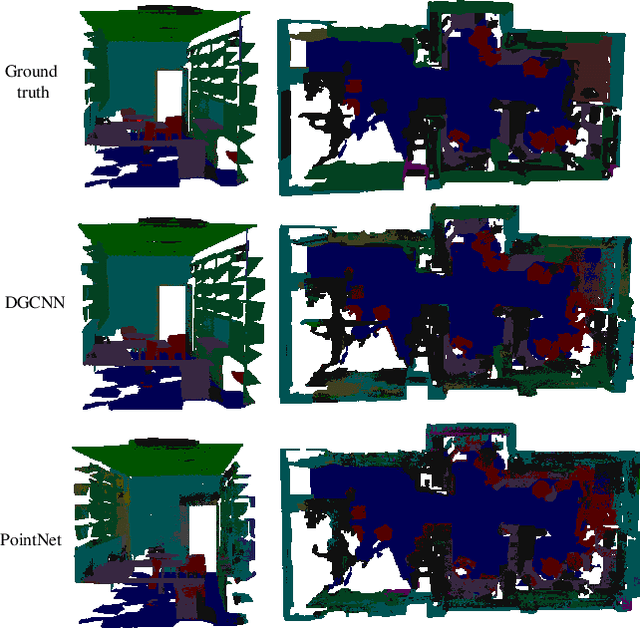
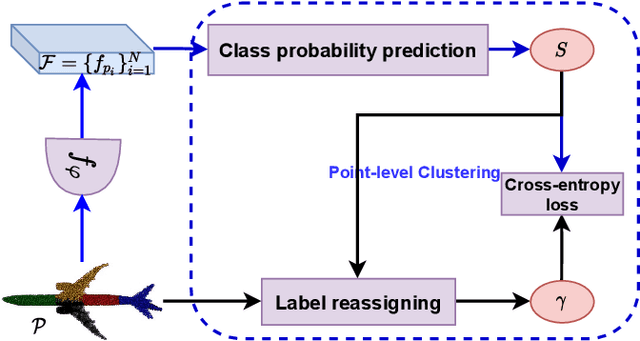
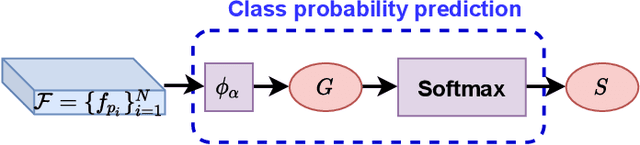
Learning from unlabeled or partially labeled data to alleviate human labeling remains a challenging research topic in 3D modeling. Along this line, unsupervised representation learning is a promising direction to auto-extract features without human intervention. This paper proposes a general unsupervised approach, named \textbf{ConClu}, to perform the learning of point-wise and global features by jointly leveraging point-level clustering and instance-level contrasting. Specifically, for one thing, we design an Expectation-Maximization (EM) like soft clustering algorithm that provides local supervision to extract discriminating local features based on optimal transport. We show that this criterion extends standard cross-entropy minimization to an optimal transport problem, which we solve efficiently using a fast variant of the Sinkhorn-Knopp algorithm. For another, we provide an instance-level contrasting method to learn the global geometry, which is formulated by maximizing the similarity between two augmentations of one point cloud. Experimental evaluations on downstream applications such as 3D object classification and semantic segmentation demonstrate the effectiveness of our framework and show that it can outperform state-of-the-art techniques.
ETC-NLG: End-to-end Topic-Conditioned Natural Language Generation
Aug 25, 2020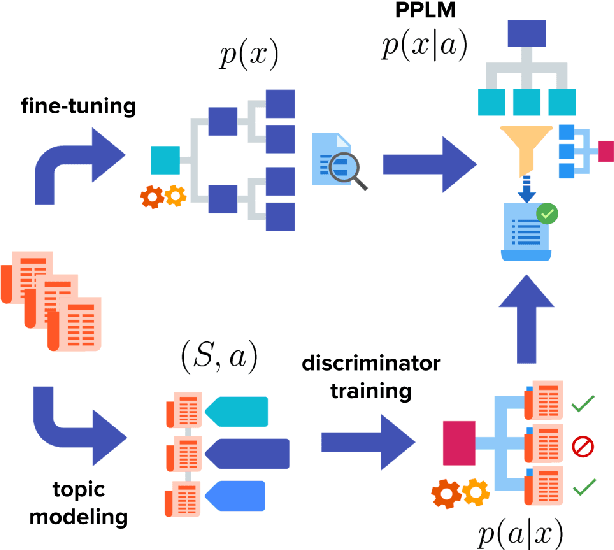
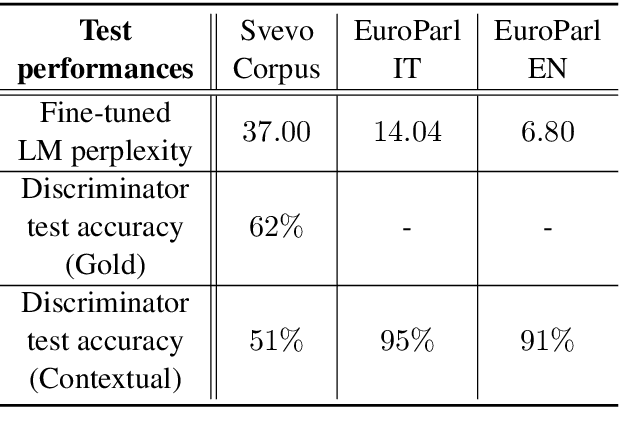

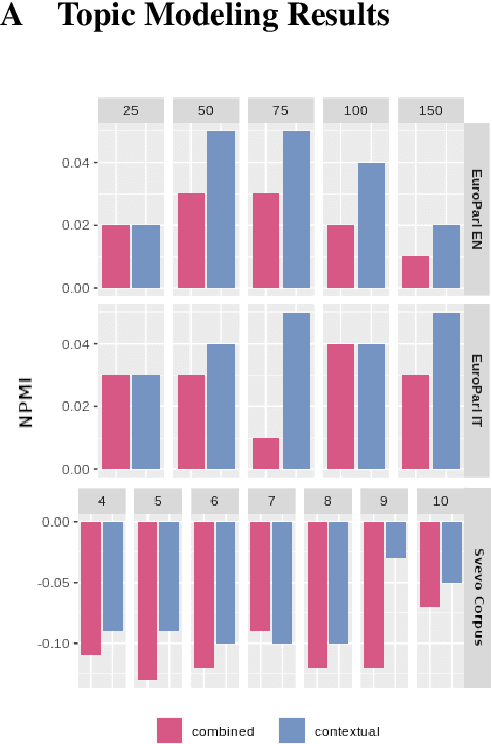
Plug-and-play language models (PPLMs) enable topic-conditioned natural language generation by pairing large pre-trained generators with attribute models used to steer the predicted token distribution towards the selected topic. Despite their computational efficiency, PPLMs require large amounts of labeled texts to effectively balance generation fluency and proper conditioning, making them unsuitable for low-resource settings. We present ETC-NLG, an approach leveraging topic modeling annotations to enable fully-unsupervised End-to-end Topic-Conditioned Natural Language Generation over emergent topics in unlabeled document collections. We first test the effectiveness of our approach in a low-resource setting for Italian, evaluating the conditioning for both topic models and gold annotations. We then perform a comparative evaluation of ETC-NLG for Italian and English using a parallel corpus. Finally, we propose an automatic approach to estimate the effectiveness of conditioning on the generated utterances.
Viewpoint and Topic Modeling of Current Events
Aug 14, 2016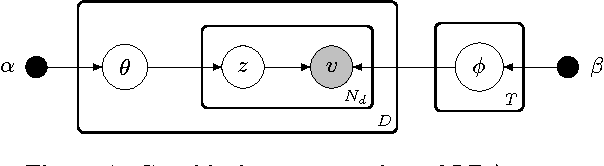

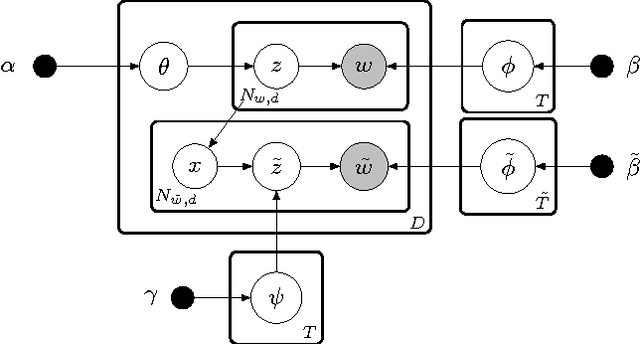

There are multiple sides to every story, and while statistical topic models have been highly successful at topically summarizing the stories in corpora of text documents, they do not explicitly address the issue of learning the different sides, the viewpoints, expressed in the documents. In this paper, we show how these viewpoints can be learned completely unsupervised and represented in a human interpretable form. We use a novel approach of applying CorrLDA2 for this purpose, which learns topic-viewpoint relations that can be used to form groups of topics, where each group represents a viewpoint. A corpus of documents about the Israeli-Palestinian conflict is then used to demonstrate how a Palestinian and an Israeli viewpoint can be learned. By leveraging the magnitudes and signs of the feature weights of a linear SVM, we introduce a principled method to evaluate associations between topics and viewpoints. With this, we demonstrate, both quantitatively and qualitatively, that the learned topic groups are contextually coherent, and form consistently correct topic-viewpoint associations.
Panarchy: ripples of a boundary concept
Dec 28, 2020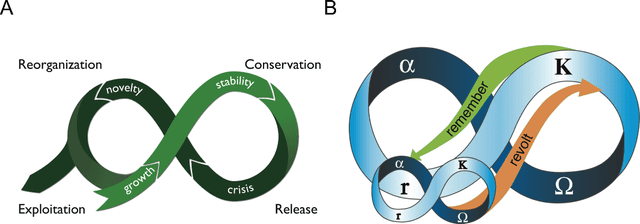
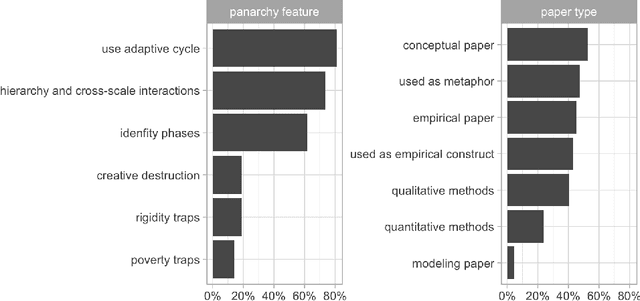
How do social-ecological systems change over time? In 2002 Holling and colleagues proposed the concept of Panarchy, which presented social-ecological systems as an interacting set of adaptive cycles, each of which is produced by the dynamic tensions between novelty and efficiency at multiple scales. Initially introduced as a conceptual framework and set of metaphors, panarchy has gained the attention of scholars across many disciplines and its ideas continue to inspire further conceptual developments. Almost twenty years after this concept was introduced we review how it has been used, tested, extended and revised. We do this by combining qualitative methods and machine learning. Document analysis was used to code panarchy features that are commonly used in the scientific literature (N = 42), a qualitative analysis that was complemented with topic modeling of 2177 documents. We find that the adaptive cycle is the feature of panarchy that has attracted the most attention. Challenges remain in empirically grounding the metaphor, but recent theoretical and empirical work offers some avenues for future research.
Semantic Concept Spaces: Guided Topic Model Refinement using Word-Embedding Projections
Aug 01, 2019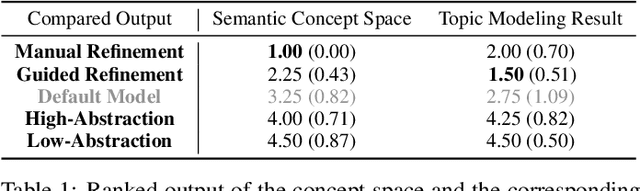
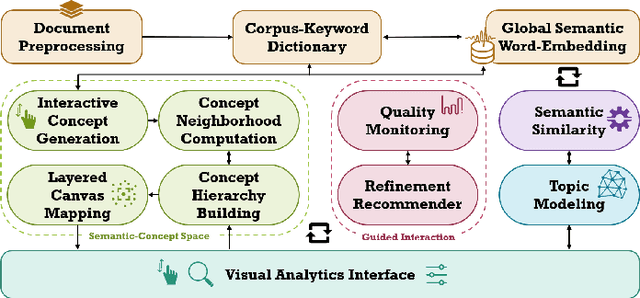
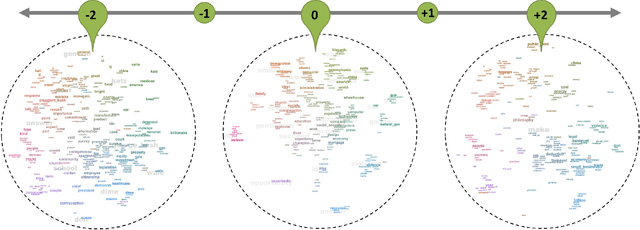

We present a framework that allows users to incorporate the semantics of their domain knowledge for topic model refinement while remaining model-agnostic. Our approach enables users to (1) understand the semantic space of the model, (2) identify regions of potential conflicts and problems, and (3) readjust the semantic relation of concepts based on their understanding, directly influencing the topic modeling. These tasks are supported by an interactive visual analytics workspace that uses word-embedding projections to define concept regions which can then be refined. The user-refined concepts are independent of a particular document collection and can be transferred to related corpora. All user interactions within the concept space directly affect the semantic relations of the underlying vector space model, which, in turn, change the topic modeling. In addition to direct manipulation, our system guides the users' decision-making process through recommended interactions that point out potential improvements. This targeted refinement aims at minimizing the feedback required for an efficient human-in-the-loop process. We confirm the improvements achieved through our approach in two user studies that show topic model quality improvements through our visual knowledge externalization and learning process.
WHAI: Weibull Hybrid Autoencoding Inference for Deep Topic Modeling
Mar 04, 2018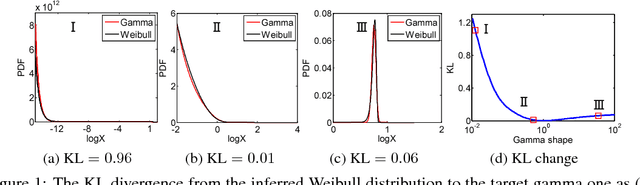
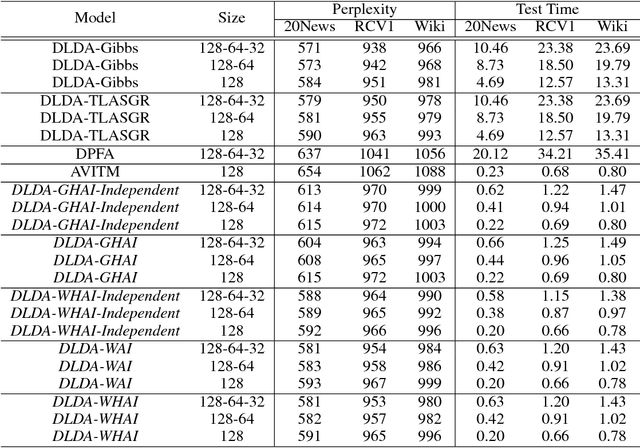
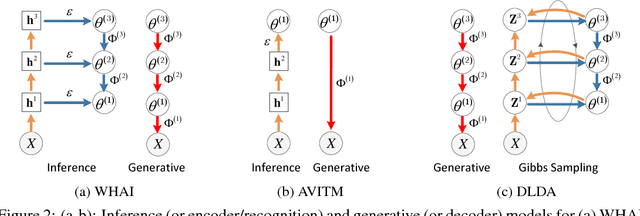
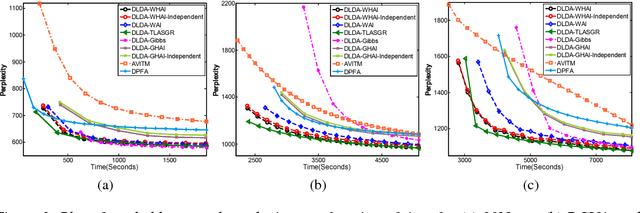
To train an inference network jointly with a deep generative topic model, making it both scalable to big corpora and fast in out-of-sample prediction, we develop Weibull hybrid autoencoding inference (WHAI) for deep latent Dirichlet allocation, which infers posterior samples via a hybrid of stochastic-gradient MCMC and autoencoding variational Bayes. The generative network of WHAI has a hierarchy of gamma distributions, while the inference network of WHAI is a Weibull upward-downward variational autoencoder, which integrates a deterministic-upward deep neural network, and a stochastic-downward deep generative model based on a hierarchy of Weibull distributions. The Weibull distribution can be used to well approximate a gamma distribution with an analytic Kullback-Leibler divergence, and has a simple reparameterization via the uniform noise, which help efficiently compute the gradients of the evidence lower bound with respect to the parameters of the inference network. The effectiveness and efficiency of WHAI are illustrated with experiments on big corpora.
Model Fusion with Kullback--Leibler Divergence
Jul 13, 2020

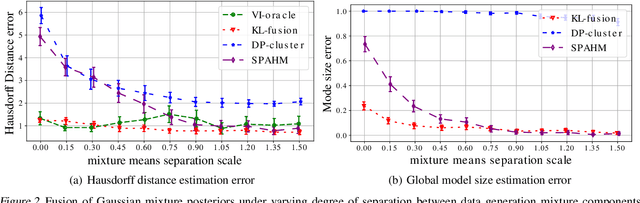
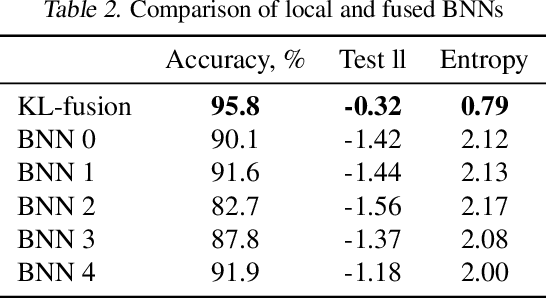
We propose a method to fuse posterior distributions learned from heterogeneous datasets. Our algorithm relies on a mean field assumption for both the fused model and the individual dataset posteriors and proceeds using a simple assign-and-average approach. The components of the dataset posteriors are assigned to the proposed global model components by solving a regularized variant of the assignment problem. The global components are then updated based on these assignments by their mean under a KL divergence. For exponential family variational distributions, our formulation leads to an efficient non-parametric algorithm for computing the fused model. Our algorithm is easy to describe and implement, efficient, and competitive with state-of-the-art on motion capture analysis, topic modeling, and federated learning of Bayesian neural networks.
ATM:Adversarial-neural Topic Model
Nov 01, 2018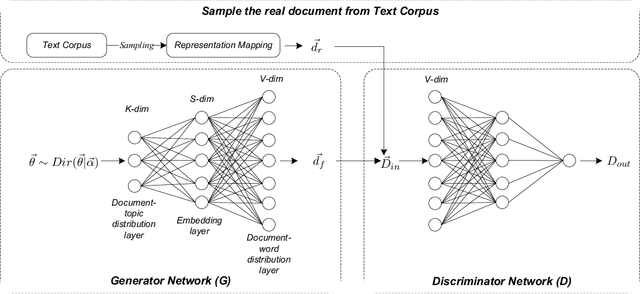

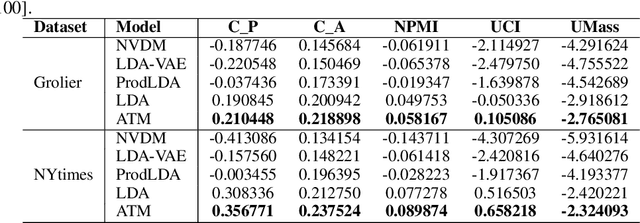
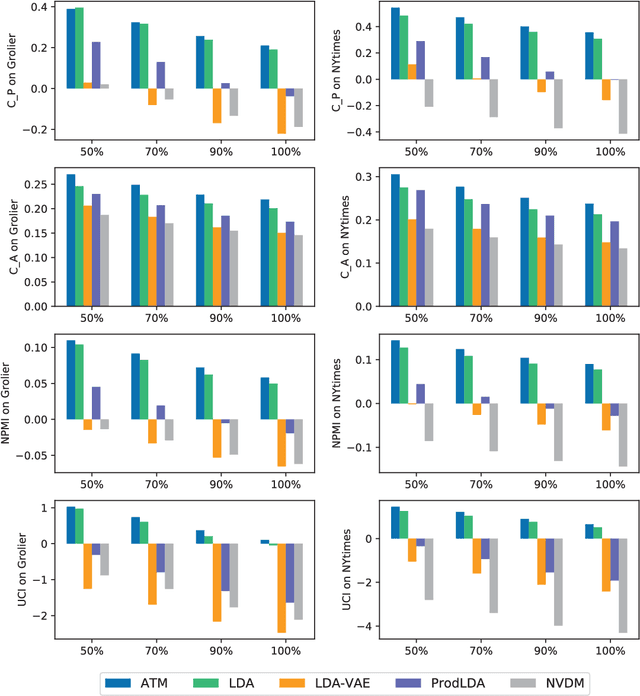
Topic models are widely used for thematic structure discovery in text. But traditional topic models often require dedicated inference procedures for specific tasks at hand. Also, they are not designed to generate word-level semantic representations. To address these limitations, we propose a topic modeling approach based on Generative Adversarial Nets (GANs), called Adversarial-neural Topic Model (ATM). The proposed ATM models topics with Dirichlet prior and employs a generator network to capture the semantic patterns among latent topics. Meanwhile, the generator could also produce word-level semantic representations. To illustrate the feasibility of porting ATM to tasks other than topic modeling, we apply ATM for open domain event extraction. Our experimental results on the two public corpora show that ATM generates more coherence topics, outperforming a number of competitive baselines. Moreover, ATM is able to extract meaningful events from news articles.
On Cross-Dataset Generalization in Automatic Detection of Online Abuse
Nov 03, 2020
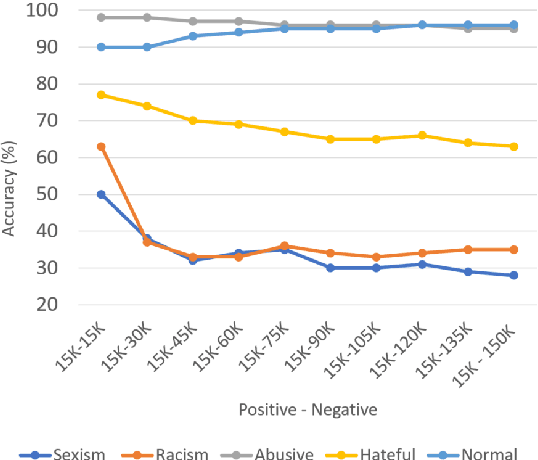
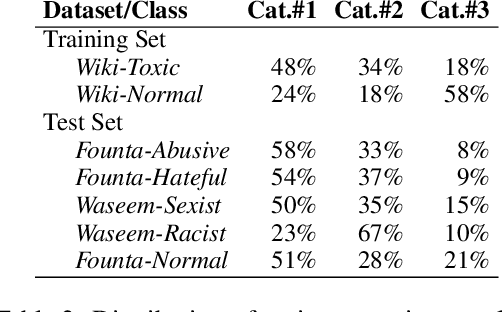
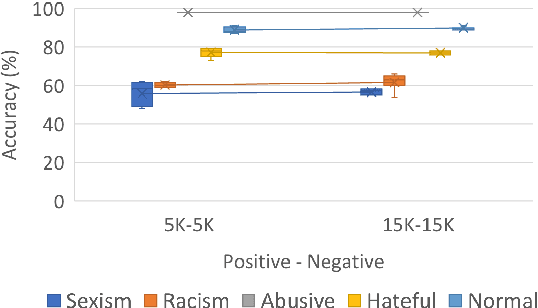
NLP research has attained high performances in abusive language detection as a supervised classification task. While in research settings, training and test datasets are usually obtained from similar data samples, in practice systems are often applied on data that are different from the training set in topic and class distributions. Also, the ambiguity in class definitions inherited in this task aggravates the discrepancies between source and target datasets. We explore the topic bias and the task formulation bias in cross-dataset generalization. We show that the benign examples in the Wikipedia Detox dataset are biased towards platform-specific topics. We identify these examples using unsupervised topic modeling and manual inspection of topics' keywords. Removing these topics increases cross-dataset generalization, without reducing in-domain classification performance. For a robust dataset design, we suggest applying inexpensive unsupervised methods to inspect the collected data and downsize the non-generalizable content before manually annotating for class labels.